De omvang en complexiteit van grote taalmodellen (LLM's) is de afgelopen jaren enorm toegenomen. LLM's hebben opmerkelijke capaciteiten getoond in het leren van de semantiek van natuurlijke taal en het produceren van mensachtige reacties. Veel recente LLM's zijn verfijnd met een krachtige techniek genaamd instructie afstemmen, waarmee het model nieuwe taken kan uitvoeren of reacties op nieuwe prompts kan genereren zonder promptspecifieke fijnafstemming. Een op instructies afgestemd model gebruikt zijn begrip van gerelateerde taken of concepten om voorspellingen te genereren voor nieuwe prompts. Omdat bij deze techniek geen modelgewichten hoeven te worden bijgewerkt, wordt het tijdrovende en rekenkundig dure proces vermeden dat nodig is om een model af te stemmen op een nieuwe, voorheen ongeziene taak.
In dit bericht laten we zien hoe u een op instructies afgestemd Flan T5-model kunt openen en implementeren vanaf Amazon SageMaker-jumpstart. We laten ook zien hoe u prompts voor Flan-T5-modellen kunt ontwerpen om verschillende NLP-taken (natural language processing) uit te voeren. Bovendien kunnen deze taken worden uitgevoerd met zero-shot learning, waarbij een goed ontworpen prompt het model naar de gewenste resultaten kan leiden. Overweeg bijvoorbeeld om een meerkeuzevraag te stellen en het model te vragen het juiste antwoord uit de beschikbare keuzes te geven. We behandelen prompts voor de volgende NLP-taken:
- Tekst samenvatting
- Gezond verstand redenering
- Vraag beantwoorden
- Sentiment classificatie
- Vertaling
- Voornaamwoord resolutie
- Tekstgeneratie op basis van artikel
- Denkbeeldig artikel op basis van titel
De code voor alle stappen in deze demo is hieronder beschikbaar notitieboekje.
JumpStart is de machine learning (ML) hub van Amazon Sage Maker dat met één klik toegang biedt tot meer dan 350 ingebouwde algoritmen; vooraf getrainde modellen van TensorFlow, PyTorch, Hugging Face en MXNet; en vooraf gebouwde oplossingssjablonen. JumpStart biedt ook voorgetraind funderingsmodellen zoals stabiliteits-AI's Stabiele diffusie tekst-naar-beeld-model, BLOEIEN, Coheres Genereer, Alexa™ van Amazon en meer.
Instructie afstemmen
Instructie afstemmen is een techniek waarbij een taalmodel wordt verfijnd op een verzameling NLP-taken met behulp van instructies. Bij deze techniek wordt het model getraind om taken uit te voeren door tekstuele instructies te volgen in plaats van specifieke datasets voor elke taak. Het model is nauwkeurig afgestemd met een set invoer- en uitvoervoorbeelden voor elke taak, waardoor het model kan worden gegeneraliseerd naar nieuwe taken waarvoor het niet expliciet is getraind, zolang er aanwijzingen voor de taken worden gegeven. Het afstemmen van instructies helpt de nauwkeurigheid en effectiviteit van modellen te verbeteren en is handig in situaties waarin grote datasets niet beschikbaar zijn voor specifieke taken.
Sinds 2020 is er een groot aantal onderzoeken naar het afstemmen van instructies uitgevoerd, wat heeft geleid tot een verzameling van verschillende taken, sjablonen en methoden. Een van de meest prominente methoden voor het afstemmen van instructies, Taalmodellen finetunen (Flan), verzamelt deze openbaar beschikbare collecties in een Flan-collectie om nauwkeurig afgestemde modellen te produceren op basis van een breed scala aan instructies. Op deze manier zijn de multi-task Flan-modellen concurrerend met dezelfde modellen die onafhankelijk van elkaar zijn afgestemd op elke specifieke taak en kunnen ze generaliseren buiten de specifieke instructies die tijdens de training worden gezien tot het volgen van instructies in het algemeen.
Zero-shot leren
Zero-shot leren in NLP stelt een vooraf getrainde LLM in staat om reacties te genereren op taken waarvoor het niet specifiek is opgeleid. Bij deze techniek wordt het model voorzien van een invoertekst en een prompt die de verwachte uitvoer van het model in natuurlijke taal beschrijft. De vooraf getrainde modellen kunnen hun kennis gebruiken om coherente en relevante antwoorden te genereren, zelfs voor prompts waarop ze niet specifiek zijn getraind. Zero-shot learning kan de benodigde tijd en gegevens verminderen en tegelijkertijd de efficiëntie en nauwkeurigheid van NLP-taken verbeteren. Zero-shot learning wordt gebruikt in een verscheidenheid aan NLP-taken, zoals het beantwoorden van vragen, samenvattingen en het genereren van tekst.
