Apache Airflow용 Amazon 관리형 워크플로 (Amazon MWAA)는 친숙한 서비스를 사용할 수 있는 관리형 서비스입니다. 아파치 에어 플로우 향상된 확장성, 가용성 및 보안을 갖춘 환경을 통해 기본 인프라 관리에 대한 운영 부담 없이 비즈니스 워크플로를 강화하고 확장할 수 있습니다. 에어플로우에서는 방향성 비순환 그래프 (DAG)는 Python 코드로 정의됩니다. 동적 DAG 일반적으로 일부 외부 조건, 구성 또는 매개변수를 기반으로 런타임 중에 즉시 DAG를 생성하는 기능을 참조하세요. 동적 DAG를 사용하면 시간이 지남에 따라 변경될 수 있는 데이터 및 구성을 기반으로 DAG 내에서 작업을 생성, 예약 및 실행할 수 있습니다.
Airflow DAG에 역동성을 도입하는 다양한 방법이 있습니다(동적 DAG 생성) 환경 변수 및 외부 파일을 사용합니다. 접근 방식 중 하나는 다음을 사용하는 것입니다. DAG 공장 YAML 기반 구성 파일 방법. 이 라이브러리는 YAML의 선언적 매개변수를 사용하여 새로운 DAG를 쉽게 생성하고 구성하는 것을 목표로 합니다. 기본 사용자 정의가 가능하고 오픈 소스이므로 새로운 기능을 간단하게 생성하고 사용자 정의할 수 있습니다.
이 게시물에서는 다음을 사용하여 YAML 파일로 동적 DAG를 생성하는 프로세스를 살펴봅니다. DAG 공장 도서관. 동적 DAG는 다음과 같은 여러 가지 이점을 제공합니다.
- 향상된 코드 재사용성 – YAML 파일을 통해 DAG를 구성함으로써 재사용 가능한 구성 요소를 촉진하여 워크플로 정의의 중복성을 줄입니다.
- 간소화된 유지 관리 – YAML 기반 DAG 생성은 워크플로 수정 및 업데이트 프로세스를 단순화하여 보다 원활한 유지 관리 절차를 보장합니다.
- 유연한 매개변수화 – YAML을 사용하면 DAG 구성을 매개변수화하여 다양한 요구 사항에 따라 워크플로를 동적으로 조정할 수 있습니다.
- 스케줄러 효율성 향상 – 동적 DAG를 사용하면 보다 효율적으로 예약하고 리소스 할당을 최적화하며 전체 워크플로 실행을 향상할 수 있습니다.
- 향상된 확장성 – YAML 기반 DAG는 병렬 실행을 허용하여 증가된 워크로드를 효율적으로 처리할 수 있는 확장 가능한 워크플로를 지원합니다.
YAML 파일과 DAG Factory 라이브러리의 강력한 기능을 활용하여 DAG 구축 및 관리에 대한 다양한 접근 방식을 활용하여 강력하고 확장 가능하며 유지 관리 가능한 데이터 파이프라인을 만들 수 있도록 지원합니다.
솔루션 개요
이 게시물에서는 코로나19 데이터 세트를 처리하도록 설계된 예제 DAG 파일을 사용합니다. 워크플로우 프로세스에는 다음에서 제공하는 오픈 소스 데이터 세트 처리가 포함됩니다. WHO-COVID-19-글로벌. 설치한 후 DAG-공장 Python 패키지에서는 다양한 작업에 대한 정의가 포함된 YAML 파일을 생성합니다. 다음을 통과하여 국가별 사망자 수를 처리합니다. Country 개별 국가 기반 DAG를 생성하는 변수로 사용됩니다.
다음 다이어그램은 논리 블록 내의 데이터 흐름과 함께 전체 솔루션을 보여줍니다.

사전 조건
이 연습에서는 다음과 같은 전제 조건이 있어야합니다.
또한 다음 단계를 완료하세요. AWS 리전 Amazon MWAA를 사용할 수 있는 경우):
- 를 생성 아마존 MWAA 환경 (아직 없는 경우) Amazon MWAA를 처음 사용하는 경우 다음을 참조하세요. Amazon Managed Workflows for Apache Airflow(MWAA) 소개.
확인 AWS 자격 증명 및 액세스 관리 (IAM) 환경 설정에 사용되는 사용자 또는 역할에는 다음 권한에 연결된 IAM 정책이 있습니다.
