De afgelopen jaren zijn Large Language Models (LLM's) steeds bekender geworden als uitstekende hulpmiddelen die in staat zijn om tekst met een ongekende vaardigheid te begrijpen, genereren en manipuleren. Hun potentiële toepassingen variëren van conversatieagenten tot het genereren van inhoud en het ophalen van informatie, en houden de belofte in van een revolutie in alle sectoren. Het benutten van dit potentieel en tegelijkertijd het verantwoorde en effectieve gebruik van deze modellen garanderen, hangt echter af van het cruciale proces van LLM-evaluatie. Een evaluatie is een taak die wordt gebruikt om de kwaliteit en verantwoordelijkheid van de output van een LLM- of generatieve AI-service te meten. Het evalueren van LLM’s wordt niet alleen gemotiveerd door de wens om de prestaties van een model te begrijpen, maar ook door de noodzaak om verantwoorde AI te implementeren en door de noodzaak om het risico op het verstrekken van verkeerde informatie of bevooroordeelde inhoud te beperken en het genereren van schadelijke, onveilige, kwaadaardige en onethische inhoud te minimaliseren. inhoud. Bovendien kan het evalueren van LLM's ook helpen de beveiligingsrisico's te beperken, vooral in de context van snelle manipulatie van gegevens. Voor op LLM gebaseerde applicaties is het van cruciaal belang om kwetsbaarheden te identificeren en veiligheidsmaatregelen te implementeren die bescherming bieden tegen mogelijke inbreuken en ongeoorloofde manipulatie van gegevens.
Door essentiële hulpmiddelen te bieden voor het evalueren van LLM's met een eenvoudige configuratie en een aanpak met één klik, Amazon SageMaker verduidelijken LLM-evaluatiemogelijkheden geven klanten toegang tot de meeste van de bovengenoemde voordelen. Met deze tools in de hand is de volgende uitdaging het integreren van LLM-evaluatie in de levenscyclus van Machine Learning and Operation (MLOps) om automatisering en schaalbaarheid in het proces te bereiken. In dit bericht laten we u zien hoe u Amazon SageMaker Clarify LLM-evaluatie kunt integreren met Amazon SageMaker Pipelines om LLM-evaluatie op schaal mogelijk te maken. Daarnaast geven we hierin een codevoorbeeld GitHub repository om gebruikers in staat te stellen parallelle evaluatie van meerdere modellen op schaal uit te voeren, met behulp van voorbeelden zoals Llama2-7b-f, Falcon-7b en verfijnde Llama2-7b-modellen.
Wie moet een LLM-evaluatie uitvoeren?
Iedereen die een vooraf getrainde LLM traint, verfijnt of eenvoudigweg gebruikt, moet deze nauwkeurig evalueren om het gedrag te beoordelen van de applicatie die door die LLM wordt aangedreven. Op basis van dit uitgangspunt kunnen we generatieve AI-gebruikers die LLM-evaluatiemogelijkheden nodig hebben in drie groepen indelen, zoals weergegeven in de volgende afbeelding: modelaanbieders, fijnafstemmers en consumenten.

- Fundamentele Model (FM) aanbieders treinmodellen voor algemeen gebruik. Deze modellen kunnen voor veel downstream-taken worden gebruikt, zoals het extraheren van functies of het genereren van inhoud. Elk getraind model moet worden vergeleken met vele taken, niet alleen om de prestaties ervan te beoordelen, maar ook om het te vergelijken met andere bestaande modellen, om gebieden te identificeren die verbeteringen behoeven en ten slotte om de vorderingen in het veld bij te houden. Modelaanbieders moeten ook de aanwezigheid van eventuele bias controleren om de kwaliteit van de startdataset en het correcte gedrag van hun model te garanderen. Het verzamelen van evaluatiegegevens is van cruciaal belang voor modelaanbieders. Bovendien moeten deze gegevens en statistieken worden verzameld om te voldoen aan de komende regelgeving. ISO 42001 Uitvoeringsbesluit van de regering-Biden en EU AI-wet normen, hulpmiddelen en tests ontwikkelen om ervoor te zorgen dat AI-systemen veilig, beveiligd en betrouwbaar zijn. De EU AI Act heeft bijvoorbeeld de taak om informatie te verstrekken over welke datasets worden gebruikt voor training, welke rekenkracht nodig is om het model uit te voeren, modelresultaten te rapporteren aan de hand van publieke/industriestandaard benchmarks en resultaten van interne en externe tests te delen.
- Model finetuners specifieke taken willen oplossen (bijvoorbeeld sentimentclassificatie, samenvatting, vraagbeantwoording) en vooraf getrainde modellen voor het overnemen van domeinspecifieke taken. Ze hebben evaluatiestatistieken nodig die zijn gegenereerd door modelaanbieders om het juiste, vooraf getrainde model als uitgangspunt te selecteren.
Ze moeten hun verfijnde modellen evalueren aan de hand van hun gewenste gebruiksscenario met taakspecifieke of domeinspecifieke datasets. Vaak moeten ze hun privédatasets beheren en creëren, omdat openbaar beschikbare datasets, zelfs die welke voor een specifieke taak zijn ontworpen, mogelijk niet voldoende de nuances weergeven die nodig zijn voor hun specifieke gebruikssituatie.
Het afstemmen is sneller en goedkoper dan een volledige training en vereist een snellere operatieve iteratie voor implementatie en testen, omdat er doorgaans veel kandidaatmodellen worden gegenereerd. Het evalueren van deze modellen maakt continue modelverbetering, kalibratie en foutopsporing mogelijk. Houd er rekening mee dat fijnafstemmers consumenten van hun eigen modellen kunnen worden wanneer ze toepassingen in de echte wereld ontwikkelen. - Model consumenten of modelimplementeerders bedienen en monitoren modellen voor algemene doeleinden of verfijnde modellen in de productie, met als doel hun toepassingen of diensten te verbeteren door de adoptie van LLM's. De eerste uitdaging die ze hebben is ervoor te zorgen dat de gekozen LLM aansluit bij hun specifieke behoeften, kosten en prestatieverwachtingen. Het interpreteren en begrijpen van de uitkomsten van het model is een aanhoudende zorg, vooral als het om privacy en gegevensbeveiliging gaat (bijvoorbeeld bij het controleren van risico's en compliance in gereguleerde sectoren, zoals de financiële sector). Continue modelevaluatie is van cruciaal belang om de verspreiding van vooringenomenheid of schadelijke inhoud te voorkomen. Door een robuust monitoring- en evaluatiekader te implementeren, kunnen modelconsumenten proactief regressie in LLM's identificeren en aanpakken, waardoor ervoor wordt gezorgd dat deze modellen hun effectiviteit en betrouwbaarheid in de loop van de tijd behouden.
