Introductie
Data zijn brandstof voor de IT-industrie en de Data Science-project in de huidige online wereld. IT-industrieën zijn sterk afhankelijk van realtime inzichten die daaruit voortkomen gegevens streamen bronnen. Het verwerken en verwerken van de streaminggegevens is het zwaarste werk Data-analyse. We weten dat streaminggegevens gegevens zijn die met een hoog volume worden uitgezonden in een continue verwerking, wat betekent dat de gegevens elke seconde veranderen. Om met deze gegevens om te gaan, gebruiken we Samenvloeiend platform – Een zelfbeheerde distributie op bedrijfsniveau van Apache Kafka.
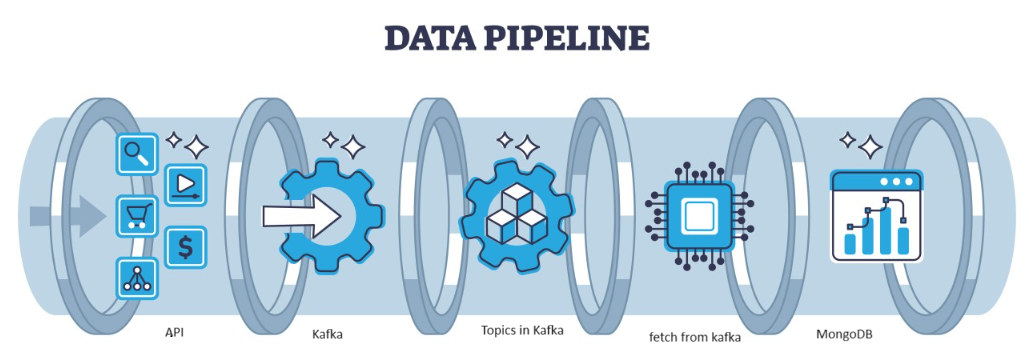
Kafka is een gedistribueerde fout die door de architectuur kan worden afgehandeld en die een populaire keuze is voor het beheren van datastromen met hoge doorvoer. De gegevens van Kafka worden vervolgens verzameld in de MongoDB in de vorm van collecties. In dit artikel gaan we de end-to-end pijplijn creëren waarin gegevens worden opgehaald met behulp van API in de Pipeline en vervolgens worden verzameld in Kafka in de vorm van onderwerpen en vervolgens worden opgeslagen in MongoDB. Van daaruit kunnen we deze gebruiken in het project of doe de feature engineering.
leerdoelen
- Ontdek wat streaminggegevens zijn en hoe u met streaminggegevens omgaat met de hulp van Kafka.
- Begrijp het Confluent Platform – Een zelfbeheerde distributie op ondernemingsniveau van Apache Kafka.
- Bewaar de gegevens die door Kafka worden verzameld in de MongoDB, een NoSQL-database die de ongestructureerde gegevens opslaat.
- Creëer een volledig end-to-end pijplijn om de gegevens in de database op te halen en op te slaan.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Identificeer het probleem
Om de streaminggegevens die van de sensor komen te verwerken, worden voertuigen die sensorgegevens bevatten per seconde geproduceerd en is het moeilijk om de gegevens te verwerken en voor te verwerken voor gebruik in de Data Science-project. Om dit probleem aan te pakken, creëren we dus een end-to-end pijplijn die de gegevens verwerkt en opslaat.
Wat zijn streaminggegevens?
Streaming gegevens zijn gegevens die continu worden gegenereerd door verschillende bronnen, wat ongestructureerde gegevens zijn. Het verwijst naar een continue stroom gegevens die in realtime of bijna realtime uit verschillende bronnen wordt gegenereerd. Bij traditionele batchverwerking worden gegevens verzameld en worden deze streaminggegevens verwerkt zodra ze worden gegenereerd. Streaminggegevens kunnen IoT-gegevens zijn, zoals temperatuursensoren en GPS-trackers, of machinegegevens. Net als gegevens worden deze gegevens gegenereerd door machines en industriële apparatuur, zoals telemetriegegevens van voertuigen en productiemachines. Er zijn streaminggegevensverwerkingsplatforms zoals Apache-Kafka.