Weinig geschoten leren omvat het trainen van een model om nieuwe taken uit te voeren door slechts een paar voorbeelden te geven. Dit is handig wanneer beperkte gelabelde gegevens beschikbaar zijn voor training. Hoewel dit bericht zich in de eerste plaats richt op zero-shot learning, zijn de modellen waarnaar wordt verwezen ook in staat om reacties te genereren op few-shot leerprompts.
Flan-T5-model
Een populair encoder-decodermodel dat bekend staat als T5 (Text-to-Text Transfer Transformer) is zo'n model dat vervolgens werd verfijnd via de Flan-methode om de Vlaai-T5 familie van modellen. Flan-T5 is een op instructies afgestemd model en is daarom in staat om verschillende zero-shot NLP-taken uit te voeren, evenals weinig-shot in-context leertaken. Met de juiste aanwijzingen kan het zero-shot NLP-taken uitvoeren, zoals tekstsamenvatting, redeneren met gezond verstand, gevolgtrekkingen in natuurlijke taal, het beantwoorden van vragen, classificatie van zinnen en sentimenten, vertaling en het oplossen van voornaamwoorden. De voorbeelden in dit bericht zijn gegenereerd met de Flan-T5-familie.
JumpStart zorgt voor een gemakkelijke inzet van deze modelfamilie door middel van Amazon SageMaker Studio en de SageMaker-SDK. Dit omvat Flan-T5 Small, Flan-T5 Base, Flan-T5 Large, Flan-T5 XL en Flan-T5 XXL. Bovendien biedt JumpStart drie versies van Flan-T5 XXL op verschillende kwantisatieniveaus:
- Flan-T5 XXL – Het volledige model, geladen in single-precision floating-point formaat (FP32).
- Flan-T5 XXL FP16 – Een half-precisie floating-point format (FP16) versie van het volledige model. Deze implementatie verbruikt minder GPU-geheugen en voert snellere gevolgtrekkingen uit dan de FP32-versie.
- Flan-T5 XXL BNB INT8 – Een 8-bits gekwantiseerde versie van het volledige model, geladen in de GPU-context met behulp van de
accelerateenbitsandbytesbibliotheken. Deze implementatie biedt toegang tot deze LLM op instanties met minder rekenkracht, zoals een ml.g5.xlarge-instantie met één GPU.
Snelle engineering voor zero-shot NLP-taken op Flan-T5-modellen
Snelle techniek houdt zich bezig met het creëren van prompts van hoge kwaliteit om het model naar de gewenste reacties te leiden. Prompts moeten worden ontworpen op basis van de specifieke taak en dataset die wordt gebruikt. Het doel hier is om het model te voorzien van de nodige informatie om antwoorden van hoge kwaliteit te genereren terwijl ruis wordt geminimaliseerd. Dit kunnen trefwoorden, aanvullende contexten, vragen en meer zijn. Zie bijvoorbeeld de volgende code:
Een goed ontworpen prompt kan het model creatiever en algemener maken, zodat het zich gemakkelijk kan aanpassen aan nieuwe taken. Prompts kunnen ook helpen om domeinkennis over specifieke taken op te nemen en de interpreteerbaarheid te verbeteren. Snelle engineering kan de prestaties van zero-shot en few-shot leermodellen aanzienlijk verbeteren. Het maken van prompts van hoge kwaliteit vereist een zorgvuldige afweging van de taak die voorhanden is, evenals een goed begrip van de sterke en zwakke punten van het model.
In de verstrekte voorbeeld notebook, demonstreert elke taak ten minste zeven promptsjablonen en een uitgebreide set parameters om de modeluitvoer te regelen, zoals de maximale reekslengte, het aantal retourreeksen en het aantal stralen. Bovendien zijn de gebruikte promptsjablonen afkomstig uit de Flan T5 GitHub-repository, dat bestaat uit veel sjablonen die worden gebruikt in de Flan-collectie. Deze verzameling sjablonen is handig om te verkennen wanneer u uw eigen snelle engineering uitvoert.
In de volgende tabel wordt het Flan-T5 XXL-model gebruikt om reacties te genereren voor verschillende zero-shot NLP-taken. De eerste kolom toont de taak, de tweede kolom bevat de prompt die aan het model is gegeven (waarbij de sjabloontekst vetgedrukt is en de niet-vetgedrukte tekst de voorbeeldinvoer is), en de derde kolom is het antwoord van het model wanneer het wordt gevraagd tegen de snel.
