개요
대규모 언어 모델(Large Language Models)의 출현으로LLM), 이들은 다음과 같은 소형 변압기 모델을 대체하여 수많은 애플리케이션에 침투했습니다. BERT 또는 많은 분야의 규칙 기반 모델 자연 언어 처리 (NLP) 작업. LLM은 다재다능하며 광범위한 사전 교육을 통해 텍스트 분류, 요약, 감정 분석 및 주제 모델링과 같은 작업을 처리할 수 있습니다. 그러나 광범위한 기능에도 불구하고 LLM은 소규모 LLM에 비해 정확도가 떨어지는 경우가 많습니다.
이러한 제한 사항을 해결하기 위한 효과적인 전략 중 하나는 사전 훈련된 LLM을 미세 조정하여 특정 작업에서 탁월한 성능을 발휘하도록 하는 것입니다. 대형 모델을 미세 조정하면 최적의 결과를 얻는 경우가 많습니다. 특히, 다른 대형 모델 중에서 Google의 Gemini는 이제 사용자에게 자체 교육 데이터를 사용하여 이러한 모델을 미세 조정할 수 있는 기능을 제공합니다. 이 가이드에서는 특정 문제에 맞게 Gemini 모델을 미세 조정하는 과정과 HuggingFace의 리소스를 사용하여 데이터 세트를 선별하는 방법을 안내합니다.
학습 목표
- Google Gemini 모델의 성능을 이해합니다.
- Gemini 모델 미세 조정을 위한 데이터 세트 준비에 대해 알아보세요.
- Gemini 모델 미세 조정을 위한 매개변수를 구성합니다.
- 미세 조정 진행 상황과 지표를 모니터링합니다.
- 새 데이터에서 Gemini 모델 성능을 테스트합니다.
- PII 마스킹을 위한 Gemini 모델 애플리케이션을 살펴보세요.

이 기사는 데이터 과학 블로그.
차례
Google, Tuning Gemini 발표
Gemini는 Pro와 Ultra의 두 가지 버전으로 제공됩니다. Pro 버전에는 Gemini 1.0 Pro와 새로운 Gemini 1.5 Pro가 있습니다. Google의 이러한 모델은 ChatGPT 및 Claude와 같은 다른 고급 모델과 경쟁합니다. Gemini 모델은 AI Studio UI와 무료 API를 통해 누구나 쉽게 액세스할 수 있습니다.
최근 Google은 Gemini 모델의 새로운 기능인 미세 조정을 발표했습니다. 이는 누구나 자신의 필요에 맞게 Gemini 모델을 조정할 수 있음을 의미합니다. AI Studio UI 또는 해당 API를 사용하여 Gemini를 미세 조정할 수 있습니다. 미세 조정은 Gemini에 자체 데이터를 제공하여 원하는 방식으로 작동할 수 있도록 하는 것입니다. Google은 PET(매개변수 효율적 조정)를 사용하여 Gemini 모델의 몇 가지 중요한 부분을 신속하게 조정하여 다양한 작업에 유용하게 만듭니다.
데이터세트 준비
모델 미세 조정을 시작하기 전에 필요한 라이브러리 설치부터 시작하겠습니다. 그런데 이 가이드에서는 Colab과 협력할 예정입니다.
필요한 라이브러리 설치
다음은 시작하는 데 필요한 Python 모듈입니다.
!pip install -q google-generativeai datasets- google-generativeai: Google Gemini 모델에 액세스할 수 있게 해주는 Google 팀의 라이브러리입니다. 동일한 라이브러리를 사용하여 Gemini 모델을 미세 조정할 수 있습니다.
- 데이터세트: 이는 HuggingFace 허브에서 다양한 데이터 세트를 다운로드하는 데 사용할 수 있는 HuggingFace의 라이브러리입니다. 우리는 이 데이터 세트 라이브러리를 사용하여 PII(개인 식별 정보) 데이터 세트를 다운로드하고 이를 Gemini 모델에 제공하여 미세 조정을 수행할 것입니다.