Wat is Kafka?
Apache Kafka is een platform dat wordt gebruikt voor het bouwen van realtime datapijplijnen en streaming-applicaties. De Kafka Streams API is een krachtige bibliotheek die directe verwerking mogelijk maakt, waarmee u vensterparameters kunt verzamelen en creëren, samenvoegingen van gegevens binnen een stream kunt uitvoeren, en meer. Apache Kafka bestaat uit een opslaglaag en een rekenlaag die efficiënte, realtime data-opname, streaming datapijplijnen en opslag tussen systemen combineert.
Wat zal de aanpak zijn?
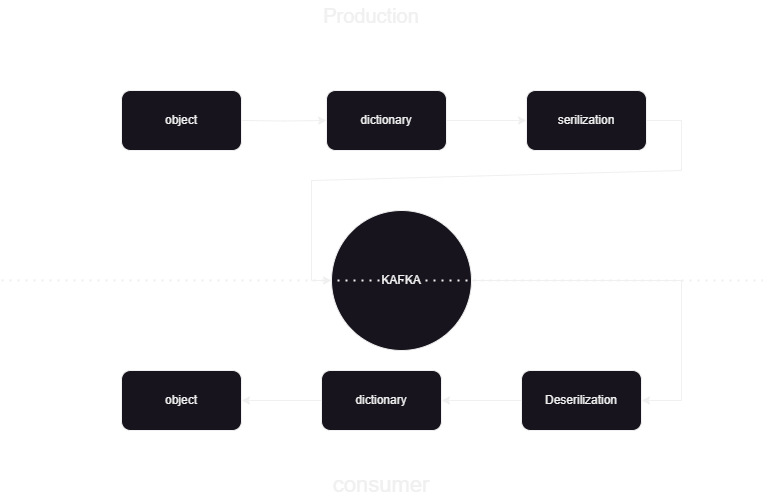
Dit is een pijplijn voor machinaal leren die ons helpt te weten hoe we de gegevens van en naar Kafka Confluent in JSON-indeling moeten publiceren en verwerken. Er zijn twee delen van kafka-gegevensverwerking, consument en producent. Om de streaminggegevens van de verschillende producenten op te slaan en samen te voegen, wordt deserialisatie van de gegevens uitgevoerd en worden die gegevens opgeslagen in de database.
Overzicht systeemarchitectuur
We verwerken de streaminggegevens met behulp van confluente kafka en de Kafka is verdeeld in twee delen:
- Kafka Producer: De Kafka Producer is verantwoordelijk voor het produceren en verzenden van gegevens naar Kafka-onderwerpen.
- Kafka Consumer: Kafka Consumer moet gegevens uit de Kafka-topics lezen en verwerken.
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
Wat zijn componenten?
- Onderwerpen: Onderwerpen zijn logische kanalen of categorieën die door producenten worden gepubliceerd. Elk onderwerp is verdeeld in een of meer partities, en elk onderwerp wordt gerepliceerd over meerdere makelaars voor fouttolerantie. Producenten publiceren gegevens over specifieke onderwerpen, en consumenten abonneren zich op onderwerpen om gegevens te gebruiken.
