Dit bericht is geschreven in samenwerking met Chaoyang He, Al Nevarez en Salman Avesttimehr van FedML.
Veel organisaties implementeren machine learning (ML) om hun zakelijke besluitvorming te verbeteren door middel van automatisering en het gebruik van grote gedistribueerde datasets. Met de toegenomen toegang tot data heeft ML het potentieel om ongeëvenaarde zakelijke inzichten en kansen te bieden. Het delen van ruwe, niet-opgeschoonde gevoelige informatie op verschillende locaties brengt echter aanzienlijke veiligheids- en privacyrisico's met zich mee, vooral in gereguleerde sectoren zoals de gezondheidszorg.
Om dit probleem aan te pakken, is federatief leren (FL) een gedecentraliseerde en collaboratieve ML-trainingstechniek die gegevensprivacy biedt terwijl de nauwkeurigheid en betrouwbaarheid behouden blijven. In tegenstelling tot traditionele ML-training vindt FL-training plaats op een geïsoleerde klantlocatie met behulp van een onafhankelijke, beveiligde sessie. De client deelt alleen de uitvoermodelparameters met een gecentraliseerde server, ook wel de trainingscoördinator of aggregatieserver genoemd, en niet de daadwerkelijke gegevens die worden gebruikt om het model te trainen. Deze aanpak neemt veel zorgen over gegevensprivacy weg en maakt tegelijkertijd effectieve samenwerking op het gebied van modeltraining mogelijk.
Hoewel FL een stap is in de richting van een betere gegevensprivacy en -beveiliging, is het geen gegarandeerde oplossing. Onveilige netwerken zonder toegangscontrole en encryptie kunnen nog steeds gevoelige informatie aan aanvallers blootstellen. Bovendien kan lokaal getrainde informatie privégegevens blootleggen als deze via een gevolgtrekkingsaanval worden gereconstrueerd. Om deze risico's te beperken, maakt het FL-model gebruik van gepersonaliseerde trainingsalgoritmen en effectieve maskering en parametrisering voordat informatie wordt gedeeld met de trainingscoördinator. Sterke netwerkcontroles op lokale en gecentraliseerde locaties kunnen de risico's op inferentie en exfiltratie verder verminderen.
In dit bericht delen we een FL-aanpak met behulp van FedML, Amazon Elastic Kubernetes-service (Amazon EKS), en Amazon Sage Maker om de patiëntresultaten te verbeteren en tegelijkertijd de privacy- en beveiligingsproblemen van gegevens aan te pakken.
De behoefte aan federatief leren in de gezondheidszorg
De gezondheidszorg is sterk afhankelijk van gedistribueerde gegevensbronnen om nauwkeurige voorspellingen en beoordelingen over de patiëntenzorg te kunnen doen. Het beperken van de beschikbare gegevensbronnen om de privacy te beschermen heeft een negatieve invloed op de nauwkeurigheid van de resultaten en uiteindelijk op de kwaliteit van de patiëntenzorg. Daarom creëert ML uitdagingen voor AWS-klanten die de privacy en veiligheid tussen gedistribueerde entiteiten moeten garanderen zonder de patiëntresultaten in gevaar te brengen.
Zorgorganisaties moeten omgaan met strikte nalevingsregels, zoals de Health Insurance Portability and Accountability Act (HIPAA) in de Verenigde Staten, terwijl ze FL-oplossingen implementeren. Het garanderen van gegevensprivacy, beveiliging en compliance wordt nog belangrijker in de gezondheidszorg, waarbij robuuste encryptie, toegangscontroles, auditmechanismen en veilige communicatieprotocollen nodig zijn. Bovendien bevatten gezondheidszorgdatasets vaak complexe en heterogene datatypen, waardoor datastandaardisatie en interoperabiliteit een uitdaging zijn in FL-omgevingen.
Gebruik case-overzicht
De in dit bericht geschetste use case betreft gegevens over hartziekten in verschillende organisaties, waarop een ML-model classificatie-algoritmen zal uitvoeren om hartziekten bij de patiënt te voorspellen. Omdat deze gegevens over organisaties heen verspreid zijn, gebruiken we federatief leren om de bevindingen te verzamelen.
De Gegevensset voor hartziekten van de Universiteit van Californië Irvine's Machine Learning Repository is een veelgebruikte dataset voor cardiovasculair onderzoek en voorspellende modellering. Het bestaat uit 303 monsters, die elk een patiënt vertegenwoordigen, en bevat een combinatie van klinische en demografische kenmerken, evenals de aan- of afwezigheid van hartziekten.
