Ondanks de schijnbaar onstuitbare acceptatie van LLM’s in verschillende sectoren, vormen ze een onderdeel van een breder technologie-ecosysteem dat de nieuwe AI-golf aandrijft. Veel conversationele AI-gebruiksscenario's vereisen LLM's zoals Llama 2, Flan T5 en Bloom om te reageren op vragen van gebruikers. Deze modellen zijn afhankelijk van parametrische kennis om vragen te beantwoorden. Het model leert deze kennis tijdens de training en codeert deze in de modelparameters. Om deze kennis te actualiseren moeten we de LLM omscholen, wat veel tijd en geld kost.
Gelukkig kunnen we bronkennis ook gebruiken om onze LLM’s te informeren. Bronkennis is informatie die via een invoerprompt in de LLM wordt ingevoerd. Een populaire benadering voor het verstrekken van bronkennis is Retrieval Augmented Generation (RAG). Met behulp van RAG halen we relevante informatie uit een externe gegevensbron en voeren die informatie in de LLM in.
In deze blogpost onderzoeken we hoe we LLM's zoals Llama-2 kunnen inzetten met Amazon Sagemaker JumpStart en hoe we onze LLM's up-to-date kunnen houden met relevante informatie via Retrieval Augmented Generation (RAG) met behulp van de Pinecone-vectordatabase om AI-hallucinatie te voorkomen .
Augmented Generation (RAG) ophalen in Amazon SageMaker
Pinecone zal de ophaalcomponent van RAG afhandelen, maar je hebt nog twee cruciale componenten nodig: ergens om de LLM-inferentie uit te voeren en ergens om het inbeddingsmodel uit te voeren.
Amazon SageMaker Studio is een geïntegreerde ontwikkelomgeving (IDE) die één enkele webgebaseerde visuele interface biedt waar u toegang hebt tot speciaal gebouwde tools om alle machine learning (ML)-ontwikkelingen uit te voeren. Het biedt SageMaker JumpStart, een modelhub waar gebruikers een bepaald model in hun eigen SageMaker-account kunnen lokaliseren, bekijken en starten. Het biedt vooraf getrainde, openbaar beschikbare en bedrijfseigen modellen voor een breed scala aan probleemtypen, waaronder basismodellen.
Amazon SageMaker Studio biedt de ideale omgeving voor het ontwikkelen van RAG-compatibele LLM-pijplijnen. Ga eerst met behulp van de AWS-console naar Amazon SageMaker en maak een SageMaker Studio-domein aan en open een Jupyter Studio-notebook.
Voorwaarden
Voer de volgende vereiste stappen uit:
- Stel Amazon SageMaker Studio in.
- Aan boord van een Amazon SageMaker-domein.
- Meld u aan voor een gratis Pinecone Vector Database.
- Vereiste bibliotheken: SageMaker Python SDK, Pinecone Client
Oplossingsoverzicht
Met behulp van de SageMaker Studio-notebook moeten we eerst de vereiste bibliotheken installeren:
Een LLM inzetten
In dit bericht bespreken we twee benaderingen voor het inzetten van een LLM. De eerste is via de HuggingFaceModel voorwerp. U kunt dit gebruiken bij het implementeren van LLM's (en het insluiten van modellen) rechtstreeks vanuit de Hugging Face-modelhub.
U kunt bijvoorbeeld een inzetbare configuratie maken voor de google/flan-t5-xl model zoals weergegeven in de volgende schermopname:
Wanneer u modellen rechtstreeks vanuit Hugging Face implementeert, initialiseert u de my_model_configuration met het volgende:
- An
envconfig vertelt ons welk model we willen gebruiken en voor welke taak. - Onze SageMaker-uitvoering
rolegeeft ons toestemming om ons model te implementeren. - An
image_uriis een afbeeldingsconfiguratie specifiek voor het implementeren van LLM's van Hugging Face.
Als alternatief heeft SageMaker een reeks modellen die direct compatibel zijn met een eenvoudiger JumpStartModel voorwerp. Veel populaire LLM's zoals Llama 2 worden ondersteund door dit model, dat kan worden geïnitialiseerd zoals weergegeven in de volgende schermafbeelding:
Voor beide versies van my_model, implementeer ze zoals weergegeven in de volgende schermopname:
Met ons geïnitialiseerde LLM-eindpunt kunt u beginnen met het uitvoeren van query's. Het formaat van onze vragen kan variëren (vooral tussen conversatie- en niet-conversationele LLM's), maar het proces is over het algemeen hetzelfde. Voor het Hugging Face-model doet u het volgende:
De oplossing vindt u in de GitHub-repository.
