개요
데이터는 IT 산업의 원동력이며, 데이터 과학 프로젝트 오늘날의 온라인 세계에서. IT 산업은 다음에서 얻은 실시간 통찰력에 크게 의존합니다. 스트리밍 데이터 소스. 스트리밍 데이터를 처리하고 처리하는 것이 가장 어려운 작업입니다. 데이터 분석. 우리는 스트리밍 데이터가 지속적인 처리에서 대량으로 방출되는 데이터라는 것을 알고 있습니다. 즉, 데이터가 매초 변경된다는 의미입니다. 우리가 사용하는 이 데이터를 처리하기 위해 컨플루언트 플랫폼 – 자체 관리형 엔터프라이즈급 배포판 아파치 카프카.
Kafka는 아키텍처로 처리할 수 있는 분산형 결함으로, 처리량이 높은 데이터 스트림을 관리하기 위한 인기 있는 선택입니다. Kafka의 데이터는 MongoDB의 컬렉션 형태로. 이 기사에서는 파이프라인의 API를 사용하여 데이터를 가져온 다음 Kafka에서 항목 형식으로 수집한 다음 거기에서 MongoDB에 저장하는 엔드 투 엔드 파이프라인을 만들 것입니다. 프로젝트에서 또는 기능 엔지니어링을 수행합니다.
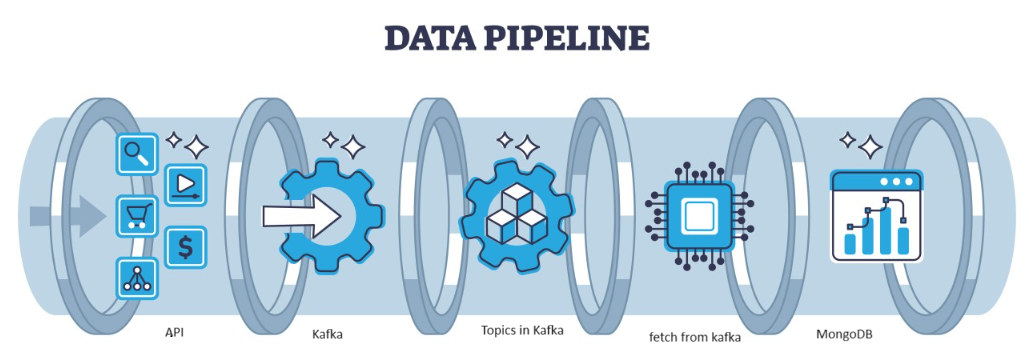
학습 목표
- 스트리밍 데이터가 무엇인지, Kafka를 사용하여 스트리밍 데이터를 처리하는 방법을 알아보세요.
- Confluent Platform 이해 – Apache Kafka의 자체 관리형 엔터프라이즈급 배포판입니다.
- Kafka가 수집한 데이터를 비정형 데이터를 저장하는 NoSQL 데이터베이스인 MongoDB에 저장합니다.
- 데이터베이스에서 데이터를 가져오고 저장하기 위한 완전한 엔드투엔드 파이프라인을 만듭니다.
이 기사는 데이터 과학 블로그.
차례
문제 파악
센서에서 나오는 스트리밍 데이터를 처리하기 위해 센서 데이터를 담고 있는 차량이 초당 생성되고, 이를 활용하기 위한 데이터 처리 및 전처리가 어렵다. 데이터 과학 프로젝트. 따라서 이 문제를 해결하기 위해 우리는 데이터를 처리하고 저장하는 엔드투엔드 파이프라인을 만들고 있습니다.
스트리밍 데이터란 무엇입니까?
스트리밍 데이터 비정형 데이터는 다양한 소스에서 지속적으로 생성되는 데이터입니다. 실시간 또는 거의 실시간으로 다양한 소스에서 생성된 데이터의 지속적인 흐름을 의미합니다. 데이터가 수집되고 이 스트리밍 데이터가 생성되는 대로 처리되는 전통적인 일괄 처리에서는 스트리밍 데이터는 온도 센서 및 GPS 추적기와 같은 IOT 데이터이거나 기계 데이터일 수 있습니다. 이는 차량 및 제조 기계의 원격 측정 데이터와 같은 기계 및 산업 장비에서 생성되는 데이터와 같습니다. Apache-Kafka와 같은 스트리밍 데이터 처리 플랫폼이 있습니다.
