İle Amazon EMR'si 6.15, başlattık AWS Göl Oluşumu Apache Hudi, Apache Iceberg ve Delta lake dahil olmak üzere Açık Tablo Formatlarında (OTF'ler) dayalı ayrıntılı erişim kontrolleri (FGAC). Bu, güvenliği ve yönetimi basitleştirmenize olanak tanır. işlemsel veri gölleri Apache Spark işlerinizde tablo, sütun ve satır düzeyindeki izinlerde erişim kontrolleri sağlayarak. Birçok büyük kurumsal şirket, içgörü kazanmak ve karar alma sürecini geliştirmek için işlemsel veri gölünü kullanmayı amaçlıyor. FGAC için Lake Formation ile entegre Amazon EMR'yi kullanarak bir göl evi mimarisi oluşturabilirsiniz. Bu hizmet kombinasyonu, güvenli ve kontrollü erişim sağlarken işlemsel veri gölünüzde veri analizi yapmanıza olanak tanır.
Amazon EMR kayıt sunucusu bileşeni tablo, sütun, satır, hücre ve iç içe öznitelik düzeyinde veri filtreleme işlevini destekler. Desteği, hem okuma (zaman yolculuğu ve artımlı sorgu dahil) hem de yazma işlemleri (INSERT gibi DML ifadelerinde) için Hive, Apache Hudi, Apache Iceberg ve Delta lake formatlarını kapsayacak şekilde genişletir. Ayrıca Amazon EMR, sürüm 6.15 ile küme içi Spark History Server, Yarn Timeline Server ve Yarn Resource Manager kullanıcı arayüzü gibi uygulama web arayüzleri için erişim kontrolü korumasını sunuyor.
Bu yazıda, FGAC'ın nasıl uygulanacağını gösteriyoruz Apaçi Hudi Lake Formation ile entegre Amazon EMR kullanan tablolar.
İşlem verileri gölü kullanım örneği
Amazon EMR müşterileri, bir veri gölünde ACID işlemlerini ve zaman yolculuğu ihtiyaçlarını desteklemek için sıklıkla Açık Tablo Formatlarını kullanır. Veri gölünde zaman yolculuğu, geçmiş versiyonları koruyarak denetim ve uyumluluk, veri kurtarma ve geri alma, tekrarlanabilir analiz ve zamanın farklı noktalarında veri araştırması gibi faydalar sağlar.
Bir diğer popüler işlem veri gölü kullanım örneği, artımlı sorgudur. Artımlı sorgu, son sorgudan bu yana bir veri gölü içindeki yalnızca yeni veya güncellenmiş verilerin işlenmesine ve analiz edilmesine odaklanan bir sorgu stratejisini ifade eder. Artımlı sorguların arkasındaki temel fikir, son sorgudan bu yana yeni veya değiştirilmiş verileri tanımlamak için meta verileri veya değişiklik izleme mekanizmalarını kullanmaktır. Sorgu motoru, bu değişiklikleri tanımlayarak sorguyu yalnızca ilgili verileri işleyecek şekilde optimize edebilir ve işlem süresini ve kaynak gereksinimlerini önemli ölçüde azaltabilir.
Çözüme genel bakış
Bu yazıda, Amazon EMR kullanarak Apache Hudi tablolarında FGAC'nin nasıl uygulanacağını gösteriyoruz. Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2) Göl Formasyonu ile entegre edilmiştir. Apache Hudi, artımlı veri işlemeyi ve veri işlem hatlarının geliştirilmesini büyük ölçüde basitleştiren açık kaynaklı bir işlemsel veri gölü çerçevesidir. Bu yeni FGAC özelliği tüm OTF'leri destekler. Burada Hudi ile göstermenin yanı sıra diğer bloglarla da diğer OTF tablolarını takip edeceğiz. Kullanırız dizüstü bilgisayarlar in Amazon SageMaker Stüdyosu Hudi verilerini bir EMR kümesi aracılığıyla farklı kullanıcı erişim izinleri aracılığıyla okumak ve yazmak. Bu, gerçek dünyadaki veri erişim senaryolarını yansıtır; örneğin, bir mühendislik kullanıcısının bir veri platformunda sorun gidermek için tam veri erişimine ihtiyacı varsa, veri analistlerinin ise bu verilerin yalnızca kişisel olarak tanımlanabilir bilgiler içermeyen bir alt kümesine erişmesi gerekebilir (PII). ). Göl Oluşumu ile bütünleşme Amazon EMR çalışma zamanı rolü ayrıca veri güvenliği duruşunuzu geliştirmenize olanak tanır ve Amazon EMR iş yükleri için veri kontrolü yönetimini basitleştirir. Bu çözüm, bir kuruluştaki farklı kullanıcıların ve rollerin farklı ihtiyaçlarını ve güvenlik gereksinimlerini karşılayarak veri erişimi için güvenli ve kontrollü bir ortam sağlar.
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.
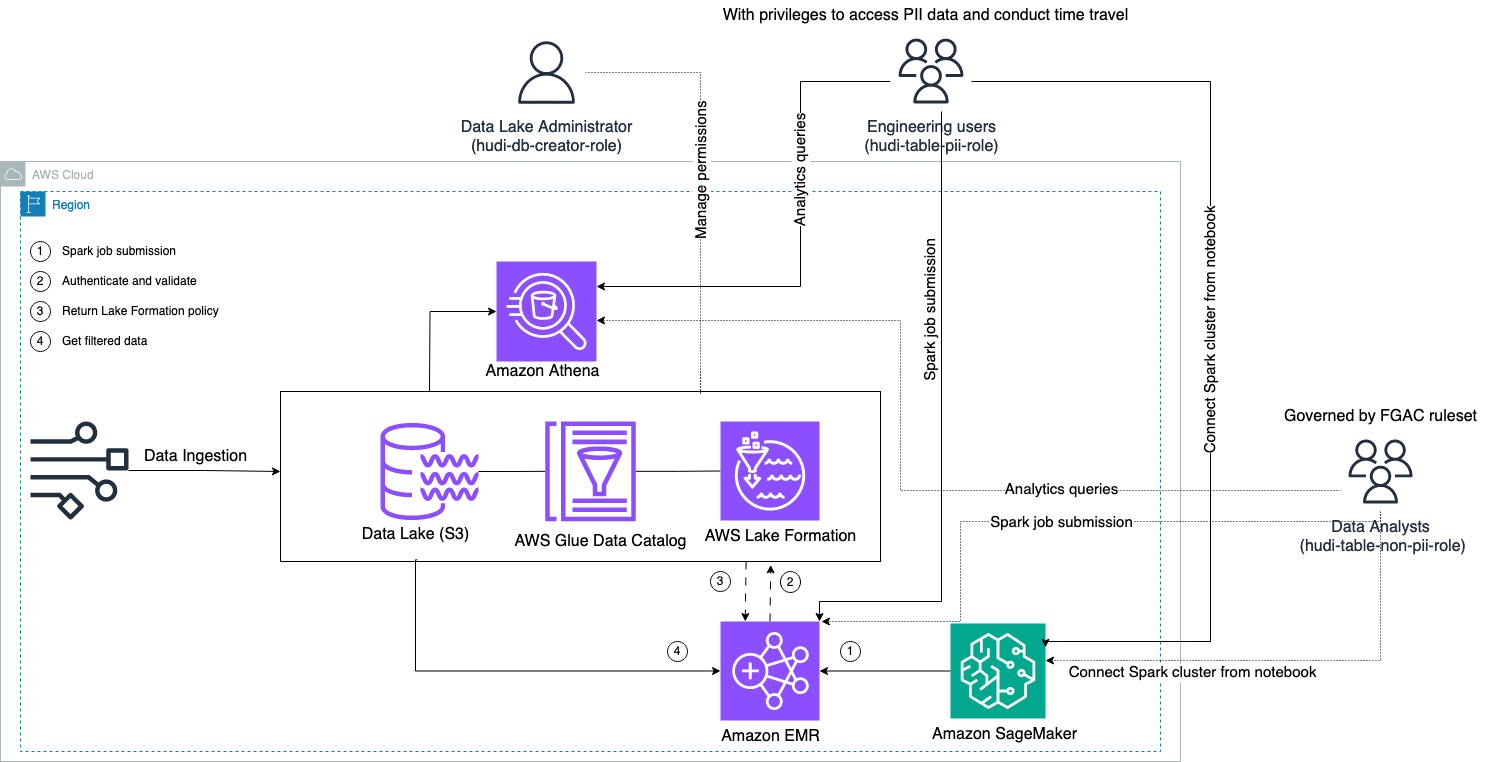
Bir Hudi veri kümesini yeni bir sürüme yükseltmek (güncellemek ve eklemek) için bir veri alma süreci yürütüyoruz. Amazon Basit Depolama Hizmeti (Amazon S3) paketini oluşturun ve tablo şemasını sürdürün veya güncelleyin. AWS Tutkal Veri Kataloğu. Sıfır veri hareketi ile Lake Formation tarafından yönetilen Hudi tablosunu aşağıdaki gibi çeşitli AWS servisleri aracılığıyla sorgulayabiliriz. Amazon Atina, Amazon EMR ve Amazon Adaçayı Yapıcı.
Kullanıcılar herhangi bir EMR kümesi uç noktası (EMR Steps, Livy, EMR Studio ve SageMaker) aracılığıyla bir Spark işi gönderdiğinde Lake Formation onların ayrıcalıklarını doğrular ve EMR kümesine PII verileri gibi hassas verileri filtrelemesi talimatını verir.
