Dit is een gastpost geschreven door Axfood AB.
In dit bericht delen we hoe Axfood, een grote Zweedse levensmiddelenretailer, de activiteiten en schaalbaarheid van hun bestaande kunstmatige intelligentie (AI) en machine learning (ML) activiteiten verbeterde door in nauwe samenwerking met AWS-experts prototypes te maken en gebruik te maken van Amazon Sage Maker.
bijl is de op één na grootste levensmiddelenretailer van Zweden, met ruim 13,000 medewerkers en ruim 300 winkels. Axfood heeft een structuur met meerdere gedecentraliseerde data science-teams met verschillende verantwoordelijkheidsgebieden. Samen met een centraal dataplatformteam brengen de data science-teams innovatie en digitale transformatie door middel van AI- en ML-oplossingen naar de organisatie. Axfood gebruikt Amazon SageMaker om hun gegevens te cultiveren met behulp van ML en heeft al jaren modellen in productie. De laatste tijd neemt het niveau van verfijning en het enorme aantal modellen in productie exponentieel toe. Maar ook al ligt het innovatietempo hoog, de verschillende teams hadden hun eigen manier van werken ontwikkeld en waren op zoek naar een nieuwe MLOps best practice.
Onze uitdaging
Om concurrerend te blijven op het gebied van clouddiensten en AI/ML, heeft Axfood ervoor gekozen om samen te werken met AWS en werkt al vele jaren met hen samen.
Tijdens een van onze terugkerende brainstormsessies met AWS bespraken we hoe we het beste tussen teams konden samenwerken om het tempo van innovatie en efficiëntie van data science- en ML-beoefenaars te verhogen. We besloten gezamenlijk een prototype te bouwen op basis van een best practice voor MLOps. Het doel van het prototype was om een modelsjabloon te bouwen waarmee alle datawetenschapsteams schaalbare en efficiënte ML-modellen konden bouwen: de basis voor een nieuwe generatie AI- en ML-platforms voor Axfood. Het sjabloon moet best practices van AWS ML-experts en bedrijfsspecifieke best practice-modellen overbruggen en combineren: het beste van twee werelden.
We besloten een prototype te bouwen van één van de momenteel meest ontwikkelde ML-modellen binnen Axfood: verkoopvoorspellingen in winkels. Meer specifiek de voorspelling voor groenten en fruit van komende campagnes voor voedingswinkels. Nauwkeurige dagelijkse prognoses ondersteunen het bestelproces voor de winkels, waardoor de duurzaamheid wordt vergroot door voedselverspilling te minimaliseren als resultaat van het optimaliseren van de verkoop door het nauwkeurig voorspellen van de benodigde voorraadniveaus in de winkels. Dit was de perfecte plek om te beginnen voor ons prototype. Niet alleen zou Axfood een nieuw AI/ML-platform krijgen, maar we zouden ook de kans krijgen om onze ML-mogelijkheden te benchmarken en te leren van toonaangevende AWS-experts.
Onze oplossing: een nieuwe ML-sjabloon op Amazon SageMaker Studio
Het bouwen van een volledige ML-pijplijn die is ontworpen voor een daadwerkelijke business case kan een uitdaging zijn. In dit geval ontwikkelen we een voorspellingsmodel, dus er zijn twee belangrijke stappen die moeten worden uitgevoerd:
- Train het model om voorspellingen te doen met behulp van historische gegevens.
- Pas het getrainde model toe om voorspellingen te doen over toekomstige gebeurtenissen.
In het geval van Axfood was hiervoor al een goed functionerende pijplijn opgezet met behulp van SageMaker-notebooks en georkestreerd door het externe workflowbeheerplatform Airflow. Er zijn echter veel duidelijke voordelen verbonden aan het moderniseren van ons ML-platform en de overstap naar Amazon SageMaker Studio en Amazon SageMaker-pijpleidingen. Overstappen naar SageMaker Studio biedt veel vooraf gedefinieerde kant-en-klare functies:
- Bewaken van de model- en datakwaliteit en de verklaarbaarheid van het model
- Ingebouwde geïntegreerde ontwikkelomgeving (IDE)-tools zoals foutopsporing
- Kosten-/prestatiebewaking
- Modelacceptatiekader
- Modelregister
De belangrijkste stimulans voor Axfood is echter de mogelijkheid om op maat gemaakte projectsjablonen te maken met behulp van Amazon SageMaker-projecten te gebruiken als blauwdruk voor alle data science-teams en ML-beoefenaars. Het Axfood-team beschikte al over een robuust en volwassen niveau van ML-modellering, dus de nadruk lag vooral op het bouwen van de nieuwe architectuur.