Hoe u een LLM-evaluatie uitvoert
Effectieve modelevaluatie omvat drie fundamentele componenten: een of meer FM's of verfijnde modellen om de inputdatasets (prompts, gesprekken of reguliere inputs) en de evaluatielogica te evalueren.
Om de modellen voor evaluatie te selecteren, moeten verschillende factoren in overweging worden genomen, waaronder gegevenskenmerken, probleemcomplexiteit, beschikbare computerbronnen en het gewenste resultaat. De invoergegevensopslag levert de gegevens die nodig zijn voor het trainen, afstemmen en testen van het geselecteerde model. Het is van cruciaal belang dat deze datastore goed gestructureerd, representatief en van hoge kwaliteit is, omdat de prestaties van het model sterk afhankelijk zijn van de gegevens waarvan het leert. Ten slotte definiëren evaluatielogica's de criteria en metrieken die worden gebruikt om de prestaties van het model te beoordelen.
Samen vormen deze drie componenten een samenhangend raamwerk dat zorgt voor de rigoureuze en systematische beoordeling van machine learning-modellen, wat uiteindelijk leidt tot weloverwogen beslissingen en verbeteringen in de effectiviteit van modellen.
Modelevaluatietechnieken zijn nog steeds een actief onderzoeksgebied. De afgelopen jaren zijn er door de gemeenschap van onderzoekers veel publieke benchmarks en raamwerken gecreëerd om een breed scala aan taken en scenario’s te dekken, zoals LIJM, Superlijm, ROER, MMLU en BIG-bank. Deze benchmarks hebben scoreborden die kunnen worden gebruikt om geëvalueerde modellen te vergelijken en te contrasteren. Benchmarks, zoals HELM, zijn ook bedoeld om statistieken te beoordelen die verder gaan dan nauwkeurigheidsmetingen, zoals precisie of F1-score. De HELM-benchmark omvat maatstaven voor eerlijkheid, vooringenomenheid en toxiciteit die een even groot belang hebben in de algehele modelevaluatiescore.
Al deze benchmarks bevatten een reeks statistieken die meten hoe het model presteert bij een bepaalde taak. De bekendste en meest voorkomende statistieken zijn ROOD (Recall-Oriented Understudy voor Gisting-evaluatie), BLUE (Tweetalige evaluatie-student), of METEOR (Metriek voor evaluatie van vertalingen met expliciete volgorde). Deze statistieken dienen als een nuttig hulpmiddel voor geautomatiseerde evaluatie en bieden kwantitatieve metingen van lexicale gelijkenis tussen gegenereerde tekst en referentietekst. Ze omvatten echter niet de volledige breedte van de mensachtige taalgeneratie, die semantisch begrip, context of stilistische nuances omvat. HELM biedt bijvoorbeeld geen evaluatiedetails die relevant zijn voor specifieke gebruiksscenario's, oplossingen voor het testen van aangepaste aanwijzingen en gemakkelijk geïnterpreteerde resultaten die door niet-experts worden gebruikt, omdat het proces duur kan zijn, niet eenvoudig op te schalen en alleen voor specifieke taken.
Bovendien vereist het bereiken van mensachtige taalgeneratie vaak de integratie van human-in-the-loop om kwalitatieve beoordelingen en menselijk oordeel te bewerkstelligen als aanvulling op de geautomatiseerde nauwkeurigheidsmetrieken. Menselijke evaluatie is een waardevolle methode voor het beoordelen van LLM-resultaten, maar kan ook subjectief zijn en vatbaar voor vooringenomenheid, omdat verschillende menselijke beoordelaars uiteenlopende meningen en interpretaties over de tekstkwaliteit kunnen hebben. Bovendien kan menselijke evaluatie veel tijd en moeite vergen en veel tijd en moeite vergen.
Laten we diep ingaan op de manier waarop Amazon SageMaker Clarify de punten naadloos met elkaar verbindt en klanten helpt bij het uitvoeren van een grondige modelevaluatie en -selectie.
LLM-evaluatie met Amazon SageMaker Clarify
Amazon SageMaker Clarify helpt klanten bij het automatiseren van de statistieken, inclusief maar niet beperkt tot nauwkeurigheid, robuustheid, toxiciteit, stereotypering en feitelijke kennis voor geautomatiseerde, en stijl, samenhang, relevantie voor op mensen gebaseerde evaluatie en evaluatiemethoden, door een raamwerk te bieden om LLM's te evalueren en op LLM gebaseerde diensten zoals Amazon Bedrock. Als een volledig beheerde service vereenvoudigt SageMaker Clarify het gebruik van open-source evaluatieframeworks binnen Amazon SageMaker. Klanten kunnen relevante evaluatiedatasets en -statistieken voor hun scenario's selecteren en deze uitbreiden met hun eigen snelle datasets en evaluatiealgoritmen. SageMaker Clarify levert evaluatieresultaten in meerdere formaten om verschillende rollen in de LLM-workflow te ondersteunen. Datawetenschappers kunnen gedetailleerde resultaten analyseren met SageMaker Clarify-visualisaties in Notebooks, SageMaker-modelkaarten en PDF-rapporten. Ondertussen kunnen operationele teams Amazon SageMaker GroundTruth gebruiken om items met een hoog risico die SageMaker Clarify identificeert, te beoordelen en te annoteren. Bijvoorbeeld door stereotypering, toxiciteit, ontsnapte PII of lage nauwkeurigheid.
Annotaties en versterkend leren worden vervolgens gebruikt om potentiële risico's te beperken. Mensvriendelijke uitleg over de geïdentificeerde risico’s versnelt het handmatige beoordelingsproces, waardoor de kosten worden verlaagd. Samenvattende rapporten bieden zakelijke belanghebbenden vergelijkende benchmarks tussen verschillende modellen en versies, waardoor geïnformeerde besluitvorming wordt vergemakkelijkt.
