Het uitbouwen van een Machine Learning Operations (MLOps)-platform in het snel evoluerende landschap van kunstmatige intelligentie (AI) en machine learning (ML) voor organisaties is essentieel voor het naadloos overbruggen van de kloof tussen data science-experimenten en -implementatie en tegelijkertijd voldoen aan de vereisten rond modelprestaties. veiligheid en naleving.
Om aan de regelgevings- en nalevingsvereisten te voldoen, zijn de belangrijkste vereisten bij het ontwerpen van een dergelijk platform:
- Adresgegevensdrift
- Bewaak de modelprestaties
- Faciliteer automatische modelherscholing
- Zorg voor een proces voor modelgoedkeuring
- Bewaar modellen in een beveiligde omgeving
In dit bericht laten we zien hoe u een MLOps-framework kunt creëren om aan deze behoeften te voldoen, terwijl u een combinatie van AWS-services en toolsets van derden gebruikt. De oplossing omvat een opstelling voor meerdere omgevingen met geautomatiseerde modelhertraining, batch-inferentie en monitoring met Amazon SageMaker-modelmonitor, modelversiebeheer met SageMaker-modelregisteren een CI/CD-pijplijn om de promotie van ML-code en pijplijnen in verschillende omgevingen te vergemakkelijken met behulp van Amazon Sage Maker, Amazon EventBridge, Amazon eenvoudige meldingsservice (Amazone S3), HashiCorp Terraform, GitHub en Jenkins CI/CD. We bouwen een model om de ernst (goedaardig of kwaadaardig) te voorspellen van een mammografische massalaesie die is getraind met de XGBoost-algoritme gebruik maken van het publiek beschikbare UCI Mammografie Massa dataset en implementeer deze met behulp van het MLOps-framework. De volledige instructies met code zijn beschikbaar in de GitHub-repository.
Overzicht oplossingen
Het volgende architectuurdiagram toont een overzicht van het MLOps-framework met de volgende belangrijke componenten:
- Strategie voor meerdere accounts – Er worden twee verschillende omgevingen (dev en prod) opgezet in twee verschillende AWS-accounts volgens de AWS Well-Architected best practices, en een derde account wordt opgezet in het centrale modelregister:
- Dev-omgeving – Waar een Amazon SageMaker Studio-domein is opgezet om modelontwikkeling, modeltraining en het testen van ML-pijplijnen (trein en inferentie) mogelijk te maken, voordat een model klaar is om te worden gepromoveerd naar hogere omgevingen.
- Prod-omgeving – Waar de ML-pijplijnen van dev worden gepromoveerd tot een eerste stap, en in de loop van de tijd worden gepland en gemonitord.
- Centraal modelregister - Amazon SageMaker-modelregister is ingesteld in een afzonderlijk AWS-account om modelversies bij te houden die in de dev- en prod-omgevingen zijn gegenereerd.
- CI/CD en broncontrole – De implementatie van ML-pijplijnen in verschillende omgevingen wordt afgehandeld via CI/CD die is opgezet met Jenkins, terwijl versiebeheer wordt afgehandeld via GitHub. Codewijzigingen samengevoegd met de corresponderende git branch van de omgeving activeren een CI/CD-workflow om de juiste wijzigingen aan te brengen in de gegeven doelomgeving.
- Batch-voorspellingen met modelmonitoring – De inferentiepijplijn gebouwd met Amazon SageMaker-pijpleidingen draait op een geplande basis om voorspellingen te genereren, samen met modelmonitoring met behulp van SageMaker Model Monitor om gegevensdrift te detecteren.
- Geautomatiseerd omscholingsmechanisme – De trainingspijplijn die is gebouwd met SageMaker Pipelines wordt geactiveerd wanneer er een gegevensdrift wordt gedetecteerd in de gevolgtrekkingspijplijn. Nadat het is getraind, wordt het model geregistreerd in het centrale modelregister, zodat het kan worden goedgekeurd door een modelgoedkeurder. Wanneer deze is goedgekeurd, wordt de bijgewerkte modelversie gebruikt om voorspellingen te genereren via de gevolgtrekkingspijplijn.
- Infrastructuur als code – De infrastructuur als code (IaC), gemaakt met behulp van HashiCorp Terraform, ondersteunt de planning van de gevolgtrekkingspijplijn met EventBridge, waardoor de treinpijplijn wordt geactiveerd op basis van een EventBridge-regel en het verzenden van meldingen met behulp van Amazon eenvoudige meldingsservice (Amazone SNS) onderwerpen.
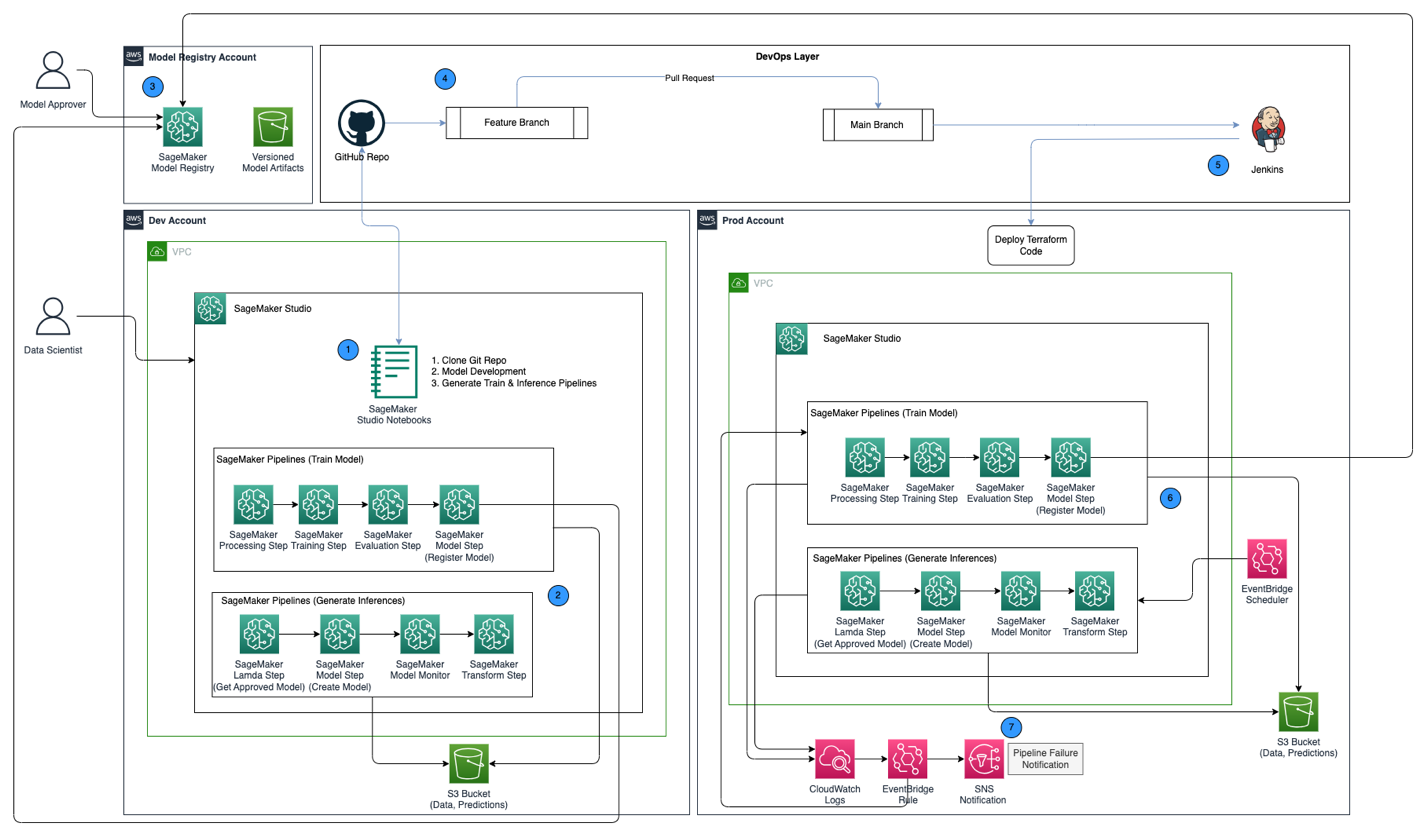
De MLOps-workflow omvat de volgende stappen:
- Krijg toegang tot het SageMaker Studio-domein in het ontwikkelingsaccount, kloon de GitHub-repository, doorloop het proces van modelontwikkeling met behulp van het meegeleverde voorbeeldmodel en genereer de trein- en inferentiepijplijnen.
- Voer de treinpijplijn uit in het ontwikkelingsaccount, dat de modelartefacten genereert voor de getrainde modelversie en het model registreert in SageMaker Model Registry in het centrale modelregisteraccount.
- Keur het model goed in SageMaker Model Registry in het centrale modelregisteraccount.
- Push de code (trein- en inferentiepijplijnen en de Terraform IaC-code om het EventBridge-schema, de EventBridge-regel en het SNS-onderwerp te maken) naar een functievertakking van de GitHub-opslagplaats. Maak een pull-aanvraag om de code samen te voegen met de hoofdtak van de GitHub-repository.