카프카란?
Apache Kafka는 실시간 데이터 파이프라인 및 스트리밍 애플리케이션을 구축하는 데 사용되는 플랫폼입니다. Kafka Streams API는 즉각적인 처리를 허용하는 강력한 라이브러리로, 창 매개변수를 수집 및 생성하고, 스트림 내에서 데이터 조인을 수행하는 등의 작업을 수행할 수 있습니다. Apache Kafka는 효율적인 실시간 데이터 수집, 스트리밍 데이터 파이프라인, 시스템 전반의 스토리지를 결합하는 스토리지 계층과 컴퓨팅 계층으로 구성됩니다.
접근 방식은 무엇입니까?
이는 Kafka confluent에서 JSON 형식으로 데이터를 게시하고 처리하는 방법을 알려주는 기계 학습 파이프라인입니다. Kafka 데이터 처리에는 소비자와 생산자의 두 부분이 있습니다. 다른 생산자의 스트리밍 데이터를 저장하고 이를 confluent에 저장한 다음 데이터에 대한 역직렬화가 수행되고 해당 데이터가 데이터베이스에 저장됩니다.
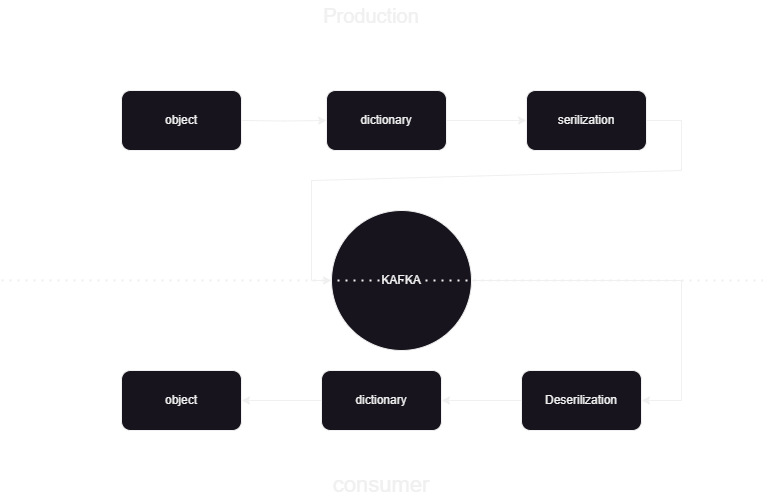
시스템 아키텍처 개요
우리는 confluent kafka의 도움으로 스트리밍 데이터를 처리하고 있으며 Kafka는 두 부분으로 나뉩니다.
- Kafka 프로듀서: Kafka 프로듀서는 Kafka 주제에 대한 데이터를 생성하고 전송하는 일을 담당합니다.
- Kafka 소비자: Kafka 소비자는 Kafka 주제의 데이터를 읽고 처리합니다.
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
구성요소란 무엇입니까?