Bu çözüm, Hudi verilerine erişim için farklı düzeylerde izinlere sahip üç farklı kullanıcı tipine sahiptir:
- hudi-db-yaratıcı-rolü – Bu, veritabanı nesnelerini oluşturma, değiştirme ve silme gibi DDL işlemlerini yürütme ayrıcalıklarına sahip olan veri gölü yöneticisi tarafından kullanılır. Satır düzeyinde ve sütun düzeyinde veri erişim kontrolü için Lake Formation'da veri filtreleme kuralları tanımlayabilirler. Bu FGAC kuralları, veri gölünün güvenliğinin sağlanmasını ve gerekli veri gizliliği düzenlemelerinin yerine getirilmesini sağlar.
- hudi-tablo-pii-rolü – Bu, mühendislik kullanıcıları tarafından kullanılır. Mühendislik kullanıcıları, hem Yazırken Kopyala (CoW) hem de Okurken Birleştir (MoR) üzerinde zaman yolculuğu ve artımlı sorgular gerçekleştirebilir. Ayrıca herhangi bir zaman damgasına dayalı olarak PII verilerine erişme ayrıcalığına da sahiptirler.
- hudi-tablo-pii-olmayan-rolü – Bu veri analistleri tarafından kullanılır. Veri analistlerinin veri erişim hakları, veri gölü yöneticileri tarafından kontrol edilen FGAC tarafından yetkilendirilen kurallara tabidir. İsimler ve adresler gibi PII verilerini içeren sütunlarda görünürlükleri yoktur. Ayrıca belirli koşulları karşılamayan veri satırlarına da erişemezler. Örneğin kullanıcılar yalnızca kendi ülkelerine ait veri satırlarına erişebilirler.
Önkoşullar
Bu yazıda kullanılan üç not defterini şuradan indirebilirsiniz: GitHub repo.
Çözümü dağıtmadan önce aşağıdakilere sahip olduğunuzdan emin olun:
İzinlerinizi ayarlamak için aşağıdaki adımları tamamlayın:
- Yönetici IAM kullanıcınızla AWS hesabınızda oturum açın.
İçinde olduğunuzdan emin olun.us-east-1Bölge.
- İçinde bir S3 klasörü oluşturun
us-east-1Bölge (örneğin,emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Daha sonra Göl Oluşumunu şu şekilde etkinleştiriyoruz: varsayılan izin modelini değiştirme.
- Lake Formation konsolunda yönetici kullanıcı olarak oturum açın.
- Klinik Veri Kataloğu ayarları altında Yönetim Gezinti bölmesinde.
- Altında Yeni oluşturulan veritabanları ve tablolar için varsayılan izinler, seçimi kaldır Yeni veritabanları için yalnızca IAM erişim kontrolünü kullanın ve Yeni veritabanlarındaki yeni tablolar için yalnızca IAM erişim kontrolünü kullanın.
- Klinik İndirim.

Alternatif olarak, Lake Formation'ı varsayılan seçenekle başlattıysanız oluşturulan kaynaklardaki (veritabanları ve tablolar) IAMAllowedPrincipals'ı iptal etmeniz gerekir.
Son olarak Amazon EMR için bir anahtar çifti oluşturuyoruz.
- Amazon EC2 konsolunda şunu seçin: Anahtar çiftleri Gezinti bölmesinde.
- Klinik Anahtar çifti oluştur.
- İçin Name, bir ad girin (örneğin
emr-fgac-hudi-keypair). - Klinik Anahtar çifti oluştur.
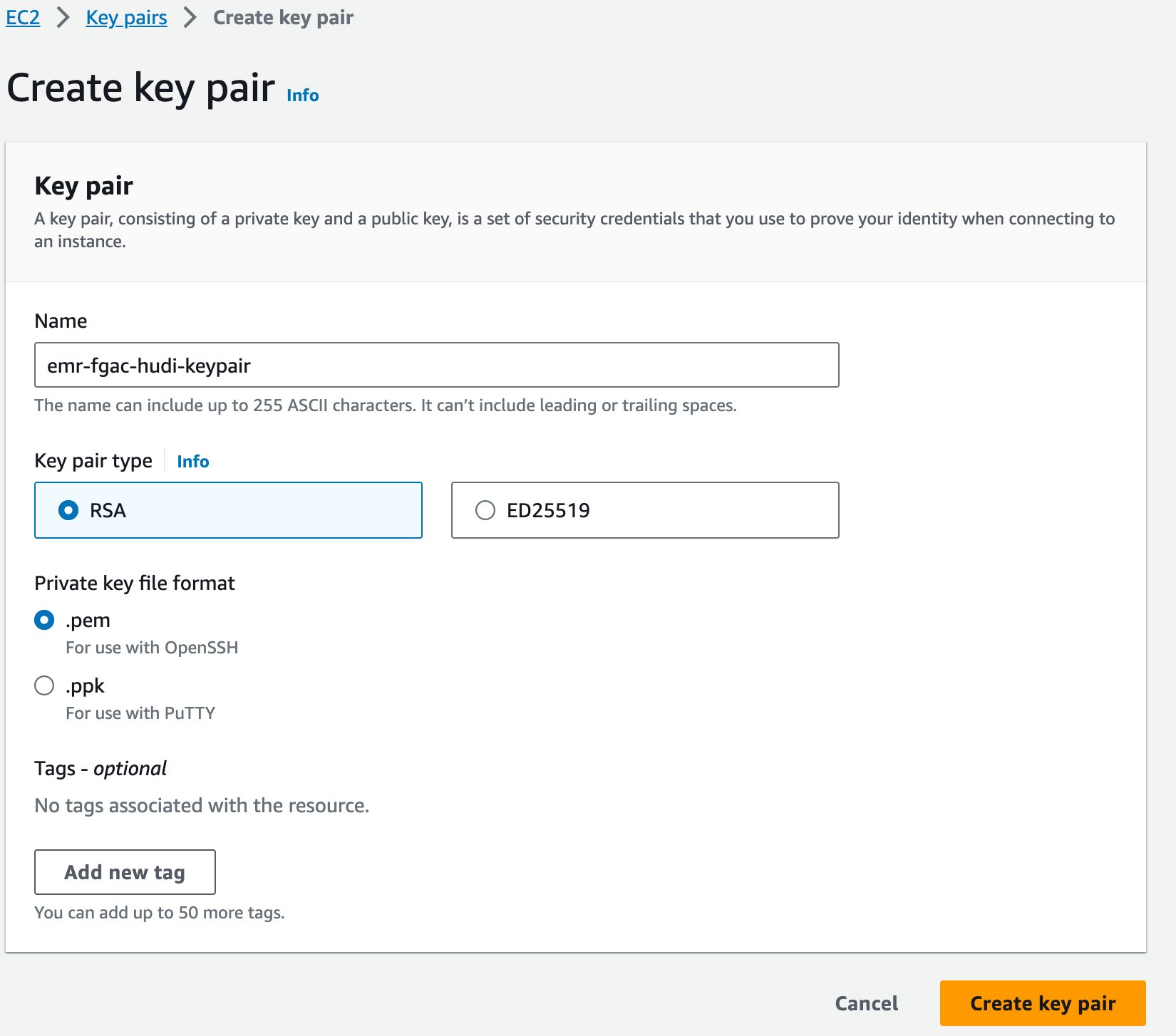
Oluşturulan anahtar çifti (bu yazı için, emr-fgac-hudi-keypair.pem) yerel bilgisayarınıza kaydedecektir.
Ardından, bir AWS Bulut9 etkileşimli geliştirme ortamı (IDE).
- AWS Cloud9 konsolunda seçin <span style="font-size:14px;">ortamları</span> Gezinti bölmesinde.
- Klinik Ortam oluştur.
- İçin Name¸ bir isim girin (örneğin,
emr-fgac-hudi-env). - Diğer ayarları varsayılan olarak bırakın.