다음 코드를 실행하면 Python 환경에 Google Generative AI 및 데이터 세트 라이브러리가 다운로드되어 설치됩니다.
OAuth 설정
다음 단계에서는 이 튜토리얼에 대한 OAuth를 설정해야 합니다. OAuth는 Gemini 미세 조정을 위해 Google에 전송하는 데이터를 안전하게 유지하기 위해 필요합니다. OAuth를 얻으려면 다음을 따르십시오. 링크. 그런 다음 OAuth를 생성한 후 client_secret.json을 다운로드합니다. CLIENT_SECRET 이름 아래 Colab Secrets에 client_secrent.json의 내용을 저장하고 아래 코드를 실행합니다.
import os
if 'COLAB_RELEASE_TAG' in os.environ:
from google.colab import userdata
import pathlib
pathlib.Path('client_secret.json').write_text(userdata.get('CLIENT_SECRET'))
# Use `--no-browser` in colab
!gcloud auth application-default login --no-browser
--client-id-file client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'
else:
!gcloud auth application-default login --client-id-file
client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'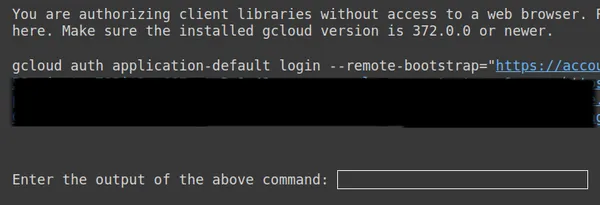
위에서 두 번째 링크를 복사하여 CMD 로컬 시스템에 붙여넣고 실행합니다.
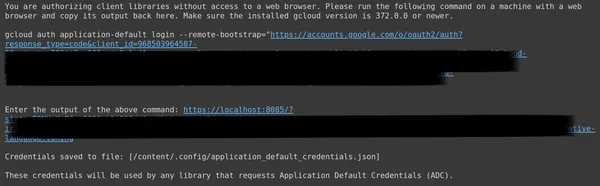
그러면 OAuth를 설정한 이메일로 로그인할 수 있는 웹 브라우저로 리디렉션됩니다. 로그인 후 CMD에 URL이 표시되면 해당 URL을 세 번째 줄에 붙여넣고 Enter 키를 누릅니다. 이제 Google을 통한 OAuth 수행이 완료되었습니다.
데이터 세트 다운로드 및 준비
먼저, Gemini 모델에 맞게 미세 조정하는 데 사용할 데이터 세트를 다운로드하는 것부터 시작하겠습니다. 이를 위해 데이터 세트 라이브러리를 사용합니다. 이에 대한 코드는 다음과 같습니다.
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
print(dataset)- 여기서는 데이터 세트 라이브러리에서 load_dataset 함수를 가져오는 것부터 시작합니다.
- 이 load_dataset() 함수에 다운로드하려는 데이터 세트를 전달합니다. 여기 예시에서는 "ai4privacy/pii-masking-200k"이며, 여기에는 200행의 마스킹된 PII 데이터와 마스킹되지 않은 PII 데이터가 포함되어 있습니다.
- 그런 다음 데이터 세트를 인쇄합니다.

데이터 세트에는 209261개의 훈련 데이터 행이 포함되어 있고 테스트 데이터는 없는 것을 볼 수 있습니다. 그리고 각 행에는 Masked_text, unmasked_text, Privacy_mask,span_labels, bio_labels 및 tokenised_text와 같은 다양한 열이 포함되어 있습니다. 샘플 데이터는 다음과 같습니다.
