개요
몇 달 전 처음 Office People에서 일하기 시작했을 때 저는 언어 모델, 특히 Word2Vec에 관심을 갖게 되었습니다. 기본 Python 사용자이기 때문에 자연스럽게 Gensim의 Word2Vec 구현에 집중하고 온라인에서 논문과 자습서를 찾았습니다. 훌륭한 데이터 과학자라면 누구나 하듯이 여러 소스의 코드 스니펫을 직접 적용하고 복제했습니다. 저는 Stackoverflow 대화, Gensim의 Google 그룹 및 라이브러리 문서를 통해 제 방법에 무엇이 잘못되었는지 이해하기 위해 더 깊이 파고들었습니다.

하지만 저는 항상 워드투벡 모델이 누락되었습니다. 실험 중에 문장을 레마타이징하거나 문장에서 구/바이그램을 찾는 것이 내 모델의 결과와 성능에 상당한 영향을 미친다는 것을 발견했습니다. 전처리의 영향은 데이터 세트와 응용 프로그램에 따라 다르지만 이 기사에 데이터 준비 단계를 포함하고 환상적인 방법을 사용하기로 결정했습니다. spaCy 라이브러리 그 옆에.
이러한 문제 중 일부는 나를 짜증나게 하여 나만의 기사를 작성하기로 결정했습니다. 나는 이것이 완벽하거나 Word2Vec을 구현하는 가장 좋은 방법이라고 약속하지 않습니다. 단지 거기에 있는 많은 것보다 낫다는 것입니다.
학습 목표
- 단어 임베딩과 시맨틱 관계 캡처에서의 역할을 이해합니다.
- Gensim 또는 TensorFlow와 같은 인기 있는 라이브러리를 사용하여 Word2Vec 모델을 구현합니다.
- Word2Vec 임베딩을 사용하여 단어 유사성을 측정하고 거리를 계산합니다.
- Word2Vec에서 캡처한 단어 유추 및 의미론적 관계를 탐색합니다.
- 감정 분석, 기계 번역 등 다양한 NLP 작업에 Word2Vec을 적용합니다.
- 특정 작업 또는 도메인에 대해 Word2Vec 모델을 미세 조정하는 기술을 배웁니다.
- 하위 단어 정보 또는 사전 훈련된 임베딩을 사용하여 어휘에 없는 단어를 처리합니다.
- 단어 의미 명확화 및 문장 수준 의미 체계와 같은 Word2Vec의 제한 사항과 장단점을 이해합니다.
- Word2Vec을 사용한 서브워드 임베딩 및 모델 최적화와 같은 고급 주제에 대해 자세히 알아보세요.
이 기사는 데이터 과학 블로그.
차례
Word2Vec 소개
Google 연구팀은 2년 2013월과 XNUMX월 사이에 두 개의 논문에서 WordXNUMXVec을 소개했습니다. 연구원들은 또한 논문과 함께 C 구현을 발표했습니다. Gensim은 첫 번째 논문 직후 Python 구현을 완료했습니다.
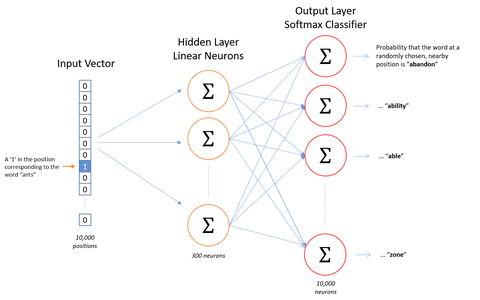
Word2Vec의 기본 가정은 유사한 컨텍스트를 가진 두 단어가 유사한 의미를 가지며 결과적으로 모델에서 유사한 벡터 표현을 갖는다는 것입니다. 예를 들어 "dog", "puppy" 및 "pup"은 "good", "fluffy" 또는 "cute"와 같은 유사한 주변 단어와 함께 유사한 컨텍스트에서 자주 사용되므로 Word2Vec에 따라 유사한 벡터 표현을 갖습니다.
