Bölüm 1 Bu iki bölümlük serinin bir bölümünde, düz metin veri niteliklerini bir takma isme (veya tam tersine) dönüştüren bir takma ad verme hizmetinin nasıl oluşturulacağı anlatılmıştır. Merkezi bir takma ad oluşturma hizmeti, takma adlar oluşturmak için benzersiz ve evrensel olarak tanınan bir mimari sağlar. Sonuç olarak bir kuruluş, hassas verileri tüm platformlarda işlemek için standart bir süreç elde edebilir. Ayrıca bu, geliştirme ekiplerinin ve analitik kullanıcıların çeşitli uyumluluk gereksinimlerini anlamak ve uygulamak için gereken her türlü karmaşıklığı ve uzmanlığı ortadan kaldırarak onların iş sonuçlarına odaklanmalarına olanak tanır.
Ayrılmış hizmet tabanlı bir yaklaşımın izlenmesi, bir kuruluş olarak iş sorunlarınızı çözmek için belirli teknolojilerin kullanılması konusunda tarafsız olduğunuz anlamına gelir. Bireysel ekipler hangi teknolojiyi tercih ederse etsin, hassas verilere takma ad vermek için takma ad verme hizmetini arayabilirler.
Bu yazıda takma ad verme hizmetini kullanabilen ortak ayıklama, dönüştürme ve yükleme (ETL) tüketim modellerine odaklanıyoruz. ETL işlerinizde takma ad kullanma hizmetini nasıl kullanacağınızı tartışıyoruz. Amazon EMR'si (kullanarak EC2'de Amazon EMR) akış ve toplu kullanım durumları için. Ek olarak, bir Amazon Atina ve AWS Tutkal dayalı tüketim modeli GitHub repo Çözümün
Çözüme genel bakış
Aşağıdaki şemada çözüm mimarisi açıklanmaktadır.

Sağdaki hesap, bu serinin 1. Bölümünde verilen talimatları kullanarak dağıtabileceğiniz takma ad verme hizmetini barındırıyor.
Soldaki hesap, bu gönderinin bir parçası olarak kurduğunuz hesaptır ve takma ad verme hizmetini kullanarak Amazon EMR'yi temel alan ETL platformunu temsil eder.
Takma ad kullanma hizmetini ve ETL platformunu aynı hesapta dağıtabilirsiniz.
Amazon EMR, Apache Spark gibi büyük veri çerçevelerini hızlı ve uygun maliyetli bir şekilde oluşturmanıza, çalıştırmanıza ve ölçeklendirmenize olanak tanır.
Bu çözümde, takma ad verme hizmetinin nasıl kullanılacağını gösteriyoruz. Amazon EMR'si ile Apache Spark toplu ve akış kullanım durumları için. Toplu uygulama, verileri bir Amazon Basit Depolama Hizmeti (Amazon S3) kovası ve akış uygulaması kayıtları tüketiyor Amazon Kinesis Veri Akışları.
Toplu işlerde ve akış işlerinde kullanılan PySpark kodu
Her iki uygulama da takma adla bağlantılı API Ağ Geçidine karşı HTTP POST çağrıları yapan ortak bir yardımcı program işlevi kullanır AWS Lambda işlev. REST API çağrıları, Spark RDD kullanılarak Spark bölümü başına yapılır. haritaBölümler işlev. POST istek gövdesi, belirli bir giriş sütunu için benzersiz değerlerin listesini içerir. POST istek yanıtı karşılık gelen takma ad verilmiş değerleri içerir. Kod, belirli bir veri kümesi için hassas değerleri takma adlı değerlerle değiştirir. Sonuç Amazon S3'e kaydedilir ve AWS Tutkal Veri Kataloğu, Apache kullanılarak Buzdağı tablo formatı.
Iceberg, ACID işlemlerini, şema gelişimini ve zaman yolculuğu sorgularını destekleyen açık bir tablo formatıdır. Uygulamak için bu özellikleri kullanabilirsiniz. Sağ unutulmaya SQL ifadelerini veya programlama arayüzlerini kullanan (veya veri silme) çözümleri. Iceberg, 6.5.0 sürümünden itibaren Amazon EMR, AWS Glue ve Athena tarafından desteklenmektedir. Toplu iş ve akış modelleri, hedef format olarak Buzdağı'nı kullanır. Buzdağı kullanılarak ACID uyumlu bir veri gölünün nasıl oluşturulacağına ilişkin bir genel bakış için bkz. Amazon EMR'de Apache Iceberg'i kullanarak yüksek performanslı, ACID uyumlu, gelişen bir veri gölü oluşturun.
Önkoşullar
Aşağıdaki ön koşullara sahip olmalısınız:
- An AWS hesabı.
- An AWS Kimlik ve Erişim Yönetimi (IAM) sorumlusunun dağıtım ayrıcalıklarına sahip olması AWS CloudFormation yığın ve ilgili kaynaklar.
- The AWS Komut Satırı Arayüzü (AWS CLI), sağlanan komut dosyalarını çalıştırmak için kullanacağınız geliştirme veya dağıtım makinesine kuruludur.
- Çözümün dağıtılacağı aynı hesapta ve AWS Bölgesinde bir S3 klasörü.
- Python3 komutların çalıştırıldığı yerel makineye kurulur.
- PyYAML kullanılarak kuruldu bip.
- CloudFormation yığınlarını dağıtan bash komut dosyalarını çalıştıran bir bash terminali.
- Parke dosyalarındaki giriş veri kümesini içeren ek bir S3 klasörü (yalnızca toplu uygulamalar için). Kopyala örnek veri kümesi S3 kovasına.
- Kopyası en son kod deposu kullanarak yerel makinede
git cloneveya indirme seçeneğini seçin.
Yeni bir bash terminali açın ve klonlanan havuzun kök klasörüne gidin.
Önerilen modellerin kaynak kodu klonlanmış depoda bulunabilir. Aşağıdaki parametreleri kullanır:
- ARTEFACT_S3_BUCKET – Altyapı kodunun depolanacağı S3 klasörü. Paketin çözümün bulunduğu hesapta ve Bölgede oluşturulması gerekir.
- AWS_REGION – Çözümün konuşlandırılacağı Bölge.
- AWS_PROFİL – Uygulanacak adlandırılmış profil AWS CLI komutu. Bu, ilgili kaynakların CloudFormation yığınını dağıtma ayrıcalıklarına sahip bir IAM sorumlusunun kimlik bilgilerini içermelidir.
- SUBNET_ID – EMR kümesinin etkinleştirileceği alt ağ kimliği. Alt ağ önceden mevcuttur ve gösterim amacıyla varsayılan VPC'nin varsayılan alt ağ kimliğini kullanırız.
- EP_URL – Takma ad verme hizmetinin uç nokta URL'si. Bunu şu şekilde dağıtılan çözümden alın: Bölüm 1 bu serinin.