Deze multivariate dataset heeft 76 attributen in de patiëntinformatie, waarvan 14 attributen het meest worden gebruikt voor het ontwikkelen en evalueren van ML-algoritmen om de aanwezigheid van hartziekten te voorspellen op basis van de gegeven attributen.
FedML-framework
Er is een ruime keuze aan FL-frameworks, maar we hebben besloten om de FedML-framework voor deze use case omdat het open source is en verschillende FL-paradigma's ondersteunt. FedML biedt een populaire open source-bibliotheek, MLOps-platform en applicatie-ecosysteem voor FL. Deze vergemakkelijken de ontwikkeling en implementatie van FL-oplossingen. Het biedt een uitgebreide reeks tools, bibliotheken en algoritmen waarmee onderzoekers en praktijkmensen FL-algoritmen kunnen implementeren en ermee kunnen experimenteren in een gedistribueerde omgeving. FedML pakt de uitdagingen aan op het gebied van gegevensprivacy, communicatie en modelaggregatie in FL en biedt een gebruiksvriendelijke interface en aanpasbare componenten. Met haar focus op samenwerking en kennisdeling wil FedML de adoptie van FL versnellen en innovatie op dit opkomende gebied stimuleren. Het FedML-framework is modelonafhankelijk, inclusief onlangs toegevoegde ondersteuning voor grote taalmodellen (LLM's). Voor meer informatie, zie FedLLM vrijgeven: bouw uw eigen grote taalmodellen op basis van bedrijfseigen gegevens met behulp van het FedML-platform.
FedML-octopus
Systeemhiërarchie en heterogeniteit vormen een belangrijke uitdaging in real-life FL-gebruiksscenario's, waarbij verschillende datasilo's een verschillende infrastructuur met CPU en GPU's kunnen hebben. In dergelijke scenario's kunt u gebruiken FedML-octopus.
FedML Octopus is het industriële platform van cross-silo FL voor training tussen organisaties en accounts. In combinatie met FedML MLOps stelt het ontwikkelaars of organisaties in staat om op een veilige manier overal en op elke schaal open samen te werken. FedML Octopus voert een gedistribueerd trainingsparadigma uit binnen elke datasilo en maakt gebruik van synchrone of asynchrone trainingen.
FedML MLOps
FedML MLOps maakt lokale ontwikkeling van code mogelijk die later overal kan worden ingezet met behulp van FedML-frameworks. Voordat u met de training begint, moet u een FedML-account aanmaken en de server- en clientpakketten in FedML Octopus aanmaken en uploaden. Voor meer details, zie stappen en Maak kennis met FedML Octopus: federatief leren opschalen naar productie met vereenvoudigde MLOps.
Overzicht oplossingen
We implementeren FedML in meerdere EKS-clusters die zijn geïntegreerd met SageMaker voor het volgen van experimenten. We gebruiken Amazon EKS-blauwdrukken voor Terraform om de benodigde infrastructuur in te zetten. EKS Blueprints helpt bij het samenstellen van complete EKS-clusters die volledig zijn opgestart met de operationele software die nodig is om workloads te implementeren en uit te voeren. Met EKS Blueprints wordt de configuratie voor de gewenste status van de EKS-omgeving, zoals het besturingsvlak, werkknooppunten en Kubernetes-add-ons, beschreven als een infrastructuur als code (IaC)-blauwdruk. Nadat een blauwdruk is geconfigureerd, kan deze worden gebruikt om consistente omgevingen te creëren voor meerdere AWS-accounts en regio's met behulp van continue implementatieautomatisering.
De inhoud die in dit bericht wordt gedeeld, weerspiegelt situaties en ervaringen uit het echte leven, maar het is belangrijk op te merken dat de inzet van deze situaties op verschillende locaties kan variëren. Hoewel we één AWS-account met afzonderlijke VPC's gebruiken, is het van cruciaal belang om te begrijpen dat individuele omstandigheden en configuraties kunnen verschillen. Daarom moet de verstrekte informatie worden gebruikt als algemene leidraad en kan aanpassing nodig zijn op basis van specifieke vereisten en lokale omstandigheden.
Het volgende diagram illustreert onze oplossingsarchitectuur.
