Het onderhouden van machine learning (ML)-workflows in de productie is een uitdagende taak, omdat het het creëren van pijplijnen voor continue integratie en continue levering (CI/CD) voor ML-code en -modellen, modelversiebeheer, monitoring van data- en conceptdrift, modelhertraining en een handleiding vereist. goedkeuringsproces om ervoor te zorgen dat nieuwe versies van het model voldoen aan zowel de prestatie- als de compliance-eisen.
In dit bericht beschrijven we hoe u een MLOps-workflow kunt maken voor batch-inferentie die taakplanning, modelmonitoring, hertraining en registratie automatiseert, evenals foutafhandeling en -melding met behulp van Amazon Sage Maker, Amazon EventBridge, AWS Lambda, Amazon eenvoudige meldingsservice (Amazon SNS), HashiCorp Terraform en GitLab CI/CD. De gepresenteerde MLOps-workflow biedt een herbruikbare sjabloon voor het beheren van de ML-levenscyclus door middel van automatisering, monitoring, controleerbaarheid en schaalbaarheid, waardoor de complexiteit en kosten van het onderhouden van batch-inferentiewerklasten in de productie worden verminderd.
Overzicht oplossingen
De volgende afbeelding illustreert de voorgestelde doel-MLOps-architectuur voor batch-inferentie voor bedrijven voor organisaties die GitLab CI/CD en Terraform-infrastructuur als code (IaC) gebruiken in combinatie met AWS-tools en -services. GitLab CI/CD fungeert als macro-orkestrator en orkestreert model build en model deploy pijpleidingen, waaronder inkoop, aanleg en bevoorrading Amazon SageMaker-pijpleidingen en ondersteunende bronnen met behulp van de SageMaker Python SDK en Terraform. SageMaker Python SDK wordt gebruikt om SageMaker-pijplijnen te maken of bij te werken voor training, training met hyperparameteroptimalisatie (HPO) en batch-inferentie. Terraform wordt gebruikt om extra bronnen te creëren, zoals EventBridge-regels, Lambda-functies en SNS-onderwerpen voor het monitoren van SageMaker-pijplijnen en het verzenden van meldingen (bijvoorbeeld wanneer een pijplijnstap mislukt of slaagt). SageMaker Pipelines fungeert als orkestrator voor ML-modeltraining en inferentieworkflows.
Dit architectuurontwerp vertegenwoordigt een strategie voor meerdere accounts waarbij ML-modellen worden gebouwd, getraind en geregistreerd in een centraal modelregister binnen een data science-ontwikkelingsaccount (dat meer controles heeft dan een typisch applicatie-ontwikkelingsaccount). Vervolgens worden inferentiepijplijnen geïmplementeerd op staging- en productieaccounts met behulp van automatisering van DevOps-tools zoals GitLab CI/CD. Optioneel kan het centrale modelregister ook in een shared services-account worden geplaatst. Verwijzen naar Operationele model voor best practices met betrekking tot een multi-accountstrategie voor ML.
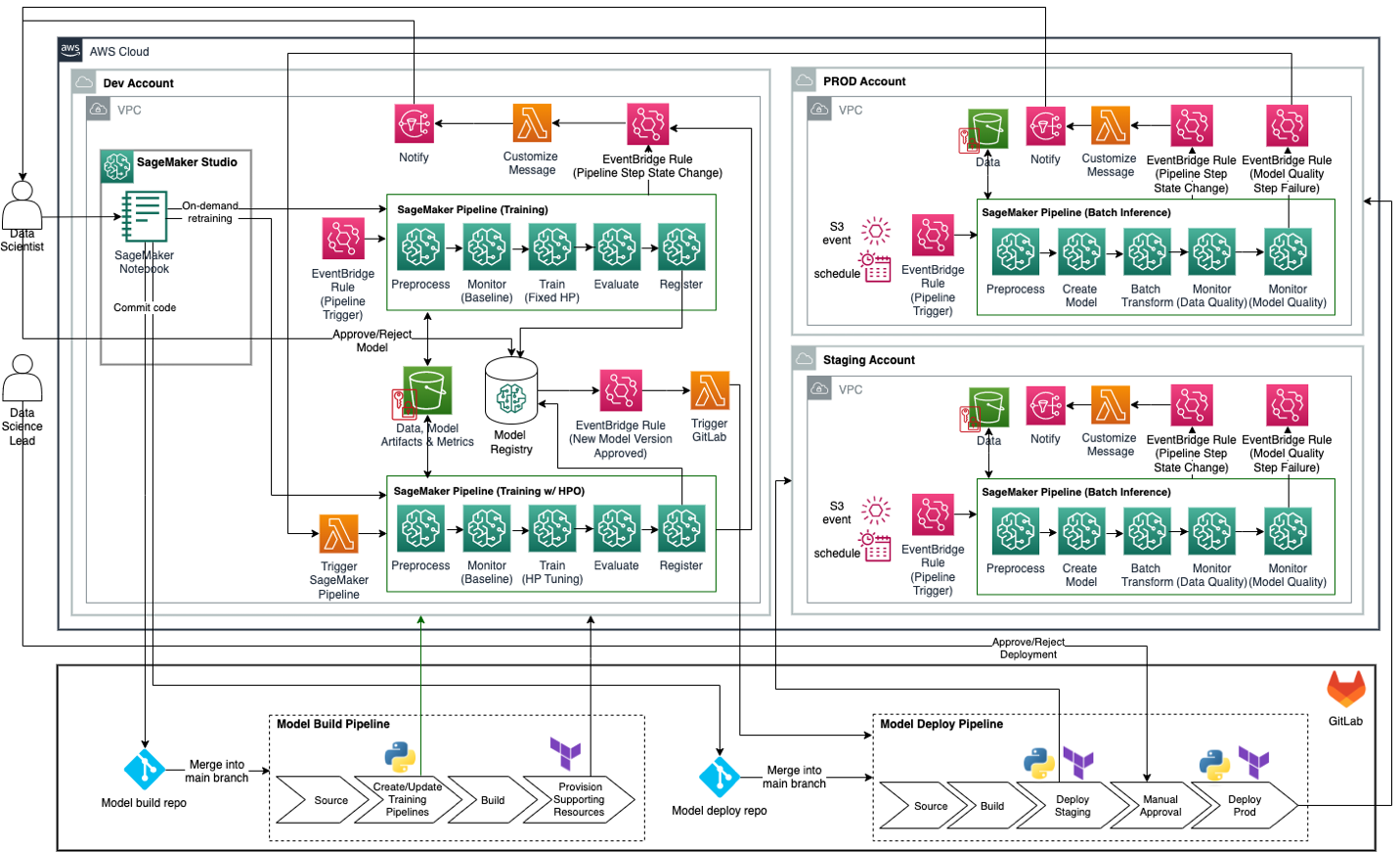
In de volgende paragrafen gaan we dieper in op verschillende aspecten van het architectuurontwerp.