Overzicht oplossingen
Het door Axfood voorgestelde nieuwe ML-framework is gestructureerd rond twee hoofdpijplijnen: de modelbouwpijplijn en de batch-inferentiepijplijn:
- Deze pijplijnen worden verdeeld in twee afzonderlijke Git-opslagplaatsen: één build-opslagplaats en één implementatie- (inferentie)-opslagplaats. Samen vormen ze een robuuste pijplijn voor het voorspellen van groenten en fruit.
- De pijplijnen zijn verpakt in een aangepaste projectsjabloon met behulp van SageMaker Projects in integratie met een externe Git-repository (Bitbucket) en Bitbucket-pijplijnen voor componenten voor continue integratie en continue implementatie (CI/CD).
- De SageMaker-projectsjabloon bevat zaadcode die overeenkomt met elke stap van het bouwen en implementeren van pijplijnen (we bespreken deze stappen later in dit bericht in meer detail) evenals de pijplijndefinitie: het recept voor hoe de stappen moeten worden uitgevoerd.
- De automatisering van het bouwen van nieuwe projecten op basis van de sjabloon wordt gestroomlijnd AWS-servicecatalogus, waar een portfolio wordt gecreëerd, dat dient als abstractie voor meerdere producten.
- Elk product vertaalt zich in een AWS CloudFormatie sjabloon, die wordt ingezet wanneer een datawetenschapper een nieuw SageMaker-project maakt met onze MLOps-blauwdruk als basis. Dit activeert een AWS Lambda functie die een Bitbucket-project creëert met twee opslagplaatsen (modelbuild en modelimplementatie) die de startcode bevatten.
Het volgende diagram illustreert de oplossingsarchitectuur. Workflow A geeft de ingewikkelde stroom weer tussen de twee modelpijplijnen: build en inferentie. Workflow B toont de stroom voor het maken van een nieuw ML-project.

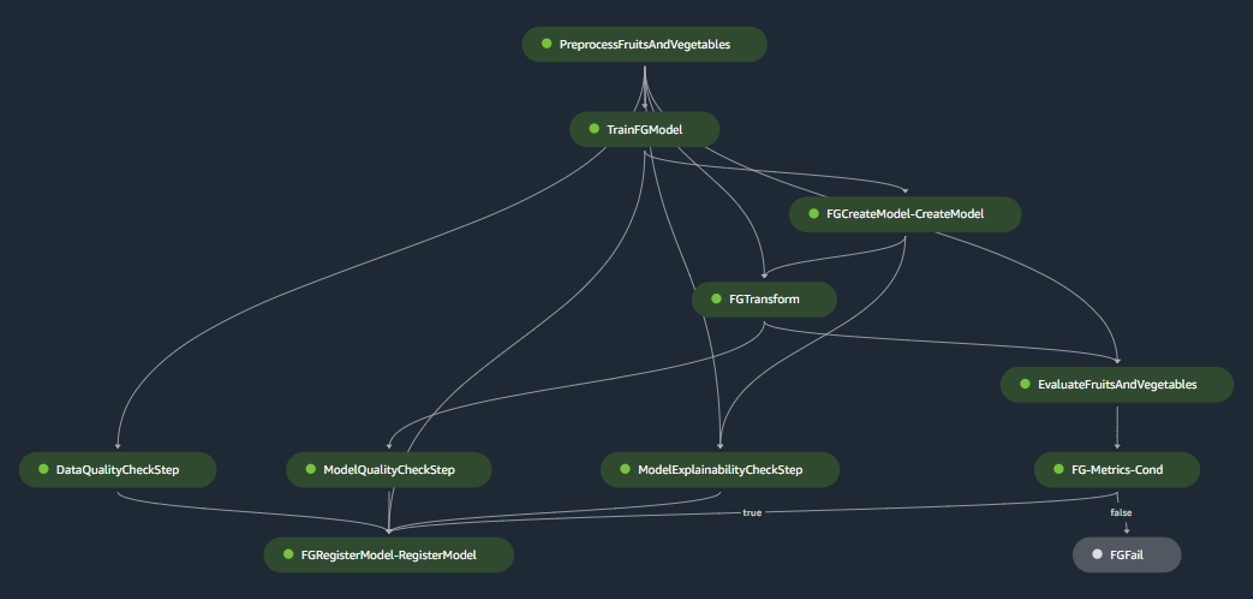
Modelbouwpijplijn
De pijplijn voor het bouwen van modellen orkestreert de levenscyclus van het model, beginnend bij de voorverwerking, via training en culminerend in registratie in het modelregister:
