Müşteriler, geleneksel analitik görevlerini yerine getirmek için veri ambarı çözümleri kullanıyor. Son zamanlarda veri gölleri, ölçeklenebilirlik, hataya dayanıklılık ve yapılandırılmış, yarı yapılandırılmış ve yapılandırılmamış veri kümeleri için destek gibi avantajlarla birlikte geldiklerinden, analitik çözümlerin temeli olmak için büyük ilgi topladı.
Veri gölleri varsayılan olarak işlemsel değildir; ancak, veri göllerini ACID özellikleriyle zenginleştiren ve işlemsel ve işlemsel olmayan depolama mekanizmaları arasında her iki dünyanın da en iyisini sunan çok sayıda açık kaynaklı çerçeve vardır.
Veri temizleme ve referans verilerle birleştirme gibi işlemleri içeren geleneksel toplu alım ve işlem ardışık düzenlerinin oluşturulması basittir ve sürdürülmesi uygun maliyetlidir. Ancak, Nesnelerin İnterneti (IoT) ve tıklama akışları gibi veri kümelerini neredeyse gerçek zamanlı teslimat SLA'ları ile hızlı bir oranda almanın zorluğu vardır. Ayrıca, kaynak sistemden hedefe değişiklik verisi yakalama (CDC) ile artımlı güncellemeler uygulamak isteyeceksiniz. Zamanında veriye dayalı kararlar almak için, kaçırılan kayıtları ve karşı basıncı hesaba katmanız ve özellikle referans verileri de hızla değişiyorsa, olay sıralamasını ve bütünlüğünü korumanız gerekir.
Bu yazıda, bu zorlukları ele almayı amaçlıyoruz. Akış verilerini kullanarak gerçek zamanlı olarak değişen bir referans tablosuna birleştirmek için adım adım bir kılavuz sunuyoruz. AWS Tutkal, Amazon DinamoDB, ve AWS Veritabanı Geçiş Hizmeti (AWS DMS'si). Ayrıca, kullanarak bir işlemsel veri gölüne akış verilerinin nasıl alınacağını da gösteriyoruz. Apaçi Hudi ACID işlemleriyle artımlı güncellemeler elde etmek için.
Çözüme genel bakış
Örnek kullanım durumumuz için, akış verileri geliyor Amazon Kinesis Veri Akışlarıve referans verileri MySQL'de yönetilir. Referans verileri, AWS DMS aracılığıyla MySQL'den DynamoDB'ye sürekli olarak çoğaltılır. Buradaki gereklilik, gerçek zamanlı akış verilerini, referans verilerle neredeyse gerçek zamanlı olarak birleştirerek zenginleştirmek ve aşağıdaki gibi bir sorgu motorundan sorgulanabilir hale getirmektir. Amazon Atina tutarlılığı korurken. Bu kullanım durumunda, gereksinim değiştiğinde MySQL'deki referans verileri güncellenebilir ve ardından sorguların, referans verilerdeki güncellemeleri yansıtarak sonuçları döndürmesi gerekir.
Bu çözüm, referans veri setinin boyutu küçük olduğunda değişen referans veri setleriyle akışlara katılmak isteyen kullanıcıların sorununa yöneliktir. Referans verileri DynamoDB tablolarında tutulur ve akış işi, yüksek verimli bir akışı küçük bir referans veri kümesiyle birleştirerek her bir mikro parti için tüm tabloyu belleğe yükler.
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.

Önkoşullar
Bu izlenecek yol için aşağıdaki ön koşullara sahip olmalısınız:
IAM rolleri ve S3 grubu oluşturma
Bu bölümde, bir Amazon Basit Depolama Hizmeti (Amazon S3) kovası ve iki AWS Kimlik ve Erişim Yönetimi (IAM) rolleri: biri AWS Glue işi için, diğeri ise AWS DMS içindir. Bunu kullanarak yapıyoruz AWS CloudFormation şablon. Aşağıdaki adımları tamamlayın:
- AWS CloudFormation konsolunda oturum açın.
- Klinik Yığını Başlat::

- Klinik Sonraki.
- İçin Yığın adı, yığınız için bir ad girin.
- İçin DinamoDBTabloAdı, girmek
tgt_country_lookup_table. Bu, yeni DynamoDB tablonuzun adıdır. - İçin S3BucketNamePrefix, yeni S3 klasörünüzün ön ekini girin.
- seç AWS CloudFormation'ın özel adlarla IAM kaynakları oluşturabileceğini kabul ediyorum.
- Klinik Yığın oluştur.
Yığın oluşturma yaklaşık 1 dakika sürebilir.
Kinesis veri akışı oluşturun
Bu bölümde, bir Kinesis veri akışı oluşturacaksınız:
- Kinesis konsolunda, Veri akışları Gezinti bölmesinde.