이 가정을 기반으로 Word2Vec을 사용하여 단어 간의 관계를 발견할 수 있습니다. 데이터 세트, 유사성을 계산하거나 해당 단어의 벡터 표현을 텍스트 분류 또는 클러스터링과 같은 다른 응용 프로그램의 입력으로 사용합니다.
Word2vec 구현
Word2Vec의 아이디어는 매우 간단합니다. 우리는 단어의 의미가 그것이 유지하는 회사에 의해 추론될 수 있다고 가정하고 있습니다. 이것은 "친구를 보여주면 당신이 누구인지 알려줄게"라는 말과 유사합니다. 다음은 word2vec의 구현입니다.
환경 설정
파이썬==3.6.3
사용된 라이브러리:
- xlrd==1.1.0:
- spaCy==2.0.12:
- 젠심==3.4.0:
- scikit-learn==0.19.1:
- 시본==0.8:
import re # For preprocessing
import pandas as pd # For data handling
from time import time # To time our operations
from collections import defaultdict # For word frequency import spacy # For preprocessing import logging # Setting up the loggings to monitor gensim
logging.basicConfig(format="%(levelname)s - %(asctime)s: %(message)s", datefmt= '%H:%M:%S', level=logging.INFO)데이터 세트
이 데이터 세트에는 600년까지 거슬러 올라가는 1989개 이상의 Simpsons 에피소드에 대한 캐릭터, 위치, 에피소드 세부 정보 및 스크립트 라인에 대한 정보가 포함되어 있습니다. 다음에서 사용할 수 있습니다. 카글. (~25MB)
전처리
전처리를 수행하는 동안 데이터 세트에서 raw_character_text 및spoken_words라는 두 개의 열만 유지됩니다.
- raw_character_text: 말하는 캐릭터(전처리 단계를 추적하는 데 유용함).
- speak_words: 대화 라인의 원시 텍스트
자체 사전 처리를 원하기 때문에 normalized_text를 유지하지 않습니다.
df = pd.read_csv('../input/simpsons_dataset.csv')
df.shape
df.head()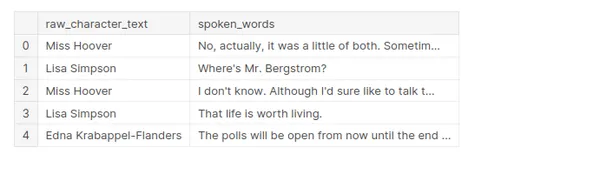
누락된 값은 어떤 일이 발생하지만 대화가 없는 스크립트 섹션에서 가져온 것입니다. “(Springfield 초등학교: EXT. ELEMENTARY – 학교 운동장 – 오후)”가 예입니다.
df.isnull().sum()
청소관련
대화의 각 줄에 대해 불용어와 알파벳이 아닌 문자를 표제어로 지정하고 제거합니다.
nlp = spacy.load('en', disable=['ner', 'parser']) def cleaning(doc): # Lemmatizes and removes stopwords # doc needs to be a spacy Doc object txt = [token.lemma_ for token in doc if not token.is_stop] if len(txt) > 2: return ' '.join(txt)알파벳이 아닌 문자를 제거합니다.
brief_cleaning = (re.sub("[^A-Za-z']+", ' ', str(row)).lower() for row in df['spoken_words'])spaCy.pipe() 속성을 사용하여 청소 프로세스 가속화:
t = time() txt = [cleaning(doc) for doc in nlp.pipe(brief_cleaning, batch_size=5000, n_threads=-1)] print('Time to clean up everything: {} mins'.format(round((time() - t) / 60, 2)))

누락된 값과 중복을 제거하려면 결과를 DataFrame에 배치합니다.
df_clean = pd.DataFrame({'clean': txt})
df_clean = df_clean.dropna().drop_duplicates()
df_clean.shape

빅그램
Bigram은 자연어 처리 및 텍스트 분석에 사용되는 개념입니다. 일련의 텍스트에 나타나는 연속적인 단어 또는 문자 쌍을 나타냅니다. 바이그램을 분석하면 주어진 텍스트에서 단어나 문자 사이의 관계에 대한 통찰력을 얻을 수 있습니다.