- Voorverwerking – Hier, de SageMaker
ScriptProcessorklasse wordt gebruikt voor feature engineering, resulterend in de dataset waarop het model zal worden getraind. - Training en batchtransformatie – Aangepaste trainings- en gevolgtrekkingscontainers van SageMaker worden ingezet om het model te trainen op basis van historische gegevens en voorspellingen te doen op basis van de evaluatiegegevens met behulp van een SageMaker Estimator en Transformer voor de respectieve taken.
- Evaluatie – Het getrainde model wordt geëvalueerd door de gegenereerde voorspellingen op basis van de evaluatiegegevens te vergelijken met de basiswaarheid
ScriptProcessor. - Basisbanen – De pijplijn creëert basislijnen op basis van statistieken in de invoergegevens. Deze zijn essentieel voor het monitoren van gegevens en modelkwaliteit, evenals voor kenmerkattributies.
- Modelregister – Het getrainde model is geregistreerd voor toekomstig gebruik. Het model zal worden goedgekeurd door aangewezen datawetenschappers om het model in te zetten voor gebruik in de productie.
Voor productieomgevingen worden gegevensopname en triggermechanismen beheerd via een primaire Airflow-orkestratie. Ondertussen wordt de pijplijn tijdens de ontwikkeling geactiveerd telkens wanneer een nieuwe commit wordt geïntroduceerd in de modelgebouwde Bitbucket-repository. De volgende afbeelding visualiseert de pijplijn voor het bouwen van modellen.
Batch-inferentiepijplijn
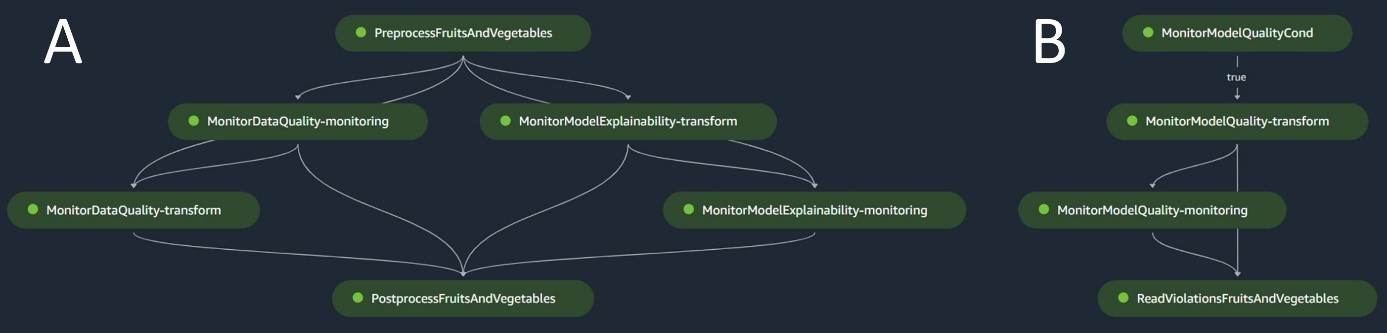
De batch-inferentiepijplijn verzorgt de inferentiefase, die uit de volgende stappen bestaat:
- Voorverwerking – Gegevens worden voorbewerkt met behulp van
ScriptProcessor. - Batch-transformatie – Het model maakt gebruik van de aangepaste inferentiecontainer met een SageMaker Transformer en genereert voorspellingen op basis van de voorverwerkte invoergegevens. Het gebruikte model is het laatst goedgekeurde getrainde model in het modelregister.
