met Amazon EMR 6.15 uur zijn we gelanceerd AWS Lake-formatie gebaseerd op fijnmazige toegangscontroles (FGAC) op Open Table Formats (OTF's), waaronder Apache Hudi, Apache Iceberg en Delta Lake. Hierdoor kunt u de beveiliging en het beheer vereenvoudigen transactionele datameren door toegangscontroles op tabel-, kolom- en rijniveau te bieden met uw Apache Spark-taken. Veel grote ondernemingen proberen hun transactionele datameer te gebruiken om inzichten te verwerven en de besluitvorming te verbeteren. U kunt een architectuur voor een meerhuis bouwen met behulp van Amazon EMR, geïntegreerd met Lake Formation voor FGAC. Met deze combinatie van services kunt u data-analyses uitvoeren op uw transactionele data lake, terwijl u verzekerd bent van veilige en gecontroleerde toegang.
De Amazon EMR-recordservercomponent ondersteunt gegevensfilterfunctionaliteit op tabel-, kolom-, rij-, cel- en geneste attribuutniveau. Het breidt ondersteuning uit voor Hive-, Apache Hudi-, Apache Iceberg- en Delta Lake-formaten voor zowel lees- (inclusief tijdreizen en incrementele query's) als schrijfbewerkingen (op DML-instructies zoals INSERT). Bovendien introduceert Amazon EMR met versie 6.15 toegangscontrolebescherming voor de webinterface van zijn applicatie, zoals Spark History Server op het cluster, Yarn Timeline Server en Yarn Resource Manager UI.
In dit bericht laten we zien hoe u FGAC kunt implementeren Apache Hudi tabellen met behulp van Amazon EMR geïntegreerd met Lake Formation.
Gebruiksscenario voor transactiedata lake
Amazon EMR-klanten gebruiken vaak Open Table Formats om hun ACID-transactie- en tijdreisbehoeften in een datameer te ondersteunen. Door historische versies te bewaren biedt data lake tijdreizen voordelen zoals auditing en compliance, dataherstel en rollback, reproduceerbare analyse en dataverkenning op verschillende tijdstippen.
Een ander populair gebruiksscenario voor transactiedata lakes is incrementele zoekopdracht. Incrementele query's verwijzen naar een querystrategie die zich richt op het verwerken en analyseren van alleen de nieuwe of bijgewerkte gegevens binnen een datameer sinds de laatste query. Het belangrijkste idee achter incrementele zoekopdrachten is het gebruik van metagegevens of mechanismen voor het bijhouden van wijzigingen om de nieuwe of gewijzigde gegevens sinds de laatste zoekopdracht te identificeren. Door deze wijzigingen te identificeren, kan de query-engine de query optimaliseren om alleen de relevante gegevens te verwerken, waardoor de verwerkingstijd en de benodigde middelen aanzienlijk worden verminderd.
Overzicht oplossingen
In dit bericht laten we zien hoe u FGAC op Apache Hudi-tabellen kunt implementeren met behulp van Amazon EMR Amazon Elastic Compute-cloud (Amazon EC2) geïntegreerd met Lake Formation. Apache Hudi is een open source transactioneel data lake-framework dat de incrementele gegevensverwerking en de ontwikkeling van datapijplijnen aanzienlijk vereenvoudigt. Deze nieuwe FGAC-functie ondersteunt alle OTF. Naast het demonstreren met Hudi hier, zullen we andere OTF-tabellen opvolgen met andere blogs. We gebruiken laptops in Amazon SageMaker Studio om Hudi-gegevens te lezen en te schrijven via verschillende gebruikerstoegangsrechten via een EMR-cluster. Dit weerspiegelt scenario's voor gegevenstoegang in de echte wereld, bijvoorbeeld als een technische gebruiker volledige gegevenstoegang nodig heeft om problemen op een gegevensplatform op te lossen, terwijl gegevensanalisten mogelijk alleen toegang nodig hebben tot een subset van die gegevens die geen persoonlijk identificeerbare informatie (PII) bevatten. ). Integratie met Lake Formation via de Amazon EMR-runtimerol stelt u verder in staat uw gegevensbeveiliging te verbeteren en het beheer van gegevenscontrole voor Amazon EMR-workloads te vereenvoudigen. Deze oplossing zorgt voor een veilige en gecontroleerde omgeving voor gegevenstoegang, die voldoet aan de uiteenlopende behoeften en beveiligingsvereisten van verschillende gebruikers en rollen in een organisatie.
Het volgende diagram illustreert de oplossingsarchitectuur.
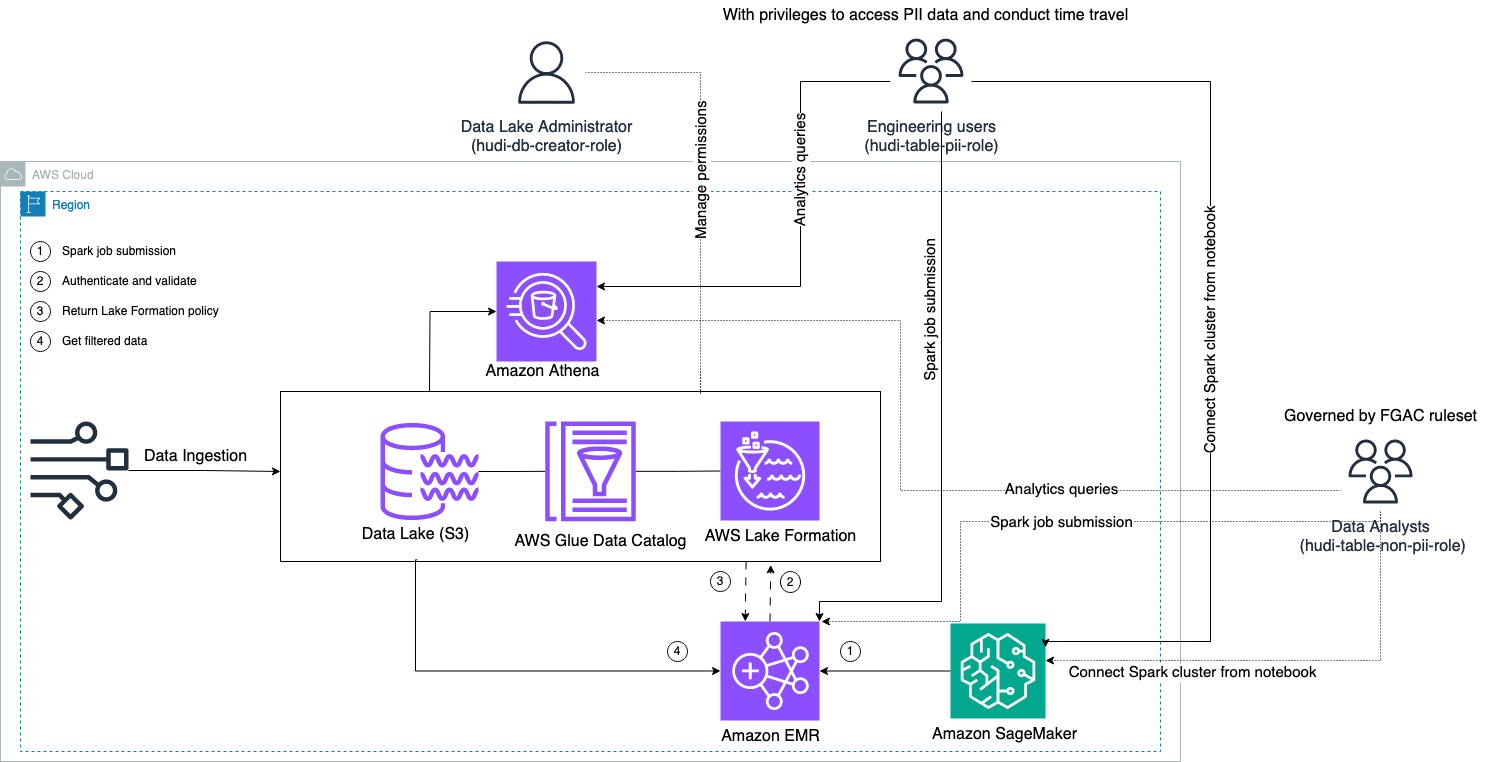
We voeren een gegevensopnameproces uit om een Hudi-gegevensset te uploaden (bij te werken en in te voegen) naar een Amazon eenvoudige opslagservice (Amazon S3) bucket, en behoud of update het tabelschema in de AWS lijm Gegevenscatalogus. Zonder gegevensbeweging kunnen we de Hudi-tabel opvragen die wordt beheerd door Lake Formation via verschillende AWS-services, zoals Amazone Athene, Amazon EMR, en Amazon Sage Maker.
Wanneer gebruikers een Spark-taak indienen via een EMR-clustereindpunt (EMR Steps, Livy, EMR Studio en SageMaker), valideert Lake Formation hun bevoegdheden en instrueert het EMR-cluster om gevoelige gegevens, zoals PII-gegevens, uit te filteren.
Deze oplossing heeft drie verschillende soorten gebruikers met verschillende machtigingsniveaus voor toegang tot de Hudi-gegevens:
- hudi-db-creator-rol – Dit wordt gebruikt door de data lake-beheerder die bevoegdheden heeft om DDL-bewerkingen uit te voeren, zoals het maken, wijzigen en verwijderen van databaseobjecten. Ze kunnen gegevensfilterregels definiëren op Lake Formation voor gegevenstoegangsbeheer op rij- en kolomniveau. Deze FGAC-regels zorgen ervoor dat het datameer beveiligd is en voldoet aan de vereiste regelgeving voor gegevensprivacy.