- API_SECRET - Bir Amazon API Ağ Geçidi anahtar içinde saklanacak AWS Sırları Yöneticisi. API anahtarı, şurada gösterilen dağıtımdan oluşturulur: Bölüm 1 bu serinin.
- S3_INPUT_PATH – Giriş veri kümesini Parquet dosyaları olarak içeren klasörü işaret eden S3 URI.
- KİNESİS_DATA_STREAM_NAME - CloudFormation yığınıyla dağıtılan Kinesis veri akışı adı.
- PARTİ BOYUTU - Toplu iş başına veri akışına aktarılacak kayıt sayısı.
- THREADS_NUM - Veri akışına veri yüklemek için yerel makinede kullanılan paralel iş parçacıklarının sayısı. Daha fazla konu daha yüksek bir mesaj hacmine karşılık gelir.
- EMR_CLUSTER_ID – Kodun çalıştırılacağı EMR kümesi kimliği (EMR kümesi, CloudFormation yığını tarafından oluşturulmuştur).
- Yığın_adı – Dağıtım betiğinde atanan CloudFormation yığınının adı.
Toplu dağıtım adımları
Önkoşullarda açıklandığı gibi, çözümü dağıtmadan önce Parquet dosyalarını yükleyin. veri kümesini test et Amazon S3'e. Daha sonra parametre olarak dosyaları içeren klasörün S3 yolunu sağlayın. <S3_INPUT_PATH>.
Çözüm kaynaklarını AWS CloudFormation üzerinden oluşturuyoruz. Çalıştırarak çözümü dağıtabilirsiniz. konuşlandırma_1.sh komut dosyası, içinde yer alan deployment_scripts klasör.
Dağıtım önkoşulları karşılandıktan sonra çözümü dağıtmak için aşağıdaki komutu girin:
sh ./deployment_scripts/deploy_1.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>
-i <S3_INPUT_PATH>Çıktı aşağıdaki ekran görüntüsüne benzemelidir.

Temizleme komutu için gerekli parametreler, işlemin sonunda yazdırılır. deploy_1.sh senaryo. Bu değerleri mutlaka not edin.
Toplu çözümü test edin
Kullanılarak dağıtılan CloudFormation şablonunda deploy_1.sh komut dosyası, aşağıdakileri içeren EMR adımı Spark toplu uygulaması EMR kümesi kurulumunun sonuna eklenir.
Sonuçları doğrulamak için CloudFormation yığın çıktılarında tanımlanan S3 klasörünü değişkenle kontrol edin SparkOutputLocation.

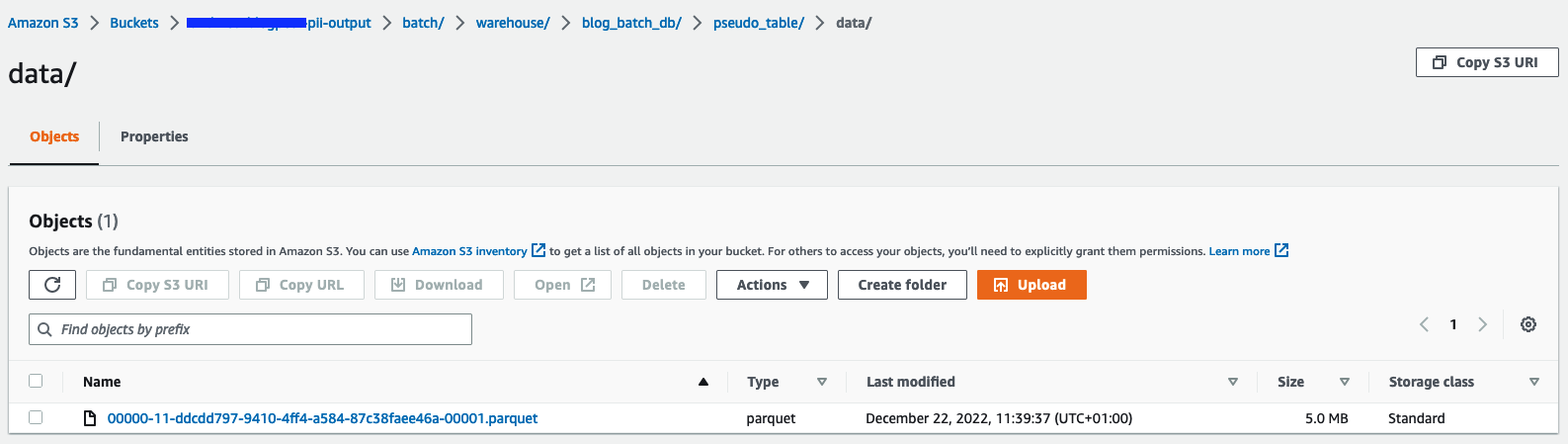
Ayrıca Athena'yı şu amaçlarla da kullanabilirsiniz: tabloyu sorgula pseudo_table veritabanında blog_batch_db.
Toplu kaynakları temizleme
Bu tatbikatın bir parçası olarak yaratılan kaynakları yok etmek,
bir bash terminalinde klonlanmış havuzun kök klasörüne gidin. Önceki çalıştırmanın çıktısı olarak gösterilen temizleme komutunu girin konuşlandırma_1.sh senaryo:
sh ./deployment_scripts/cleanup_1.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>Çıktı aşağıdaki ekran görüntüsüne benzemelidir.

Akış dağıtım adımları
Çözüm kaynaklarını AWS CloudFormation üzerinden oluşturuyoruz. Çalıştırarak çözümü dağıtabilirsiniz. konuşlandırma_2.sh komut dosyası, içinde yer alan deployment_scripts dosya. Bu kalıba ilişkin CloudFormation yığın şablonu şu adreste mevcuttur: GitHub repo.
Dağıtım önkoşulları karşılandıktan sonra çözümü dağıtmak için aşağıdaki komutu girin:
sh deployment_scripts/deploy_2.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>Çıktı aşağıdaki ekran görüntüsüne benzemelidir.
Temizleme komutu için gerekli parametreler çıktının sonunda yazdırılır. konuşlandırma_2.sh senaryo. Bu değerleri daha sonra kullanmak üzere kaydettiğinizden emin olun.
Akış çözümünü test edin
Kullanılarak dağıtılan CloudFormation şablonunda deploy_2.sh komut dosyası, aşağıdakileri içeren EMR adımı Spark akış uygulaması EMR kümesi kurulumunun sonuna eklenir. Uçtan uca ardışık düzeni test etmek için kayıtları dağıtılan Kinesis veri akışına aktarmanız gerekir. Bir bash terminalinde aşağıdaki komutları kullanarak, süreç manuel olarak durduruluncaya kadar kayıtları sürekli olarak akışa koyacak bir Kinesis üreticisini etkinleştirebilirsiniz. Yapımcının mesaj ses düzeyini değiştirerek kontrol edebilirsiniz. BATCH_SIZE ve THREADS_NUM değişkenler.


