In recent years, data lakes have become a mainstream architecture, and data quality validation is a critical factor to improve the reusability and consistency of the data. AWS Glue Data Quality reduces the effort required to validate data from days to hours, and provides computing recommendations, statistics, and insights about the resources required to run data validation.
AWS Glue Data Quality is built on DeeQu, an open source tool developed and used at Amazon to calculate data quality metrics and verify data quality constraints and changes in the data distribution so you can focus on describing how data should look instead of implementing algorithms.
In this post, we provide benchmark results of running increasingly complex data quality rulesets over a predefined test dataset. As part of the results, we show how AWS Glue Data Quality provides information about the runtime of extract, transform, and load (ETL) jobs, the resources measured in terms of data processing units (DPUs), and how you can track the cost of running AWS Glue Data Quality for ETL pipelines by defining custom cost reporting in AWS Cost Explorer.
Solution overview
We start by defining our test dataset in order to explore how AWS Glue Data Quality automatically scales depending on input datasets.
Dataset details
The test dataset contains 104 columns and 1 million rows stored in Parquet format. You can download the dataset or recreate it locally using the Python script provided in the repository. If you opt to run the generator script, you need to install the Pandas and Mimesis packages in your Python environment:
The dataset schema is a combination of numerical, categorical, and string variables in order to have enough attributes to use a combination of built-in AWS Glue Data Quality rule types. The schema replicates some of the most common attributes found in financial market data such as instrument ticker, traded volumes, and pricing forecasts.
Data quality rulesets
We categorize some of the built-in AWS Glue Data Quality rule types to define the benchmark structure. The categories consider whether the rules perform column checks that don’t require row-level inspection (simple rules), row-by-row analysis (medium rules), or data type checks, eventually comparing row values against other data sources (complex rules). The following table summarizes these rules.
| Simple Rules | Medium Rules | Complex Rules |
| ColumnCount | DistinctValuesCount | ColumnValues |
| ColumnDataType | IsComplete | Completeness |
| ColumnExist | Sum | ReferentialIntegrity |
| ColumnNamesMatchPattern | StandardDeviation | ColumnCorrelation |
| RowCount | Mean | RowCountMatch |
| ColumnLength | . | . |
We define eight different AWS Glue ETL jobs where we run the data quality rulesets. Each job has a different number of data quality rules associated to it. Each job also has an associated user-defined cost allocation tag that we use to create a data quality cost report in AWS Cost Explorer later on.
We provide the plain text definition for each ruleset in the following table.
| Job name | Simple Rules | Medium Rules | Complex Rules | Number of Rules | Tag | Definition |
| ruleset-0 | 0 | 0 | 0 | 0 | dqjob:rs0 | – |
| ruleset-1 | 0 | 0 | 1 | 1 | dqjob:rs1 | Link |
| ruleset-5 | 3 | 1 | 1 | 5 | dqjob:rs5 | Link |
| ruleset-10 | 6 | 2 | 2 | 10 | dqjob:rs10 | Link |
| ruleset-50 | 30 | 10 | 10 | 50 | dqjob:rs50 | Link |
| ruleset-100 | 50 | 30 | 20 | 100 | dqjob:rs100 | Link |
| ruleset-200 | 100 | 60 | 40 | 200 | dqjob:rs200 | Link |
| ruleset-400 | 200 | 120 | 80 | 400 | dqjob:rs400 | Link |
Create the AWS Glue ETL jobs containing the data quality rulesets
We upload the test dataset to Amazon Simple Storage Service (Amazon S3) and also two additional CSV files that we’ll use to evaluate referential integrity rules in AWS Glue Data Quality (isocodes.csv and exchanges.csv) after they have been added to the AWS Glue Data Catalog. Complete the following steps:
- On the Amazon S3 console, create a new S3 bucket in your account and upload the test dataset.
- Create a folder in the S3 bucket called
isocodesand upload the isocodes.csv file. - Create another folder in the S3 bucket called exchange and upload the exchanges.csv file.
- On the AWS Glue console, run two AWS Glue crawlers, one for each folder to register the CSV content in AWS Glue Data Catalog (
data_quality_catalog). For instructions, refer to Adding an AWS Glue Crawler.
The AWS Glue crawlers generate two tables (exchanges and isocodes) as part of the AWS Glue Data Catalog.

Now we will create the AWS Identity and Access Management (IAM) role that will be assumed by the ETL jobs at runtime:
- On the IAM console, create a new IAM role called
AWSGlueDataQualityPerformanceRole - For Trusted entity type, select AWS service.
- For Service or use case, choose Glue.
- Choose Next.

- For Permission policies, enter
AWSGlueServiceRole - Choose Next.

- Create and attach a new inline policy (
AWSGlueDataQualityBucketPolicy) with the following content. Replace the placeholder with the S3 bucket name you created earlier:
Next, we create one of the AWS Glue ETL jobs, ruleset-5.
- On the AWS Glue console, under ETL jobs in the navigation pane, choose Visual ETL.
- In the Create job section, choose Visual ETL.x

- In the Visual Editor, add a Data Source – S3 Bucket source node:
- For S3 URL, enter the S3 folder containing the test dataset.
- For Data format, choose Parquet.

