Amazon SageMaker Studio biedt een volledig beheerde oplossing voor datawetenschappers om interactief machine learning (ML)-modellen te bouwen, trainen en implementeren. Tijdens het werken aan hun ML-taken beginnen datawetenschappers hun workflow doorgaans met het ontdekken van relevante gegevensbronnen en het verbinden daarvan. Vervolgens gebruiken ze SQL om gegevens uit verschillende bronnen te verkennen, analyseren, visualiseren en integreren voordat ze deze gebruiken in hun ML-training en gevolgtrekking. Voorheen moesten datawetenschappers vaak met meerdere tools jongleren om SQL in hun workflow te ondersteunen, wat de productiviteit belemmerde.
We zijn verheugd om aan te kondigen dat JupyterLab-notebooks in SageMaker Studio nu worden geleverd met ingebouwde ondersteuning voor SQL. Datawetenschappers kunnen nu:
- Maak verbinding met populaire datadiensten, waaronder Amazone Athene, Amazon roodverschuiving, Amazon DataZoneen Sneeuwvlok rechtstreeks in de notitieboekjes
- Blader en zoek naar databases, schema's, tabellen en weergaven, en bekijk een voorbeeld van gegevens binnen de notebookinterface
- Combineer SQL- en Python-code in dezelfde notebook voor efficiënte verkenning en transformatie van gegevens voor gebruik in ML-projecten
- Gebruik productiviteitsfuncties voor ontwikkelaars, zoals het voltooien van SQL-opdrachten, hulp bij het formatteren van code en syntaxisaccentuering om de ontwikkeling van code te versnellen en de algehele productiviteit van ontwikkelaars te verbeteren
Bovendien kunnen beheerders de verbindingen met deze dataservices veilig beheren, waardoor datawetenschappers toegang krijgen tot geautoriseerde gegevens zonder dat ze de inloggegevens handmatig hoeven te beheren.
In dit bericht begeleiden we u bij het instellen van deze functie in SageMaker Studio en leiden we u door de verschillende mogelijkheden van deze functie. Vervolgens laten we zien hoe u de SQL-ervaring in een notebook kunt verbeteren met behulp van de tekst-naar-SQL-mogelijkheden van geavanceerde grote taalmodellen (LLM's) om complexe SQL-query's te schrijven met tekst in natuurlijke taal als invoer. Om een breder publiek van gebruikers in staat te stellen SQL-query's te genereren op basis van natuurlijke taalinvoer in hun notebooks, laten we u ten slotte zien hoe u deze tekst-naar-SQL-modellen kunt implementeren met behulp van Amazon Sage Maker eindpunten.
Overzicht oplossingen
Met de SQL-integratie van SageMaker Studio JupyterLab notebook kunt u nu verbinding maken met populaire gegevensbronnen zoals Snowflake, Athena, Amazon Redshift en Amazon DataZone. Met deze nieuwe functie kunt u verschillende functies uitvoeren.
U kunt bijvoorbeeld gegevensbronnen zoals databases, tabellen en schema's rechtstreeks vanuit uw JupyterLab-ecosysteem visueel verkennen. Als uw notebookomgevingen draaien op SageMaker Distribution 1.6 of hoger, zoek dan naar een nieuwe widget aan de linkerkant van uw JupyterLab-interface. Deze toevoeging verbetert de toegankelijkheid en het beheer van gegevens binnen uw ontwikkelomgeving.
Als u momenteel niet de aanbevolen SageMaker-distributie (1.5 of lager) of een aangepaste omgeving gebruikt, raadpleeg dan de bijlage voor meer informatie.
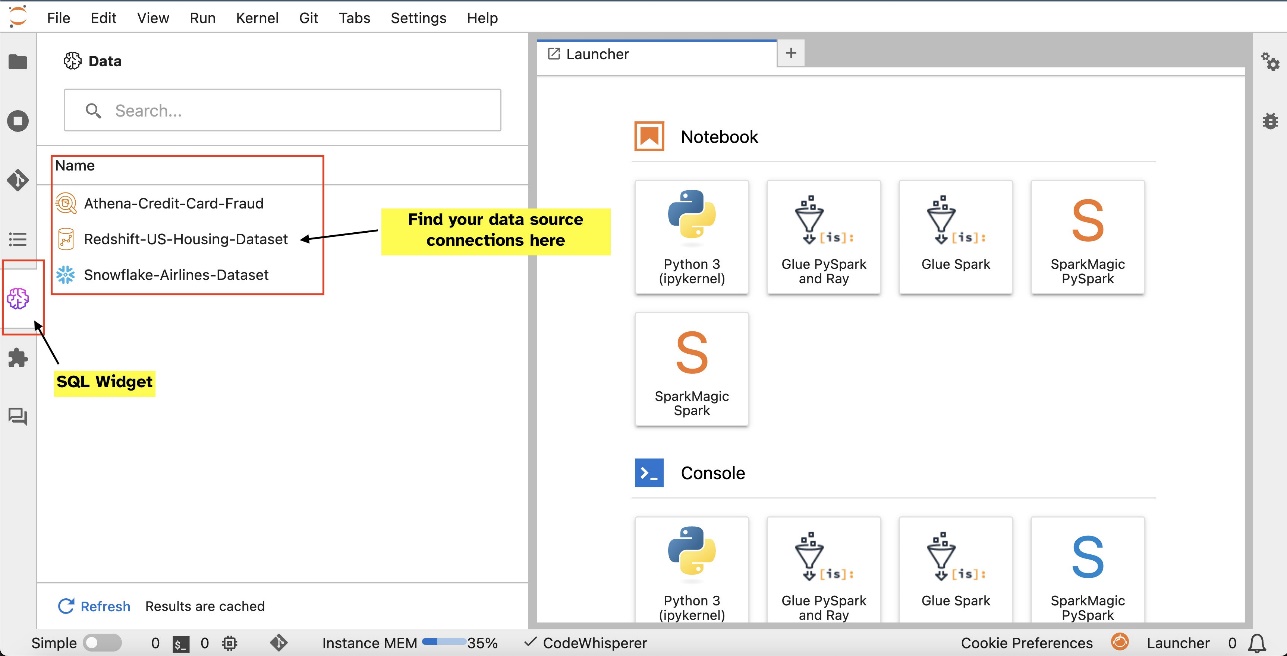
Nadat u verbindingen hebt ingesteld (geïllustreerd in de volgende sectie), kunt u gegevensverbindingen weergeven, door databases en tabellen bladeren en schema's inspecteren.