Infrastructuur als code
IaC biedt een manier om de IT-infrastructuur te beheren via machinaal leesbare bestanden, waardoor efficiënt versiebeheer wordt gegarandeerd. In dit bericht en het bijbehorende codevoorbeeld laten we zien hoe u dit kunt gebruiken HashiCorp Terraform met GitLab CI/CD om AWS-bronnen effectief te beheren. Deze aanpak onderstreept het belangrijkste voordeel van IaC, namelijk het bieden van een transparant en herhaalbaar proces in het beheer van de IT-infrastructuur.
Modeltraining en omscholing
In dit ontwerp draait de SageMaker-trainingspijplijn volgens een schema (via EventBridge) of op basis van een Amazon eenvoudige opslagservice (Amazon S3) gebeurtenistrigger (bijvoorbeeld wanneer een triggerbestand of nieuwe trainingsgegevens, in het geval van een enkel trainingsgegevensobject, in Amazon S3 worden geplaatst) om het model regelmatig opnieuw te kalibreren met nieuwe gegevens. Deze pijplijn introduceert geen structurele of materiële wijzigingen in het model, omdat er gebruik wordt gemaakt van vaste hyperparameters die zijn goedgekeurd tijdens het beoordelingsproces van het ondernemingsmodel.
De trainingspijplijn registreert de nieuw getrainde modelversie in de Amazon SageMaker-modelregister als het model een vooraf gedefinieerde prestatiedrempel voor het model overschrijdt (bijvoorbeeld RMSE voor regressie en F1-score voor classificatie). Wanneer een nieuwe versie van het model in het modelregister wordt geregistreerd, wordt er via Amazon SNS een melding aan de verantwoordelijke datawetenschapper geactiveerd. De datawetenschapper moet vervolgens de nieuwste versie van het model in de Amazon SageMaker Studio UI of via een API-aanroep met behulp van de AWS-opdrachtregelinterface (AWS CLI) of AWS SDK voor Python (Boto3) voordat de nieuwe versie van het model kan worden gebruikt voor gevolgtrekking.
De SageMaker-trainingspijplijn en de ondersteunende bronnen worden gecreëerd door het GitLab model build pijplijn, hetzij via een handmatige uitvoering van de GitLab-pijplijn, hetzij automatisch wanneer code wordt samengevoegd in de main tak van de model build Git-opslagplaats.
Batch-gevolgtrekking
De batch-inferentiepijplijn van SageMaker draait volgens een schema (via EventBridge) of ook op basis van een S3-gebeurtenistrigger. De batch-inferentiepijplijn haalt automatisch de nieuwste goedgekeurde versie van het model uit het modelregister en gebruikt deze voor inferentie. De batch-inferentiepijplijn omvat stappen voor het controleren van de gegevenskwaliteit aan de hand van een basislijn die is gemaakt door de trainingspijplijn, evenals de modelkwaliteit (modelprestaties) als er ground-truth-labels beschikbaar zijn.
Als de batch-inferentiepijplijn problemen met de gegevenskwaliteit ontdekt, wordt de verantwoordelijke datawetenschapper hiervan op de hoogte gesteld via Amazon SNS. Als er problemen met de modelkwaliteit worden ontdekt (RMSE is bijvoorbeeld groter dan een vooraf opgegeven drempelwaarde), mislukt de pijplijnstap voor de modelkwaliteitscontrole, wat op zijn beurt een EventBridge-gebeurtenis activeert om de training met de HPO-pijplijn te starten.
De batch-inferentiepijplijn van SageMaker en de ondersteunende bronnen worden gemaakt door GitLab model deploy pijplijn, hetzij via een handmatige uitvoering van de GitLab-pijplijn, hetzij automatisch wanneer code wordt samengevoegd in de main tak van de model deploy Git-opslagplaats.
Modeltuning en hertuning
De SageMaker-training met HPO-pijplijn wordt geactiveerd wanneer de stap van de modelkwaliteitscontrole van de batch-inferentiepijplijn mislukt. De modelkwaliteitscontrole wordt uitgevoerd door modelvoorspellingen te vergelijken met de daadwerkelijke ground-truth-labels. Als de modelkwaliteitsmetriek (bijvoorbeeld RMSE voor regressie en F1-score voor classificatie) niet voldoet aan een vooraf opgegeven criterium, wordt de stap van de modelkwaliteitscontrole gemarkeerd als mislukt. De SageMaker-training met HPO-pijplijn kan indien nodig ook handmatig worden geactiveerd (in de SageMaker Studio UI of via een API-aanroep met behulp van de AWS CLI of SageMaker Python SDK). Omdat de hyperparameters van het model veranderen, moet de verantwoordelijke datawetenschapper goedkeuring verkrijgen van de ondernemingsmodelbeoordelingsraad voordat de nieuwe modelversie kan worden goedgekeurd in het modelregister.
De SageMaker-training met HPO-pijplijn en de ondersteunende bronnen worden gemaakt door het GitLab model build pijplijn, hetzij via een handmatige uitvoering van de GitLab-pijplijn, hetzij automatisch wanneer code wordt samengevoegd in de main tak van de model build Git-opslagplaats.