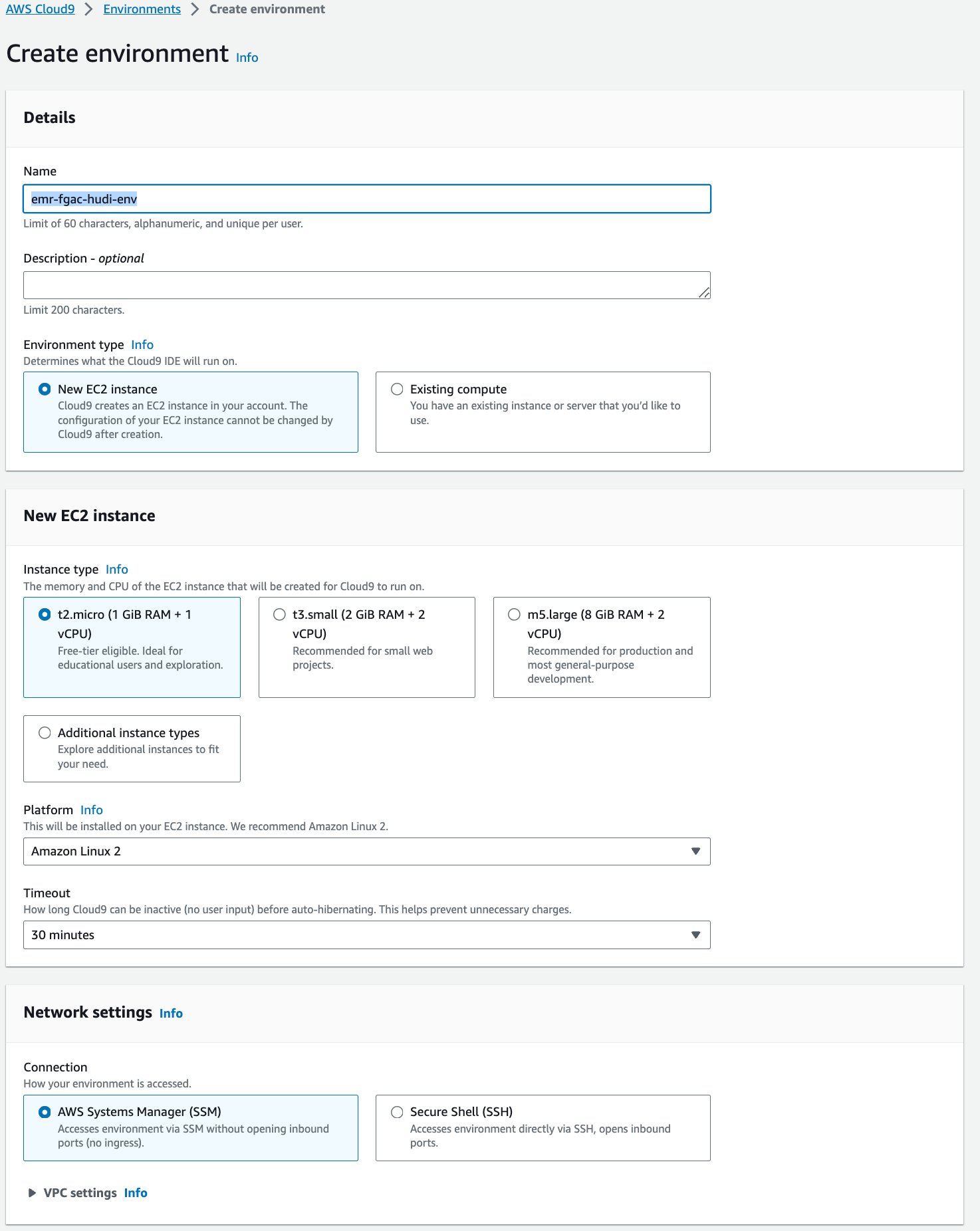
- Klinik oluşturmak.
- IDE hazır olduğunda, Açılış açmak için.
- AWS Cloud9 IDE'de, fileto menü seç Yerel Dosyaları Yükle.

- Anahtar çifti dosyasını yükleyin (
emr-fgac-hudi-keypair.pem). - Artı işaretini seçin ve seçin Yeni Terminal.
- Terminalde aşağıdaki komut satırlarını girin:
Örnek kodun yalnızca gösterim amaçlı bir kavram kanıtı olduğunu unutmayın. Üretim sistemlerinde sertifika vermek için güvenilir bir sertifika yetkilisi (CA) kullanın. Bakınız Aktarım halindeki verilerin Amazon EMR şifrelemesiyle şifrelenmesi için sertifikaların sağlanması Ayrıntılar için.
Çözümü AWS CloudFormation aracılığıyla dağıtın
Biz bir AWS CloudFormation Aşağıdaki hizmetleri ve bileşenleri otomatik olarak ayarlayan şablon:
- Veri gölü için bir S3 paketi. Örnek TPC-DS veri kümesini içerir.
- Güvenlik yapılandırmasına ve genel DNS'nin etkin olduğu bir EMR kümesi.
- Lake Formation ayrıntılı izinlerine sahip EMR çalışma zamanı IAM rolleri:
- -hudi-db-yaratıcı-rolü – Bu rol Apache Hudi veritabanı ve tabloları oluşturmak için kullanılır.
- -hudi-tablo-pii-rolü – Bu rol, PII içeren sütunlar da dahil olmak üzere Hudi tablolarının tüm sütunlarının sorgulanmasına izin verir.
- -hudi-tablo-pii-olmayan-rolü – Bu rol, PII sütunlarını Lake Formation'a göre filtreleyen Hudi tablolarını sorgulama izni sağlar.
- Kullanıcıların karşılık gelen EMR çalışma zamanı rollerini üstlenmelerine olanak tanıyan SageMaker Studio yürütme rolleri.
- VPC, alt ağlar ve güvenlik grupları gibi ağ kaynakları.
Kaynakları dağıtmak için aşağıdaki adımları tamamlayın:
- Klinik Hızlı yığın oluşturma CloudFormation yığınını başlatmak için.
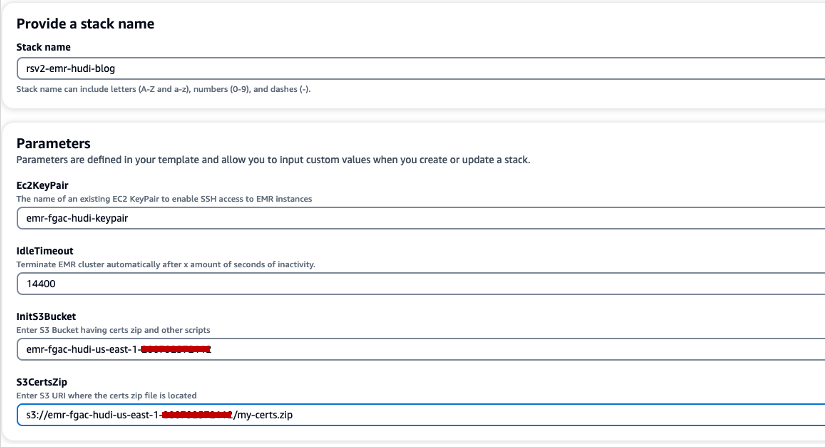
- İçin Yığın adı, bir yığın adı girin (örneğin,
rsv2-emr-hudi-blog). - İçin Ec2KeyPair, anahtar çiftinizin adını girin.
- İçin Boşta Kalma Zaman Aşımı, kullanılmadığında kümeye ödeme yapılmasını önlemek amacıyla EMR kümesi için bir boşta kalma zaman aşımı değeri girin.
- İçin InitS3BucketAmazon EMR şifreleme sertifikası .zip dosyasını kaydetmek için oluşturduğunuz S3 klasör adını girin.
- İçin S3CertsZipAmazon EMR şifreleme sertifikası .zip dosyasının S3 URI'sini girin.
- seç AWS CloudFormation'ın özel adlarla IAM kaynakları oluşturabileceğini kabul ediyorum.
- Klinik Yığın oluştur.
CloudFormation yığın dağıtımı yaklaşık 10 dakika sürer.
Amazon EMR entegrasyonu için Lake Formation'ı kurun
Göl Formasyonunu ayarlamak için aşağıdaki adımları tamamlayın:
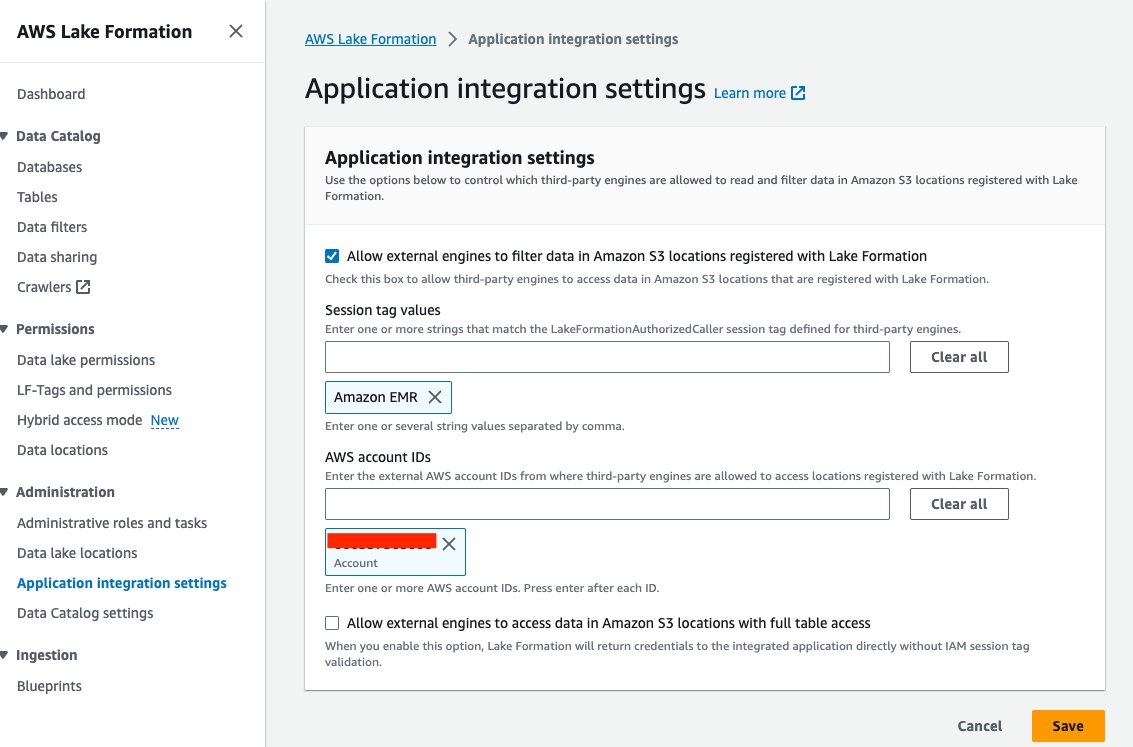
- Göl Oluşumu konsolunda seçin Uygulama entegrasyon ayarları altında Yönetim Gezinti bölmesinde.
- seç Harici motorların Lake Formation'a kayıtlı Amazon S3 konumlarındaki verileri filtrelemesine izin ver.
- Klinik Amazon EMR'si için Oturum etiketi değerleri.
- AWS hesap kimliğinizi girin AWS hesap kimlikleri.
- Klinik İndirim.
