Dit bericht is geschreven in samenwerking met Bhajandeep Singh en Ajay Vishwakarma van Wipro's AWS AI/ML Practice.
Veel organisaties gebruiken een combinatie van on-premise en open source data science-oplossingen om machine learning (ML)-modellen te creëren en te beheren.
Datawetenschaps- en DevOps-teams kunnen te maken krijgen met uitdagingen bij het beheren van deze geïsoleerde toolstacks en systemen. Het integreren van meerdere toolstacks om een compacte oplossing te bouwen kan het bouwen van aangepaste connectoren of workflows met zich meebrengen. Het beheren van verschillende afhankelijkheden op basis van de huidige versie van elke stapel en het onderhouden van deze afhankelijkheden met de release van nieuwe updates van elke stapel bemoeilijkt de oplossing. Dit verhoogt de kosten van het onderhoud van de infrastructuur en belemmert de productiviteit.
Aanbiedingen voor kunstmatige intelligentie (AI) en machine learning (ML) van Amazon Web Services (AWS), samen met geïntegreerde monitoring- en meldingsdiensten, helpen organisaties het vereiste niveau van automatisering, schaalbaarheid en modelkwaliteit te bereiken tegen optimale kosten. AWS helpt data science- en DevOps-teams ook om samen te werken en het algehele levenscyclusproces van modellen te stroomlijnen.
Het AWS-portfolio van ML-services omvat een robuuste set services die u kunt gebruiken om de ontwikkeling, training en implementatie van machine learning-applicaties te versnellen. Het dienstenpakket kan worden gebruikt ter ondersteuning van de volledige levenscyclus van modellen, inclusief het monitoren en opnieuw trainen van ML-modellen.
In dit bericht bespreken we de modelontwikkeling en de implementatie van het MLOps-framework voor een van Wipro's klanten die gebruikmaakt van Amazon Sage Maker en andere AWS-services.
Wipro is een AWS Premier Tier Services-partner en Managed Service Provider (MSP). Zijn AI/ML-oplossingen zorgen voor verbeterde operationele efficiëntie, productiviteit en klantervaring voor veel van hun zakelijke klanten.
Huidige uitdagingen
Laten we eerst eens kijken naar enkele van de uitdagingen waarmee de datawetenschaps- en DevOps-teams van de klant te maken kregen met hun huidige opzet. We kunnen vervolgens onderzoeken hoe het geïntegreerde SageMaker AI/ML-aanbod deze uitdagingen heeft helpen oplossen.
- Samenwerking – Datawetenschappers werkten elk aan hun eigen lokale Jupyter-notebooks om ML-modellen te maken en te trainen. Het ontbrak hen aan een effectieve methode om te delen en samen te werken met andere datawetenschappers.
- Schaalbaarheid – Het trainen en opnieuw trainen van ML-modellen kostte steeds meer tijd naarmate modellen complexer werden terwijl de toegewezen infrastructuurcapaciteit statisch bleef.
- MLOps – Modelmonitoring en doorlopend beheer waren niet nauw geïntegreerd en geautomatiseerd met de ML-modellen. Er zijn afhankelijkheden en complexiteiten bij het integreren van tools van derden in de MLOps-pijplijn.
- Herbruikbaarheid – Zonder herbruikbare MLOps-frameworks moet elk model afzonderlijk worden ontwikkeld en beheerd, wat de algehele inspanning vergroot en de operationalisering van het model vertraagt.
Dit diagram geeft een samenvatting van de uitdagingen en hoe Wipro's implementatie op SageMaker deze heeft aangepakt met ingebouwde SageMaker-services en -aanbiedingen.
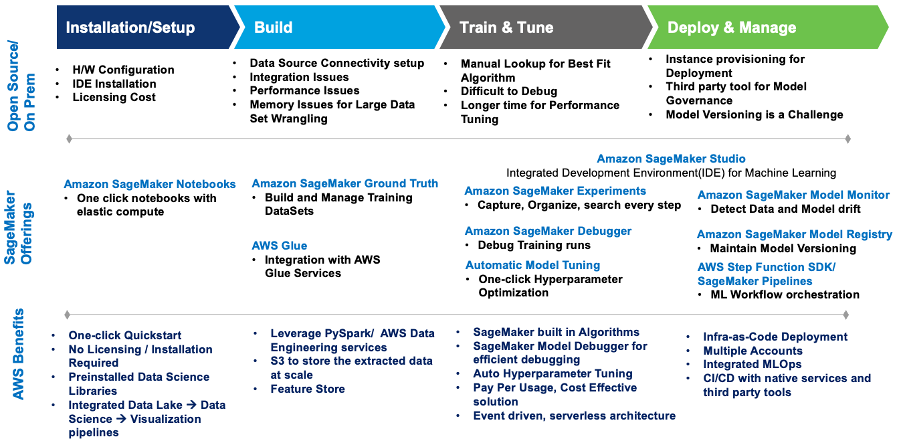
Figuur 1 – SageMaker-aanbod voor migratie van ML-workloads
Wipro definieerde een architectuur die de uitdagingen op een kostengeoptimaliseerde en volledig geautomatiseerde manier aanpakt.