- Activeer de Jenkins CI/CD-pijplijn, die is ingesteld met de GitHub-opslagplaats. De CI/CD-pijplijn implementeert de code in het prod-account om de trein- en inferentiepijplijnen te maken, samen met Terraform-code om het EventBridge-schema, de EventBridge-regel en het SNS-onderwerp in te richten.
- De inferentiepijplijn is gepland om dagelijks te draaien, terwijl de treinpijplijn is ingesteld om te draaien wanneer er gegevensdrift wordt gedetecteerd uit de inferentiepijplijn.
- Meldingen worden via het SNS-onderwerp verzonden wanneer er een fout optreedt in de trein- of inferentiepijplijn.
Voorwaarden
Voor deze oplossing moet u aan de volgende vereisten voldoen:
- Drie AWS-accounts (dev-, prod- en centrale modelregisteraccounts)
- Een SageMaker Studio-domein ingesteld in elk van de drie AWS-accounts (zie Aan boord van Amazon SageMaker Studio of bekijk de video Ga snel aan boord van Amazon SageMaker Studio voor installatie-instructies)
- Jenkins (we gebruiken Jenkins 2.401.1) met beheerdersrechten geïnstalleerd op AWS
- Terraform versie 1.5.5 of hoger geïnstalleerd op de Jenkins-server
Voor deze functie werken wij in de us-east-1 Regio waar de oplossing moet worden geïmplementeerd.
KMS-sleutels inrichten in ontwikkelaars- en prod-accounts
Onze eerste stap is creëren AWS Sleutelbeheerservice (AWS KMS)-sleutels in de dev- en prod-accounts.
Maak een KMS-sleutel in het ontwikkelaarsaccount en geef toegang tot het prod-account
Voer de volgende stappen uit om een KMS-sleutel in het ontwikkelaarsaccount te maken:
- Kies op de AWS KMS-console Door de klant beheerde sleutels in het navigatievenster.
- Kies Sleutel maken.
- Voor Sleutel typeselecteer Symmetrisch.
- Voor Sleutelgebruikselecteer Coderen en decoderen.
- Kies Volgende.
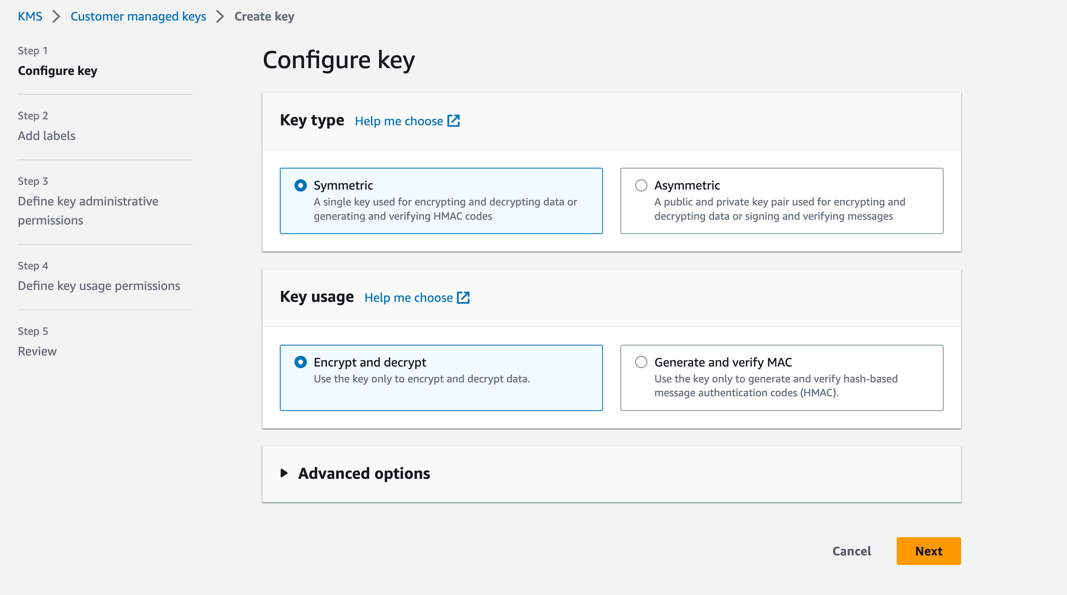
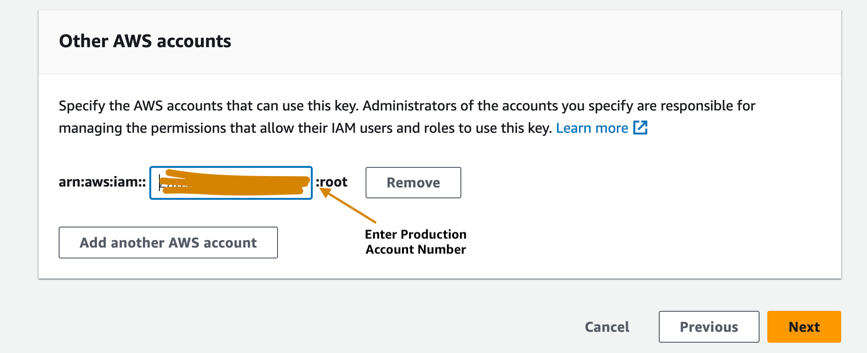
- Voer het productieaccountnummer in om het productieaccount toegang te geven tot de KMS-sleutel die is ingericht in het ontwikkelaarsaccount. Dit is een vereiste stap omdat de modelartefacten de eerste keer dat het model in het ontwikkelaarsaccount wordt getraind, worden gecodeerd met de KMS-sleutel voordat ze naar de S3-bucket in het centrale modelregisteraccount worden geschreven. Het productieaccount heeft toegang nodig tot de KMS-sleutel om de modelartefacten te ontsleutelen en de gevolgtrekkingspijplijn uit te voeren.
- Kies Volgende en voltooi het maken van uw sleutel.
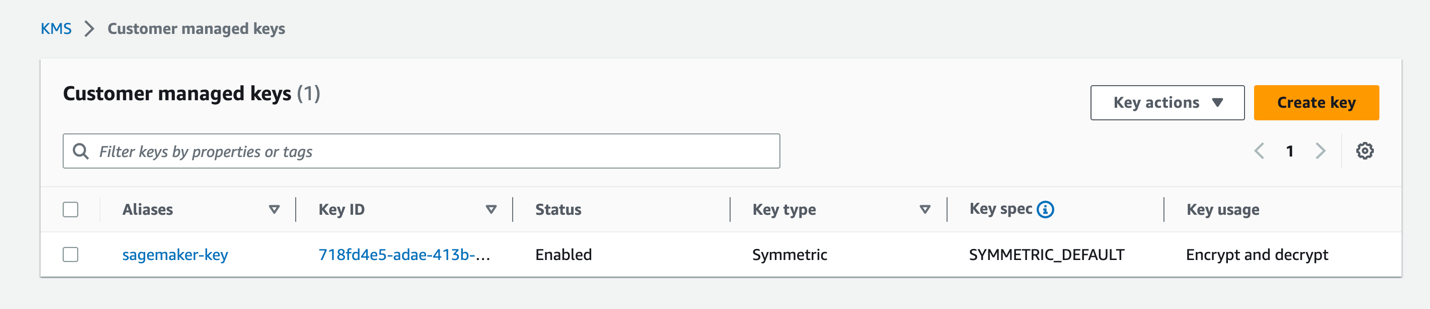
Nadat de sleutel is ingericht, zou deze zichtbaar moeten zijn op de AWS KMS-console.
Maak een KMS-sleutel in het prod-account
Doorloop dezelfde stappen in de vorige sectie om een door de klant beheerde KMS-sleutel in het prod-account te maken. U kunt de stap overslaan om de KMS-sleutel met een ander account te delen.
Stel een S3-bucket voor modelartefacten in het centrale modelregisteraccount in
Maak met het touwtje een S3-bucket naar keuze sagemaker in de naamgevingsconventie als onderdeel van de naam van de bucket in het centrale modelregisteraccount, en werk het bucketbeleid op de S3-bucket bij om machtigingen te geven aan zowel de dev- als de prod-accounts om modelartefacten in de S3-bucket te lezen en te schrijven.
De volgende code is het bucketbeleid dat moet worden bijgewerkt op de S3-bucket:
Stel IAM-rollen in uw AWS-accounts in
De volgende stap is het opzetten AWS Identiteits- en toegangsbeheer (IAM)-rollen in uw AWS-accounts met machtigingen voor AWS Lambda, SageMaker en Jenkins.
Lambda uitvoeringsrol
Instellen Lambda-uitvoeringsrollen in de dev- en prod-accounts, die zullen worden gebruikt door de Lambda-functie die wordt uitgevoerd als onderdeel van de SageMaker Pipelines Lambda-stap. Deze stap wordt uitgevoerd vanuit de gevolgtrekkingspijplijn om het nieuwste goedgekeurde model op te halen, op basis van welke gevolgtrekkingen worden gegenereerd. Maak IAM-rollen in de dev- en prod-accounts met de naamgevingsconventie arn:aws:iam::<account-id>:role/lambda-sagemaker-role en voeg het volgende IAM-beleid toe:
- Beleid 1 – Maak een inline-beleid met de naam
cross-account-model-registry-access, die toegang geeft tot het modelpakket dat is ingesteld in het modelregister in het centrale account: - Beleid 2 - Bijvoegen AmazonSageMakerFullAccess, dat is een Door AWS beheerd beleid dat volledige toegang verleent tot SageMaker. Het biedt ook geselecteerde toegang tot gerelateerde services, zoals Automatisch schalen van AWS-toepassing, Amazon S3, Amazon Elastic Container-register (Amazon ECR), en Amazon CloudWatch-logboeken.