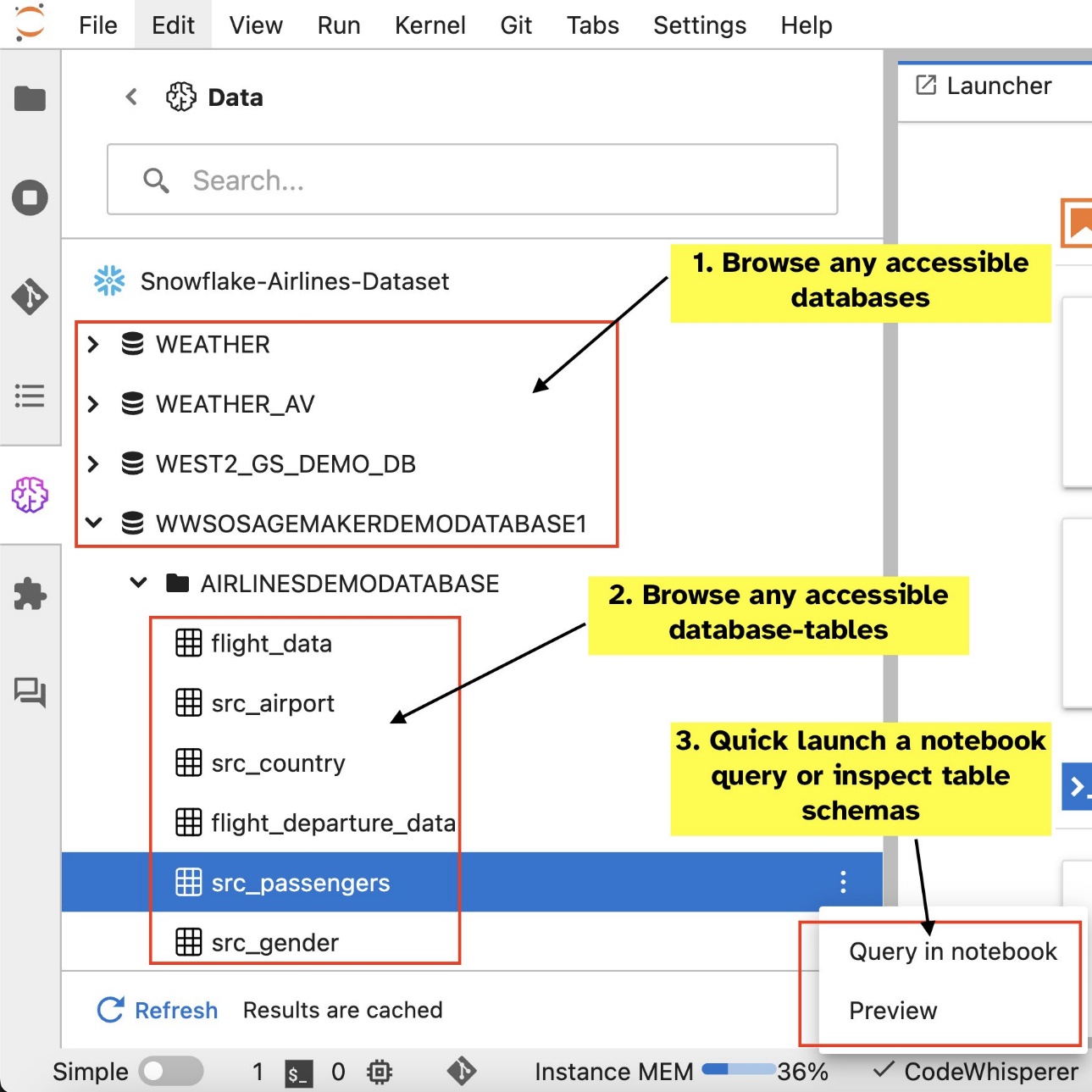
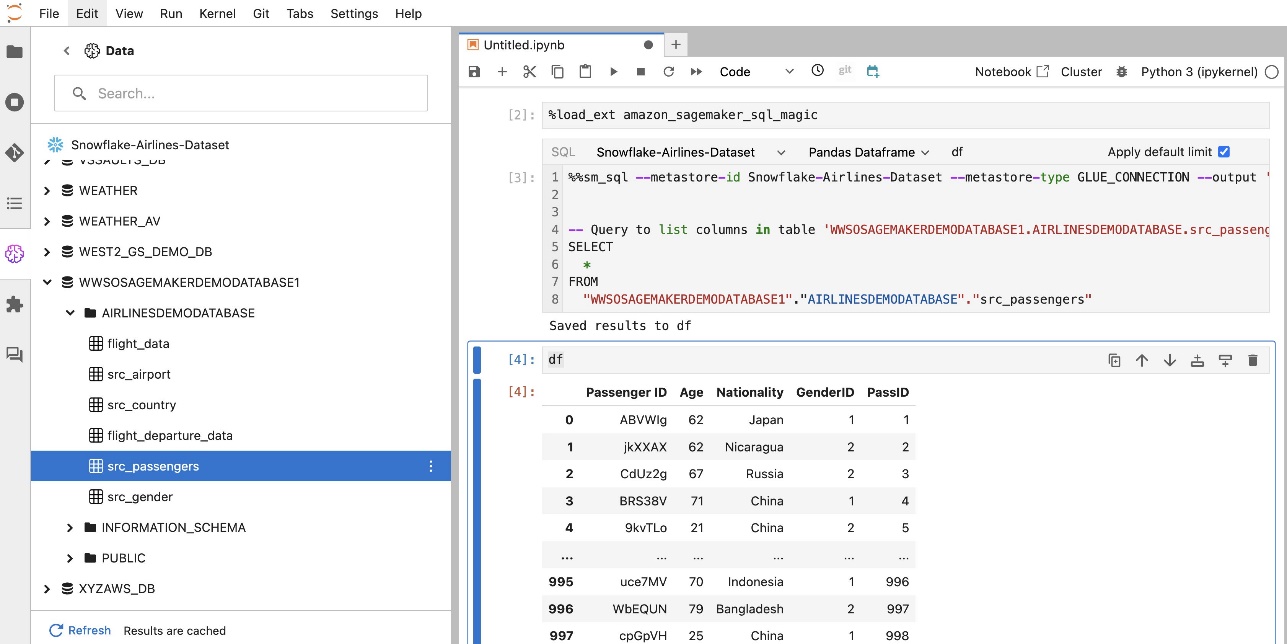
Met de ingebouwde SQL-extensie van SageMaker Studio JupyterLab kunt u SQL-query's rechtstreeks vanaf een notebook uitvoeren. Jupyter-notebooks kunnen onderscheid maken tussen SQL- en Python-code met behulp van de %%sm_sql magic-opdracht, die bovenaan elke cel moet worden geplaatst die SQL-code bevat. Deze opdracht geeft aan JupyterLab aan dat de volgende instructies SQL-opdrachten zijn in plaats van Python-code. De uitvoer van een query kan direct in de notebook worden weergegeven, waardoor een naadloze integratie van SQL- en Python-workflows in uw gegevensanalyse wordt vergemakkelijkt.
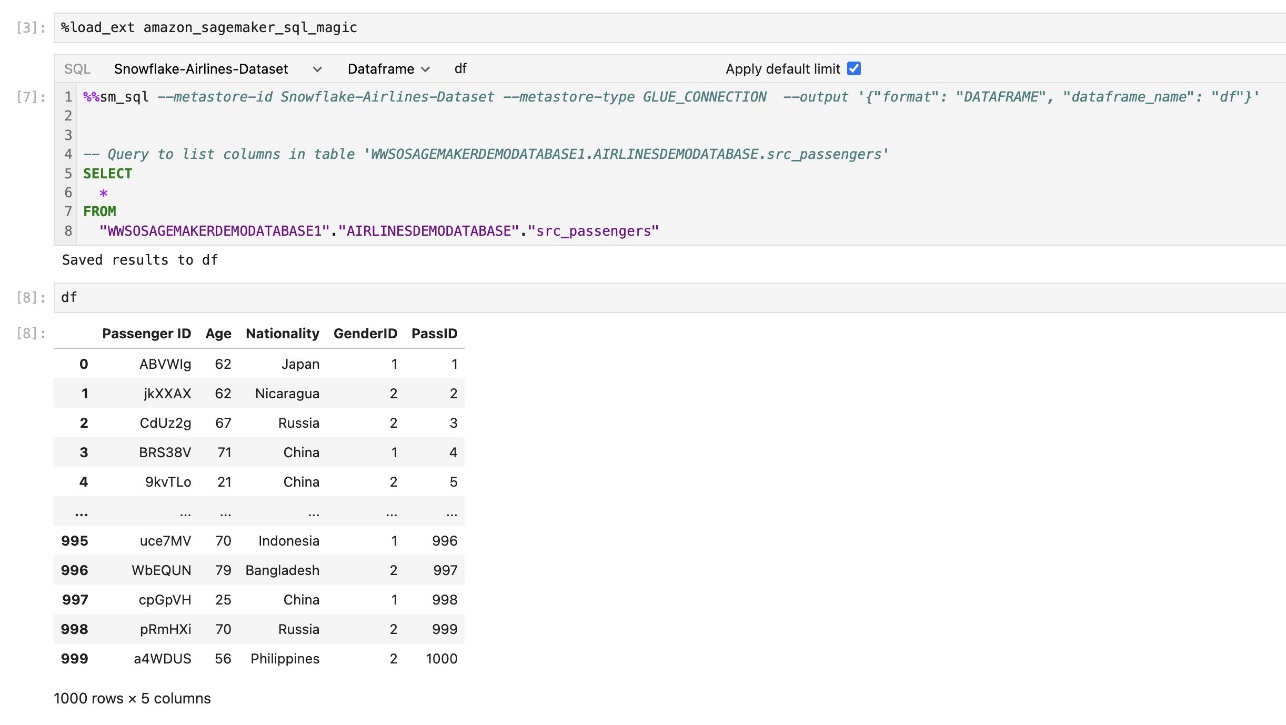
De uitvoer van een query kan visueel worden weergegeven als HTML-tabellen, zoals weergegeven in de volgende schermafbeelding.

Ze kunnen ook worden geschreven naar een panda's DataFrame.
Voorwaarden
Zorg ervoor dat u aan de volgende vereisten voldoet om de SageMaker Studio notebook SQL-ervaring te kunnen gebruiken:
- SageMaker Studio V2 – Zorg ervoor dat u de meest recente versie van uw SageMaker Studio-domein en gebruikersprofielen. Als u momenteel SageMaker Studio Classic gebruikt, raadpleegt u Migreren vanuit Amazon SageMaker Studio Classic.
- IAM-rol – SageMaker vereist een AWS Identiteits- en toegangsbeheer (IAM)-rol die moet worden toegewezen aan een SageMaker Studio-domein of gebruikersprofiel om machtigingen effectief te beheren. Mogelijk is een update van de uitvoeringsrol vereist om het bladeren door gegevens en de SQL-runfunctie mogelijk te maken. Met het volgende voorbeeldbeleid kunnen gebruikers toekennen, vermelden en uitvoeren AWS lijm, Athene, Amazon eenvoudige opslagservice (Amazone S3), AWS-geheimenmanageren Amazon Redshift-bronnen:
- JupyterLab-ruimte – Je hebt toegang nodig tot de bijgewerkte SageMaker Studio en JupyterLab Space met SageMaker-distributie v1.6 of latere afbeeldingsversies. Als u aangepaste images gebruikt voor JupyterLab Spaces of oudere versies van SageMaker Distribution (v1.5 of lager), raadpleeg dan de bijlage voor instructies om de benodigde pakketten en modules te installeren om deze functie in uw omgevingen in te schakelen. Voor meer informatie over SageMaker Studio JupyterLab Spaces raadpleegt u Verhoog de productiviteit op Amazon SageMaker Studio: maak kennis met JupyterLab Spaces en generatieve AI-tools.