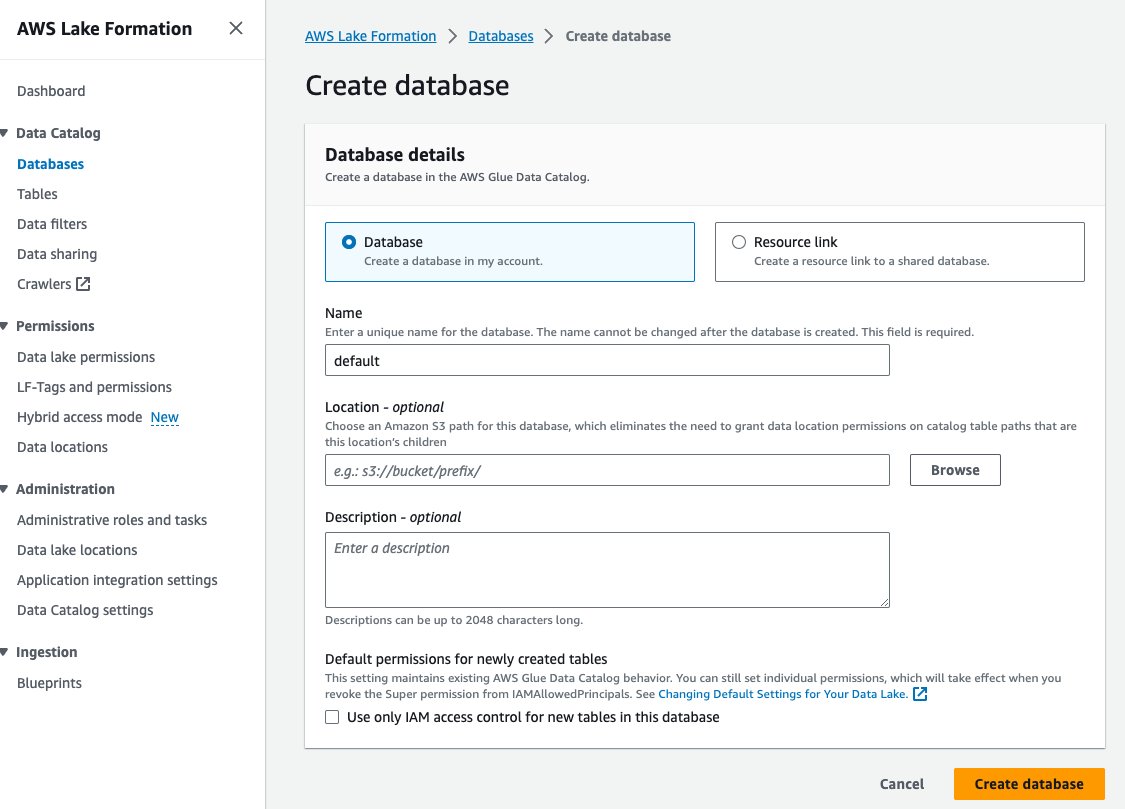
- Klinik veritabanları altında Veri Kataloğu Gezinti bölmesinde.
- Klinik Veritabanı oluştur.
- İçin Name, varsayılanı girin.
- Klinik Veritabanı oluştur.
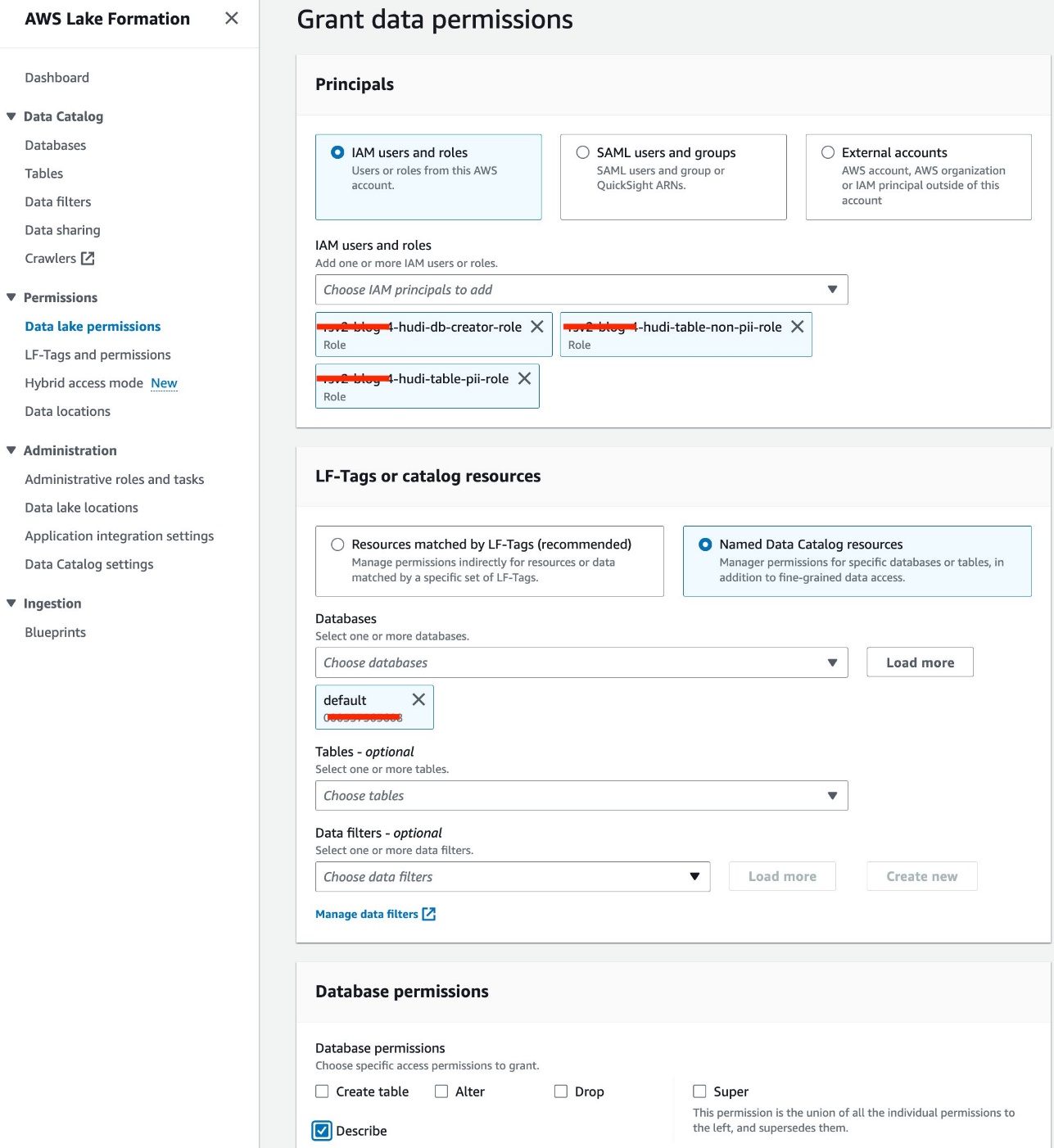
- Klinik Veri gölü izinleri altında İzinler Gezinti bölmesinde.
- Klinik Hibe.
- seç IAM kullanıcıları ve rolleri.
- IAM rollerinizi seçin.
- İçin veritabanları, varsayılanı seçin.
- İçin Veritabanı izinleriseçin Tanımlamak.
- Klinik Hibe.
Hudi JAR dosyasını Amazon EMR HDFS'ye kopyalayın
için Hudi'yi Jupyter not defterleriyle kullanınHudi'yi kullanacak bir Spark oturumu yapılandırabilmeniz için, Amazon EMR yerel dizininden HDFS depolama alanına bir Hudi JAR dosyasının kopyalanmasını içeren EMR kümesi için aşağıdaki adımları tamamlamanız gerekir:
- Gelen SSH trafiğini yetkilendirin (bağlantı noktası 22).
- Değerini kopyalayın Birincil düğüm genel DNS'si (örneğin, EMR kümesinden ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) Özet Bölüm.
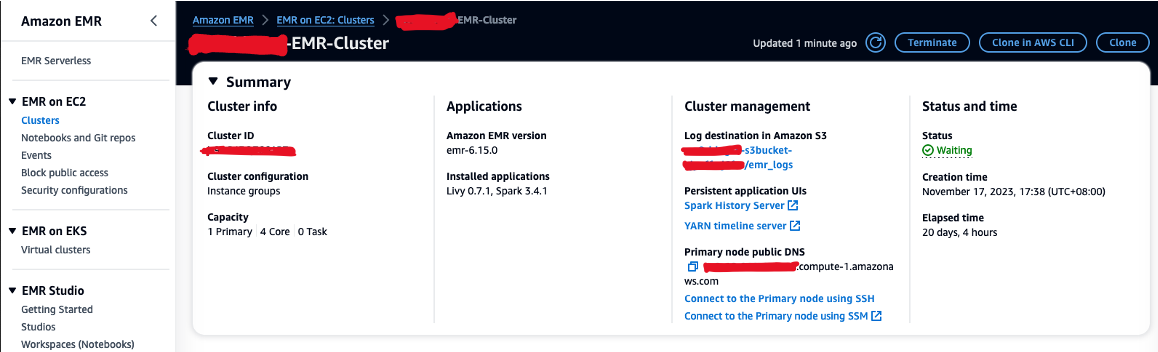
- EC9 anahtar çiftini oluşturmak için kullandığınız önceki AWS Cloud2 terminaline geri dönün.