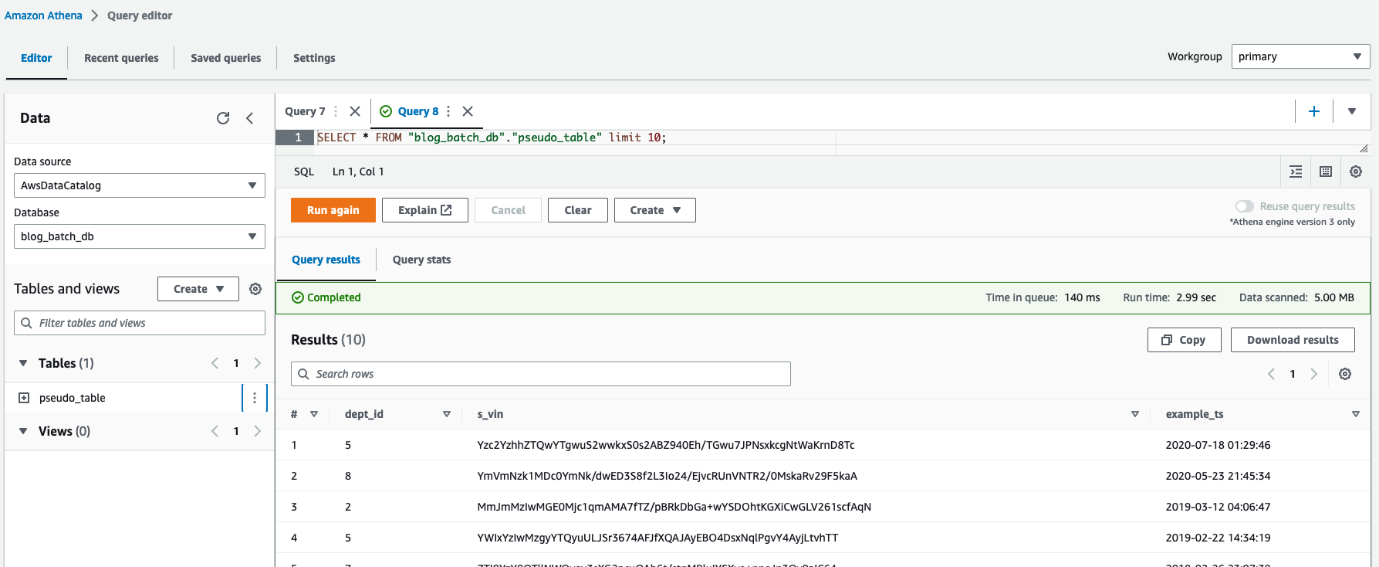
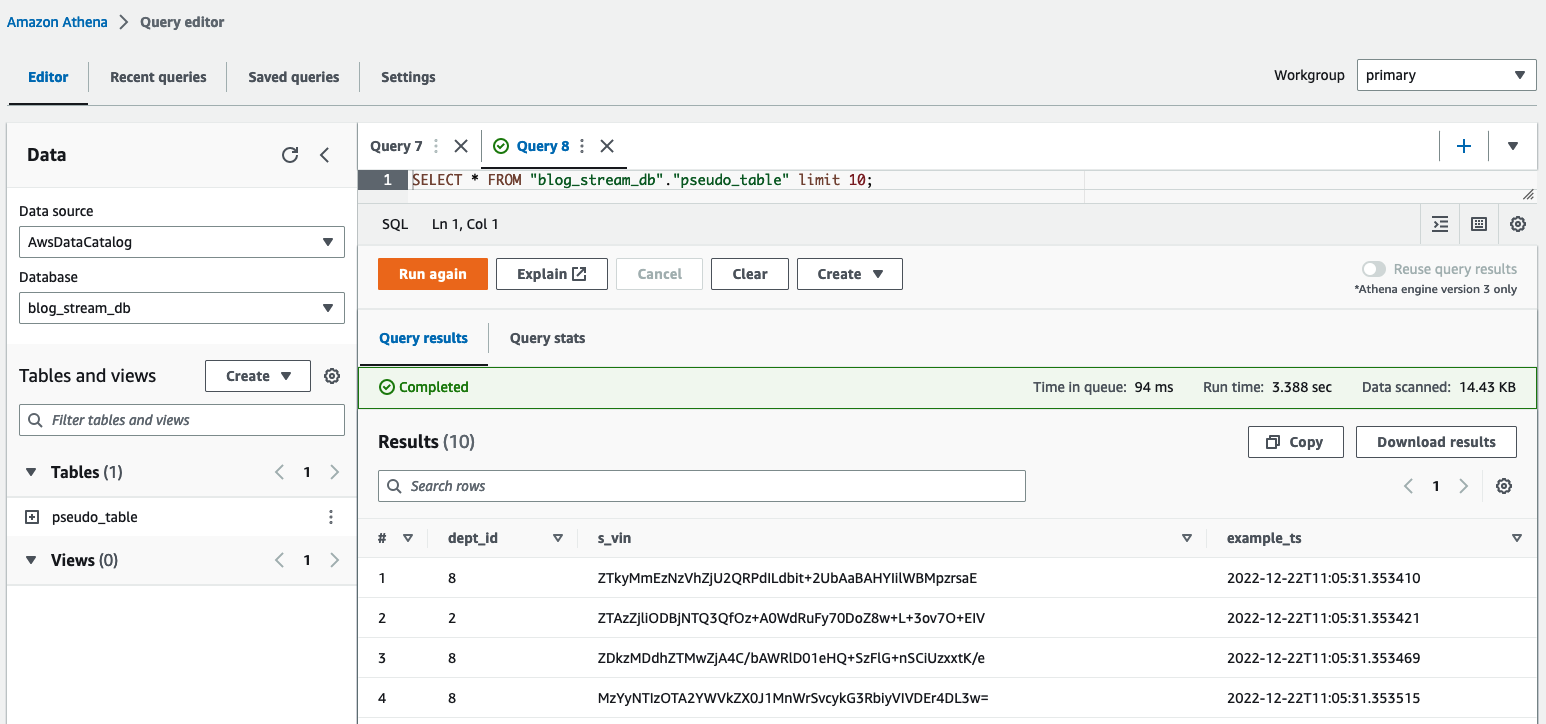
Athena sorgu düzenleyicisinde, sorgulayarak sonuçları kontrol edin. table pseudo_table veritabanında blog_stream_db.
Akış kaynaklarını temizleme
Bu alıştırmanın bir parçası olarak oluşturulan kaynakları yok etmek için aşağıdaki adımları tamamlayın:
- Önceki bölümde bash terminalinde başlatılan Python Kinesis üreticisini durdurun.