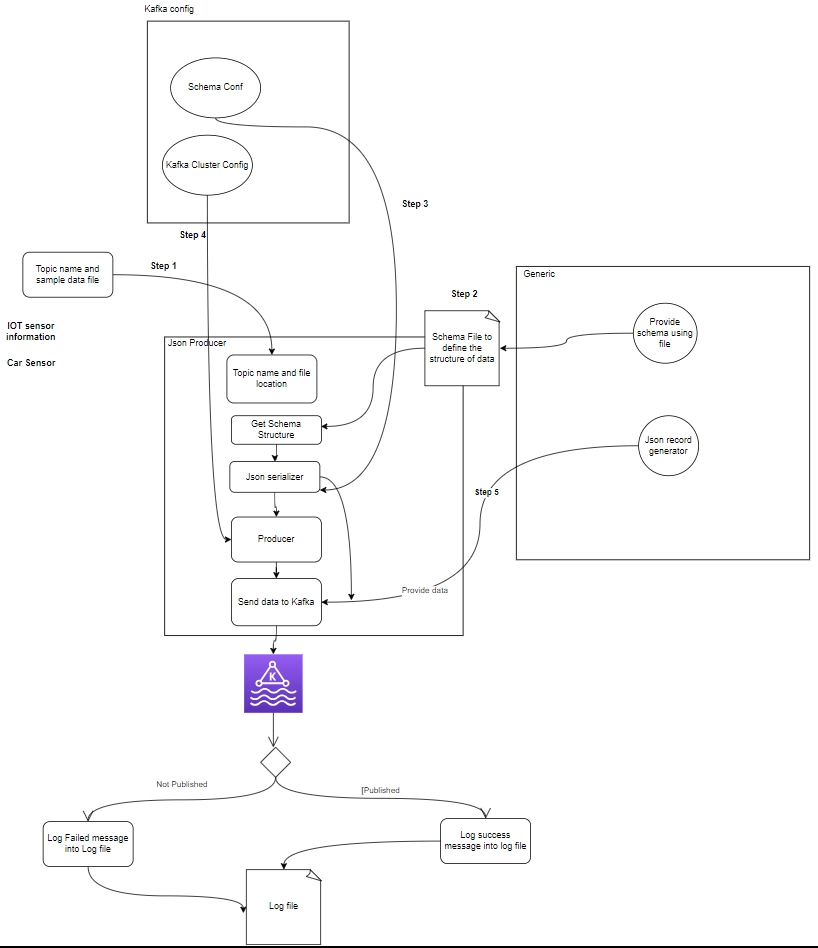
- 주제 : 주제는 제작자가 게시하는 논리적 채널 또는 카테고리입니다. 각 주제는 하나 이상의 파티션으로 나뉘며 각 주제는 내결함성을 위해 여러 브로커에 복제됩니다. 생산자는 특정 주제에 대한 데이터를 게시하고, 소비자는 데이터를 사용하기 위해 주제를 구독합니다.
- 제작자 : Apache Kafka 생산자는 Kafka 클러스터에 이벤트를 게시(쓰기)하는 클라이언트 애플리케이션입니다. 데이터를 주제로 보내는 애플리케이션을 Kafka 생산자라고 합니다. 이 섹션에서는 Kafka 생산자에 대한 개요를 제공합니다.
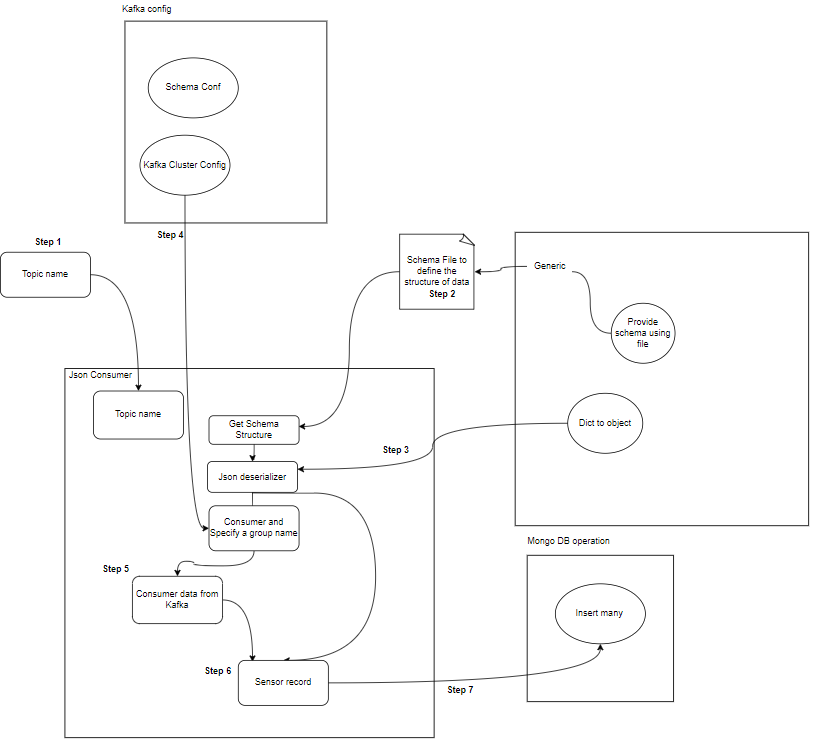
- 소비자: Kafka 소비자는 Kafka 주제에서 데이터를 읽고 처리하는 일을 담당합니다. 소비자는 Kafka의 데이터를 사용하고 이에 반응해야 하는 모든 애플리케이션의 일부가 될 수 있습니다. Kafka 브로커에서 하나 이상의 주제와 데이터를 구독합니다. 소비자는 소비자 그룹으로 구성될 수 있으며, 각 소비자 그룹에는 하나 이상의 소비자가 있고 주제의 각 주제는 그룹 내 한 명의 소비자에 의해서만 소비됩니다. 이를 통해 데이터 소비의 병렬 처리 및 로드 밸런싱이 가능합니다.