- Beleid 3 - Bijvoegen AWSLambda_FullAccess, een door AWS beheerd beleid dat volledige toegang verleent tot Lambda, Lambda-consolefuncties en andere gerelateerde AWS-services.
- Beleid 4 – Gebruik het volgende IAM-vertrouwensbeleid voor de IAM-rol:
SageMaker-uitvoeringsrol
Aan de SageMaker Studio-domeinen die in de dev- en prod-accounts zijn ingesteld, moet aan elk een uitvoeringsrol zijn gekoppeld, die te vinden is op de Domeininstellingen tabblad op de pagina met domeindetails, zoals weergegeven in de volgende schermafbeelding. Deze rol wordt gebruikt om trainingstaken uit te voeren, taken te verwerken en meer binnen het SageMaker Studio-domein.
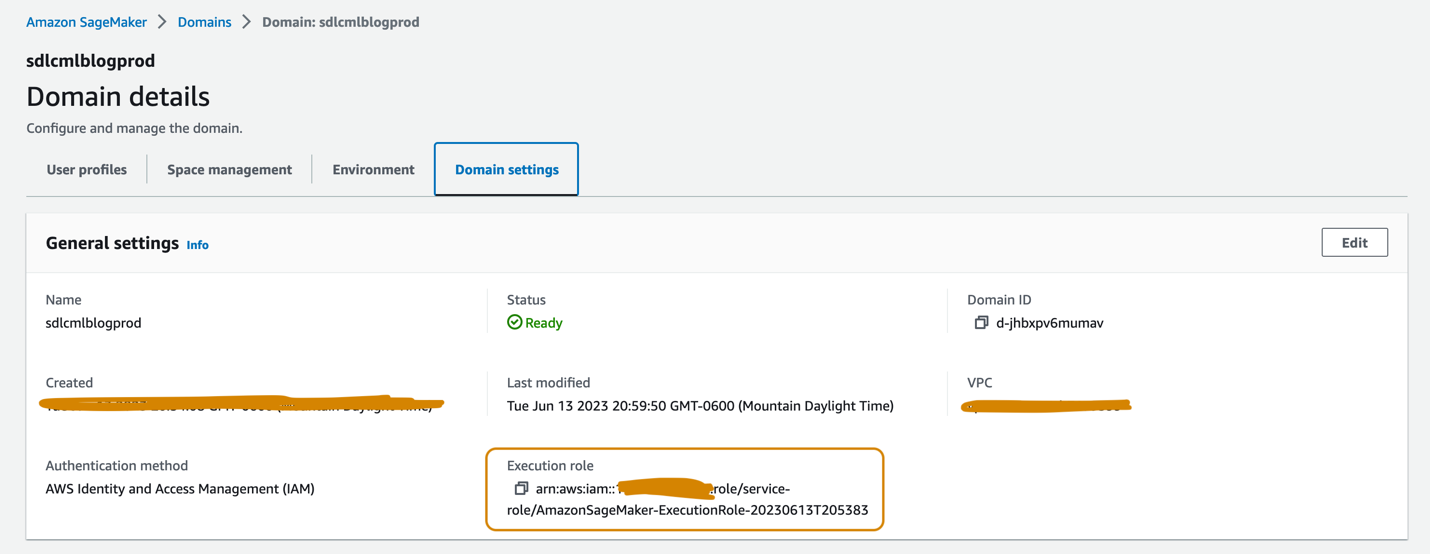
Voeg het volgende beleid toe aan de SageMaker-uitvoeringsrol in beide accounts:
- Beleid 1 – Maak een inline-beleid met de naam
cross-account-model-artifacts-s3-bucket-access, die toegang geeft tot de S3-bucket in het centrale modelregisteraccount, waarin de modelartefacten worden opgeslagen: - Beleid 2 – Maak een inline-beleid met de naam
cross-account-model-registry-access, die toegang geeft tot het modelpakket in het modelregister in het centrale modelregisteraccount: - Beleid 3 – Maak een inline-beleid met de naam
kms-key-access-policy, die toegang geeft tot de KMS-sleutel die in de vorige stap is gemaakt. Geef de account-ID op waarin het beleid wordt gemaakt en de KMS-sleutel-ID die in dat account is gemaakt. - Beleid 4 - Bijvoegen AmazonSageMakerFullAccess, dat is een Door AWS beheerd beleid die volledige toegang verleent tot SageMaker en geselecteerde toegang tot gerelateerde services.
- Beleid 5 - Bijvoegen AWSLambda_FullAccess, een door AWS beheerd beleid dat volledige toegang verleent tot Lambda, Lambda-consolefuncties en andere gerelateerde AWS-services.
- Beleid 6 - Bijvoegen CloudWatchEventsFullAccess, een door AWS beheerd beleid dat volledige toegang verleent tot CloudWatch Events.
- Beleid 7 – Voeg het volgende IAM-vertrouwensbeleid toe voor de IAM-rol voor SageMaker-uitvoering:
- Beleid 8 (specifiek voor de SageMaker-uitvoeringsrol in het prod-account) – Maak een inline-beleid met de naam
cross-account-kms-key-access-policy, die toegang geeft tot de KMS-sleutel die in het ontwikkelaarsaccount is gemaakt. Dit is vereist voor de deductiepijplijn om modelartefacten te lezen die zijn opgeslagen in het centrale modelregisteraccount, waar de modelartefacten worden gecodeerd met behulp van de KMS-sleutel van het ontwikkelaarsaccount wanneer de eerste versie van het model wordt gemaakt op basis van het ontwikkelaarsaccount.
Jenkins-rol voor meerdere accounts
Stel een IAM-rol in met de naam cross-account-jenkins-role in het prod-account, waarvan Jenkins aanneemt dat hij ML-pijplijnen en bijbehorende infrastructuur in het prod-account zal implementeren.
Voeg het volgende beheerde IAM-beleid toe aan de rol:
CloudWatchFullAccessAmazonS3FullAccessAmazonSNSFullAccessAmazonSageMakerFullAccessAmazonEventBridgeFullAccessAWSLambda_FullAccess
Werk de vertrouwensrelatie voor de rol bij om machtigingen te geven aan het AWS-account dat als host fungeert voor de Jenkins-server:
Update machtigingen voor de IAM-rol die is gekoppeld aan de Jenkins-server
Ervan uitgaande dat Jenkins is ingesteld op AWS, updatet u de IAM-rol die aan Jenkins is gekoppeld om het volgende beleid toe te voegen, waardoor Jenkins toegang krijgt om de bronnen in het prod-account te implementeren:
- Beleid 1 – Maak het volgende inline-beleid met de naam
assume-production-role-policy: - Beleid 2 – Bevestig de
CloudWatchFullAccessbeheerd IAM-beleid.
Stel de modelpakketgroep in het centrale modelregisteraccount in
Maak vanuit het SageMaker Studio-domein in het centrale modelregisteraccount een modelpakketgroep met de naam mammo-severity-model-package met behulp van het volgende codefragment (dat u kunt uitvoeren met een Jupyter-notebook):
Stel toegang tot het modelpakket in voor IAM-rollen in de dev- en prod-accounts
Toegang verlenen tot de SageMaker-uitvoeringsrollen die zijn gemaakt in de dev- en prod-accounts, zodat u modelversies binnen het modelpakket kunt registreren mammo-severity-model-package vanuit beide accounts in het centrale modelregister. Voer vanuit het SageMaker Studio-domein in het centrale modelregisteraccount de volgende code uit in een Jupyter-notebook:
Stel Jenkins in
In deze sectie configureren we Jenkins om de ML-pijplijnen en de bijbehorende Terraform-infrastructuur in het prod-account te maken via de Jenkins CI/CD-pijplijn.