Neem bijvoorbeeld de samenvattingstaak: om een modelprompt te maken, kunt u de sjabloon samenvoegen Briefly summarize this paragraph: met het tekstvoorbeeld dat u wilt samenvatten. Alle taken in deze tabel gebruikten dezelfde payloadparameters: max_length=150 om een bovengrens te stellen aan het aantal responstokens, no_repeat_ngram_size=5 om n-gram herhaling te ontmoedigen, en do_sample=False om bemonstering voor herhaalbaarheid uit te schakelen. We bespreken de beschikbare payloadparameteropties bij het opvragen van het eindpunt in meer detail later.
| Taak | Prompt (sjabloon vetgedrukt) | Modeluitgang |
| Samenvattend | Vat deze paragraaf kort samen: Amazon Comprehend gebruikt natuurlijke taalverwerking (NLP) om inzichten over de inhoud van documenten te extraheren. Het ontwikkelt inzichten door de entiteiten, sleutelzinnen, taal, sentimenten en andere gemeenschappelijke elementen in een document te herkennen. Gebruik Amazon Comprehend om nieuwe producten te maken op basis van inzicht in de structuur van documenten. Met Amazon Comprehend kunt u bijvoorbeeld in feeds van sociale netwerken zoeken naar productvermeldingen of een volledige documentrepository scannen op sleutelzinnen. U hebt toegang tot de documentanalysemogelijkheden van Amazon Comprehend met behulp van de Amazon Comprehend-console of met behulp van de Amazon Comprehend API's. U kunt real-time analyses uitvoeren voor kleine werklasten of u kunt asynchrone analysetaken starten voor grote documentensets. U kunt de vooraf getrainde modellen gebruiken die Amazon Comprehend biedt, of u kunt uw eigen aangepaste modellen trainen voor classificatie en entiteitsherkenning. Alle Amazon Comprehend-functies accepteren UTF-8-tekstdocumenten als invoer. Bovendien accepteren aangepaste classificatie en aangepaste entiteitsherkenning afbeeldingsbestanden, PDF-bestanden en Word-bestanden als invoer. Amazon Comprehend kan documenten in verschillende talen onderzoeken en analyseren, afhankelijk van de specifieke functie. Zie Ondersteunde talen in Amazon Comprehend voor meer informatie. De dominante taalcapaciteit van Amazon Comprehend kan documenten onderzoeken en de dominante taal bepalen voor een veel bredere selectie van talen. |
Begrijp de mogelijkheden van Amazon Comprehend |
| Gezond verstand redeneren of redeneren in natuurlijke taal | Het WK voetbal is van start gegaan in Los Angeles, Verenigde Staten.nnOp basis van bovenstaande paragraaf kunnen we concluderen dat ”Het WK vindt plaats in de Verenigde Staten.”?nn[”ja”, ”nee”] | ja |
| vraag beantwoorden |
Antwoord gebaseerd op context:nnMet de nieuwste en meest innovatieve Kindle tot nu toe kun je aantekeningen maken op miljoenen boeken en documenten, lijsten en dagboeken schrijven en meer. Voor lezers die altijd al hebben gewild dat ze in hun eBooks konden schrijven, laat de nieuwe Kindle van Amazon hen precies dat doen. De Kindle Scribe is de eerste Kindle voor lezen en schrijven en stelt gebruikers in staat hun boeken en documenten aan te vullen met notities, lijsten en meer. Hier is alles wat je moet weten over de Kindle Scribe, inclusief veelgestelde vragen. De Kindle Scribe maakt het gemakkelijk om te lezen en te schrijven zoals op papier De Kindle Scribe heeft een 10.2-inch, niet-verblindend scherm (het grootste van alle Kindle-apparaten), een scherpe resolutie van 300 ppi en 35 led-koplampen die zich automatisch aanpassen aan je omgeving. Personaliseer uw ervaring verder met het instelbare warme licht, lettergroottes, regelafstand en meer. Het wordt geleverd met naar keuze de Basic Pen of de Premium Pen, die u gebruikt om op het scherm te schrijven zoals u op papier zou doen. Ze hechten ook magnetisch aan je Kindle en hoeven nooit te worden opgeladen. De Premium Pen bevat een speciale gum en een aanpasbare sneltoets. De Kindle Scribe heeft de meeste opslagopties van alle Kindle-apparaten: kies uit 8 GB, 16 GB of 32 GB, afhankelijk van je lees- en schrijfniveau.nnwat zijn de belangrijkste kenmerken van de nieuwe Kindle? |