- hudi-table-pii-rol – Dit wordt gebruikt door technische gebruikers. De technische gebruikers zijn in staat tijdreizen en incrementele zoekopdrachten uit te voeren op zowel Copy-on-Write (CoW) als Merge-on-Read (MoR). Ze hebben ook het recht om toegang te krijgen tot PII-gegevens op basis van tijdstempels.
- hudi-table-non-pii-rol – Dit wordt gebruikt door data-analisten. De datatoegangsrechten van data-analisten worden beheerst door door FGAC geautoriseerde regels die worden beheerd door data lake-beheerders. Ze hebben geen zichtbaarheid in kolommen die PII-gegevens bevatten, zoals namen en adressen. Bovendien hebben ze geen toegang tot rijen met gegevens die niet aan bepaalde voorwaarden voldoen. De gebruikers hebben bijvoorbeeld alleen toegang tot gegevensrijen die bij hun land horen.
Voorwaarden
Je kunt de drie notitieboekjes die in dit bericht worden gebruikt downloaden van de GitHub repo.
Zorg ervoor dat u over het volgende beschikt voordat u de oplossing implementeert:
Voer de volgende stappen uit om uw machtigingen in te stellen:
- Log in op uw AWS-account met uw beheerder IAM-gebruiker.
Zorg ervoor dat u zich in hetus-east-1Regio.
- Maak een S3-bucket in het
us-east-1Regio (bijvoorbeeldemr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Vervolgens schakelen we Lake Formation in het standaardmachtigingsmodel wijzigen.
- Meld u aan bij de Lake Formation-console als beheerder.
- Kies Instellingen voor gegevenscatalogus voor Administratie in het navigatievenster.
- Onder Standaardmachtigingen voor nieuw gemaakte databases en tabellen, deselecteren Gebruik alleen IAM-toegangscontrole voor nieuwe databases en Gebruik alleen IAM-toegangscontrole voor nieuwe tabellen in nieuwe databases.
- Kies Bespaar.

Als alternatief moet u IAMAllowedPrincipals intrekken voor resources (databases en tabellen) die zijn gemaakt als u Lake Formation met de standaardoptie hebt gestart.
Ten slotte creëren we een sleutelpaar voor Amazon EMR.
- Kies op de Amazon EC2-console: Sleutelparen in het navigatievenster.
- Kies Sleutelpaar maken.
- Voor Naam, voer een naam in (bijvoorbeeld
emr-fgac-hudi-keypair). - Kies Sleutelpaar maken.
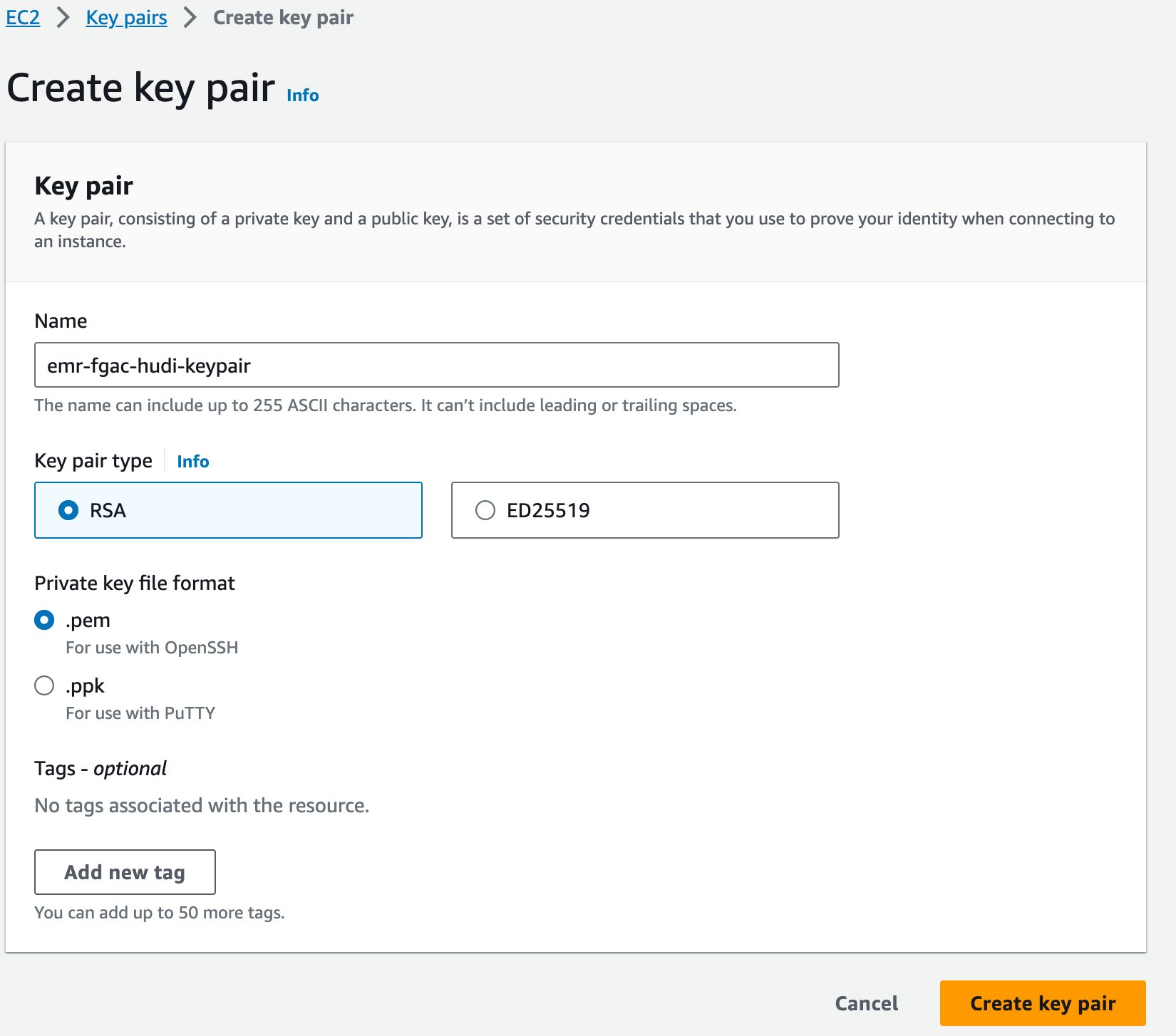
Het gegenereerde sleutelpaar (voor dit bericht, emr-fgac-hudi-keypair.pem) wordt opgeslagen op uw lokale computer.
Vervolgens maken we een AWS-Cloud9 interactieve ontwikkelomgeving (IDE).
- Kies op de AWS Cloud9-console omgevingen in het navigatievenster.
- Kies Creëer omgeving.
- Voor Naam¸ voer een naam in (bijvoorbeeld
emr-fgac-hudi-env). - Behoud de overige instellingen als standaard.
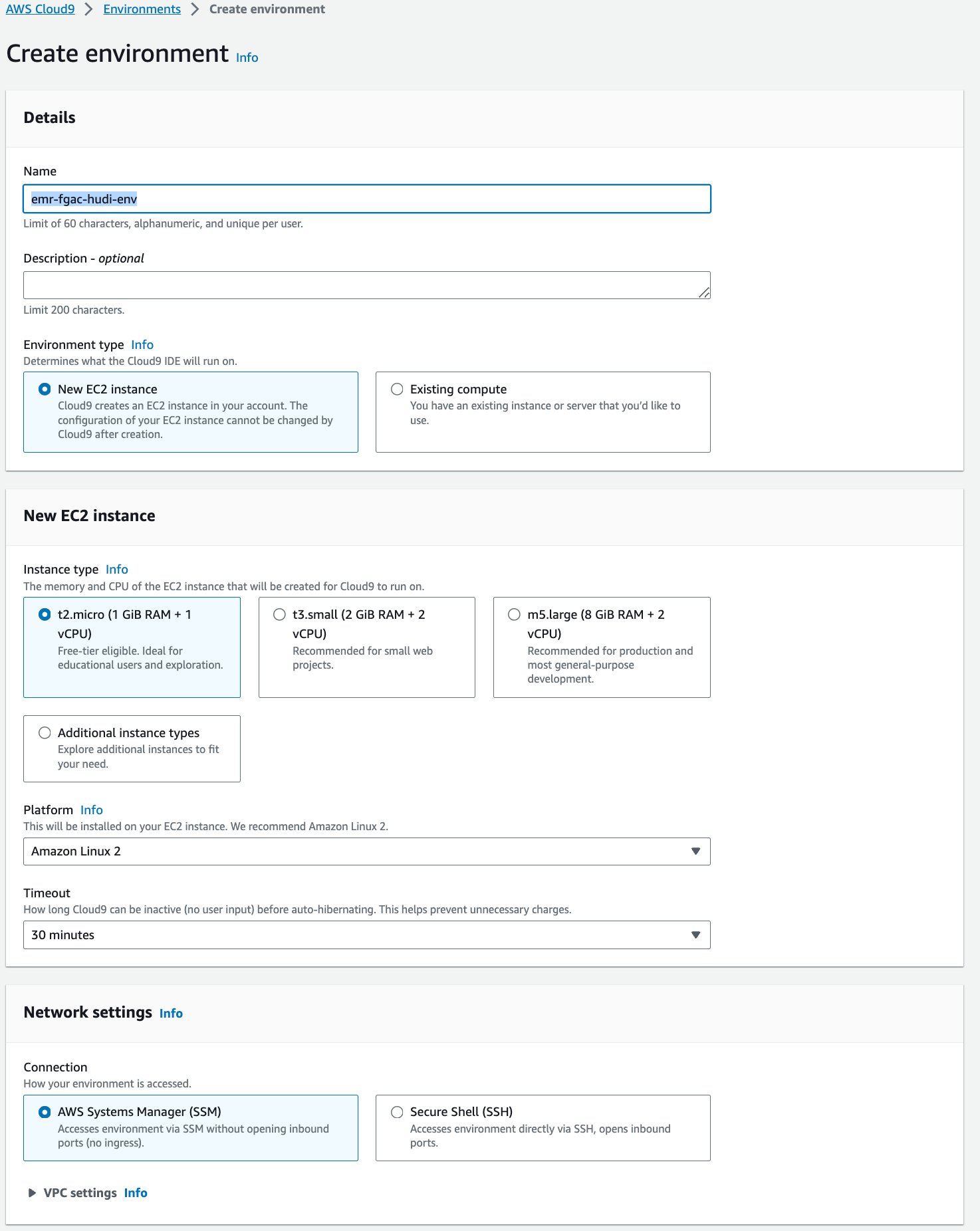
- Kies creëren.