Het volgende is de use case en het model dat is gebruikt om de oplossing te bouwen:
- Use case: Prijsvoorspelling op basis van de dataset voor gebruikte auto's
- Probleemtype: Regressie
- Gebruikte modellen: XGBoost en Linear Learner (ingebouwde algoritmen van SageMaker)
Oplossingsarchitectuur
Wipro-consultants voerden een diepgaande ontdekkingsworkshop uit met de data science-, DevOps- en data-engineeringteams van de klant om inzicht te krijgen in de huidige omgeving en hun vereisten en verwachtingen voor een moderne oplossing op AWS. Aan het einde van de adviesopdracht had het team de volgende architectuur geïmplementeerd die effectief tegemoetkwam aan de kernvereisten van het klantteam, waaronder:
Code delen – Met SageMaker-notebooks kunnen datawetenschappers experimenteren en code delen met andere teamleden. Wipro versnelde hun ML-modeltraject verder door Wipro’s codeversnellers en fragmenten te implementeren om feature-engineering, modeltraining, modelimplementatie en pijplijncreatie te versnellen.
Pijplijn voor continue integratie en continue levering (CI/CD). – Door gebruik te maken van de GitHub-repository van de klant zijn codeversies en geautomatiseerde scripts mogelijk om pijplijnimplementatie te starten wanneer nieuwe versies van de code worden vastgelegd.
MLops – De architectuur implementeert een SageMaker-modelmonitoringpijplijn voor continu beheer van modelkwaliteit door gegevens- en modeldrift te valideren zoals vereist door het gedefinieerde schema. Telkens wanneer drift wordt gedetecteerd, wordt er een gebeurtenis gelanceerd om de respectieve teams op de hoogte te stellen om actie te ondernemen of een hertraining van het model te starten.
Gebeurtenisgestuurde architectuur – De pijplijnen voor modeltraining, modelimplementatie en modelmonitoring zijn door het gebruik goed geïntegreerd Amazon EventBridge, een serverloze evenementenbus. Wanneer gedefinieerde gebeurtenissen plaatsvinden, kan EventBridge een pijplijn aanroepen die als reactie wordt uitgevoerd. Dit levert een losjes gekoppelde set pijpleidingen op die naar behoefte kunnen draaien als reactie op de omgeving.
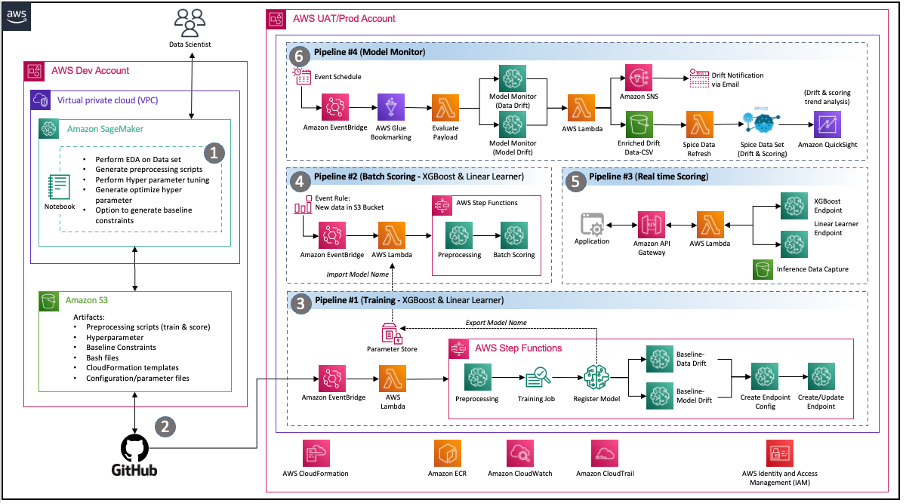
Figuur 2 – Event Driven MLOps-architectuur met SageMaker
Componenten van de oplossing
In deze sectie worden de verschillende oplossingscomponenten van de architectuur beschreven.