Het gegenereerde antwoord dat we hier krijgen slaat nergens op: het is een hallucinatie.
Extra context bieden aan LLM
Llama 2 probeert onze vraag uitsluitend te beantwoorden op basis van interne parametrische kennis. Het is duidelijk dat de modelparameters geen kennis opslaan van welke instanties we wel kunnen gebruiken met managed spot-training in SageMaker.
Om deze vraag correct te beantwoorden, moeten we gebruik maken van bronkennis. Dat wil zeggen dat we via de prompt aanvullende informatie aan de LLM geven. Laten we die informatie rechtstreeks toevoegen als aanvullende context voor het model.
We zien nu het juiste antwoord op de vraag; Dat was gemakkelijk! Het is echter onwaarschijnlijk dat een gebruiker contexten in zijn prompts invoegt; hij zou het antwoord op zijn vraag al weten.
In plaats van handmatig een enkele context in te voegen, identificeert u automatisch relevante informatie uit een uitgebreidere database met informatie. Daarvoor heb je Retrieval Augmented Generation nodig.
Ophalen Augmented Generation
Met Retrieval Augmented Generation kunt u een database met informatie coderen in een vectorruimte, waarbij de nabijheid tussen vectoren hun relevantie/semantische gelijkenis vertegenwoordigt. Met deze vectorruimte als kennisbank kunt u een nieuwe gebruikersquery converteren, deze in dezelfde vectorruimte coderen en de meest relevante records ophalen die eerder zijn geïndexeerd.
Nadat u deze relevante records heeft opgehaald, selecteert u er een paar en neemt u deze op in de LLM-prompt als aanvullende context, waardoor de LLM beschikt over zeer relevante bronkennis. Dit is een proces in twee stappen waarbij:
- Door te indexeren wordt de vectorindex gevuld met informatie uit een gegevensset.
- Het ophalen gebeurt tijdens een zoekopdracht en hier halen we relevante informatie uit de vectorindex op.
Voor beide stappen is een inbeddingsmodel nodig om onze voor mensen leesbare platte tekst te vertalen naar semantische vectorruimte. Gebruik de zeer efficiënte MiniLM-zintransformator van Hugging Face, zoals weergegeven in de volgende schermopname. Dit model is geen LLM en is daarom niet op dezelfde manier geïnitialiseerd als ons Llama 2-model.
In het hub_config, specificeer de model-ID zoals weergegeven in de schermopname hierboven, maar gebruik voor de taak feature-extractie omdat we vectorinsluitingen genereren en geen tekst zoals onze LLM. Hierna initialiseert u de modelconfiguratie met HuggingFaceModel zoals voorheen, maar deze keer zonder de LLM-afbeelding en met enkele versieparameters.
U kunt het model opnieuw implementeren met deploy, met behulp van de kleinere (alleen CPU) instantie van ml.t2.large. Het MiniLM-model is klein, heeft dus niet veel geheugen nodig en heeft geen GPU nodig, omdat het snel insluitingen kan maken, zelfs op een CPU. Indien gewenst kunt u het model sneller op GPU uitvoeren.
Om insluitingen te maken, gebruikt u de predict methode en geef een lijst met contexten door die moeten worden gecodeerd via de inputs sleutel zoals afgebeeld:
Er worden twee invoercontexten doorgegeven, waardoor twee contextvectorinbeddingen worden geretourneerd, zoals weergegeven:
len(out)
2
De inbeddingsdimensionaliteit van het MiniLM-model is 384 wat betekent dat elke vector die MiniLM-uitvoer insluit een dimensionaliteit moet hebben van 384. Als u echter naar de lengte van onze insluitingen kijkt, ziet u het volgende:
len(out[0]), len(out[1])
(8, 8)
Twee lijsten bevatten elk acht items. MiniLM verwerkt eerst tekst in een tokenisatiestap. Deze tokenisatie transformeert onze voor mensen leesbare platte tekst in een lijst met modelleesbare token-ID's. In de uitvoerfuncties van het model kunt u de insluitingen op tokenniveau zien. een van deze inbedding toont de verwachte dimensionaliteit van 384 zoals getoond:
len(out[0][0])
384
Transformeer deze insluitingen op tokenniveau in insluitingen op documentniveau door de gemiddelde waarden voor elke vectordimensie te gebruiken, zoals weergegeven in de volgende afbeelding.