- Nabewerking – De voorspellingen ondergaan een reeks nabewerkingsstappen met behulp van
ScriptProcessor. - Monitoren – Doorlopende bewaking voltooit controles op afwijkingen met betrekking tot gegevenskwaliteit, modelkwaliteit en attributie van kenmerken.
Als er discrepanties optreden, beoordeelt een bedrijfslogica binnen het naverwerkingsscript of herscholing van het model noodzakelijk is. Het is de bedoeling dat de pijpleiding met regelmatige tussenpozen loopt.
Het volgende diagram illustreert de batch-inferentiepijplijn. Werkstroom A komt overeen met voorverwerking, gegevenskwaliteit en controles op attributie van kenmerken, gevolgtrekkingen en naverwerking. Workflow B komt overeen met driftcontroles van modelkwaliteit. Deze pijplijnen zijn verdeeld omdat de driftcontrole van de modelkwaliteit alleen wordt uitgevoerd als er nieuwe grondwaarheidsgegevens beschikbaar zijn.
SageMaker-modelmonitor
met Amazon SageMaker-modelmonitor geïntegreerd profiteren de pijpleidingen van realtime monitoring op het volgende:
- Data kwaliteit – Bewaakt eventuele afwijkingen of inconsistenties in gegevens
- Model kwaliteit – Houdt rekening met eventuele schommelingen in de prestaties van het model
- Kenmerkattributie – Controleert op afwijkingen in kenmerkattributies
Het monitoren van de modelkwaliteit vereist toegang tot ground-truth-gegevens. Hoewel het verkrijgen van de grondwaarheid soms een uitdaging kan zijn, dient het gebruik van gegevens of het monitoren van de attributie van kenmerken als een competente proxy voor het modelleren van de kwaliteit.
Concreet let het systeem bij afwijkende gegevenskwaliteit op het volgende:
- Begrip drift – Dit heeft betrekking op veranderingen in de correlatie tussen input en output, waarvoor grondwaarheid vereist is
- Covariabele verschuiving – Hier ligt de nadruk op veranderingen in de verdeling van onafhankelijke invoervariabelen
De datadrift-functionaliteit van SageMaker Model Monitor legt de invoergegevens nauwgezet vast en onderzoekt deze nauwkeurig, waarbij regels en statistische controles worden ingezet. Er worden waarschuwingen gegenereerd wanneer er afwijkingen worden gedetecteerd.
Naast het gebruik van driftcontroles op de gegevenskwaliteit als proxy voor het monitoren van modeldegradatie, monitort het systeem ook de attributiedrift van kenmerken met behulp van de genormaliseerde discounted cumulative gain (NDCG)-score. Deze score is gevoelig voor zowel veranderingen in de rangorde van de attributie van kenmerken als voor de ruwe attributiescores van kenmerken. Door het verloop van de attributie voor individuele kenmerken en hun relatieve belang te monitoren, is het eenvoudig om verslechtering van de modelkwaliteit op te sporen.
Model uitlegbaarheid
De uitlegbaarheid van modellen is een cruciaal onderdeel van ML-implementaties, omdat het transparantie in voorspellingen garandeert. Voor een gedetailleerd begrip gebruiken we Amazon SageMaker verduidelijken.
Het biedt zowel globale als lokale modelverklaringen via een model-agnostische kenmerkattributietechniek gebaseerd op het Shapley-waardeconcept. Dit wordt gebruikt om te decoderen waarom een bepaalde voorspelling is gedaan tijdens de gevolgtrekking. Dergelijke verklaringen, die inherent contrastief zijn, kunnen variëren op basis van verschillende uitgangswaarden. SageMaker Clarify helpt bij het bepalen van deze basislijn met behulp van K-means of K-prototypes in de invoergegevensset, die vervolgens wordt toegevoegd aan de modelbouwpijplijn. Deze functionaliteit stelt ons in staat om in de toekomst generatieve AI-applicaties te bouwen voor een beter begrip van hoe het model werkt.