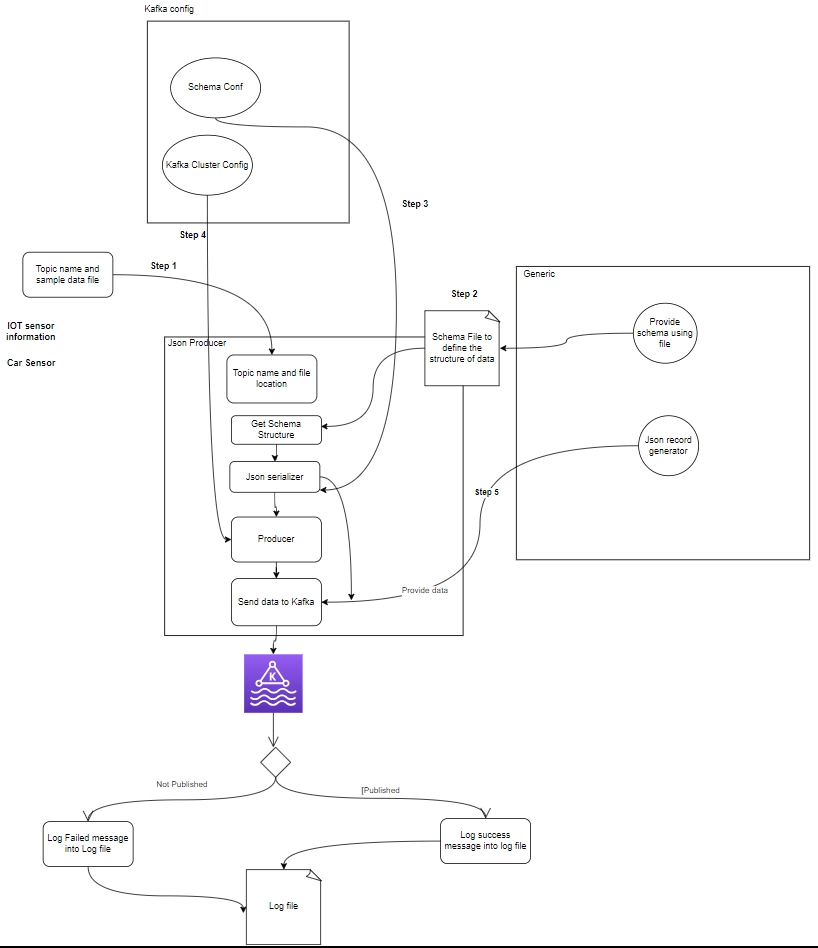
- Producenten: Een Apache Kafka Producer is een clienttoepassing die gebeurtenissen publiceert (schrijft) naar een Kafka-cluster. Applicaties die gegevens naar onderwerpen verzenden, staan bekend als Kafka-producenten. Deze sectie geeft een overzicht van de Kafka-producent.
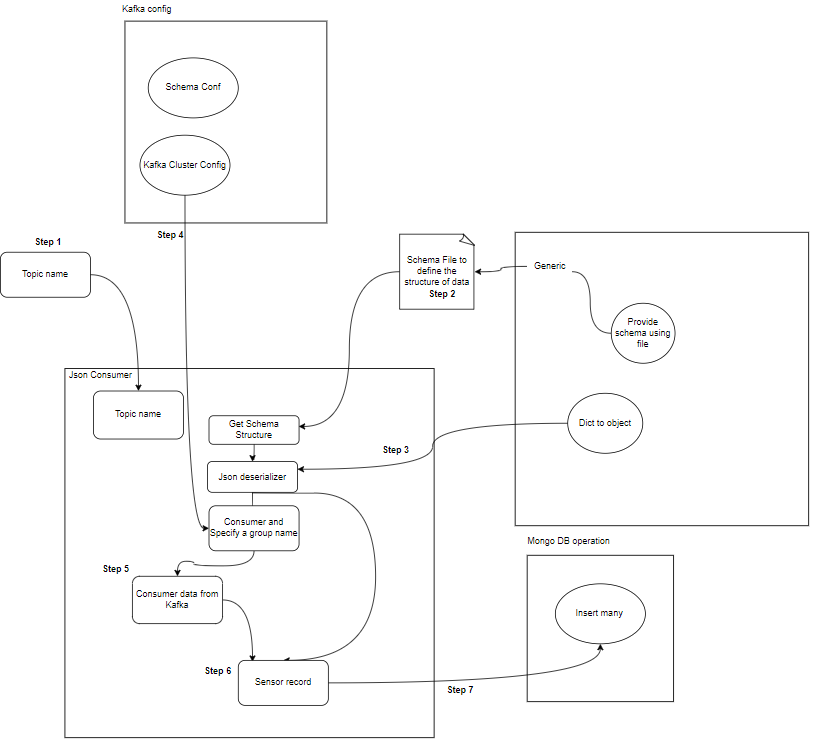
- Consument: Kafka-consumenten zijn verantwoordelijk voor het lezen en verwerken van gegevens uit Kafka-onderwerpen en het verwerken ervan. Consumenten kunnen deel uitmaken van elke applicatie die gegevens van Kafka moet gebruiken en erop moet reageren. Zij abonneren zich op één of meerdere onderwerpen en data van Kafka-makelaars. Consumenten kunnen worden georganiseerd in consumentengroepen, waarbij elke consumentengroep een of meer consumenten heeft en elk onderwerp van een onderwerp door slechts één consument binnen de groep wordt geconsumeerd. Dit maakt parallelle verwerking en taakverdeling van het dataverbruik mogelijk.