- Wanneer de IDE gereed is, kiest u Openen om het te openen.
- In de AWS Cloud9 IDE, op de Dien in menu, kies Lokale bestanden uploaden.

- Upload het sleutelpaarbestand (
emr-fgac-hudi-keypair.pem). - Kies het plusteken en kies Nieuwe terminal.
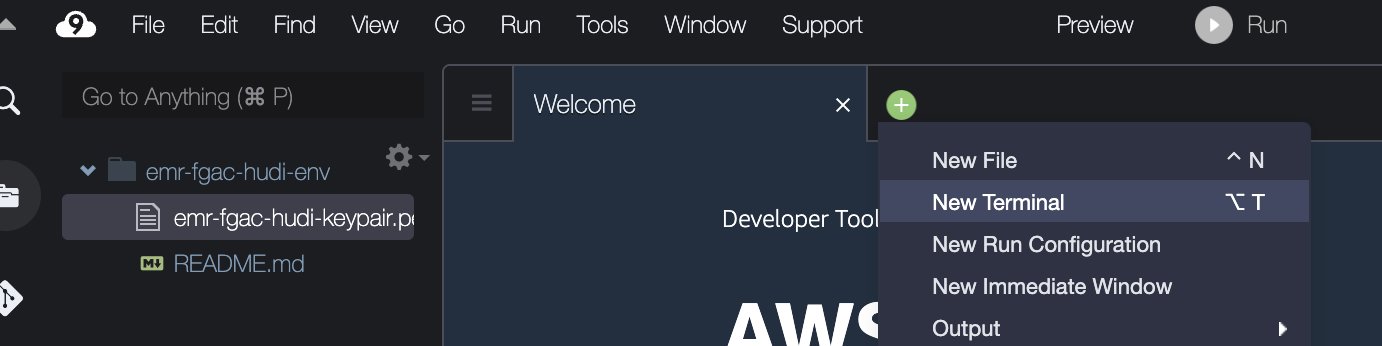
- Voer in de terminal de volgende opdrachtregels in:
Houd er rekening mee dat de voorbeeldcode alleen een proof of concept is en uitsluitend bedoeld is voor demonstratiedoeleinden. Gebruik voor productiesystemen een vertrouwde certificeringsinstantie (CA) om certificaten uit te geven. Verwijzen naar Het verstrekken van certificaten voor het versleutelen van gegevens die onderweg zijn met Amazon EMR-versleuteling voor meer info.
Implementeer de oplossing via AWS CloudFormation
Wij bieden een AWS CloudFormatie sjabloon waarmee automatisch de volgende services en componenten worden ingesteld:
- Een S3-bucket voor het datameer. Het bevat de voorbeeld-TPC-DS-gegevensset.
- Een EMR-cluster met beveiligingsconfiguratie en openbare DNS ingeschakeld.
- EMR-runtime IAM-rollen met gedetailleerde machtigingen voor Lake Formation:
- -hudi-db-creator-rol – Deze rol wordt gebruikt om de Apache Hudi-database en -tabellen te maken.
- -hudi-table-pii-rol – Deze rol geeft toestemming om alle kolommen van Hudi-tabellen te doorzoeken, inclusief kolommen met PII.
- -hudi-table-non-pii-rol – Deze rol biedt toestemming om Hudi-tabellen op te vragen die PII-kolommen hebben uitgefilterd op Lake Formation.
- Uitvoeringsrollen van SageMaker Studio waarmee gebruikers hun overeenkomstige EMR-runtimerollen op zich kunnen nemen.
- Netwerkbronnen zoals VPC, subnetten en beveiligingsgroepen.
Voer de volgende stappen uit om de resources te implementeren:
- Kies Maak snel een stapel om de CloudFormation-stack te starten.
- Voor Stack naam, voer een stapelnaam in (bijvoorbeeld
rsv2-emr-hudi-blog). - Voor Ec2KeyPaarVoer de naam van uw sleutelpaar in.
- Voor IdleTime-out, voert u een time-out voor inactiviteit in voor het EMR-cluster om te voorkomen dat u voor het cluster moet betalen wanneer het niet wordt gebruikt.
- Voor InitS3EmmerVoer de S3-bucketnaam in die u hebt gemaakt om het .zip-bestand van het Amazon EMR-coderingscertificaat op te slaan.
- Voor S3CertsZipVoer de S3-URI van het .zip-bestand van het Amazon EMR-coderingscertificaat in.
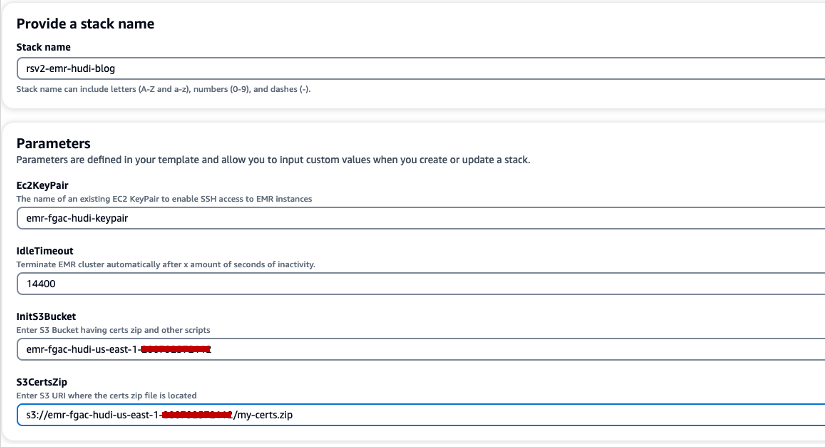
- kies Ik erken dat AWS CloudFormation IAM-bronnen met aangepaste namen kan maken.
- Kies Maak een stapel.
De implementatie van de CloudFormation-stack duurt ongeveer 10 minuten.
Stel Lake Formation in voor Amazon EMR-integratie
Voer de volgende stappen uit om Lake Formation in te stellen:
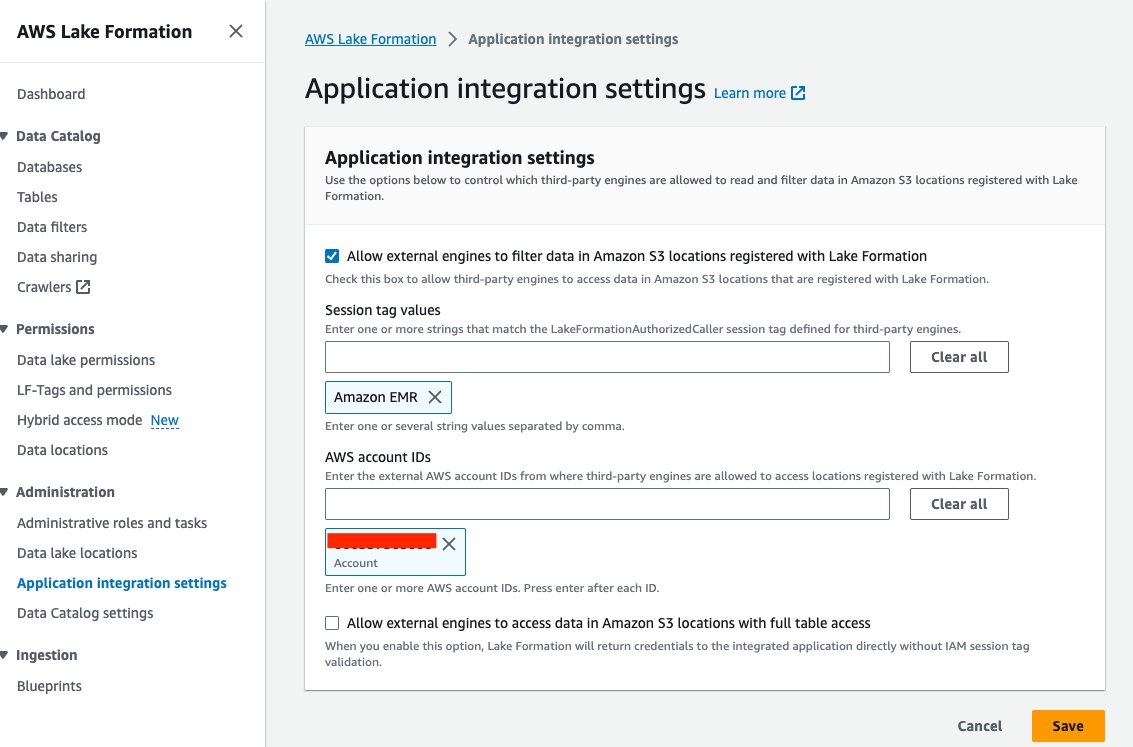
- Kies op de Lake Formation-console Instellingen voor applicatie-integratie voor Administratie in het navigatievenster.