- Klinik Veri akışı oluşturun.
- İçin Veri akışı adı, akış adınızı girin.
- Kalan ayarları varsayılan olarak bırakın ve Veri akışı oluşturun.
İsteğe bağlı modda bir Kinesis veri akışı oluşturulur.
Bir Aurora MySQL kümesi oluşturun ve yapılandırın
Bu bölümde, kaynak veritabanı olarak bir Aurora MySQL kümesi oluşturacak ve yapılandıracaksınız. Birinci, CDC'yi etkinleştirmek için kaynak Aurora MySQL veritabanı kümenizi yapılandırın AWS DMS aracılığıyla DynamoDB'ye.
Bir parametre grubu oluşturun
Yeni bir parametre grubu oluşturmak için aşağıdaki adımları tamamlayın:
- Amazon RDS konsolunda, Parametre grupları Gezinti bölmesinde.
- Klinik Parametre grubu oluştur.
- İçin Parametre grubu ailesiseçin
aurora-mysql5.7. - İçin Tip, seçmek DB Kümesi Parametre Grubu.
- İçin Grup ismi, girmek
my-mysql-dynamodb-cdc. - İçin Açıklama, girmek
Parameter group for demo Aurora MySQL database. - Klinik oluşturmak.
- seç
my-mysql-dynamodb-cdc, ve Seç Düzenle altında Parametre grubu işlemleri. - Parametre grubunu aşağıdaki gibi düzenleyin:
| Name | Özellik |
| binlog_row_image | tam |
| binlog_format | SIRA |
| binlog_checksum | YOK |
| log_slave_updates | 1 |
- Klinik Değişiklikleri Kaydet.

Aurora MySQL kümesini oluşturun
Aurora MySQL kümesini oluşturmak için aşağıdaki adımları tamamlayın:
- Amazon RDS konsolunda, veritabanları Gezinti bölmesinde.
- Klinik Veritabanı oluştur.
- İçin Bir veritabanı oluşturma yöntemi seçin, seçmek standart oluşturma.
- Altında motor seçenekleri, Için Motor tipi, seçmek Aurora (MySQL Uyumlu).
- İçin Motor versiyonu, seçmek Aurora (MySQL 5.7) 2.11.2.
- İçin Şablonlar, seçmek üretim.
- Altında Ayarlar, Için DB kümesi tanımlayıcısı, veritabanınız için bir ad girin.
- İçin ana kullanıcı adı, birincil kullanıcı adınızı girin.
- İçin Ana parola ve Ana şifreyi onaylayın, birincil şifrenizi girin.
- Altında Örnek yapılandırma, Için veritabanı bulut sunucusu sınıfı, seçmek Burstable sınıfları (t sınıfları içerir) Ve seç db.t3.küçük.
- Altında Kullanılabilirlik ve dayanıklılık, Için Multi-AZ dağıtımı, seçmek Bir Aurora Replikası oluşturmayın.
- Altında Bağlantı, Için İşlem kaynağı, seçmek Bir EC2 bilgi işlem kaynağına bağlanmayın.
- İçin Ağ türü, seçmek IPv4.
- İçin Sanal özel bulut (VPC), VPC'nizi seçin.
- İçin DB alt ağ grubu, genel alt ağınızı seçin.
- İçin Kamu erişim, seçmek Evet.
- İçin VPC güvenlik grubu (güvenlik duvarı), genel alt ağınız için güvenlik grubunu seçin.
- Altında Veritabanı kimlik doğrulaması, Için Veritabanı kimlik doğrulama seçenekleri, seçmek Parola kimlik doğrulaması.
- Altında Ek yapılandırma, Için DB kümesi parametre grubu, daha önce oluşturduğunuz küme parametre grubunu seçin.
- Klinik Veritabanı oluştur.
Kaynak veritabanına izin verme
Bir sonraki adım, kaynak Aurora MySQL veritabanında gerekli izni vermektir. Artık DB kümesine şunu kullanarak bağlanabilirsiniz: MySQL yardımcı programı. Aşağıdaki görevleri tamamlamak için sorgular çalıştırabilirsiniz:
- Bir demo veritabanı ve tablo oluşturun ve veriler üzerinde sorgular çalıştırın
- AWS DMS uç noktası tarafından kullanılan bir kullanıcı için izin verme
Aşağıdaki adımları tamamlayın:
- Veritabanı kümenize bağlanmak için kullandığınız EC2 bulut sunucusunda oturum açın.