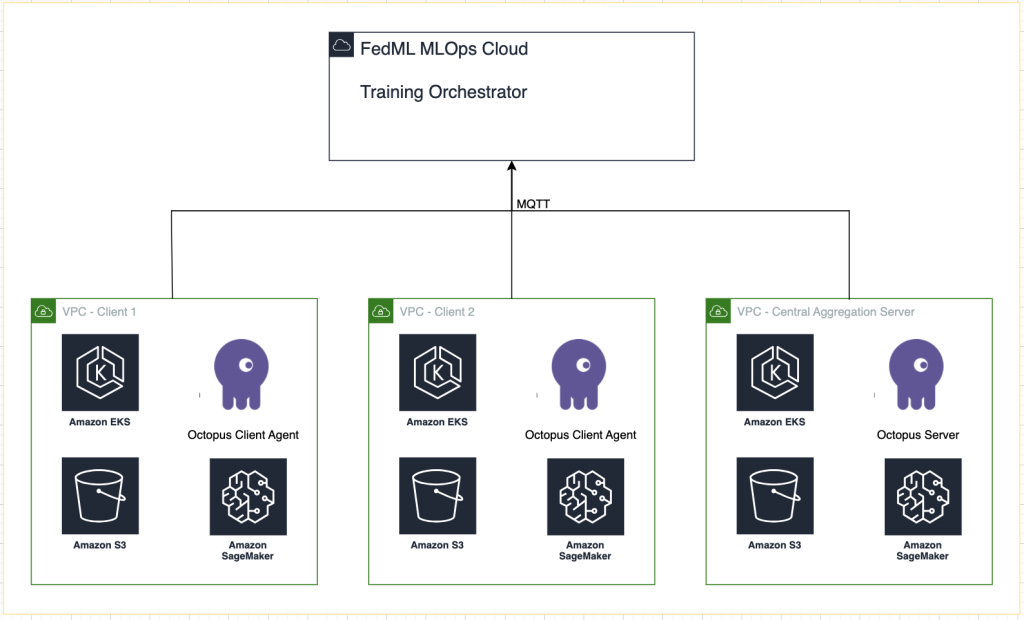
Naast de tracking die FedML MLOps voor elke trainingsrun biedt, gebruiken we Amazon SageMaker-experimenten om de prestaties van elk klantmodel en het gecentraliseerde (aggregator) model te volgen.
SageMaker Experiments is een mogelijkheid van SageMaker waarmee u uw ML-experimenten kunt maken, beheren, analyseren en vergelijken. Door experimentdetails, parameters en resultaten vast te leggen, kunnen onderzoekers hun werk nauwkeurig reproduceren en valideren. Het maakt een effectieve vergelijking en analyse van verschillende benaderingen mogelijk, wat leidt tot geïnformeerde besluitvorming. Bovendien faciliteert het volgen van experimenten iteratieve verbeteringen door inzicht te verschaffen in de voortgang van modellen en onderzoekers in staat te stellen te leren van eerdere iteraties, waardoor uiteindelijk de ontwikkeling van effectievere oplossingen wordt versneld.
Voor elke run sturen we het volgende naar SageMaker Experiments:
- Modelevaluatiestatistieken – Trainingsverlies en Area Under the Curve (AUC)
- Hyperparameters – Epoch, leersnelheid, batchgrootte, optimalisatie en gewichtsverval
Voorwaarden
Om dit bericht te volgen, moet u aan de volgende vereisten voldoen:
Implementeer de oplossing
Om te beginnen kloont u de repository die de voorbeeldcode lokaal host:
Implementeer vervolgens de use case-infrastructuur met behulp van de volgende opdrachten:
Het kan 20 tot 30 minuten duren voordat de Terraform-sjabloon volledig is geïmplementeerd. Nadat deze is geïmplementeerd, volgt u de stappen in de volgende secties om de FL-toepassing uit te voeren.
Maak een MLOps-implementatiepakket
Als onderdeel van de FedML-documentatie moeten we de client- en serverpakketten maken, die het MLOps-platform naar de server en clients zal distribueren om met de training te beginnen.
Om deze pakketten te maken, voert u het volgende script uit in de hoofdmap:
Hierdoor worden de respectievelijke pakketten aangemaakt in de volgende map in de hoofdmap van het project:
Upload de pakketten naar het FedML MLOps-platform
Voer de volgende stappen uit om de pakketten te uploaden:
- Kies in de FedML-gebruikersinterface Mijn toepassingen in het navigatievenster.