- Aşağıdaki komutu girin:
sh ./deployment_scripts/cleanup_2.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>Çıktı aşağıdaki ekran görüntüsüne benzemelidir.

Performans ayrıntıları
Kullanım durumları veri boyutu, işlem kapasitesi ve maliyet açısından gereksinimlere göre farklılık gösterebilir. Performansı etkileyebilecek bazı kıyaslama ve faktörleri sunduk; ancak, özel gereksinimlerinizi karşılayıp karşılamadığını görmek için çözümü daha düşük ortamlarda doğrulamanızı önemle tavsiye ederiz.
Önerilen çözümün (Amazon EMR kullanarak bir veri kümesine takma ad vermeyi amaçlayan) performansını, takma ad verme hizmetine yapılan maksimum paralel çağrı sayısı ve her çağrı için yük boyutu ile etkileyebilirsiniz. Paralel aramalar açısından dikkate alınması gereken faktörler şunlardır: Secrets Manager'dan GetSecretValue çağrı sınırı (saniyede 10.000, sabit sınır) ve Lambda varsayılan eşzamanlılık paralelliği (varsayılan olarak 1,000; kota isteği ile artırılabilir). Yürütücülerin sayısını, veri kümesini oluşturan bölüm sayısını ve küme yapılandırmasını (düğümlerin sayısı ve türü) ayarlayarak maksimum paralelliği kontrol edebilirsiniz. Her çağrının veri kapasitesi boyutu açısından dikkate alınması gereken faktörler şunlardır: API Ağ Geçidi maksimum yük boyutu (6 MB) ve Lambda fonksiyonunun maksimum çalışma süresi (15 dakika). Her API çağrısı başına takma ad verilecek öğe sayısını belirleyen PySpark betiğinin bir parametresi olan toplu iş boyutu değerini ayarlayarak yük boyutunu ve Lambda işlevi çalışma zamanını kontrol edebilirsiniz. Tüm bu faktörlerin etkisini yakalamak ve Amazon EMR'yi kullanarak tüketim kalıplarının performansını değerlendirmek için aşağıdaki senaryoları tasarladık ve izledik.
Toplu tüketim modeli performansı
Toplu tüketim modelinin performansını değerlendirmek için, her biri 1 MB olan 10, 100 ve 97.7 Parquet dosyasından oluşan üç giriş veri kümesiyle takma ad kullanma uygulamasını çalıştırdık. Giriş dosyalarını kullanarak oluşturduk. dataset_generator.py komut.
Küme kapasitesi düğümleri 1 birincil (m5.4xlarge) ve 15 çekirdek (m5d.8xlarge) idi. Bu küme yapılandırması her üç senaryo için de aynı kaldı ve Spark uygulamasının 100'e kadar yürütücü kullanmasına izin verdi. batch_sizeÜç senaryo için de aynı olan, API çağrısı başına 900 VIN'ye ayarlandı ve maksimum VIN boyutu 5 bayttı.
Aşağıdaki tabloda üç senaryoya ilişkin bilgiler yer almaktadır.
| Yürütme Kimliği | yeniden bölme | Veri Kümesi Boyutu | Uygulayıcı Sayısı | Yürütücü başına çekirdek | Yürütücü Hafızası | Süre |
| A | 800 | 9.53 GB | 100 | 4 | 4 GiB | 11 dakika, 10 saniye |
| B | 80 | 0.95 GB | 10 | 4 | 4 GiB | 8 dakika, 36 saniye |
| C | 8 | 0.09 GB | 1 | 4 | 4 GiB | 7 dakika, 56 saniye |
Gördüğümüz gibi, çağrıları takma ad verme hizmetimize doğru şekilde paralel hale getirmek, genel çalışma süresini kontrol etmemizi sağlar.
Aşağıdaki örneklerde takma ad kullanma hizmeti için üç önemli Lambda metriğini analiz ediyoruz: Invocations, ConcurrentExecutions, ve Duration.
Aşağıdaki grafik şunları göstermektedir: Invocations metrik, istatistikle birlikte SUM turuncu renkte ve RUNNING SUM Mavi.

Kümülatif çağrıların başlangıç ve bitiş noktaları arasındaki farkı hesaplayarak her çalıştırma sırasında kaç çağrı yapıldığını çıkarabiliriz.
| Çalıştırma kimliği | Veri Kümesi Boyutu | Toplam Çağrı |
| A | 9.53 GB | 1.467.000 - 0 = 1.467.000 |
| B | 0.95 GB | 1.467.000 - 1.616.500 = 149.500 |
| C | 0.09 GB | 1.616.500 - 1.631.000 = 14.500 |
Beklendiği gibi çağrı sayısı veri kümesi boyutuyla orantılı olarak 10 oranında artmaktadır.
Aşağıdaki grafik toplamı göstermektedir ConcurrentExecutions metrik, istatistikle birlikte MAX Mavi.
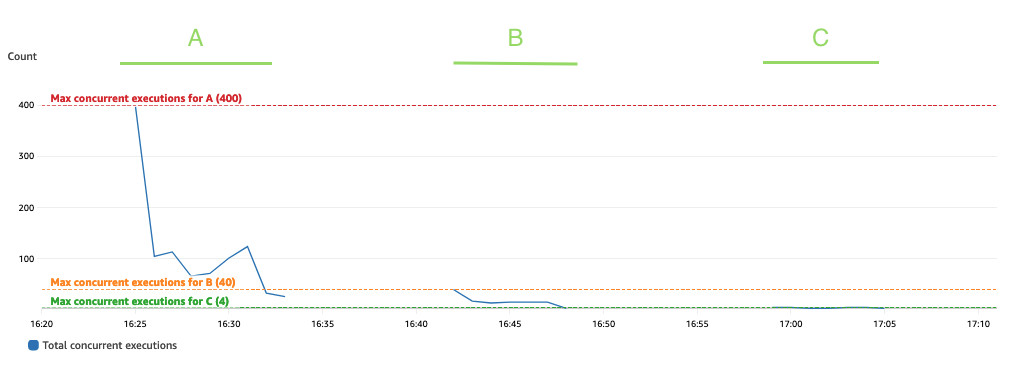
Uygulama, eşzamanlı Lambda işlevi çalıştırmalarının maksimum sayısı, paralel olarak işlenebilen Spark görevlerinin (Spark veri kümesi bölümleri) miktarına göre belirlenecek şekilde tasarlanmıştır. Bu sayı şu şekilde hesaplanabilir: MIN (yürütücüler x executor_cores, Spark veri kümesi bölümleri).