- EMR birincil düğümünde SSH'ye aşağıdaki komutu çalıştırın. Yer tutucuyu EMR DNS ana bilgisayar adınızla değiştirin:
- Hudi JAR dosyasını HDFS'ye kopyalamak için aşağıdaki komutu çalıştırın:
Lake Formation'da Hudi veritabanını ve tablolarını oluşturun
Artık EMR çalışma zamanı rolü tarafından etkinleştirilen FGAC ile Hudi veritabanını ve tablolarını oluşturmaya hazırız. EMR çalışma zamanı rolü bir EMR kümesine bir iş veya sorgu gönderdiğinizde belirtebileceğiniz bir IAM rolüdür.
Veritabanı oluşturucusuna izin ver
Öncelikle Lake Formation veritabanı oluşturucusuna şunu yapma iznini verelim:<STACK-NAME>-hudi-db-creator-role:
- AWS hesabınızda yönetici olarak oturum açın.
- Göl Oluşumu konsolunda seçin İdari roller ve görevler altında Yönetim Gezinti bölmesinde.
- AWS oturum açma kullanıcınızın veri gölü yöneticisi olarak eklendiğini doğrulayın.
- içinde Veritabanı yaratıcısı bölümü, seçim Hibe.
- İçin IAM kullanıcıları ve rolleri, seçmek
<STACK-NAME>-hudi-db-creator-role. - İçin Katalog izinleriseçin Veritabanı oluştur.
- Klinik Hibe.
Veri gölü konumunu kaydetme
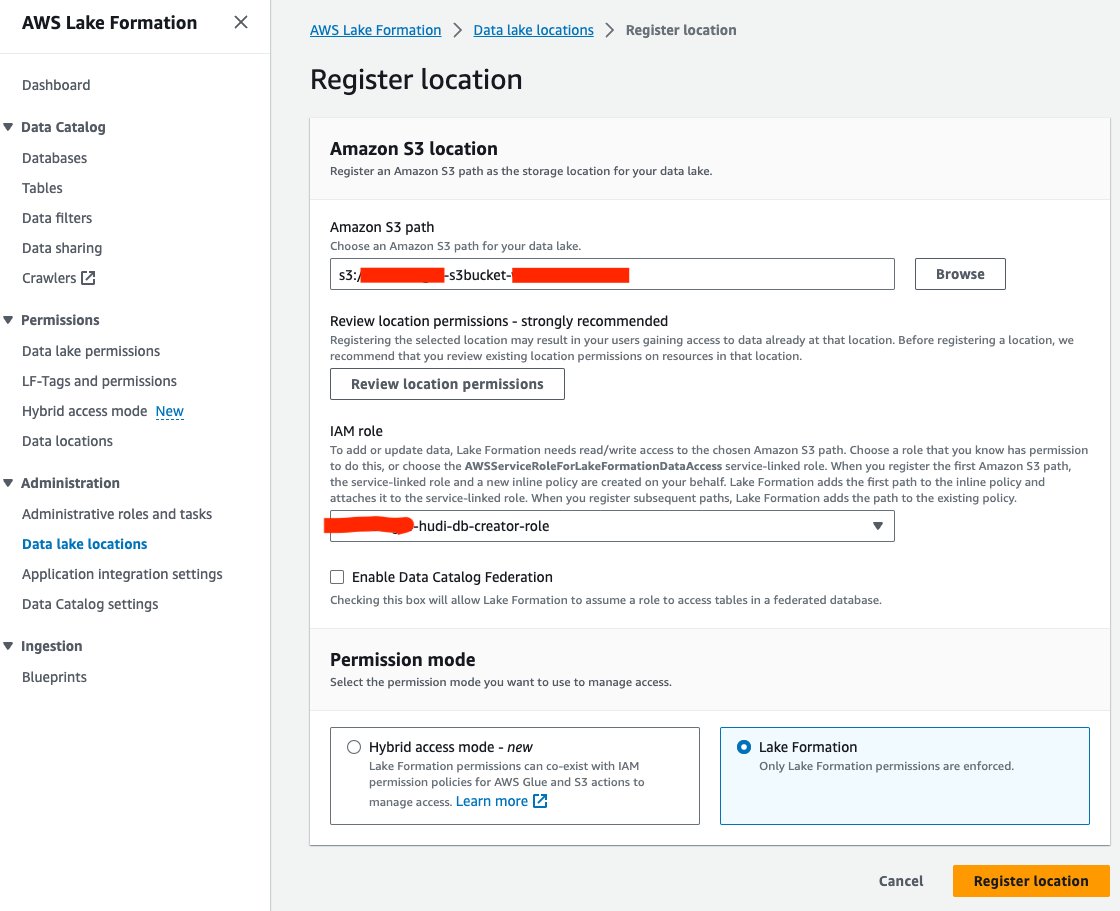
Ardından S3 veri gölü konumunu Lake Formation'a kaydedelim:
- Göl Oluşumu konsolunda seçin Veri gölü konumları altında Yönetim Gezinti bölmesinde.
- Klinik Konumu kaydet.
- İçin Amazon S3 yolu, Seçmek Araştır ve data lake S3 paketini seçin. (
<STACK_NAME>s3bucket-XXXXXXX) CloudFormation yığınından oluşturuldu. - İçin IAM rolü, seçmek
<STACK-NAME>-hudi-db-creator-role. - İçin izin moduseçin Göl Oluşumu.
- Klinik Konumu kaydet.
Veri konumu izni ver
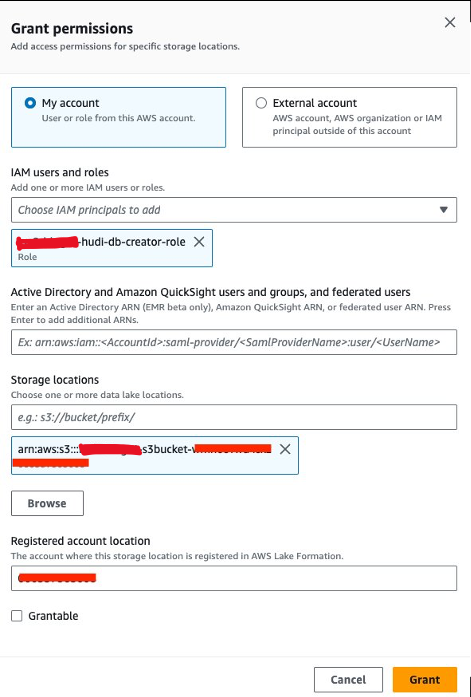
Daha sonra, hibe etmemiz gerekiyor<STACK-NAME>-hudi-db-creator-roleveri konumu izni:
- Göl Oluşumu konsolunda seçin Veri konumları altında İzinler Gezinti bölmesinde.
- Klinik Hibe.
- İçin IAM kullanıcıları ve rolleri, seçmek
<STACK-NAME>-hudi-db-creator-role. - İçin Depolama yerleri, S3 paketini girin (
<STACK_NAME>-s3bucket-XXXXXXX). - Klinik Hibe.
EMR kümesine bağlanın
Şimdi, veritabanı oluşturucu EMR çalışma zamanı rolüyle EMR kümesine bağlanmak için SageMaker Studio'da bir Jupyter not defteri kullanalım:
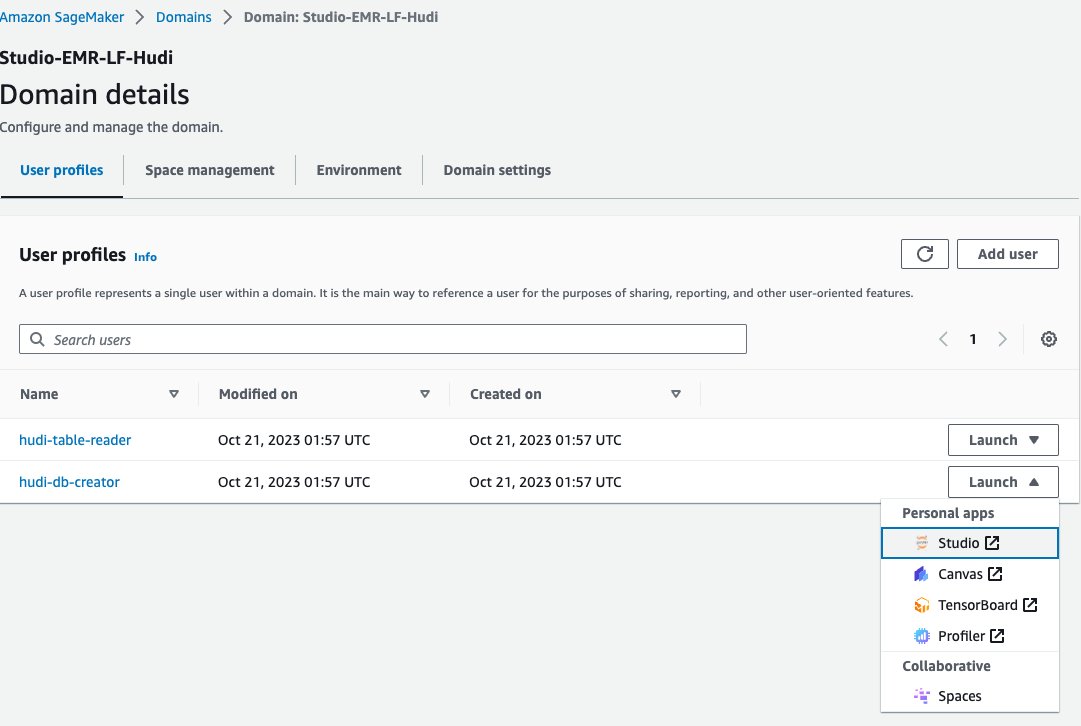
- SageMaker konsolunda, Alanlar Gezinti bölmesinde.