- Kies Nieuwe applicatie.
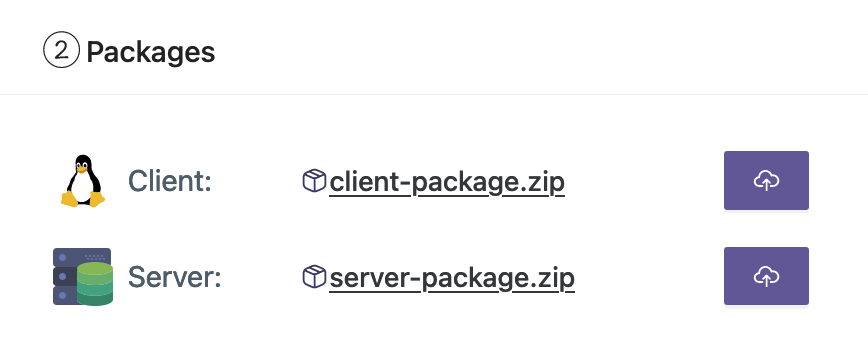
- Upload de client- en serverpakketten vanaf uw werkstation.
- U kunt ook de hyperparameters aanpassen of nieuwe aanmaken.

Activeer federatieve training
Voer de volgende stappen uit om federatieve training uit te voeren:
- Kies in de FedML-gebruikersinterface Projectlijst in het navigatievenster.
- Kies Maak een nieuw project.
- Voer een groepsnaam en een projectnaam in en kies vervolgens OK.

- Kies het nieuw gemaakte project en kies Nieuwe run maken om een trainingsloop te starten.
- Selecteer de edge-clientapparaten en de centrale aggregatorserver voor deze trainingsuitvoering.
- Kies de applicatie die u in de vorige stappen hebt gemaakt.

- Werk een van de hyperparameters bij of gebruik de standaardinstellingen.
- Kies Start om te beginnen met trainen.

- Kies de trainingsstatus tabblad en wacht tot de trainingsrun is voltooid. U kunt ook naar de beschikbare tabbladen navigeren.
- Wanneer de training is voltooid, kiest u de Systeem tabblad om de duur van de trainingstijd op uw edge-servers en aggregatiegebeurtenissen te bekijken.
Bekijk resultaten en experimentdetails
Wanneer de training is afgerond, kunt u de resultaten bekijken met FedML en SageMaker.
Op de FedML-gebruikersinterface, op de Modellen Op het tabblad kunt u de aggregator en het klantmodel zien. U kunt deze modellen ook downloaden van de website.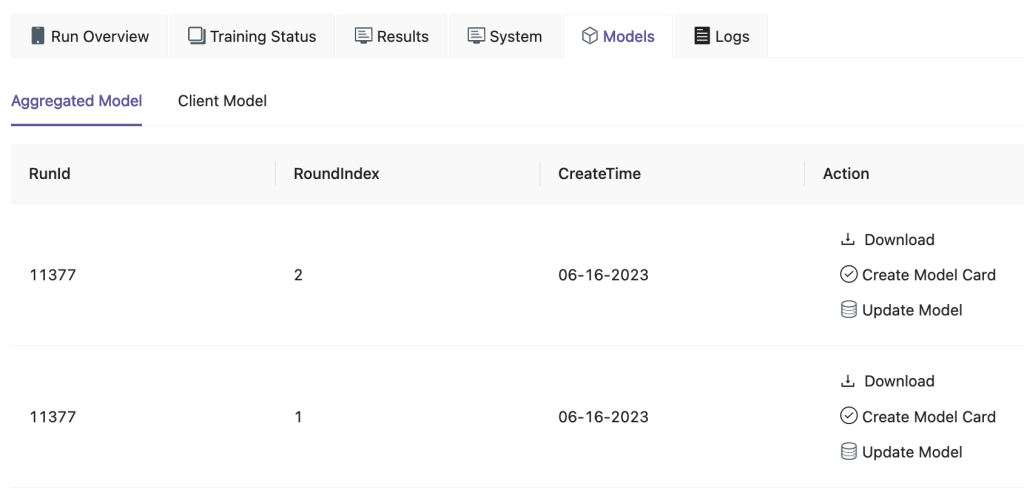
U kunt ook inloggen op Amazon SageMaker Studio En kies Experimenten in het navigatievenster.