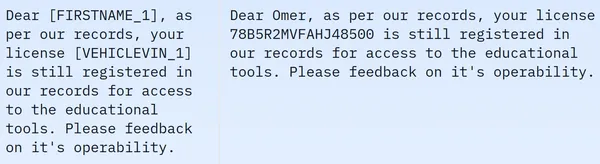
표시된 이미지에서 우리는 마스크된 문장과 마스크되지 않은 문장을 모두 관찰합니다. 구체적으로 마스킹된 문장에서는 사람 이름, 차량번호 등 특정 요소가 특정 태그에 의해 가려져 있다. 추가 처리를 위해 데이터를 준비하려면 이제 일부 데이터 전처리를 수행해야 합니다. 다음은 이 전처리 단계에 대한 코드입니다.
df = dataset['train'].to_pandas()
df = df[['unmasked_text','masked_text']][:2000]
df.columns = ['input','output']
- 먼저 데이터 세트에서 데이터의 훈련 부분을 가져옵니다(다운로드한 데이터 세트에는 훈련 부분만 포함되어 있습니다). 그런 다음 이를 Pandas Dataframe으로 변환합니다.
- 여기에서는 Gemini를 미세 조정하려면 unmasked_text 및 Masked_text 열만 필요하므로 이 두 개만 사용합니다.
- 그런 다음 데이터의 처음 2000개 행을 얻습니다. Gemini를 미세 조정하기 위해 처음 2000개 행을 사용하여 작업할 것입니다.
- 그런 다음 unmasked_text 및 Masked_text의 열 이름을 입력 및 출력 열로 편집합니다. 왜냐하면 PII(개인 식별 정보)가 포함된 입력 텍스트 데이터를 Gemini 모델에 제공할 때 PII가 있는 출력 텍스트 데이터를 생성할 것으로 예상하기 때문입니다. 마스크되어 있습니다.
Gemini 미세 조정을 위한 데이터 형식 지정
다음 단계는 데이터 형식을 지정하는 것입니다. 이를 위해 포맷터 기능을 생성할 것입니다:
def formatter(x):
text = f"""
Given the information below, mask the personal identifiable information.
Input:
{x['input']}
Output:
"""
return text
df['text_input'] = df.apply(formatter,axis=1)
print(df['text_input'][0])- 여기서는 데이터 행인 x를 가져오는 함수 포맷터를 정의합니다.
- 그런 다음 f-문자열로 변수 텍스트를 정의합니다. 여기서 컨텍스트를 제공하고 이어서 데이터프레임의 입력 데이터를 제공합니다.
- 마지막으로 서식이 지정된 텍스트를 반환합니다.
- 마지막 줄은 apply() 함수를 통해 생성한 데이터프레임의 각 행에 포맷터 함수를 적용합니다.
- axis=1은 함수가 데이터프레임의 각 행에 적용됨을 나타냅니다.
코드를 실행하면 입력 필드를 포함하여 각 행에 대해 서식이 지정된 텍스트가 포함된 "train"이라는 새 열이 생성됩니다. 데이터프레임의 요소 중 하나를 관찰해 보겠습니다.
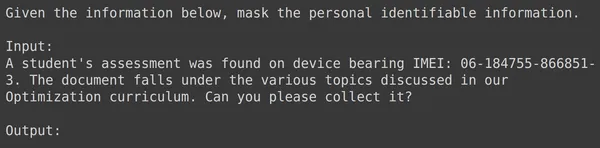
데이터를 훈련 세트와 테스트 세트로 나누기
text_input에는 각 행에 PII를 마스킹하라는 데이터 시작 부분에 컨텍스트가 포함되어 있고 입력 데이터가 뒤따르고 그 뒤에 출력이라는 단어가 오는 데이터가 포함되어 있음을 알 수 있습니다. 여기서 모델은 출력을 생성해야 합니다. 이제 데이터프레임을 학습 및 테스트로 나누어야 합니다.
df = df[['text_input','output']]
df_train = df.iloc[:1900,:]
df_test = df.iloc[1900:,:]- text_input 및 출력 열이 포함되도록 데이터를 필터링하는 것부터 시작합니다. Gemini를 훈련시키기 위해 Google Fine-Tune 라이브러리에서 예상되는 열입니다.