여기에 언급된 액세스 정책은 이 게시물의 예시일 뿐입니다. 프로덕션 환경에서는 연습을 통해 필요한 세분화된 권한만 제공하세요. 최소 권한 원칙.
- Amazon MWAA 환경을 생성하는 동안 계정 내에서 고유한 Amazon S3 버킷 이름을 생성하고 다음과 같은 폴더를 생성합니다.
dags와requirements.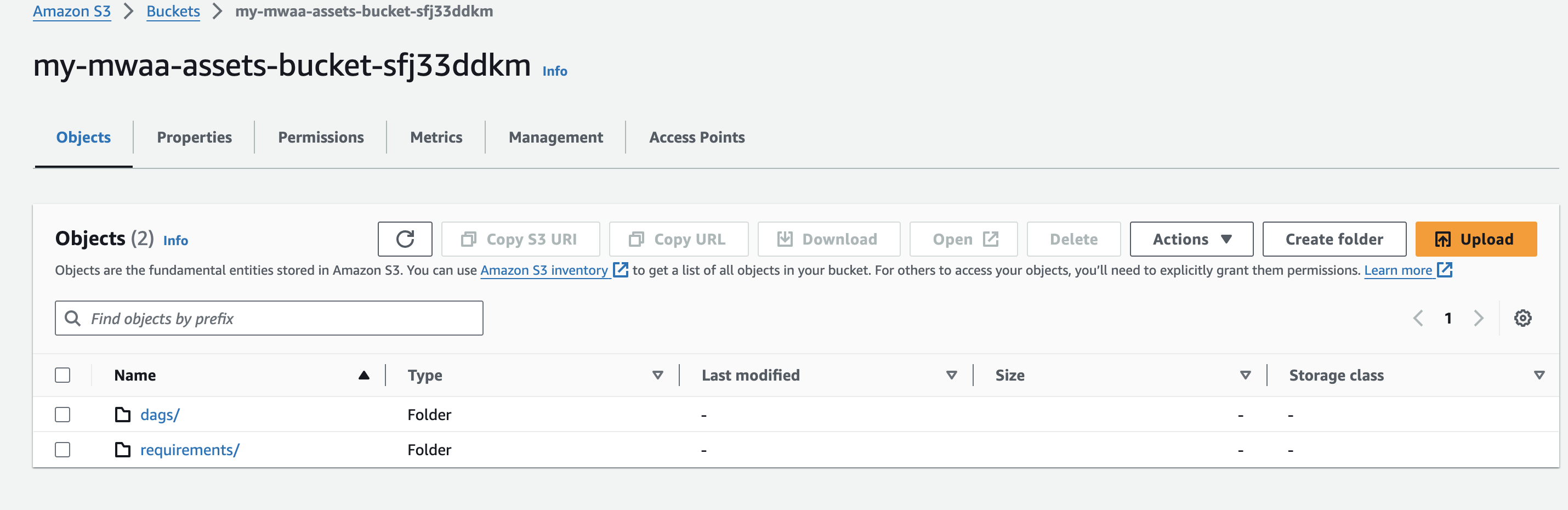
- 생성 및 업로드
requirements.txt다음 내용을 담은 파일을requirements폴더. 바꾸다{environment-version}환경의 버전 번호와{Python-version}환경과 호환되는 Python 버전:
이 게시물에 설명된 사용 사례 예시에만 Pandas가 필요합니다. dag-factory 유일한 필수 플러그인입니다. 최신 버전의 호환성을 확인하는 것이 좋습니다. dag-factory 아마존 MWAA와 함께. 그만큼 boto 와 psycopg2-binary 라이브러리는 Apache Airflow v2 기본 설치에 포함되어 있으므로 requirements.txt 파일.
- 를 다운로드 WHO-COVID-19-글로벌 데이터 파일 로컬 컴퓨터에 업로드하고
dagsS3 버킷의 접두사.
최신 AWS S3 버킷 버전을 가리키고 있는지 확인하세요. requirements.txt 추가 패키지 설치를 위한 파일입니다. 환경 구성에 따라 일반적으로 15~20분 정도 소요됩니다.