Industrialisatie: van prototype tot productie
Het MLOps-project kent een hoge mate van automatisering en kan als blauwdruk dienen voor vergelijkbare use cases:
- De infrastructuur kan volledig worden hergebruikt, terwijl de startcode voor elke taak kan worden aangepast, waarbij de meeste wijzigingen beperkt blijven tot de pijplijndefinitie en de bedrijfslogica voor voorverwerking, training, gevolgtrekking en naverwerking.
- De trainings- en inferentiescripts worden gehost met behulp van aangepaste containers van SageMaker, zodat een verscheidenheid aan modellen kan worden ondergebracht zonder wijzigingen in de gegevens- en modelmonitoring of de stappen voor het uitleggen van modellen, zolang de gegevens in tabelvorm zijn.
Nadat we het werk aan het prototype hadden afgerond, gingen we kijken hoe we het in de productie moesten gebruiken. Om dit te doen, voelden we de behoefte om enkele aanvullende aanpassingen aan de MLOps-sjabloon aan te brengen:
- De oorspronkelijke zaadcode die in het prototype voor de sjabloon werd gebruikt, omvatte voor- en nabewerkingsstappen die vóór en na de kern-ML-stappen werden uitgevoerd (training en gevolgtrekking). Wanneer u echter opschaalt om de sjabloon voor meerdere gebruiksscenario's in de productie te gebruiken, kunnen de ingebouwde voor- en naverwerkingsstappen leiden tot een verminderde algemeenheid en reproductie van code.
- Om de algemeenheid te verbeteren en repetitieve code te minimaliseren, hebben we ervoor gekozen om de pijplijnen nog verder af te slanken. In plaats van de voor- en naverwerkingsstappen uit te voeren als onderdeel van de ML-pijplijn, voeren we deze uit als onderdeel van de primaire Airflow-orkestratie voor en na het activeren van de ML-pijplijn.
- Op deze manier worden use case-specifieke verwerkingstaken van de sjabloon geabstraheerd, en wat overblijft is een kern-ML-pijplijn die taken uitvoert die algemeen zijn voor meerdere use-cases met minimale herhaling van code. Parameters die per gebruiksscenario verschillen, worden geleverd als invoer voor de ML-pijplijn vanuit de primaire Airflow-orkestratie.
Het resultaat: een snelle en efficiënte aanpak voor het bouwen en implementeren van modellen
Het prototype in samenwerking met AWS heeft geresulteerd in een MLOps-sjabloon volgens de huidige best practices die nu beschikbaar is voor gebruik door alle datawetenschapsteams van Axfood. Door een nieuw SageMaker-project binnen SageMaker Studio te creëren, kunnen datawetenschappers snel en naadloos aan de slag met nieuwe ML-projecten en overgaan naar productie, waardoor een efficiënter tijdbeheer mogelijk wordt. Dit wordt mogelijk gemaakt door vervelende, repetitieve MLOps-taken te automatiseren als onderdeel van de sjabloon.
Verder zijn er op geautomatiseerde wijze diverse nieuwe functionaliteiten toegevoegd aan onze ML-setup. Deze winsten omvatten:
- Modelbewaking – We kunnen driftcontroles uitvoeren op model- en datakwaliteit en op de verklaarbaarheid van modellen
- Model- en datalijn – Het is nu mogelijk om precies te traceren welke data voor welk model zijn gebruikt
- Modelregister – Dit helpt ons modellen te catalogiseren voor productie en modelversies te beheren
Conclusie
In dit bericht bespraken we hoe Axfood de activiteiten en schaalbaarheid van onze bestaande AI- en ML-activiteiten verbeterde in samenwerking met AWS-experts en door SageMaker en aanverwante producten te gebruiken.