Wat is de projectstructuur?
Dit toont het stroomdiagram van het project hoe de map en de bestanden in het project zijn verdeeld:
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- Kafka-producent: De producent is het belangrijkste onderdeel dat sensorgegevens genereert (bijvoorbeeld uit CSV-bestanden in sample_data/) en deze publiceert in een Kafka-onderwerp. foutcondities die kunnen optreden tijdens het genereren of publiceren van gegevens.
- Kafka-makelaar(s): Kafka-makelaars slaan gegevens op en repliceren deze binnen het Kafka-cluster, verzorgen de gegevenspartitionering en zorgen voor fouttolerantie en hoge beschikbaarheid.
- Kafka Consument(en): Consumenten lezen gegevens uit Kafka-onderwerpen, verwerken deze (bijvoorbeeld transformaties, aggregaties) en slaan deze op in MongoDB. Ze monitoren ook foutcondities die kunnen optreden tijdens de gegevensverwerking.
- MongoDB: MongoDB slaat de sensorgegevens op die zijn ontvangen van Kafka-consumenten. Het biedt een query voor het ophalen van gegevens en zorgt voor de duurzaamheid van gegevens door middel van replicatie- en fouttolerantiemechanismen.
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
Vereisten voor gegevensopslag
Samenvloeiende Kafka
- Account aanmaken: Om Kafka te begrijpen heb je Confluent nodig. Je houdt van Apache Kafka®, maar beheert het niet. Cloud-native, complete en volledig beheerde service gaat verder dan Kafka, zodat uw beste mensen zich kunnen concentreren op het leveren van waarde aan uw bedrijf.
- Onderwerpen maken:
- Ga naar de startpagina en naar de zijbalk
- Ga naar Omgeving en klik vervolgens op Standaard
- Ga naar de onderwerpen

- selecteer het Nieuw onderwerp geef de naam van het onderwerp op

MongoDB
Maak een aanmelding en meld u vervolgens aan bij de MongoDB Atlas en bewaar de verbindingslink van de Mongodb Atlas voor verder gebruik.
Stapsgewijze handleiding voor het opzetten van projecten
- Python-installatie: Zorg ervoor dat Python op uw computer is geïnstalleerd. U kunt downloaden en installeren Python van de officiële website.
- Conda-versie: Controleer de Conda-versie in de terminal.
