
"1온스의 예방은 1파운드의 치료와 같다"라는 옛말은 어떤 일이 발생한 후에 손상을 복구하는 것보다 처음부터 발생하는 것을 막는 것이 더 쉽다는 것을 상기시켜 줍니다.
인공지능(AI) 시대에 이 속담은 정규화와 같은 기술을 통해 과적합과 같은 잠재적인 함정을 피하는 것이 중요함을 강조합니다.
이 기사에서는 Sci-kit Learn(머신 러닝)과 Tensorflow(딥 러닝)을 사용하여 애플리케이션에 대한 기본 원리부터 시작하여 정규화를 알아보고 이러한 결과를 비교하여 실제 데이터 세트로 변형시키는 힘을 확인합니다. 시작하자!
정규화는 모델의 과적합을 방지하는 것을 목표로 하는 머신러닝과 딥러닝에서 중요한 개념입니다.
과적합은 모델이 훈련 데이터를 너무 잘 학습할 때 발생합니다. 상황은 귀하의 모델이 사실이 되기에는 너무 좋다는 것을 보여줍니다.
과적합이 어떤 모습인지 살펴보겠습니다.
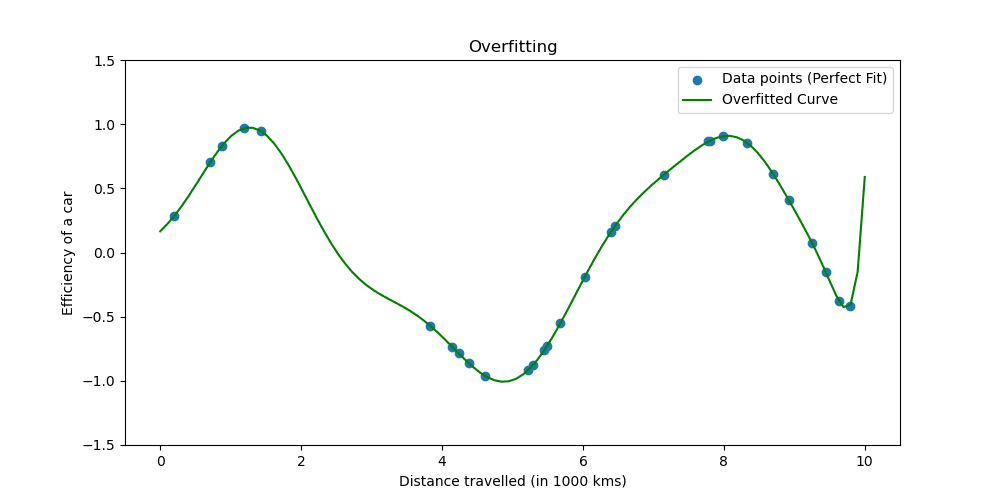
정규화 기술은 학습 프로세스를 조정하여 모델을 단순화함으로써 모델이 훈련 데이터에서 잘 작동하고 새 데이터에 잘 일반화되도록 합니다. 우리는 이를 수행하는 두 가지 잘 알려진 방법을 탐색할 것입니다.
기계 학습에서 정규화는 선형 및 로지스틱 회귀와 같은 선형 모델에 적용되는 경우가 많습니다. 이러한 맥락에서 가장 일반적인 정규화 형태는 다음과 같습니다.
- L1 정규화(올가미 회귀)
- L2 정규화(능형 회귀)
올가미 정규화 일부 계수 값이 정확히 0이 되도록 허용하여 모델이 가장 필수적인 특성만 사용하도록 장려합니다. 이는 특성 선택에 특히 유용할 수 있습니다.


반면에, 미국에서 체류를 연장하고자 이전의 승인을 갱신하려던 능선 정규화 값의 제곱에 불이익을 주어 중요한 계수를 억제합니다.