De volgende afbeelding toont het raamwerk voor het evalueren van LLM's en op LLM gebaseerde services:
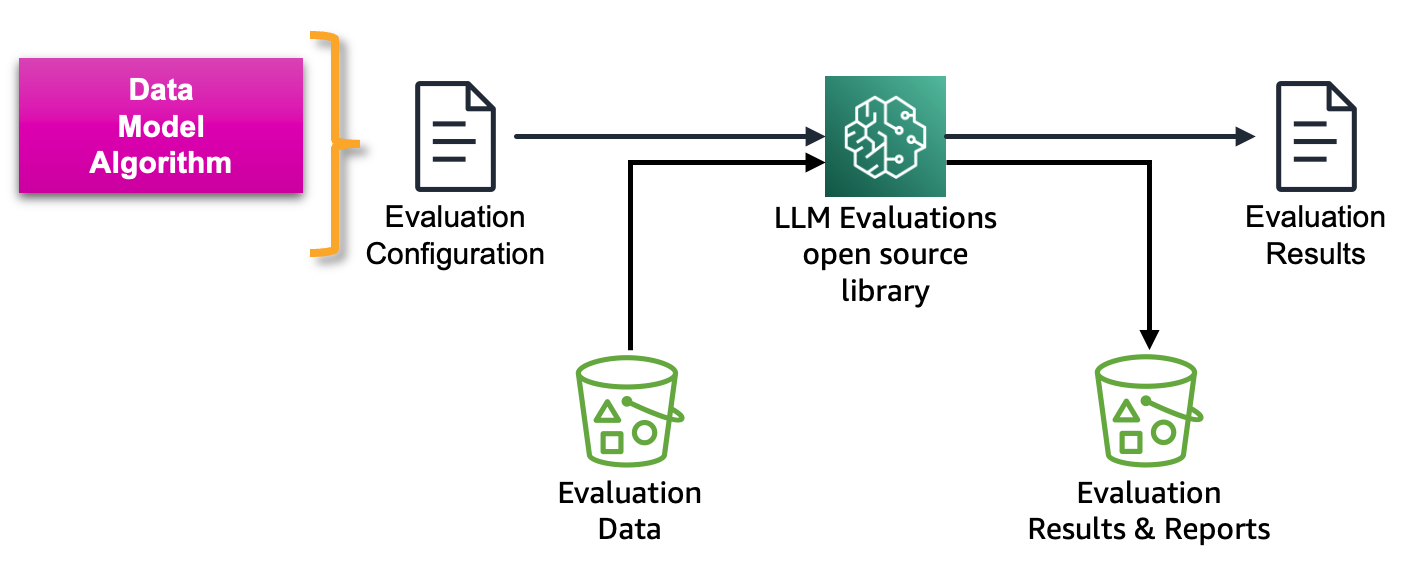
Amazon SageMaker Clarify LLM-evaluatie is een open-source Foundation Model Evaluation (FMEval)-bibliotheek ontwikkeld door AWS om klanten te helpen LLM's eenvoudig te evalueren. Alle functionaliteiten zijn ook opgenomen in Amazon SageMaker Studio om LLM-evaluatie voor zijn gebruikers mogelijk te maken. In de volgende secties introduceren we de integratie van Amazon SageMaker Clarify LLM-evaluatiemogelijkheden met SageMaker Pipelines om LLM-evaluatie op schaal mogelijk te maken door gebruik te maken van MLOps-principes.
Amazon SageMaker MLOps-levenscyclus
Zoals het bericht “MLOps foundation roadmap voor ondernemingen met Amazon SageMaker” beschrijft, is MLOps de combinatie van processen, mensen en technologie om ML-use cases efficiënt te produceren.
De volgende afbeelding toont de end-to-end MLOps-levenscyclus:

Een typisch traject begint met een datawetenschapper die een proof-of-concept (PoC)-notebook maakt om te bewijzen dat ML een zakelijk probleem kan oplossen. Tijdens de Proof of Concept (PoC)-ontwikkeling is het de taak van de datawetenschapper om de Key Performance Indicators (KPI's) van het bedrijf om te zetten in machine learning-modelstatistieken, zoals precisie of fout-positieve percentages, en een beperkte testdataset te gebruiken om deze te evalueren. statistieken. Datawetenschappers werken samen met ML-ingenieurs om code over te zetten van notebooks naar opslagplaatsen, waarbij ML-pijplijnen worden gecreëerd met behulp van Amazon SageMaker Pipelines, die verschillende verwerkingsstappen en -taken met elkaar verbinden, waaronder voorverwerking, training, evaluatie en naverwerking, terwijl er voortdurend nieuwe productie wordt geïntegreerd gegevens. De implementatie van Amazon SageMaker Pipelines is afhankelijk van repository-interacties en activering van de CI/CD-pijplijn. De ML-pijplijn onderhoudt de best presterende modellen, containerimages, evaluatieresultaten en statusinformatie in een modelregister, waar belanghebbenden van modellen de prestaties beoordelen en beslissen over de voortgang naar productie op basis van prestatieresultaten en benchmarks, gevolgd door activering van een andere CI/CD-pijplijn voor staging en productie-implementatie. Eenmaal in productie gebruiken ML-consumenten het model via applicatie-getriggerde inferentie via directe aanroep of API-oproepen, met feedbackloops naar modeleigenaren voor voortdurende prestatie-evaluatie.
Amazon SageMaker Clarify en MLOps-integratie
Na de MLOps-levenscyclus produceren fijnafstemmers of gebruikers van open-sourcemodellen verfijnd afgestemde modellen of FM met behulp van Amazon SageMaker Jumpstart- en MLOps-services, zoals beschreven in MLOps-praktijken implementeren met Amazon SageMaker JumpStart vooraf getrainde modellen. Dit leidde tot een nieuw domein voor foundation model operations (FMOps) en LLM Operations (LLMOps) FMOps/LLMOps: Operationaliseer generatieve AI en verschillen met MLOps.