- Veritabanı kümenizin birincil veritabanı eşgörünümüne bağlanmak için komut istemine aşağıdaki komutu girin:
- Bir veritabanı oluşturmak için aşağıdaki SQL komutunu çalıştırın:
- Bir tablo oluşturmak için aşağıdaki SQL komutunu çalıştırın:
- Tabloyu verilerle doldurmak için aşağıdaki SQL komutunu çalıştırın:
- AWS DMS uç noktası için bir kullanıcı oluşturmak üzere aşağıdaki SQL komutunu çalıştırın ve CDC görevleri için izin verme (yer tutucuyu tercih ettiğiniz parola ile değiştirin):
DynamoDB referans tablosuna veri yüklemek için AWS DMS kaynakları oluşturun ve yapılandırın
Bu bölümde, verileri DynamoDB referans tablosuna çoğaltmak için AWS DMS oluşturup yapılandıracaksınız.
Bir AWS DMS çoğaltma örneği oluşturun
Öncelikle, aşağıdaki adımları tamamlayarak bir AWS DMS çoğaltma örneği oluşturun:
- AWS DMS konsolunda seçin Çoğaltma örnekleri Gezinti bölmesinde.
- Klinik Çoğaltma örneği oluştur.
- Altında Ayarlar, Için Name, örneğiniz için bir ad girin.
- Altında Örnek yapılandırma, Için Yüksek kullanılabilirlik, seçmek Geliştirme veya test iş yükü (Single-AZ).
- Altında Bağlantı ve güvenlik, Için VPC güvenlik grupları, seçmek varsayılan.
- Klinik Çoğaltma örneği oluştur.
Amazon VPC uç noktaları oluşturun
İsteğe bağlı olarak oluşturabilirsiniz DynamoDB için Amazon VPC uç noktaları özel bir ağdaki AWS DMS örneğinden DynamoDB tablonuza bağlanmanız gerektiğinde. Ayrıca etkinleştirdiğinizden emin olun. Herkese açık VPC'nizin dışında bir veritabanına bağlanmanız gerektiğinde.
Bir AWS DMS kaynak uç noktası oluşturun
Aşağıdaki adımları tamamlayarak bir AWS DMS kaynak uç noktası oluşturun:
- AWS DMS konsolunda seçin Uç noktalar Gezinti bölmesinde.
- Klinik Bitiş noktası oluştur.
- İçin Uç nokta türü, seçmek Kaynak uç noktası.
- Altında Uç nokta yapılandırması, Için uç nokta tanımlayıcısı, uç noktanız için bir ad girin.
- İçin Kaynak motor, seçmek Amazon Aurora MySQL'i.
- İçin Uç nokta veritabanına erişim, seçmek Erişim bilgilerini manuel olarak sağlayın.
- İçin Sunucu Adı, Aurora yazıcı örneğinizin uç nokta adını girin (örneğin,
mycluster.cluster-123456789012.us-east-1.rds.amazonaws.com). - İçin Liman, girmek
3306. - İçin kullanıcı adı, AWS DMS göreviniz için bir kullanıcı adı girin.
- İçin Şifre, Bir parola girin.
- Klinik Bitiş noktası oluştur.
Bir AWS DMS hedef uç noktası oluşturun
Aşağıdaki adımları tamamlayarak bir AWS DMS hedef uç noktası oluşturun:
- AWS DMS konsolunda seçin Uç noktalar Gezinti bölmesinde.
- Klinik Bitiş noktası oluştur.
- İçin Uç nokta türü, seçmek Hedef uç nokta.
- Altında Uç nokta yapılandırması, Için uç nokta tanımlayıcısı, uç noktanız için bir ad girin.
- İçin Hedef motor, seçmek Amazon DinamoDB.
- İçin Hizmet erişim rolü ARN, AWS DMS göreviniz için IAM rolünü girin.
- Klinik Bitiş noktası oluştur.
AWS DMS geçiş görevleri oluşturma
Aşağıdaki adımları tamamlayarak AWS DMS veritabanı geçiş görevleri oluşturun:
- AWS DMS konsolunda seçin Veritabanı taşıma görevleri Gezinti bölmesinde.
- Klinik Görev oluştur.
- Altında Görev yapılandırması, Için görev tanımlayıcı, göreviniz için bir ad girin.
- İçin Çoğaltma örneği, çoğaltma örneğinizi seçin.
- İçin Kaynak veritabanı uç noktası, kaynak uç noktanızı seçin.
- İçin Hedef veritabanı uç noktası, hedef uç noktanızı seçin.
- İçin Taşıma türü, seçmek Mevcut verileri taşıyın ve devam eden değişiklikleri çoğaltın.
- Altında Görev ayarları, Için Hedef tablo hazırlama modu, seçmek Hiçbir şey yapma.
- İçin Tam yük tamamlandıktan sonra görevi durdurun, seçmek durma.
- İçin LOB sütun ayarları, seçmek Sınırlı LOB modu.