Modelbewaking
Gegevensstatistieken en basislijnen voor beperkingen worden gegenereerd als onderdeel van de training en training met HPO-pijplijnen. Ze worden opgeslagen in Amazon S3 en ook geregistreerd bij het getrainde model in het modelregister als het model de evaluatie doorstaat. De voorgestelde architectuur voor de batch-inferentiepijplijn maakt gebruik van Amazon SageMaker-modelmonitor voor gegevenskwaliteitscontroles, tijdens het gebruik van custom Amazon SageMaker-verwerking stappen voor modelkwaliteitscontrole. Dit ontwerp ontkoppelt gegevens- en modelkwaliteitscontroles, waardoor u alleen een waarschuwingsmelding kunt sturen wanneer gegevensafwijking wordt gedetecteerd; en activeer de training met HPO-pijplijn wanneer een schending van de modelkwaliteit wordt gedetecteerd.
Modelgoedkeuring
Nadat een nieuw getraind model in het modelregister is geregistreerd, ontvangt de verantwoordelijke datawetenschapper een melding. Als het model is getraind door de trainingspijplijn (herkalibratie met nieuwe trainingsgegevens terwijl de hyperparameters zijn hersteld), is er geen goedkeuring nodig van het beoordelingscomité van het ondernemingsmodel. De datawetenschapper kan de nieuwe versie van het model zelfstandig beoordelen en goedkeuren. Aan de andere kant, als het model is getraind door de training met HPO-pijplijn (opnieuw afstemmen door hyperparameters te wijzigen), moet de nieuwe modelversie het ondernemingsbeoordelingsproces doorlopen voordat deze kan worden gebruikt voor gevolgtrekking in de productie. Wanneer het beoordelingsproces is voltooid, kan de datawetenschapper doorgaan en de nieuwe versie van het model in het modelregister goedkeuren. De status van het modelpakket wijzigen naar Approved zal een Lambda-functie activeren via EventBridge, die op zijn beurt het GitLab zal activeren model deploy pijplijn via een API-aanroep. Hierdoor wordt de batch-inferentiepijplijn van SageMaker automatisch bijgewerkt om de nieuwste goedgekeurde versie van het model voor inferentie te gebruiken.
Er zijn twee manieren om een nieuwe modelversie in het modelregister goed te keuren of af te wijzen: met behulp van de AWS SDK voor Python (Boto3) of via de gebruikersinterface van SageMaker Studio. Standaard worden zowel de trainingspijplijn als de opleiding met HPO-pijplijn ingesteld ModelApprovalStatus naar PendingManualApproval. De verantwoordelijke datawetenschapper kan de goedkeuringsstatus voor het model bijwerken door de update_model_package API van Boto3. Verwijzen naar Werk de goedkeuringsstatus van een model bij voor meer informatie over het bijwerken van de goedkeuringsstatus van een model via de gebruikersinterface van SageMaker Studio.
Gegevens I/O-ontwerp
SageMaker werkt rechtstreeks samen met Amazon S3 voor het lezen van invoer en het opslaan van uitvoer van individuele stappen in de trainings- en gevolgtrekkingspijplijnen. Het volgende diagram illustreert hoe verschillende Python-scripts, onbewerkte en verwerkte trainingsgegevens, onbewerkte en verwerkte gevolgtrekkingsgegevens, gevolgtrekkingsresultaten en ground-truth-labels (indien beschikbaar voor monitoring van modelkwaliteit), modelartefacten, trainings- en gevolgtrekkingsevaluatiestatistieken (monitoring van modelkwaliteit), evenals datakwaliteitsbaselines en overtredingsrapporten (voor datakwaliteitsmonitoring) kunnen binnen een S3-bucket worden georganiseerd. De richting van de pijlen in het diagram geeft aan welke bestanden invoer of uitvoer zijn van hun respectievelijke stappen in de SageMaker-pijplijnen. De pijlen zijn kleurgecodeerd op basis van het pijplijnstaptype, zodat ze gemakkelijker leesbaar zijn. De pijplijn uploadt automatisch Python-scripts uit de GitLab-repository en slaat uitvoerbestanden of modelartefacten van elke stap op in het juiste S3-pad.