De volgende afbeelding toont de end-to-end LLMOps-levenscyclus:
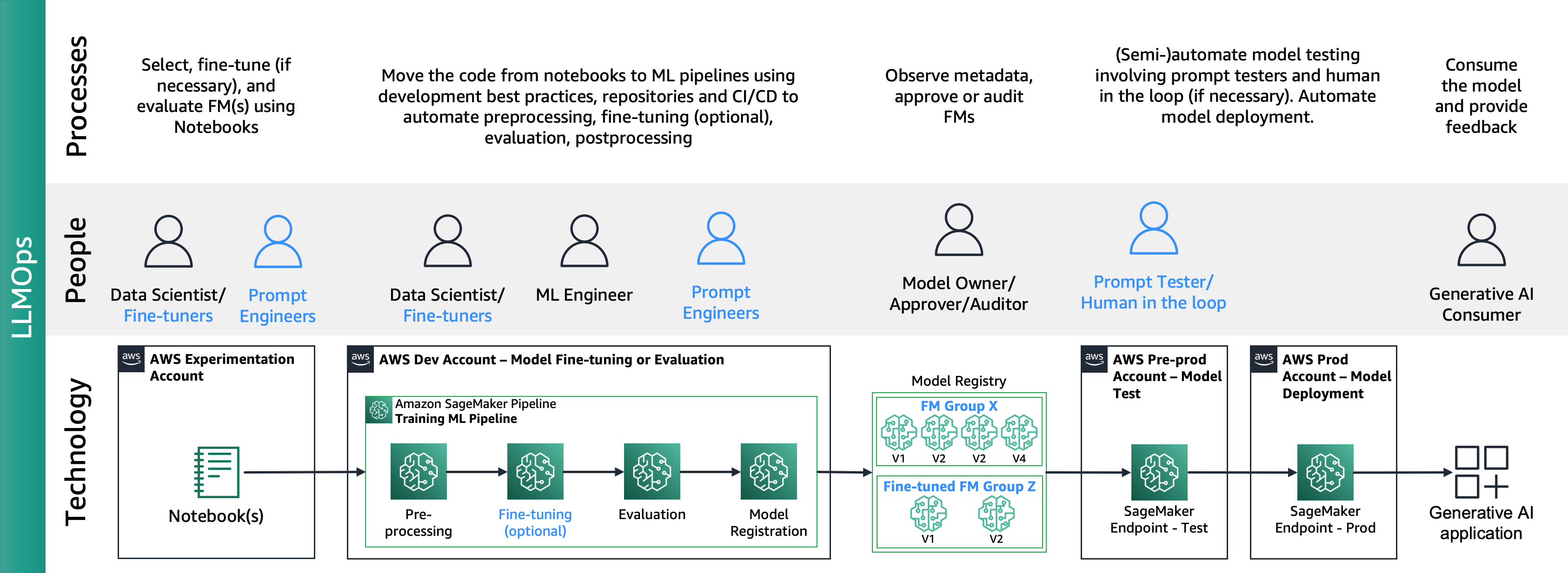
In LLMOps zijn de belangrijkste verschillen vergeleken met MLOps modelselectie en modelevaluatie waarbij verschillende processen en statistieken betrokken zijn. In de eerste experimenteerfase selecteren de datawetenschappers (of finetuners) de FM die zal worden gebruikt voor een specifieke generatieve AI-gebruikscasus.
Dit resulteert vaak in het testen en afstemmen van meerdere FM's, waarvan sommige vergelijkbare resultaten kunnen opleveren. Na de selectie van het/de model(len) zijn prompt-ingenieurs verantwoordelijk voor het voorbereiden van de noodzakelijke invoergegevens en de verwachte output voor evaluatie (bijvoorbeeld invoerprompts bestaande uit invoergegevens en query's) en definiëren ze metrieken zoals gelijkenis en toxiciteit. Naast deze statistieken moeten datawetenschappers of fijnafstemmers de resultaten valideren en de juiste FM kiezen, niet alleen op basis van precisiestatistieken, maar ook op basis van andere mogelijkheden zoals latentie en kosten. Vervolgens kunnen ze een model op een SageMaker-eindpunt implementeren en de prestaties ervan op kleine schaal testen. Hoewel de experimenteerfase een eenvoudig proces kan inhouden, vereist de overgang naar productie dat klanten het proces automatiseren en de robuustheid van de oplossing vergroten. Daarom moeten we dieper ingaan op de manier waarop we de evaluatie kunnen automatiseren, waardoor testers een efficiënte evaluatie op schaal kunnen uitvoeren en realtime monitoring van modelinvoer en -uitvoer kunnen implementeren.