- kies Laat externe zoekmachines gegevens filteren op Amazon S3-locaties die zijn geregistreerd bij Lake Formation.
- Kies Amazon EMR For Sessietagwaarden.
- Voer uw AWS-account-ID in voor AWS-account-ID's.
- Kies Bespaar.
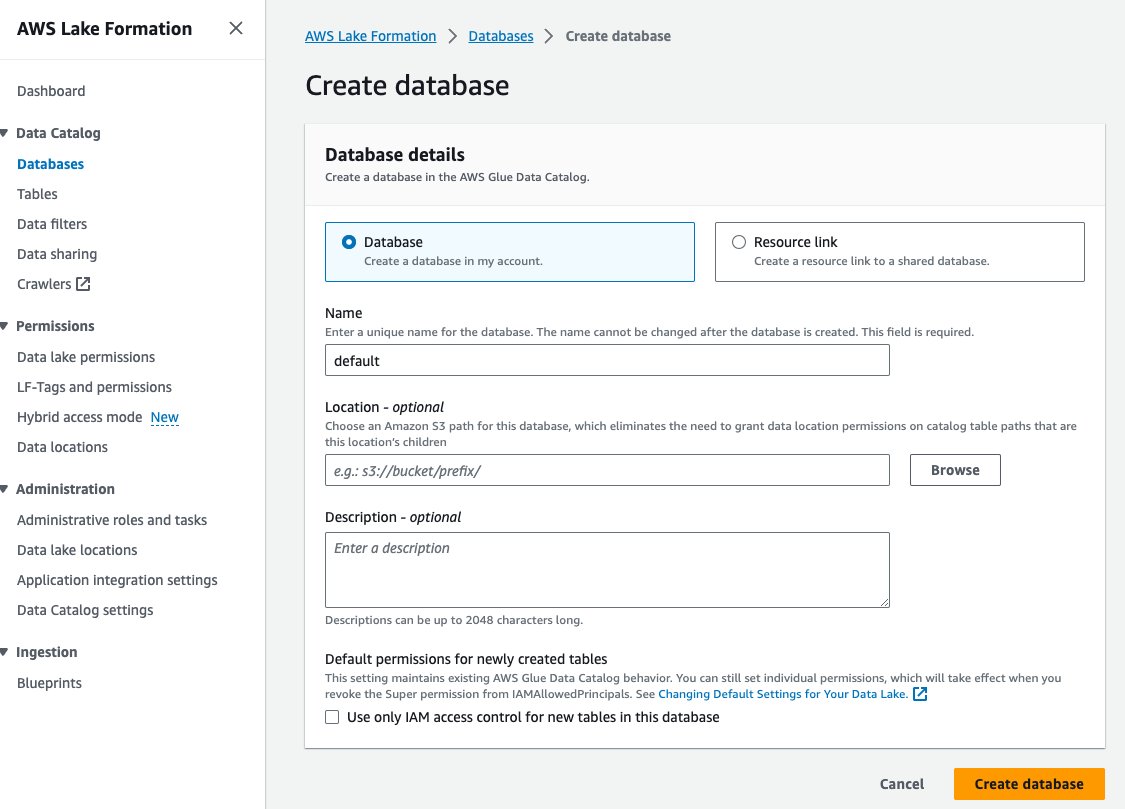
- Kies databases voor Gegevenscatalogus in het navigatievenster.
- Kies Maak een database.
- Voor Naam, voer standaard in.
- Kies Maak een database.
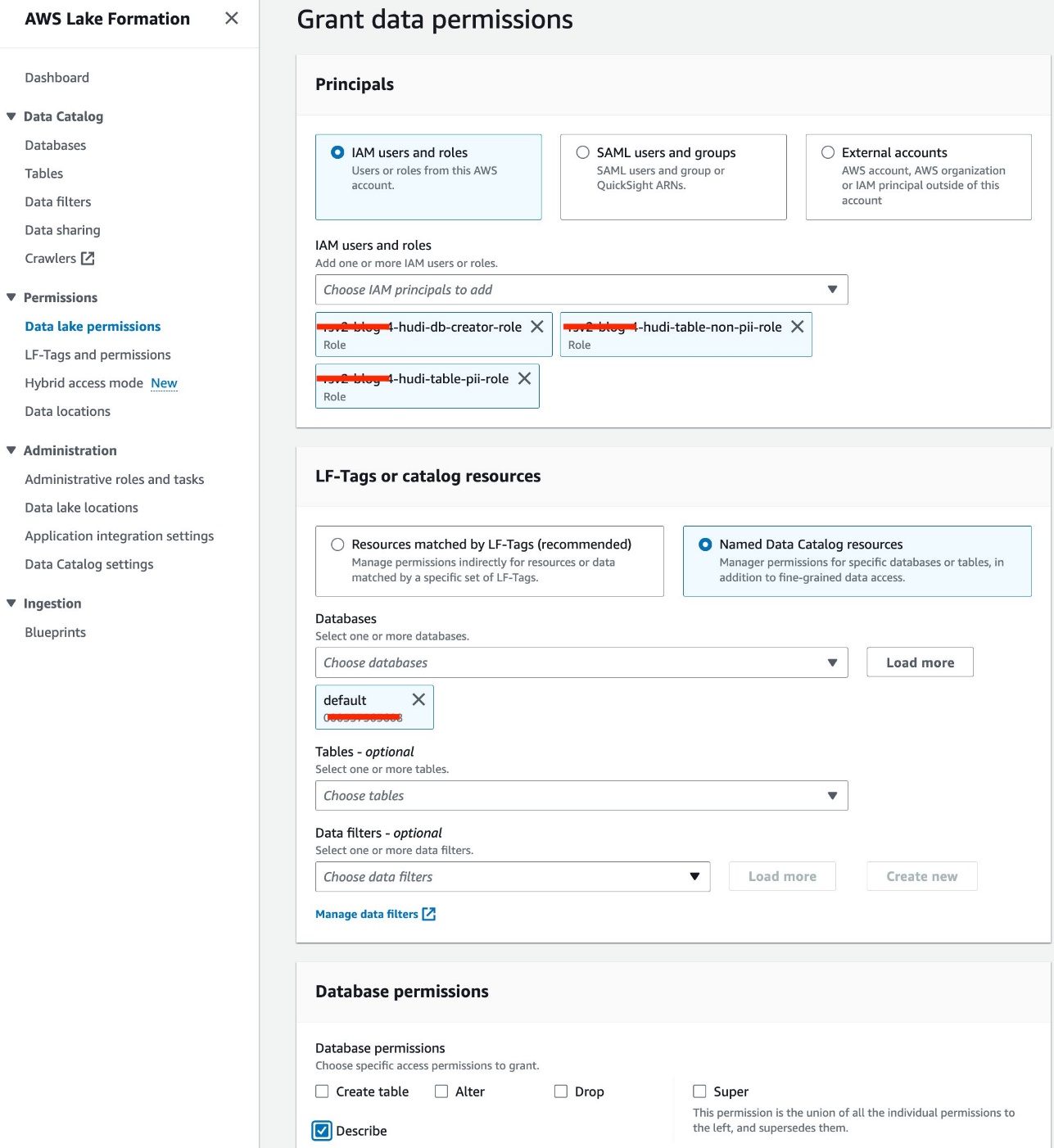
- Kies Data lake-machtigingen voor machtigingen in het navigatievenster.
- Kies Grant.
- kies IAM-gebruikers en -rollen.
- Kies uw IAM-rollen.
- Voor databases, kies standaard.
- Voor Databasemachtigingenselecteer Beschrijven.
- Kies Grant.
Kopieer het Hudi JAR-bestand naar Amazon EMR HDFS
Naar gebruik Hudi met Jupyter-notebooks, moet u de volgende stappen uitvoeren voor het EMR-cluster, waaronder het kopiëren van een Hudi JAR-bestand van de lokale Amazon EMR-map naar de HDFS-opslag, zodat u een Spark-sessie kunt configureren om Hudi te gebruiken:
- Autoriseer inkomend SSH-verkeer (poort 22).
- Kopieer de waarde voor Openbare DNS van primair knooppunt (bijvoorbeeld ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) uit het EMR-cluster Samengevat pagina.
