아마존 폴리 텍스트를 생생한 음성으로 변환하는 서비스입니다. 이를 통해 텍스트를 여러 언어의 음성으로 변환할 수 있는 전체 종류의 응용 프로그램을 개발할 수 있습니다.
이 서비스는 다른 AWS AI 또는 기계 학습(ML) 서비스와 함께 챗봇, 오디오 북 및 기타 텍스트 음성 변환 애플리케이션에서 사용할 수 있습니다. 예를 들어, 아마존 렉스 그리고 Amazon Polly를 결합하여 사용자와 양방향 대화에 참여하고 사용자의 명령에 따라 특정 작업을 수행하는 챗봇을 만들 수 있습니다. 아마존 전사, 아마존 번역, 및 Amazon Polly를 결합하여 음성을 소스 언어의 텍스트로 변환하고 다른 언어로 번역한 후 말할 수 있습니다.
이 게시물에서는 Amazon Polly를 사용하여 말할 때 텍스트를 강조 표시하는 흥미로운 접근 방식을 제시합니다. 이 솔루션은 다음을 수행하기 위해 많은 텍스트 음성 변환 응용 프로그램에서 사용할 수 있습니다.
- 책, 웹 사이트 및 블로그의 오디오에 시각적 기능 추가
- 고객이 말하면서 빠르게 텍스트를 이해하려고 할 때 이해력을 높입니다.
우리의 솔루션은 클라이언트(이 예에서는 브라우저)에게 Amazon Polly가 말하는 텍스트(단어 또는 문장)를 즉시 알 수 있는 기능을 제공합니다. 이를 통해 클라이언트는 텍스트를 말할 때 동적으로 강조 표시할 수 있습니다. 이러한 기능은 앞에서 언급한 사용 사례에 대해 음성에 대한 시각적 지원을 제공하는 데 유용합니다.
텍스트 강조 표시 외에 추가 작업을 수행하도록 솔루션을 확장할 수 있습니다. 예를 들어 브라우저는 텍스트를 말할 때 프런트 엔드에서 이미지를 표시하거나 음악을 재생하거나 기타 애니메이션을 실행할 수 있습니다. 이 기능은 동적 오디오 북, 교육 콘텐츠 및 풍부한 텍스트 음성 변환 응용 프로그램을 만드는 데 유용합니다.
솔루션 개요
솔루션의 핵심은 Amazon Polly를 사용하여 텍스트 문자열을 음성으로 변환하는 것입니다. 텍스트는 브라우저에서 입력하거나 솔루션에 의해 노출된 엔드포인트에 대한 API 호출을 통해 입력할 수 있습니다. Amazon Polly에서 생성된 음성은 오디오 파일(MP3 형식)로 아마존 단순 스토리지 서비스 (Amazon S3) 버킷.
그러나 오디오 파일만 사용하면 각 단어가 언제 말해지는지에 대한 자세한 정보가 없기 때문에 브라우저는 즉시 텍스트의 어떤 부분이 말하고 있는지 찾을 수 없습니다.
Amazon Polly는 스피치 마크를 사용하여 이를 얻을 수 있는 방법을 제공합니다. 스피치 마크는 각 단어나 문장이 말해지는 시간(오디오 시작부터 밀리초 단위로 측정)을 보여주는 텍스트 파일에 저장됩니다.
Amazon Polly는 줄로 구분된 JSON 스트림에서 스피치 마크 객체를 반환합니다. 스피치 마크 개체에는 다음 필드가 포함됩니다.
- Time – 해당 오디오 스트림의 시작부터 밀리초 단위의 타임스탬프
- 타입 – 스피치 마크의 유형(문장, 단어, viseme 또는 SSML)
- 스타트 – 입력 텍스트에서 개체 시작의 바이트 단위 오프셋(문자 아님)(viseme 표시 제외)
- 종료 – 입력 텍스트에서 개체 끝의 바이트 단위 오프셋(문자 아님)(viseme 표시 제외)
- 가치관 – 이것은 스피치 마크의 유형에 따라 다릅니다.