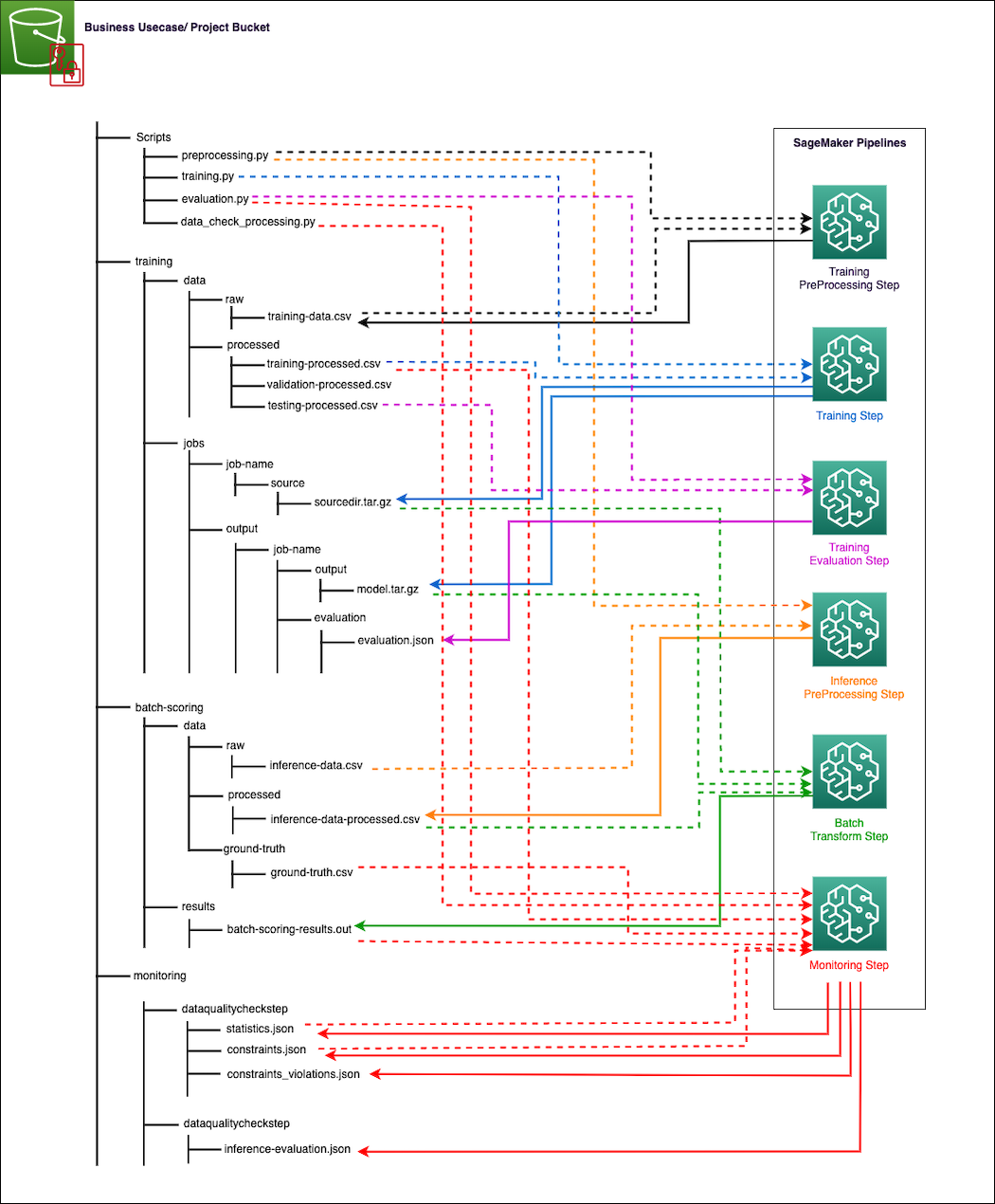
De data engineer is verantwoordelijk voor het volgende:
- Gelabelde trainingsgegevens uploaden naar het juiste pad in Amazon S3. Dit omvat onder meer het regelmatig toevoegen van nieuwe trainingsgegevens om ervoor te zorgen dat de trainingspijplijn en de training met HPO-pijplijn toegang hebben tot recente trainingsgegevens voor respectievelijk hertraining en herafstemming van modellen.
- Het uploaden van invoergegevens voor gevolgtrekking naar het juiste pad in de S3-bucket vóór een geplande uitvoering van de gevolgtrekkingspijplijn.
- Ground Truth-labels uploaden naar het juiste S3-pad voor monitoring van de modelkwaliteit.
De datawetenschapper is verantwoordelijk voor het volgende:
- Ground Truth-labels voorbereiden en deze aan het data-engineeringteam verstrekken om te uploaden naar Amazon S3.
- De modelversies die door de training met HPO-pijplijn zijn getraind, door het ondernemingsbeoordelingsproces laten gaan en de benodigde goedkeuringen verkrijgen.
- Handmatig goedkeuren of afwijzen van nieuw getrainde modelversies in het modelregister.
- Het goedkeuren van de productiepoort voor de gevolgtrekkingspijplijn en het ondersteunen van middelen die naar productie moeten worden gepromoveerd.
Voorbeeldcode
In deze sectie presenteren we een voorbeeldcode voor batch-inferentiebewerkingen met een configuratie voor één account, zoals weergegeven in het volgende architectuurdiagram. De voorbeeldcode is te vinden in de GitHub-repository, en kan dienen als uitgangspunt voor batch-inferentie met modelmonitoring en automatische herscholing met behulp van kwaliteitspoorten die vaak nodig zijn voor ondernemingen. De voorbeeldcode verschilt op de volgende manieren van de doelarchitectuur:
- Het gebruikt één AWS-account voor het bouwen en implementeren van het ML-model en ondersteunende bronnen. Verwijzen naar Uw AWS-omgeving organiseren met meerdere accounts voor hulp bij het instellen van meerdere accounts op AWS.
- Het maakt gebruik van een enkele GitLab CI/CD-pijplijn voor het bouwen en implementeren van het ML-model en ondersteunende bronnen.
- Wanneer een nieuwe versie van het model wordt getraind en goedgekeurd, wordt de GitLab CI/CD-pijplijn niet automatisch geactiveerd en moet deze handmatig worden uitgevoerd door de verantwoordelijke datawetenschapper om de SageMaker batch-inferentiepijplijn bij te werken met de nieuwste goedgekeurde versie van het model.
- Het ondersteunt alleen S3-gebeurtenisgebaseerde triggers voor het uitvoeren van de SageMaker-training en inferentiepijplijnen.