- Toegangsreferenties voor gegevensbronnen – Voor deze SageMaker Studio-notebookfunctie zijn gebruikersnaam en wachtwoord vereist voor toegang tot gegevensbronnen zoals Snowflake en Amazon Redshift. Creëer op gebruikersnaam en wachtwoord gebaseerde toegang tot deze gegevensbronnen als u er nog geen heeft. Op OAuth gebaseerde toegang tot Snowflake wordt op het moment van schrijven niet ondersteund.
- Laad SQL-magie – Voordat u SQL-query's uitvoert vanuit een Jupyter-notebookcel, is het van essentieel belang dat u de SQL Magics-extensie laadt. Gebruik de opdracht
%load_ext amazon_sagemaker_sql_magicom deze functie in te schakelen. Bovendien kunt u de%sm_sql?opdracht om een uitgebreide lijst met ondersteunde opties voor query's vanuit een SQL-cel weer te geven. Deze opties omvatten onder meer het instellen van een standaardquerylimiet van 1,000, het uitvoeren van een volledige extractie en het injecteren van queryparameters. Deze opstelling maakt flexibele en efficiënte manipulatie van SQL-gegevens rechtstreeks binnen uw notebookomgeving mogelijk.
Maak databaseverbindingen
De ingebouwde SQL-browse- en uitvoeringsmogelijkheden van SageMaker Studio worden verbeterd door AWS Glue-verbindingen. Een AWS Glue-verbinding is een AWS Glue Data Catalog-object dat essentiële gegevens opslaat, zoals inloggegevens, URI-strings en Virtual Private Cloud (VPC)-informatie voor specifieke datastores. Deze verbindingen worden gebruikt door AWS Glue-crawlers, -taken en ontwikkelingseindpunten om toegang te krijgen tot verschillende soorten gegevensopslag. U kunt deze verbindingen gebruiken voor zowel bron- als doelgegevens, en zelfs dezelfde verbinding hergebruiken voor meerdere crawlers of ETL-taken (extraheren, transformeren en laden).
Om SQL-gegevensbronnen in het linkerdeelvenster van SageMaker Studio te verkennen, moet u eerst AWS Glue-verbindingsobjecten maken. Deze verbindingen vergemakkelijken de toegang tot verschillende gegevensbronnen en stellen u in staat hun schematische gegevenselementen te verkennen.
In de volgende secties doorlopen we het proces van het maken van SQL-specifieke AWS Glue-connectoren. Hierdoor kunt u datasets in verschillende datastores openen, bekijken en verkennen. Voor meer gedetailleerde informatie over AWS Glue-verbindingen raadpleegt u Verbinding maken met gegevens.
Een AWS Glue-verbinding maken
De enige manier om gegevensbronnen in SageMaker Studio te brengen is met AWS Glue-verbindingen. U moet AWS Glue-verbindingen maken met specifieke verbindingstypen. Op het moment van schrijven is het enige ondersteunde mechanisme voor het maken van deze verbindingen het gebruik van de AWS-opdrachtregelinterface (AWS CLI).
JSON-bestand met verbindingsdefinitie
Wanneer u verbinding maakt met verschillende gegevensbronnen in AWS Glue, moet u eerst een JSON-bestand maken dat de verbindingseigenschappen definieert, ook wel de verbindingsdefinitiebestand. Dit bestand is cruciaal voor het tot stand brengen van een AWS Glue-verbinding en zou alle noodzakelijke configuraties voor toegang tot de gegevensbron moeten beschrijven. Voor best practices op het gebied van beveiliging wordt aanbevolen om Secrets Manager te gebruiken om gevoelige informatie, zoals wachtwoorden, veilig op te slaan. Ondertussen kunnen andere verbindingseigenschappen rechtstreeks worden beheerd via AWS Glue-verbindingen. Deze aanpak zorgt ervoor dat gevoelige inloggegevens worden beschermd, terwijl de verbindingsconfiguratie nog steeds toegankelijk en beheersbaar blijft.
Hier volgt een voorbeeld van een JSON-verbindingsdefinitie:
Bij het opzetten van AWS Glue-verbindingen voor uw gegevensbronnen zijn er enkele belangrijke richtlijnen die u moet volgen om zowel functionaliteit als beveiliging te bieden:
- Stringificatie van eigenschappen - Binnen de
PythonPropertiessleutel, zorg ervoor dat alle eigenschappen zijn stringified sleutel-waardeparen. Het is van cruciaal belang om dubbele aanhalingstekens op de juiste manier te vermijden door waar nodig het backslash-teken () te gebruiken. Dit helpt het juiste formaat te behouden en syntaxisfouten in uw JSON te voorkomen. - Omgaan met gevoelige informatie – Hoewel het mogelijk is om alle verbindingseigenschappen erin op te nemen
PythonProperties, is het raadzaam om gevoelige gegevens zoals wachtwoorden niet rechtstreeks in deze eigenschappen op te nemen. Gebruik in plaats daarvan Secrets Manager voor het verwerken van gevoelige informatie. Deze aanpak beveiligt uw gevoelige gegevens door deze op te slaan in een gecontroleerde en gecodeerde omgeving, weg van de belangrijkste configuratiebestanden.
Maak een AWS Glue-verbinding met behulp van de AWS CLI
Nadat u alle noodzakelijke velden in uw JSON-bestand met de verbindingsdefinitie hebt opgenomen, bent u klaar om een AWS Glue-verbinding tot stand te brengen voor uw gegevensbron met behulp van de AWS CLI en de volgende opdracht:
Deze opdracht initieert een nieuwe AWS Glue-verbinding op basis van de specificaties in uw JSON-bestand. Hieronder volgt een kort overzicht van de opdrachtcomponenten:
- -regio – Dit specificeert de AWS-regio waar uw AWS Glue-verbinding zal worden gemaakt. Het is van cruciaal belang om de regio te selecteren waar uw gegevensbronnen en andere services zich bevinden om de latentie te minimaliseren en te voldoen aan de vereisten voor gegevenslocatie.
- –cli-input-json bestand:///pad/naar/bestand/connection/definition/file.json – Deze parameter zorgt ervoor dat de AWS CLI de invoerconfiguratie leest uit een lokaal bestand dat uw verbindingsdefinitie in JSON-indeling bevat.
U zou AWS Glue-verbindingen moeten kunnen maken met de voorgaande AWS CLI-opdracht vanaf uw Studio JupyterLab-terminal. Op de Dien in menu, kies New en terminal.

Indien de create-connection Als de opdracht succesvol wordt uitgevoerd, zou uw gegevensbron in het SQL-browservenster moeten worden vermeld. Als uw gegevensbron niet wordt vermeld, kiest u verversen om de cache bij te werken.

Maak een Snowflake-verbinding
In deze sectie concentreren we ons op het integreren van een Snowflake-gegevensbron met SageMaker Studio. Het maken van Snowflake-accounts, databases en magazijnen valt buiten het bestek van dit bericht. Om aan de slag te gaan met Snowflake, raadpleegt u de Sneeuwvlok gebruikershandleiding. In dit bericht concentreren we ons op het maken van een JSON-bestand met Snowflake-definitie en het tot stand brengen van een Snowflake-gegevensbronverbinding met behulp van AWS Glue.
Maak een Secrets Manager-geheim
U kunt verbinding maken met uw Snowflake-account door een gebruikers-ID en wachtwoord te gebruiken of door privésleutels te gebruiken. Om verbinding te maken met een gebruikers-ID en wachtwoord, moet u uw inloggegevens veilig opslaan in Secrets Manager. Zoals eerder vermeld, wordt het, hoewel het mogelijk is om deze informatie onder PythonProperties in te sluiten, niet aanbevolen om gevoelige informatie in platte tekst op te slaan. Zorg er altijd voor dat gevoelige gegevens veilig worden verwerkt om potentiële veiligheidsrisico's te voorkomen.
Voer de volgende stappen uit om informatie op te slaan in Secrets Manager:
- Kies op de Secrets Manager-console Bewaar een nieuw geheim.
- Voor Geheim type, kiezen Ander soort geheim.
- Kies voor het sleutel-waardepaar Platte tekst en voer het volgende in:
- Voer een naam in voor uw geheim, zoals
sm-sql-snowflake-secret. - Laat de overige instellingen op standaard staan of pas deze indien nodig aan.
- Creëer het geheim.