Automatiseer FM-evaluatie
Amazon SageMaker Pipelines automatiseren alle fasen van voorverwerking, FM-verfijning (optioneel) en evaluatie op schaal. Gegeven de geselecteerde modellen tijdens het experimenteren, moeten prompt-ingenieurs een groter aantal cases behandelen door veel prompts voor te bereiden en deze op te slaan in een aangewezen opslagplaats, genaamd prompt catalog. Voor meer informatie, zie FMOps/LLMOps: Operationaliseer generatieve AI en verschillen met MLOps. Vervolgens kunnen Amazon SageMaker Pipelines als volgt worden gestructureerd:
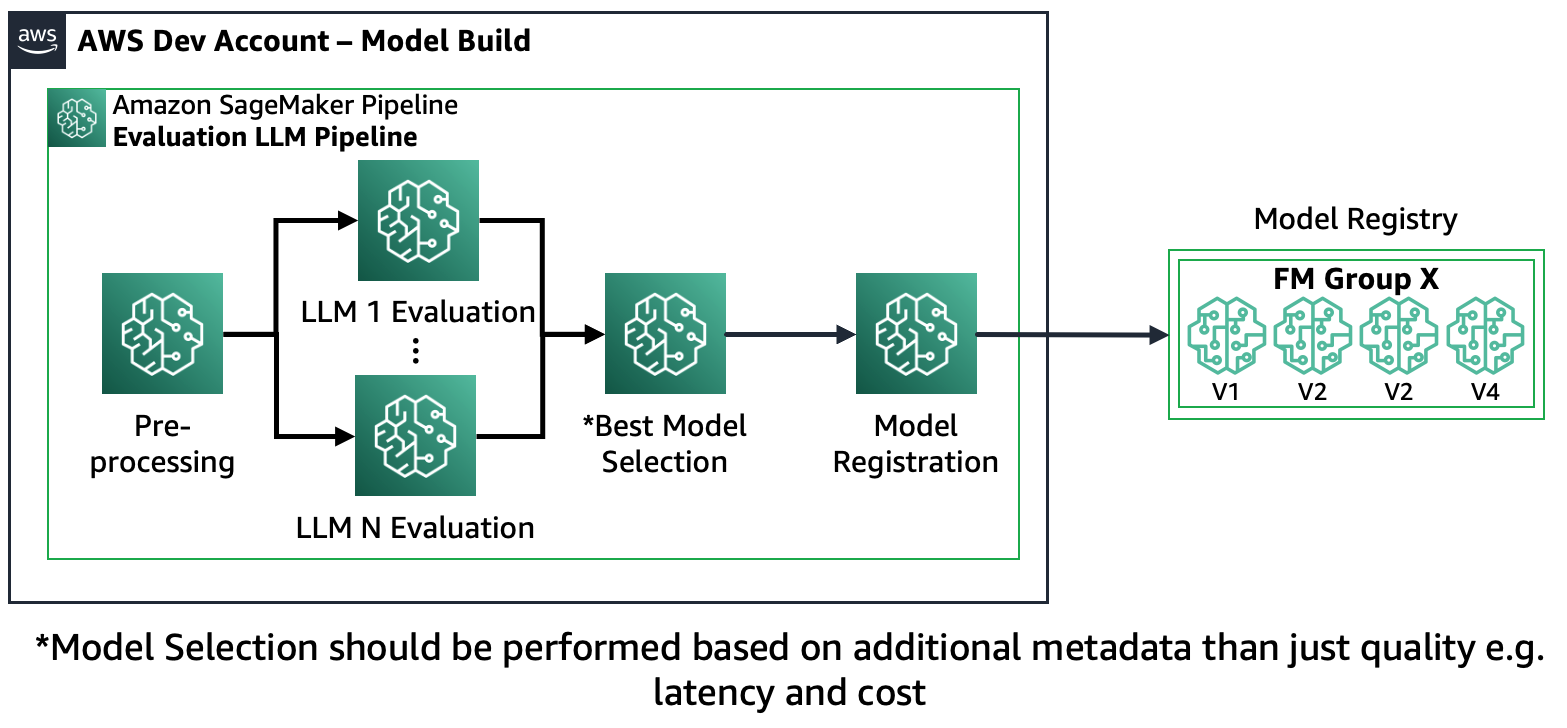
Scenario 1 – Evalueer meerdere FM's: In dit scenario kunnen de FM's de zakelijke gebruikscasus dekken zonder finetuning. De Amazon SageMaker Pipeline bestaat uit de volgende stappen: voorverwerking van gegevens, parallelle evaluatie van meerdere FM's, vergelijking van modellen en selectie op basis van nauwkeurigheid en andere eigenschappen zoals kosten of latentie, registratie van geselecteerde modelartefacten en metadata.
Het volgende diagram illustreert deze architectuur.
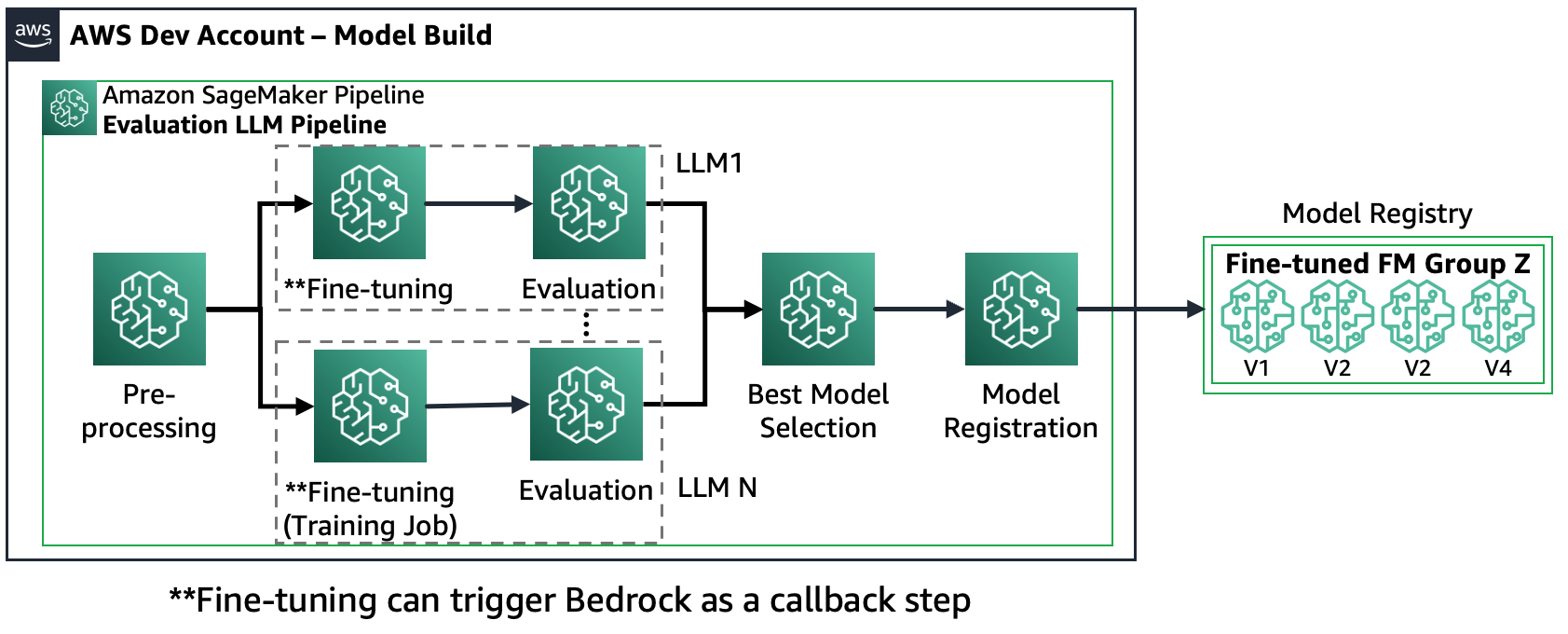
Scenario 2 – Meerdere FM's verfijnen en evalueren: In dit scenario is de Amazon SageMaker Pipeline net zo gestructureerd als Scenario 1, maar worden voor elke FM de stappen voor verfijning en evaluatie parallel uitgevoerd. Het best afgestemde model wordt geregistreerd in het Modelregister.