"I love ice cream"이라는 문장을 예로 들어 봅시다. 이 문장에서 바이그램을 식별하기 위해 연속 단어 쌍을 살펴봅니다.
"좋아요"
"사랑의 얼음"
"아이스크림"
이러한 각 쌍은 바이그램을 나타냅니다. Bigram은 다양한 언어 처리 작업에 유용할 수 있습니다. 예를 들어 언어 모델링에서 바이그램을 사용하여 이전 단어를 기반으로 문장의 다음 단어를 예측할 수 있습니다.
바이그램은 트라이그램(연속적인 삼중항) 또는 n-그램(n개의 단어 또는 문자의 연속적인 시퀀스)이라는 더 큰 시퀀스로 확장될 수 있습니다. n의 선택은 당면한 특정 분석 또는 작업에 따라 다릅니다.
Gensim Phrases 패키지는 문장 목록에서 일반적인 구문(bigrams)을 자동으로 감지하는 데 사용되고 있습니다. https://radimrehurek.com/gensim/models/phrases.html
주로 "mr_burns" 및 "bart_simpson"과 같은 단어를 캡처하기 위해 이 작업을 수행합니다!
from gensim.models.phrases import Phrases, Phraser
sent = [row.split() for row in df_clean['clean']]문장 목록에서 다음 구문이 생성됩니다.
phrases = Phrases(sent, min_count=30, progress_per=10000)
Phraser()의 목표는 바이그램 감지 작업에 꼭 필요하지 않은 모델 상태를 폐기하여 Phrases() 메모리 소비를 줄이는 것입니다.
bigram = Phraser(phrases)
감지된 바이그램을 기반으로 코퍼스를 변환합니다.
sentences = bigram[sent]가장 빈번한 단어
주로 표제어 정리, 불용어 제거 및 바이그램 추가의 효과에 대한 온전한 검사입니다.
word_freq = defaultdict(int)
for sent in sentences: for i in sent: word_freq[i] += 1
len(word_freq)

sorted(word_freq, key=word_freq.get, reverse=True)[:10]
모델 훈련을 3단계로 분리
명확성과 모니터링을 위해 교육을 세 가지 단계로 나누는 것을 선호합니다.
- Word2Vec():
- 이 첫 번째 단계에서는 모델의 매개변수를 하나씩 설정합니다.
- 매개 변수 문장을 제공하지 않음으로써 의도적으로 모델을 초기화하지 않은 상태로 둡니다.
- build_vocab():
- 일련의 문장에서 어휘를 구축하여 모델을 초기화합니다.
- 진행 상황을 추적할 수 있으며 더 중요한 것은 로깅을 사용하여 단어 말뭉치에 대한 min_count 및 sample의 영향을 추적할 수 있습니다. 이 두 매개변수, 특히 샘플이 모델 성능에 상당한 영향을 미친다는 사실을 발견했습니다. 둘 다 표시하면 영향력을 보다 정확하고 간단하게 관리할 수 있습니다.
- .기차():
- 마지막으로 모델이 훈련됩니다.