- Virtuele omgeving creëren: Creëer een virtuele omgeving met behulp van venv.
conda create -p venv python==3.10 -y- Activering van virtuele omgeving: Activeer de virtuele omgeving:
conda activate venv/- Installeer de vereiste pakketten: Gebruik pip om de benodigde afhankelijkheden te installeren die worden vermeld in het bestand require.txt:
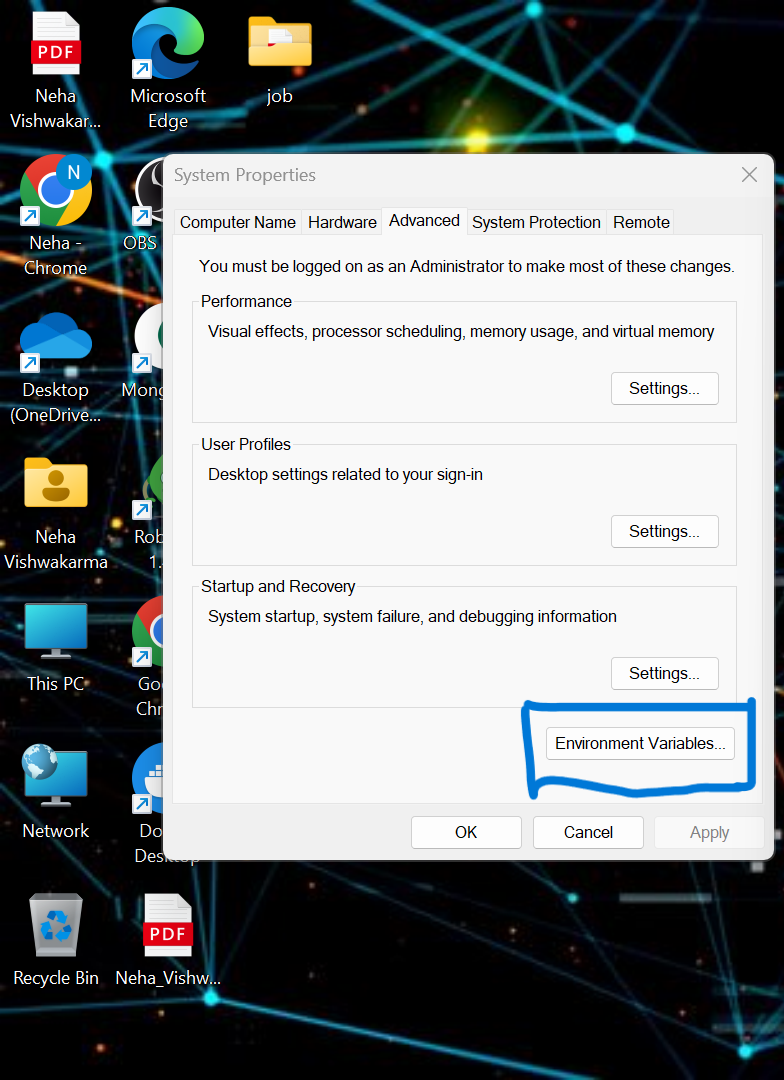
pip install -r requirements.txt- we moeten enkele omgevingsvariabelen in het lokale systeem instellen. Dit is de samenvloeiende clusteromgevingsvariabele in de cloud
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
Werk de referentie in het .env-bestand bij en voer de onderstaande opdracht uit om uw toepassing in de docker uit te voeren.
- Maak een .env-bestand in de hoofdmap van uw project als dit niet beschikbaar is, plak de onderstaande inhoud en werk de inloggegevens bij
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- Het producenten- en consumentenbestand uitvoeren:
python producer_main.py
python consumer_main.pyHoe code implementeren?
- src/: Deze map is de hoofdmap voor alle broncodebestanden. Binnen deze map hebben we de volgende submappen:
consumer/: Deze map bevat de code voor de Kafka_consumer, verantwoordelijk voor het lezen van gegevens uit Kafka-onderwerpen en het verwerken ervan.
producer/: Deze map bevat de code voor de Kafka_producer, verantwoordelijk voor het genereren en verzenden van sensorgegevens naar Kafka-onderwerpen. - LEESMIJ.md: Dit Markdown-bestand bevat documentatie en instructies voor het project, inclusief een overzicht van het doel ervan, de instructies, gebruiksrichtlijnen en eventuele informatie.