10.2-inch, niet-verblindend scherm |
| Zin of sentimentclassificatie | recensie:nDeze beweging is zo geweldig en verblindt en verheugt ons opnieuwnIs deze filmrecensiezin negatief of positief?nOPTIES:n-positief n-negatief | positief |
| Vertaling | Mijn naam is ArthurnnVertaal naar Duits | Mijn naam is Arthur |
| Voornaamwoord resolutie | Allen maakte zijn vriend, Xin, aan het lachen toen hij een grappige grap vertelde.nnWie is he verwijzend naar?nn(A)Allen n(B)Xin | Allen |
| Titelgeneratie op basis van een artikel |
Met de nieuwste en meest innovatieve Kindle tot nu toe kun je aantekeningen maken op miljoenen boeken en documenten, lijsten en dagboeken schrijven en meer. Voor lezers die altijd al hebben gewild dat ze in hun eBooks konden schrijven, laat de nieuwe Kindle van Amazon hen precies dat doen. De Kindle Scribe is de eerste Kindle voor lezen en schrijven en stelt gebruikers in staat hun boeken en documenten aan te vullen met notities, lijsten en meer. Hier is alles wat je moet weten over de Kindle Scribe, inclusief veelgestelde vragen. De Kindle Scribe maakt het gemakkelijk om te lezen en te schrijven zoals op papier De Kindle Scribe heeft een 10.2-inch, niet-verblindend scherm (het grootste van alle Kindle-apparaten), een scherpe resolutie van 300 ppi en 35 led-koplampen die zich automatisch aanpassen aan je omgeving. Personaliseer uw ervaring verder met het instelbare warme licht, lettergroottes, regelafstand en meer. Het wordt geleverd met naar keuze de Basic Pen of de Premium Pen, die u gebruikt om op het scherm te schrijven zoals u op papier zou doen. Ze hechten ook magnetisch aan je Kindle en hoeven nooit te worden opgeladen. De Premium Pen bevat een speciale gum en een aanpasbare sneltoets. De Kindle Scribe heeft de meeste opslagopties van alle Kindle-apparaten: kies uit 8 GB, 16 GB of 32 GB, afhankelijk van je lees- en schrijfniveau. nnGeef me een goede titel voor bovenstaand artikel. |
Alles wat u moet weten over de nieuwe Kindle Scribe |
| Denkbeeldige artikelgeneratie op basis van een titel | Titel: ”De universiteit komt met een nieuwe faciliteit“\nGezien de bovenstaande titel van een denkbeeldig artikel, stel je het artikel voor.n | De Universiteit van de Filipijnen (UP) gaat een nieuw gebouw bouwen voor haar College of Medicine and Health Sciences (CMHS) op de campus van de Universiteit van Santo Tomas (UST) in Bacolod City. Het CMHS-gebouw, dat op de UST-campus komt te staan, wordt het eerste gebouw dat door de universiteit op de UST-campus wordt gebouwd. Het CMMS-gebouw zal het eerste in zijn soort in het land zijn, volgens UP Vice President for Administration and Finance Dr. Jose L. Alcala. Het CMMH-gebouw wordt het tweede gebouw dat door de UP in de UST wordt gebouwd. Het eerste gebouw, dat in 2008 werd opgeleverd, is de UP |
Toegang tot op instructies afgestemde modellen van Flan-T5 in SageMaker
JumpStart biedt drie mogelijkheden om aan de slag te gaan met deze op instructies afgestemde Flan-modellen: JumpStart-basismodellen, Studio en de SageMaker SDK. De volgende paragrafen illustreren hoe elk van deze wegen eruit ziet en beschrijven hoe ze toegankelijk zijn.
JumpStart-basismodellen
Ontwikkelaars kunnen de visuele interface van het JumpStart-basismodellen, toegankelijk via de SageMaker-console, om op instructies afgestemde Flan-modellen te testen zonder een enkele regel code te schrijven. Deze speeltuin biedt een invoerprompt-tekstvak samen met bedieningselementen voor verschillende parameters die worden gebruikt tijdens inferentie. Deze functie bevindt zich momenteel in een gesloten voorbeeld en u zult het zien Toegang vragen knop in plaats van modellen als u geen toegang heeft. Zoals te zien is in de volgende schermafbeeldingen, hebt u toegang tot funderingsmodellen in het navigatievenster van de SageMaker-console. Kiezen Bekijk model op de Flan-T5 XL-modelkaart om toegang te krijgen tot de gebruikersinterface.