Beteken een poolingoperatie om één enkele 384-dimensionale vector te krijgen.
Met twee 384-dimensionale vectorinsluitingen, één voor elke invoertekst. Om ons leven gemakkelijker te maken, verpakt u het coderingsproces in één enkele functie, zoals weergegeven in de volgende schermopname:
De gegevensset downloaden
Download de veelgestelde vragen over Amazon SageMaker als kennisbank om de gegevens te verkrijgen die zowel vraag- als antwoordkolommen bevatten.

Download de veelgestelde vragen over Amazon SageMaker
Wanneer u de zoekopdracht uitvoert, zoekt u naar Alleen antwoorden, zodat u de kolom Vraag kunt laten vallen. Zie notitieboekje voor details.
Onze dataset en de inbeddingspijplijn zijn klaar. Het enige dat we nu nodig hebben, is een plek om deze inbedding op te slaan.
Indexeren
De Pinecone-vectordatabase slaat vectorinbedding op en doorzoekt deze efficiënt op schaal. Om een database aan te maken heeft u een gratis API-sleutel van Pinecone nodig.
Nadat u verbinding hebt gemaakt met de Pinecone-vectordatabase, maakt u een enkele vectorindex (vergelijkbaar met een tabel in traditionele databases). Geef de index een naam retrieval-augmentation-aws en lijn de index uit dimension en metric parameters met die vereist door het inbeddingsmodel (in dit geval MiniLM).
Om te beginnen met het invoegen van gegevens, voert u het volgende uit:
U kunt beginnen met het doorzoeken van de index met de vraag eerder in dit bericht.
Bovenstaande uitvoer laat zien dat we relevante contexten retourneren om ons te helpen onze vraag te beantwoorden. Sinds we top_k = 1, index.query retourneerde het bovenste resultaat naast de metadata die luidt Managed Spot Training can be used with all instances supported in Amazon.
De prompt vergroten
Gebruik de opgehaalde contexten om de prompt uit te breiden en bepaal de maximale hoeveelheid context die u in de LLM wilt invoeren. Gebruik de 1000 tekenlimiet om elke geretourneerde context iteratief aan de prompt toe te voegen totdat u de lengte van de inhoud overschrijdt.
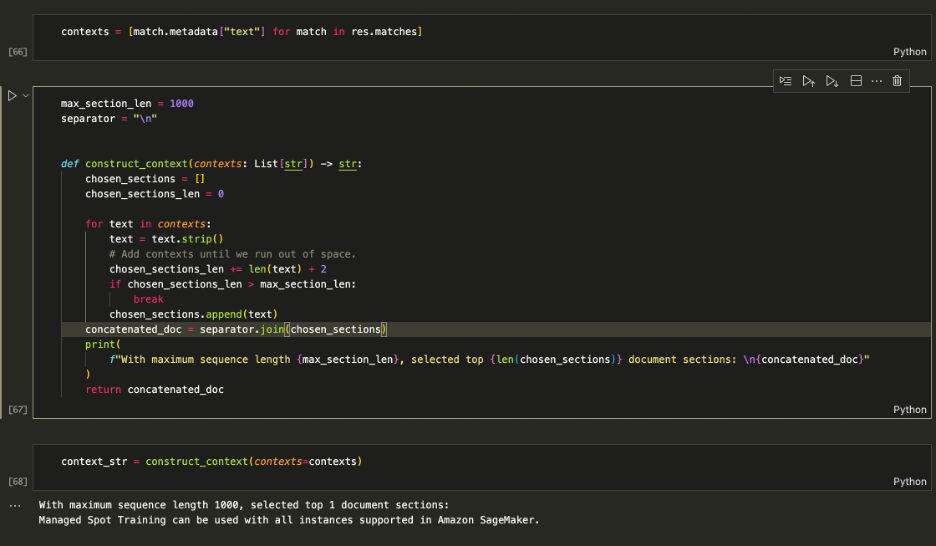
De prompt vergroten
Eten geven aan context_str in de LLM-prompt, zoals weergegeven in de volgende schermopname:
[Invoer]: Welke instanties kan ik gebruiken met Managed Spot Training in SageMaker? [Uitvoer]: op basis van de geboden context kunt u Managed Spot Training gebruiken met alle instanties die worden ondersteund in Amazon SageMaker. Daarom is het antwoord: alle instanties die worden ondersteund in Amazon SageMaker.
De logica werkt, dus verpak het in één enkele functie om alles overzichtelijk te houden.