- 이 페이지의 로깅은 대부분 유용합니다.
import multiprocessing from gensim.models import Word2Vec cores = multiprocessing.cpu_count() # Count the number of cores in a computer w2v_model = Word2Vec(min_count=20, window=2, size=300, sample=6e-5, alpha=0.03, min_alpha=0.0007, negative=20, workers=cores-1)word2vec의 Gensim 구현: https://radimrehurek.com/gensim/models/word2vec.html
어휘 테이블 구축
Word2Vec은 우리가 어휘 테이블을 생성하도록 요구합니다(모든 단어를 소화하고, 고유한 단어를 필터링하고, 그들에 대해 몇 가지 기본 카운트를 수행함으로써):
t = time() w2v_model.build_vocab(sentences, progress_per=10000) print('Time to build vocab: {} mins'.format(round((time() - t) / 60, 2))) 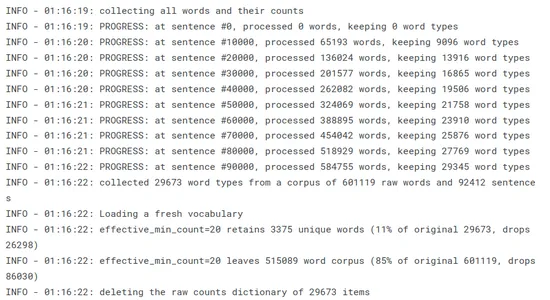
어휘 테이블은 단어를 인덱스로 인코딩하고 훈련 또는 추론 중에 해당 단어 임베딩을 찾는 데 중요합니다. 이는 Word2Vec 모델 훈련을 위한 기반을 형성하고 연속 벡터 공간에서 효율적인 단어 표현을 가능하게 합니다.
모델 훈련
Word2Vec 모델 교육에는 텍스트 데이터 모음을 알고리즘에 공급하고 모델의 매개변수를 최적화하여 단어 임베딩을 학습하는 작업이 포함됩니다. Word2Vec의 학습 매개변수에는 학습 프로세스와 결과 단어 임베딩의 품질에 영향을 미치는 다양한 하이퍼 매개변수 및 설정이 포함됩니다. 다음은 Word2Vec에 일반적으로 사용되는 훈련 매개변수입니다.
- total_examples = int – 문장의 수;
- epochs = int – 말뭉치에 대한 반복(epochs) 수 – [10, 20, 30]
t = time() w2v_model.train(sentences, total_examples=w2v_model.corpus_count, epochs=30, report_delay=1) print('Time to train the model: {} mins'.format(round((time() - t) / 60, 2)))
우리는 모델을 더 훈련시킬 생각이 없기 때문에 모델을 훨씬 더 메모리 효율적으로 만들기 위해 init_sims()를 호출하고 있습니다.
w2v_model.init_sims(replace=True)
이러한 매개 변수는 컨텍스트 창 크기, 빈도가 높은 단어와 희귀한 단어 간의 절충, 학습 속도, 훈련 알고리즘 및 음성 샘플링을 위한 음성 샘플 수와 같은 측면을 제어합니다. 이러한 매개변수를 조정하면 Word2Vec 교육 프로세스의 품질, 효율성 및 메모리 요구 사항에 영향을 줄 수 있습니다.
모델 탐색
Word2Vec 모델이 훈련되면 이를 탐색하여 학습된 단어 임베딩에 대한 통찰력을 얻고 유용한 정보를 추출할 수 있습니다. 다음은 Word2Vec 모델을 탐색하는 몇 가지 방법입니다.
가장 유사한
Word2Vec에서는 학습된 단어 임베딩을 기반으로 주어진 단어와 가장 유사한 단어를 찾을 수 있습니다. 유사성은 일반적으로 코사인 유사성을 사용하여 계산됩니다. 다음은 Word2Vec을 사용하여 대상 단어와 가장 유사한 단어를 찾는 예입니다.
쇼의 주인공에 대해 무엇을 얻을 수 있는지 봅시다.
similar_words = w2v_model.wv.most_similar(positive=["homer"])
for word, similarity in similar_words: print(f"{word}: {similarity}")
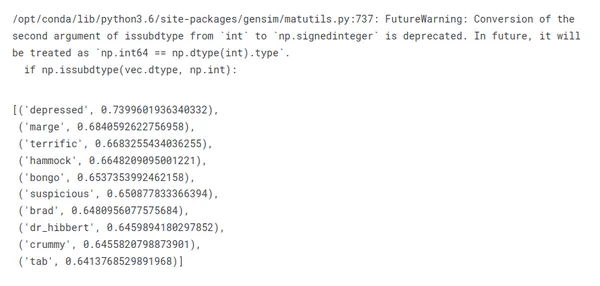
분명히 하자면, "호머"와 가장 유사한 단어를 볼 때 반드시 그의 가족 구성원, 성격 특성 또는 가장 기억에 남는 인용구를 얻지는 않습니다.