- etki alanını seçin
<STACK-NAME>-Studio-EMR-LF-Hudi. - Üzerinde Başlatmak kullanıcı profilinin yanındaki menü
<STACK-NAME>-hudi-db-creator, seçmek Stüdyo.
- Not defterini indirin rsv2-hudi-db-yaratıcı-dizüstü bilgisayar.
- Yükleme simgesini seçin.
- İndirilen Jupyter not defterini seçin ve Açılış.
- Yüklenen not defterini açın.
- İçin Resim, seçmek Kıvılcım Büyüsü.
- İçin çekirdek, seçmek PyKıvılcım.
- Diğer yapılandırmaları varsayılan olarak bırakın ve seç.

- Klinik Küme EMR kümesine bağlanmak için.

- EC2 kümesindeki EMR'yi seçin (
<STACK-NAME>-EMR-Cluster) CloudFormation yığınıyla oluşturuldu. - Klinik Sosyal medya.
- İçin EMR yürütme rolü, seçmek
<STACK-NAME>-hudi-db-creator-role. - Klinik Sosyal medya.
Veritabanı ve tablolar oluşturun
Artık Hudi veritabanını ve tablolarını oluşturmak için not defterindeki adımları takip edebilirsiniz. Başlıca adımlar aşağıdaki gibidir:
- Dizüstü bilgisayarı başlattığınızda yapılandırın
“spark.sql.catalog.spark_catalog.lf.managed":"true"Spark_catalog'un Lake Formation tarafından korunduğunu Spark'a bildirmek için. - Aşağıdaki Spark SQL'i kullanarak Hudi tabloları oluşturun.
- Kaynak tablodaki verileri Hudi tablolarına ekleyin.
- Hudi tablolarına tekrar veri ekleyin.
FGAC ile Göl Oluşumu aracılığıyla Hudi tablolarını sorgulama
Hudi veritabanını ve tablolarını oluşturduktan sonra Lake Formation ile ayrıntılı erişim kontrolünü kullanarak tabloları sorgulamaya hazırsınız. İki tür Hudi tablosu oluşturduk: Yazıldığında Kopyala (COW) ve Okuduğunda Birleştir (MOR). COW tablosu, verileri sütunlu bir biçimde (Parke) saklar ve her güncelleme, yazma sırasında dosyaların yeni bir sürümünü oluşturur. Bu, her güncellemede Hudi'nin tüm dosyayı yeniden yazdığı anlamına gelir; bu da daha fazla kaynak tüketebilir ancak daha hızlı okuma performansı sağlar. Öte yandan MOR, COW'un özellikle yazma veya değişiklik ağırlıklı iş yükleri için ideal olmayabileceği durumlar için tanıtıldı. Bir MOR tablosunda, her güncelleme olduğunda Hudi yalnızca değiştirilen kaydın satırını yazar, bu da maliyeti azaltır ve düşük gecikmeli yazmalara olanak tanır. Ancak okuma performansı COW tablolarına göre daha yavaş olabilir.
Tablo erişim izni ver
IAM rolünü kullanıyoruz<STACK-NAME>-hudi-table-pii-roleHudi COW ve MOR içeren PII sütunlarını sorgulamak için. Tabloya ilk olarak Lake Formation üzerinden erişim izni veriyoruz:
- Göl Oluşumu konsolunda seçin Veri gölü izinleri altında İzinler Gezinti bölmesinde.
- Klinik Hibe.
- Klinik
<STACK-NAME>-hudi-table-pii-roleiçin IAM kullanıcıları ve rolleri. - Seçin
rsv2_blog_hudi_db_1için veritabanı veritabanları. - İçin tablolarJupyter not defterinde oluşturduğunuz dört Hudi tablosunu seçin.
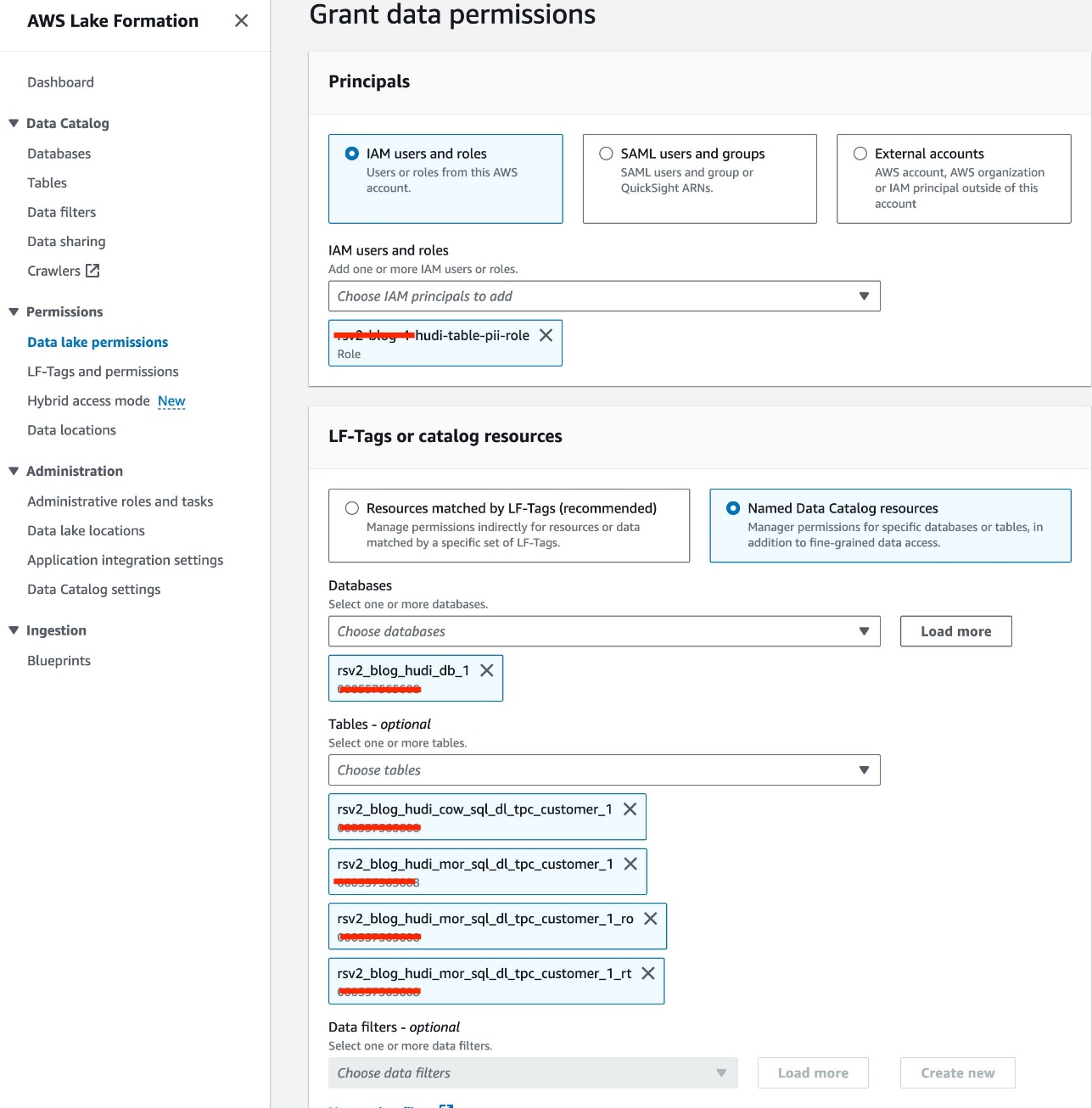
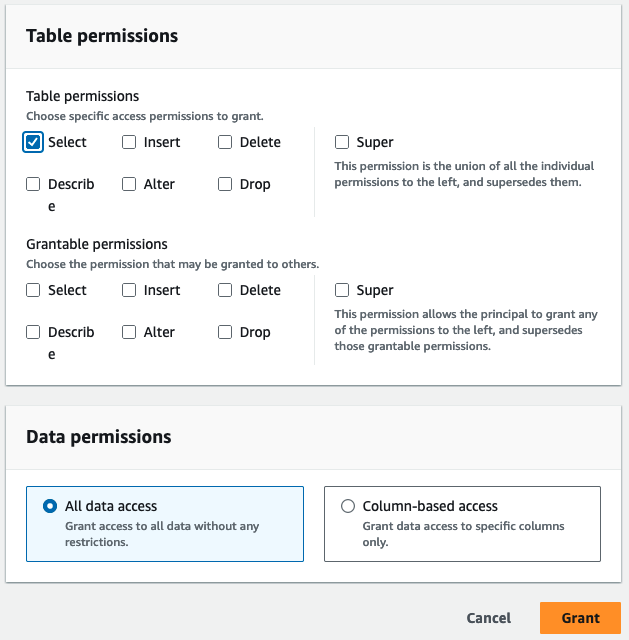
- İçin Tablo izinleriseçin seç.
- Klinik Hibe.
Kimlik bilgisi sütunlarını sorgula
Artık Hudi tablolarını sorgulamak için not defterini çalıştırmaya hazırsınız. Not defterini SageMaker Studio'da çalıştırmak için önceki bölüme benzer adımları izleyelim:
- SageMaker konsolunda, şuraya gidin:
<STACK-NAME>-Studio-EMR-LF-Hudietki. - Üzerinde Başlatmak yanındaki menü
<STACK-NAME>-hudi-table-readerkullanıcı profili, seçin Stüdyo. - İndirilen not defterini yükleyin rsv2-hudi-tablo-pii-okuyucu-not defteri.
- Yüklenen not defterini açın.