프로젝트 구조는 무엇입니까?
다음은 프로젝트에서 폴더와 파일이 어떻게 나누어지는지 프로젝트의 흐름도를 보여줍니다.
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- 카프카 프로듀서: 생산자는 센서 데이터(예: Sample_data/의 CSV 파일에서)를 생성하고 이를 Kafka 주제에 게시하는 주요 부분입니다. 데이터 생성 또는 게시 중에 발생할 수 있는 오류 조건.
- Kafka 브로커: Kafka 브로커는 Kafka 클러스터 전체에 데이터를 저장 및 복제하고, 데이터 분할을 처리하고, 내결함성과 고가용성을 보장합니다.
- Kafka 소비자: 소비자는 Kafka 주제에서 데이터를 읽고 이를 처리(예: 변환, 집계)한 후 MongoDB에 저장합니다. 또한 데이터 처리 중에 발생할 수 있는 오류 조건을 모니터링합니다.
- MongoDB : MongoDB는 Kafka 소비자로부터 받은 센서 데이터를 저장합니다. 데이터 검색을 위한 쿼리를 제공하고 복제 및 내결함성 메커니즘을 통해 데이터 내구성을 보장합니다.
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
데이터 저장을 위한 전제 조건
컨플루언트 카프카
- 계정 만들기: Kafka를 이해하려면 Confluent가 필요합니다. Apache Kafka®를 좋아하지만 관리하지는 않습니다. 클라우드 기반의 완전한 완전 관리형 서비스는 Kafka를 능가하므로 최고의 인력이 비즈니스에 가치를 제공하는 데 집중할 수 있습니다.
- 주제 만들기:
- 홈 페이지 및 사이드바로 이동하세요.
- 환경으로 이동한 다음 기본값을 클릭하세요.
- 주제로 이동

- 새 주제를 선택하고 주제 이름을 입력하세요.

MongoDB의
가입을 생성한 다음 MongoDB Atlas에 로그인하고 나중에 사용할 수 있도록 Mongodb Atlas의 연결 링크를 저장합니다.
프로젝트 설정을 위한 단계별 가이드
- Python 설치: Python이 컴퓨터에 설치되어 있는지 확인합니다. 다운로드하여 설치할 수 있습니다. Python 공식 웹 사이트에서.
- Conda 버전: 터미널에서 Conda 버전을 확인하세요.
- 가상 환경 생성: venv를 사용하여 가상 환경을 생성합니다.
conda create -p venv python==3.10 -y- 가상 환경 활성화: 가상 환경 활성화:
conda activate venv/- 필수 패키지 설치: pip를 사용하여 요구 사항.txt 파일에 나열된 필수 종속성을 설치합니다.
pip install -r requirements.txt- 로컬 시스템에서 일부 환경 변수를 설정해야 합니다. 이것이 합류 클라우드 클러스터 환경 변수입니다.
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
.env 파일의 자격 증명을 업데이트하고 아래 명령을 실행하여 Docker에서 애플리케이션을 실행하세요..
- 사용할 수 없는 경우 프로젝트의 루트 디렉터리에 .env 파일을 생성하고 아래 내용을 붙여넣고 자격 증명을 업데이트하세요.
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- 생산자 및 소비자 파일 실행:
python producer_main.py
python consumer_main.py코드를 구현하는 방법?
- 소스/: 이 디렉터리는 모든 소스 코드 파일의 기본 폴더입니다. 이 디렉터리에는 다음과 같은 하위 디렉터리가 있습니다.