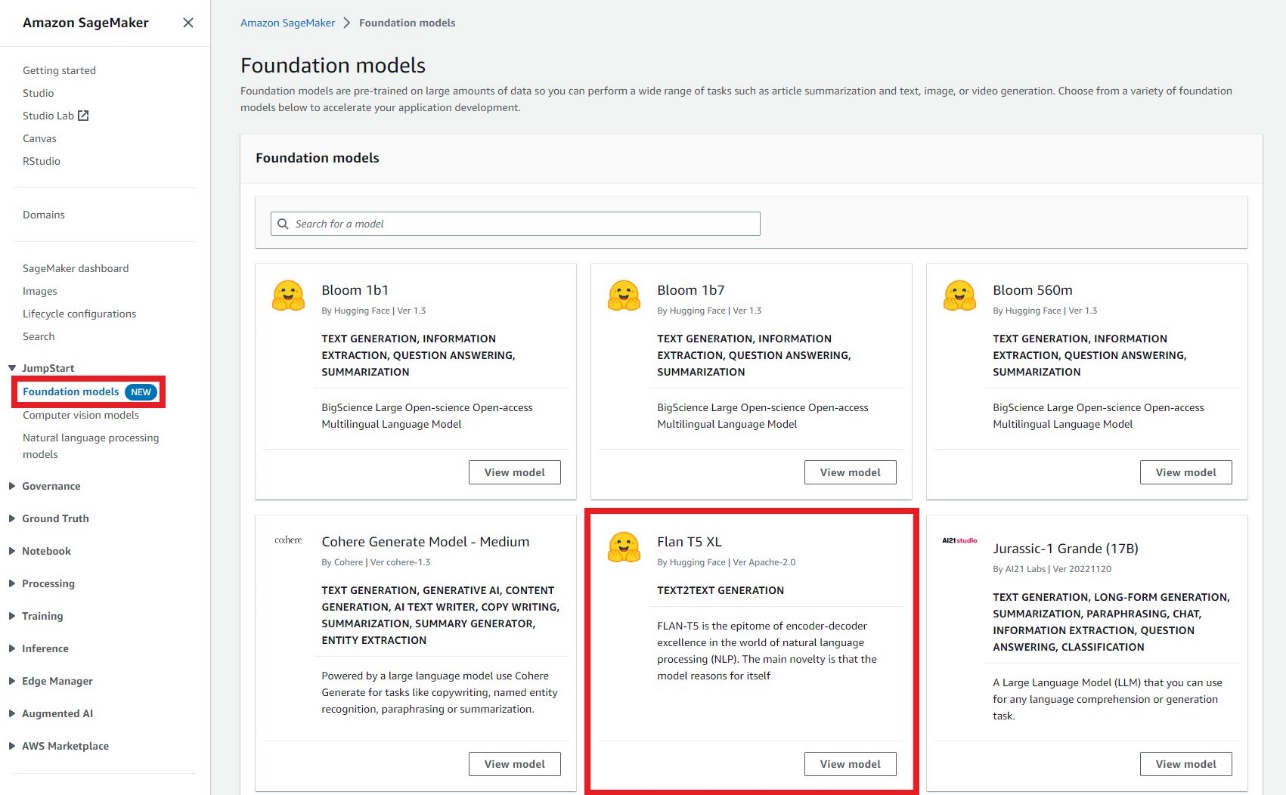
U kunt deze flexibele gebruikersinterface gebruiken om een demo van het model uit te proberen.
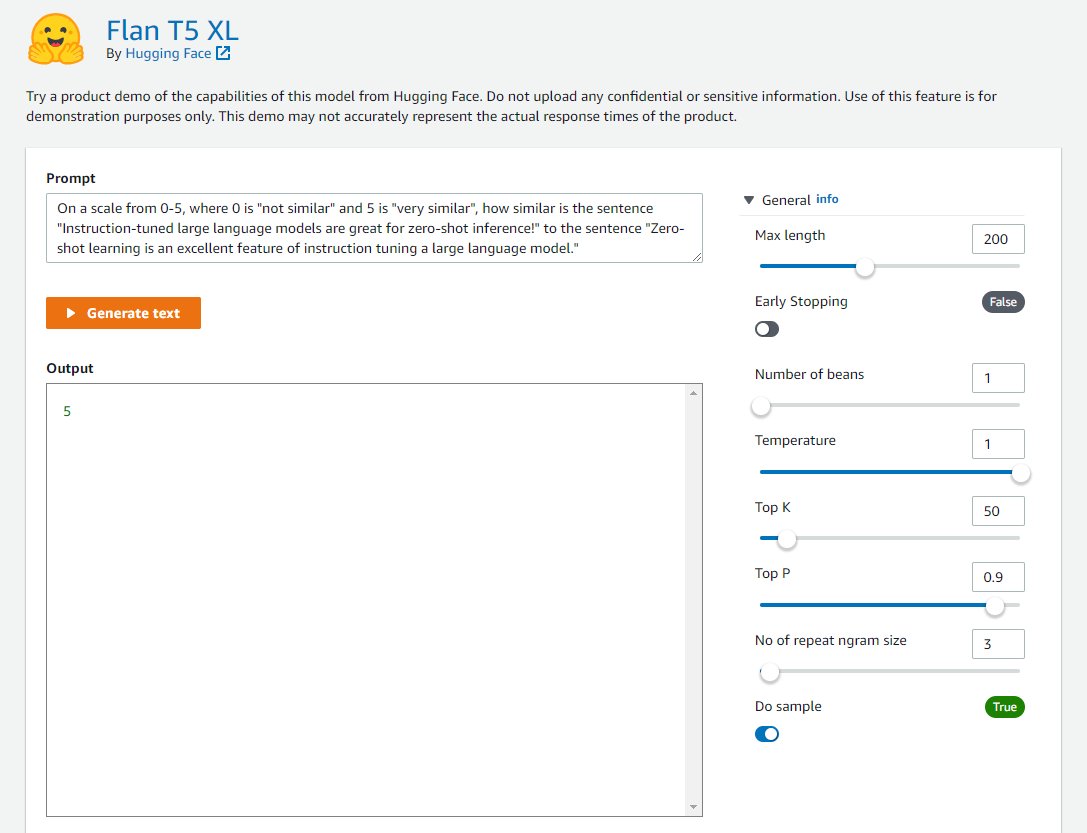
SageMaker Studio
Je hebt ook toegang tot deze modellen via de JumpStart-bestemmingspagina in Studio. Deze pagina bevat een lijst met beschikbare end-to-end ML-oplossingen, vooraf getrainde modellen en voorbeeldlaptops.