Het volgende diagram illustreert deze architectuur.
Scenario 3 – Evalueer meerdere FM's en verfijn de FM's: Dit scenario is een combinatie van het evalueren van FM's voor algemeen gebruik en verfijnde FM's. In dit geval willen de klanten controleren of een verfijnd model beter kan presteren dan een FM voor algemeen gebruik.
De volgende afbeelding toont de resulterende SageMaker Pipeline-stappen.
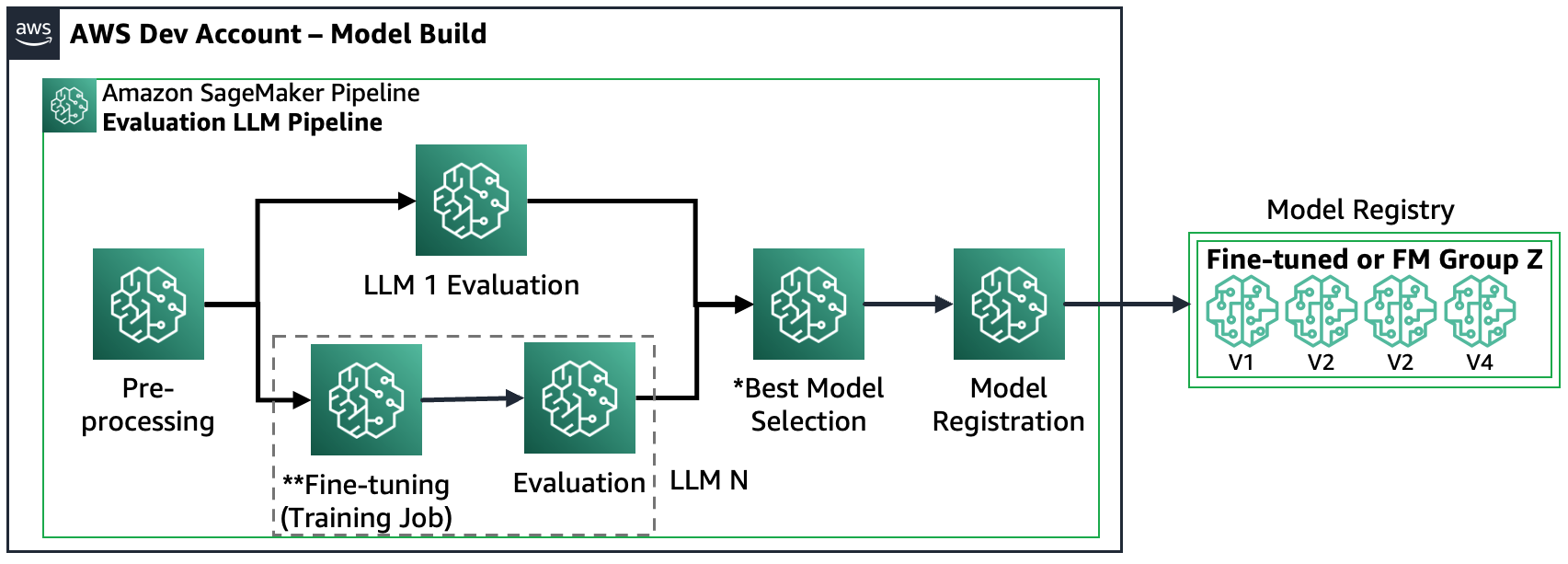
Merk op dat modelregistratie twee patronen volgt: (a) een open-sourcemodel en artefacten opslaan of (b) een verwijzing naar een eigen FM opslaan. Voor meer informatie, zie FMOps/LLMOps: Operationaliseer generatieve AI en verschillen met MLOps.
Overzicht oplossingen
Om uw reis naar LLM-evaluatie op schaal te versnellen, hebben we een oplossing gemaakt die de scenario's implementeert met behulp van zowel Amazon SageMaker Clarify als de nieuwe Amazon SageMaker Pipelines SDK. Het codevoorbeeld, inclusief datasets, bronnotebooks en SageMaker Pipelines (stappen en ML-pijplijn), is beschikbaar op GitHub. Om deze voorbeeldoplossing te ontwikkelen, hebben we twee FM's gebruikt: Llama2 en Falcon-7B. In dit bericht ligt onze primaire focus op de belangrijkste elementen van de SageMaker Pipeline-oplossing die betrekking hebben op het evaluatieproces.
Evaluatieconfiguratie: Om de evaluatieprocedure te standaardiseren, hebben we een YAML-configuratiebestand gemaakt (evaluation_config.yaml), dat de noodzakelijke details bevat voor het evaluatieproces, inclusief de dataset, het(de) model(len) en de algoritmen die tijdens de evaluatie moeten worden uitgevoerd. evaluatiestap van de SageMaker Pipeline. Het volgende voorbeeld illustreert het configuratiebestand:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"Evaluatiestap: De nieuwe SageMaker Pipeline SDK biedt gebruikers de flexibiliteit om aangepaste stappen in de ML-workflow te definiëren met behulp van de '@step' Python-decorator. Daarom moeten de gebruikers als volgt een basis Python-script maken dat de evaluatie uitvoert:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultSageMaker-pijplijn: Na het creëren van de noodzakelijke stappen, zoals gegevensvoorverwerking, modelimplementatie en modelevaluatie, moet de gebruiker de stappen aan elkaar koppelen met behulp van de SageMaker Pipeline SDK. De nieuwe SDK genereert automatisch de workflow door de afhankelijkheden tussen verschillende stappen te interpreteren wanneer een API voor het maken van een SageMaker Pipeline wordt aangeroepen, zoals weergegeven in het volgende voorbeeld:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
pipeline.start()In het voorbeeld wordt de evaluatie van een enkele FM geïmplementeerd door de initiële dataset voor te verwerken, het model te implementeren en de evaluatie uit te voeren. De gegenereerde pijplijngerichte acyclische grafiek (DAG) wordt weergegeven in de volgende afbeelding.