- vereisten.txt: Dit bestand bevat de Python-bibliotheek die vereist is voor het project. Elke afhankelijkheid wordt vermeld samen met het versienummer. Tools zoals pip kunnen dit bestand gebruiken om de benodigde afhankelijkheden automatisch te installeren.
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: Om de MongoDB Altas via de link te verbinden, schrijven we het Python-script
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
voer uw URL in die een kopie is van de MongoDb Altas
Output:
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
Dit bestand wordt uitgevoerd en we noemen het python producer_main.py en dit gaat het onderstaande bestand oproepen:
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
Output:

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
Dit bestand wordt uitgevoerd en we noemen het python consument_main.py en dit gaat het onderstaande bestand oproepen:
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()Output:

Wanneer we zowel de consument als de producent laten draaien, draait het systeem op de kafka en wordt de informatie/data sneller verzameld

Output:
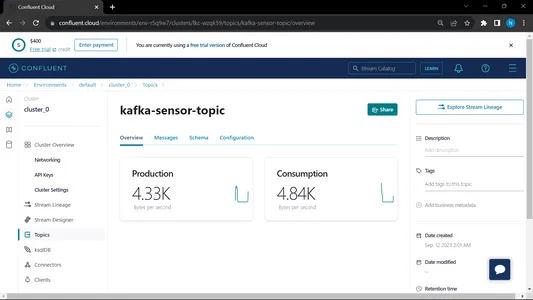
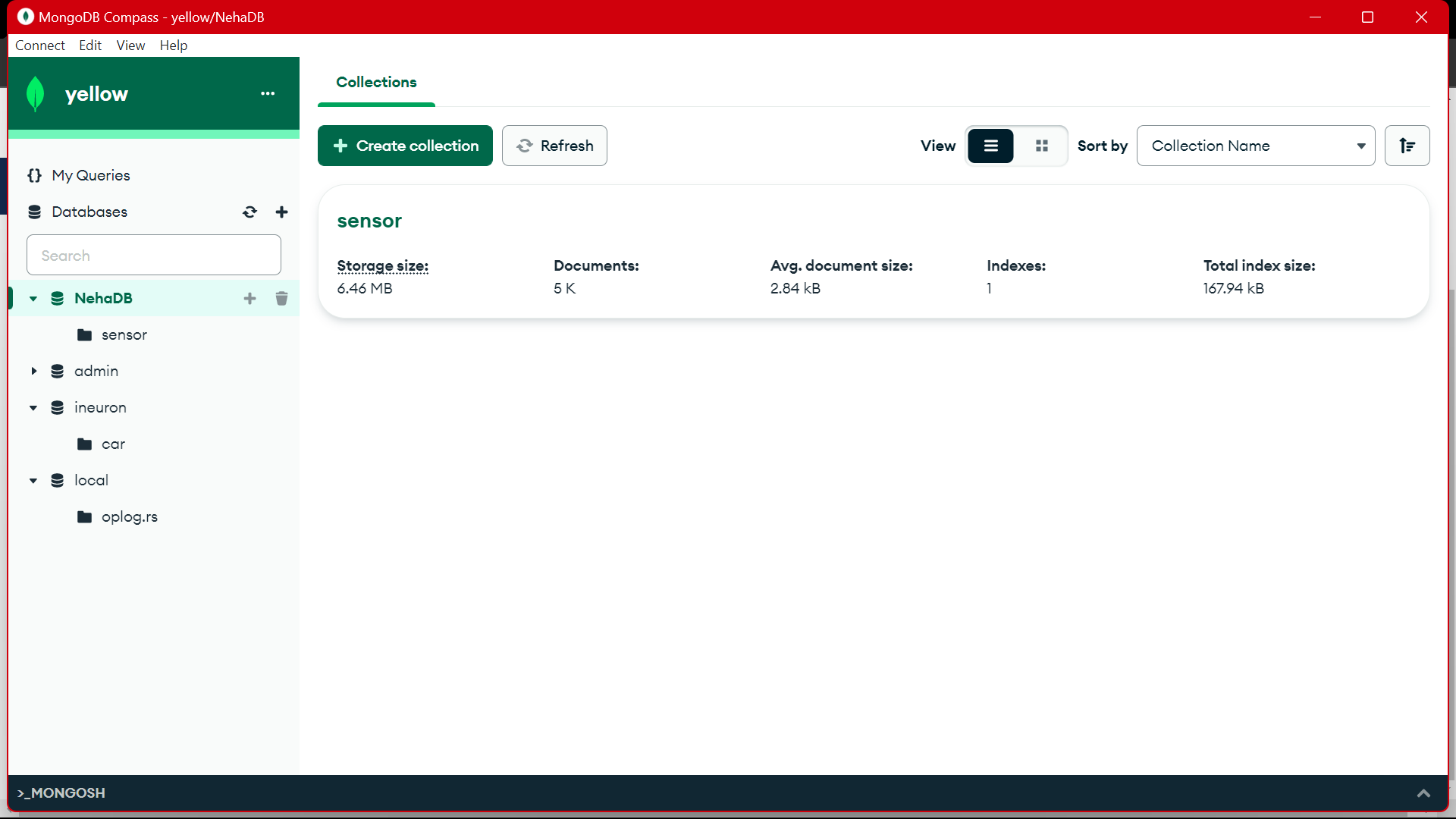
Vanuit MongoDB gebruiken we deze data voor voorbewerking in EDA, feature engineering en data-analyse worden op deze data uitgevoerd.
[Ingesloten inhoud]
Conclusie
In dit artikel begrijpen we hoe we de streaminggegevens van de sensor naar de Kafka opslaan en verwerken in de vorm van JSON-indeling, waarna we de gegevens opslaan in MongoDB. We weten dat streaminggegevens gegevens zijn die met een hoog volume worden uitgezonden in een continue verwerking, wat betekent dat de gegevens elke