- İçin Görev günlükleri, etkinleştirme CloudWatch günlüklerini aç ve Toplu iş için optimize edilmiş uygulamayı açın.
- Altında Tablo eşlemeleri, seçmek JSON Editörü ve aşağıdaki kuralları girin.
Burada sütuna değer ekleyebilirsiniz. Aşağıdaki kurallarla, AWS DMS CDC görevi önce içinde belirtilen ada sahip yeni bir DynamoDB tablosu oluşturacaktır. target-table-name. Sonra tüm kayıtları çoğaltacak, DB tablosundaki sütunları DynamoDB tablosundaki niteliklerle eşleştirme.

- Klinik Görev oluştur.
Artık AWS DMS replikasyon görevi başlatılmıştır.
- Bekle Durum olarak göstermek yükleme tamamlandı.
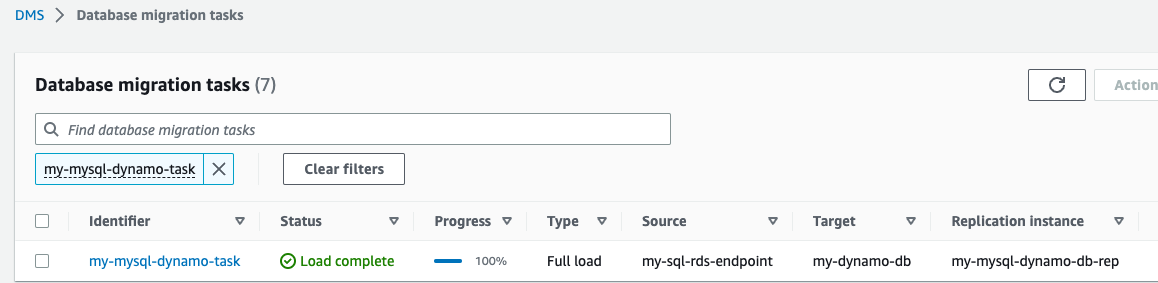
- DynamoDB konsolunda, tablolar Gezinti bölmesinde.
- DynamoDB referans tablosunu seçin ve Tablo öğelerini keşfedin Çoğaltılan kayıtları gözden geçirmek için.

Bir AWS Glue Data Catalog tablosu ve bir AWS Glue akışlı ETL işi oluşturun
Bu bölümde, bir AWS Glue Data Catalog tablosu ve bir AWS Glue akış ayıklama, dönüştürme ve yükleme (ETL) işi oluşturacaksınız.
Veri Kataloğu tablosu oluşturma
Aşağıdaki adımlarla kaynak Kinesis veri akışı için bir AWS Glue Data Catalog tablosu oluşturun:
- AWS Glue konsolunda seçin veritabanları altında Veri Kataloğu Gezinti bölmesinde.
- Klinik Veritabanı ekle.
- İçin Name, girmek
my_kinesis_db. - Klinik Veritabanı oluştur.
- Klinik tablolar altında veritabanları, Daha sonra seçmek Tablo ekle.
- İçin Name, girmek
my_stream_src_table. - İçin veritabanı, seçmek
my_kinesis_db. - İçin kaynak türünü seçin, seçmek Kinesis.
- İçin Kinesis veri akışı şu konumda bulunur:, seçmek hesabım.
- İçin Kinesis akışı adı, veri akışınız için bir ad girin.
- İçin Sınıflandırmaseçin JSON.
- Klinik Sonraki.
- Klinik Şemayı JSON olarak düzenle, aşağıdaki JSON'u girin ve ardından İndirim.