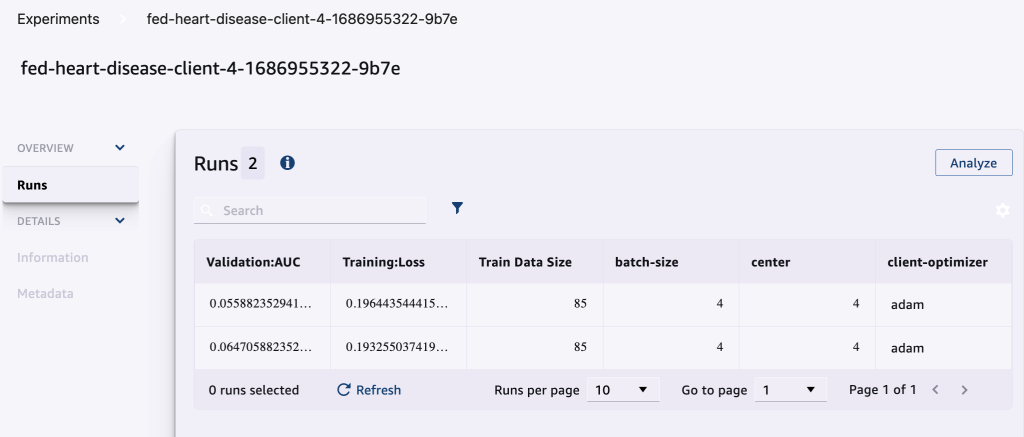
De volgende schermafbeelding toont de geregistreerde experimenten.
Experimenteer trackingcode
In deze sectie onderzoeken we de code die het volgen van SageMaker-experimenten integreert met de FL-frameworktraining.
Open in een editor naar keuze de volgende map om de wijzigingen in de code te bekijken om de trackingcode van het SageMaker-experiment te injecteren als onderdeel van de training:
Voor het volgen van de training, wij maak een SageMaker-experiment met parameters en statistieken geregistreerd met behulp van de log_parameter en log_metric opdracht zoals beschreven in het volgende codevoorbeeld.
Een vermelding in de config/fedml_config.yaml bestand declareert het experimentvoorvoegsel, waarnaar in de code wordt verwezen om unieke experimentnamen te maken: sm_experiment_name: "fed-heart-disease". U kunt dit bijwerken naar elke waarde naar keuze.
Zie bijvoorbeeld de volgende code voor de heart_disease_trainer.py, die door elke klant wordt gebruikt om het model op zijn eigen dataset te trainen:
Voor elke clientuitvoering worden de experimentdetails bijgehouden met behulp van de volgende code in heart_disease_trainer.py:
Op dezelfde manier kunt u de code gebruiken in heart_disease_aggregator.py om een test uit te voeren op lokale gegevens na het bijwerken van de modelgewichten. De details worden na elke communicatie met de klanten geregistreerd.
Opruimen
Wanneer u klaar bent met de oplossing, zorg er dan voor dat u de gebruikte resources opruimt om efficiënt resourcegebruik en kostenbeheer te garanderen en onnodige uitgaven en verspilling van resources te voorkomen. Het actief opruimen van de omgeving, zoals het verwijderen van ongebruikte instances, het stoppen van onnodige services en het verwijderen van tijdelijke gegevens, draagt bij aan een schone en georganiseerde infrastructuur. U kunt de volgende code gebruiken om uw bronnen op te schonen:
Samengevat
Door Amazon EKS als infrastructuur en FedML als raamwerk voor FL te gebruiken, kunnen we een schaalbare en beheerde omgeving bieden voor training en het inzetten van gedeelde modellen, met respect voor de gegevensprivacy. Met het gedecentraliseerde karakter van FL kunnen organisaties veilig samenwerken, het potentieel van gedistribueerde data ontsluiten en ML-modellen verbeteren zonder de privacy van gegevens in gevaar te brengen.
Zoals altijd verwelkomt AWS uw feedback. Laat uw mening en vragen achter in het opmerkingengedeelte.
Over de auteurs
 Randy DeFauw is een Senior Principal Solutions Architect bij AWS. Hij heeft een MSEE-diploma behaald aan de Universiteit van Michigan, waar hij werkte aan computervisie voor autonome voertuigen. Hij heeft ook een MBA van de Colorado State University. Randy heeft diverse functies in de technologiesector bekleed, variërend van software-engineering tot productmanagement. Hij betrad de big data-ruimte in 2013 en blijft dat gebied verkennen. Hij werkt actief aan projecten op het gebied van ML en heeft gepresenteerd op tal van conferenties, waaronder Strata en GlueCon.