Experimenteer met notitieboekjes
- Doel: Het datawetenschapsteam van de klant wilde experimenteren met verschillende datasets en meerdere modellen om tot de optimale functies te komen, en deze te gebruiken als verdere input voor de geautomatiseerde pijplijn.
- Oplossing: Wipro heeft SageMaker-experimentnotebooks gemaakt met codefragmenten voor elke herbruikbare stap, zoals het lezen en schrijven van gegevens, modelfunctie-engineering, modeltraining en afstemming van hyperparameters. Feature-engineeringtaken kunnen ook worden voorbereid in Data Wrangler, maar de klant vroeg specifiek om SageMaker-verwerkingstaken en AWS Stap Functies omdat ze zich meer op hun gemak voelden bij het gebruik van die technologieën. We hebben de AWS Step Function Data Science SDK gebruikt om een stapfunctie (voor stroomtesten) rechtstreeks vanuit de notebookinstantie te maken om goed gedefinieerde invoer voor de pijplijnen mogelijk te maken. Dit heeft het datawetenschapperteam geholpen om pijplijnen in een veel sneller tempo te creëren en te testen.
Geautomatiseerde trainingspijplijn
- Doel: Om een geautomatiseerde trainings- en hertrainingspijplijn mogelijk te maken met configureerbare parameters zoals exemplaartype, hyperparameters en een Eenvoudige opslagservice van Amazon (Amazon S3) bak locatie. De pijplijn moet ook worden gelanceerd door de data push-gebeurtenis naar S3.
- Oplossing: Wipro implementeerde een herbruikbare trainingspijplijn met behulp van de Step Functions SDK, SageMaker-verwerking, trainingstaken, een SageMaker-modelmonitorcontainer voor het genereren van basislijnen, AWS Lambdaen EventBridge-services. Met behulp van AWS-gebeurtenisgestuurde architectuur wordt de pijplijn geconfigureerd om automatisch te starten op basis van een nieuwe gegevensgebeurtenis die naar de toegewezen S3-bucket wordt gepusht. Meldingen zijn geconfigureerd om naar de gedefinieerde e-mailadressen te worden verzonden. Op een hoog niveau ziet de trainingsstroom er als volgt uit:
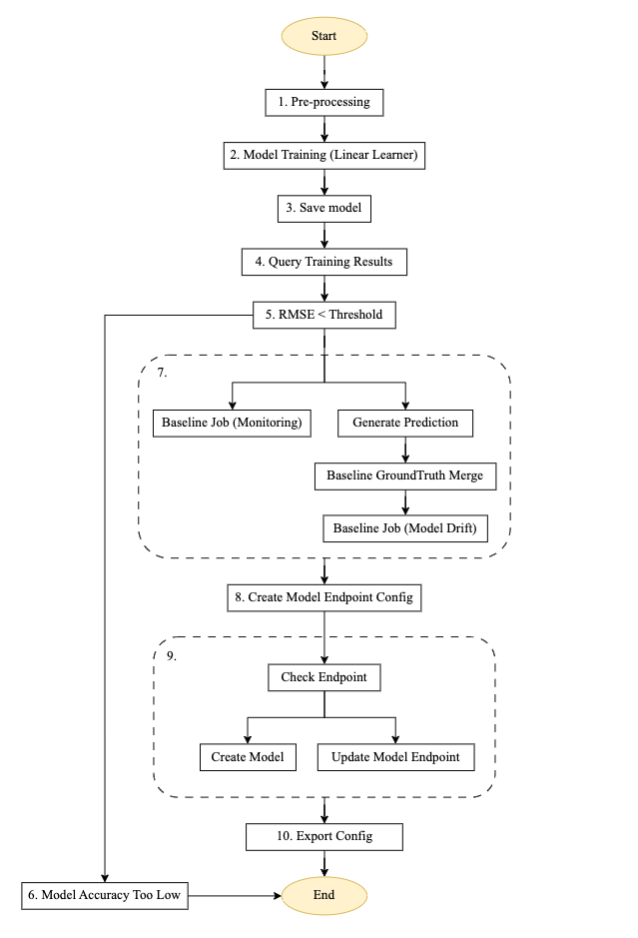
Figuur 3 – Trainingspijplijnstapmachine.