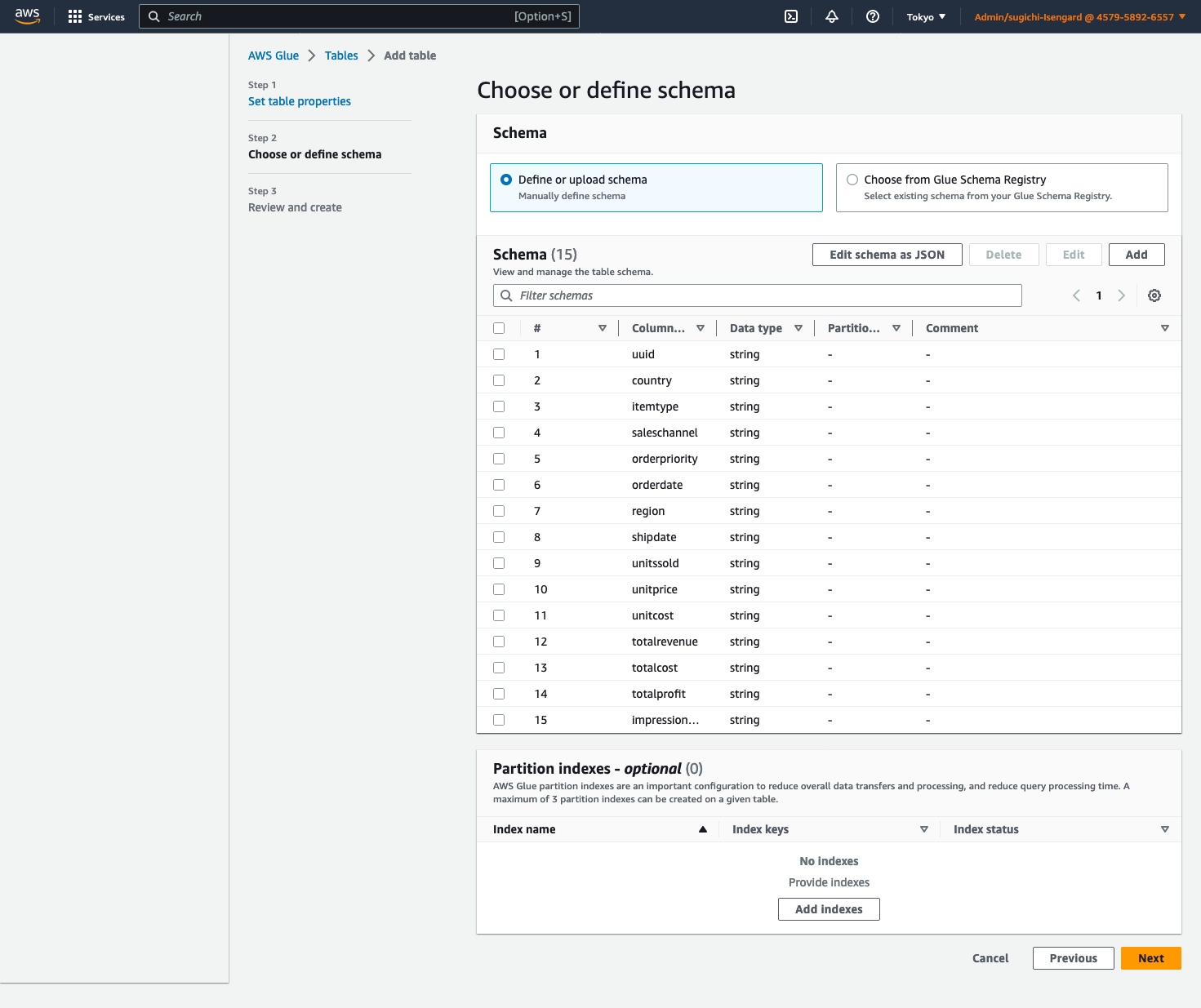
-
- Klinik Sonraki, Daha sonra seçmek oluşturmak.
Bir AWS Glue akışı ETL işi oluşturun
Ardından, bir AWS Glue akış işi oluşturursunuz. AWS Glue 3.0 ve sonrası, yerel olarak Apache Hudi'yi destekler, bu yüzden bir Hudi tablosuna almak için bu yerel entegrasyonu kullanıyoruz. AWS Glue akış işini oluşturmak için aşağıdaki adımları tamamlayın:
- AWS Glue Studio konsolunda şunu seçin: Spark komut dosyası düzenleyicisi Ve seç oluşturmak.
- Altında İş detayları sekme için Name, işiniz için bir isim girin.
- İçin IAM Rolü, AWS Glue işiniz için IAM rolünü seçin.
- İçin Tipseçin Kıvılcım Akışı.
- İçin Tutkal versiyonu, seçmek Tutkal 4.0 – Spark 3.3, Scala 2, Python 3'ü destekler.
- İçin İstenen işçi sayısı, girmek
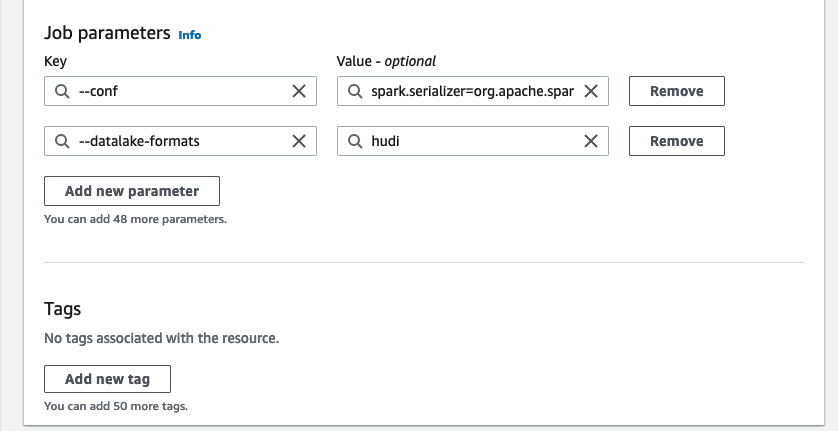
3. - Altında Gelişmiş özellikler, Için İş parametreleri, seçmek Yeni parametre ekle.