- Maak op de CloudWatch-console een loggroep met de naam
jenkins-logbinnen het prod-account waarnaar Jenkins logboeken uit de CI/CD-pijplijn zal pushen. De loggroep moet worden aangemaakt in dezelfde regio als waar de Jenkins-server is ingesteld.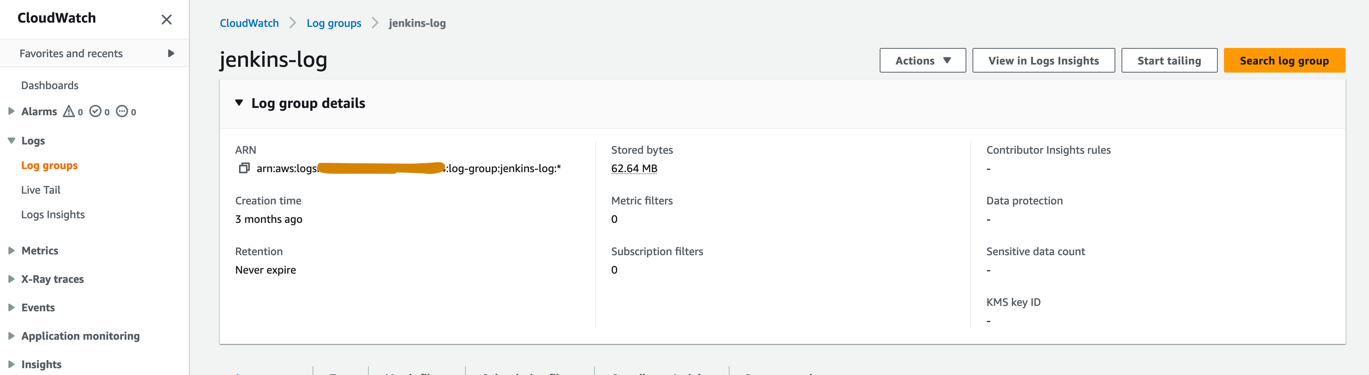
- Installeer de volgende plug-ins op uw Jenkins-server:
- Stel AWS-inloggegevens in Jenkins in met behulp van de IAM-rol voor meerdere accounts (
cross-account-jenkins-role) ingericht in het prod-account.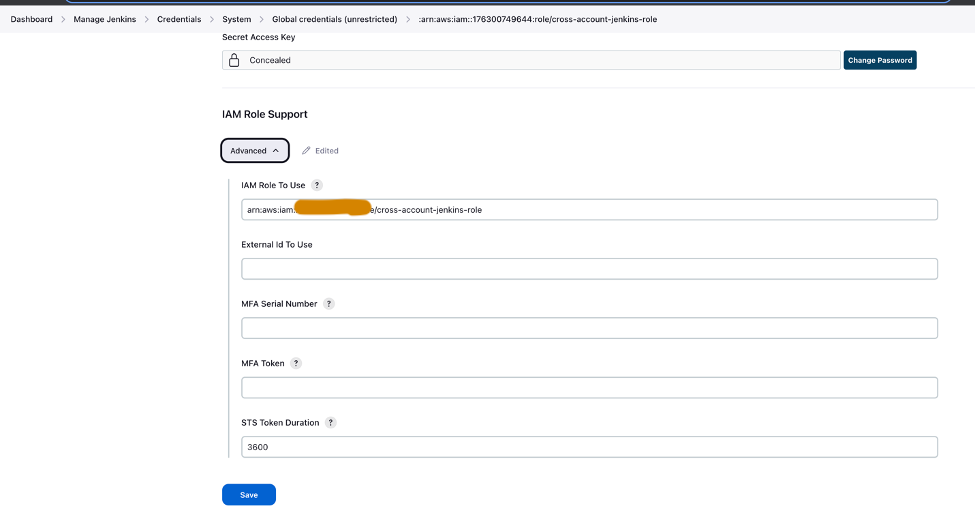
- Voor Systeemconfiguratie, kiezen AWS.

- Geef de inloggegevens en de CloudWatch-logboekgroep op die u eerder hebt gemaakt.

- Stel GitHub-referenties in binnen Jenkins.
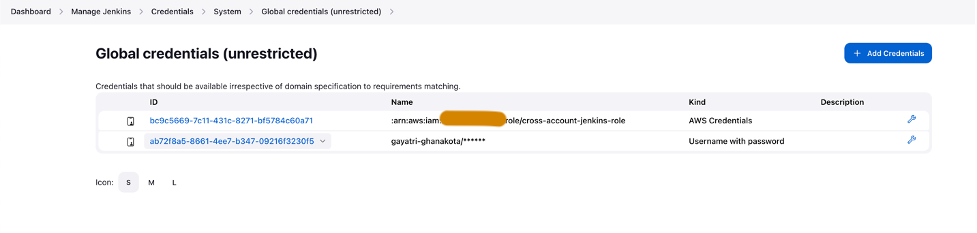
- Maak een nieuw project in Jenkins.
- Voer een projectnaam in en kies Pijpleiding.
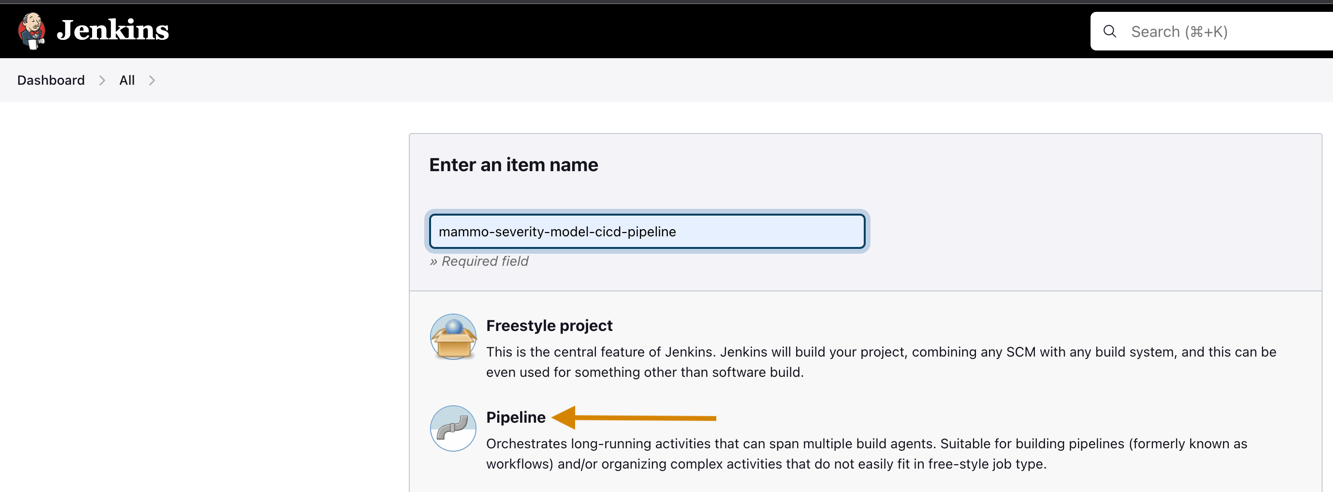
- Op de Algemeen tab, selecteer GitHub-project en ga de vork in GitHub-repository URL.
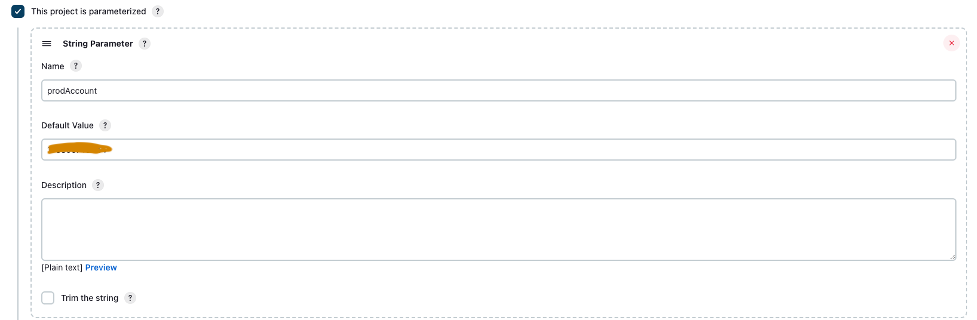
- kies Dit project is geparametriseerd.
- Op de Parameter toevoegen menu, kies Tekenreeksparameter.

- Voor Naam, ga naar binnen
prodAccount. - Voor Standaardwaarde, voer de productaccount-ID in.
- Onder Geavanceerde projectoptiesvoor Definitieselecteer Pipeline-script van SCM.
- Voor SCM, kiezen Git.
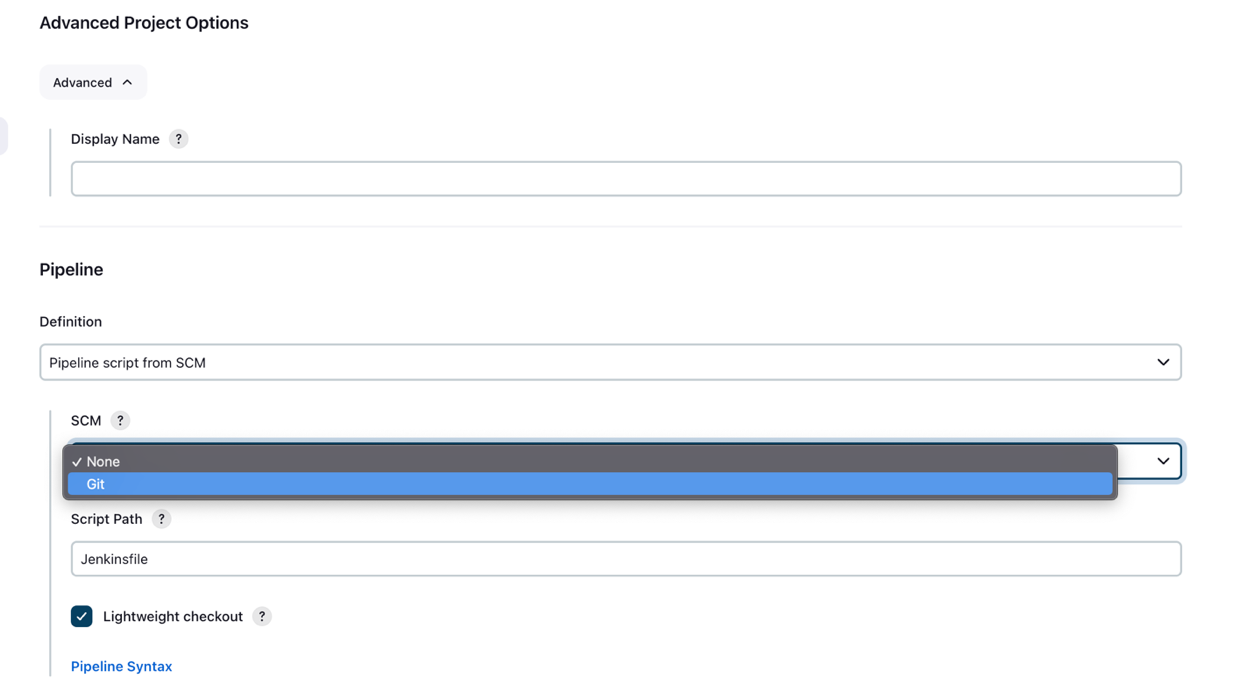
- Voor Repository-URL, voer de gevorkte in GitHub-repository URL.