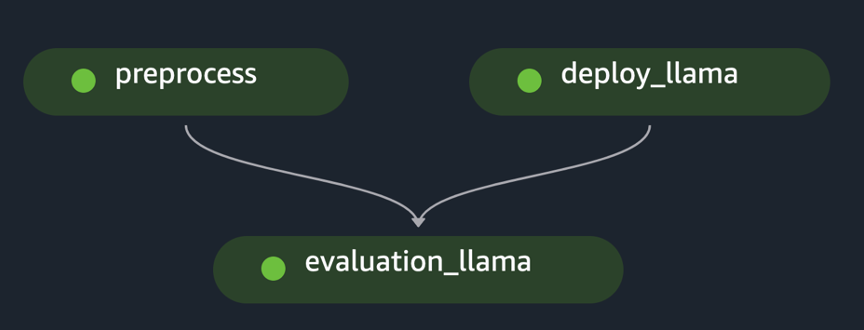
Door een vergelijkbare aanpak te volgen en het voorbeeld te gebruiken en aan te passen Verfijn LLaMA 2-modellen op SageMaker JumpStart, hebben we de pijplijn gemaakt om een verfijnd model te evalueren, zoals weergegeven in de volgende afbeelding.

Door de voorgaande SageMaker Pipeline-stappen als “Lego”-blokken te gebruiken, hebben we de oplossing voor Scenario 1 en Scenario 3 ontwikkeld, zoals weergegeven in de volgende afbeeldingen. In het bijzonder de GitHub Met de repository kan de gebruiker meerdere FM's parallel evalueren of een complexere evaluatie uitvoeren, waarbij evaluatie van zowel basis- als verfijnde modellen wordt gecombineerd.


Extra functionaliteiten die beschikbaar zijn in de repository zijn onder meer:
- Dynamische generatie van evaluatiestappen: Onze oplossing genereert dynamisch alle noodzakelijke evaluatiestappen op basis van het configuratiebestand, zodat gebruikers een willekeurig aantal modellen kunnen evalueren. We hebben de oplossing uitgebreid om een eenvoudige integratie van nieuwe soorten modellen te ondersteunen, zoals Hugging Face of Amazon Bedrock.
- Voorkom herimplementatie van eindpunten: Als er al een eindpunt aanwezig is, slaan we het implementatieproces over. Hierdoor kan de gebruiker eindpunten met FM's hergebruiken voor evaluatie, wat resulteert in kostenbesparingen en een kortere implementatietijd.
- Eindpunt opruimen: Na voltooiing van de evaluatie stelt de SageMaker Pipeline de geïmplementeerde eindpunten buiten gebruik. Deze functionaliteit kan worden uitgebreid om het beste modeleindpunt levend te houden.
- Modelselectiestap: We hebben een tijdelijke aanduiding voor de modelselectiestap toegevoegd die de bedrijfslogica van de uiteindelijke modelselectie vereist, inclusief criteria zoals kosten of latentie.
- Stap voor modelregistratie: Het beste model kan in Amazon SageMaker Model Registry worden geregistreerd als een nieuwe versie van een specifieke modelgroep.
- Warm zwembad: Met door SageMaker beheerde warme pools kunt u de ingerichte infrastructuur behouden en hergebruiken na voltooiing van een taak om de latentie voor repetitieve werklasten te verminderen
De volgende afbeelding illustreert deze mogelijkheden en een evaluatievoorbeeld van meerdere modellen dat de gebruikers eenvoudig en dynamisch kunnen maken met behulp van onze oplossing in deze GitHub repository.
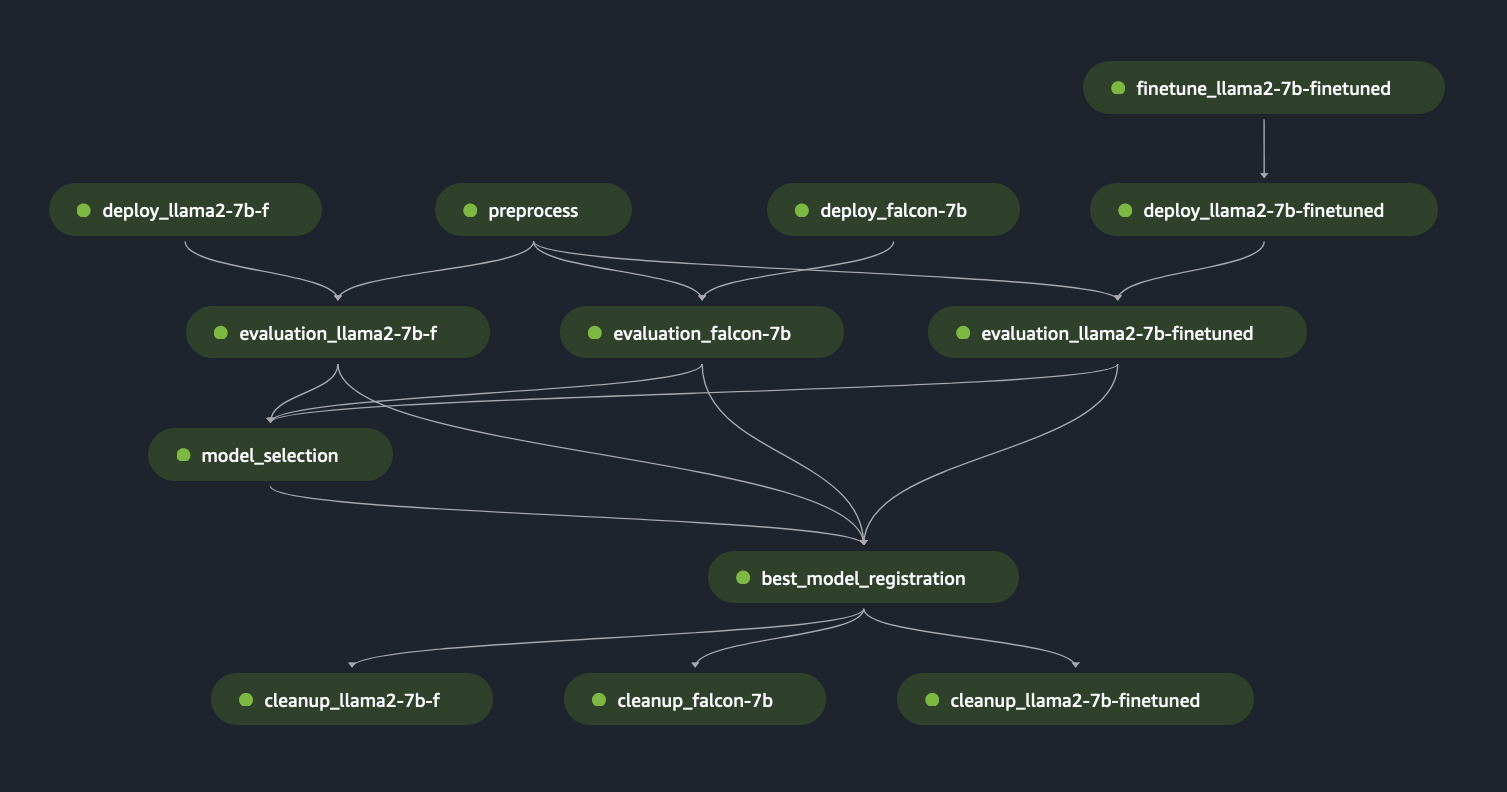
We hebben de gegevensvoorbereiding opzettelijk buiten het bereik gehouden, omdat deze in een ander bericht diepgaand zal worden beschreven, inclusief promptcatalogusontwerpen, promptsjablonen en promptoptimalisatie. Voor meer informatie en gerelateerde componentdefinities raadpleegt u FMOps/LLMOps: Operationaliseer generatieve AI en verschillen met MLOps.