U kunt een Flan-T5-modelkaart kiezen om een modeleindpunt te implementeren via de gebruikersinterface.
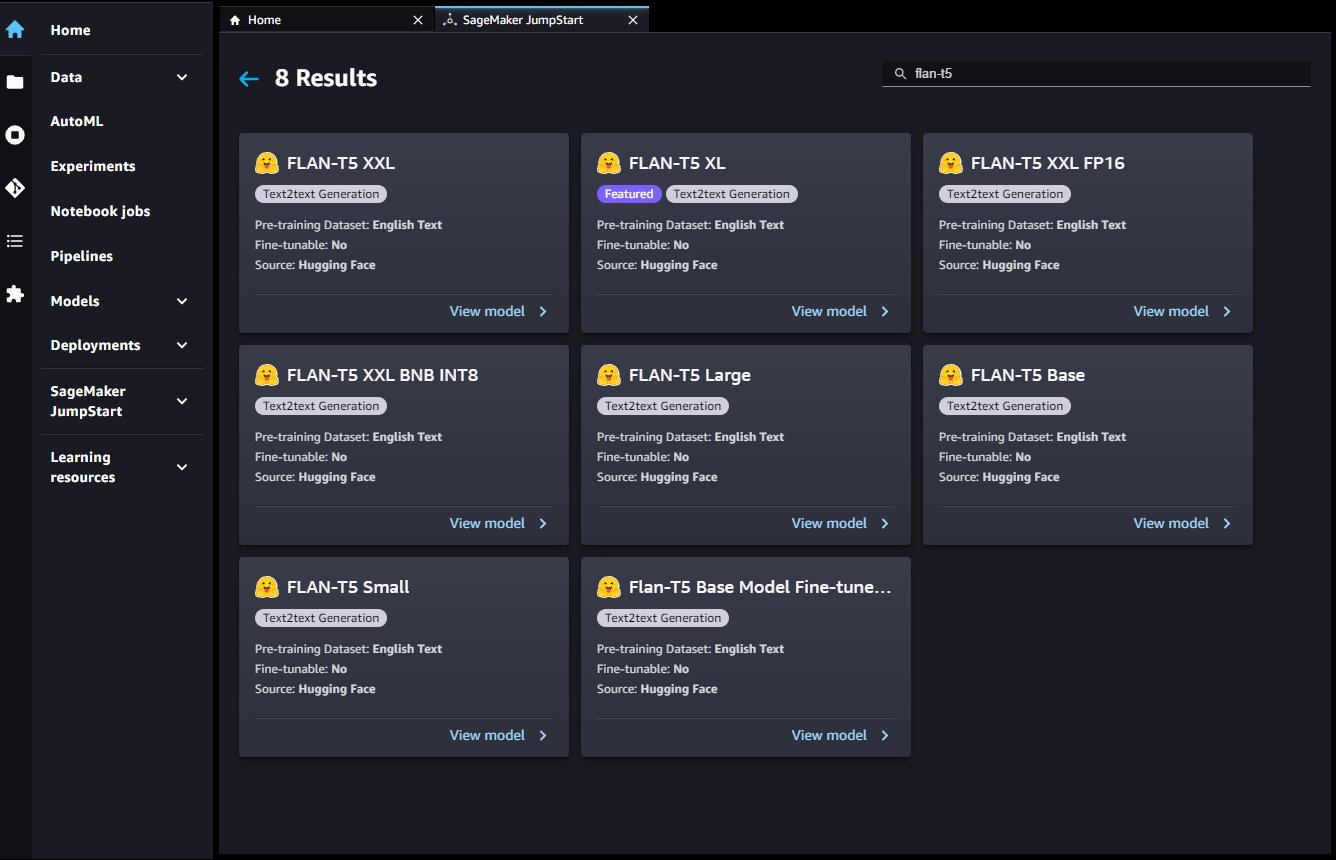
Nadat uw eindpunt is gelanceerd, kunt u een voorbeeld Jupyter-notebook starten dat laat zien hoe u dat eindpunt kunt opvragen.