- İçin anahtar, girmek
--conf. - İçin Özellik, girmek
spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.hive.convertMetastoreParquet=false. - Klinik Yeni parametre ekle.
- İçin anahtar, girmek
--datalake-formats. - İçin Özellik, girmek
hudi. - İçin Komut dosyası yolu, girmek
s3://<S3BucketName>/scripts/. - İçin geçici yol, girmek
s3://<S3BucketName>/temporary/. - İsteğe bağlı olarak Spark UI günlük yolu, girmek
s3://<S3BucketName>/sparkHistoryLogs/.
- Üzerinde Senaryo sekmesinde, aşağıdaki betiği AWS Glue Studio düzenleyicisine girin ve seçin oluşturmak.
Neredeyse gerçek zamanlı akış işi, bir Kinesis veri akışını sık sık güncellenen referans verilerini içeren bir DynamoDB tablosuyla birleştirerek verileri zenginleştirir. Zenginleştirilmiş veri kümesi, veri gölündeki hedef Hudi tablosuna yüklenir. Yer değiştirmek AWS CloudFormation aracılığıyla oluşturduğunuz klasörünüzle:
- Klinik koşmak Akış işini başlatmak için
Aşağıdaki ekran görüntüsü, DataFrame'lerin örneklerini gösterir. data_frame, country_lookup_df, ve final_frame.
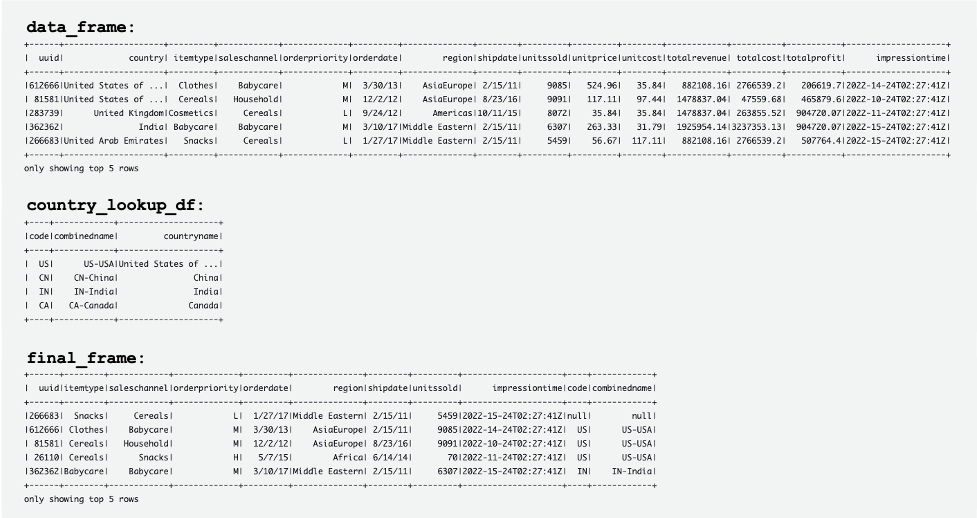
AWS Glue işi, DynamoDB'deki Kinesis veri akışından ve referans tablosundan gelen kayıtları başarıyla birleştirdi ve ardından birleştirilen kayıtları Hudi formatında Amazon S3'e aldı.
Örnek veriler oluşturmak ve Kinesis veri akışına yüklemek için bir Python betiği oluşturun ve çalıştırın
Bu bölümde, örnek veriler oluşturmak ve bunu kaynak Kinesis veri akışına yüklemek için bir Python oluşturup çalıştıracaksınız. Aşağıdaki adımları tamamlayın:
- AWS Cloud9'da, EC2 bulut sunucunuzda veya veri akışınıza kayıt koyan diğer herhangi bir bilgi işlem ana bilgisayarında oturum açın.
- adlı bir Python dosyası oluşturun.
generate-data-for-kds.py:
- Python dosyasını açın ve aşağıdaki betiği girin:
Bu komut dosyası, her 2 saniyede bir Kinesis veri akışı kaydı koyar.
Aurora MySQL kümesindeki referans tablosunun güncellenmesini simüle edin
Artık tüm kaynaklar ve yapılandırmalar hazır. Bu örnek için, eklemek istiyoruz 3 haneli ülke kodu referans tablosuna Değişiklikleri simüle etmek için Aurora MySQL tablosundaki kayıtları güncelleyelim. Aşağıdaki adımları tamamlayın:
- AWS Glue akış işinin zaten çalışıyor olduğundan emin olun.