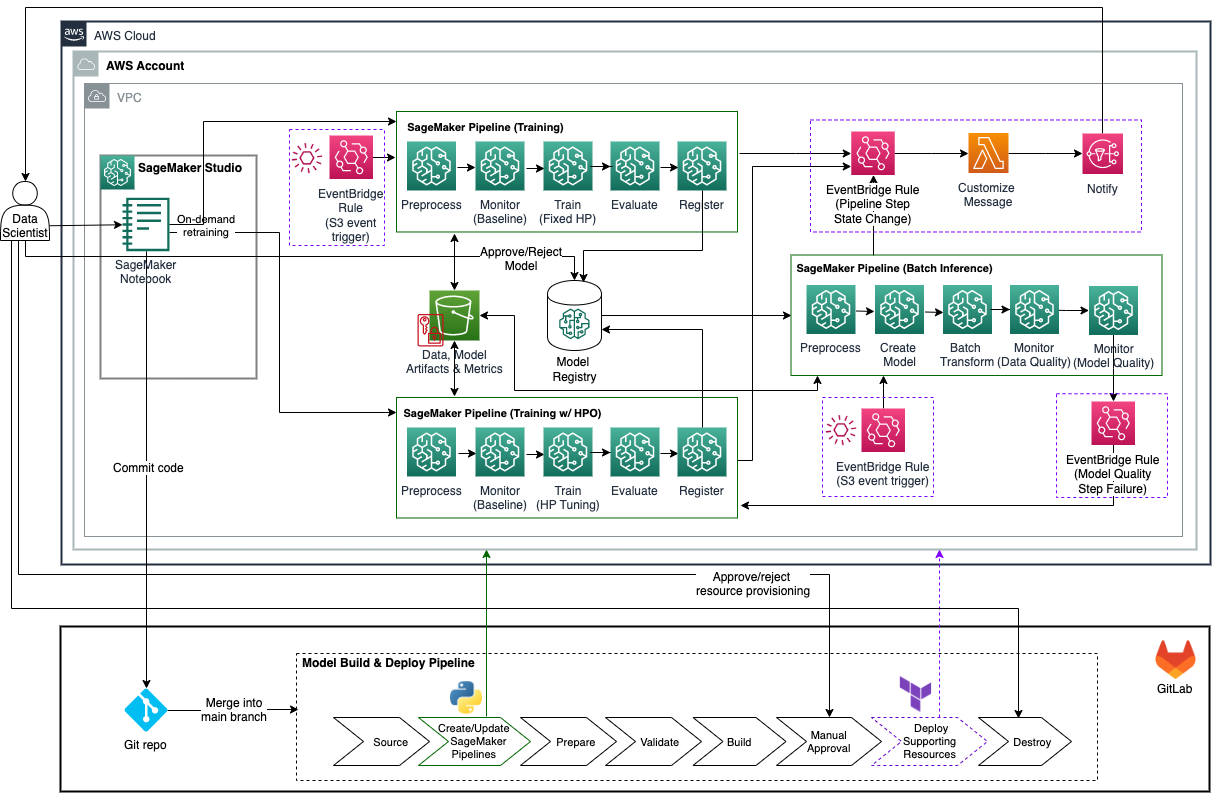
Voorwaarden
U moet aan de volgende vereisten voldoen voordat u deze oplossing implementeert:
- Een AWS-account
- SageMaker Studio
- Een SageMaker-uitvoeringsrol met Amazon S3 lezen/schrijven en AWS Sleutelbeheerservice (AWS KMS) machtigingen coderen/decoderen
- Een S3-bucket voor het opslaan van gegevens, scripts en modelartefacten
- Terraform versie 0.13.5 of hoger
- GitLab met een werkende Docker runner voor het draaien van de pijpleidingen
- De AWS CLI
- jq
- unzip
- Python3 (Python 3.7 of hoger) en de volgende Python-pakketten:
- boto3
- sagemaker
- panda's
- pyyaml
Opslagplaatsstructuur
De GitHub-repository bevat de volgende mappen en bestanden:
/code/lambda_function/– Deze map bevat het Python-bestand voor een Lambda-functie die meldingsberichten voorbereidt en verzendt (via Amazon SNS) over de stapstatuswijzigingen van de SageMaker-pijplijnen/data/– Deze map bevat de onbewerkte gegevensbestanden (gegevens over training, gevolgtrekking en grondwaarheid)/env_files/– Deze map bevat het Terraform-invoervariabelenbestand/pipeline_scripts/– Deze map bevat drie Python-scripts voor het maken en bijwerken van training, gevolgtrekking en training met HPO SageMaker-pijplijnen, evenals configuratiebestanden voor het specificeren van de parameters van elke pijplijn/scripts/– Deze map bevat aanvullende Python-scripts (zoals voorverwerking en evaluatie) waarnaar wordt verwezen door de training, gevolgtrekking en training met HPO-pijplijnen.gitlab-ci.yml– Dit bestand specificeert de GitLab CI/CD-pijplijnconfiguratie/events.tf– Dit bestand definieert EventBridge-bronnen/lambda.tf– Dit bestand definieert de Lambda-meldingsfunctie en de bijbehorende AWS Identiteits- en toegangsbeheer (IAM)-middelen/main.tf– Dit bestand definieert Terraform-gegevensbronnen en lokale variabelen/sns.tf– Dit bestand definieert Amazon SNS-bronnen/tags.json– Met dit JSON-bestand kunt u aangepaste sleutel-waardeparen voor tags declareren en deze toevoegen aan uw Terraform-bronnen met behulp van een lokale variabele/variables.tf– Dit bestand declareert alle Terraform-variabelen
Variabelen en configuratie
De volgende tabel toont de variabelen die worden gebruikt om deze oplossing te parametriseren. Verwijs naar de ./env_files/dev_env.tfvars bestand voor meer details.