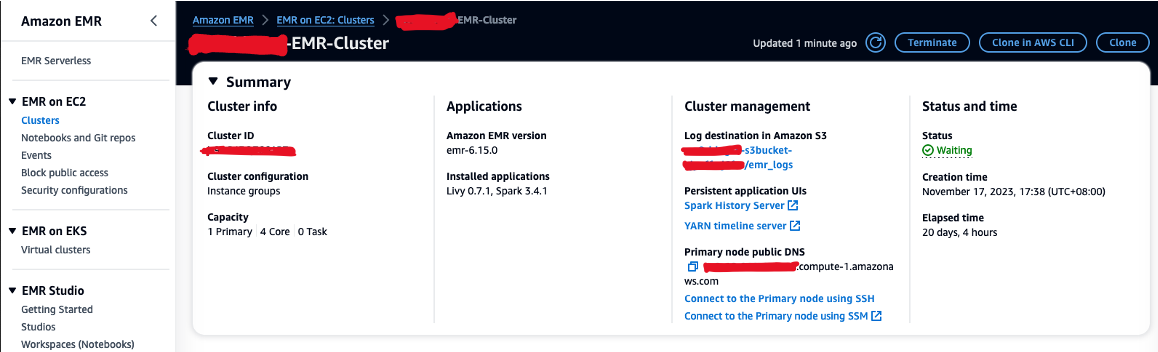
- Ga terug naar de vorige AWS Cloud9-terminal die u gebruikte om het EC2-sleutelpaar te maken.
- Voer de volgende opdracht uit naar SSH in het primaire EMR-knooppunt. Vervang de tijdelijke aanduiding door uw EMR DNS-hostnaam:
- Voer de volgende opdracht uit om het Hudi JAR-bestand naar HDFS te kopiëren:
Maak de Hudi-database en -tabellen in Lake Formation
Nu zijn we klaar om de Hudi-database en -tabellen te maken waarbij FGAC is ingeschakeld door de EMR-runtimerol. De EMR-runtimerol is een IAM-rol die u kunt opgeven wanneer u een taak of query indient bij een EMR-cluster.
Verleen toestemming voor het maken van de database
Laten we eerst de maker van de Lake Formation-database hiervoor toestemming geven<STACK-NAME>-hudi-db-creator-role:
- Meld u als beheerder aan bij uw AWS-account.
- Kies op de Lake Formation-console Administratieve rollen en taken voor Administratie in het navigatievenster.
- Bevestig dat uw AWS-inloggebruiker is toegevoegd als data lake-beheerder.
- In het Database-maker sectie, kies Grant.
- Voor IAM-gebruikers en -rollen, kiezen
<STACK-NAME>-hudi-db-creator-role. - Voor Catalogusmachtigingenselecteer Maak een database.
- Kies Grant.
Registreer de data lake-locatie
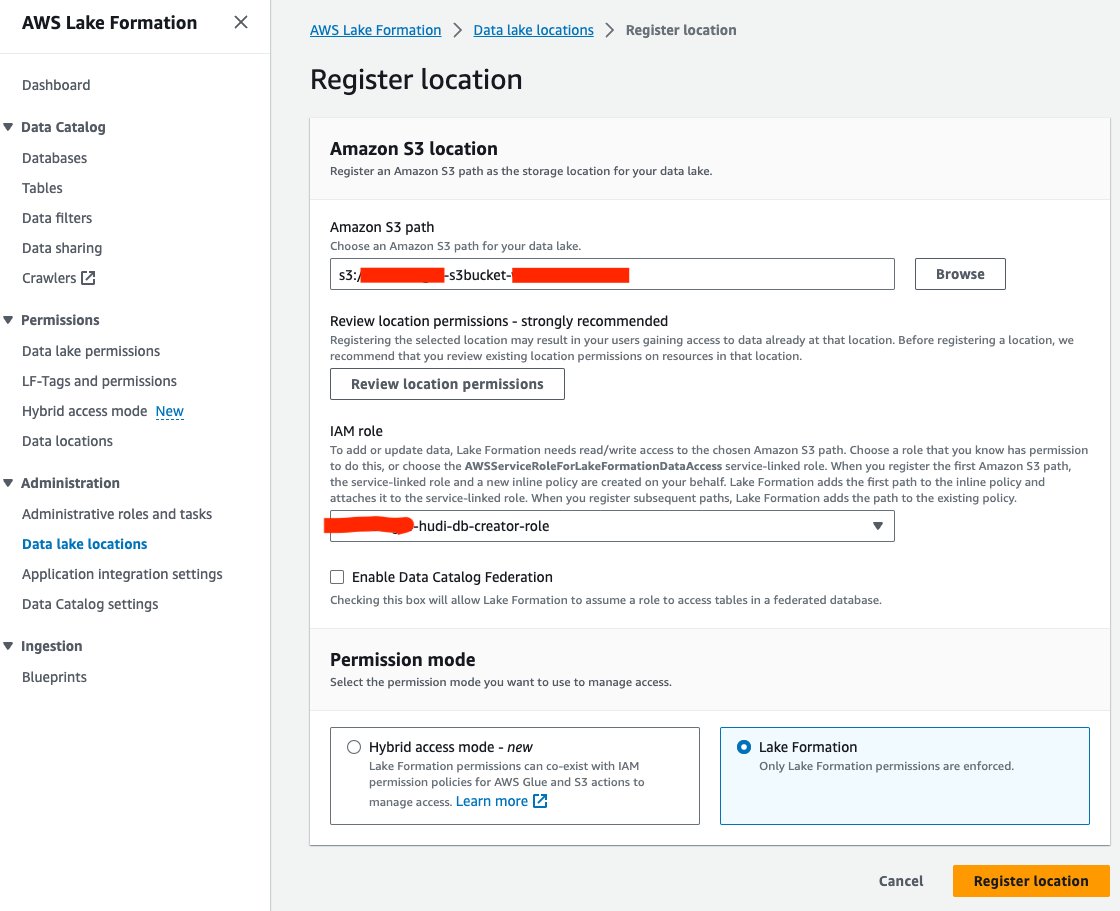
Laten we vervolgens de S3-datameerlocatie in Lake Formation registreren:
- Kies op de Lake Formation-console Data Lake-locaties voor Administratie in het navigatievenster.
- Kies Registreer locatie.
- Voor Amazon S3-pad, Kies Blader en kies de data lake S3-bucket. (
<STACK_NAME>s3bucket-XXXXXXX) gemaakt op basis van de CloudFormation-stack. - Voor IAM-rol, kiezen
<STACK-NAME>-hudi-db-creator-role. - Voor Toestemmingsmodusselecteer Vorming van het meer.
- Kies Registreer locatie.
Verleen toestemming voor gegevenslocatie
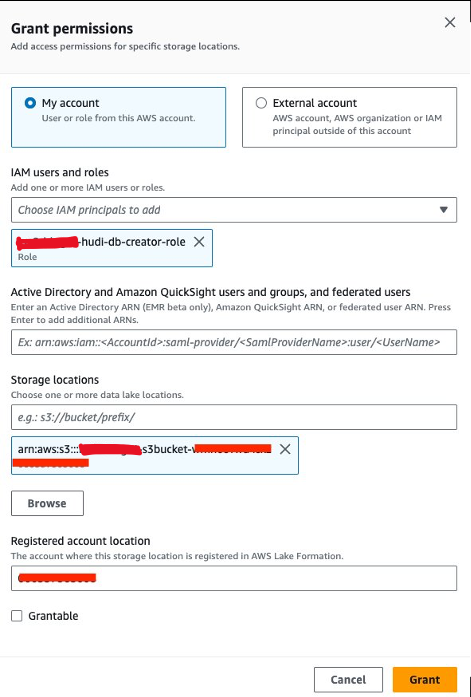
Vervolgens moeten we verlenen<STACK-NAME>-hudi-db-creator-rolede toestemming voor gegevenslocatie:
- Kies op de Lake Formation-console Gegevenslocaties voor machtigingen in het navigatievenster.
- Kies Grant.
- Voor IAM-gebruikers en -rollen, kiezen
<STACK-NAME>-hudi-db-creator-role. - Voor Opslaglocaties, voer de S3-bucket in (
<STACK_NAME>-s3bucket-XXXXXXX). - Kies Grant.
Maak verbinding met het EMR-cluster
Laten we nu een Jupyter-notebook in SageMaker Studio gebruiken om verbinding te maken met het EMR-cluster met de EMR-runtimerol van de databasemaker:
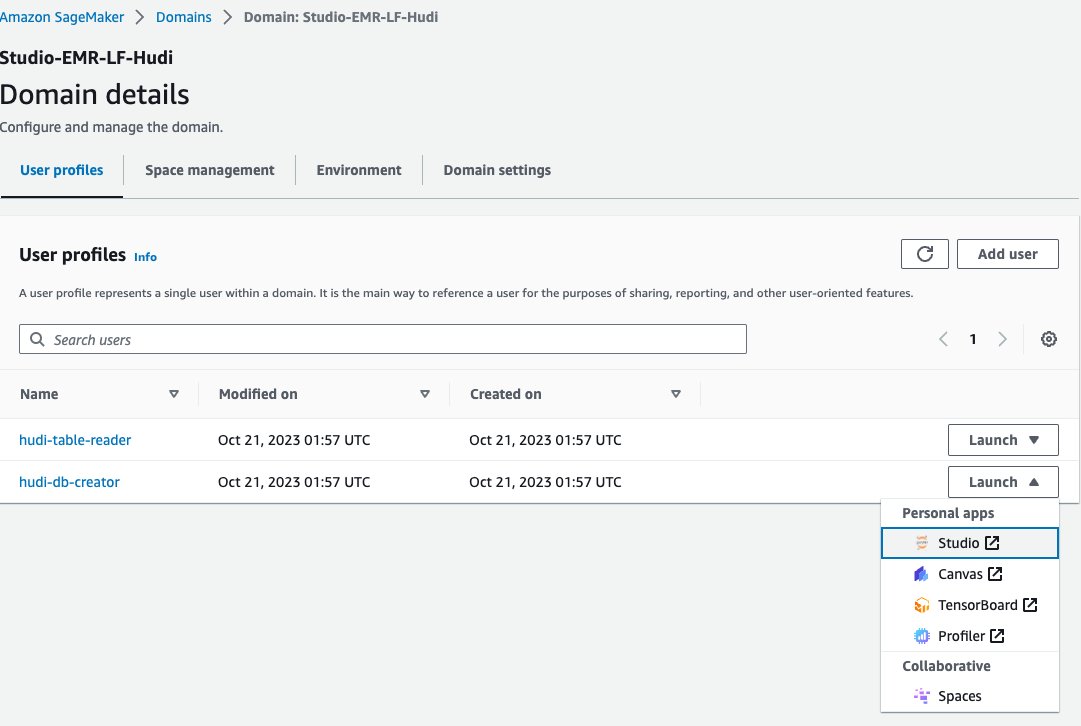
- Kies op de SageMaker-console domeinen in het navigatievenster.