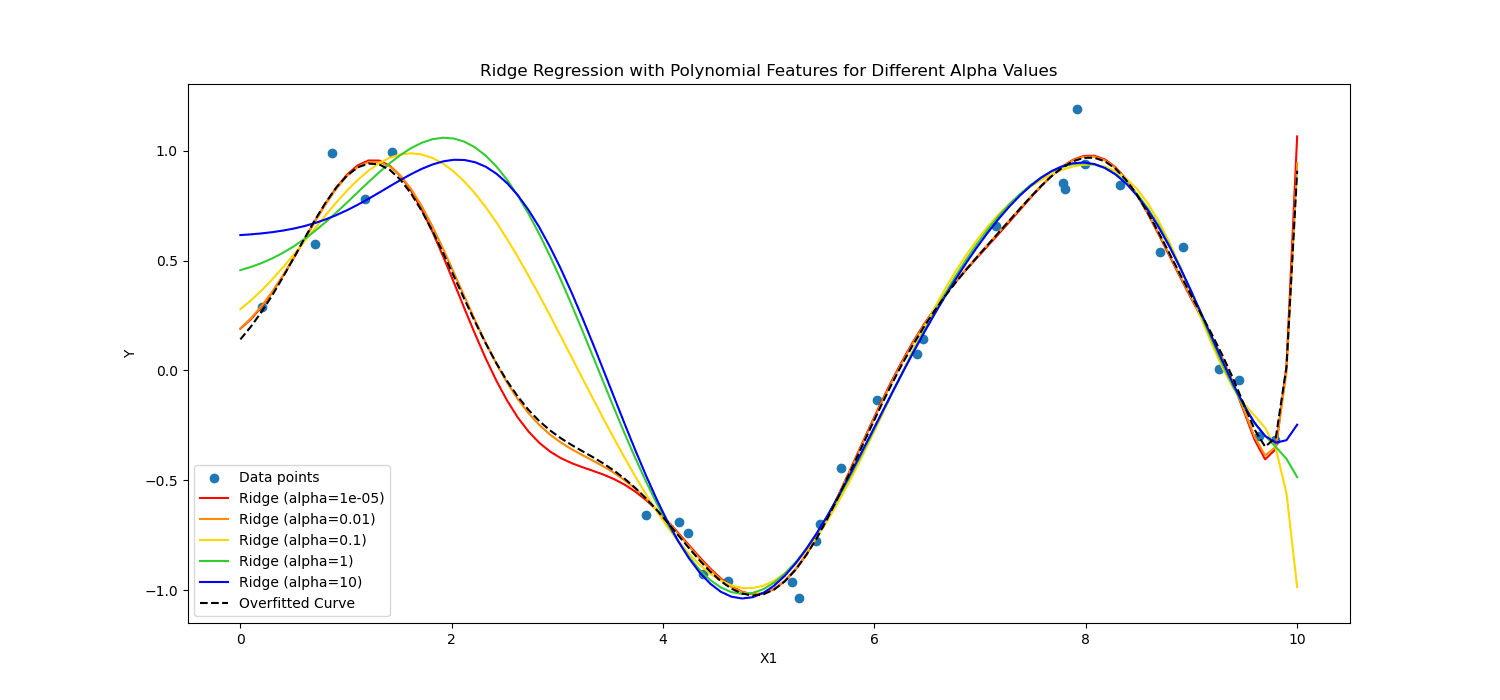
즉, 그들은 다르게 계산했습니다.
이것을 심장병 환자 데이터에 적용하여 딥 러닝과 머신 러닝에서의 효과를 살펴보겠습니다.
이제 정규화를 적용하여 심장 환자 데이터를 분석하여 정규화의 힘을 살펴보겠습니다. 다음에서 데이터세트에 접근할 수 있습니다. 여기에서 지금 확인해 보세요..
기계 학습을 적용하기 위해 Scikit-learn을 사용합니다. 딥러닝을 적용하기 위해 TensorFlow를 사용하겠습니다. 시작하자!
기계 학습의 정규화
Scikit-learn은 가장 인기 있는 것 중 하나입니다. Python 라이브러리 간단하고 효율적인 데이터 분석 및 모델링 도구를 제공하는 머신러닝을 위한 것입니다.
여기에는 특히 선형 모델에 대한 다양한 정규화 기술의 구현이 포함됩니다.