- Gemini는 text_input을 얻고 출력을 작성하는 방법을 배웁니다.
- 데이터를 원본 데이터의 1900개 행을 포함하는 df_train으로 나눕니다.
- 그리고 원본 데이터의 약 100행을 포함하는 df_test
- df_train에서 Gemini를 훈련한 다음 df_test에서 3-4개의 예를 가져와 테스트하여 생성된 출력을 확인합니다.
따라서 코드를 실행하면 데이터가 필터링되어 학습과 테스트로 나뉩니다. 마지막으로 데이터 전처리 부분이 끝났습니다.
쌍둥이자리 모델 미세 조정
Gemini 모델을 미세 조정하려면 아래에 언급된 단계를 따르세요.
튜닝 매개변수 설정
이번 섹션에서는 Gemini 모델을 튜닝하는 과정을 살펴보겠습니다. 이를 위해 다음 코드를 사용하여 작업합니다.
import google.generativeai as genai
bm_name = "models/gemini-1.0-pro-001"
name = 'pii-model'
operation = genai.create_tuned_model(
source_model=bm_name,
training_data=df_train,
id = name,
epoch_count = 2,
batch_size=4,
learning_rate=0.001,
)
- google.generativeai 라이브러리 가져오기: 이 라이브러리는 Google의 Generative AI 서비스와 상호작용하기 위한 API를 제공합니다.
- 기본 모델 이름 제공: 이는 미세 조정된 모델의 시작점으로 작업하려는 사전 훈련된 모델의 이름입니다. 현재 조정 가능한 유일한 모델은 models/gemini-1.0-pro-001이며, 이를 bm_name 변수에 저장합니다.
- 미세 조정된 모델의 이름 제공: 미세 조정된 모델에 부여할 이름입니다. 여기서는 "pii-model"이라는 이름을 지정합니다.
- 튜닝된 모델 작업 개체 만들기: 이 개체는 미세 조정된 모델을 만드는 작업을 나타냅니다. 다음 인수를 사용합니다.
- source_model: 기본 모델의 이름
- training_data: 방금 생성한 미세 조정 모델(df_train)에 대한 훈련 데이터입니다.
- id: 미세 조정된 모델의 ID/이름
- epoch_count: 학습 에포크 횟수입니다. 이 예에서는 2개의 에포크를 사용합니다.
- 배치_크기: 훈련을 위한 배치 크기입니다. 이 예에서는 값을 4로 설정하겠습니다.
- learning_rate: 학습에 대한 학습률입니다. 여기서는 0.001의 값을 제공합니다.
- 매개변수 제공이 완료되었습니다. 이 코드를 실행하면 미세 조정된 모델 객체가 생성됩니다. 이제 Gemini LLM 교육 과정을 시작해야 합니다. 이를 위해 다음 코드를 사용하여 작업합니다.
매개변수 설정이 완료되었습니다. 이 코드를 실행하면 조정된 모델 객체가 생성됩니다. 이제 Gemini LLM 교육 과정을 시작해야 합니다. 이를 위해 다음 코드를 사용하여 작업합니다.
model = genai.get_tuned_model(f'tunedModels/{name}')
print(model)조정된 모델 생성
여기서는 genai 라이브러리의 .get_tuned_model() 함수를 사용하여 정의된 모델 이름을 전달하고 훈련 프로세스를 시작합니다. 그런 다음 아래 이미지와 같이 모델을 인쇄합니다.
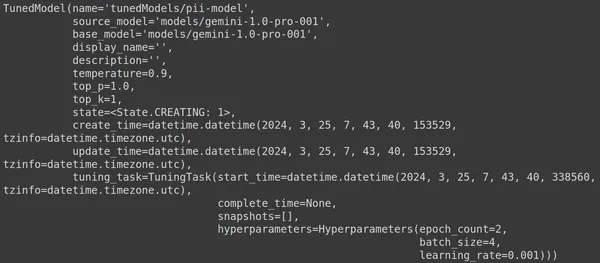
모델은 TunedModel 유형입니다. 여기에서 우리가 정의한 모델에 대한 다양한 매개변수를 관찰할 수 있습니다. 그들은:
- name: 이 변수에는 조정된 모델에 제공한 이름이 포함됩니다.