- Kies het domein
<STACK-NAME>-Studio-EMR-LF-Hudi. - Op de Lancering menu naast het gebruikersprofiel
<STACK-NAME>-hudi-db-creator, kiezen studio.
- Download het notitieboek rsv2-hudi-db-creator-notebook.
- Kies het uploadpictogram.
- Kies het gedownloade Jupyter-notebook en kies Openen.
- Open het geüploade notitieblok.
- Voor Beeld, kiezen SparkMagic.
- Voor pit, kiezen PySpark.
- Laat de overige configuraties standaard staan en kies kies.

- Kies TROS om verbinding te maken met het EMR-cluster.

- Kies de EMR op EC2-cluster (
<STACK-NAME>-EMR-Cluster) gemaakt met de CloudFormation-stack. - Kies Verbinden.
- Voor EMR-uitvoeringsrol, kiezen
<STACK-NAME>-hudi-db-creator-role. - Kies Verbinden.
Database en tabellen maken
Nu kunt u de stappen in het notitieboekje volgen om de Hudi-database en -tabellen te maken. De belangrijkste stappen zijn als volgt:
- Wanneer u de notebook start, configureert u
“spark.sql.catalog.spark_catalog.lf.managed":"true"om Spark te informeren dat spark_catalog wordt beschermd door Lake Formation. - Maak Hudi-tabellen met behulp van de volgende Spark SQL.
- Gegevens uit de brontabel invoegen in de Hudi-tabellen.
- Voeg gegevens opnieuw in de Hudi-tabellen in.
Query's op de Hudi-tabellen via Lake Formation met FGAC
Nadat u de Hudi-database en -tabellen hebt gemaakt, bent u klaar om de tabellen te bevragen met behulp van fijnmazige toegangscontrole met Lake Formation. We hebben twee soorten Hudi-tabellen gemaakt: Copy-On-Write (COW) en Merge-On-Read (MOR). De COW-tabel slaat gegevens op in een kolomvormig formaat (Parquet), en elke update creëert tijdens het schrijven een nieuwe versie van bestanden. Dit betekent dat Hudi voor elke update het volledige bestand herschrijft, wat meer hulpbronnen kan vergen, maar snellere leesprestaties biedt. MOR daarentegen wordt geïntroduceerd voor gevallen waarin COW mogelijk niet optimaal is, met name voor werklasten die veel schrijven of wijzigen. In een MOR-tabel schrijft Hudi elke keer dat er een update is, alleen de rij voor het gewijzigde record, wat de kosten verlaagt en schrijfbewerkingen met lage latentie mogelijk maakt. De leesprestaties kunnen echter langzamer zijn in vergelijking met COW-tabellen.
Verleen machtigingen voor toegang tot de tabel
Wij maken gebruik van de IAM-rol<STACK-NAME>-hudi-table-pii-roleom Hudi COW en MOR te bevragen die PII-kolommen bevatten. We verlenen eerst de toestemming voor toegang tot de tafel via Lake Formation:
- Kies op de Lake Formation-console Data lake-machtigingen voor machtigingen in het navigatievenster.
- Kies Grant.
- Kies
<STACK-NAME>-hudi-table-pii-roleFor IAM-gebruikers en -rollen. - Kies de
rsv2_blog_hudi_db_1databank voor databases. - Voor Tafels, kies de vier Hudi-tabellen die u in het Jupyter-notebook hebt gemaakt.
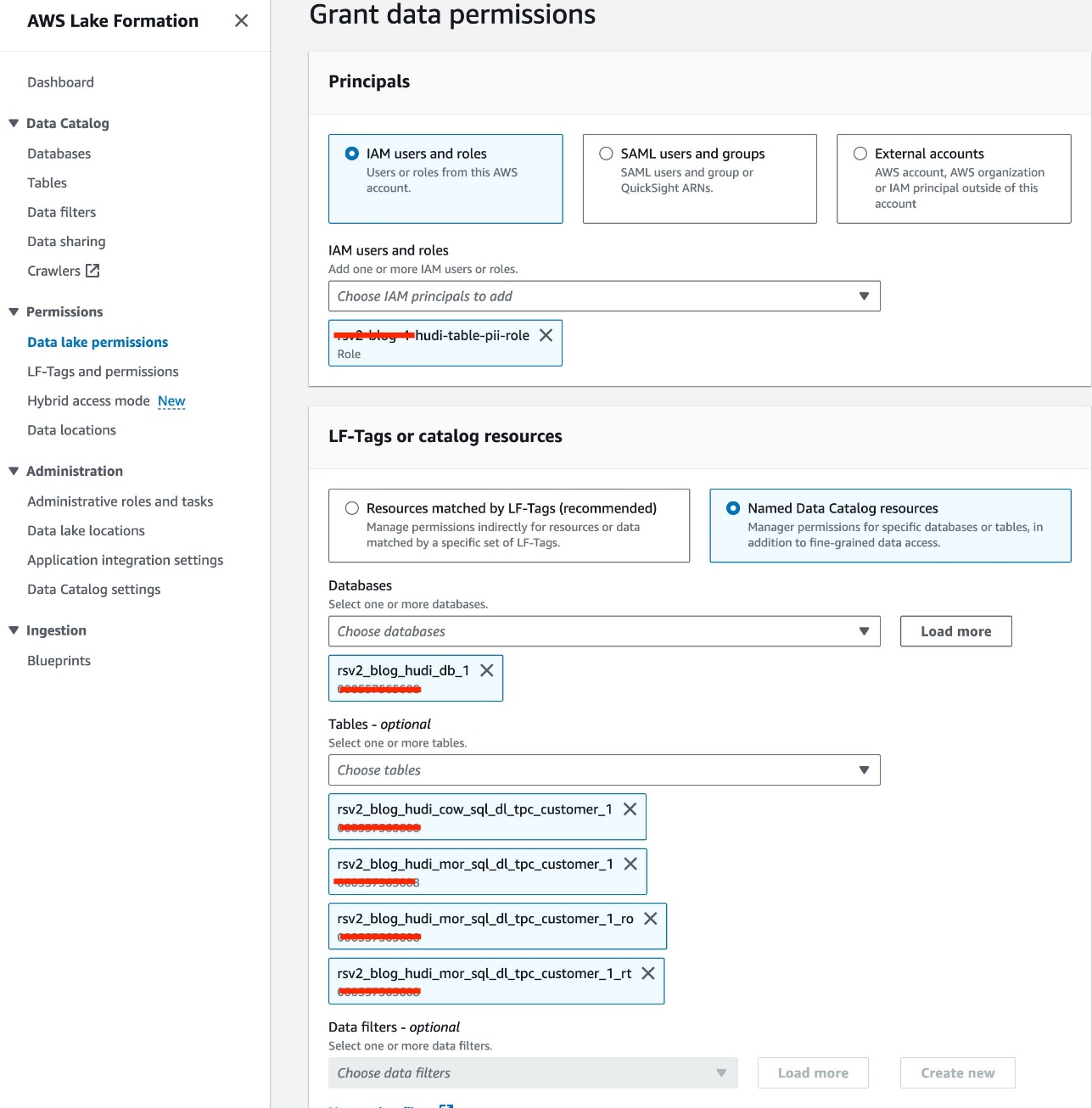
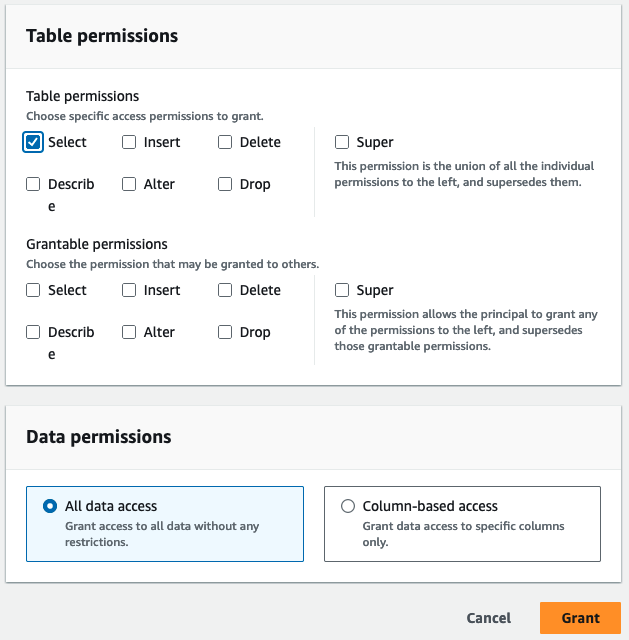
- Voor Tabelrechtenselecteer kies.