Testte, her biri dört çekirdekli 800 yürütücü kullanarak A işlenmiş 100 bölümü çalıştırın. Bu, 400 görevin paralel olarak işlenmesini sağlar, böylece Lambda işlevi eşzamanlı çalıştırmaları 400'ün üzerinde olamaz. Aynı mantık B ve C çalıştırmaları için de uygulandı. Bunun, eşzamanlı çalıştırma miktarının hiçbir zaman belirtilen değeri aşmadığı önceki grafikte yansıtıldığını görebiliriz. 400, 40 ve 4 değerleri.
Kısıtlamayı önlemek için paralel olarak işlenebilecek Spark görevlerinin miktarının Lambda işlevi eşzamanlılık sınırının üzerinde olmadığından emin olun. Durum böyleyse Lambda işlevi eşzamanlılık sınırını artırmanız (performansı korumak istiyorsanız) ya da bölüm miktarını veya mevcut yürütücülerin sayısını (uygulama performansını etkiler) azaltmanız gerekir.
Aşağıdaki grafik Lambda'yı göstermektedir Duration metrik, istatistikle birlikte AVG turuncu renkte ve MAX yeşil.
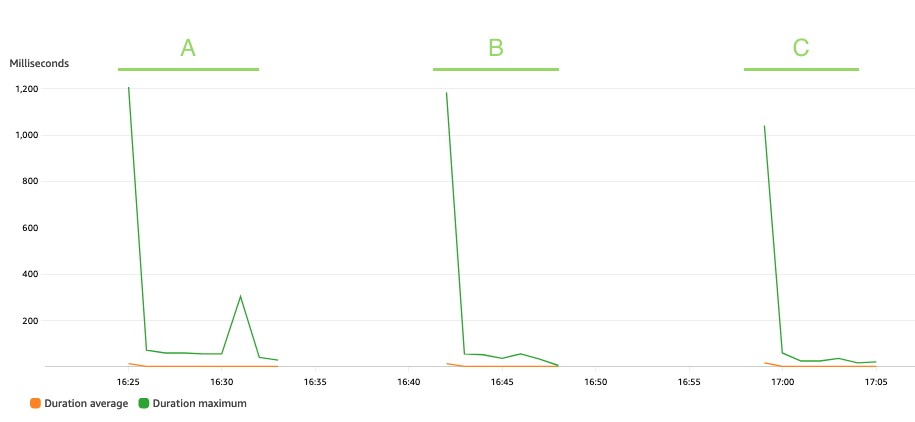
Beklendiği gibi, veri kümesinin boyutu, soğuk başlatmalarla karşı karşıya kalan bazı ilk çağrılar dışında, üç senaryo boyunca ortalama 3 milisaniye kadar sabit kalan takma ad verme işlevinin çalıştırılma süresini etkilemez. Bunun nedeni, her takma ad çağrısına dahil edilen maksimum kayıt sayısının sabit olmasıdır (batch_size değeri).
Lambda, çağrı sayısına ve kodunuzun çalışması için geçen süreye (süre) göre faturalandırılır. Takma ad kullanma hizmetinin maliyetini tahmin etmek için ortalama süre ve çağrı ölçümlerini kullanabilirsiniz.
Akış tüketim modeli performansı
Akış tüketim modelinin performansını değerlendirmek için yapımcı.py Kayıtları gruplar halinde Kinesis veri akışına gönderen bir Kinesis veri üreticisini tanımlayan komut dosyası.
Akış uygulaması 15 dakika boyunca çalışır durumda bırakıldı ve bir batch_interval 1 dakikadır; bu, akış verilerinin gruplara bölüneceği zaman aralığıdır. Aşağıdaki tablo ilgili faktörleri özetlemektedir.
| yeniden bölme | Küme Kapasitesi Düğümleri | Uygulayıcı Sayısı | Yöneticinin Hafızası | Toplu Pencere | Parti boyutu | Şasi Boyutu |
| 17 |
1 Birincil (m5.xlarge), 3 Çekirdek (m5.2xlarge) |
6 | 9 GiB | 60 saniye | 900 VIN/API çağrısı. | 5 Bayt / VIN |
Aşağıdaki grafiklerde Kinesis Veri Akışları ölçümleri gösterilmektedir PutRecords (mavi renkte) ve GetRecords (turuncu renkte) 1 dakikalık periyotlarla ve istatistik kullanılarak toplanmıştır SUM. İlk grafik, dakikada 6.8 MB'a ulaşan bayt cinsinden ölçümü gösteriyor. İkinci grafik, kayıt sayısındaki ölçümün dakikada 85,000 kayıtla zirve yaptığını gösteriyor.
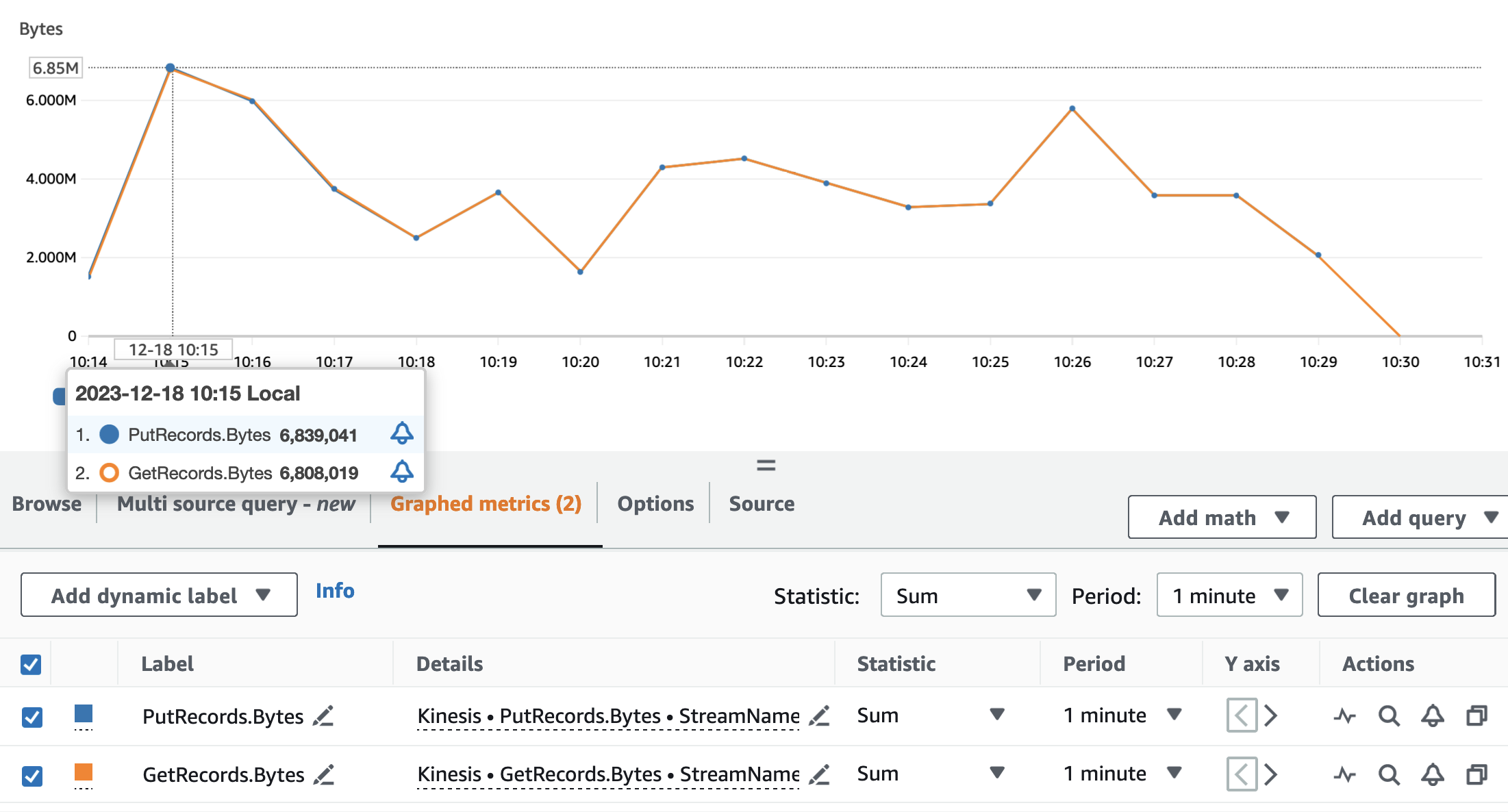

Metriklerin olduğunu görebiliriz GetRecords ve PutRecords neredeyse tüm uygulamanın çalışması için örtüşen değerlere sahip. Bu, akış uygulamasının akışın yüküne ayak uydurabildiği anlamına gelir.