- SSML – SSML 태그
- 비짐 – 비짐 이름
- 단어 또는 문장 – 시작 및 끝 필드로 구분되는 입력 텍스트의 하위 문자열
예를 들어 "Mary had a little lamb"이라는 문장은 SpeechMarkTypes = ["단어", "문장"] 스피치 마크를 얻기 위한 API 호출:
"had"(3행 끝)라는 단어는 오디오 스트림이 시작된 후 373밀리초에 시작하여 입력 텍스트의 5바이트에서 시작하여 8바이트에서 끝납니다.
아키텍처 개요
솔루션의 아키텍처는 다음 다이어그램에 나와 있습니다.
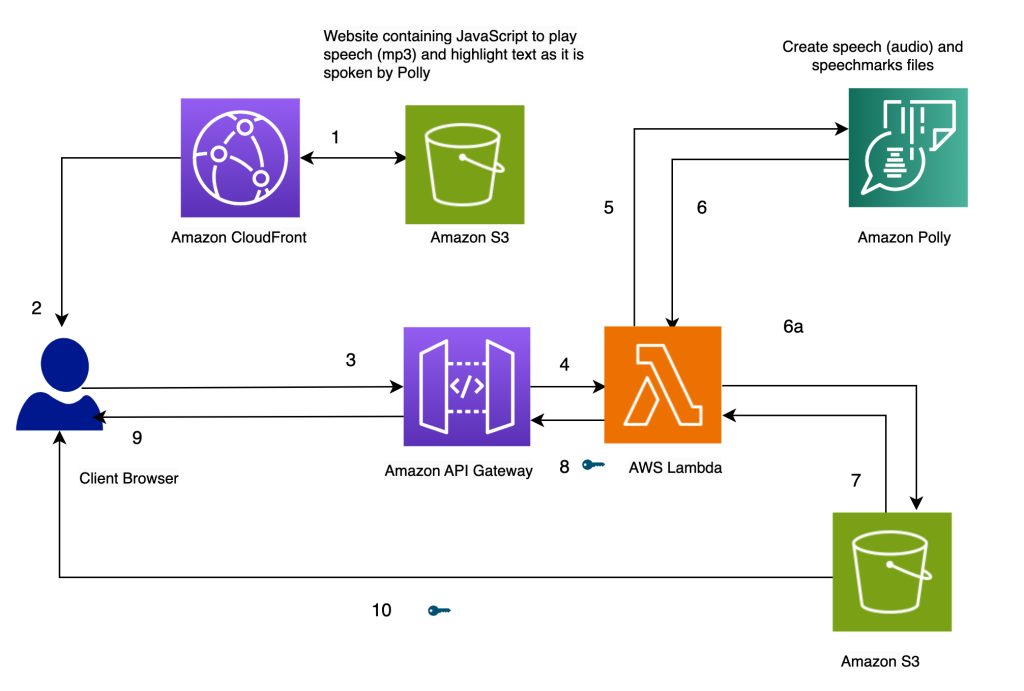
Amazon Polly를 사용하여 말하는 대로 텍스트 강조 표시
솔루션에 대한 당사 웹 사이트는 정적 파일(JavaScript, HTML)로 Amazon S3에 저장되며 아마존 CloudFront를 (1) 최종 사용자의 브라우저에 제공됩니다(2).
사용자가 간단한 HTML 형식을 통해 브라우저에 텍스트를 입력하면 브라우저에서 JavaScript로 처리됩니다. 다음을 통해 API(3)를 호출합니다. 아마존 API 게이트웨이, 호출 AWS 람다 기능 (4). Lambda 함수는 Amazon Polly(5)를 호출하여 스피치(오디오) 및 스피치 마크(JSON) 파일을 생성합니다. 오디오 및 스피치 마크 파일을 가져오기 위해 Amazon Polly를 두 번 호출합니다. 호출은 JavaScript 비동기 함수를 사용하여 이루어집니다. 이러한 호출의 출력은 Amazon S3(6a)에 저장되는 오디오 및 스피치 마크 파일입니다. 여러 사용자가 S3 버킷에서 서로의 파일을 덮어쓰는 것을 방지하기 위해 파일은 타임스탬프가 있는 폴더에 저장됩니다. 이렇게 하면 두 명의 사용자가 Amazon S3에서 서로의 파일을 덮어쓸 가능성이 최소화됩니다. 프로덕션 릴리스의 경우 사용자 ID 또는 타임스탬프 및 기타 고유한 특성을 기반으로 사용자 파일을 분리하기 위해 보다 강력한 접근 방식을 사용할 수 있습니다.