Consumer/: 이 디렉터리에는 Kafka 주제에서 데이터를 읽고 처리하는 Kafka_consumer에 대한 코드가 포함되어 있습니다.
producer/: 이 디렉터리에는 센서 데이터를 생성하고 Kafka 항목으로 보내는 작업을 담당하는 Kafka_producer에 대한 코드가 포함되어 있습니다. - 읽어보세요.md: 이 Markdown 파일에는 목적 개요, 지침, 사용 지침 및 기타 정보를 포함하여 프로젝트에 대한 문서와 지침이 포함되어 있습니다.
- 요구사항.txt: 이 파일에는 프로젝트에 필요한 Python 라이브러리가 나열되어 있습니다. 각 종속성은 해당 버전 번호와 함께 나열됩니다. pip와 같은 도구는 이 파일을 사용하여 필요한 종속성을 자동으로 설치할 수 있습니다.
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: 링크를 통해 MongoDB Altas를 연결하기 위해 Python 스크립트를 작성하고 있습니다.
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
MongoDb Altas에서 복사한 URL을 입력하세요.
출력:
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
이 파일이 실행된 다음 파이썬 producer_main.py 그리고 이것은 아래 파일을 호출할 것입니다:
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
출력:

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
이 파일이 실행된 다음 파이썬 소비자_main.py 그리고 이것은 아래 파일을 호출할 것입니다:
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()출력:

소비자와 생산자를 모두 실행하면 시스템이 kafka에서 실행되고 정보/데이터가 더 빠르게 수집됩니다.

출력:
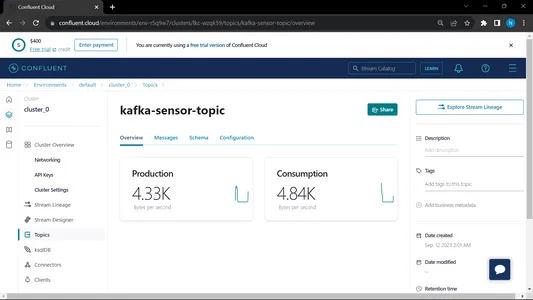
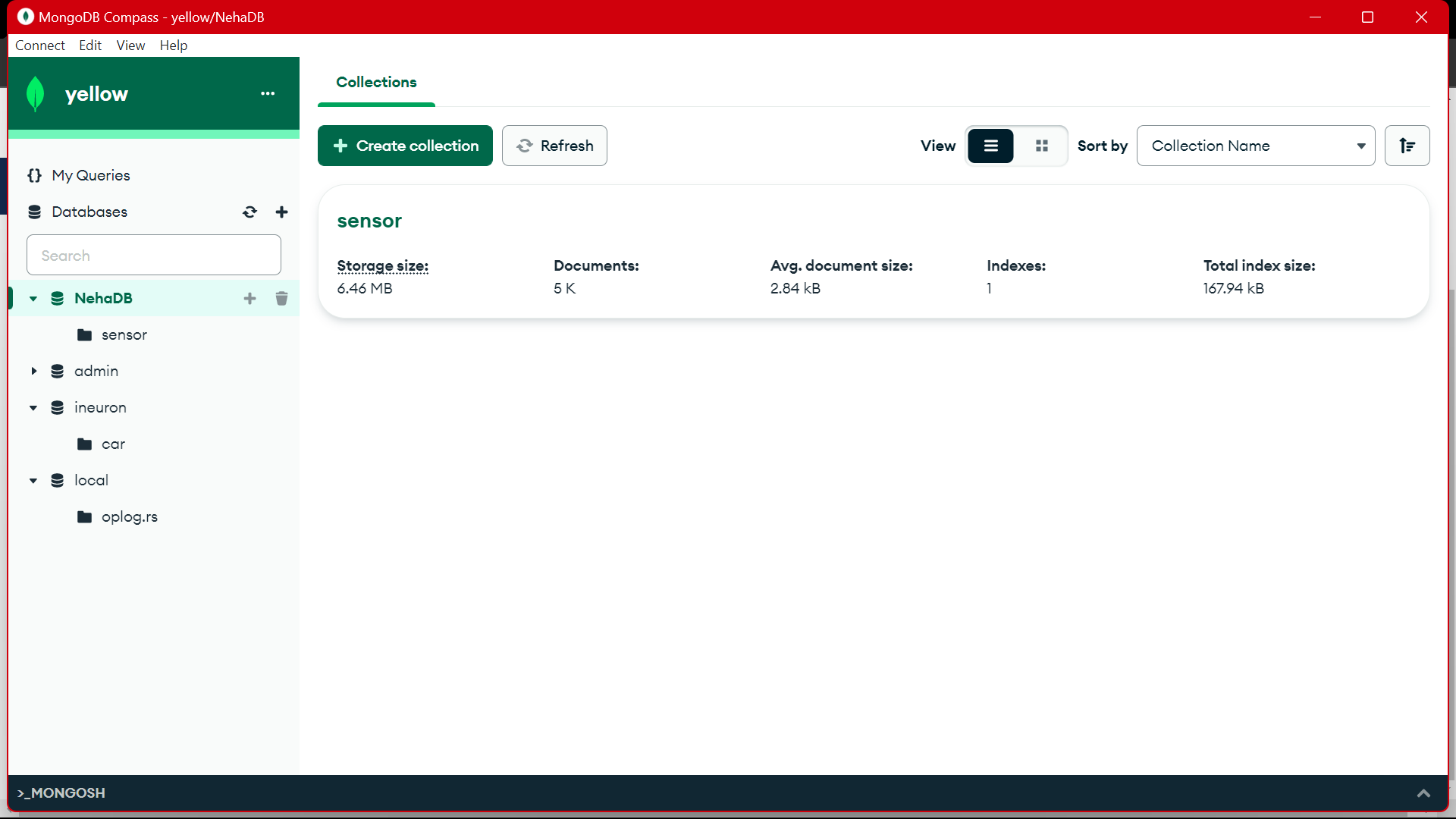