Daha sonra takma ad kullanma hizmeti için ilgili Lambda metriklerini analiz ediyoruz: Invocations, ConcurrentExecutions, ve Duration.
Aşağıdaki grafik şunları göstermektedir: Invocations metrik, istatistikle birlikte SUM (turuncu renkte) ve RUNNING SUM Mavi.
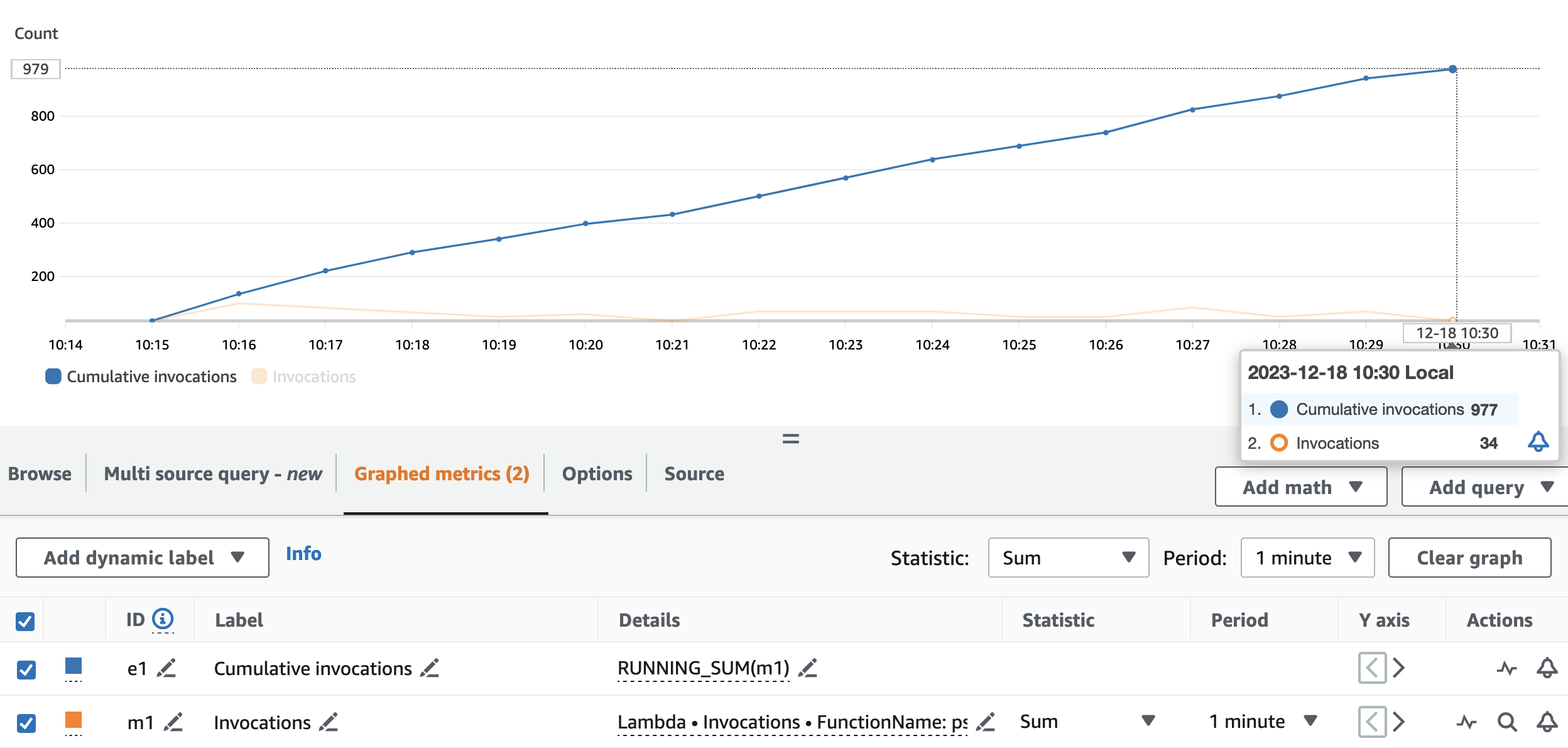
Kümülatif çağrıların başlangıç ve bitiş noktaları arasındaki farkı hesaplayarak çalıştırma sırasında kaç çağrı yapıldığını çıkarabiliriz. Spesifik olarak, 15 dakika içinde akış uygulaması, takma adlandırma API'sini 977 kez çağırdı; bu da dakikada yaklaşık 65 çağrı anlamına geliyor.
Aşağıdaki grafik toplamı göstermektedir ConcurrentExecutions metrik, istatistikle birlikte MAX Mavi.