DAG 검증
Amazon MWAA 환경이 다음과 같이 표시되는 경우 유효한 Amazon MWAA 콘솔에서 다음을 선택하여 Airflow UI로 이동합니다. Airflow UI 열기 당신의 환경 옆에.

DAG 탭으로 이동하여 기존 DAG를 확인합니다.
DAG 구성
다음 단계를 완료하십시오.
- 이름이 지정된 빈 파일을 만듭니다.
dynamic_dags.yml,example_dag_factory.py와process_s3_data.py로컬 컴퓨터에서. - 편집
process_s3_data.py파일을 다운로드하고 다음 코드 내용으로 저장한 후 파일을 Amazon S3 버킷에 다시 업로드합니다.dags폴더. 우리는 코드에서 몇 가지 기본적인 데이터 처리를 수행하고 있습니다.- Amazon S3 위치에서 파일 읽기
- 이름 바꾸기
Country_code해당 국가에 적합한 열입니다. - 특정 국가별로 데이터를 필터링합니다.
- 처리된 최종 데이터를 CSV 형식으로 작성하고 S3 접두사에 다시 업로드합니다.
- 편집
dynamic_dags.yml다음 코드 내용으로 저장한 다음 파일을 다시 업로드하세요.dags폴더. 우리는 다음과 같이 국가를 기반으로 다양한 DAG를 연결하고 있습니다.- 모든 DAG에 전달되는 기본 인수를 정의합니다.
- 다음을 전달하여 개별 국가에 대한 DAG 정의를 만듭니다.
op_args - 지도
process_s3_data기능python_callable_name. - 파이썬 연산자 Amazon S3 버킷에 저장된 csv 파일 데이터를 처리합니다.
- 우리는 설정했습니다
schedule_interval10분으로 제한되지만 필요에 따라 이 값을 자유롭게 조정하세요.
- 파일 편집
example_dag_factory.py다음 코드 내용으로 저장한 다음 파일을 다시 업로드하세요.dags폴더. 코드는 기존 DAG를 정리하고 생성합니다.clean_dags()방법과 이를 사용하여 새 DAG를 생성하는 방법generate_dags()의 방법DagFactory예.
- 파일을 업로드한 후 Airflow UI 콘솔로 돌아가 DAG 탭으로 이동하면 새 DAG를 찾을 수 있습니다.
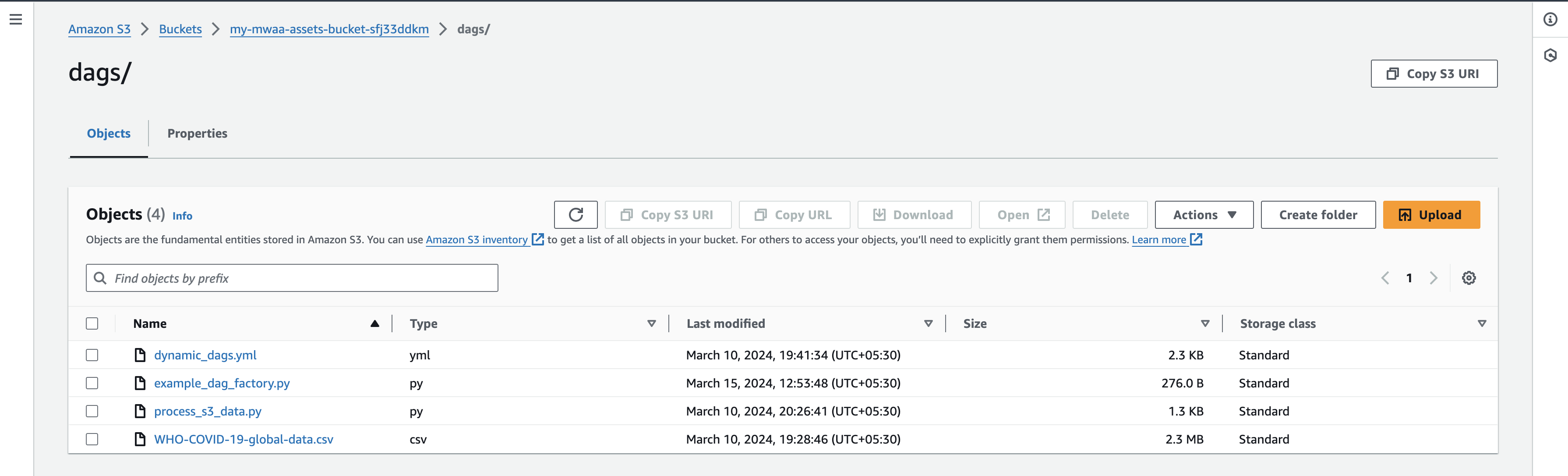
- 파일을 업로드한 후 Airflow UI 콘솔로 돌아가서 DAG 탭 아래에 아래와 같이 새 DAG가 나타나는 것을 확인할 수 있습니다.