Conclusie
In dit bericht hebben we ons gericht op het automatiseren en operationeel maken van de evaluatie van LLM's op grote schaal met behulp van Amazon SageMaker Clarify LLM-evaluatiemogelijkheden en Amazon SageMaker Pipelines. Naast theoretische architectuurontwerpen hebben we hierin voorbeeldcode GitHub repository (met Llama2 en Falcon-7B FM's) waarmee klanten hun eigen schaalbare evaluatiemechanismen kunnen ontwikkelen.
De volgende afbeelding toont de modelevaluatiearchitectuur.

In dit bericht hebben we ons gericht op het operationeel maken van de LLM-evaluatie op schaal, zoals weergegeven aan de linkerkant van de afbeelding. In de toekomst zullen we ons concentreren op het ontwikkelen van voorbeelden die de end-to-end levenscyclus van FM's tot productie vervullen door de richtlijn te volgen die wordt beschreven in FMOps/LLMOps: Operationaliseer generatieve AI en verschillen met MLOps. Dit omvat LLM-bediening, monitoring en opslag van outputbeoordelingen die uiteindelijk automatische herevaluatie en fijnafstemming zullen veroorzaken en, ten slotte, het gebruik van mens-in-the-loop om te werken aan gelabelde gegevens of promptcatalogi.
Over de auteurs
 Dr Sokratis Kartakis is een Principal Machine Learning en Operations Specialist Solutions Architect voor Amazon Web Services. Sokratis richt zich erop zakelijke klanten in staat te stellen hun Machine Learning (ML) en generatieve AI-oplossingen te industrialiseren door AWS-services te exploiteren en hun bedrijfsmodel vorm te geven, dat wil zeggen MLOps/FMOps/LLMOps-fundamenten, en een transformatie-roadmap waarbij gebruik wordt gemaakt van de beste ontwikkelingspraktijken. Hij heeft meer dan 15 jaar besteed aan het bedenken, ontwerpen, leiden en implementeren van innovatieve end-to-end ML- en AI-oplossingen op productieniveau op het gebied van energie, detailhandel, gezondheidszorg, financiën, autosport enz.
Dr Sokratis Kartakis is een Principal Machine Learning en Operations Specialist Solutions Architect voor Amazon Web Services. Sokratis richt zich erop zakelijke klanten in staat te stellen hun Machine Learning (ML) en generatieve AI-oplossingen te industrialiseren door AWS-services te exploiteren en hun bedrijfsmodel vorm te geven, dat wil zeggen MLOps/FMOps/LLMOps-fundamenten, en een transformatie-roadmap waarbij gebruik wordt gemaakt van de beste ontwikkelingspraktijken. Hij heeft meer dan 15 jaar besteed aan het bedenken, ontwerpen, leiden en implementeren van innovatieve end-to-end ML- en AI-oplossingen op productieniveau op het gebied van energie, detailhandel, gezondheidszorg, financiën, autosport enz.
 Jagdeep Singh Soni is een Senior Partner Solutions Architect bij AWS gevestigd in Nederland. Hij gebruikt zijn passie voor DevOps, GenAI en buildertools om zowel systeemintegrators als technologiepartners te helpen. Jagdeep past zijn achtergrond in applicatieontwikkeling en architectuur toe om innovatie binnen zijn team te stimuleren en nieuwe technologieën te promoten.
Jagdeep Singh Soni is een Senior Partner Solutions Architect bij AWS gevestigd in Nederland. Hij gebruikt zijn passie voor DevOps, GenAI en buildertools om zowel systeemintegrators als technologiepartners te helpen. Jagdeep past zijn achtergrond in applicatieontwikkeling en architectuur toe om innovatie binnen zijn team te stimuleren en nieuwe technologieën te promoten.
 Dr. Riccardo Gatti is een Senior Startup Solution Architect gevestigd in Italië. Hij is technisch adviseur voor klanten en helpt hen hun bedrijf te laten groeien door de juiste tools en technologieën te selecteren om te innoveren, snel te schalen en binnen enkele minuten wereldwijd te gaan. Hij is altijd gepassioneerd geweest door machinaal leren en generatieve AI, en heeft deze technologieën gedurende zijn hele carrière in verschillende domeinen bestudeerd en toegepast. Hij is gastheer en redacteur van de Italiaanse AWS-podcast ‘Casa Startup’, gewijd aan verhalen van oprichters van startups en nieuwe technologische trends.
Dr. Riccardo Gatti is een Senior Startup Solution Architect gevestigd in Italië. Hij is technisch adviseur voor klanten en helpt hen hun bedrijf te laten groeien door de juiste tools en technologieën te selecteren om te innoveren, snel te schalen en binnen enkele minuten wereldwijd te gaan. Hij is altijd gepassioneerd geweest door machinaal leren en generatieve AI, en heeft deze technologieën gedurende zijn hele carrière in verschillende domeinen bestudeerd en toegepast. Hij is gastheer en redacteur van de Italiaanse AWS-podcast ‘Casa Startup’, gewijd aan verhalen van oprichters van startups en nieuwe technologische trends.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/