- Daha önce açıklandığı gibi birincil veritabanı bulut sunucusuna yeniden bağlanın.
- Kayıtları güncellemek için SQL komutlarınızı girin:
Şimdi Aurora MySQL kaynak veritabanındaki referans tablosu güncellendi. Ardından, değişiklikler otomatik olarak DynamoDB'deki referans tablosuna kopyalanır.
Aşağıdaki tablolar, içindeki kayıtları göstermektedir. data_frame, country_lookup_df, ve final_frame. içinde country_lookup_df ve final_frame, combinedname sütun olarak biçimlendirilmiş değerlere sahip <2-digit-country-code>-<3-digit-country-code>-<country-name>, başvurulan tablodaki değiştirilen kayıtların AWS Glue akış işini yeniden başlatmadan tabloya yansıtıldığını gösterir. Bu, AWS Glue işinin Kinesis veri akışından gelen kayıtları, referans tablosu değişirken bile referans tablosuyla başarıyla birleştirdiği anlamına gelir.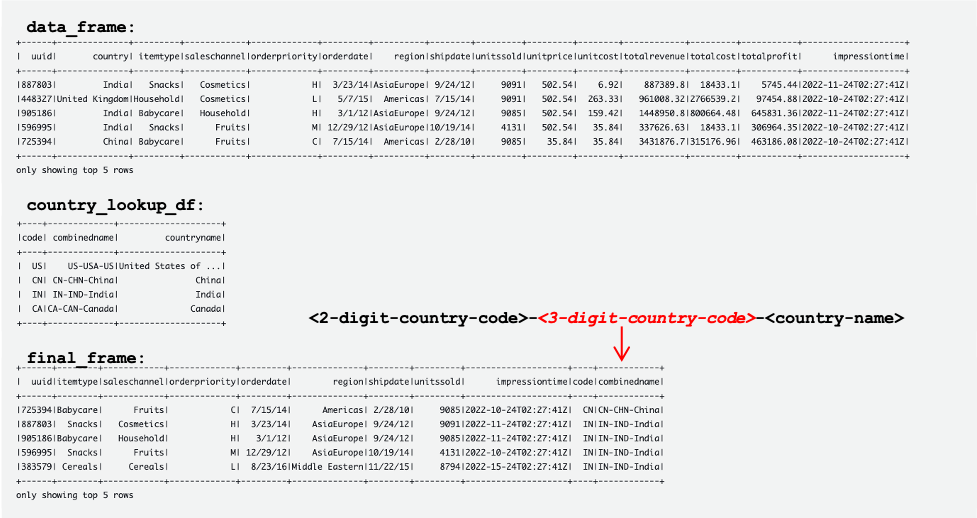
Athena kullanarak Hudi tablosunu sorgulama
Hedef tablodaki kayıtları görmek için Athena kullanarak Hudi tablosunu sorgulayalım. Aşağıdaki adımları tamamlayın:
- Komut dosyasının ve AWS Glue Streaming işinin hala çalıştığından emin olun:
- Python betiği (
generate-data-for-kds.py) hala çalışıyor. - Üretilen veriler veri akışına gönderiliyor.
- AWS Glue akış işi hala çalışıyor.
- Python betiği (
- Athena konsolunda, sorgu düzenleyicide aşağıdaki SQL'i çalıştırın:
Aşağıdaki sorgu sonucu, başvurulan tablo değiştirilmeden önce işlenen kayıtları gösterir. Kayıtlar combinedname sütun benzer <2-digit-country-code>-<country-name>.

Aşağıdaki sorgu sonucu, başvurulan tablo değiştirildikten sonra işlenen kayıtları gösterir. Kayıtlar combinedname sütun benzer <2-digit-country-code>-<3-digit-country-code>-<country-name>.

Artık, değiştirilen referans verilerinin, Kinesis veri akışındaki kayıtları ve DynamoDB'deki referans verilerini birleştiren hedef Hudi tablosuna başarıyla yansıtıldığını anlıyorsunuz.
Temizlemek
Son adım olarak, kaynakları temizleyin:
- Kinesis veri akışını silin.
- AWS DMS geçiş görevini, uç noktayı ve çoğaltma örneğini silin.
- AWS Glue akış işini durdurun ve silin.
- AWS Cloud9 ortamını silin.
- CloudFormation şablonunu silin.