- Dizüstü bilgisayar kurulum adımlarını tekrarlayın ve aynı EMR kümesine bağlanın ancak rolü kullanın
<STACK-NAME>-hudi-table-pii-role.
Mevcut aşamada, FGAC özellikli EMR kümesinin, artımlı sorgular ve zaman yolculuğu gerçekleştirmek için Hudi'nin taahhüt süresi sütununu sorgulaması gerekiyor. Spark'ın "timestamp as of" sözdizimini desteklemez ve Spark.read(). FGAC'ın etkin olduğu gelecekteki Amazon EMR sürümlerine her iki eylem için de destek eklemek için aktif olarak çalışıyoruz.
Artık not defterindeki adımları takip edebilirsiniz. Aşağıda öne çıkan bazı adımlar verilmiştir:
- Anlık görüntü sorgusu çalıştırın.
- Artımlı bir sorgu çalıştırın.
- Bir zaman yolculuğu sorgusu çalıştırın.
- MOR okuma için optimize edilmiş ve gerçek zamanlı tablo sorgularını çalıştırın.
Hudi tablolarını sütun düzeyinde ve satır düzeyinde veri filtreleriyle sorgulama
IAM rolünü kullanıyoruz<STACK-NAME>-hudi-table-non-pii-roleHudi tablolarını sorgulamak için. Bu rolün PII içeren herhangi bir sütunu sorgulamasına izin verilmez. Ayrıntılı erişim kontrolünü uygulamak için Göl Oluşumu sütun düzeyinde ve satır düzeyinde veri filtrelerini kullanıyoruz:
- Göl Oluşumu konsolunda seçin Veri filtreleri altında Veri Kataloğu Gezinti bölmesinde.
- Klinik Yeni filtre oluştur.
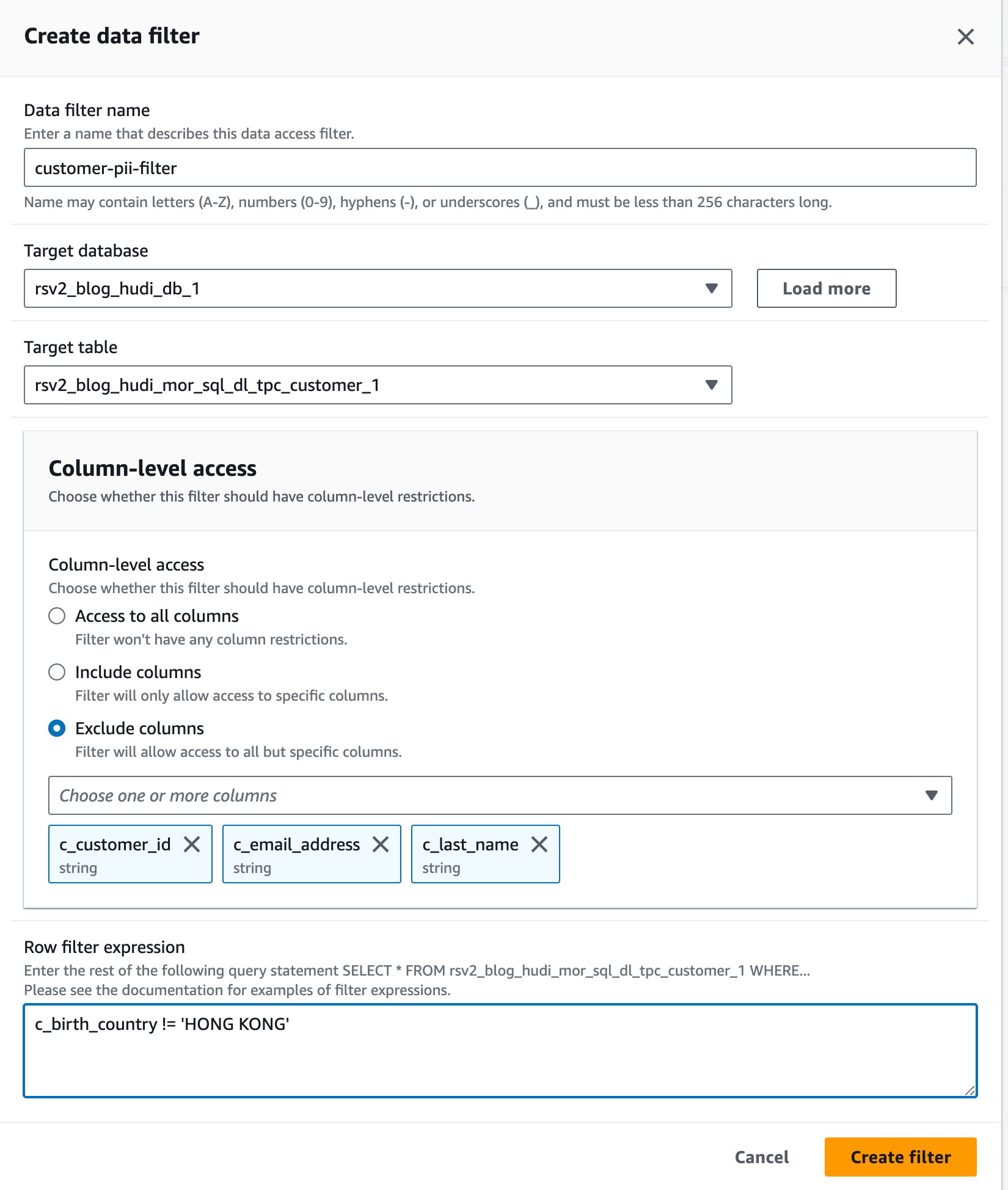
- İçin Veri filtresi adı, girmek
customer-pii-filter. - Klinik
rsv2_blog_hudi_db_1için Hedef veritabanı. - Klinik
rsv2_blog_hudi_mor_sql_dl_customer_1için Hedef tablo. - seç Sütunları hariç tut ve seçiniz
c_customer_id,c_email_address, vec_last_namesütunlar. - Keşfet
c_birth_country != 'HONG KONG'için Satır filtresi ifadesi. - Klinik Filtre oluştur.
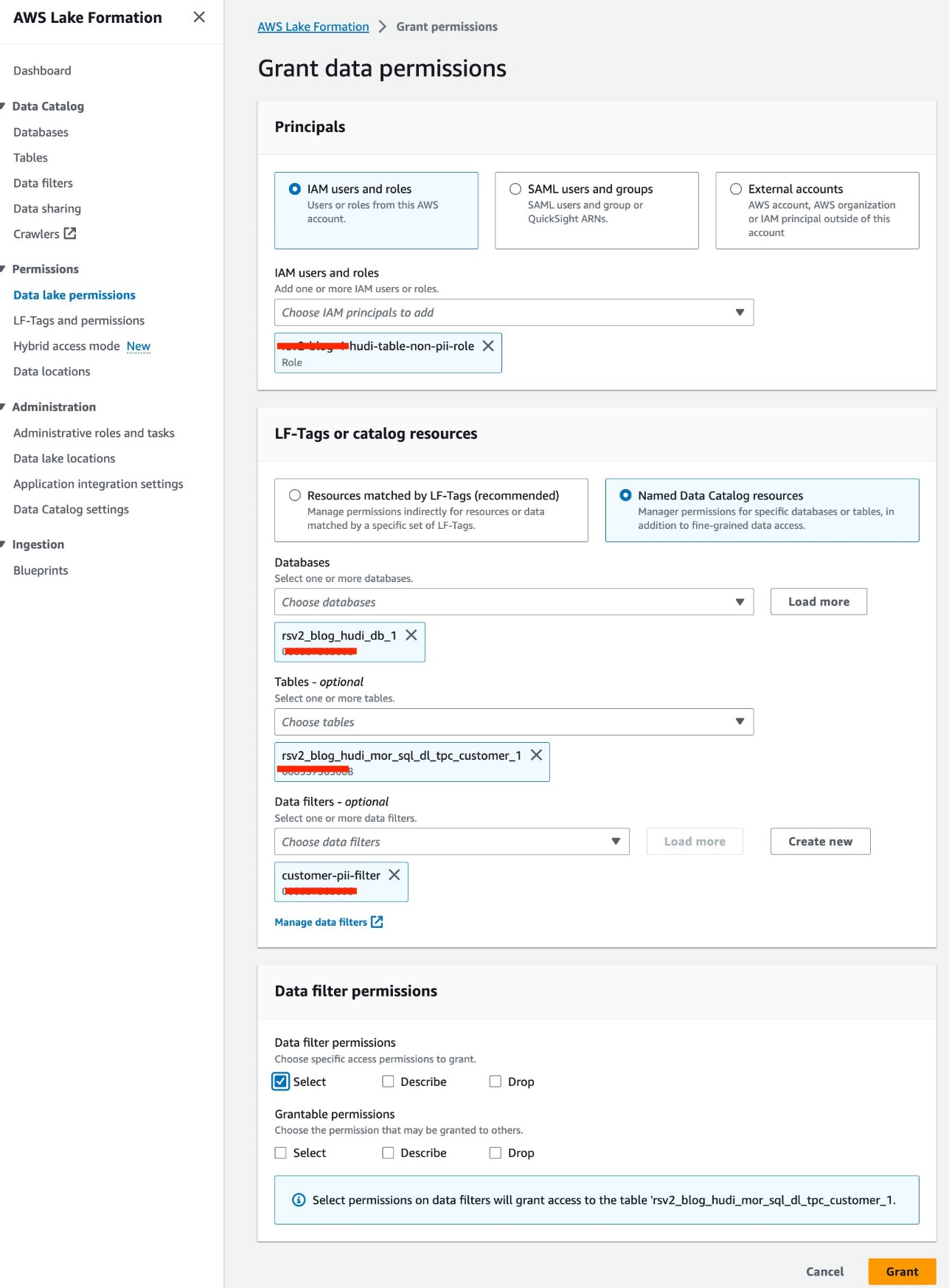
- Klinik Veri gölü izinleri altında İzinler Gezinti bölmesinde.