MongoDB에서는 이 데이터를 사용하여 EDA에서 전처리하고 기능 엔지니어링 및 데이터 분석 작업이 이 데이터에 대해 수행됩니다.
[포함 된 콘텐츠]
결론
이 기사에서는 센서에서 Kafka로의 스트리밍 데이터를 JSON 형식으로 저장하고 처리한 다음 데이터를 MongoDB에 저장하는 방법을 이해합니다. 우리는 스트리밍 데이터가 지속적인 처리에서 대량으로 방출되는 데이터라는 것을 알고 있습니다. 즉, 데이터가 매초 변경된다는 의미입니다. 우리는 파이프라인의 API를 사용하여 데이터를 가져온 다음 Kafka에서 항목 형식으로 수집한 다음 거기에서 MongoDB에 저장하여 프로젝트에서 사용하거나 다음 작업을 수행할 수 있는 엔드 투 엔드 파이프라인을 만들었습니다. 기능 엔지니어링.
주요 요점
- 스트리밍 데이터가 무엇인지, Kafka를 사용하여 스트리밍 데이터를 처리하는 방법을 알아보세요.
- Confluent Platform 이해 – Apache Kafka의 자체 관리형 엔터프라이즈급 배포판입니다.
- Kafka가 수집한 데이터를 비정형 데이터를 저장하는 NoSQL 데이터베이스인 MongoDB에 저장합니다.
- 데이터베이스에서 데이터를 가져오고 저장하기 위한 완전한 엔드투엔드 파이프라인을 만듭니다.
- 프로젝트의 각 구성 요소 기능을 이해하고 이를 Docker에 구현하고 언제든지 사용할 수 있도록 클라우드에 구현합니다.
자료
자주 묻는 질문
A. MongoDB는 비정형 데이터로 데이터를 저장합니다. 스트리밍 데이터는 MongoDB를 데이터베이스로 사용하는 메모리 활용을 위한 비정형 형태의 데이터입니다.
A. 목적은 추가 분석, 보고 또는 애플리케이션 사용을 위해 Kafka 주제로 수집된 데이터를 MongoDB에서 소비, 처리 및 저장할 수 있는 실시간 데이터 처리 파이프라인을 만드는 것입니다.
A. 사용 사례에는 실시간 분석, IoT 데이터 처리, 로그 집계, 소셜 미디어 모니터링, 추천 시스템이 포함되며, 여기서 스트리밍 데이터는 추가 분석이나 애플리케이션 사용을 위해 처리 및 저장되어야 합니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