- Voor GeloofsbrievenVoer de GitHub-referenties in die zijn opgeslagen in Jenkins.
- Enter
mainin de Takken om te bouwen sectie, op basis waarvan de CI/CD-pijplijn wordt geactiveerd.
- Voor Scriptpad, ga naar binnen
Jenkinsfile. - Kies Bespaar.
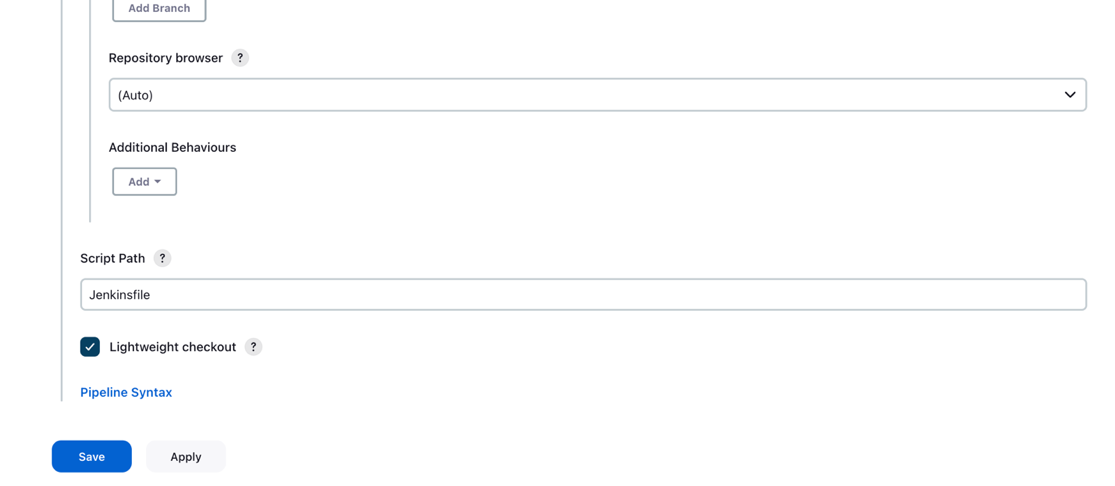
De Jenkins-pijplijn moet worden gemaakt en zichtbaar zijn op uw dashboard.
S3-buckets inrichten, gegevens verzamelen en voorbereiden
Voer de volgende stappen uit om uw S3-buckets en gegevens in te stellen:
- Maak met het touwtje een S3-bucket naar keuze
sagemakerin de naamgevingsconventie als onderdeel van de naam van de bucket in zowel dev- als prod-accounts om datasets en modelartefacten op te slaan. - Stel een S3-bucket in om de Terraform-status in het productaccount te behouden.
- Download en bewaar de openbaar beschikbare UCI Mammografie Massa gegevensset naar de S3-bucket die u eerder in het ontwikkelaarsaccount hebt gemaakt.
- Fork en kloon de GitHub-repository binnen het SageMaker Studio-domein in het ontwikkelaarsaccount. De repository heeft de volgende mappenstructuur:
- /environments – Configuratiescript voor de productieomgeving
- /mlops-infra – Code voor het inzetten van AWS-services met behulp van Terraform-code
- /pijpleidingen – Code voor pijplijncomponenten van SageMaker
- Jenkinsbestand – Script om te implementeren via de Jenkins CI/CD-pijplijn
- setup.py – Nodig om de vereiste Python-modules te installeren en de run-pipeline-opdracht te maken
- mammografie-ernst-modeling.ipynb - Hiermee kunt u de ML-workflow maken en uitvoeren
- Maak een map met de naam data in de gekloonde GitHub-repositorymap en sla een kopie op van het openbaar beschikbare UCI Mammografie Massa gegevensset.
- Volg het Jupyter-notebook
mammography-severity-modeling.ipynb. - Voer de volgende code uit in het notebook om de gegevensset voor te verwerken en deze te uploaden naar de S3-bucket in het ontwikkelaarsaccount:
De code genereert de volgende datasets:
-
- data/mammo-train-dataset-part1.csv – Zal worden gebruikt om de eerste versie van het model te trainen.
- data/mammo-train-dataset-part2.csv – Zal worden gebruikt om de tweede versie van het model te trainen, samen met de dataset mammo-train-dataset-part1.csv.
- data/mammo-batch-dataset.csv – Wordt gebruikt om gevolgtrekkingen te genereren.
- data/mammo-batch-dataset-outliers.csv – Zal uitschieters in de dataset introduceren om de gevolgtrekkingspijplijn te laten mislukken. Hierdoor kunnen we het patroon testen om automatische hertraining van het model te activeren.
- Upload de dataset
mammo-train-dataset-part1.csvonder het voorvoegselmammography-severity-model/train-dataseten upload de gegevenssetsmammo-batch-dataset.csvenmammo-batch-dataset-outliers.csvnaar het voorvoegselmammography-severity-model/batch-datasetvan de S3-bucket die in het ontwikkelaarsaccount is gemaakt: - Upload de datasets
mammo-train-dataset-part1.csvenmammo-train-dataset-part2.csvonder het voorvoegselmammography-severity-model/train-datasetin de S3-bucket die in het prod-account is aangemaakt via de Amazon S3-console.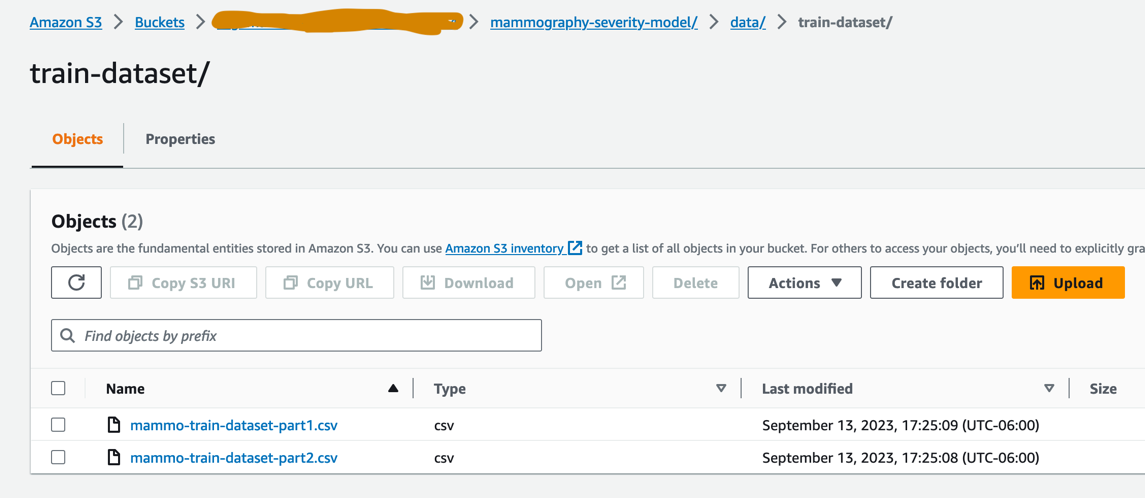
- Upload de datasets
mammo-batch-dataset.csvenmammo-batch-dataset-outliers.csvnaar het voorvoegselmammography-severity-model/batch-datasetvan de S3-bucket in het productaccount.