seconde veranderen. We hebben de end-to-end pijplijn gecreëerd waarin gegevens worden opgehaald met behulp van API in the Pipeline en vervolgens worden verzameld in Kafka in de vorm van onderwerpen en vervolgens worden opgeslagen in MongoDB. Van daaruit kunnen we deze gebruiken in het project of de functie techniek.
Key Takeaways
- Ontdek wat streaminggegevens zijn en hoe u met streaminggegevens omgaat met de hulp van Kafka.
- begrijp het Confluent Platform – Een zelfbeheerde distributie op ondernemingsniveau van Apache Kafka.
- sla de gegevens die door Kafka worden verzameld op in de MongoDB, een NoSQL-database die de ongestructureerde gegevens opslaat.
- Creëer een volledig end-to-end pijplijn om de gegevens in de database op te halen en op te slaan.
- Begrijp de functionaliteit van elk onderdeel van het project, implementeer het op de docker en implementeer het in een cloud, zodat u het op elk moment kunt gebruiken.
Resources
Veelgestelde Vragen / FAQ
A. MongoDB slaat de gegevens op in ongestructureerde gegevens. streaminggegevens zijn ongestructureerde vormen van gegevens voor geheugengebruik. We gebruiken MongoDB als database.
A. Het doel is om een realtime gegevensverwerkingspijplijn te creëren waar gegevens die zijn opgenomen in Kafka-onderwerpen kunnen worden geconsumeerd, verwerkt en opgeslagen in MongoDB voor verdere analyse, rapportage of toepassingsgebruik.
A. Gebruiksscenario's omvatten realtime analyses, IoT-gegevensverwerking, logaggregatie, monitoring van sociale media en aanbevelingssystemen, waarbij streaminggegevens moeten worden verwerkt en opgeslagen voor verdere analyse of toepassingsgebruik.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