- Kies Grant.
PII-kolommen opvragen
Nu bent u klaar om de notebook uit te voeren om de Hudi-tabellen op te vragen. Laten we soortgelijke stappen volgen als in de vorige sectie om de notebook in SageMaker Studio uit te voeren:
- Navigeer op de SageMaker-console naar de
<STACK-NAME>-Studio-EMR-LF-Hudidomein. - Op de Lancering menu naast de
<STACK-NAME>-hudi-table-readergebruikersprofiel, kies studio. - Upload het gedownloade notitieboekje rsv2-hudi-table-pii-reader-notebook.
- Open het geüploade notitieblok.
- Herhaal de stappen voor het instellen van het notebook en maak verbinding met hetzelfde EMR-cluster, maar gebruik de rol
<STACK-NAME>-hudi-table-pii-role.
In de huidige fase moet het EMR-cluster met FGAC-functionaliteit de commit-tijdkolom van Hudi opvragen voor het uitvoeren van incrementele query's en tijdreizen. Het ondersteunt de “timestamp as of”-syntaxis van Spark niet en Spark.read(). We werken actief aan het opnemen van ondersteuning voor beide acties in toekomstige Amazon EMR-releases waarbij FGAC is ingeschakeld.
U kunt nu de stappen in het notitieboekje volgen. Hieronder volgen enkele gemarkeerde stappen:
- Voer een momentopnamequery uit.
- Voer een incrementele query uit.
- Voer een tijdreisquery uit.
- Voer MOR-leesgeoptimaliseerde en realtime tabelquery's uit.
Query's uitvoeren op de Hudi-tabellen met gegevensfilters op kolom- en rijniveau
Wij maken gebruik van de IAM-rol<STACK-NAME>-hudi-table-non-pii-roleom Hudi-tabellen op te vragen. Deze rol mag geen kolommen opvragen die PII bevatten. We gebruiken de gegevensfilters op kolom- en rijniveau van Lake Formation om fijnmazig toegangscontrole te implementeren:
- Kies op de Lake Formation-console Gegevensfilters voor Gegevenscatalogus in het navigatievenster.
- Kies Nieuw filter maken.
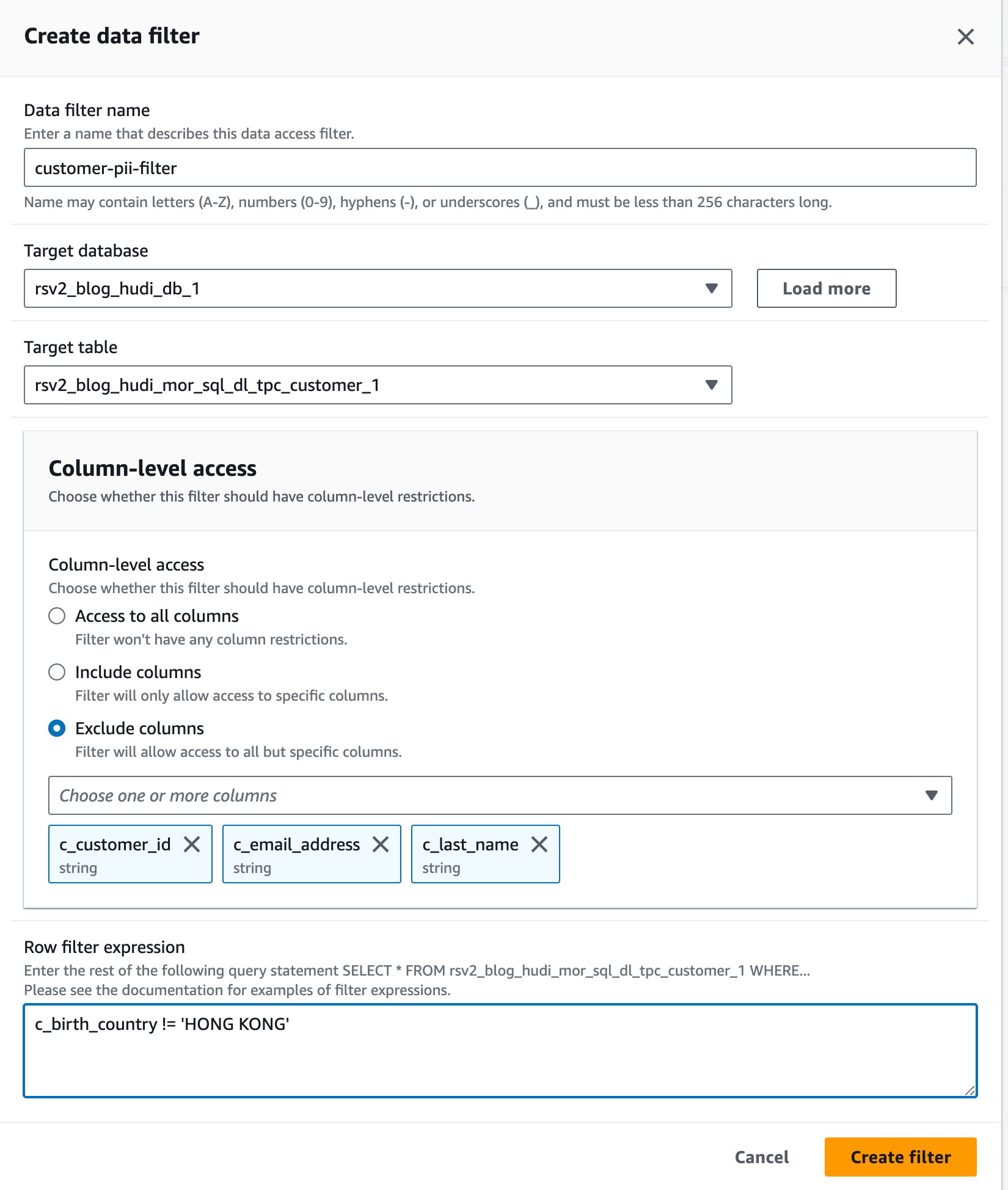
- Voor Naam gegevensfilter, ga naar binnen
customer-pii-filter. - Kies
rsv2_blog_hudi_db_1For Doeldatabase. - Kies
rsv2_blog_hudi_mor_sql_dl_customer_1For Doeltabel. - kies Kolommen uitsluiten En kies de
c_customer_id,c_email_addressenc_last_namekolommen. - Enter
c_birth_country != 'HONG KONG'For Uitdrukking rijfilter. - Kies Maak een filter.
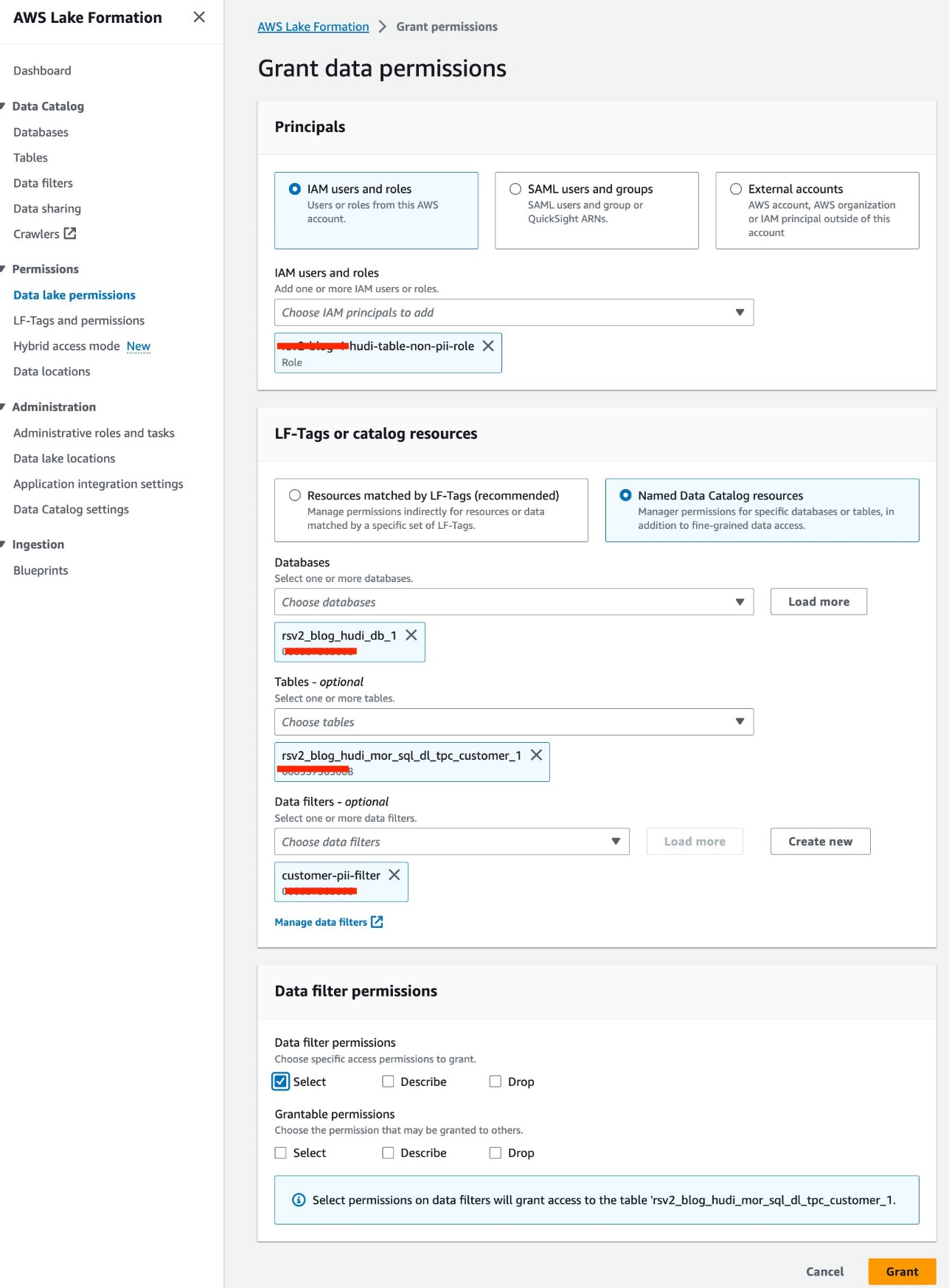
- Kies Data lake-machtigingen voor machtigingen in het navigatievenster.