- source_model: 이것은 우리가 미세 조정하고 있는 소스 모델입니다. 이 예에서는 models/gemini-1.0-pro입니다.
- base_model: 이것은 다시 우리가 미세 조정 중인 기본 모델이며, 이 예에서는 models/Gemini-1.0-pro입니다. 기본 모델은 이전에 미세 조정된 모델일 수도 있습니다. 여기는 둘 다 똑같아
- display_name: 조정된 모델의 표시 이름
- 설명: 모델에 대한 설명과 모델의 내용이 포함됩니다.
- 온도: 값이 높을수록 대형 언어 모델에서 더 창의적인 답변이 생성됩니다. 여기서는 기본적으로 0.9로 설정되어 있습니다.
- top_p: 텍스트를 생성하는 동안 토큰 선택에 대한 최고 확률을 정의합니다. top_p가 많을수록 더 많은 토큰이 선택됩니다. 즉, 더 큰 데이터 샘플에서 토큰이 선택됩니다.
- top_k: 각 단계에서 가장 가능성이 높은 k개의 다음 토큰에서 샘플링하도록 지시합니다. 여기서 top_k는 1입니다. 이는 가능성이 가장 높은 다음 토큰이 선택될 것임을 의미합니다. 즉, 확률이 가장 높은 토큰이 항상 선택됩니다.
- state: 상태가 생성 중입니다. 이는 모델이 현재 미세 조정되고 있음을 의미합니다.
- create_time: 모델이 생성된 시간
- update_time: 모델이 마지막으로 튜닝된 시간입니다.
- tune_task: 온도, 에포크, 배치 크기 등 튜닝을 위해 정의한 매개변수가 포함되어 있습니다.
교육 과정 시작
다음 코드를 통해 조정된 모델의 상태와 메타데이터를 얻을 수도 있습니다.
print(operation.metadata)
여기에는 예측 가능한 총 단계, 즉 950개가 표시됩니다. 이 예에는 1900행의 훈련 데이터가 있기 때문입니다. 각 단계에서 우리는 4개의 배치(즉, 4개 행)를 취하므로 하나의 완전한 에포크에 대해 1900/4, 즉 475개의 단계를 갖게 됩니다. 훈련을 위해 2개의 에포크를 설정했는데, 이는 2*475 = 950단계를 의미합니다.
교육 진행 상황 모니터링
아래 코드는 학습이 완료된 비율과 전체 학습 프로세스를 완료하는 데 걸리는 시간을 알려주는 상태 표시줄을 만듭니다.
import time
for status in operation.wait_bar():
time.sleep(30)
위의 코드는 진행률 표시줄을 생성하며, 완료되면 튜닝 프로세스가 종료되었음을 의미합니다.
훈련 성과 시각화
작업 개체에는 훈련 스냅샷도 포함되어 있습니다. 에포크당 평균 손실과 같은 평가 지표가 포함됩니다. 다음 코드를 사용하여 이를 시각화할 수 있습니다.
import pandas as pd
import seaborn as sns
model = operation.result()
snapshots = pd.DataFrame(model.tuning_task.snapshots)
sns.lineplot(data=snapshots, x = 'epoch', y='mean_loss')- 여기서는 Operation.result()에서 최종 조정된 모델을 얻습니다.
- 모델을 훈련할 때 모델은 빈번한 간격으로 스냅샷을 찍습니다. 이러한 스냅샷에는 평균 손실과 같은 데이터가 포함되어 있습니다. 따라서 model.tuning_task.snapshots를 호출하여 조정된 모델의 스냅샷을 추출합니다.
- 스냅샷을 pd.DataFrame에 전달하고 snapshots 변수에 저장하여 이러한 스냅샷에서 데이터프레임을 생성합니다.