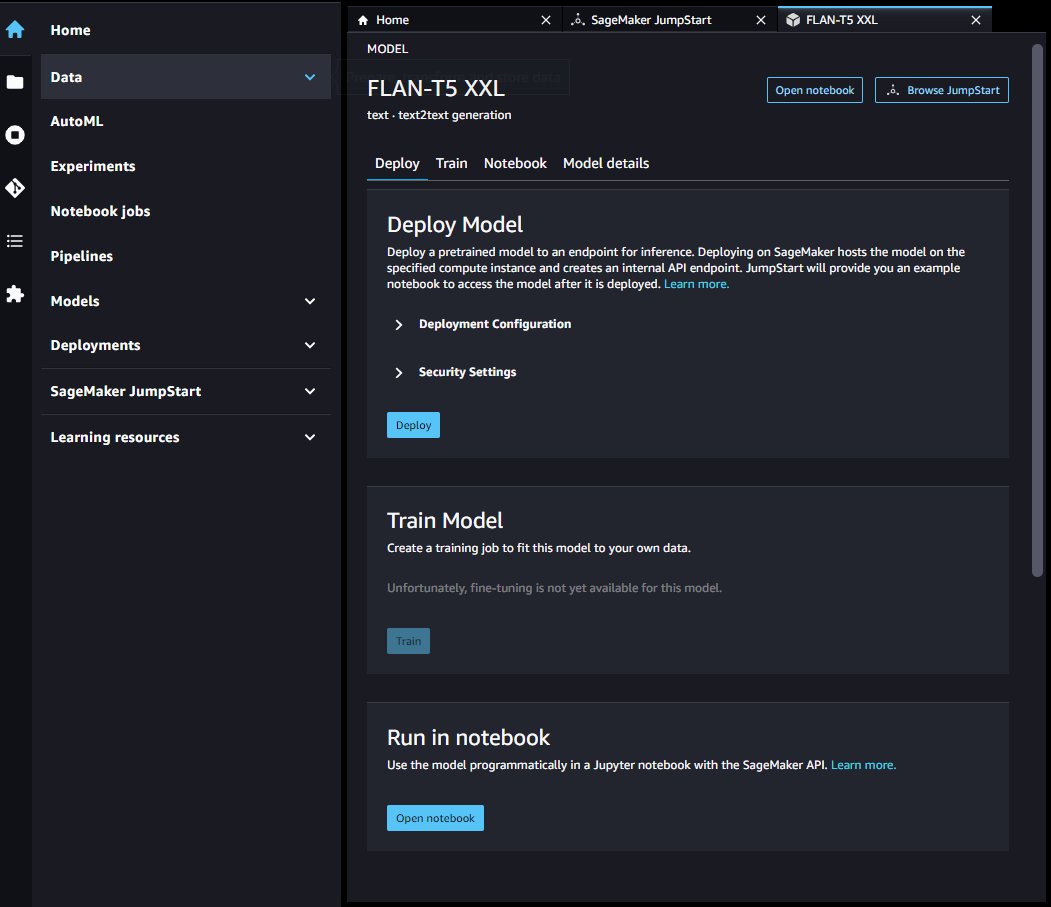
SageMaker Python-SDK
Ten slotte kunt u een eindpunt programmatisch implementeren via de SageMaker SDK. U moet de model-ID van uw gewenste model opgeven in de SageMaker-modelhub en het instantietype dat wordt gebruikt voor implementatie. De model-URI, die het inferentiescript bevat, en de URI van de Docker-container worden verkregen via de SageMaker SDK. Deze URI's worden geleverd door JumpStart en kunnen worden gebruikt om een SageMaker-modelobject te initialiseren voor implementatie. Zie de volgende code:
Nu het eindpunt is geïmplementeerd, kunt u het eindpunt opvragen om gegenereerde tekst te produceren. Beschouw een samenvattingstaak als voorbeeld, waarbij u een samenvatting wilt maken van de volgende tekst:
U moet deze tekst opgeven binnen een JSON-nettolading wanneer u het eindpunt aanroept. Deze JSON-payload kan alle gewenste inferentieparameters bevatten die helpen bij het beheersen van de lengte, de bemonsteringsstrategie en de beperkingen van de volgorde van uitvoertokens. Terwijl de Transformers-bibliotheek een volledige lijst definieert van beschikbare payload-parameters, zijn veel belangrijke payloadparameters als volgt gedefinieerd:
- maximale lengte – Het model genereert tekst totdat de uitvoerlengte (inclusief de invoercontextlengte) bereikt is
max_length. Indien gespecificeerd, moet het een positief geheel getal zijn. - aantal_return_sequences – Het aantal geretourneerde uitvoerreeksen. Indien gespecificeerd, moet het een positief geheel getal zijn.