- Klinik Hibe.
- Klinik
<STACK-NAME>-hudi-table-non-pii-roleiçin IAM kullanıcıları ve rolleri. - Klinik
rsv2_blog_hudi_db_1için veritabanları. - Klinik
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1için tablolar. - Klinik
customer-pii-filteriçin Veri filtreleri. - İçin Veri filtresi izinleriseçin seç.
- Klinik Hibe.
Notebook'u SageMaker Studio'da çalıştırmak için benzer adımları takip edelim:
- SageMaker konsolunda etki alanına gidin
Studio-EMR-LF-Hudi. - Üzerinde Başlatmak için menü
hudi-table-readerkullanıcı profili, seçin Stüdyo. - İndirilen not defterini yükleyin rsv2-hudi-tablo-pii-olmayan-okuyucu-not defteri Ve seç Açılış.
- Dizüstü bilgisayar kurulum adımlarını tekrarlayın ve aynı EMR kümesine bağlanın ancak rolü seçin
<STACK-NAME>-hudi-table-non-pii-role.
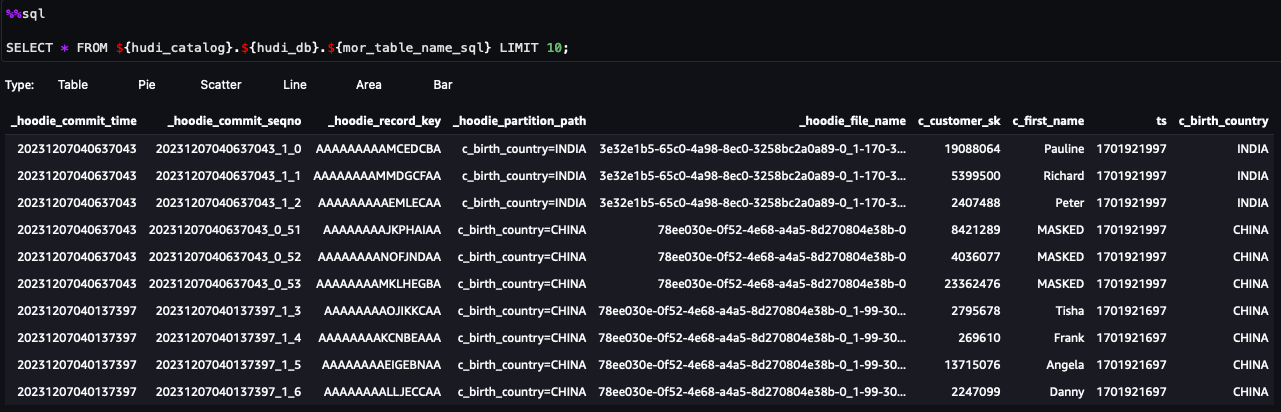
Artık not defterindeki adımları takip edebilirsiniz. Sorgu sonuçlarından Göl Oluşumu veri filtresi aracılığıyla FGAC'ın uygulandığını görebilirsiniz. Rol, PII sütunlarını göremiyorc_customer_id,c_last_name, vec_email_address. Ayrıca, gelen satırlarHONG KONGfiltrelendi.
Temizlemek
Çözümle ilgili denemelerinizi tamamladıktan sonra beklenmedik maliyetlerden kaçınmak için aşağıdaki adımları uygulayarak kaynakları temizlemenizi öneririz:
- SageMaker Studio uygulamalarını kapatın Kullanıcı profilleri için.
EMR kümesi, boşta kalma zaman aşımı değerinden sonra otomatik olarak silinecektir.
- silmek Amazon Elastik Dosya Sistemi (Amazon EFS) birimi etki alanı için oluşturuldu.
- S3 kovalarını boşaltın CloudFormation yığını tarafından oluşturuldu.
- AWS CloudFormation konsolunda yığını silin.
Sonuç
Bu yazıda, Amazon EMR'de ayrıntılı erişim kontrolünü zorunlu kılan bu yeni özelliği göstermek için OTF tablolarından biri olan Apachi Hudi'yi kullandık. OTF tabloları için Lake Formation'da ayrıntılı izinler tanımlayabilir ve bunları EMR kümelerindeki Spark SQL sorguları aracılığıyla uygulayabilirsiniz. Anlık görüntü sorgularını çalıştırma, artımlı sorgular, zaman yolculuğu ve DML sorgusu gibi işlemsel veri gölü özelliklerini de kullanabilirsiniz. Bu yeni özelliğin tüm OTF tablolarını kapsadığını lütfen unutmayın.
Bu özellik, Amazon EMR 6.15 sürümünden itibaren kullanıma sunuldu bölgeler Amazon EMR'nin mevcut olduğu yerler. Amazon EMR'nin Lake Formation ile entegrasyonu sayesinde büyük verileri güvenle yönetip işleyebilir, içgörülerin kilidini açabilir ve veri güvenliğini ve yönetişimini korurken bilinçli karar almayı kolaylaştırabilirsiniz.
Daha fazla bilgi edinmek için bkz. Amazon EMR ile Göl Oluşumunu Etkinleştirin ve veri yolculuğunuz boyunca size yardımcı olabilecek AWS Çözüm Mimarlarınızla iletişime geçmekten çekinmeyin.
Yazar Hakkında
 Raymond Lai büyük kurumsal müşterilerin ihtiyaçlarını karşılama konusunda uzmanlaşmış bir Kıdemli Çözüm Mimarıdır. Uzmanlığı, karmaşık kurumsal sistemleri ve veritabanlarını AWS'ye geçirme, kurumsal veri ambarı ve veri gölü platformları oluşturma konusunda müşterilere yardımcı olmakta yatmaktadır. Raymond, AI/ML kullanım senaryolarına yönelik çözümleri belirleme ve tasarlama konusunda uzmandır ve özellikle AWS Sunucusuz çözümlere ve Olay Odaklı Mimari tasarımına odaklanmaktadır.
Raymond Lai büyük kurumsal müşterilerin ihtiyaçlarını karşılama konusunda uzmanlaşmış bir Kıdemli Çözüm Mimarıdır. Uzmanlığı, karmaşık kurumsal sistemleri ve veritabanlarını AWS'ye geçirme, kurumsal veri ambarı ve veri gölü platformları oluşturma konusunda müşterilere yardımcı olmakta yatmaktadır. Raymond, AI/ML kullanım senaryolarına yönelik çözümleri belirleme ve tasarlama konusunda uzmandır ve özellikle AWS Sunucusuz çözümlere ve Olay Odaklı Mimari tasarımına odaklanmaktadır.
 Bin Wang, PhD, AWS'de Kıdemli Analitik Uzman Çözüm Mimarıdır ve özellikle reklamcılığa odaklanarak makine öğrenimi sektöründe 12 yıldan fazla deneyime sahiptir. Doğal dil işleme (NLP), öneri sistemleri, çeşitli makine öğrenimi algoritmaları ve makine öğrenimi operasyonları konularında uzmanlığa sahiptir. Gerçek dünyadaki sorunları çözmek için ML/DL ve büyük veri tekniklerini uygulama konusunda derin bir tutkuya sahiptir.
Bin Wang, PhD, AWS'de Kıdemli Analitik Uzman Çözüm Mimarıdır ve özellikle reklamcılığa odaklanarak makine öğrenimi sektöründe 12 yıldan fazla deneyime sahiptir. Doğal dil işleme (NLP), öneri sistemleri, çeşitli makine öğrenimi algoritmaları ve makine öğrenimi operasyonları konularında uzmanlığa sahiptir. Gerçek dünyadaki sorunları çözmek için ML/DL ve büyük veri tekniklerini uygulama konusunda derin bir tutkuya sahiptir.
 Aditya Şah AWS'de Yazılım Geliştirme Mühendisidir. Veritabanları ve Veri ambarı motorları ile ilgilenmektedir ve Apache Hive ve Apache Spark gibi motorlar için performans optimizasyonları, güvenlik uyumluluğu ve ACID uyumluluğu üzerinde çalışmıştır.
Aditya Şah AWS'de Yazılım Geliştirme Mühendisidir. Veritabanları ve Veri ambarı motorları ile ilgilenmektedir ve Apache Hive ve Apache Spark gibi motorlar için performans optimizasyonları, güvenlik uyumluluğu ve ACID uyumluluğu üzerinde çalışmıştır.
 Melodi Yang AWS'de Amazon EMR için Kıdemli Büyük Veri Çözüm Mimarıdır. Veri dönüşümünde başarılarına yardımcı olmak için en iyi uygulama rehberliği ve teknik tavsiye sağlamak üzere AWS müşterileriyle birlikte çalışan deneyimli bir analitik lideridir. İlgi alanları açık kaynaklı çerçeveler ve otomasyon, veri mühendisliği ve DataOps'tur.
Melodi Yang AWS'de Amazon EMR için Kıdemli Büyük Veri Çözüm Mimarıdır. Veri dönüşümünde başarılarına yardımcı olmak için en iyi uygulama rehberliği ve teknik tavsiye sağlamak üzere AWS müşterileriyle birlikte çalışan deneyimli bir analitik lideridir. İlgi alanları açık kaynaklı çerçeveler ve otomasyon, veri mühendisliği ve DataOps'tur.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/