이를 bigram "homer_simpson"이 반환하는 것과 비교하십시오.
w2v_model.wv.most_similar(positive=["homer_simpson"])
지금 마지는 어때?
w2v_model.wv.most_similar(positive=["marge"])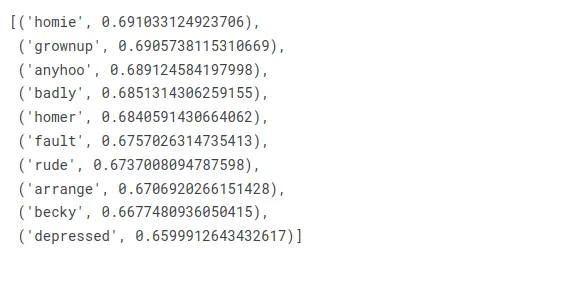
지금 Bart를 확인해 봅시다.
w2v_model.wv.most_similar(positive=["bart"])
말이 되는 것 같습니다!
유사성
다음은 Word2Vec을 사용하여 두 단어 사이의 코사인 유사성을 찾는 예입니다.
예: 두 단어 간의 코사인 유사도 계산.
w2v_model.wv.similarity("moe_'s", 'tavern')
누가 Moe의 선술집을 잊을 수 있습니까? 바니가 아닙니다.
w2v_model.wv.similarity('maggie', 'baby')
Maggie는 실제로 Simpsons에서 가장 유명한 아기입니다!
w2v_model.wv.similarity('bart', 'nelson')
Bart와 Nelson은 친구이지만 그렇게 가깝지는 않습니다.
오드원 아웃
여기에서 우리는 목록에 속하지 않는 단어를 제공하도록 모델에 요청합니다!
Jimbo, Milhouse, Kearney 중 괴롭힘을 당하지 않는 사람은 누구입니까?
w2v_model.wv.doesnt_match(['jimbo', 'milhouse', 'kearney'])
Nelson, Bart 및 Milhouse의 우정을 비교하면 어떨까요?
w2v_model.wv.doesnt_match(["nelson", "bart", "milhouse"])
넬슨이 이상한 사람인 것 같습니다!
마지막으로 호머와 그의 두 시누이의 관계는 어떻습니까?
w2v_model.wv.doesnt_match(['homer', 'patty', 'selma'])
젠장, 그들은 정말 당신을 좋아하지 않습니다 호머!
유추 차이
호머가 마지(marge)를 의미하듯이 여성을 의미하는 단어는 무엇입니까?
w2v_model.wv.most_similar(positive=["woman", "homer"], negative=["marge"], topn=3)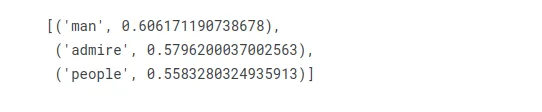
"man"이 첫 번째 위치에 옵니다.
Bart가 남자에게 하는 말처럼 여자에게 하는 말은 무엇입니까?
w2v_model.wv.most_similar(positive=["woman", "bart"], negative=["man"], topn=3)
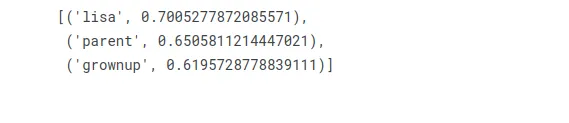
Lisa는 Bart의 여동생이자 그녀의 남성 상대입니다!