DAG를 활성화하고 개별적으로 테스트하여 활성화할 수 있습니다. 활성화하면 다음과 같은 추가 CSV 파일이 생성됩니다. count_death_{COUNTRY_CODE}.csv dags 폴더에 생성됩니다.
청소
이 게시물에서 논의된 다양한 AWS 서비스 사용과 관련된 비용이 발생할 수 있습니다. 향후 요금이 발생하지 않도록 하려면 이 게시물에 설명된 작업을 완료한 후 Amazon MWAA 환경을 삭제하고 S3 버킷을 비운 후 삭제하세요.
결론
이 블로그 게시물에서는 대그공장 동적 DAG를 생성하는 라이브러리입니다. 동적 DAG는 구성에 따라 DAG 파일을 구문 분석할 때마다 결과를 생성하는 기능이 특징입니다. 다음 시나리오에서는 동적 DAG 사용을 고려해보세요.
- DAG 생성의 유연성이 중요한 기존 시스템에서 Airflow로의 마이그레이션 자동화
- 서로 다른 DAG 간에 매개변수만 변경되는 상황으로 인해 워크플로 관리 프로세스가 간소화됩니다.
- 소스 시스템의 진화하는 구조에 의존하는 DAG를 관리하여 변화에 대한 적응성을 제공합니다.
- 이러한 청사진을 생성하고 일관성과 효율성을 촉진하여 팀이나 조직 전체에서 DAG에 대한 표준화된 방식을 확립합니다.
- 복잡한 Python 코딩에 대해 YAML 기반 선언을 수용하여 DAG 구성 및 유지 관리 프로세스를 단순화합니다.
- 데이터 입력을 기반으로 적응하고 발전하는 데이터 기반 워크플로우를 생성하여 효율적인 자동화를 가능하게 합니다.
동적 DAG를 워크플로에 통합하면 자동화, 적응성, 표준화를 향상하여 궁극적으로 데이터 파이프라인 관리의 효율성과 효과를 높일 수 있습니다.
Amazon MWAA DAG Factory에 대해 자세히 알아보려면 다음을 방문하세요. 분석 워크숍을 위한 Amazon MWAA: DAG Factory. Amazon MWAA에 대한 자세한 내용과 코드 예제를 보려면 다음을 방문하세요. Amazon MWAA 사용 설명서 그리고 Amazon MWAA 예제 GitHub 저장소.
저자에 관하여
 자예시 신데 AWS ProServe India의 수석 애플리케이션 설계자입니다. 그는 서버리스, DevOps 및 분석과 같은 최신 소프트웨어 개발 방식을 사용하여 클라우드 중심의 다양한 솔루션을 만드는 것을 전문으로 합니다.
자예시 신데 AWS ProServe India의 수석 애플리케이션 설계자입니다. 그는 서버리스, DevOps 및 분석과 같은 최신 소프트웨어 개발 방식을 사용하여 클라우드 중심의 다양한 솔루션을 만드는 것을 전문으로 합니다.
 하쉬드 욜라 AWS ProServe India의 수석 클라우드 설계자로서 고객이 인프라를 AWS로 마이그레이션하고 현대화할 수 있도록 지원합니다. 그는 컨테이너, AIOP, AWS 개발자 도구 및 서비스를 사용하여 DevSecOps 및 확장 가능한 인프라 구축을 전문으로 합니다.
하쉬드 욜라 AWS ProServe India의 수석 클라우드 설계자로서 고객이 인프라를 AWS로 마이그레이션하고 현대화할 수 있도록 지원합니다. 그는 컨테이너, AIOP, AWS 개발자 도구 및 서비스를 사용하여 DevSecOps 및 확장 가능한 인프라 구축을 전문으로 합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/dynamic-dag-generation-with-yaml-and-dag-factory-in-amazon-mwaa/