Maak een AWS Glue-verbinding voor Snowflake
Zoals eerder besproken zijn AWS Glue-verbindingen essentieel voor toegang tot elke verbinding vanuit SageMaker Studio. U kunt een lijst vinden van alle ondersteunde verbindingseigenschappen voor Snowflake. Hier volgt een voorbeeld van een JSON-verbindingsdefinitie voor Snowflake. Vervang de tijdelijke aanduiding-waarden door de juiste waarden voordat u deze op schijf opslaat:
Gebruik de volgende opdracht om een AWS Glue-verbindingsobject voor de Snowflake-gegevensbron te maken:
Met deze opdracht wordt een nieuwe Snowflake-gegevensbronverbinding gemaakt in uw SQL-browservenster waarin u kunt bladeren, en u kunt er SQL-query's op uitvoeren vanuit uw JupyterLab-notebookcel.
Een Amazon Redshift-verbinding maken
Amazon Redshift is een volledig beheerde datawarehouse-service op petabyte-schaal die de analyse van al uw gegevens met behulp van standaard SQL vereenvoudigt en de kosten verlaagt. De procedure voor het maken van een Amazon Redshift-verbinding komt nauw overeen met die voor een Snowflake-verbinding.
Maak een Secrets Manager-geheim
Net als bij de Snowflake-installatie moet u, om verbinding te maken met Amazon Redshift met behulp van een gebruikers-ID en wachtwoord, de geheime informatie veilig opslaan in Secrets Manager. Voer de volgende stappen uit:
- Kies op de Secrets Manager-console Bewaar een nieuw geheim.
- Voor Geheim type, kiezen Referenties voor Amazon Redshift-cluster.
- Voer de inloggegevens in die zijn gebruikt om in te loggen om toegang te krijgen tot Amazon Redshift als gegevensbron.
- Kies het Redshift-cluster dat aan de geheimen is gekoppeld.
- Voer een naam in voor het geheim, bijvoorbeeld
sm-sql-redshift-secret. - Laat de overige instellingen op standaard staan of pas deze indien nodig aan.
- Creëer het geheim.
Door deze stappen te volgen, zorgt u ervoor dat uw verbindingsreferenties veilig worden verwerkt, waarbij u de robuuste beveiligingsfuncties van AWS gebruikt om gevoelige gegevens effectief te beheren.
Creëer een AWS Glue-verbinding voor Amazon Redshift
Om een verbinding met Amazon Redshift tot stand te brengen met behulp van een JSON-definitie, vult u de benodigde velden in en slaat u de volgende JSON-configuratie op schijf op:
Om een AWS Glue-verbindingsobject voor de Redshift-gegevensbron te maken, gebruikt u de volgende AWS CLI-opdracht:
Met deze opdracht wordt een verbinding in AWS Glue gemaakt die is gekoppeld aan uw Redshift-gegevensbron. Als de opdracht succesvol wordt uitgevoerd, kunt u uw Redshift-gegevensbron zien in het SageMaker Studio JupyterLab-notebook, klaar voor het uitvoeren van SQL-query's en het uitvoeren van gegevensanalyse.

Maak een Athena-verbinding
Athena is een volledig beheerde SQL-queryservice van AWS die analyse mogelijk maakt van gegevens die zijn opgeslagen in Amazon S3 met behulp van standaard SQL. Om een Athena-verbinding in te stellen als gegevensbron in de SQL-browser van het JupyterLab-notebook, moet u een Athena-voorbeeldverbindingsdefinitie-JSON maken. De volgende JSON-structuur configureert de noodzakelijke details om verbinding te maken met Athena, waarbij de gegevenscatalogus, de S3-stagingdirectory en de regio worden gespecificeerd:
Om een AWS Glue-verbindingsobject voor de Athena-gegevensbron te maken, gebruikt u de volgende AWS CLI-opdracht:
Als de opdracht succesvol is, hebt u rechtstreeks toegang tot de Athena-gegevenscatalogus en -tabellen vanuit de SQL-browser in uw SageMaker Studio JupyterLab-notebook.
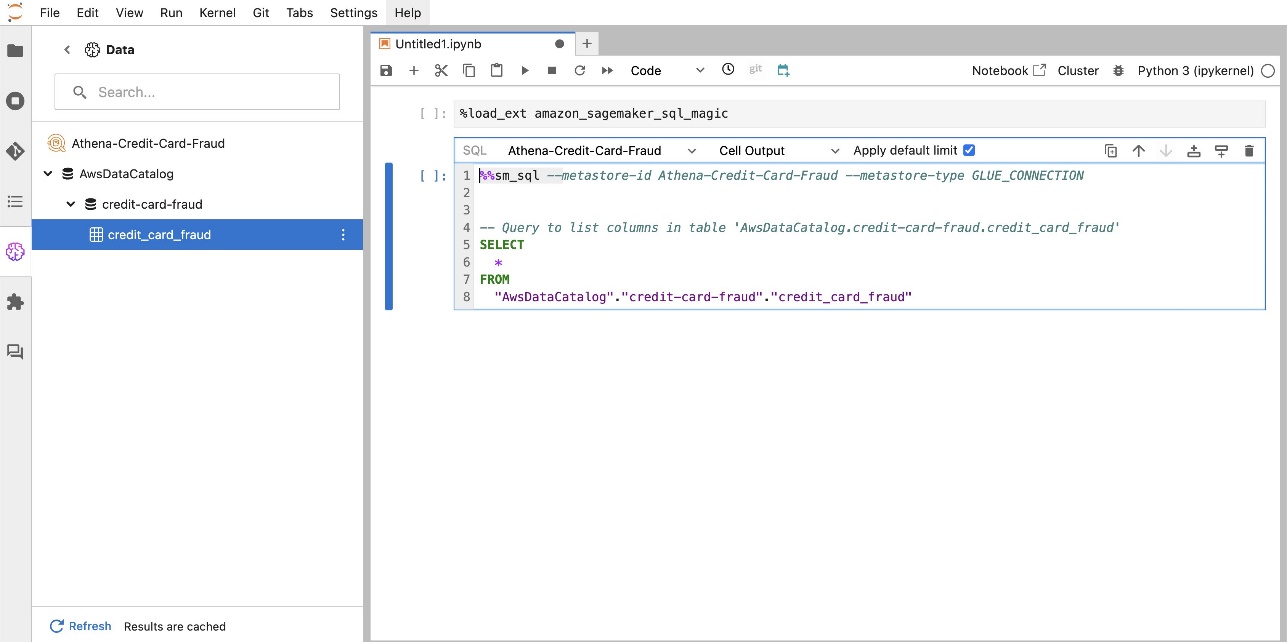
Gegevens opvragen uit meerdere bronnen
Als u meerdere gegevensbronnen in SageMaker Studio hebt geïntegreerd via de ingebouwde SQL-browser en de SQL-functie voor notebooks, kunt u snel query's uitvoeren en moeiteloos schakelen tussen backends van gegevensbronnen in daaropvolgende cellen binnen een notebook. Deze mogelijkheid zorgt voor naadloze overgangen tussen verschillende databases of gegevensbronnen tijdens uw analyseworkflow.
U kunt query's uitvoeren op een diverse verzameling backends van gegevensbronnen en de resultaten rechtstreeks naar de Python-ruimte brengen voor verdere analyse of visualisatie. Dit wordt gefaciliteerd door de %%sm_sql magische opdracht beschikbaar in SageMaker Studio-notebooks. Om de resultaten van uw SQL-query uit te voeren in een Pandas DataFrame, zijn er twee opties:
- Kies het uitvoertype in de celwerkbalk van uw notebook dataframe en geef uw DataFrame-variabele een naam
- Voeg de volgende parameter toe aan uw
%%sm_sqlopdracht:
Het volgende diagram illustreert deze werkstroom en laat zien hoe u moeiteloos query's kunt uitvoeren op verschillende bronnen in daaropvolgende notebookcellen, en hoe u een SageMaker-model kunt trainen met behulp van trainingstaken of rechtstreeks in de notebook met behulp van lokale rekenkracht. Bovendien laat het diagram zien hoe de ingebouwde SQL-integratie van SageMaker Studio de processen van extractie en bouwen rechtstreeks binnen de vertrouwde omgeving van een JupyterLab-notebookcel vereenvoudigt.