Sonuç
Gerçek zamanlı veri alımını ve işlenmesini içeren bir işlemsel veri gölü oluşturmak ve sürdürmek, hangi alım hizmetinin kullanılacağı, referans verilerinizin nasıl depolanacağı ve hangi işlemsel veri gölü çerçevesinin kullanılacağı gibi alınması gereken çok sayıda değişken bileşene ve karara sahiptir. Bu gönderide, işlemsel bir veri gölü için yapı taşları olarak AWS yerel bileşenlerini ve açık kaynak çerçevesi olarak Apache Hudi'yi kullanarak böyle bir işlem hattının uygulama ayrıntılarını sağladık.
Bu çözümün, bu tür gereksinimlerle yeni bir veri gölü uygulamak isteyen kuruluşlar için bir başlangıç noktası olabileceğine inanıyoruz. Ek olarak, farklı bileşenler tamamen takılabilir ve yeni gereksinimleri hedeflemek veya mevcut olanları geçirerek sorunlu noktaları ele almak için mevcut veri gölleriyle karıştırılabilir ve eşleştirilebilir.
yazarlar hakkında
 Maniş Kola AWS'de bir Veri Laboratuvarı Çözümleri Mimarıdır ve burada veri analitiği ve yapay zeka ihtiyaçları için bulutta yerel çözümler tasarlamak üzere çeşitli sektörlerdeki müşterilerle yakın işbirliği içinde çalışır. İş sorunlarını çözmek ve ölçeklenebilir prototipler oluşturmak için AWS yolculuklarında müşterilerle iş birliği yapıyor. Manish'in AWS'ye katılmadan önceki deneyimi, müşterilerin veri ambarı, BI, veri entegrasyonu ve veri gölü projelerini uygulamalarına yardımcı olmayı içerir.
Maniş Kola AWS'de bir Veri Laboratuvarı Çözümleri Mimarıdır ve burada veri analitiği ve yapay zeka ihtiyaçları için bulutta yerel çözümler tasarlamak üzere çeşitli sektörlerdeki müşterilerle yakın işbirliği içinde çalışır. İş sorunlarını çözmek ve ölçeklenebilir prototipler oluşturmak için AWS yolculuklarında müşterilerle iş birliği yapıyor. Manish'in AWS'ye katılmadan önceki deneyimi, müşterilerin veri ambarı, BI, veri entegrasyonu ve veri gölü projelerini uygulamalarına yardımcı olmayı içerir.
 Santosh Kotagiri AWS'de somut iş sonuçlarına götüren veri analitiği ve bulut çözümleri deneyimine sahip bir Çözüm Mimarıdır. Uzmanlığı, bulutta yerel ve açık kaynaklı hizmetlere odaklanarak, sektörlerdeki müşteriler için ölçeklenebilir veri analitiği çözümleri tasarlama ve uygulamada yatmaktadır. İşi büyütmek ve karmaşık sorunları çözmek için teknolojiden yararlanma konusunda tutkulu.
Santosh Kotagiri AWS'de somut iş sonuçlarına götüren veri analitiği ve bulut çözümleri deneyimine sahip bir Çözüm Mimarıdır. Uzmanlığı, bulutta yerel ve açık kaynaklı hizmetlere odaklanarak, sektörlerdeki müşteriler için ölçeklenebilir veri analitiği çözümleri tasarlama ve uygulamada yatmaktadır. İşi büyütmek ve karmaşık sorunları çözmek için teknolojiden yararlanma konusunda tutkulu.
 Çiho Sugimoto AWS Büyük Veri Destek ekibinde bir Bulut Destek Mühendisidir. Müşterilerin ETL iş yüklerini kullanarak veri gölleri oluşturmasına yardımcı olma konusunda tutkulu. Gezegen bilimini seviyor ve hafta sonları asteroit Ryugu'yu incelemekten hoşlanıyor.
Çiho Sugimoto AWS Büyük Veri Destek ekibinde bir Bulut Destek Mühendisidir. Müşterilerin ETL iş yüklerini kullanarak veri gölleri oluşturmasına yardımcı olma konusunda tutkulu. Gezegen bilimini seviyor ve hafta sonları asteroit Ryugu'yu incelemekten hoşlanıyor.
 Noritaka Sekiyama AWS Glue ekibinde Baş Büyük Veri Mimarıdır. Müşterilere yardımcı olmak için yazılım yapıları oluşturmaktan sorumludur. Boş zamanlarında yeni yol bisikletiyle bisiklete binmekten keyif alıyor.
Noritaka Sekiyama AWS Glue ekibinde Baş Büyük Veri Mimarıdır. Müşterilere yardımcı olmak için yazılım yapıları oluşturmaktan sorumludur. Boş zamanlarında yeni yol bisikletiyle bisiklete binmekten keyif alıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Adryenn Ashley ile Geleceği Basmak. Buradan Erişin.
- PREIPO® ile PRE-IPO Şirketlerinde Hisse Al ve Sat. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/join-streaming-source-cdc-glue/