| Naam | Omschrijving |
bucket_name |
S3-bucket die wordt gebruikt om gegevens, scripts en modelartefacten op te slaan |
bucket_prefix |
S3-voorvoegsel voor het ML-project |
bucket_train_prefix |
S3-voorvoegsel voor trainingsgegevens |
bucket_inf_prefix |
S3-voorvoegsel voor gevolgtrekkingsgegevens |
notification_function_name |
Naam van de Lambda-functie die meldingsberichten over de stapstatuswijzigingen van SageMaker-pijplijnen voorbereidt en verzendt |
custom_notification_config |
De configuratie voor het aanpassen van het meldingsbericht voor specifieke SageMaker-pijplijnstappen wanneer een specifieke pijplijnuitvoeringsstatus wordt gedetecteerd |
email_recipient |
De e-mailadreslijst voor het ontvangen van meldingen over stapstatuswijzigingen van SageMaker-pijplijnen |
pipeline_inf |
Naam van de SageMaker-inferentiepijplijn |
pipeline_train |
Naam van de SageMaker-trainingspijplijn |
pipeline_trainwhpo |
Naam van SageMaker-training met HPO-pijplijn |
recreate_pipelines |
Indien ingesteld op true, zullen de drie bestaande SageMaker-pijplijnen (training, inferentie, training met HPO) worden verwijderd en zullen er nieuwe worden gemaakt wanneer GitLab CI/CD wordt uitgevoerd |
model_package_group_name |
Naam van de modelpakketgroep |
accuracy_mse_threshold |
Maximale waarde van MSE voordat een update van het model vereist is |
role_arn |
IAM-rol ARN van de uitvoeringsrol van de SageMaker-pijplijn |
kms_key |
KMS-sleutel ARN voor Amazon S3- en SageMaker-codering |
subnet_id |
Subnet-ID voor SageMaker-netwerkconfiguratie |
sg_id |
Beveiligingsgroep-ID voor SageMaker-netwerkconfiguratie |
upload_training_data |
Indien ingesteld op trueworden trainingsgegevens geüpload naar Amazon S3, en deze uploadbewerking activeert de uitvoering van de trainingspijplijn |
upload_inference_data |
Indien ingesteld op true, worden gevolgtrekkingsgegevens geüpload naar Amazon S3, en deze uploadbewerking activeert de uitvoering van de gevolgtrekkingspijplijn |
user_id |
De werknemers-ID van de SageMaker-gebruiker die als tag aan SageMaker-bronnen wordt toegevoegd |
Implementeer de oplossing
Voer de volgende stappen uit om de oplossing in uw AWS-account te implementeren:
- Kloon de GitHub-repository naar uw werkmap.
- Controleer en wijzig de GitLab CI/CD-pijplijnconfiguratie zodat deze bij uw omgeving past. De configuratie wordt gespecificeerd in de
./gitlab-ci.ymlbestand. - Raadpleeg het README-bestand om de algemene oplossingsvariabelen in het
./env_files/dev_env.tfvarsbestand. Dit bestand bevat variabelen voor zowel Python-scripts als Terraform-automatisering.- Controleer de aanvullende SageMaker Pipelines-parameters die zijn gedefinieerd in de YAML-bestanden onder
./batch_scoring_pipeline/pipeline_scripts/. Controleer en update de parameters indien nodig.
- Controleer de aanvullende SageMaker Pipelines-parameters die zijn gedefinieerd in de YAML-bestanden onder
- Bekijk de scripts voor het maken van de SageMaker-pijplijn in
./pipeline_scripts/evenals de scripts waarnaar wordt verwezen in de./scripts/map. De voorbeeldscripts in de GitHub-opslagplaats zijn gebaseerd op de Abalone-gegevensset. Als u een andere dataset gaat gebruiken, zorg er dan voor dat u de scripts bijwerkt zodat deze bij uw specifieke probleem passen. - Plaats uw gegevensbestanden in het
./data/map met behulp van de volgende naamgevingsconventie. Als u de Abalone-gegevensset samen met de meegeleverde voorbeeldscripts gebruikt, zorg er dan voor dat de gegevensbestanden geen koptekst bevatten, dat de trainingsgegevens zowel onafhankelijke variabelen als doelvariabelen bevatten, waarbij de oorspronkelijke volgorde van de kolommen behouden blijft, dat de gevolgtrekkingsgegevens alleen onafhankelijke variabelen bevatten en dat de grondwaarheid bestand bevat alleen de doelvariabele.training-data.csvinference-data.csvground-truth.csv
- Voer de code door en push deze naar de repository om de uitvoering van de GitLab CI/CD-pijplijn (eerste uitvoering) te activeren. Houd er rekening mee dat de eerste pijplijnuitvoering mislukt op de