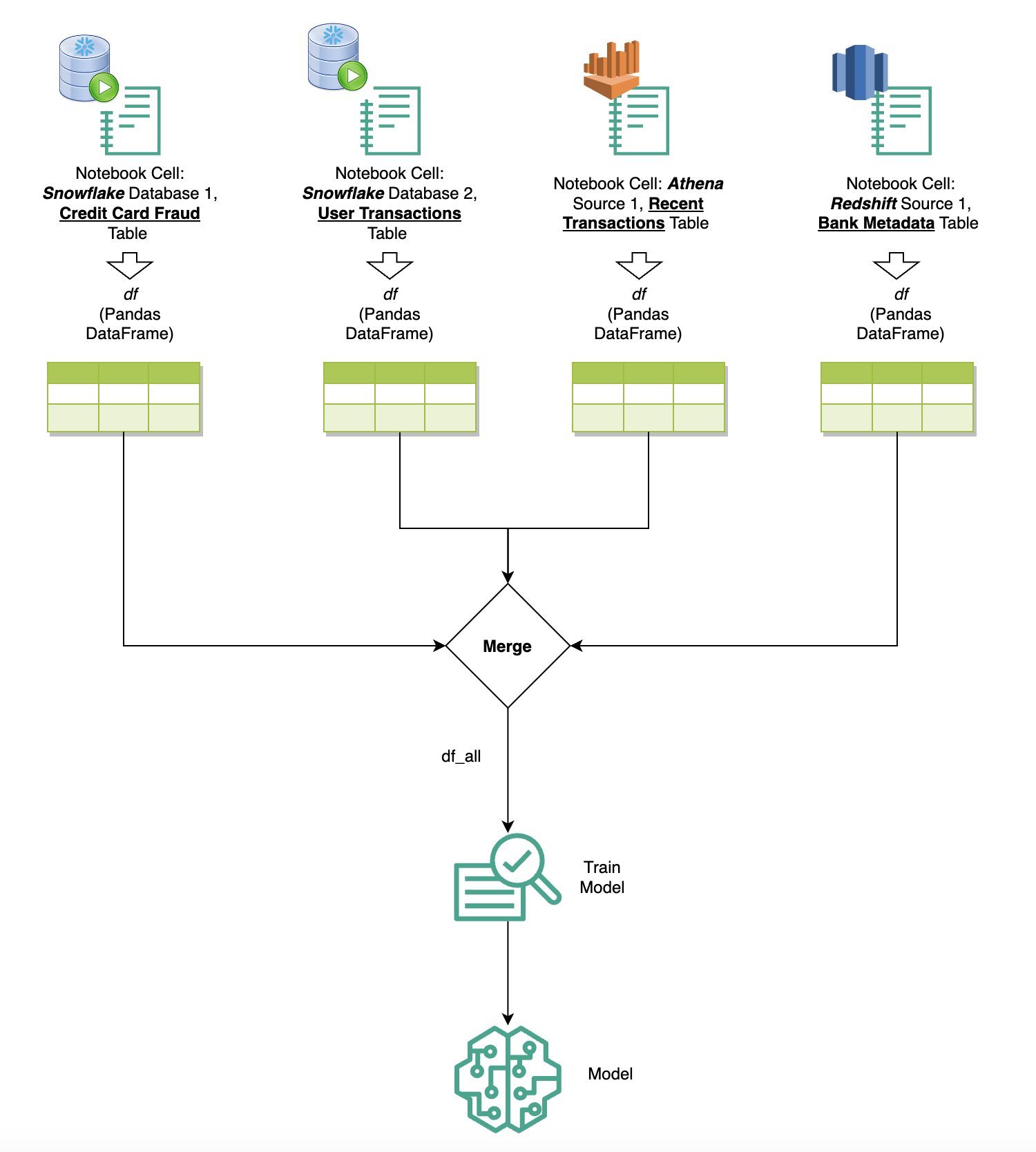
Tekst naar SQL: natuurlijke taal gebruiken om het schrijven van query's te verbeteren
SQL is een complexe taal die inzicht vereist in databases, tabellen, syntaxis en metadata. Tegenwoordig kan generatieve kunstmatige intelligentie (AI) u in staat stellen complexe SQL-query's te schrijven zonder dat u diepgaande SQL-ervaring nodig heeft. De vooruitgang van LLM's heeft een aanzienlijke invloed gehad op de op natuurlijke taalverwerking (NLP) gebaseerde SQL-generatie, waardoor nauwkeurige SQL-query's op basis van natuurlijke taalbeschrijvingen kunnen worden gemaakt - een techniek die Text-to-SQL wordt genoemd. Het is echter essentieel om de inherente verschillen tussen menselijke taal en SQL te erkennen. Menselijke taal kan soms dubbelzinnig of onnauwkeurig zijn, terwijl SQL gestructureerd, expliciet en ondubbelzinnig is. Het overbruggen van deze kloof en het nauwkeurig omzetten van natuurlijke taal in SQL-query's kan een enorme uitdaging vormen. Wanneer ze de juiste aanwijzingen krijgen, kunnen LLM's deze kloof helpen overbruggen door de bedoeling achter de menselijke taal te begrijpen en dienovereenkomstig nauwkeurige SQL-query's te genereren.
Met de release van de SageMaker Studio in-notebook SQL-queryfunctie maakt SageMaker Studio het eenvoudig om databases en schema's te inspecteren, en SQL-query's te schrijven, uit te voeren en te debuggen zonder ooit de Jupyter notebook IDE te verlaten. In deze sectie wordt onderzocht hoe de tekst-naar-SQL-mogelijkheden van geavanceerde LLM's het genereren van SQL-query's met behulp van natuurlijke taal binnen Jupyter-notebooks kunnen vergemakkelijken. We maken gebruik van het geavanceerde Text-to-SQL-model defog/sqlcoder-7b-2 in combinatie met Jupyter AI, een generatieve AI-assistent die speciaal is ontworpen voor Jupyter-notebooks, om complexe SQL-query's te maken op basis van natuurlijke taal. Door dit geavanceerde model te gebruiken, kunnen we moeiteloos en efficiënt complexe SQL-query's maken met behulp van natuurlijke taal, waardoor onze SQL-ervaring binnen notebooks wordt verbeterd.
Prototyping van notebooks met behulp van de Hugging Face Hub
Om met het prototypen te beginnen, hebt u het volgende nodig:
- GitHub-code – De code die in deze sectie wordt gepresenteerd, is als volgt beschikbaar GitHub repo en door te verwijzen naar de voorbeeld notebook.
- JupyterLab-ruimte – Toegang tot een SageMaker Studio JupyterLab Space ondersteund door GPU-gebaseerde instances is essentieel. Voor de
defog/sqlcoder-7b-2model wordt een 7B-parametermodel met behulp van een ml.g5.2xlarge-instantie aanbevolen. Alternatieven zoalsdefog/sqlcoder-70b-alpheen ofdefog/sqlcoder-34b-alphazijn ook haalbaar voor conversie van natuurlijke taal naar SQL, maar voor prototyping kunnen grotere instantietypen nodig zijn. Zorg ervoor dat u over het quotum beschikt om een door GPU ondersteund exemplaar te starten door naar de Service Quotas-console te navigeren, naar SageMaker te zoeken en te zoeken naarStudio JupyterLab Apps running on <instance type>.
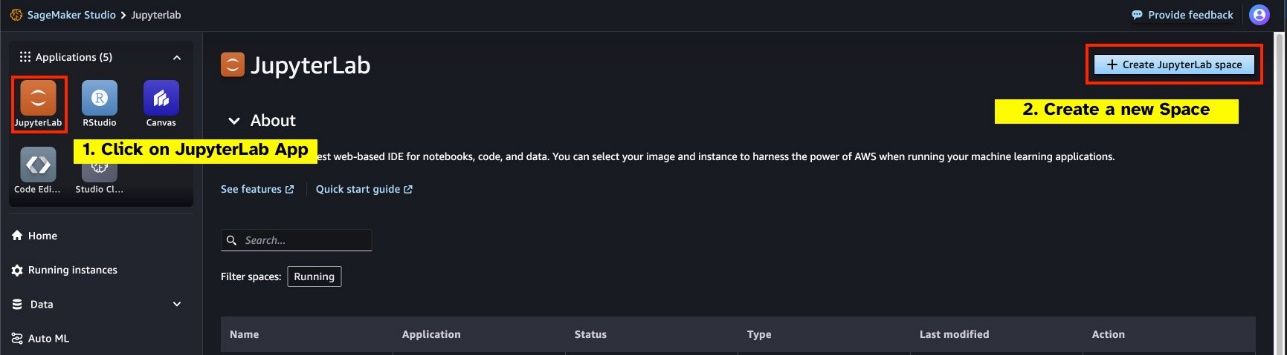
Start een nieuwe GPU-ondersteunde JupyterLab Space vanuit uw SageMaker Studio. Het wordt aanbevolen om een nieuwe JupyterLab Space te maken met minimaal 75 GB aan Amazon elastische blokwinkel (Amazon EBS) opslag voor een 7B-parametermodel.