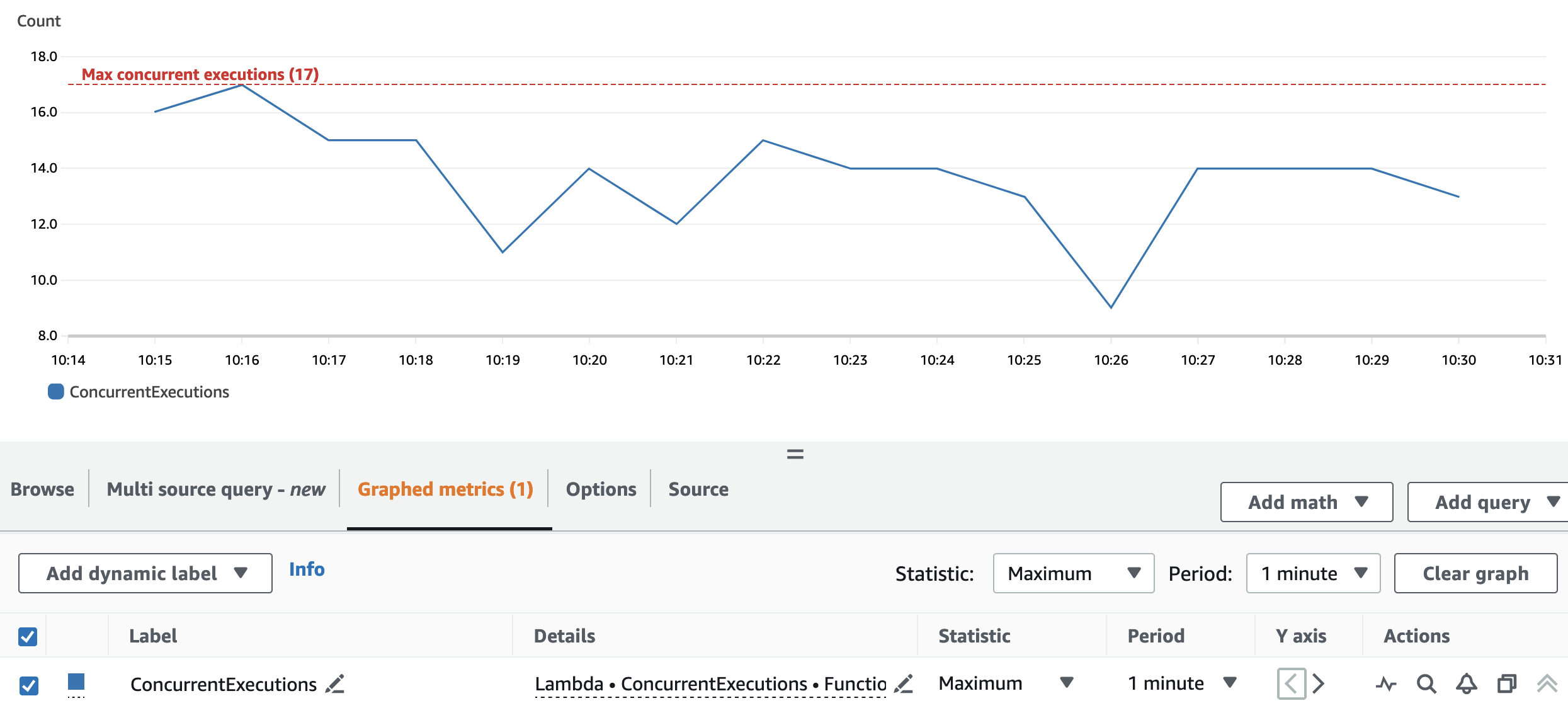
Yeniden bölümleme ve küme yapılandırması, uygulamanın tüm Spark RDD bölümlerini paralel olarak işlemesine olanak tanır. Sonuç olarak, Lambda işlevinin eşzamanlı çalıştırmaları her zaman yeniden bölümleme numarasına (17) eşit veya altındadır.
Kısıtlamayı önlemek için paralel olarak işlenebilecek Spark görevlerinin miktarının Lambda işlevi eşzamanlılık sınırının üzerinde olmadığından emin olun. Bu açıdan toplu kullanım durumuyla ilgili önerilerin aynısı geçerlidir.
Aşağıdaki grafik Lambda'yı göstermektedir Duration metrik, istatistikle birlikte AVG mavi ve MAX turuncu.
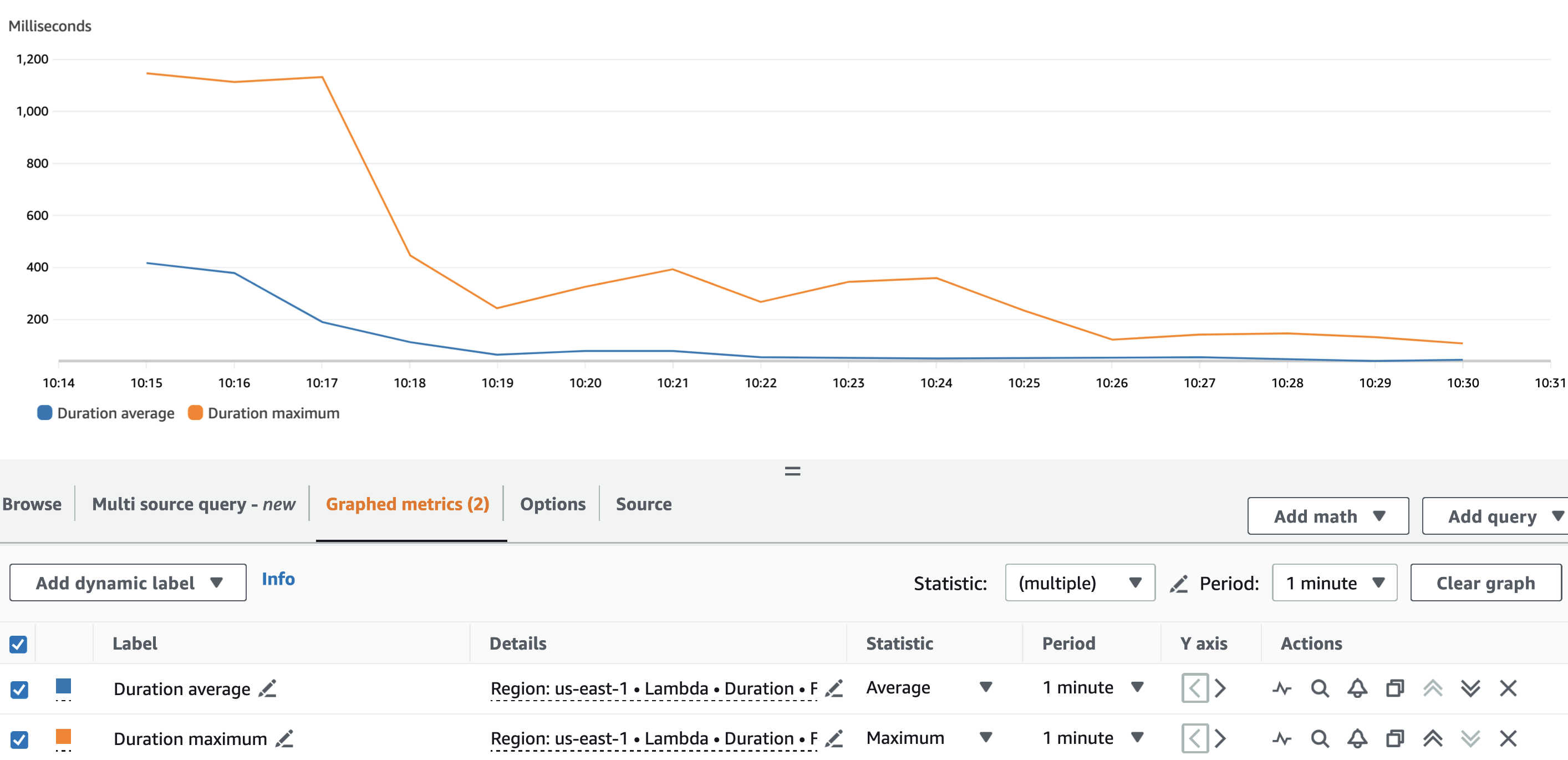
Beklendiği gibi, Lambda fonksiyonunun soğuk başlangıcı bir yana, takma ad verme fonksiyonunun ortalama süresi çalışma boyunca aşağı yukarı sabitti. Bunun nedeni batch_size Çağrı başına takma ad verilecek VIN sayısını tanımlayan değer 900 olarak ayarlandı ve bu değerde sabit kaldı.