Deze verbeteringen zullen de datawetenschapsteams van Axfood helpen om ML-workflows op een meer gestandaardiseerde manier te bouwen en zullen de analyse en monitoring van modellen in productie aanzienlijk vereenvoudigen, waardoor de kwaliteit van ML-modellen die door onze teams worden gebouwd en onderhouden, wordt gegarandeerd.
Laat eventuele feedback of vragen achter in het opmerkingengedeelte.
Over de auteurs
 Dr. Björn Blomqvist is hoofd AI-strategie bij Axfood AB. Voordat hij bij Axfood AB kwam, leidde hij een team van datawetenschappers bij Dagab, een onderdeel van Axfood, waar hij innovatieve machine learning-oplossingen bouwde met de missie om mensen in heel Zweden goed en duurzaam voedsel te bieden. Geboren en getogen in het noorden van Zweden, waagt Björn zich in zijn vrije tijd naar besneeuwde bergen en open zeeën.
Dr. Björn Blomqvist is hoofd AI-strategie bij Axfood AB. Voordat hij bij Axfood AB kwam, leidde hij een team van datawetenschappers bij Dagab, een onderdeel van Axfood, waar hij innovatieve machine learning-oplossingen bouwde met de missie om mensen in heel Zweden goed en duurzaam voedsel te bieden. Geboren en getogen in het noorden van Zweden, waagt Björn zich in zijn vrije tijd naar besneeuwde bergen en open zeeën.
 Oskar Klang is Senior Data Scientist op de analytics-afdeling van Dagab, waar hij graag werkt met alles wat met analytics en machine learning te maken heeft, bijvoorbeeld het optimaliseren van supply chain-operaties, het bouwen van voorspellingsmodellen en, meer recentelijk, GenAI-applicaties. Hij zet zich in voor het bouwen van meer gestroomlijnde machine learning-pijplijnen, waardoor de efficiëntie en schaalbaarheid worden verbeterd.
Oskar Klang is Senior Data Scientist op de analytics-afdeling van Dagab, waar hij graag werkt met alles wat met analytics en machine learning te maken heeft, bijvoorbeeld het optimaliseren van supply chain-operaties, het bouwen van voorspellingsmodellen en, meer recentelijk, GenAI-applicaties. Hij zet zich in voor het bouwen van meer gestroomlijnde machine learning-pijplijnen, waardoor de efficiëntie en schaalbaarheid worden verbeterd.
 Pavel Maslov is een Senior DevOps- en ML-ingenieur in het Analytic Platforms-team. Pavel heeft uitgebreide ervaring met het ontwikkelen van frameworks, infrastructuur en tools in de domeinen DevOps en ML/AI op het AWS-platform. Pavel is een van de belangrijkste spelers geweest bij het opbouwen van de fundamentele capaciteiten binnen ML bij Axfood.
Pavel Maslov is een Senior DevOps- en ML-ingenieur in het Analytic Platforms-team. Pavel heeft uitgebreide ervaring met het ontwikkelen van frameworks, infrastructuur en tools in de domeinen DevOps en ML/AI op het AWS-platform. Pavel is een van de belangrijkste spelers geweest bij het opbouwen van de fundamentele capaciteiten binnen ML bij Axfood.
 Joakim Berg is de teamleider en producteigenaar van Analytic Platforms, gevestigd in Stockholm, Zweden. Hij geeft leiding aan een team van Data Platform-end DevOps/MLOps-ingenieurs die data- en ML-platforms leveren voor de Data Science-teams. Joakim heeft vele jaren ervaring met het leiden van senior ontwikkelings- en architectuurteams uit verschillende sectoren.
Joakim Berg is de teamleider en producteigenaar van Analytic Platforms, gevestigd in Stockholm, Zweden. Hij geeft leiding aan een team van Data Platform-end DevOps/MLOps-ingenieurs die data- en ML-platforms leveren voor de Data Science-teams. Joakim heeft vele jaren ervaring met het leiden van senior ontwikkelings- en architectuurteams uit verschillende sectoren.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/how-axfood-enables-accelerated-machine-learning-throughout-the-organization-using-amazon-sagemaker/