Stroombeschrijving voor de geautomatiseerde trainingspijplijn
Het bovenstaande diagram is een geautomatiseerde trainingspijplijn die is gebouwd met behulp van Step Functions, Lambda en SageMaker. Het is een herbruikbare pijplijn voor het opzetten van geautomatiseerde modeltraining, het genereren van voorspellingen, het creëren van een basislijn voor modelmonitoring en datamonitoring, en het creëren en bijwerken van een eindpunt op basis van de eerdere modeldrempelwaarde.
- Voorverwerking: Deze stap neemt gegevens van een Amazon S3-locatie als invoer en gebruikt de SageMaker SKLearn-container om de noodzakelijke functie-engineering en gegevensvoorverwerkingstaken uit te voeren, zoals de trein-, test- en valideringssplitsing.
- Modeltraining: Met behulp van de SageMaker SDK voert deze stap trainingscode uit met de respectieve modelafbeelding en traint datasets van voorverwerkingsscripts terwijl de getrainde modelartefacten worden gegenereerd.
- Model opslaan: Met deze stap wordt een model gemaakt op basis van de getrainde modelartefacten. De modelnaam wordt ter referentie opgeslagen in een andere pijplijn met behulp van de AWS Systems Manager-parameteropslag.
- Trainingsresultaten opvragen: Deze stap roept de Lambda-functie aan om de metrische gegevens van de voltooide trainingstaak op te halen uit de eerdere modeltrainingsstap.
- RMSE-drempel: Met deze stap wordt de getrainde modelmetriek (RMSE) vergeleken met een gedefinieerde drempelwaarde om te beslissen of moet worden doorgegaan naar de implementatie van het eindpunt of dat dit model moet worden afgewezen.
- Modelnauwkeurigheid te laag: Bij deze stap wordt de nauwkeurigheid van het model vergeleken met het vorige beste model. Als het model faalt bij metrische validatie, wordt de melding door een Lambda-functie verzonden naar het doelonderwerp dat is geregistreerd Amazon eenvoudige meldingsservice (Amazon SNS). Als deze controle mislukt, wordt de stroom afgesloten omdat het nieuwe getrainde model niet aan de gedefinieerde drempelwaarde voldoet.
- Basislijn taakgegevensafwijking: Als het getrainde model de validatiestappen doorstaat, worden basislijnstatistieken gegenereerd voor deze getrainde modelversie om monitoring mogelijk te maken en worden de parallelle vertakkingsstappen uitgevoerd om de basislijn voor de modelkwaliteitscontrole te genereren.
- Modeleindpuntconfiguratie maken: Met deze stap wordt een eindpuntconfiguratie gemaakt voor het geëvalueerde model in de vorige stap met een gegevensverzameling mogelijk maken configuratie.
- Eindpunt controleren: Met deze stap wordt gecontroleerd of het eindpunt bestaat of moet worden gemaakt. Op basis van de uitvoer is de volgende stap het maken of bijwerken van het eindpunt.
- Configuratie exporteren: Met deze stap exporteert u de modelnaam, de eindpuntnaam en de eindpuntconfiguratie van de parameter naar de AWS-systeembeheerder Parameteropslag.
Waarschuwingen en meldingen zijn geconfigureerd om te worden verzonden naar de geconfigureerde SNS-onderwerp-e-mail over het mislukken of slagen van de statuswijziging van de statusmachine. Dezelfde pijplijnconfiguratie wordt hergebruikt voor het XGBoost-model.
Geautomatiseerde pijplijn voor batchscores
- Doel: Start batchscores zodra de scoringsinvoerbatchgegevens beschikbaar zijn op de betreffende Amazon S3-locatie. De batchscore moet het laatst geregistreerde model gebruiken om de score uit te voeren.
- Oplossing: Wipro implementeerde een herbruikbare scorepijplijn met behulp van de Step Functions SDK, SageMaker batchtransformatietaken, Lambda en EventBridge. De pijplijn wordt automatisch geactiveerd op basis van de nieuwe beschikbaarheid van scorebatchgegevens op de betreffende S3-locatie.