Randy DeFauw is een Senior Principal Solutions Architect bij AWS. Hij heeft een MSEE-diploma behaald aan de Universiteit van Michigan, waar hij werkte aan computervisie voor autonome voertuigen. Hij heeft ook een MBA van de Colorado State University. Randy heeft diverse functies in de technologiesector bekleed, variërend van software-engineering tot productmanagement. Hij betrad de big data-ruimte in 2013 en blijft dat gebied verkennen. Hij werkt actief aan projecten op het gebied van ML en heeft gepresenteerd op tal van conferenties, waaronder Strata en GlueCon.
 Arnab Sinha is een Senior Solutions Architect voor AWS en treedt op als Field CTO om organisaties te helpen bij het ontwerpen en bouwen van schaalbare oplossingen die de bedrijfsresultaten ondersteunen bij datacentermigraties, digitale transformatie en applicatiemodernisering, big data en machine learning. Hij heeft klanten in verschillende sectoren ondersteund, waaronder energie, detailhandel, productie, gezondheidszorg en biowetenschappen. Arnab beschikt over alle AWS-certificeringen, inclusief de ML Specialty-certificering. Voordat hij bij AWS kwam, was Arnab een technologieleider en bekleedde hij voorheen architecten- en technische leiderschapsrollen.
Arnab Sinha is een Senior Solutions Architect voor AWS en treedt op als Field CTO om organisaties te helpen bij het ontwerpen en bouwen van schaalbare oplossingen die de bedrijfsresultaten ondersteunen bij datacentermigraties, digitale transformatie en applicatiemodernisering, big data en machine learning. Hij heeft klanten in verschillende sectoren ondersteund, waaronder energie, detailhandel, productie, gezondheidszorg en biowetenschappen. Arnab beschikt over alle AWS-certificeringen, inclusief de ML Specialty-certificering. Voordat hij bij AWS kwam, was Arnab een technologieleider en bekleedde hij voorheen architecten- en technische leiderschapsrollen.
 Prachi Kulkarni is een Senior Solutions Architect bij AWS. Haar specialisatie is machine learning en ze werkt actief aan het ontwerpen van oplossingen met behulp van verschillende AWS ML-, big data- en analysemogelijkheden. Prachi heeft ervaring in meerdere domeinen, waaronder de gezondheidszorg, uitkeringen, detailhandel en onderwijs, en heeft in verschillende functies gewerkt op het gebied van productengineering en -architectuur, management en klantensucces.
Prachi Kulkarni is een Senior Solutions Architect bij AWS. Haar specialisatie is machine learning en ze werkt actief aan het ontwerpen van oplossingen met behulp van verschillende AWS ML-, big data- en analysemogelijkheden. Prachi heeft ervaring in meerdere domeinen, waaronder de gezondheidszorg, uitkeringen, detailhandel en onderwijs, en heeft in verschillende functies gewerkt op het gebied van productengineering en -architectuur, management en klantensucces.
 Tamer Sherif is een Principal Solutions Architect bij AWS, met een diverse achtergrond op het gebied van technologie en bedrijfsadviesdiensten, die ruim 17 jaar als Solutions Architect heeft gewerkt. Met een focus op infrastructuur bestrijkt de expertise van Tamer een breed spectrum van verticale sectoren, waaronder de commerciële sector, de gezondheidszorg, de automobielsector, de publieke sector, productie, olie en gas, mediadiensten en meer. Zijn vaardigheid strekt zich uit tot verschillende domeinen, zoals cloudarchitectuur, edge computing, netwerken, opslag, virtualisatie, bedrijfsproductiviteit en technisch leiderschap.
Tamer Sherif is een Principal Solutions Architect bij AWS, met een diverse achtergrond op het gebied van technologie en bedrijfsadviesdiensten, die ruim 17 jaar als Solutions Architect heeft gewerkt. Met een focus op infrastructuur bestrijkt de expertise van Tamer een breed spectrum van verticale sectoren, waaronder de commerciële sector, de gezondheidszorg, de automobielsector, de publieke sector, productie, olie en gas, mediadiensten en meer. Zijn vaardigheid strekt zich uit tot verschillende domeinen, zoals cloudarchitectuur, edge computing, netwerken, opslag, virtualisatie, bedrijfsproductiviteit en technisch leiderschap.