여기에서는 L1(Lasso) 및 L2(Ridge) 정규화를 적용하는 방법을 살펴보겠습니다.
다음 코드에서는 Ridge(L2) 및 Lasso 정규화(L1) 기술을 사용하여 로지스틱 회귀를 학습합니다. 마지막으로 자세한 보고서를 살펴보겠습니다. 코드를 보자.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
다음은 출력입니다.
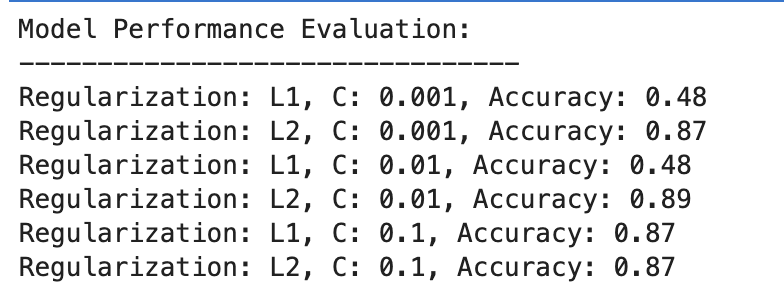
결과를 평가해 봅시다.
L1 정규화
- C=0.001에서는 정확도가 현저히 낮습니다(48%). 이는 모델이 과소적합되었음을 나타냅니다. 너무 많은 정규화를 보여줍니다.
- C가 0.01로 증가함에 따라 L1의 정확도는 변경되지 않고 모델이 여전히 과소적합 문제를 겪고 있거나 정규화가 너무 강함을 나타냅니다.
- C=0.1에서는 정확도가 87%로 크게 향상되어 정규화 강도를 줄이면 모델이 데이터에서 더 잘 학습할 수 있음을 보여줍니다.
L2 정규화
전반적으로 L2 정규화는 C=87의 경우 0.001%의 정확도, C=89의 경우 0.01%의 정확도로 일관되게 잘 수행되고 C=87의 경우 0.1%로 안정화됩니다.
이는 잠재적으로 그 특성으로 인해 L2 정규화가 로지스틱 회귀 모델의 이 데이터 세트에 대해 일반적으로 더 관대하고 효과적이라는 것을 의미합니다.
딥러닝의 정규화
L1(Lasso) 및 L2(Ridge) 정규화, 드롭아웃 및 조기 중지를 포함하여 딥러닝에는 여러 정규화 기술이 사용됩니다.
이번 예제에서는 이전 기계 학습 예제에서 했던 작업을 반복하기 위해 L1 및 L2 정규화를 적용하겠습니다. 이번에는 L1 및 L2 정규화 값 목록을 정의해 보겠습니다.
그런 다음 이러한 모든 가치에 대해 딥 러닝 모델을 훈련 및 평가하고 마지막에는 결과를 평가합니다.
코드를 봅시다.
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:8} | {metrics[1]:8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
다음은 출력입니다.
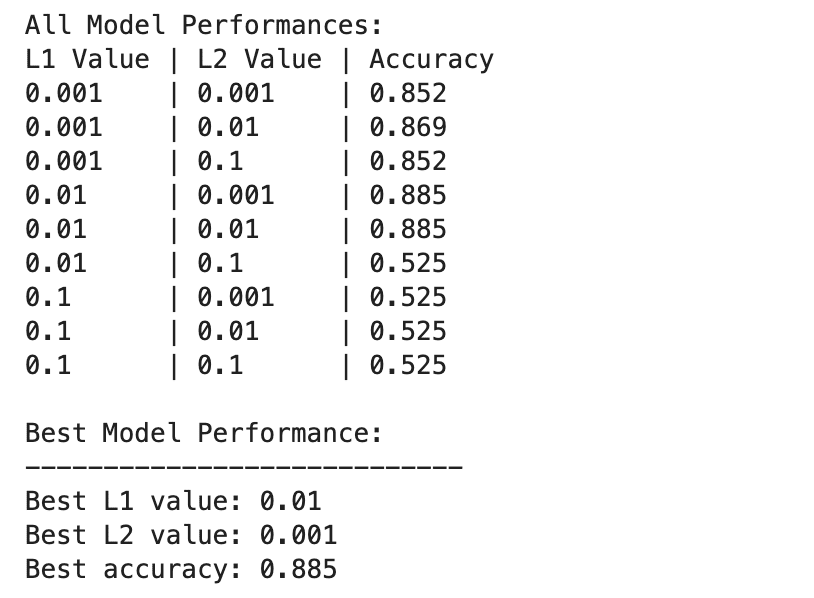
딥 러닝 모델 성능은 L1 및 L2 정규화 값의 다양한 조합에 따라 더욱 광범위하게 달라집니다.