pipelinefase omdat er nog geen goedgekeurde modelversie is die het inferentiepijplijnscript kan gebruiken. Bekijk het stappenlogboek en verifieer een nieuwe SageMaker-pijplijn met de naamTrainingPipelineis met succes aangemaakt.

-
- Open de gebruikersinterface van SageMaker Studio, bekijk de trainingspijplijn en voer deze uit.
- Na de succesvolle uitvoering van de trainingspijplijn keurt u de geregistreerde modelversie goed in het modelregister en voert u vervolgens de gehele GitLab CI/CD-pijplijn opnieuw uit.
- Bekijk de uitvoer van het Terraform-plan in het
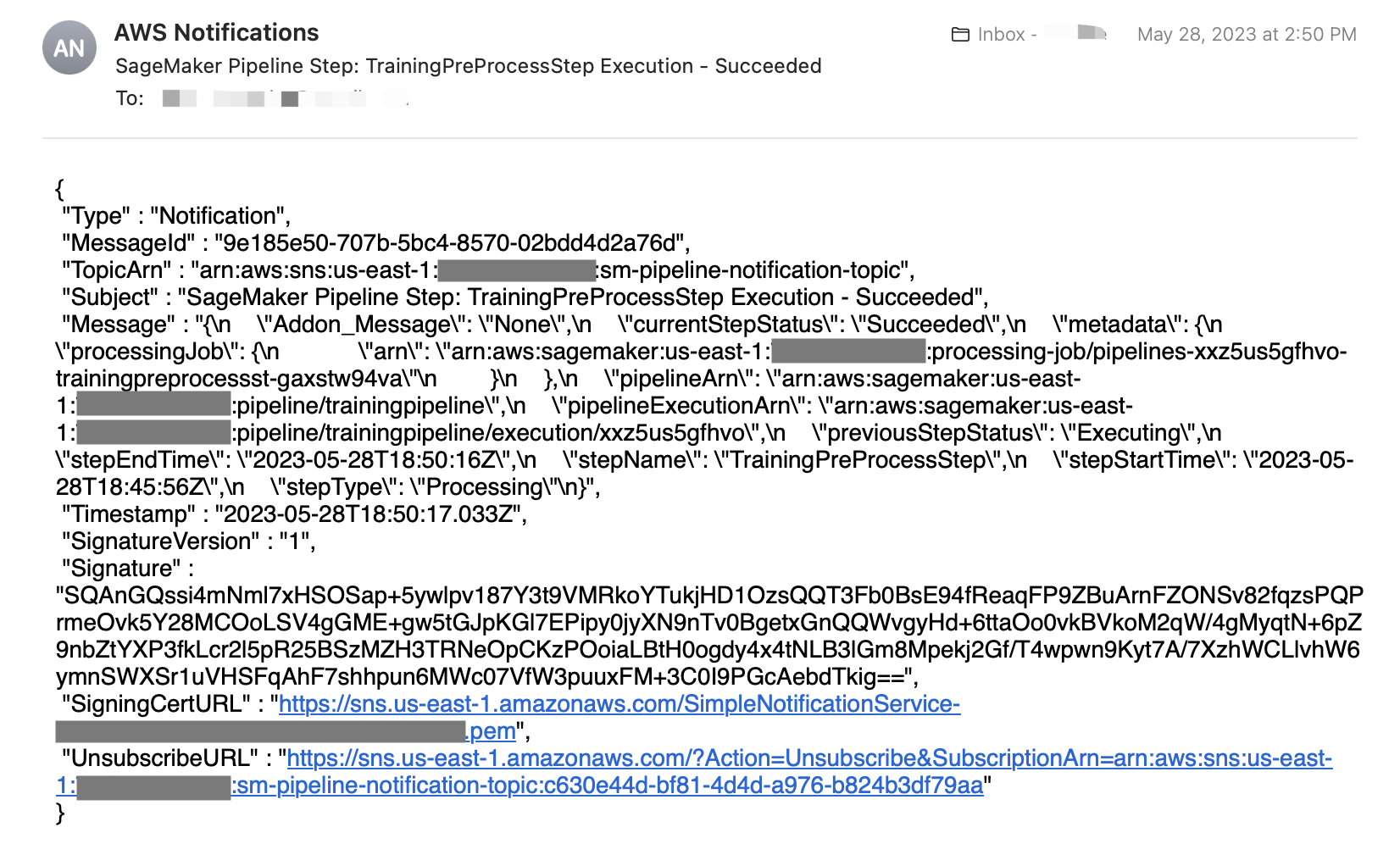
buildfase. Keur de handleiding goedapplyfase in de GitLab CI/CD-pijplijn om de pijplijnuitvoering te hervatten en Terraform te autoriseren om de monitoring- en meldingsbronnen in uw AWS-account te maken. - Controleer ten slotte de uitvoeringsstatus en uitvoer van de SageMaker-pijplijnen in de gebruikersinterface van SageMaker Studio en controleer uw e-mail op meldingsberichten, zoals weergegeven in de volgende schermafbeelding. De standaard berichttekst heeft de JSON-indeling.
SageMaker-pijplijnen
In deze sectie beschrijven we de drie SageMaker-pijplijnen binnen de MLOps-workflow.
Trainingspijplijn
De trainingspijplijn bestaat uit de volgende stappen:
- Voorverwerkingsstap, inclusief functietransformatie en codering
- Stap voor controle van de gegevenskwaliteit voor het genereren van gegevensstatistieken en de basislijn van beperkingen met behulp van de trainingsgegevens
- Trainingsstap
- Evaluatiestap voor training
- Voorwaardestap om te controleren of het getrainde model voldoet aan een vooraf opgegeven prestatiedrempel
- Modelregistratiestap om het nieuw getrainde model in het modelregister te registreren als het getrainde model voldoet aan de vereiste prestatiedrempel
Beide skip_check_data_quality en register_new_baseline_data_quality parameters zijn ingesteld True in de trainingspijplijn. Deze parameters instrueren de pijplijn om de controle van de gegevenskwaliteit over te slaan en alleen nieuwe gegevensstatistieken of basislijnen voor beperkingen te maken en te registreren met behulp van de trainingsgegevens. De volgende afbeelding toont een succesvolle uitvoering van de trainingspijplijn.

Batch-inferentiepijplijn
De batch-inferentiepijplijn bestaat uit de volgende stappen:
- Een model maken op basis van de laatst goedgekeurde modelversie in het modelregister
- Voorverwerkingsstap, inclusief functietransformatie en codering
- Batch-inferentiestap
- Voorverwerkingsstap voor de controle van de gegevenskwaliteit, waarbij een nieuw CSV-bestand wordt aangemaakt met zowel invoergegevens als modelvoorspellingen die kunnen worden gebruikt voor de controle van de gegevenskwaliteit
- Stap voor controle van gegevenskwaliteit, waarbij de invoergegevens worden gecontroleerd aan de hand van basisstatistieken en beperkingen die aan het geregistreerde model zijn gekoppeld
- Voorwaardestap om te controleren of er grondwaarheidsgegevens beschikbaar zijn. Als er grondwaarheidsgegevens beschikbaar zijn, wordt de stap voor modelkwaliteitscontrole uitgevoerd
- Berekeningsstap voor modelkwaliteit, die de modelprestaties berekent op basis van ground-truth-labels
Beide skip_check_data_quality en register_new_baseline_data_quality parameters zijn ingesteld False in de inferentiepijplijn. Deze parameters instrueren de pijplijn om een gegevenskwaliteitscontrole uit te voeren met behulp van de gegevensstatistieken of beperkingenbasislijn die is gekoppeld aan het geregistreerde model (supplied_baseline_statistics_data_quality en supplied_baseline_constraints_data_quality) en sla het maken of registreren van nieuwe gegevensstatistieken en basislijnen van beperkingen over tijdens gevolgtrekking. De volgende afbeelding illustreert een uitvoering van de batch-inferentiepijplijn waarbij de stap voor het controleren van de gegevenskwaliteit is mislukt vanwege slechte prestaties van het model op de inferentiegegevens. In dit specifieke geval wordt de training met HPO-pijplijn automatisch geactiveerd om het model te verfijnen.