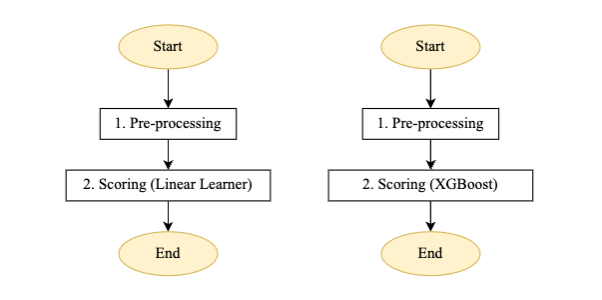
Figuur 4 – Scorepijplijnstapmachine voor lineaire leerling en XGBoost-model
Stroombeschrijving voor de geautomatiseerde batchscorepijplijn:
- Voorverwerking: De invoer voor deze stap is een gegevensbestand van de respectieve S3-locatie en voert de vereiste voorverwerking uit voordat de batchtransformatietaak van SageMaker wordt aangeroepen.
- Scoren: Met deze stap wordt de batchtransformatietaak uitgevoerd om gevolgtrekkingen te genereren, de nieuwste versie van het geregistreerde model aan te roepen en de score-uitvoer op te slaan in een S3-bucket. Wipro heeft de invoerfilter- en join-functionaliteit van de SageMaker batchtransformatie-API gebruikt. Het hielp de scoregegevens te verrijken voor een betere besluitvorming.
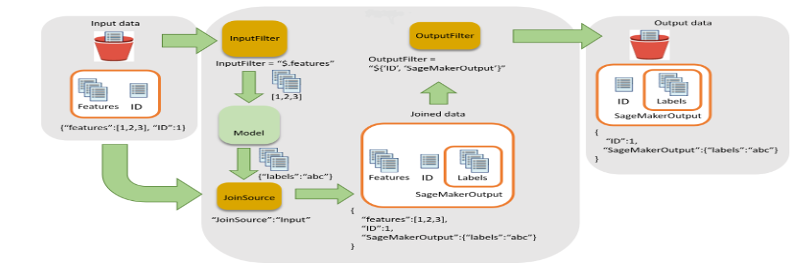
Figuur 5 – Invoerfilter en join-stroom voor batchtransformatie
- In deze stap wordt de State Machine-pijplijn gelanceerd door een nieuw gegevensbestand in de S3-bucket.
De melding is geconfigureerd om te worden verzonden naar het geconfigureerde SNS-onderwerp-e-mailbericht over het mislukken/succes van de statuswijziging van de statusmachine.
Realtime gevolgtrekkingspijplijn
- Doel: Om realtime gevolgtrekkingen uit de eindpunten van beide modellen (Linear Learner en XGBoost) mogelijk te maken en de maximaal voorspelde waarde te verkrijgen (of door een andere aangepaste logica te gebruiken die kan worden geschreven als een Lambda-functie) die naar de applicatie moet worden geretourneerd.
- Oplossing: Het Wipro-team heeft herbruikbare architectuur geïmplementeerd met behulp van Amazon API-gateway, Lambda en SageMaker-eindpunt zoals weergegeven in afbeelding 6:

Figuur 6 – Realtime gevolgtrekkingspijplijn
Stroombeschrijving voor de realtime inferentiepijplijn, weergegeven in figuur 6:
- De payload wordt vanuit de applicatie naar Amazon API Gateway gestuurd, die deze naar de betreffende Lambda-functie stuurt.
- Een Lambda-functie (met een geïntegreerde aangepaste SageMaker-laag) voert de vereiste voorverwerking, JSON- of CSV-payload-formattering uit en roept de respectieve eindpunten aan.
- Het antwoord wordt teruggestuurd naar Lambda en via API Gateway teruggestuurd naar de applicatie.
De klant gebruikte deze pijplijn voor modellen op kleine en middelgrote schaal, waaronder het gebruik van verschillende soorten open-sourcealgoritmen. Een van de belangrijkste voordelen van SageMaker is dat verschillende soorten algoritmen in SageMaker kunnen worden gebracht en kunnen worden ingezet met behulp van een BYOC-techniek (bring your own container). BYOC omvat het containeriseren van het algoritme en het registreren van de afbeelding Amazon Elastic Container Registry (Amazon ECR)en vervolgens dezelfde afbeelding gebruiken om een container te maken voor training en gevolgtrekking.
Schaalvergroting is een van de grootste problemen in de machine learning-cyclus. SageMaker wordt geleverd met de benodigde hulpmiddelen voor het schalen van een model tijdens gevolgtrekking. In de voorgaande architectuur moeten gebruikers het automatisch schalen van SageMaker inschakelen, dat uiteindelijk de werklast afhandelt. Om automatisch schalen in te schakelen, moeten gebruikers een beleid voor automatisch schalen opgeven dat vraagt om de doorvoer per exemplaar en de maximale en minimale exemplaren. Binnen het geldende beleid verwerkt SageMaker automatisch de werklast voor realtime eindpunten en schakelt indien nodig tussen instanties.