- 마지막으로 추출된 스냅샷 데이터로부터 선 플롯을 생성합니다.
코드를 실행하면 다음 그래프가 생성됩니다.
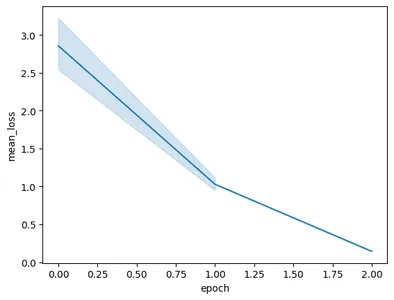
이 이미지에서는 단 3번의 훈련으로 손실이 0.5에서 2 미만으로 감소한 것을 볼 수 있습니다. 마지막으로 Gemini 모델 학습이 완료되었습니다.
미세 조정된 Gemini 모델 테스트
이 섹션에서는 테스트 데이터를 사용하여 모델을 테스트합니다. 이제 조정된 모델을 사용하기 위해 다음 코드를 사용합니다.
model = genai.GenerativeModel(model_name=f'tunedModels/{name}')위의 코드는 개인 식별 정보 데이터로 방금 훈련한 조정된 모델을 로드합니다. 이제 따로 보관해 둔 테스트 데이터의 몇 가지 예를 사용하여 이 모델을 테스트하겠습니다. 이를 위해 임의의 text_input과 테스트 세트의 해당 출력을 인쇄해 보겠습니다.
print(df_test['text_input'][1900])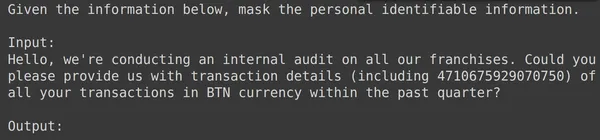
df_test['output'][1900]
위에서는 임의의 text_input과 테스트 세트에서 가져온 출력을 볼 수 있습니다. 이제 이 text_input을 모델에 전달하고 생성된 출력을 관찰하겠습니다.
text = df_test['text_input'][1900]
res = model.generate_content(text)
print(res.text)
모델이 주어진 text_input에 대한 개인 식별 정보를 성공적으로 마스킹했으며 모델에 의해 생성된 출력이 테스트 세트의 출력과 정확히 일치한다는 것을 알 수 있습니다. 이제 몇 가지 예를 더 들어 이를 시도해 보겠습니다.
print(df_test['text_input'][1969])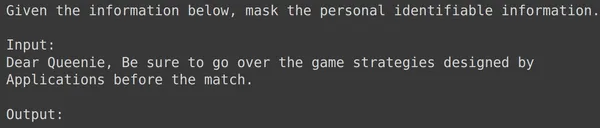
print(df_test['output'][1969])
text = df_test['text_input'][1969]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1987])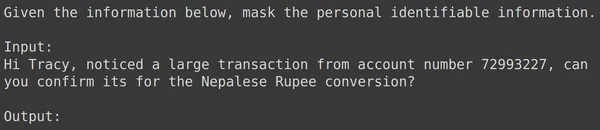
print(df_test['output'][1987])
text = df_test['text_input'][1987]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1933])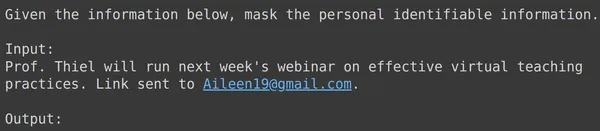
print(df_test['output'][1933])
text = df_test['text_input'][1933]
res = model.generate_content(text)
print(res.text)
위의 모든 예에서 미세 조정된 모델 성능이 좋다는 것을 알 수 있습니다. 모델은 주어진 훈련 데이터로부터 학습하고 마스킹을 올바르게 적용하여 민감한 개인 정보를 숨길 수 있었습니다. 따라서 우리는 미세 조정을 위한 데이터 세트를 생성하는 방법과 데이터 세트에서 Gemini 모델을 미세 조정하는 방법을 처음부터 끝까지 살펴보았습니다. 그리고 우리가 본 결과는 미세 조정 모델에 대해 매우 유망해 보입니다.