- Knuffelen Gezicht Hub – Als uw SageMaker Studio-domein toegang heeft om modellen te downloaden van de Knuffelen Gezicht Hub, kunt u de
AutoModelForCausalLMklas van knuffelgezicht/transformatoren om modellen automatisch te downloaden en vast te zetten op uw lokale GPU's. De modelgewichten worden opgeslagen in de cache van uw lokale machine. Zie de volgende code:
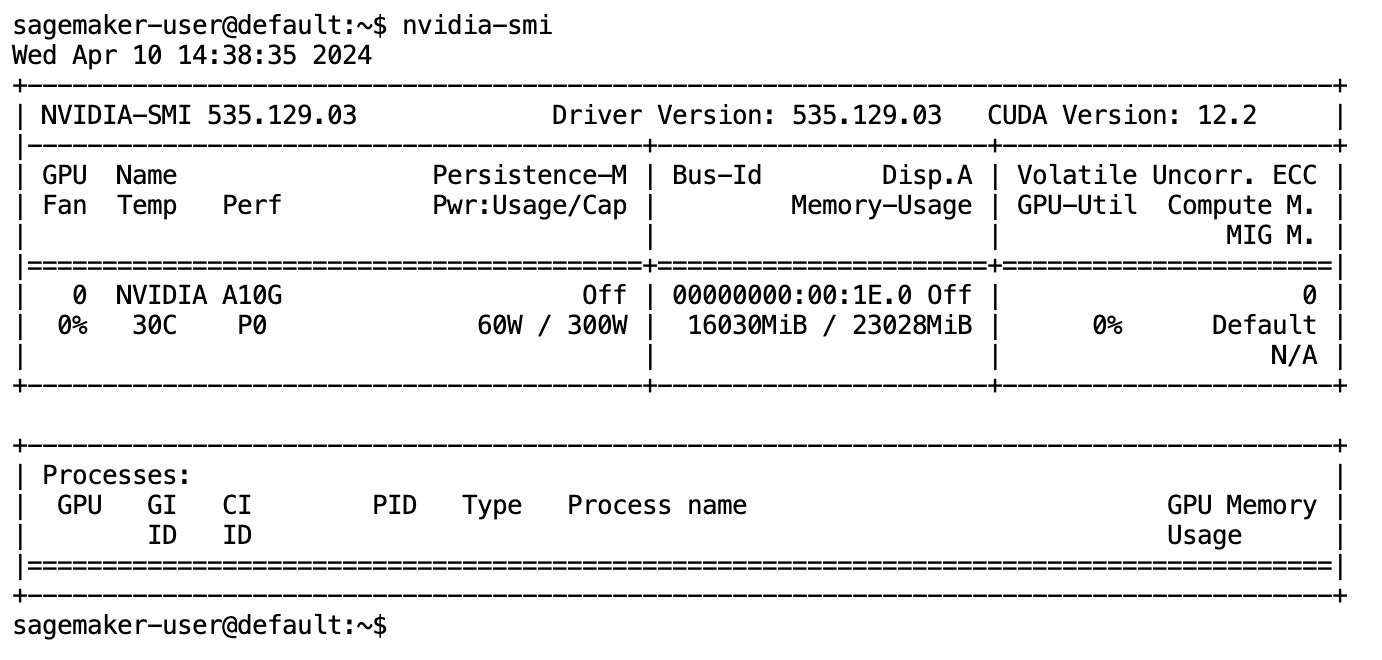
Nadat het model volledig is gedownload en in het geheugen is geladen, zou u een toename in het GPU-gebruik op uw lokale computer moeten waarnemen. Dit geeft aan dat het model de GPU-bronnen actief gebruikt voor rekentaken. U kunt dit in uw eigen JupyterLab-ruimte verifiëren door uit te voeren nvidia-smi (voor een eenmalige weergave) of nvidia-smi —loop=1 (om elke seconde te herhalen) vanaf uw JupyterLab-terminal.
Tekst-naar-SQL-modellen blinken uit in het begrijpen van de intentie en context van het verzoek van een gebruiker, zelfs als de gebruikte taal conversatie of dubbelzinnig is. Het proces omvat het vertalen van natuurlijke taalinvoer naar de juiste databaseschema-elementen, zoals tabelnamen, kolomnamen en voorwaarden. Een kant-en-klaar tekst-naar-SQL-model kent echter niet inherent de structuur van uw datawarehouse en de specifieke databaseschema's, of is niet in staat om de inhoud van een tabel nauwkeurig te interpreteren uitsluitend op basis van kolomnamen. Om deze modellen effectief te kunnen gebruiken om praktische en efficiënte SQL-query's uit natuurlijke taal te genereren, is het noodzakelijk om het SQL-tekstgeneratiemodel aan te passen aan uw specifieke magazijndatabaseschema. Deze aanpassing wordt vergemakkelijkt door het gebruik van LLM-prompts. Het volgende is een aanbevolen promptsjabloon voor het defog/sqlcoder-7b-2 tekst-naar-SQL-model, verdeeld in vier delen:
- Taak – In deze sectie moet een taak op hoog niveau worden gespecificeerd die door het model moet worden uitgevoerd. Het moet het type database-backend bevatten (zoals Amazon RDS, PostgreSQL of Amazon Redshift) om het model bewust te maken van eventuele genuanceerde syntactische verschillen die van invloed kunnen zijn op het genereren van de uiteindelijke SQL-query.
- Instructies – Deze sectie moet taakgrenzen en domeinbewustzijn voor het model definiëren, en kan enkele voorbeelden bevatten om het model te begeleiden bij het genereren van nauwkeurig afgestemde SQL-query's.
- Database schema – In deze sectie moeten de schema's van uw magazijndatabase gedetailleerd worden beschreven, waarbij de relaties tussen tabellen en kolommen worden beschreven om het model te helpen de databasestructuur te begrijpen.
- Antwoord – Deze sectie is gereserveerd voor het model om het SQL-queryantwoord uit te voeren op de natuurlijke taalinvoer.
Een voorbeeld van het databaseschema en de prompt die in deze sectie worden gebruikt, is beschikbaar in de GitHub-opslagplaats.
Prompt engineering gaat niet alleen over het formuleren van vragen of uitspraken; het is een genuanceerde kunst en wetenschap die een aanzienlijke invloed heeft op de kwaliteit van interacties met een AI-model. De manier waarop u een prompt maakt, kan de aard en het nut van de reactie van de AI diepgaand beïnvloeden. Deze vaardigheid is van cruciaal belang bij het maximaliseren van het potentieel van AI-interacties, vooral bij complexe taken die gespecialiseerd begrip en gedetailleerde antwoorden vereisen.
Het is belangrijk om de mogelijkheid te hebben om snel de respons van een model voor een bepaalde prompt te bouwen en te testen, en de prompt te optimaliseren op basis van de respons. JupyterLab-notebooks bieden de mogelijkheid om direct modelfeedback te ontvangen van een model dat op lokale rekenkracht draait, en de prompt te optimaliseren en de reactie van een model verder af te stemmen of een model volledig te wijzigen. In dit bericht gebruiken we een SageMaker Studio JupyterLab-notebook, ondersteund door de NVIDIA A5.2G 10 GB GPU van ml.g24xlarge om tekst-naar-SQL-modelinferentie op de notebook uit te voeren en interactief onze modelprompt te bouwen totdat de reactie van het model voldoende is afgestemd om te voorzien antwoorden die direct uitvoerbaar zijn in de SQL-cellen van JupyterLab. Om modelinferentie uit te voeren en tegelijkertijd modelreacties te streamen, gebruiken we een combinatie van model.generate en TextIteratorStreamer zoals gedefinieerd in de volgende code:
De uitvoer van het model kan worden versierd met SageMaker SQL-magie %%sm_sql ..., waarmee het JupyterLab-notebook de cel kan identificeren als een SQL-cel.
Host tekst-naar-SQL-modellen als SageMaker-eindpunten
Aan het einde van de prototypefase hebben we onze favoriete Text-to-SQL LLM geselecteerd, een effectief promptformaat en een geschikt instancetype voor het hosten van het model (enkele GPU of meerdere GPU's). SageMaker vergemakkelijkt de schaalbare hosting van aangepaste modellen door het gebruik van SageMaker-eindpunten. Deze eindpunten kunnen worden gedefinieerd op basis van specifieke criteria, waardoor de inzet van LLM's als eindpunten mogelijk wordt gemaakt. Met deze mogelijkheid kunt u de oplossing opschalen naar een breder publiek, waardoor gebruikers SQL-query's kunnen genereren op basis van natuurlijke taalinvoer met behulp van op maat gehoste LLM's. Het volgende diagram illustreert deze architectuur.

Om uw LLM als SageMaker-eindpunt te hosten, genereert u verschillende artefacten.
Het eerste artefact zijn modelgewichten. SageMaker Deep Java Library (DJL) Serving Met containers kunt u configuraties instellen via een meta serveren.eigenschappen -bestand, waarmee u kunt bepalen hoe modellen worden verkregen - rechtstreeks vanuit de Hugging Face Hub of door modelartefacten te downloaden van Amazon S3. Als u specificeert model_id=defog/sqlcoder-7b-2, zal DJL Serving proberen dit model rechtstreeks te downloaden van de Hugging Face Hub. Elke keer dat het eindpunt wordt geïmplementeerd of elastisch wordt geschaald, kunnen er echter kosten voor inkomend/uitgaand netwerkverkeer in rekening worden gebracht. Om deze kosten te vermijden en mogelijk het downloaden van modelartefacten te versnellen, wordt aanbevolen het gebruik over te slaan model_id in serving.properties en sla modelgewichten op als S3-artefacten en specificeer ze alleen met s3url=s3://path/to/model/bin.