Voer de treinpijpleiding uit
Onder <project-name>/pipelines/train, ziet u de volgende Python-scripts:
- scripts/raw_preprocess.py - Integreert met SageMaker Processing voor feature engineering
- scripts/evaluate_model.py – Maakt in dit geval berekening van modelmetrieken mogelijk
auc_score - train_pipeline.py – Bevat de code voor de modeltrainingspijplijn
Voer de volgende stappen uit:
- Upload de scripts naar Amazon S3:
- Haal de treinpijplijninstantie op:
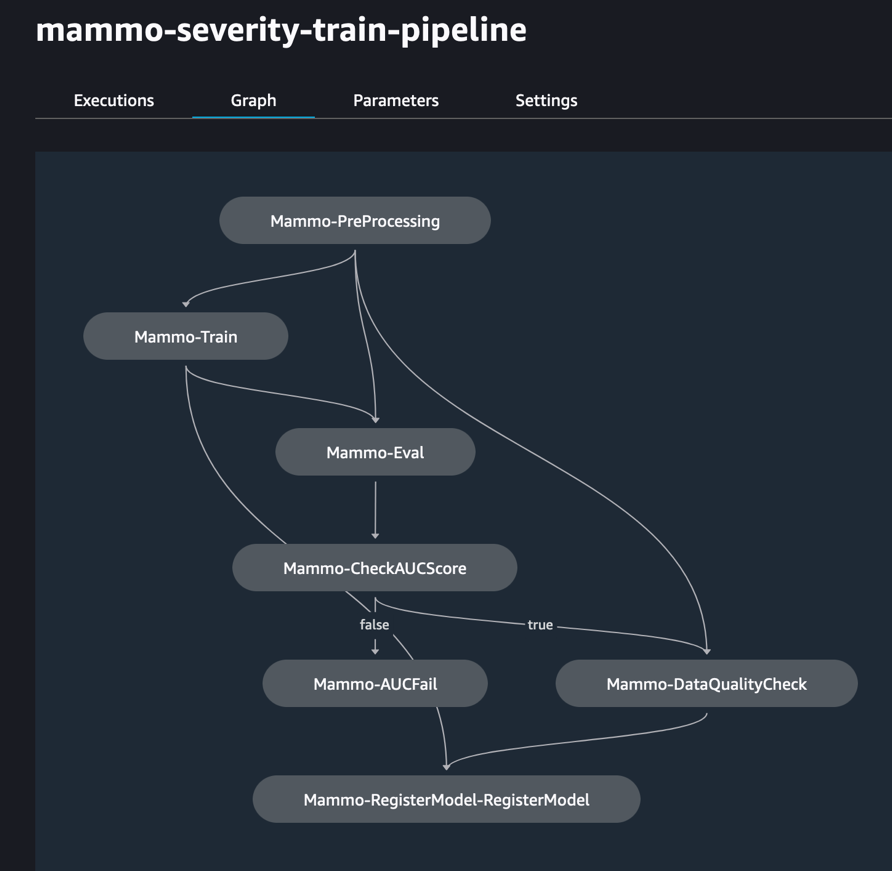
- Dien de treinpijplijn in en voer deze uit:
De volgende afbeelding toont een succesvolle uitvoering van de trainingspijplijn. De laatste stap in de pijplijn registreert het model in het centrale modelregistratieaccount.

Keur het model goed in het centrale modellenregister
Log in op het centrale modelregisteraccount en krijg toegang tot het SageMaker-modelregister binnen het SageMaker Studio-domein. Wijzig de status van de modelversie in Goedgekeurd.
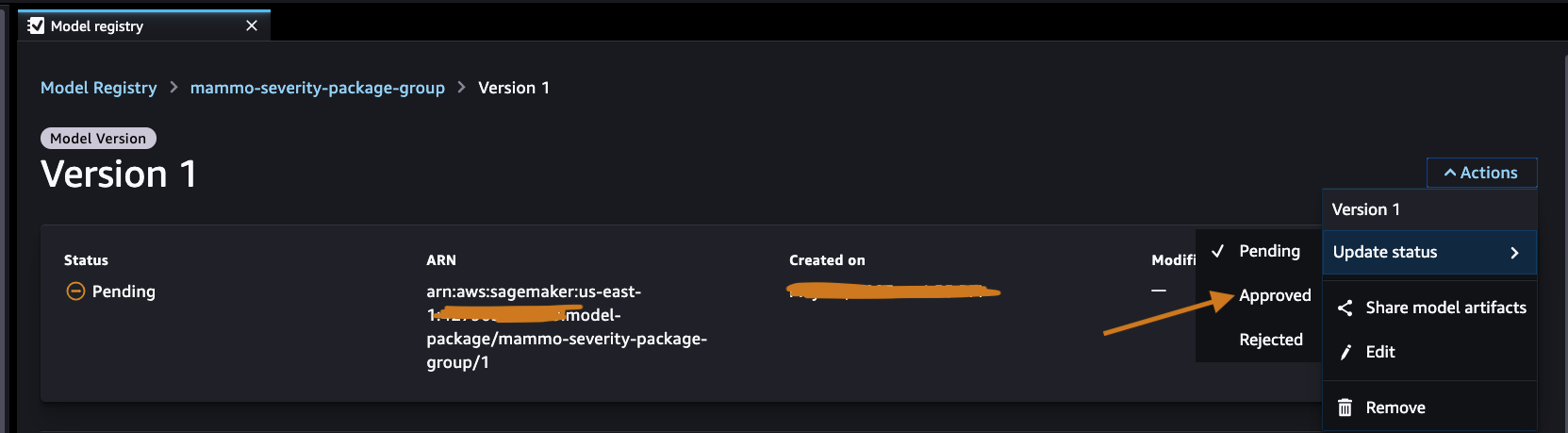
Na goedkeuring moet de status van de modelversie worden gewijzigd.
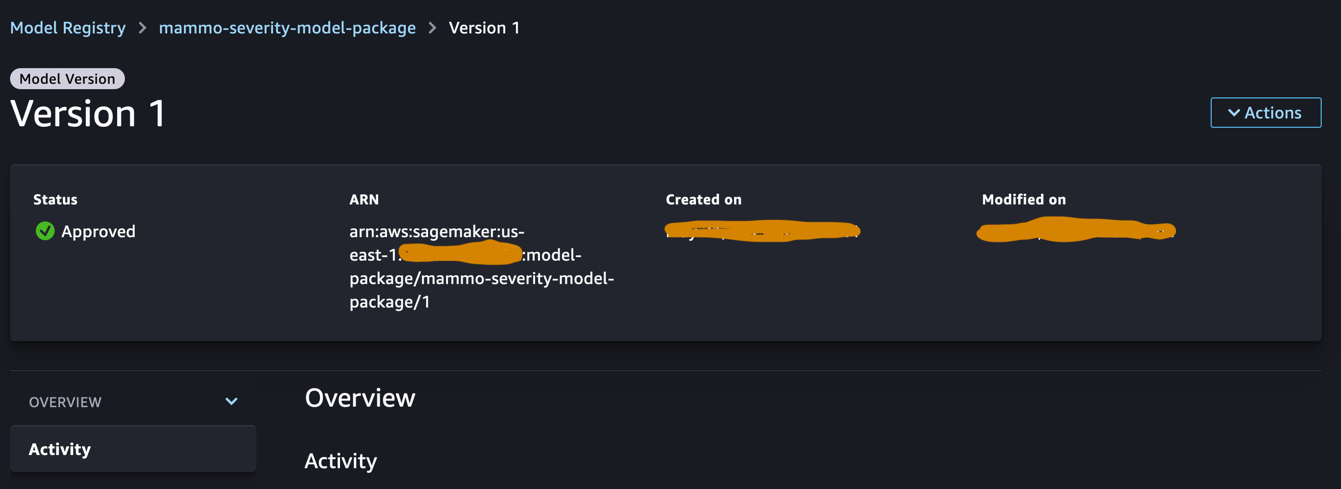
Voer de gevolgtrekkingspijplijn uit (optioneel)
Deze stap is niet vereist, maar u kunt nog steeds de gevolgtrekkingspijplijn uitvoeren om voorspellingen te genereren in het ontwikkelaarsaccount.