- Create a new action node, Transform: Evaluate-Data-Catalog:
- For Node parents, choose the node you created.
- Add the ruleset-5 definition under Ruleset editor.

- Scroll to the end and under Performance Configuration, enable Cache Data.

- Under Job details, for IAM Role, choose
AWSGlueDataQualityPerformanceRole.
- In the Tags section, define dqjob tag as rs5.
This tag will be different for each of the data quality ETL jobs; we use them in AWS Cost Explorer to review the ETL jobs cost.

- Choose Save.
- Repeat these steps with the rest of the rulesets to define all the ETL jobs.

Run the AWS Glue ETL jobs
Complete the following steps to run the ETL jobs:
- On the AWS Glue console, choose Visual ETL under ETL jobs in the navigation pane.
- Select the ETL job and choose Run job.
- Repeat for all the ETL jobs.

When the ETL jobs are complete, the Job run monitoring page will display the job details. As shown in the following screenshot, a DPU hours column is provided for each ETL job.

Review performance
The following table summarizes the duration, DPU hours, and estimated costs from running the eight different data quality rulesets over the same test dataset. Note that all rulesets have been run with the entire test dataset described earlier (104 columns, 1 million rows).
| ETL Job Name | Number of Rules | Tag | Duration (sec) | # of DPU hours | # of DPUs | Cost ($) |
| ruleset-400 | 400 | dqjob:rs400 | 445.7 | 1.24 | 10 | $0.54 |
| ruleset-200 | 200 | dqjob:rs200 | 235.7 | 0.65 | 10 | $0.29 |
| ruleset-100 | 100 | dqjob:rs100 | 186.5 | 0.52 | 10 | $0.23 |
| ruleset-50 | 50 | dqjob:rs50 | 155.2 | 0.43 | 10 | $0.19 |
| ruleset-10 | 10 | dqjob:rs10 | 152.2 | 0.42 | 10 | $0.18 |
| ruleset-5 | 5 | dqjob:rs5 | 150.3 | 0.42 | 10 | $0.18 |
| ruleset-1 | 1 | dqjob:rs1 | 150.1 | 0.42 | 10 | $0.18 |
| ruleset-0 | 0 | dqjob:rs0 | 53.2 | 0.15 | 10 | $0.06 |
The cost of evaluating an empty ruleset is close to zero, but it has been included because it can be used as a quick test to validate the IAM roles associated to the AWS Glue Data Quality jobs and read permissions to the test dataset in Amazon S3. The cost of data quality jobs only starts to increase after evaluating rulesets with more than 100 rules, remaining constant below that number.
We can observe that the cost of running data quality for the largest ruleset in the benchmark (400 rules) is still slightly above $0.50.
Data quality cost analysis in AWS Cost Explorer
In order to see the data quality ETL job tags in AWS Cost Explorer, you need to activate the user-defined cost allocation tags first.
After you create and apply user-defined tags to your resources, it can take up to 24 hours for the tag keys to appear on your cost allocation tags page for activation. It can then take up to 24 hours for the tag keys to activate.
- On the AWS Cost Explorer console, choose Cost Explorer Saved Reports in the navigation pane.
- Choose Create new report.