결론
결론적으로 이 가이드는 개인 식별 정보(PII)를 마스킹하기 위해 Google의 대표적인 Gemini 모델을 미세 조정하는 방법에 대한 포괄적인 연습을 제공했습니다. 우리는 Gemini 모델의 미세 조정 기능에 대한 Google 블로그 게시물을 탐색하여 작업별 정확도를 달성하기 위해 이러한 모델을 미세 조정해야 한다는 점을 강조하면서 시작했습니다. 데이터 세트 준비, Gemini 모델 미세 조정 및 성능 테스트를 포함하여 가이드에 설명된 실제 단계를 통해 사용자는 PII 마스킹 작업을 위해 대규모 언어 모델의 기능을 활용할 수 있습니다.
이 가이드의 주요 내용은 다음과 같습니다.
- Gemini 모델은 미세 조정을 위한 강력한 라이브러리를 제공하므로 사용자는 매개변수 효율적 조정(PET)을 통해 PII 마스킹을 포함한 특정 작업에 맞게 조정할 수 있습니다.
- 데이터세트 준비는 필수 모듈 설치, 데이터 보안을 위한 OAuth 시작, 교육용 데이터 형식 지정 등이 포함된 중요한 단계입니다.
- 미세 조정 프로세스에는 준비된 데이터 세트에서 Gemini 모델을 훈련하기 위한 기본 모델, 시대 수, 배치 크기 및 학습 속도와 같은 매개변수 제공이 포함됩니다.
- 상태 업데이트 및 에포크당 평균 손실과 같은 지표의 시각화를 통해 훈련 진행 상황 모니터링이 용이해집니다.
- 별도의 테스트 데이터 세트에서 미세 조정된 모델을 테스트하여 데이터 무결성을 유지하면서 PII를 정확하게 마스킹하는 성능을 검증합니다.
- 제공된 예는 민감한 개인 정보를 성공적으로 마스킹하는 데 있어 미세 조정된 Gemini 모델의 효율성을 보여 주며 실제 응용 프로그램에 대한 유망한 결과를 나타냅니다.
자주 묻는 질문
A. PET(Parameter Efficient Tuning)는 모델의 작은 매개변수 세트만 미세 조정하는 미세 조정 기술 중 하나입니다. 이는 Google에서 Gemini 모델의 중요한 레이어를 신속하게 미세 조정하는 데 사용됩니다. 모델을 사용자 데이터에 효율적으로 적용하여 특정 작업에 대한 성능을 향상시킵니다.
A. Gemini 모델 조정에는 기본 모델 이름, 에포크 수, 배치 크기 및 학습률과 같은 매개변수 제공이 포함됩니다. 이러한 매개변수는 훈련 프로세스에 영향을 미치고 궁극적으로 모델 성능에 영향을 미칩니다.
A. 사용자는 상태 업데이트, 에포크당 평균 손실과 같은 지표의 시각화, 훈련 프로세스의 스냅샷 관찰을 통해 미세 조정된 Gemini 모델의 훈련 진행 상황을 모니터링할 수 있습니다.
A. Gemini 모델을 미세 조정하기 전에 사용자는 google-generativeai 및 데이터 세트와 같은 필수 라이브러리를 설치해야 합니다. 또한 데이터 보안을 위해 OAuth를 시작하고 교육용 데이터 세트 형식을 지정하는 것이 중요한 단계입니다.
A. 미세 조정된 Gemini 모델은 데이터 익명화, NLP 애플리케이션의 개인정보 보호, GDPR과 같은 데이터 보호 규정 준수 등 PII 마스킹이 필요한 다양한 도메인에 적용될 수 있습니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2024/03/guide-to-fine-tuning-gemini-for-masking-pii-data/