Kinesis veri akışının alınma oranı ve akış uygulamamızın tüketim oranı, takma ad verme hizmetine karşı yapılan API çağrılarının sayısını ve dolayısıyla ilgili maliyeti etkileyen faktörlerdir.
Aşağıdaki grafik Lambda'yı göstermektedir Invocations metrik, istatistikle birlikte SUM turuncu ve Kinesis Veri Akışları GetRecords.Records metrik, istatistikle birlikte SUM Mavi. Akıştan dakika başına alınan kayıt miktarı ile Lambda işlevi çağrılarının miktarı arasında bir korelasyon olduğunu ve dolayısıyla akış çalıştırmasının maliyetini etkilediğini görebiliriz.

Ek olarak, batch_intervalkullanarak akış uygulamasının tüketim oranını kontrol edebiliriz. Spark akış özellikleri sevmek spark.streaming.receiver.maxRate ve spark.streaming.blockInterval. Daha fazla ayrıntı için bkz. Spark Yayını + Kinesis Entegrasyonu ve Spark Streaming Programlama Kılavuzu.
Sonuç
Veri gizliliği yasalarının kuralları ve düzenlemeleri arasında gezinmek zor olabilir. PII niteliklerinin takma adlandırılması, hassas verileri işlerken dikkate alınması gereken birçok noktadan biridir.
Bu iki bölümlük seride, sağlam bir veri platformu oluşturmanıza yardımcı olacak özelliklere sahip çeşitli AWS hizmetlerini kullanarak bir takma ad kullanma hizmetini nasıl oluşturup kullanabileceğinizi araştırdık. İçinde Bölüm 1takma ad verme hizmetinin nasıl oluşturulacağını göstererek temelini oluşturduk. Bu yazıda, takma ad kullanma hizmetini uygun maliyetli ve performanslı bir şekilde kullanmak için çeşitli modelleri sergiledik. Kontrol et GitHub Ek tüketim kalıpları için depo.
Yazarlar Hakkında
 Edvin Hallvaxhiu AWS Profesyonel Hizmetlere sahip Kıdemli Küresel Güvenlik Mimarıdır ve siber güvenlik ve otomasyon konusunda tutkuludur. Müşterilerin bulutta güvenli ve uyumlu çözümler oluşturmasına yardımcı olur. İş dışında seyahat etmeyi ve spor yapmayı sever.
Edvin Hallvaxhiu AWS Profesyonel Hizmetlere sahip Kıdemli Küresel Güvenlik Mimarıdır ve siber güvenlik ve otomasyon konusunda tutkuludur. Müşterilerin bulutta güvenli ve uyumlu çözümler oluşturmasına yardımcı olur. İş dışında seyahat etmeyi ve spor yapmayı sever.
 Rahul Şaurya AWS Profesyonel Hizmetlerinde Baş Büyük Veri Mimarıdır. AWS'de veri platformları ve analitik uygulamalar geliştiren müşterilere yardımcı oluyor ve onlarla yakın işbirliği içinde çalışıyor. Rahul, iş dışında köpeği Barney ile uzun yürüyüşler yapmayı seviyor.
Rahul Şaurya AWS Profesyonel Hizmetlerinde Baş Büyük Veri Mimarıdır. AWS'de veri platformları ve analitik uygulamalar geliştiren müşterilere yardımcı oluyor ve onlarla yakın işbirliği içinde çalışıyor. Rahul, iş dışında köpeği Barney ile uzun yürüyüşler yapmayı seviyor.
 Andrea Montanari AWS Profesyonel Hizmetlerinde Kıdemli Büyük Veri Mimarıdır. AWS'de geniş ölçekte analiz çözümleri oluşturma konusunda müşterileri ve iş ortaklarını aktif olarak destekliyor.
Andrea Montanari AWS Profesyonel Hizmetlerinde Kıdemli Büyük Veri Mimarıdır. AWS'de geniş ölçekte analiz çözümleri oluşturma konusunda müşterileri ve iş ortaklarını aktif olarak destekliyor.
 Maria Guerra AWS Professional Services ile bir Büyük Veri Mimarıdır. Maria'nın veri analitiği ve makine mühendisliğinde geçmişi vardır. Müşterilerin bulutta verilerle ilgili iş yüklerini tasarlamasına ve geliştirmesine yardımcı olur.
Maria Guerra AWS Professional Services ile bir Büyük Veri Mimarıdır. Maria'nın veri analitiği ve makine mühendisliğinde geçmişi vardır. Müşterilerin bulutta verilerle ilgili iş yüklerini tasarlamasına ve geliştirmesine yardımcı olur.
 Puşpraj Singh AWS Profesyonel Hizmetlerinde Kıdemli Veri Mimarıdır. Veri ve DevOps mühendisliği konusunda tutkulu. Müşterilerin geniş ölçekte veri odaklı uygulamalar oluşturmasına yardımcı oluyor.
Puşpraj Singh AWS Profesyonel Hizmetlerinde Kıdemli Veri Mimarıdır. Veri ve DevOps mühendisliği konusunda tutkulu. Müşterilerin geniş ölçekte veri odaklı uygulamalar oluşturmasına yardımcı oluyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/build-a-pseudonymization-service-on-aws-to-protect-sensitive-data-part-2/