최고의 성능은 L1=0.01 및 L2=0.001에서 관찰되었으며 정확도는 88.5%입니다. 이는 모델이 데이터의 기본 패턴을 캡처할 수 있도록 하면서 과적합을 방지하는 균형 잡힌 정규화를 나타냅니다.
특히 L1=0.1 또는 L2=0.1에서 정규화 값이 높을수록 모델 정확도가 52.5%로 크게 감소합니다. 이는 정규화가 너무 많으면 모델의 학습 용량이 심각하게 제한된다는 것을 의미합니다.
정규화의 기계 학습 및 딥 러닝
머신러닝과 딥러닝의 결과를 비교해 보겠습니다.
정규화의 효율성: 머신러닝과 딥러닝 맥락 모두에서 적절한 정규화는 과적합을 완화하는 데 도움이 되지만, 과도한 정규화는 과소적합으로 이어집니다. 최적의 정규화 강도는 다양하며 딥 러닝 모델은 복잡성이 높기 때문에 잠재적으로 더 미묘한 균형이 필요할 수 있습니다.
성능 : 최고 성능의 기계 학습 모델(C=2, 0.01% 정확도의 L89)과 최고 성능의 딥 러닝 모델(L1=0.01, L2=0.001, 88.5% 정확도)은 비슷한 정확도를 달성하여 두 접근 방식이 모두 효과적일 수 있음을 보여줍니다. 이 데이터 세트에서 높은 성능을 달성하기 위해 정규화되었습니다.
정규화 전략: L2 정규화는 로지스틱 회귀 모델에서 C 선택에 더 효과적이고 덜 민감한 것으로 보이는 반면, L1 및 L2 정규화의 조합은 기능 선택과 가중치 페널티 사이의 균형을 제공하여 딥 러닝에서 최상의 결과를 제공합니다.
정규화의 선택과 강도는 학습 복잡성과 과적합 또는 과소적합의 위험 사이의 균형을 맞추기 위해 신중하게 조정되어야 합니다.
이 탐색 전반에 걸쳐 정규화에 대한 신비를 풀고 과적합을 방지하고 모델이 보이지 않는 데이터에 대해 잘 일반화되도록 하는 역할을 보여주었습니다.
정규화 기술을 적용하면 기계 학습 및 딥 러닝의 숙련도에 더 가까워지고 데이터 과학자 도구 세트가 강화됩니다.
데이터 프로젝트로 이동하여 다음과 같은 다양한 시나리오에서 데이터를 정규화해 보세요. 배송 기간 예측. 이 데이터 프로젝트에서는 머신러닝과 딥러닝 모델을 모두 사용했습니다. 하지만 결국 개선의 여지가 있을 수 있다는 점도 언급했습니다. 그렇다면 거기에서 정규화를 시도해 보고 그것이 도움이 되는지 확인해 보는 것은 어떨까요?
네이트 로시디 데이터 과학자이자 제품 전략 분야의 전문가입니다. 그는 분석을 가르치는 겸임 교수이기도 하며, 스트라타스크래치, 데이터 사이언티스트가 상위 기업의 실제 인터뷰 질문을 통해 인터뷰를 준비하는 데 도움이 되는 플랫폼입니다. 그와 연결 트위터: StrataScratch or 링크드인.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-regularization-and-what-is-it-for