Het opslaan van een model (met zijn tokenizer) op schijf en het uploaden naar Amazon S3 kan worden bereikt met slechts een paar regels code:
U gebruikt ook een databasepromptbestand. In deze opstelling bestaat de databaseprompt uit Task, Instructions, Database Schema en Answer sections. Voor de huidige architectuur wijzen we voor elk databaseschema een afzonderlijk promptbestand toe. Er is echter flexibiliteit om deze configuratie uit te breiden en meerdere databases per promptbestand op te nemen, waardoor het model samengestelde joins tussen databases op dezelfde server kan uitvoeren. Tijdens onze prototypefase slaan we de databaseprompt op als een tekstbestand met de naam <Database-Glue-Connection-Name>.prompt, Waar Database-Glue-Connection-Name komt overeen met de verbindingsnaam die zichtbaar is in uw JupyterLab-omgeving. Dit bericht verwijst bijvoorbeeld naar een Snowflake-verbinding met de naam Airlines_Dataset, dus het databasepromptbestand krijgt de naam Airlines_Dataset.prompt. Dit bestand wordt vervolgens opgeslagen op Amazon S3 en vervolgens gelezen en in de cache opgeslagen door onze modelservinglogica.
Bovendien maakt deze architectuur het voor alle geautoriseerde gebruikers van dit eindpunt mogelijk om natuurlijke taal-naar-SQL-query's te definiëren, op te slaan en te genereren zonder de noodzaak van meerdere herimplementaties van het model. Wij gebruiken het volgende voorbeeld van een databaseprompt om de Text-to-SQL-functionaliteit te demonstreren.
Vervolgens genereert u aangepaste modelservicelogica. In deze sectie schetst u een aangepaste gevolgtrekkingslogica met de naam model.py. Dit script is ontworpen om de prestaties en integratie van onze Text-to-SQL-services te optimaliseren:
- Definieer de logica voor het cachen van databasepromptbestanden – Om de latentie te minimaliseren, implementeren we een aangepaste logica voor het downloaden en cachen van databasepromptbestanden. Dit mechanisme zorgt ervoor dat prompts direct beschikbaar zijn, waardoor de overhead die gepaard gaat met frequente downloads wordt verminderd.
- Definieer logica voor aangepaste modelinferentie – Om de inferentiesnelheid te verbeteren, wordt ons tekst-naar-SQL-model geladen in het float16-precisieformaat en vervolgens omgezet in een DeepSpeed-model. Deze stap maakt een efficiëntere berekening mogelijk. Bovendien specificeert u binnen deze logica welke parameters gebruikers kunnen aanpassen tijdens inferentieoproepen om de functionaliteit aan te passen aan hun behoeften.
- Definieer aangepaste invoer- en uitvoerlogica – Het opzetten van duidelijke en aangepaste invoer-/uitvoerformaten is essentieel voor een soepele integratie met downstream-applicaties. Eén zo'n toepassing is JupyterAI, die we in de volgende sectie bespreken.
Daarnaast nemen we onder meer een serving.properties bestand, dat fungeert als een globaal configuratiebestand voor modellen die worden gehost met behulp van DJL-serving. Voor meer informatie, zie Configuraties en instellingen.
Tenslotte kunt u ook een requirements.txt bestand om aanvullende modules te definiëren die nodig zijn voor gevolgtrekking en alles in een tarball te verpakken voor implementatie.
Zie de volgende code:
Integreer uw eindpunt met de SageMaker Studio Jupyter AI-assistent
Jupyter AI is een open source-tool die generatieve AI naar Jupyter-notebooks brengt en een robuust en gebruiksvriendelijk platform biedt voor het verkennen van generatieve AI-modellen. Het verbetert de productiviteit in JupyterLab en Jupyter-notebooks door functies te bieden zoals de %%ai-magie voor het creëren van een generatieve AI-speeltuin in notebooks, een native chat-UI in JupyterLab voor interactie met AI als gespreksassistent, en ondersteuning voor een breed scala aan LLM's van aanbieders zoals Amazone Titan, AI21, Anthropic, Cohere en Hugging Face of beheerde services zoals Amazonebodem en SageMaker-eindpunten. Voor dit bericht gebruiken we de kant-en-klare integratie van Jupyter AI met SageMaker-eindpunten om de tekst-naar-SQL-mogelijkheden in JupyterLab-notebooks te brengen. De Jupyter AI-tool is vooraf geïnstalleerd in alle SageMaker Studio JupyterLab Spaces, ondersteund door SageMaker Distributie-afbeeldingen; eindgebruikers hoeven geen aanvullende configuraties uit te voeren om de Jupyter AI-extensie te gaan gebruiken voor integratie met een door SageMaker gehost eindpunt. In deze sectie bespreken we de twee manieren om de geïntegreerde Jupyter AI-tool te gebruiken.
Jupyter AI in een notebook met behulp van magie
Jupyter AI's %%ai Met magic command kunt u uw SageMaker Studio JupyterLab-notebooks transformeren in een reproduceerbare generatieve AI-omgeving. Om AI-magie te gaan gebruiken, moet je ervoor zorgen dat je de jupyter_ai_magics-extensie hebt geladen die je wilt gebruiken %%ai magie, en bovendien laden amazon_sagemaker_sql_magic gebruiken %%sm_sql magie:
Als u vanaf uw notebook een oproep naar uw SageMaker-eindpunt wilt uitvoeren met behulp van de %%ai magic-opdracht, geef de volgende parameters op en structureer de opdracht als volgt:
- –regionaam – Geef de regio op waar uw eindpunt wordt geïmplementeerd. Dit zorgt ervoor dat het verzoek naar de juiste geografische locatie wordt doorgestuurd.
- –verzoekschema – Voeg het schema van de invoergegevens toe. Dit schema schetst de verwachte indeling en typen invoergegevens die uw model nodig heeft om de aanvraag te verwerken.
- –reactiepad – Definieer het pad binnen het responsobject waar de uitvoer van uw model zich bevindt. Dit pad wordt gebruikt om de relevante gegevens te extraheren uit het antwoord dat door uw model wordt geretourneerd.
- -f (optioneel) - Dit is een uitvoerformatter vlag die het type uitvoer aangeeft dat door het model wordt geretourneerd. Als de uitvoer in de context van een Jupyter-notebook code is, moet deze vlag dienovereenkomstig worden ingesteld om de uitvoer op te maken als uitvoerbare code bovenaan een Jupyter-notebookcel, gevolgd door een invoergebied voor vrije tekst voor gebruikersinteractie.