Onder <project-name>/pipelines/inference, ziet u de volgende Python-scripts:
- scripts/lambda_helper.py – Haalt de nieuwste goedgekeurde modelversie op uit het centrale modelregisteraccount met behulp van een SageMaker Pipelines Lambda-stap
- inference_pipeline.py – Bevat de code voor de modelinferentiepijplijn
Voer de volgende stappen uit:
- Upload het script naar de S3-bucket:
- Haal de inferentiepijplijninstantie op met behulp van de normale batchgegevensset:
- Dien de gevolgtrekkingspijplijn in en voer deze uit:
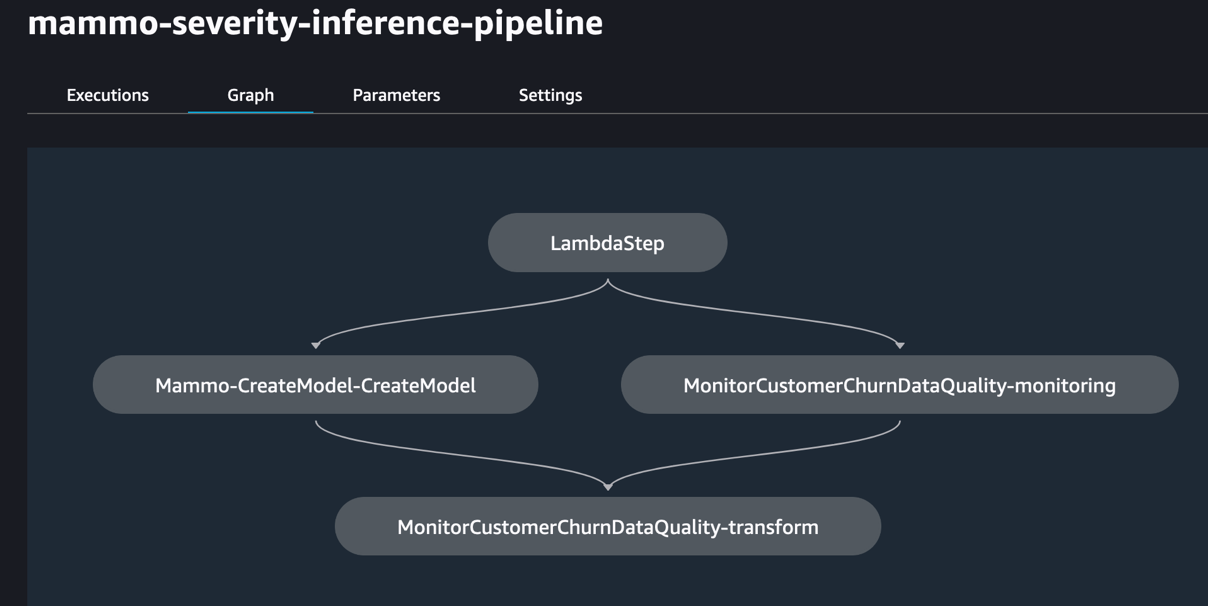
De volgende afbeelding toont een succesvolle uitvoering van de inferentiepijplijn. De laatste stap in de pijplijn genereert de voorspellingen en slaat deze op in de S3-bucket. We gebruiken MonitorBatchTransformStep om de invoer in de batchtransformatietaak te controleren. Als er uitschieters zijn, gaat de inferentiepijplijn over in een mislukte status.
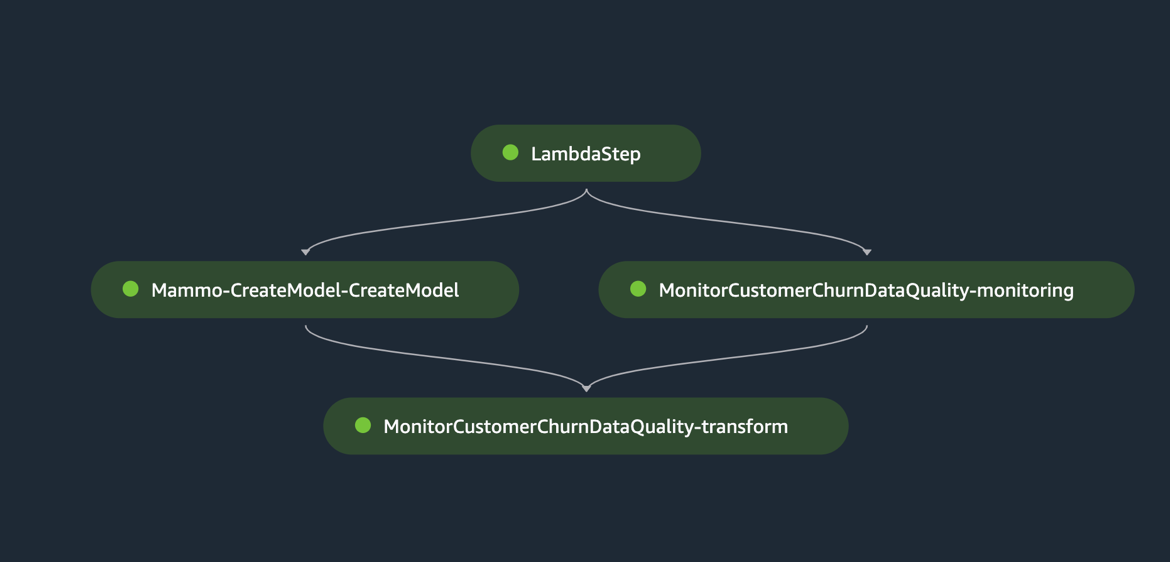
Voer de Jenkins-pijplijn uit
De environment/ map in de GitHub-repository bevat het configuratiescript voor het prod-account. Voer de volgende stappen uit om de Jenkins-pijplijn te activeren:
- Update het configuratiescript
prod.tfvars.jsongebaseerd op de bronnen die in de vorige stappen zijn gemaakt: - Eenmaal bijgewerkt, duwt u de code naar de gevorkte GitHub-repository en voegt u de code samen in de hoofdvertakking.
- Ga naar de Jenkins-gebruikersinterface en kies Bouw met parametersen activeer de CI/CD-pijplijn die in de vorige stappen is gemaakt.

Wanneer de build voltooid en succesvol is, kunt u inloggen op het prod-account en de trein- en inferentiepijplijnen binnen het SageMaker Studio-domein bekijken.
Bovendien ziet u drie EventBridge-regels op de EventBridge-console in het prod-account:
- Plan de deductiepijplijn
- Stuur een storingsmelding op de treinleiding
- Wanneer de inferentiepijplijn er niet in slaagt de treinpijplijn te activeren, verzendt u een melding

Ten slotte ziet u een SNS-meldingsonderwerp op de Amazon SNS-console dat meldingen via e-mail verzendt. U ontvangt een e-mail waarin u wordt gevraagd de aanvaarding van deze e-mailmeldingen te bevestigen.

Test de gevolgtrekkingspijplijn met behulp van een batchgegevensset zonder uitschieters
Om te testen of de inferentiepijplijn in het prod-account werkt zoals verwacht, kunnen we inloggen op het prod-account en de inferentiepijplijn activeren met behulp van de batchgegevensset zonder uitschieters.
Voer de pijplijn uit via de SageMaker Pipelines-console in het SageMaker Studio-domein van het prod-account, waar de transform_input zal de S3 URI van de dataset zijn zonder uitbijters (s3://<s3-bucket-in-prod-account>/mammography-severity-model/data/mammo-batch-dataset.csv).
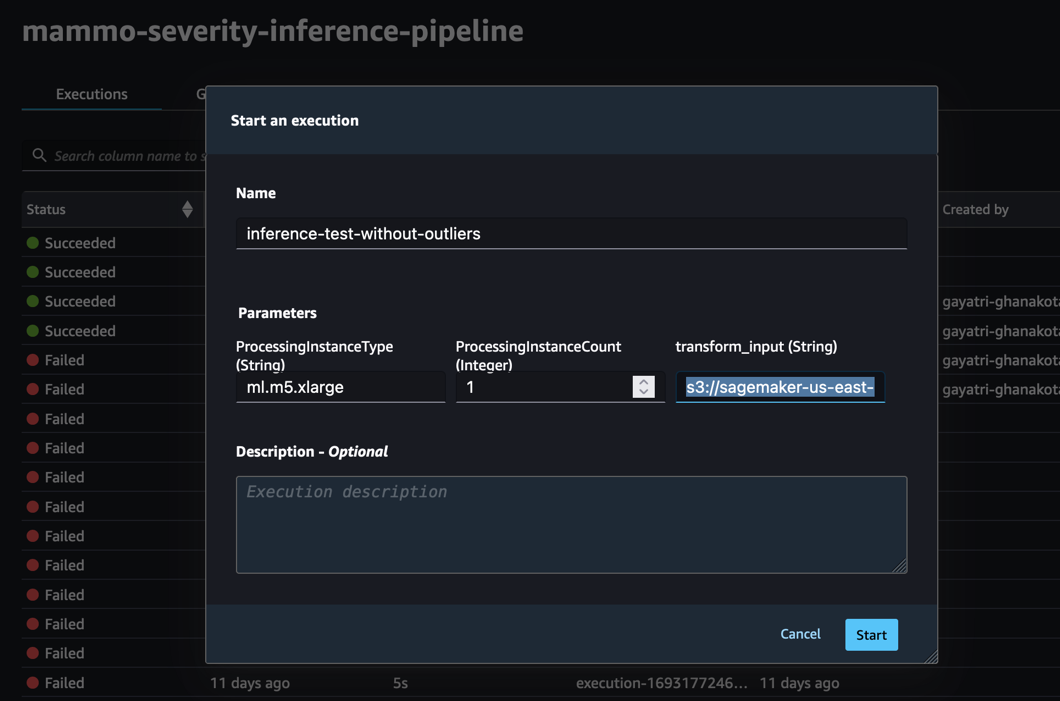
De inferentiepijplijn slaagt en schrijft de voorspellingen terug naar de S3-bucket.