결론
결론적으로 Word2Vec은 자연어 처리(NLP) 분야에서 널리 사용되는 알고리즘으로 단어를 연속 벡터 공간에서 조밀한 벡터로 표현하여 단어 임베딩을 학습합니다. 대규모 텍스트 코퍼스에서 동시 발생 패턴을 기반으로 단어 간의 의미론적 및 구문론적 관계를 캡처합니다.
Word2Vec은 신경망 아키텍처인 CBOW(Continuous Bag-of-Words) 또는 Skip-gram 모델을 활용하여 작동합니다. Word2Vec에서 생성된 단어 임베딩은 의미 및 구문 정보를 인코딩하는 단어의 조밀한 벡터 표현입니다. 단어 유사성 계산과 같은 수학적 연산을 허용하고 다양한 NLP 작업의 기능으로 사용할 수 있습니다.
주요 요점
- Word2Vec은 단어 임베딩, 단어의 조밀한 벡터 표현을 학습합니다.
- 텍스트 말뭉치에서 동시 발생 패턴을 분석하여 의미론적 관계를 포착합니다.
- 이 알고리즘은 CBOW 또는 Skip-gram 모델과 함께 신경망을 사용합니다.
- 단어 임베딩은 단어 유사성 계산을 가능하게 합니다.
- 다양한 NLP 작업에서 기능으로 사용할 수 있습니다.
- Word2Vec은 정확한 임베딩을 위해 대규모 훈련 코퍼스가 필요합니다.
- 단어 의미 명확성을 캡처하지 않습니다.
- Word2Vec에서는 어순을 고려하지 않습니다.
- 어휘 이외의 단어는 문제를 일으킬 수 있습니다.
- 제한 사항에도 불구하고 Word2Vec은 NLP에서 중요한 애플리케이션을 보유하고 있습니다.
Word2Vec은 강력한 알고리즘이지만 몇 가지 제한 사항이 있습니다. 정확한 단어 임베딩을 학습하려면 많은 양의 학습 데이터가 필요합니다. 각 단어를 원자적 엔터티로 취급하고 단어 의미 명확성을 캡처하지 않습니다. 사전에 임베딩이 없기 때문에 어휘 외 단어는 문제가 될 수 있습니다.
Word2Vec은 NLP의 발전에 크게 기여했으며 정보 검색, 감정 분석, 기계 번역 등과 같은 작업을 위한 유용한 도구로 계속 사용되고 있습니다.
자주 답변 및 질문
A: Word2Vec은 자연어 처리(NLP) 작업에 널리 사용되는 알고리즘입니다. 얕은 2계층 신경망은 단어를 연속 벡터 공간에서 조밀한 벡터로 표현하여 단어 임베딩을 학습합니다. WordXNUMXVec은 대규모 텍스트 코퍼스에서 동시 발생 패턴을 기반으로 단어 간의 의미론적 및 구문론적 관계를 캡처합니다.
A: Word2Vec은 "분산 표현"이라는 기술을 사용하여 단어 임베딩을 학습합니다. CBOW(Continuous Bag-of-Words) 또는 Skip-gram 모델과 같은 신경망 아키텍처를 사용합니다. CBOW 모델은 문맥 단어를 기반으로 타겟 단어를 예측하는 반면, Skip-gram 모델은 타겟 단어가 주어진 컨텍스트 단어를 예측합니다. 교육 중에 모델은 단어 벡터를 조정하여 대상 단어나 문맥 단어를 정확하게 예측할 가능성을 최대화합니다.
A: 단어 임베딩은 연속 벡터 공간에서 단어의 조밀한 벡터 표현입니다. 단어에 대한 의미 체계 및 구문 정보를 인코딩하고 훈련 말뭉치의 분포 속성을 기반으로 관계를 캡처합니다. 단어 유사성 계산과 같은 수학적 연산을 가능하게 하고 감정 분석, 기계 번역 등과 같은 다양한 NLP 작업의 기능으로 사용합니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/07/step-by-step-guide-to-word2vec-with-gensim/