Lambda 함수는 스피치 및 스피치 마크 파일에 대해 미리 서명된 URL을 생성하고 배열(7, 8, 9) 형식으로 브라우저에 반환합니다.
브라우저가 텍스트 파일을 API 끝점(3)으로 보낼 때 한 번의 동기 호출(9)에서 오디오 파일과 스피치 마크 파일에 대해 미리 서명된 URL 두 개를 반환합니다. 이는 화살표 옆에 키 기호로 표시됩니다.
브라우저의 JavaScript 기능은 URL 핸들(10)에서 스피치 마크 파일과 오디오를 가져옵니다. 오디오를 재생하도록 오디오 플레이어를 설정합니다. (HTML 오디오 태그는 이 용도로 사용됩니다).
사용자가 재생 버튼을 클릭하면 이전 단계에서 검색된 스피치 마크를 구문 분석하여 시간 제한을 사용하여 일련의 시간이 지정된 이벤트를 생성합니다. 이벤트는 브라우저에서 음성 텍스트를 강조 표시하는 데 사용되는 또 다른 JavaScript 기능인 콜백 기능을 호출합니다. 동시에 JavaScript 함수는 URL 핸들에서 오디오 파일을 스트리밍합니다.
그 결과 이벤트가 적절한 시간에 실행되어 오디오가 재생되는 동안 음성으로 텍스트를 강조 표시합니다. JavaScript 시간 제한을 사용하면 강조 표시된 텍스트와 오디오를 동기화할 수 있습니다.
사전 조건
이 솔루션을 실행하려면 다음이 필요합니다. AWS 계정 과 AWS 자격 증명 및 액세스 관리 (IAM) Amazon CloudFront, Amazon API Gateway, Amazon Polly, Amazon S3, AWS Lambda 및 AWS Step Functions를 사용할 권한이 있는 사용자.
Lambda를 사용하여 스피치 및 스피치 마크 생성
다음 코드는 Amazon Polly를 호출합니다. synthesize_speech 기능을 두 번 사용하여 오디오 및 스피치 마크 파일을 가져옵니다. 비동기 함수로 실행되며 약속을 사용하여 동시에 결과를 반환하도록 조정됩니다.
JavaScript 쪽에서 텍스트 강조 표시는 형광펜(시작, 종료, 단어)에 의해 수행되며 시간이 지정된 이벤트는 다음으로 설정됩니다. setTimers():
대체 접근법
이전 접근 방식 대신 몇 가지 대안을 고려할 수 있습니다.
- Step Functions 상태 시스템 내에서 스피치 마크와 오디오 파일을 모두 생성합니다. 상태 시스템은 병렬 분기 조건을 호출하여 두 가지 다른 Lambda 함수를 호출할 수 있습니다. 하나는 음성을 생성하고 다른 하나는 음성 마크를 생성합니다. 이에 대한 코드는 다음에서 찾을 수 있습니다. 단계별 기능 사용 Github 저장소의 하위 폴더.
- Amazon Polly를 비동기식으로 호출하여 오디오 및 스피치 마크를 생성합니다. 이 접근 방식은 텍스트 콘텐츠가 크거나 사용자가 실시간 응답을 필요로 하지 않는 경우에 사용할 수 있습니다. 긴 오디오 파일 생성에 대한 자세한 내용은 다음을 참조하십시오. 긴 오디오 파일 만들기.