 Hans Nesbitt is een Senior Solutions Architect bij AWS, gevestigd in Zuid-Californië. Hij werkt samen met klanten in het westen van de VS om zeer schaalbare, flexibele en veerkrachtige cloudarchitecturen te creëren. In zijn vrije tijd brengt hij graag tijd door met zijn gezin, kookt en speelt hij gitaar.
Hans Nesbitt is een Senior Solutions Architect bij AWS, gevestigd in Zuid-Californië. Hij werkt samen met klanten in het westen van de VS om zeer schaalbare, flexibele en veerkrachtige cloudarchitecturen te creëren. In zijn vrije tijd brengt hij graag tijd door met zijn gezin, kookt en speelt hij gitaar.
 Chaoyang Hij is medeoprichter en CTO van FedML, Inc., een startup die zich inzet voor een gemeenschap die open en collaboratieve AI opbouwt, waar dan ook en op elke schaal. Zijn onderzoek richt zich op gedistribueerde en federatieve machine learning-algoritmen, -systemen en -toepassingen. Hij promoveerde in computerwetenschappen aan de University of Southern California.
Chaoyang Hij is medeoprichter en CTO van FedML, Inc., een startup die zich inzet voor een gemeenschap die open en collaboratieve AI opbouwt, waar dan ook en op elke schaal. Zijn onderzoek richt zich op gedistribueerde en federatieve machine learning-algoritmen, -systemen en -toepassingen. Hij promoveerde in computerwetenschappen aan de University of Southern California.
 Al Nevarez is directeur productmanagement bij FedML. Vóór FedML was hij groepsproductmanager bij Google en senior manager data science bij LinkedIn. Hij heeft verschillende patenten op het gebied van dataproducten en heeft techniek gestudeerd aan Stanford University.
Al Nevarez is directeur productmanagement bij FedML. Vóór FedML was hij groepsproductmanager bij Google en senior manager data science bij LinkedIn. Hij heeft verschillende patenten op het gebied van dataproducten en heeft techniek gestudeerd aan Stanford University.
 Salman Avesttimehr is medeoprichter en CEO van FedML. Hij was Dean's Professor bij USC, directeur van het USC-Amazon Center on Trustworthy AI, en Amazon Scholar in Alexa AI. Hij is een expert op het gebied van federatieve en gedecentraliseerde machine learning, informatietheorie, beveiliging en privacy. Hij is een Fellow van IEEE en promoveerde in EECS aan UC Berkeley.
Salman Avesttimehr is medeoprichter en CEO van FedML. Hij was Dean's Professor bij USC, directeur van het USC-Amazon Center on Trustworthy AI, en Amazon Scholar in Alexa AI. Hij is een expert op het gebied van federatieve en gedecentraliseerde machine learning, informatietheorie, beveiliging en privacy. Hij is een Fellow van IEEE en promoveerde in EECS aan UC Berkeley.
 Samir Jongen is een ervaren bedrijfstechnoloog bij AWS die nauw samenwerkt met de C-level executives van klanten. Als voormalig C-suite executive die transformaties heeft aangestuurd bij meerdere Fortune 100-bedrijven, deelt Samir zijn waardevolle ervaringen om zijn klanten te helpen slagen in hun eigen transformatietraject.
Samir Jongen is een ervaren bedrijfstechnoloog bij AWS die nauw samenwerkt met de C-level executives van klanten. Als voormalig C-suite executive die transformaties heeft aangestuurd bij meerdere Fortune 100-bedrijven, deelt Samir zijn waardevolle ervaringen om zijn klanten te helpen slagen in hun eigen transformatietraject.
 Stefan Kraemer is bestuurs- en CxO-adviseur en voormalig directeur bij AWS. Stephen bepleit cultuur en leiderschap als de fundamenten van succes. Hij belijdt dat beveiliging en innovatie de drijvende krachten zijn achter cloudtransformatie die zeer concurrerende, datagestuurde organisaties mogelijk maken.
Stefan Kraemer is bestuurs- en CxO-adviseur en voormalig directeur bij AWS. Stephen bepleit cultuur en leiderschap als de fundamenten van succes. Hij belijdt dat beveiliging en innovatie de drijvende krachten zijn achter cloudtransformatie die zeer concurrerende, datagestuurde organisaties mogelijk maken.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/federated-learning-on-aws-using-fedml-amazon-eks-and-amazon-sagemaker/