Training met HPO-pijplijn
De training met HPO pipeline bestaat uit de volgende stappen:
- Voorverwerkingsstap (featuretransformatie en codering)
- Stap voor controle van de gegevenskwaliteit voor het genereren van gegevensstatistieken en de basislijn van beperkingen met behulp van de trainingsgegevens
- Afstemmingsstap voor hyperparameters
- Evaluatiestap voor training
- Conditiestap om te controleren of het getrainde model voldoet aan een vooraf gespecificeerde nauwkeurigheidsdrempel
- Modelregistratiestap als het best getrainde model voldoet aan de vereiste nauwkeurigheidsdrempel
Beide skip_check_data_quality en register_new_baseline_data_quality parameters zijn ingesteld True in de opleiding met HPO-pijplijn. De volgende afbeelding toont een succesvolle uitvoering van de training met de HPO-pijplijn.

Opruimen
Voer de volgende stappen uit om uw bronnen op te schonen:
- Gebruik de
destroyfase in de GitLab CI/CD-pijplijn om alle door Terraform geleverde bronnen te elimineren. - Gebruik de AWS CLI om lijst en verwijderen eventuele resterende pijplijnen die zijn gemaakt door de Python-scripts.
- Verwijder optioneel andere AWS-bronnen, zoals de S3-bucket of IAM-rol die buiten de CI/CD-pijplijn is gemaakt.
Conclusie
In dit bericht hebben we laten zien hoe bedrijven MLOps-workflows kunnen creëren voor hun batch-inferentietaken met behulp van Amazon SageMaker, Amazon EventBridge, AWS Lambda, Amazon SNS, HashiCorp Terraform en GitLab CI/CD. De gepresenteerde workflow automatiseert de monitoring van gegevens en modellen, het opnieuw trainen van modellen, evenals het uitvoeren van batchtaken, het versiebeheer van code en het inrichten van de infrastructuur. Dit kan leiden tot aanzienlijke verminderingen van de complexiteit en kosten van het onderhouden van batch-inferentietaken in de productie. Voor meer informatie over implementatiedetails raadpleegt u de GitHub repo.
Over de auteurs
 Hassan Shojaei is een Sr. Data Scientist bij AWS Professional Services, waar hij klanten in verschillende sectoren, zoals de sport-, verzekerings- en financiële dienstverlening, helpt bij het oplossen van hun zakelijke uitdagingen door het gebruik van big data, machine learning en cloudtechnologieën. Voorafgaand aan deze rol leidde Hasan meerdere initiatieven om nieuwe op fysica gebaseerde en datagestuurde modelleringstechnieken te ontwikkelen voor topenergiebedrijven. Buiten zijn werk heeft Hasan een passie voor boeken, wandelen, fotografie en geschiedenis.
Hassan Shojaei is een Sr. Data Scientist bij AWS Professional Services, waar hij klanten in verschillende sectoren, zoals de sport-, verzekerings- en financiële dienstverlening, helpt bij het oplossen van hun zakelijke uitdagingen door het gebruik van big data, machine learning en cloudtechnologieën. Voorafgaand aan deze rol leidde Hasan meerdere initiatieven om nieuwe op fysica gebaseerde en datagestuurde modelleringstechnieken te ontwikkelen voor topenergiebedrijven. Buiten zijn werk heeft Hasan een passie voor boeken, wandelen, fotografie en geschiedenis.
 Wenxin Liu is een Sr. Cloudinfrastructuurarchitect. Wenxin adviseert ondernemingen over hoe ze de adoptie van de cloud kunnen versnellen en ondersteunt hun innovaties op de cloud. Hij is een dierenliefhebber en heeft een passie voor snowboarden en reizen.
Wenxin Liu is een Sr. Cloudinfrastructuurarchitect. Wenxin adviseert ondernemingen over hoe ze de adoptie van de cloud kunnen versnellen en ondersteunt hun innovaties op de cloud. Hij is een dierenliefhebber en heeft een passie voor snowboarden en reizen.
 Vivek Lakshmanan is een Machine Learning-ingenieur bij Amazon. Hij heeft een masterdiploma in Software Engineering met specialisatie in Data Science en enkele jaren ervaring als MLE. Vivek is enthousiast over het toepassen van geavanceerde technologieën en het bouwen van AI/ML-oplossingen voor klanten in de cloud. Hij heeft een passie voor statistiek, NLP en modeluitlegbaarheid in AI/ML. In zijn vrije tijd speelt hij graag cricket en maakt hij roadtrips.
Vivek Lakshmanan is een Machine Learning-ingenieur bij Amazon. Hij heeft een masterdiploma in Software Engineering met specialisatie in Data Science en enkele jaren ervaring als MLE. Vivek is enthousiast over het toepassen van geavanceerde technologieën en het bouwen van AI/ML-oplossingen voor klanten in de cloud. Hij heeft een passie voor statistiek, NLP en modeluitlegbaarheid in AI/ML. In zijn vrije tijd speelt hij graag cricket en maakt hij roadtrips.
 Andy Cracchiolo is een Cloud Infrastructuur Architect. Met meer dan 15 jaar ervaring in de IT-infrastructuur is Andy een ervaren en resultaatgerichte IT-professional. Naast het optimaliseren van de IT-infrastructuur, operaties en automatisering heeft Andy een bewezen staat van dienst in het analyseren van IT-operaties, het identificeren van inconsistenties en het implementeren van procesverbeteringen die de efficiëntie verhogen, de kosten verlagen en de winst verhogen.
Andy Cracchiolo is een Cloud Infrastructuur Architect. Met meer dan 15 jaar ervaring in de IT-infrastructuur is Andy een ervaren en resultaatgerichte IT-professional. Naast het optimaliseren van de IT-infrastructuur, operaties en automatisering heeft Andy een bewezen staat van dienst in het analyseren van IT-operaties, het identificeren van inconsistenties en het implementeren van procesverbeteringen die de efficiëntie verhogen, de kosten verlagen en de winst verhogen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- ChartPrime. Verhoog uw handelsspel met ChartPrime. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/mlops-for-batch-inference-with-model-monitoring-and-retraining-using-amazon-sagemaker-hashicorp-terraform-and-gitlab-ci-cd/