U kunt nu vragen stellen zoals hieronder weergegeven:
Opruimen
Als u wilt voorkomen dat er ongewenste kosten in rekening worden gebracht, verwijdert u het model en het eindpunt.
Conclusie
In dit bericht hebben we u kennis laten maken met RAG met LLM's met open toegang op SageMaker. We hebben ook laten zien hoe je Amazon SageMaker Jumpstart-modellen kunt inzetten met Llama 2, Hugging Face LLM's met Flan T5 en hoe je modellen kunt inbedden met MiniLM.
We hebben een complete end-to-end RAG-pijplijn geïmplementeerd met behulp van onze open-accessmodellen en een Pinecone-vectorindex. Hiermee hebben we laten zien hoe we hallucinaties kunnen minimaliseren, de LLM-kennis up-to-date kunnen houden en uiteindelijk de gebruikerservaring en het vertrouwen in onze systemen kunnen verbeteren.
Om dit voorbeeld zelf uit te voeren, kloont u deze GitHub-repository en doorloopt u de voorgaande stappen met behulp van de Vraagantwoordnotitieboekje op GitHub.
Over de auteurs
 Vedante Jain is een Sr. AI/ML Specialist en werkt aan strategische Generatieve AI-initiatieven. Voordat hij bij AWS kwam, heeft Vedant ML/Data Science Specialty-posities bekleed bij verschillende bedrijven zoals Databricks, Hortonworks (nu Cloudera) en JP Morgan Chase. Buiten zijn werk heeft Vedant een passie voor muziek maken, rotsklimmen, wetenschap gebruiken om een zinvol leven te leiden en keukens van over de hele wereld ontdekken.
Vedante Jain is een Sr. AI/ML Specialist en werkt aan strategische Generatieve AI-initiatieven. Voordat hij bij AWS kwam, heeft Vedant ML/Data Science Specialty-posities bekleed bij verschillende bedrijven zoals Databricks, Hortonworks (nu Cloudera) en JP Morgan Chase. Buiten zijn werk heeft Vedant een passie voor muziek maken, rotsklimmen, wetenschap gebruiken om een zinvol leven te leiden en keukens van over de hele wereld ontdekken.
 James Briggs is een Staff Developer Advocate bij Pinecone, gespecialiseerd in vectorzoeken en AI/ML. Hij begeleidt ontwikkelaars en bedrijven bij het ontwikkelen van hun eigen GenAI-oplossingen via online onderwijs. Vóór Pinecone werkte James aan AI voor kleine tech-startups tot gevestigde financiële instellingen. Buiten zijn werk heeft James een passie voor reizen en het omarmen van nieuwe avonturen, variërend van surfen en duiken tot Muay Thai en BJJ.
James Briggs is een Staff Developer Advocate bij Pinecone, gespecialiseerd in vectorzoeken en AI/ML. Hij begeleidt ontwikkelaars en bedrijven bij het ontwikkelen van hun eigen GenAI-oplossingen via online onderwijs. Vóór Pinecone werkte James aan AI voor kleine tech-startups tot gevestigde financiële instellingen. Buiten zijn werk heeft James een passie voor reizen en het omarmen van nieuwe avonturen, variërend van surfen en duiken tot Muay Thai en BJJ.
 Xin Huang is een Senior Applied Scientist voor Amazon SageMaker JumpStart en Amazon SageMaker ingebouwde algoritmen. Hij richt zich op het ontwikkelen van schaalbare machine learning-algoritmen. Zijn onderzoeksinteresses liggen op het gebied van natuurlijke taalverwerking, verklaarbaar diep leren op tabelgegevens en robuuste analyse van niet-parametrische ruimte-tijd clustering. Hij heeft veel artikelen gepubliceerd in ACL-, ICDM-, KDD-conferenties en Royal Statistical Society: Series A.
Xin Huang is een Senior Applied Scientist voor Amazon SageMaker JumpStart en Amazon SageMaker ingebouwde algoritmen. Hij richt zich op het ontwikkelen van schaalbare machine learning-algoritmen. Zijn onderzoeksinteresses liggen op het gebied van natuurlijke taalverwerking, verklaarbaar diep leren op tabelgegevens en robuuste analyse van niet-parametrische ruimte-tijd clustering. Hij heeft veel artikelen gepubliceerd in ACL-, ICDM-, KDD-conferenties en Royal Statistical Society: Series A.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/mitigate-hallucinations-through-retrieval-augmented-generation-using-pinecone-vector-database-llama-2-from-amazon-sagemaker-jumpstart/