- Select Cost and usage as the report type.
- Choose Create Report.
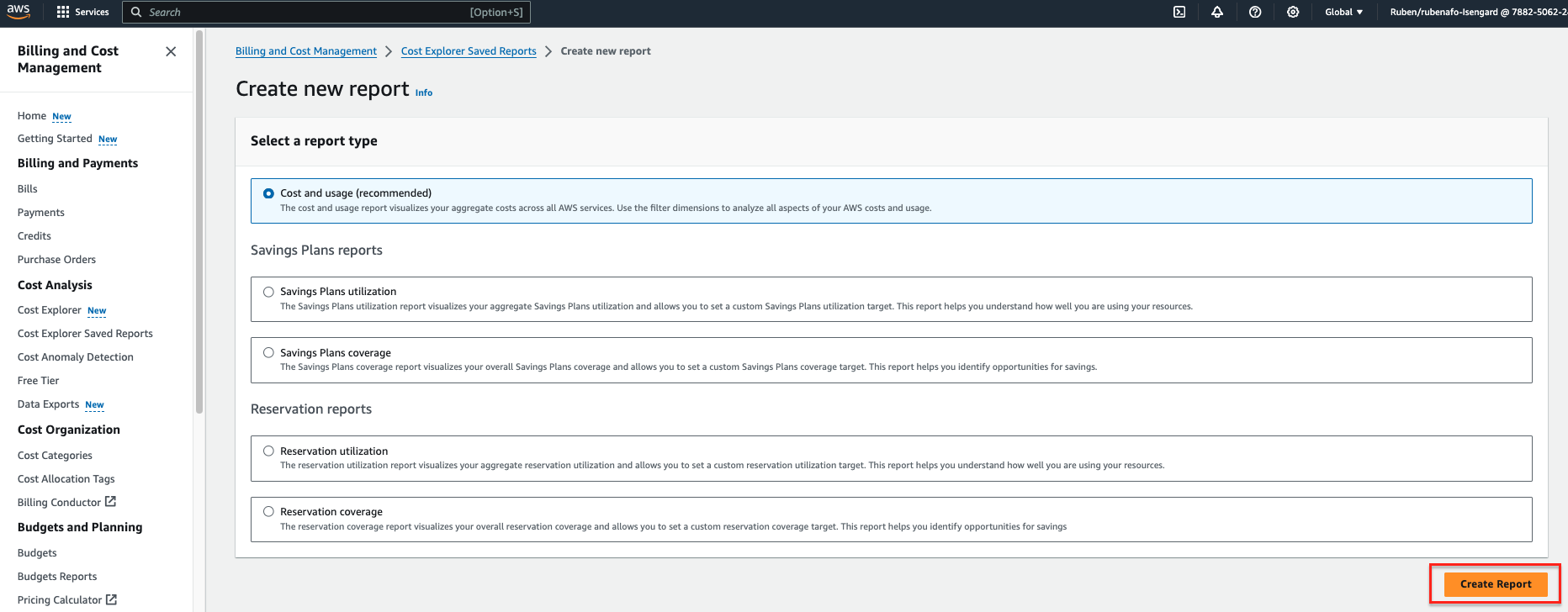
- For Date Range, enter a date range.
- For Granularity¸ choose Daily.
- For Dimension, choose Tag, then choose the
dqjobtag.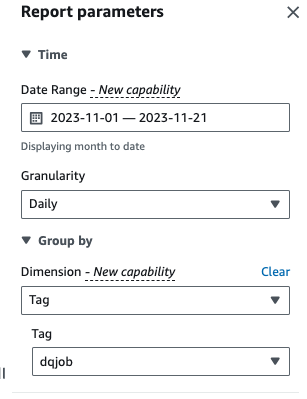
- Under Applied filters, choose the
dqjobtag and the eight tags used in the data quality rulesets (rs0, rs1, rs5, rs10, rs50, rs100, rs200, and rs400).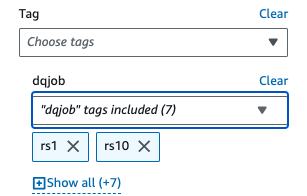
- Choose Apply.
The Cost and Usage report will be updated. The X-axis shows the data quality ruleset tags as categories. The Cost and usage graph in AWS Cost Explorer will refresh and show the total monthly cost of the latest data quality ETL jobs run, aggregated by ETL job.

Clean up
To clean up the infrastructure and avoid additional charges, complete the following steps:
- Empty the S3 bucket initially created to store the test dataset.
- Delete the ETL jobs you created in AWS Glue.
- Delete the
AWSGlueDataQualityPerformanceRoleIAM role. - Delete the custom report created in AWS Cost Explorer.
Conclusion
AWS Glue Data Quality provides an efficient way to incorporate data quality validation as part of ETL pipelines and scales automatically to accommodate increasing volumes of data. The built-in data quality rule types offer a wide range of options to customize the data quality checks and focus on how your data should look instead of implementing undifferentiated logic.
In this benchmark analysis, we showed how common-size AWS Glue Data Quality rulesets have little or no overhead, whereas in complex cases, the cost increases linearly. We also reviewed how you can tag AWS Glue Data Quality jobs to make cost information available in AWS Cost Explorer for quick reporting.
AWS Glue Data Quality is generally available in all AWS Regions where AWS Glue is available. Learn more about AWS Glue Data Quality and AWS Glue Data Catalog in Getting started with AWS Glue Data Quality from the AWS Glue Data Catalog.
About the Authors
 Ruben Afonso is a Global Financial Services Solutions Architect with AWS. He enjoys working on analytics and AI/ML challenges, with a passion for automation and optimization. When not at work, he enjoys finding hidden spots off the beaten path around Barcelona.
Ruben Afonso is a Global Financial Services Solutions Architect with AWS. He enjoys working on analytics and AI/ML challenges, with a passion for automation and optimization. When not at work, he enjoys finding hidden spots off the beaten path around Barcelona.
 Kalyan Kumar Neelampudi (KK) is a Specialist Partner Solutions Architect (Data Analytics & Generative AI) at AWS. He acts as a technical advisor and collaborates with various AWS partners to design, implement, and build practices around data analytics and AI/ML workloads. Outside of work, he’s a badminton enthusiast and culinary adventurer, exploring local cuisines and traveling with his partner to discover new tastes and experiences.
Kalyan Kumar Neelampudi (KK) is a Specialist Partner Solutions Architect (Data Analytics & Generative AI) at AWS. He acts as a technical advisor and collaborates with various AWS partners to design, implement, and build practices around data analytics and AI/ML workloads. Outside of work, he’s a badminton enthusiast and culinary adventurer, exploring local cuisines and traveling with his partner to discover new tastes and experiences.

Gonzalo Herreros is a Senior Big Data Architect on the AWS Glue team.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/measure-performance-of-aws-glue-data-quality-for-etl-pipelines/