Aangepaste modelmonitorpijplijn
- Doel: Het klantenteam wilde geautomatiseerde modelmonitoring om zowel gegevensdrift als modeldrift vast te leggen. Het Wipro-team gebruikte SageMaker-modelmonitoring om zowel datadrift als modeldrift mogelijk te maken met een herbruikbare pijplijn voor realtime gevolgtrekkingen en batchtransformatie. Merk op dat tijdens de ontwikkeling van deze oplossing de SageMaker-modelmonitoring geen voorzieningen voorzag voor het detecteren van gegevens of modeldrift voor batchtransformatie. We hebben aanpassingen geïmplementeerd om de modelmonitorcontainer te gebruiken voor de payload van batchtransformaties.
- Oplossing: Het Wipro-team implementeerde een herbruikbare pijplijn voor modelmonitoring voor het gebruik van realtime- en batchgewijze inferentiepayloads AWS lijm om de incrementele payload vast te leggen en de modelbewakingstaak aan te roepen volgens het gedefinieerde schema.

Figuur 7 – Model monitorstapmachine
Stroombeschrijving voor de aangepaste modelmonitorpijplijn:
De pijplijn wordt uitgevoerd volgens het gedefinieerde schema dat via EventBridge is geconfigureerd.
- CSV-consolidatie – Het maakt gebruik van de AWS Glue-bladwijzerfunctie om de aanwezigheid van incrementele payload in de gedefinieerde S3-bucket van realtime gegevensverzameling en -respons en batchgegevensrespons te detecteren. Vervolgens worden deze gegevens samengevoegd voor verdere verwerking.
- Evalueer de lading – Als er incrementele gegevens of payload aanwezig zijn voor de huidige run, wordt de monitoringtak aangeroepen. Anders wordt de taak omzeild zonder verwerking en wordt de taak afgesloten.
- Nabewerking – De monitoringtak is ontworpen om twee parallelle subtakken te hebben: één voor gegevensdrift en één voor modeldrift.
- Monitoring (gegevensdrift) – De datadrift-tak wordt uitgevoerd wanneer er een payload aanwezig is. Het maakt gebruik van de nieuwste getrainde basislijnbeperkingen en statistische bestanden die zijn gegenereerd via de trainingspijplijn voor de gegevensfuncties en voert de modelbewakingstaak uit.
- Monitoring (modeldrift) – De modeldrifttak werkt alleen wanneer grondwaarheidsgegevens worden geleverd, samen met de gevolgtrekkingspayload. Het maakt gebruik van getrainde modelbasislijnbeperkingen en statistische bestanden die zijn gegenereerd via de trainingspijplijn voor de modelkwaliteitsfuncties en voert de modelbewakingstaak uit.
- Evalueer drift – Het resultaat van zowel gegevens- als modeldrift is een bestand met overtredingen van beperkingen dat wordt geëvalueerd door de evaluatie-drift Lambda-functie die een melding naar de respectievelijke Amazon SNS-onderwerpen verzendt met details over de drift. Driftgegevens worden verder verrijkt door de toevoeging van attributen voor rapportagedoeleinden. De e-mails met driftmeldingen zullen er ongeveer hetzelfde uitzien als de voorbeelden in Figuur 8.

Figuur 8 – Meldingsbericht over gegevens- en modelafwijking

Figuur 9 – Meldingsbericht over gegevens- en modelafwijking
Inzichten met Amazon QuickSight-visualisatie:
- Doel: De klant wilde inzicht krijgen in de gegevens- en modeldrift, de driftgegevens relateren aan de respectievelijke modelmonitoringtaken en de trends in de gevolgtrekkingsgegevens ontdekken om de aard van de trends in interferentiegegevens te begrijpen.
- Oplossing: Het Wipro-team heeft de driftgegevens verrijkt door invoergegevens te verbinden met het driftresultaat, waardoor triage van drift naar monitoring en respectievelijke scoregegevens mogelijk is. Visualisaties en dashboards zijn gemaakt met behulp van Amazon QuickSight Met Amazone Athene als gegevensbron (met behulp van de Amazon S3 CSV-score- en driftgegevens).