- Kies Grant.
- Kies
<STACK-NAME>-hudi-table-non-pii-roleFor IAM-gebruikers en -rollen. - Kies
rsv2_blog_hudi_db_1For databases. - Kies
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1For Tafels. - Kies
customer-pii-filterFor Gegevensfilters. - Voor Gegevensfiltermachtigingenselecteer kies.
- Kies Grant.
Laten we soortgelijke stappen volgen om de notebook in SageMaker Studio uit te voeren:
- Navigeer op de SageMaker-console naar het domein
Studio-EMR-LF-Hudi. - Op de Lancering menu voor de
hudi-table-readergebruikersprofiel, kies studio. - Upload het gedownloade notitieboekje rsv2-hudi-table-non-pii-reader-notebook En kies Openen.
- Herhaal de stappen voor het instellen van het notebook en maak verbinding met hetzelfde EMR-cluster, maar selecteer de rol
<STACK-NAME>-hudi-table-non-pii-role.
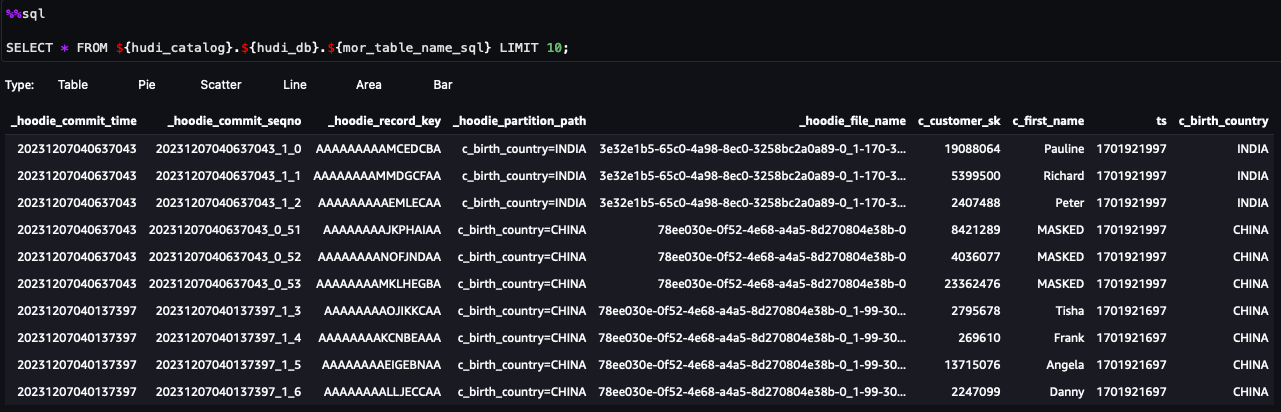
U kunt nu de stappen in het notitieboekje volgen. Uit de queryresultaten kunt u zien dat FGAC via het Lake Formation-gegevensfilter is toegepast. De rol kan de PII-kolommen niet zienc_customer_id,c_last_name enc_email_address. Ook de rijen uitHONG KONGzijn gefilterd.
Opruimen
Nadat u klaar bent met het experimenteren met de oplossing, raden we u aan bronnen op te schonen met de volgende stappen om onverwachte kosten te voorkomen:
- Sluit de SageMaker Studio-apps af voor de gebruikersprofielen.
Het EMR-cluster wordt automatisch verwijderd na de time-outwaarde voor inactiviteit.
- Verwijder de Amazon elastisch bestandssysteem (Amazon EFS) volume gemaakt voor het domein.
- Leeg de S3-emmers gemaakt door de CloudFormation-stack.
- Verwijder de stapel op de AWS CloudFormation-console.
Conclusie
In dit bericht hebben we Apachi Hudi, een type OTF-tabellen, gebruikt om deze nieuwe functie te demonstreren om fijnmazige toegangscontrole op Amazon EMR af te dwingen. U kunt gedetailleerde machtigingen definiëren in Lake Formation voor OTF-tabellen en deze toepassen via Spark SQL-query's op EMR-clusters. U kunt ook transactionele data lake-functies gebruiken, zoals het uitvoeren van snapshotquery's, incrementele query's, tijdreizen en DML-query's. Houd er rekening mee dat deze nieuwe functie alle OTF-tabellen omvat.
Deze functie wordt in totaal gelanceerd vanaf Amazon EMR-release 6.15 Regio's waar Amazon EMR beschikbaar is. Met de Amazon EMR-integratie met Lake Formation kunt u vol vertrouwen big data beheren en verwerken, inzichten ontsluiten en weloverwogen besluitvorming mogelijk maken, terwijl de gegevensbeveiliging en het bestuur behouden blijven.
Raadpleeg voor meer informatie: Schakel merenvorming in met Amazon EMR en neem gerust contact op met uw AWS Solutions Architects, die u kunnen helpen bij uw datatraject.
Over de auteur
 Raymond Lay is een Senior Solutions Architect die gespecialiseerd is in het voorzien in de behoeften van grote zakelijke klanten. Zijn expertise ligt in het assisteren van klanten bij het migreren van ingewikkelde bedrijfssystemen en databases naar AWS, het bouwen van enterprise datawarehousing en data lake-platforms. Raymond blinkt uit in het identificeren en ontwerpen van oplossingen voor AI/ML-use cases, en hij heeft een bijzondere focus op AWS Serverless-oplossingen en Event Driven Architecture-ontwerp.
Raymond Lay is een Senior Solutions Architect die gespecialiseerd is in het voorzien in de behoeften van grote zakelijke klanten. Zijn expertise ligt in het assisteren van klanten bij het migreren van ingewikkelde bedrijfssystemen en databases naar AWS, het bouwen van enterprise datawarehousing en data lake-platforms. Raymond blinkt uit in het identificeren en ontwerpen van oplossingen voor AI/ML-use cases, en hij heeft een bijzondere focus op AWS Serverless-oplossingen en Event Driven Architecture-ontwerp.
 Bin Wang, PhD, is een Senior Analytic Specialist Solutions Architect bij AWS, met meer dan 12 jaar ervaring in de ML-industrie, met een bijzondere focus op adverteren. Hij beschikt over expertise op het gebied van natuurlijke taalverwerking (NLP), aanbevelingssystemen, diverse ML-algoritmen en ML-bewerkingen. Hij heeft een grote passie voor het toepassen van ML/DL- en big data-technieken om problemen uit de echte wereld op te lossen.
Bin Wang, PhD, is een Senior Analytic Specialist Solutions Architect bij AWS, met meer dan 12 jaar ervaring in de ML-industrie, met een bijzondere focus op adverteren. Hij beschikt over expertise op het gebied van natuurlijke taalverwerking (NLP), aanbevelingssystemen, diverse ML-algoritmen en ML-bewerkingen. Hij heeft een grote passie voor het toepassen van ML/DL- en big data-technieken om problemen uit de echte wereld op te lossen.
 Aditya Sjah is een softwareontwikkelingsingenieur bij AWS. Hij is geïnteresseerd in databases en datawarehouse-engines en heeft gewerkt aan prestatie-optimalisaties, beveiligingscompliance en ACID-compliance voor motoren als Apache Hive en Apache Spark.
Aditya Sjah is een softwareontwikkelingsingenieur bij AWS. Hij is geïnteresseerd in databases en datawarehouse-engines en heeft gewerkt aan prestatie-optimalisaties, beveiligingscompliance en ACID-compliance voor motoren als Apache Hive en Apache Spark.
 Melodie Yang is Senior Big Data Solution Architect voor Amazon EMR bij AWS. Ze is een ervaren analyseleider die samenwerkt met AWS-klanten om best practice-begeleiding en technisch advies te bieden om hun succes bij datatransformatie te ondersteunen. Haar interessegebieden zijn open source frameworks en automatisering, data engineering en DataOps.
Melodie Yang is Senior Big Data Solution Architect voor Amazon EMR bij AWS. Ze is een ervaren analyseleider die samenwerkt met AWS-klanten om best practice-begeleiding en technisch advies te bieden om hun succes bij datatransformatie te ondersteunen. Haar interessegebieden zijn open source frameworks en automatisering, data engineering en DataOps.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/