De opdracht in een Jupyter-notebookcel kan er bijvoorbeeld als volgt uitzien:
Jupyter AI-chatvenster
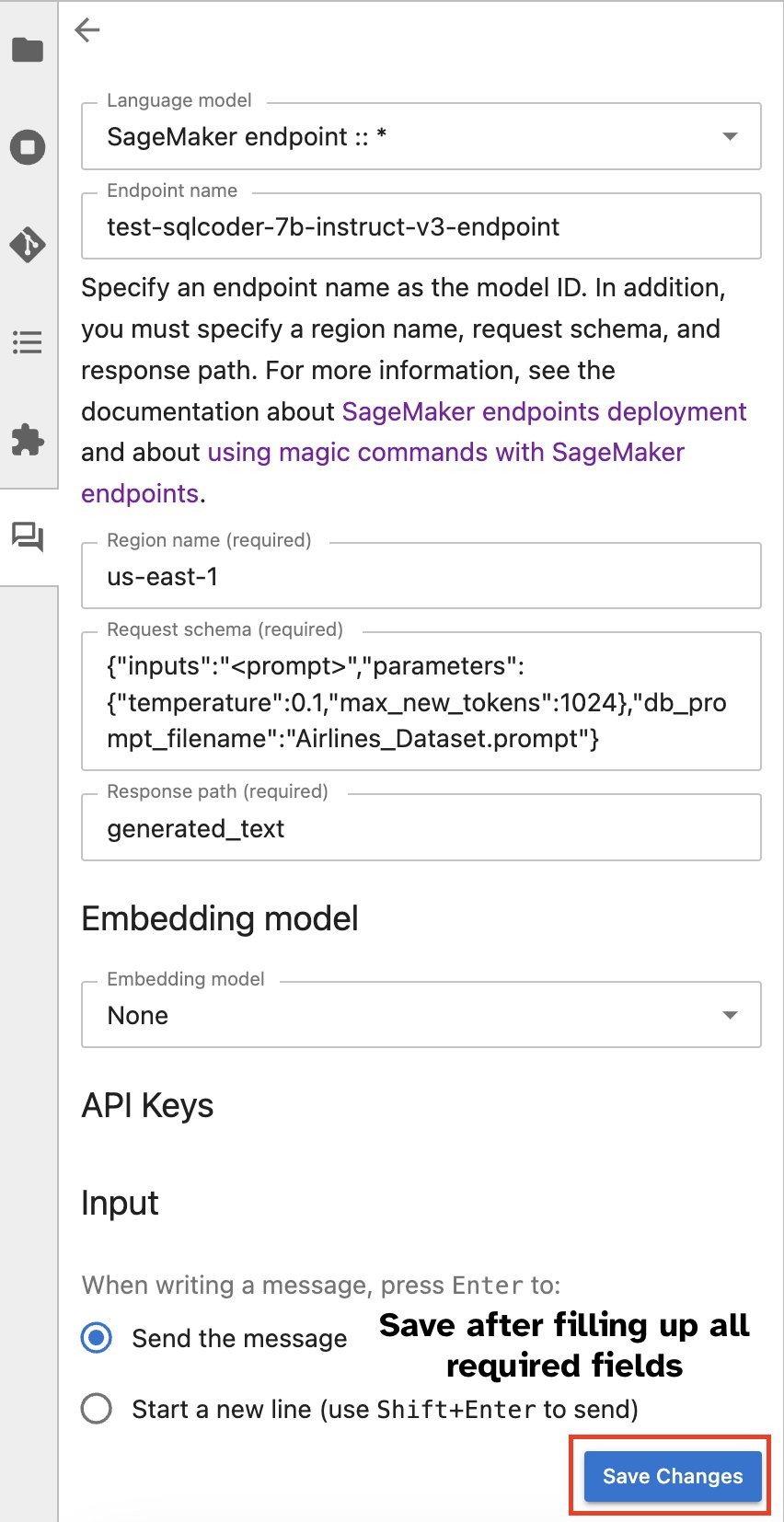
Als alternatief kunt u communiceren met SageMaker-eindpunten via een ingebouwde gebruikersinterface, waardoor het proces van het genereren van zoekopdrachten of het aangaan van een dialoog wordt vereenvoudigd. Voordat u begint met chatten met uw SageMaker-eindpunt, configureert u de relevante instellingen in Jupyter AI voor het SageMaker-eindpunt, zoals weergegeven in de volgende schermafbeelding.
 |
 |
Conclusie
SageMaker Studio vereenvoudigt en stroomlijnt nu de datawetenschapperworkflow door SQL-ondersteuning te integreren in JupyterLab-notebooks. Hierdoor kunnen datawetenschappers zich concentreren op hun taken zonder dat ze meerdere tools hoeven te beheren. Bovendien zorgt de nieuwe ingebouwde SQL-integratie in SageMaker Studio ervoor dat datapersona's moeiteloos SQL-query's kunnen genereren met tekst in natuurlijke taal als invoer, waardoor hun workflow wordt versneld.
We raden u aan deze functies in SageMaker Studio te verkennen. Voor meer informatie, zie Bereid gegevens voor met SQL in Studio.
Bijlage
Schakel de SQL-browser en de SQL-cel van de notebook in aangepaste omgevingen in
Als u geen SageMaker Distribution-image of Distribution-images 1.5 of lager gebruikt, voert u de volgende opdrachten uit om de SQL-browsingfunctie in uw JupyterLab-omgeving in te schakelen:
Verplaats de SQL-browserwidget
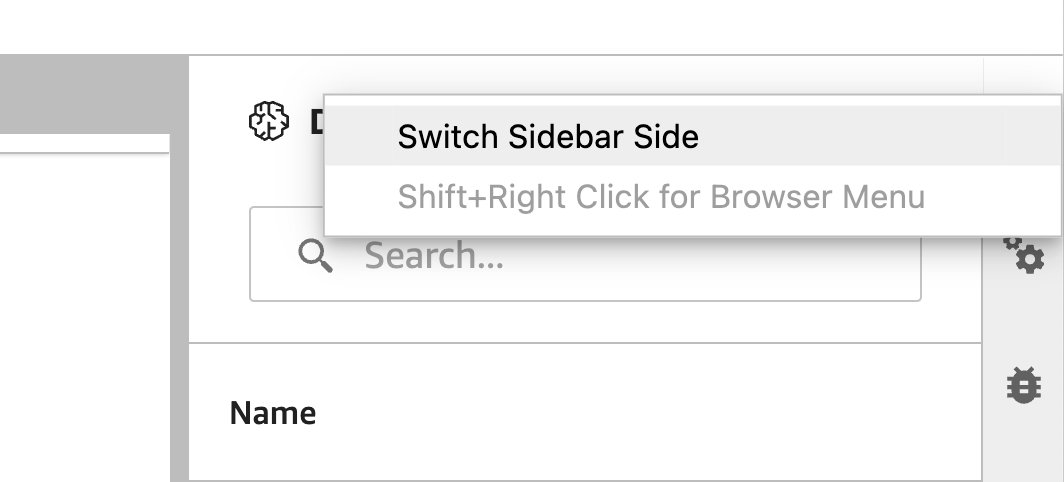
JupyterLab-widgets maken verplaatsing mogelijk. Afhankelijk van uw voorkeur kunt u widgets naar beide zijden van het JupyterLab-widgetvenster verplaatsen. Als u wilt, kunt u de richting van de SQL-widget naar de andere kant (van rechts naar links) van de zijbalk verplaatsen door eenvoudig met de rechtermuisknop op het widgetpictogram te klikken en te kiezen Zijbalkzijde wijzigen.
 |
 |
Over de auteurs
 Pranav Murthy is een AI/ML Specialist Solutions Architect bij AWS. Hij richt zich op het helpen van klanten bij het bouwen, trainen, implementeren en migreren van machine learning (ML)-workloads naar SageMaker. Hij werkte eerder in de halfgeleiderindustrie en ontwikkelde grote computer vision (CV) en natuurlijke taalverwerkingsmodellen (NLP) om halfgeleiderprocessen te verbeteren met behulp van de modernste ML-technieken. In zijn vrije tijd houdt hij van schaken en reizen. Je kunt Pranav vinden op LinkedIn.
Pranav Murthy is een AI/ML Specialist Solutions Architect bij AWS. Hij richt zich op het helpen van klanten bij het bouwen, trainen, implementeren en migreren van machine learning (ML)-workloads naar SageMaker. Hij werkte eerder in de halfgeleiderindustrie en ontwikkelde grote computer vision (CV) en natuurlijke taalverwerkingsmodellen (NLP) om halfgeleiderprocessen te verbeteren met behulp van de modernste ML-technieken. In zijn vrije tijd houdt hij van schaken en reizen. Je kunt Pranav vinden op LinkedIn.
 Varun Sjah is een software-ingenieur die werkt aan Amazon SageMaker Studio bij Amazon Web Services. Hij richt zich op het bouwen van interactieve ML-oplossingen die de gegevensverwerking en gegevensvoorbereiding vereenvoudigen. In zijn vrije tijd houdt Varun van buitenactiviteiten zoals wandelen en skiën, en is hij altijd in voor het ontdekken van nieuwe, opwindende plekken.
Varun Sjah is een software-ingenieur die werkt aan Amazon SageMaker Studio bij Amazon Web Services. Hij richt zich op het bouwen van interactieve ML-oplossingen die de gegevensverwerking en gegevensvoorbereiding vereenvoudigen. In zijn vrije tijd houdt Varun van buitenactiviteiten zoals wandelen en skiën, en is hij altijd in voor het ontdekken van nieuwe, opwindende plekken.
 Sumedha Swamy is Principal Product Manager bij Amazon Web Services, waar hij het SageMaker Studio-team leidt in zijn missie om de favoriete IDE voor datawetenschap en machinaal leren te ontwikkelen. Hij heeft zich de afgelopen 15 jaar gewijd aan het bouwen van op Machine Learning gebaseerde consumenten- en bedrijfsproducten.
Sumedha Swamy is Principal Product Manager bij Amazon Web Services, waar hij het SageMaker Studio-team leidt in zijn missie om de favoriete IDE voor datawetenschap en machinaal leren te ontwikkelen. Hij heeft zich de afgelopen 15 jaar gewijd aan het bouwen van op Machine Learning gebaseerde consumenten- en bedrijfsproducten.
 Bosco Albuquerque is een Sr. Partner Solutions Architect bij AWS en heeft meer dan 20 jaar ervaring in het werken met database- en analyseproducten van leveranciers van bedrijfsdatabases en cloudproviders. Hij heeft technologiebedrijven geholpen bij het ontwerpen en implementeren van oplossingen en producten voor data-analyse.
Bosco Albuquerque is een Sr. Partner Solutions Architect bij AWS en heeft meer dan 20 jaar ervaring in het werken met database- en analyseproducten van leveranciers van bedrijfsdatabases en cloudproviders. Hij heeft technologiebedrijven geholpen bij het ontwerpen en implementeren van oplossingen en producten voor data-analyse.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