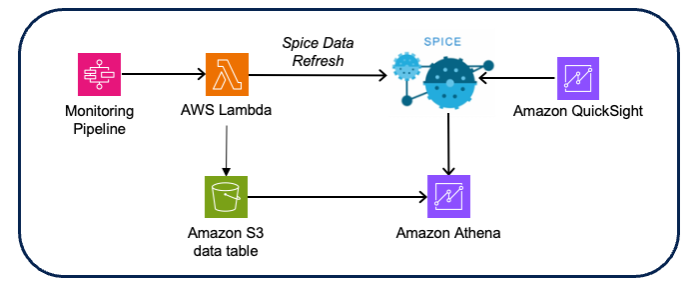
Figuur 10 – Architectuur voor visualisatie van modelmonitoring
Ontwerp Overwegingen:
- Gebruik de QuickSight Spice-gegevensset voor betere prestaties in het geheugen.
- Gebruik QuickSight-API's voor het vernieuwen van gegevenssets om het vernieuwen van Spice-gegevens te automatiseren.
- Implementeer op groepen gebaseerde beveiliging voor toegangscontrole voor dashboards en analyses.
- Automatiseer de implementatie voor verschillende accounts met behulp van export- en importgegevenssets, gegevensbronnen en analyse-API-aanroepen van QuickSight.
Dashboard voor modelmonitoring:
Om een effectief resultaat en zinvolle inzichten in de modelmonitoringtaken mogelijk te maken, zijn er aangepaste dashboards gemaakt voor de modelmonitoringgegevens. De invoergegevenspunten worden parallel gecombineerd met gegevens over inferentieverzoeken, taakgegevens en monitoringuitvoer om een visualisatie te creëren van trends die worden onthuld door de modelmonitoring.
Dit heeft het klantenteam echt geholpen om de aspecten van verschillende gegevensfuncties te visualiseren, samen met de voorspelde uitkomst van elke batch gevolgtrekkingsverzoeken.
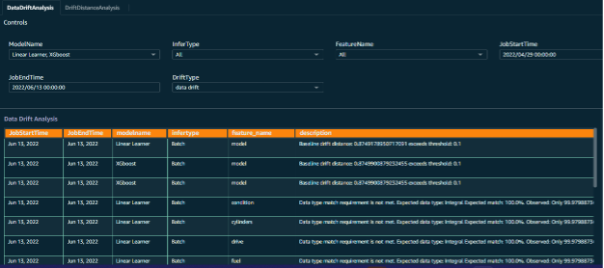
Figuur 11 – Modelmonitordashboard met selectieprompts

Figuur 12 – Analyse van modelmonitordrift
Conclusie
De implementatie die in dit bericht wordt uitgelegd, stelde Wipro in staat om hun lokale modellen effectief naar AWS te migreren en een schaalbaar, geautomatiseerd raamwerk voor modelontwikkeling te bouwen.
Het gebruik van herbruikbare raamwerkcomponenten stelt het datawetenschapsteam in staat hun werk effectief te verpakken als inzetbare AWS Step Functions JSON-componenten. Tegelijkertijd gebruikten en verbeterden de DevOps-teams de geautomatiseerde CI/CD-pijplijn om de naadloze promotie en herscholing van modellen in hogere omgevingen te vergemakkelijken.
De modelmonitoringcomponent maakt continue monitoring van de modelprestaties mogelijk en gebruikers ontvangen waarschuwingen en meldingen wanneer gegevens- of modeldrift wordt gedetecteerd.
Het team van de klant gebruikt dit MLOps-framework om meer modellen te migreren of te ontwikkelen en de adoptie van SageMaker te vergroten.
Door het uitgebreide pakket SageMaker-services te benutten in combinatie met onze zorgvuldig ontworpen architectuur, kunnen klanten naadloos meerdere modellen integreren, waardoor de implementatietijd aanzienlijk wordt verkort en de complexiteit die gepaard gaat met het delen van code wordt verminderd. Bovendien vereenvoudigt onze architectuur het onderhoud van codeversies, waardoor een gestroomlijnd ontwikkelingsproces wordt gegarandeerd.
Deze architectuur verzorgt de gehele machine learning-cyclus en omvat geautomatiseerde modeltraining, realtime en batch-inferentie, proactieve modelmonitoring en driftanalyse. Deze end-to-end oplossing stelt klanten in staat optimale modelprestaties te bereiken met behoud van rigoureuze monitoring- en analysemogelijkheden om voortdurende nauwkeurigheid en betrouwbaarheid te garanderen.