- Amazon Polly에서 다음을 사용하여 미리 서명된 URL을 직접 생성하도록 합니다.
generate_presigned_urlBoto3에서 Amazon Polly 클라이언트를 호출합니다. 이 접근 방식을 사용하면 Amazon Polly가 매번 새로 오디오 및 스피치 마크를 생성합니다. 현재 접근 방식에서는 이러한 파일을 Amazon S3에 저장합니다. 이 저장된 파일은 우리 코드 버전의 브라우저에서 액세스할 수 없지만 Amazon Polly를 사용하여 텍스트의 오디오를 다시 생성하는 대신 Amazon S3에서 가져와서 이전에 생성된 오디오 파일을 재생하도록 코드를 수정할 수 있습니다. 우리는 더 있습니다 Python으로 Amazon Polly에 액세스하기 위한 코드 예제 AWS 코드 라이브러리에서.
솔루션 만들기
전체 솔루션은 당사에서 구할 수 있습니다. Github 레포. 계정에서 이 솔루션을 생성하려면 README.md 파일의 지침을 따르십시오. 솔루션에는 다음이 포함됩니다. AWS 클라우드 포메이션 리소스를 프로비저닝하기 위한 템플릿입니다.
대청소
이 데모에서 생성된 리소스를 정리하려면 다음 단계를 수행하십시오.
- CloudFormation 템플릿(버킷 A), 소스 코드(버킷 B) 및 웹사이트(
pth-cf-text-highlighter-website-[Suffix]). - CloudFormation 스택 삭제
pth-cf. - 음성 파일이 포함된 S3 버킷을 삭제합니다(
pth-speech-[Suffix]). 이 버킷은 Amazon Polly에서 생성된 오디오 및 스피치 마크 파일을 저장하기 위해 CloudFormation 템플릿에서 생성되었습니다.
요약
이 게시물에서는 Amazon Polly를 사용하여 말하는 텍스트를 강조 표시할 수 있는 솔루션의 예를 보여 주었습니다. 이것은 오디오 파일에서 각 단어나 문장이 시작되는 위치에 대한 마커를 제공하는 Amazon Polly 스피치 마크 기능을 사용하여 개발되었습니다.
이 솔루션은 CloudFormation 템플릿으로 제공됩니다. 텍스트 음성 변환을 수행하는 모든 웹 응용 프로그램에 있는 그대로 배포할 수 있습니다. 이는 책의 오디오, 립싱크 기능이 있는 아바타(viseme 스피치 마크 사용), 웹 사이트 및 블로그에 시각적 기능을 추가하고 청각 장애가 있는 사람들을 돕는 데 유용합니다.
텍스트 강조 표시 외에 추가 작업을 수행하도록 확장할 수 있습니다. 예를 들어 브라우저는 텍스트를 말하는 동안 프런트 엔드에서 이미지를 표시하고, 음악을 재생하고, 다른 애니메이션을 실행할 수 있습니다. 이 기능은 동적 오디오 북, 교육 콘텐츠 및 풍부한 텍스트 음성 변환 응용 프로그램을 만드는 데 유용할 수 있습니다.
이 솔루션을 사용해 보고 다음 링크에서 관련 AWS 서비스에 대해 자세히 알아보십시오. 특정 요구 사항에 맞게 기능을 확장할 수 있습니다.
저자에 관하여
 바라드 G 바라다라잔 AWS에서 DNB(Digital Native Businesses) 고객을 위한 신뢰할 수 있는 조언자이자 현장 CTO입니다. 그는 그들이 AWS 제품 및 서비스를 사용하여 대규모로 혁신적인 솔루션을 설계하고 구축하도록 돕습니다. Varad의 관심 분야는 IT 전략 컨설팅, 아키텍처 및 제품 관리입니다. 업무 외에 Varad는 창의적인 글쓰기, 가족 및 친구와 함께 영화 감상, 여행을 즐깁니다.
바라드 G 바라다라잔 AWS에서 DNB(Digital Native Businesses) 고객을 위한 신뢰할 수 있는 조언자이자 현장 CTO입니다. 그는 그들이 AWS 제품 및 서비스를 사용하여 대규모로 혁신적인 솔루션을 설계하고 구축하도록 돕습니다. Varad의 관심 분야는 IT 전략 컨설팅, 아키텍처 및 제품 관리입니다. 업무 외에 Varad는 창의적인 글쓰기, 가족 및 친구와 함께 영화 감상, 여행을 즐깁니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/highlight-text-as-its-being-spoken-using-amazon-polly/