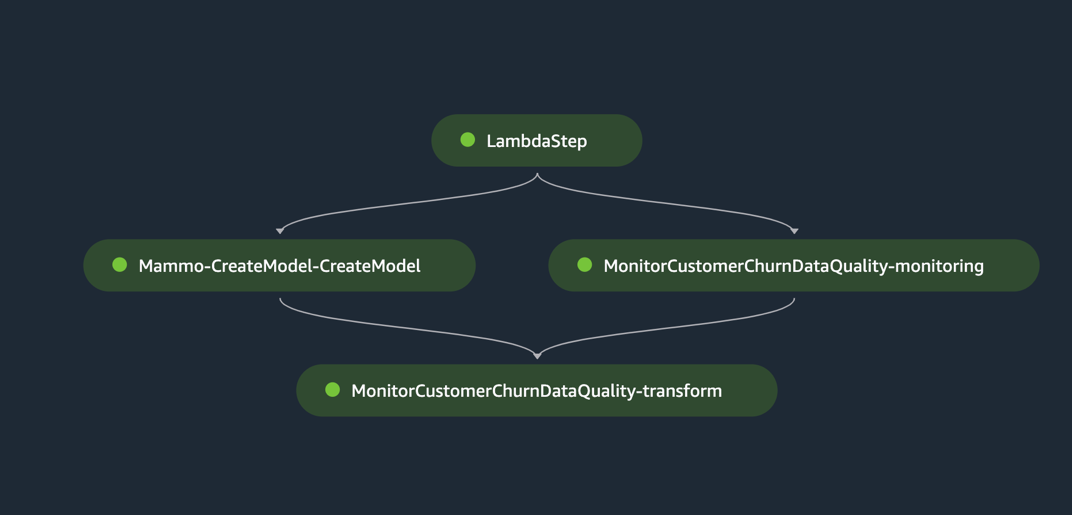
Test de gevolgtrekkingspijplijn met behulp van een batchgegevensset met uitbijters
U kunt de gevolgtrekkingspijplijn uitvoeren met behulp van de batchgegevensset met uitbijters om te controleren of het geautomatiseerde hertrainingsmechanisme werkt zoals verwacht.
Voer de pijplijn uit via de SageMaker Pipelines-console in het SageMaker Studio-domein van het prod-account, waar de transform_input zal de S3-URI zijn van de dataset met uitbijters (s3://<s3-bucket-in-prod-account>/mammography-severity-model/data/mammo-batch-dataset-outliers.csv).

De gevolgtrekkingspijplijn mislukt zoals verwacht, waardoor de EventBridge-regel wordt geactiveerd, die op zijn beurt de treinpijplijn activeert.
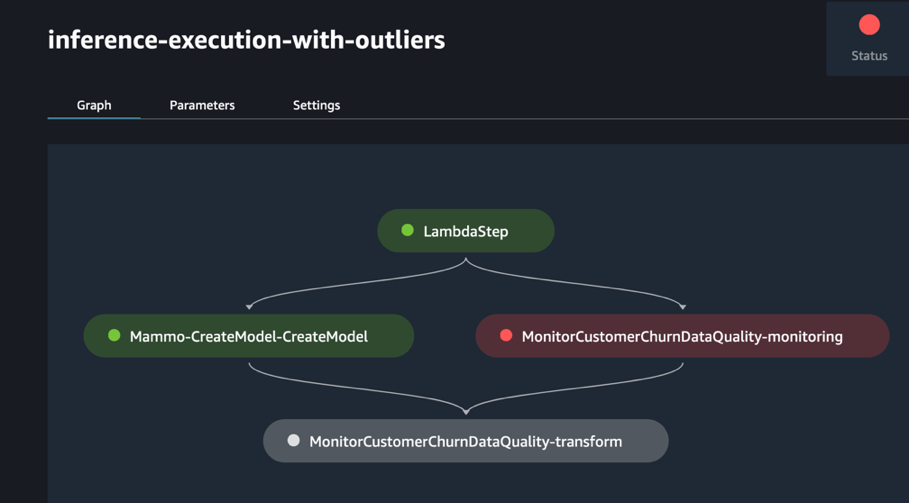
Na enkele ogenblikken zou u een nieuwe run van de treinpijplijn op de SageMaker Pipelines-console moeten zien, die de twee verschillende treingegevenssets ophaalt (mammo-train-dataset-part1.csv en mammo-train-dataset-part2.csv) geüpload naar de S3-bucket om het model opnieuw te trainen.

U ziet ook een melding verzonden naar de e-mail waarin u zich op het SNS-onderwerp heeft geabonneerd.
Als u de bijgewerkte modelversie wilt gebruiken, logt u in op het centrale modelregisteraccount en keurt u de modelversie goed. Deze wordt opgehaald tijdens de volgende uitvoering van de gevolgtrekkingspijplijn die wordt geactiveerd via de geplande EventBridge-regel.
Hoewel de trein- en inferentiepijplijnen een statische gegevensset-URL gebruiken, kunt u de gegevensset-URL als dynamische variabelen aan de trein- en inferentiepijplijnen laten doorgeven om bijgewerkte gegevenssets te gebruiken om het model opnieuw te trainen en voorspellingen te genereren in een realistisch scenario.
Opruimen
Voer de volgende stappen uit om toekomstige kosten te voorkomen:
- Verwijder het SageMaker Studio-domein voor alle AWS-accounts.
- Verwijder alle bronnen die buiten SageMaker zijn gemaakt, inclusief de S3-buckets, IAM-rollen, EventBridge-regels en het SNS-onderwerp dat is ingesteld via Terraform in het prod-account.
- Verwijder de SageMaker-pijplijnen die voor accounts zijn gemaakt met behulp van de AWS-opdrachtregelinterface (AWS CLI).
Conclusie
Organisaties moeten vaak afstemmen op ondernemingsbrede toolsets om samenwerking tussen verschillende functionele gebieden en teams mogelijk te maken. Deze samenwerking zorgt ervoor dat uw MLOps-platform zich kan aanpassen aan de veranderende bedrijfsbehoeften en versnelt de adoptie van ML binnen teams. In dit bericht wordt uitgelegd hoe je een MLOps-framework kunt maken in een opstelling met meerdere omgevingen om geautomatiseerde modelhertraining, batch-inferentie en monitoring met Amazon SageMaker Model Monitor, modelversiebeheer met SageMaker Model Registry en promotie van ML-code en pijplijnen in omgevingen met een CI/CD-pijplijn. We hebben deze oplossing gedemonstreerd met behulp van een combinatie van AWS-services en toolsets van derden. Voor instructies over het implementeren van deze oplossing, zie de GitHub-repository. U kunt deze oplossing ook uitbreiden door uw eigen gegevensbronnen en modelleringsframeworks in te voeren.
Over de auteurs
 Gayatri Ghanakota is een Sr. Machine Learning Engineer bij AWS Professional Services. Ze heeft een passie voor het ontwikkelen, implementeren en uitleggen van AI/ML-oplossingen in verschillende domeinen. Voorafgaand aan deze functie leidde ze meerdere initiatieven als datawetenschapper en ML-engineer bij wereldwijde topbedrijven in de financiële en winkelruimte. Ze heeft een master's degree in Computer Science, gespecialiseerd in Data Science, van de University of Colorado, Boulder.
Gayatri Ghanakota is een Sr. Machine Learning Engineer bij AWS Professional Services. Ze heeft een passie voor het ontwikkelen, implementeren en uitleggen van AI/ML-oplossingen in verschillende domeinen. Voorafgaand aan deze functie leidde ze meerdere initiatieven als datawetenschapper en ML-engineer bij wereldwijde topbedrijven in de financiële en winkelruimte. Ze heeft een master's degree in Computer Science, gespecialiseerd in Data Science, van de University of Colorado, Boulder.
 Sunita Koppar is een Sr. Data Lake Architect bij AWS Professional Services. Ze heeft een passie voor het oplossen van pijnpunten bij klanten, het verwerken van big data en het bieden van schaalbare oplossingen voor de lange termijn. Voorafgaand aan deze rol ontwikkelde ze producten op het gebied van internet, telecom en automotive, en was ze klant van AWS. Ze heeft een masterdiploma in Data Science behaald aan de University of California, Riverside.
Sunita Koppar is een Sr. Data Lake Architect bij AWS Professional Services. Ze heeft een passie voor het oplossen van pijnpunten bij klanten, het verwerken van big data en het bieden van schaalbare oplossingen voor de lange termijn. Voorafgaand aan deze rol ontwikkelde ze producten op het gebied van internet, telecom en automotive, en was ze klant van AWS. Ze heeft een masterdiploma in Data Science behaald aan de University of California, Riverside.
 Saswata Dash is een DevOps-consultant bij AWS Professional Services. Ze heeft gewerkt met klanten in de gezondheidszorg en de biowetenschappen, de luchtvaart en de productie. Ze heeft een passie voor alles wat met automatisering te maken heeft en heeft uitgebreide ervaring met het ontwerpen en bouwen van klantoplossingen op ondernemingsniveau in AWS. Buiten haar werk streeft ze haar passie voor fotografie en het vastleggen van zonsopgangen na.
Saswata Dash is een DevOps-consultant bij AWS Professional Services. Ze heeft gewerkt met klanten in de gezondheidszorg en de biowetenschappen, de luchtvaart en de productie. Ze heeft een passie voor alles wat met automatisering te maken heeft en heeft uitgebreide ervaring met het ontwerpen en bouwen van klantoplossingen op ondernemingsniveau in AWS. Buiten haar werk streeft ze haar passie voor fotografie en het vastleggen van zonsopgangen na.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/promote-pipelines-in-a-multi-environment-setup-using-amazon-sagemaker-model-registry-hashicorp-terraform-github-and-jenkins-ci-cd/