Om deze architectuur te creëren, begint u met het creëren van essentiële bronnen zoals Amazon virtuele privécloud (Amazon VPC), SageMaker-notebooks en Lambda-functies. Zorg ervoor dat u de juiste instelling uitvoert AWS identiteits- en toegangsbeheer (IAM) beleid voor deze hulpbronnen.
Concentreer u vervolgens op het bouwen van de componenten van de architectuur, zoals training en voorverwerkingsscripts, binnen SageMaker Studio of Jupyter Notebook. Deze stap omvat het ontwikkelen van de benodigde code en configuraties om de gewenste functionaliteiten mogelijk te maken.
Nadat de componenten van de architectuur zijn gedefinieerd, kunt u doorgaan met het bouwen van de Lambda-functies voor het genereren van gevolgtrekkingen of het uitvoeren van nabewerkingsstappen op de gegevens.
Gebruik uiteindelijk Step Functions om de componenten met elkaar te verbinden en een soepele workflow tot stand te brengen die de uitvoering van elke stap coördineert.
Over de auteurs
 Stephan Randolph is een Senior Partner Solutions Architect bij Amazon Web Services (AWS). Hij ondersteunt en ondersteunt Global Systems Integrator (GSI)-partners met de nieuwste AWS-technologie bij het ontwikkelen van brancheoplossingen om zakelijke uitdagingen op te lossen. Stephen is vooral gepassioneerd door beveiliging en generatieve AI, en helpt klanten en partners bij het ontwerpen van veilige, efficiënte en innovatieve oplossingen op AWS.
Stephan Randolph is een Senior Partner Solutions Architect bij Amazon Web Services (AWS). Hij ondersteunt en ondersteunt Global Systems Integrator (GSI)-partners met de nieuwste AWS-technologie bij het ontwikkelen van brancheoplossingen om zakelijke uitdagingen op te lossen. Stephen is vooral gepassioneerd door beveiliging en generatieve AI, en helpt klanten en partners bij het ontwerpen van veilige, efficiënte en innovatieve oplossingen op AWS.
 Bhajandeep Singh heeft gediend als AWS AI/ML Center of Excellence Head bij Wipro Technologies, waar hij klantbetrokkenheid leidde om data-analyse en AI-oplossingen te leveren. Hij heeft de AWS AI/ML Specialty-certificering en schrijft technische blogs over AI/ML-diensten en -oplossingen. Met ervaring met het leiden van AWS AI/ML-oplossingen in verschillende sectoren, heeft Bhajandeep klanten in staat gesteld de waarde van AWS AI/ML-diensten te maximaliseren door zijn expertise en leiderschap.
Bhajandeep Singh heeft gediend als AWS AI/ML Center of Excellence Head bij Wipro Technologies, waar hij klantbetrokkenheid leidde om data-analyse en AI-oplossingen te leveren. Hij heeft de AWS AI/ML Specialty-certificering en schrijft technische blogs over AI/ML-diensten en -oplossingen. Met ervaring met het leiden van AWS AI/ML-oplossingen in verschillende sectoren, heeft Bhajandeep klanten in staat gesteld de waarde van AWS AI/ML-diensten te maximaliseren door zijn expertise en leiderschap.
 Ajay Vishwakarma is een ML-ingenieur voor de AWS-vleugel van Wipro's AI-oplossingspraktijk. Hij heeft goede ervaring met het bouwen van BYOM-oplossingen voor aangepast algoritme in SageMaker, end-to-end ETL-pijplijnimplementatie, het bouwen van chatbots met Lex, het delen van QuickSight-bronnen tussen accounts en het bouwen van CloudFormation-sjablonen voor implementaties. Hij houdt ervan om AWS te verkennen en elk probleem van de klant als een uitdaging te beschouwen om meer te ontdekken en er oplossingen voor te bieden.
Ajay Vishwakarma is een ML-ingenieur voor de AWS-vleugel van Wipro's AI-oplossingspraktijk. Hij heeft goede ervaring met het bouwen van BYOM-oplossingen voor aangepast algoritme in SageMaker, end-to-end ETL-pijplijnimplementatie, het bouwen van chatbots met Lex, het delen van QuickSight-bronnen tussen accounts en het bouwen van CloudFormation-sjablonen voor implementaties. Hij houdt ervan om AWS te verkennen en elk probleem van de klant als een uitdaging te beschouwen om meer te ontdekken en er oplossingen voor te bieden.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/modernizing-data-science-lifecycle-management-with-aws-and-wipro/