- aantal_beams - Het aantal stralen dat wordt gebruikt bij de hebzuchtige zoektocht. Indien gespecificeerd, moet het een geheel getal groter dan of gelijk aan zijn
num_return_sequences. - no_repeat_ngram_size – Het model zorgt ervoor dat een reeks woorden van
no_repeat_ngram_sizewordt niet herhaald in de uitgangsvolgorde. Indien gespecificeerd, moet het een positief geheel getal groter dan 1 zijn. - temperatuur- – Regelt de willekeur in de uitvoer. Een hogere temperatuur resulteert in een uitvoervolgorde met woorden met een lage waarschijnlijkheid, en een lagere temperatuur resulteert in een uitvoervolgorde met woorden met een hoge waarschijnlijkheid. Als
temperaturegelijk is aan 0, resulteert dit in hebzuchtige decodering. Indien gespecificeerd, moet het een positieve vlotter zijn. - vroeg_stoppen - Indien
True, is het genereren van tekst voltooid wanneer alle straalhypothesen het einde van het stence-token bereiken. Indien gespecificeerd, moet het Booleaans zijn. - doen_voorbeeld - Indien
True, bemonster het volgende woord volgens de waarschijnlijkheid. Indien gespecificeerd, moet het Booleaans zijn. - top_k – Neem in elke stap van het genereren van tekst een voorbeeld van alleen de
top_kmeest waarschijnlijke woorden. Indien gespecificeerd, moet het een positief geheel getal zijn. - top_p – Steek in elke stap van het genereren van tekst een steekproef uit de kleinst mogelijke reeks woorden met cumulatieve waarschijnlijkheid
top_p. Indien gespecificeerd, moet het een float zijn tussen 0–1. - zaad – Herstel de gerandomiseerde status voor reproduceerbaarheid. Indien gespecificeerd, moet het een geheel getal zijn.
We kunnen elke subset van deze parameters specificeren terwijl we een eindpunt aanroepen. Vervolgens laten we een voorbeeld zien van het aanroepen van een eindpunt met deze argumenten:
Dit codeblok genereert een voorbeeld van een uitvoerreeks dat lijkt op de volgende tekst:
Opruimen
Verwijder de SageMaker-inferentie-eindpunten om doorlopende kosten te voorkomen. U kunt de eindpunten verwijderen via de SageMaker-console of vanuit de Studio-notebook met behulp van de volgende opdrachten:
Conclusie
In dit bericht hebben we een overzicht gegeven van de voordelen van zero-shot learning en beschreven hoe snelle engineering de prestaties van op instructies afgestemde modellen kan verbeteren. We hebben ook laten zien hoe u eenvoudig een op instructies afgestemd Flan T5-model van JumpStart kunt implementeren en voorbeelden hebben gegeven om te demonstreren hoe u verschillende NLP-taken kunt uitvoeren met behulp van het geïmplementeerde Flan T5-modeleindpunt in SageMaker.
We moedigen u aan om een Flan T5-model van JumpStart te implementeren en uw eigen prompts voor NLP-use-cases te maken.
Bekijk het volgende voor meer informatie over JumpStart:
Over de auteurs
 Dr Xin Huang is een toegepast wetenschapper voor de ingebouwde algoritmen van Amazon SageMaker JumpStart en Amazon SageMaker. Hij richt zich op het ontwikkelen van schaalbare algoritmen voor machine learning. Zijn onderzoeksinteresses liggen op het gebied van natuurlijke taalverwerking, verklaarbaar diep leren op tabelgegevens en robuuste analyse van niet-parametrische ruimte-tijdclustering. Hij heeft veel artikelen gepubliceerd in ACL, ICDM, KDD-conferenties en het tijdschrift Royal Statistical Society: Series A.
Dr Xin Huang is een toegepast wetenschapper voor de ingebouwde algoritmen van Amazon SageMaker JumpStart en Amazon SageMaker. Hij richt zich op het ontwikkelen van schaalbare algoritmen voor machine learning. Zijn onderzoeksinteresses liggen op het gebied van natuurlijke taalverwerking, verklaarbaar diep leren op tabelgegevens en robuuste analyse van niet-parametrische ruimte-tijdclustering. Hij heeft veel artikelen gepubliceerd in ACL, ICDM, KDD-conferenties en het tijdschrift Royal Statistical Society: Series A.
 Vivek Gangasani is Senior Machine Learning Solutions Architect bij Amazon Web Services. Hij werkt samen met Machine Learning Startups om AI/ML-applicaties op AWS te bouwen en te implementeren. Momenteel richt hij zich op het leveren van oplossingen voor MLOps, ML Inference en low-code ML. Hij heeft gewerkt aan projecten in verschillende domeinen, waaronder Natural Language Processing en Computer Vision.
Vivek Gangasani is Senior Machine Learning Solutions Architect bij Amazon Web Services. Hij werkt samen met Machine Learning Startups om AI/ML-applicaties op AWS te bouwen en te implementeren. Momenteel richt hij zich op het leveren van oplossingen voor MLOps, ML Inference en low-code ML. Hij heeft gewerkt aan projecten in verschillende domeinen, waaronder Natural Language Processing en Computer Vision.
 Dr Kyle Ulrich is een Applied Scientist met de Ingebouwde algoritmen van Amazon SageMaker team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
Dr Kyle Ulrich is een Applied Scientist met de Ingebouwde algoritmen van Amazon SageMaker team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/zero-shot-prompting-for-the-flan-t5-foundation-model-in-amazon-sagemaker-jumpstart/

