개요
빅 데이터 및 고급 분석에서 PySpark는 대규모 데이터 세트를 처리하고 분산 데이터를 분석하기 위한 강력한 도구로 등장했습니다. 클라우드의 AWS 애플리케이션에 PySpark를 배포하면 데이터 집약적인 작업에 확장성과 유연성을 제공하여 판도를 바꿀 수 있습니다. Amazon Web Services(AWS)는 이러한 배포에 이상적인 플랫폼을 제공하며 Docker 컨테이너와 결합하면 원활하고 효율적인 솔루션이 됩니다.

그러나 클라우드 인프라에 PySpark를 배포하는 것은 복잡하고 어려울 수 있습니다. 분산 컴퓨팅 환경 설정, Spark 클러스터 구성 및 리소스 관리의 복잡성으로 인해 많은 사람들이 잠재력을 최대한 활용하지 못하는 경우가 많습니다.
학습 목표
- PySpark, AWS 및 Docker의 기본 개념을 알아보고 클라우드에 PySpark 클러스터를 배포하기 위한 견고한 기반을 확보하세요.
- AWS 구성, Docker 이미지 준비, Spark 클러스터 관리 등 Docker를 사용하여 AWS에서 PySpark를 설정하는 포괄적인 단계별 가이드를 따르세요.
- 데이터 처리 워크플로를 최대한 활용하기 위한 모니터링, 확장 및 모범 사례 준수를 포함하여 AWS에서 PySpark 성능을 최적화하기 위한 전략을 알아보세요.
이 기사는 데이터 과학 블로그.

사전 조건
Docker를 사용하여 AWS에 PySpark를 배포하는 여정을 시작하기 전에 다음 전제 조건이 충족되었는지 확인하세요.
🚀 로컬 PySpark 설치: PySpark 애플리케이션을 개발하고 테스트하려면 로컬 시스템에 PySpark를 설치하는 것이 중요합니다. 운영 체제의 공식 문서에 따라 PySpark를 설치할 수 있습니다. 이 로컬 설치는 개발 환경 역할을 하므로 PySpark 코드를 AWS에 배포하기 전에 작성하고 테스트할 수 있습니다.
🌐 AWS 계정: PySpark 배포에 필요한 클라우드 인프라 및 서비스에 액세스하려면 활성 AWS(Amazon Web Services) 계정이 필요합니다. AWS 계정이 없으면 AWS 웹사이트에서 가입할 수 있습니다. AWS는 신규 사용자를 위해 리소스가 제한된 프리 티어를 제공하지만 결제 정보를 제공할 준비를 하십시오.
🐳 도커 설치: Docker는 이 배포 프로세스의 핵심 구성 요소입니다. Ubuntu 운영 체제 설치 지침에 따라 로컬 컴퓨터에 Docker를 설치합니다. Docker 컨테이너를 사용하면 PySpark 애플리케이션을 일관되게 캡슐화하고 배포할 수 있습니다.
Windows
- 를 방문
- 를 다운로드 Windows용 도커 데스크탑 설치 관리자.
- 설치 프로그램을 두 번 클릭하여 실행합니다.
- 설치 마법사의 지시를 따르십시오.
- 설치가 완료되면 애플리케이션에서 Docker Desktop을 실행하세요.
macOS
- 머리로
- 를 다운로드 Mac용 도커 데스크탑 설치 관리자.
- 설치 프로그램을 두 번 클릭하여 엽니다.
- Docker 아이콘을 애플리케이션 폴더로 드래그하세요.
- 애플리케이션에서 Docker를 실행하세요.
리눅스 (우분투)
1. 터미널을 열고 패키지 관리자를 업데이트합니다.
sudo apt-get update2. 필요한 종속성을 설치합니다.
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common3. Docker의 공식 GPG 키를 추가합니다.
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg4. Docker 저장소를 설정합니다.
echo "deb [signed-by=/usr/share/keyrings/docker-archive-keyring.gpg]
https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null5. 패키지 색인을 다시 업데이트하십시오.
sudo apt-get update6. 도커를 설치합니다.
sudo apt-get install -y docker-ce docker-ce-cli containerd.io7. Docker 서비스를 시작하고 활성화합니다.
sudo systemctl start docker
sudo systemctl enable docker8. 설치를 확인합니다.
sudo docker --version**** 한 줄에 분할선 추가
AWS 설정
Amazon Web Services(AWS)는 PySpark 배포의 중추이며, 두 가지 필수 서비스인 Elastic Container Registry(ECR)와 Elastic Compute Cloud(EC2)를 사용하여 동적 클라우드 환경을 생성합니다.
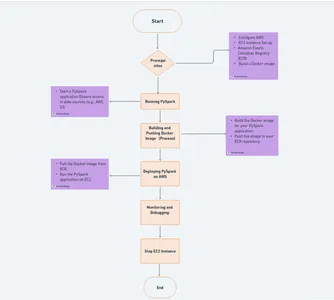
AWS 계정 등록
아직 방문하지 않으셨다면 AWS 가입 페이지 계정을 만들려면 AWS 프리 티어 이상의 기능을 탐색하려면 등록 절차에 따라 필요한 정보를 제공하고 결제 세부 정보를 준비하십시오.
AWS 프리 티어
AWS를 처음 사용하는 경우 제한된 리소스와 서비스를 12개월 동안 무료로 제공하는 AWS 프리 티어를 활용해 보십시오. 이는 비용을 들이지 않고 AWS를 탐색할 수 있는 훌륭한 방법입니다.
AWS 액세스 키 및 비밀 키
AWS와 프로그래밍 방식으로 상호 작용하려면 액세스 키 ID와 보안 액세스 키가 필요합니다. 생성하려면 다음 단계를 따르세요.
- AWS 관리 콘솔에 로그인합니다.
- IAM(Identity & Access Management) 서비스로 이동합니다.
- 왼쪽 탐색 창에서 "사용자"를 클릭합니다.
- 새 사용자를 생성하거나 기존 사용자를 선택합니다.
- '보안 자격 증명' 탭에서 액세스 키를 생성하세요.
- 나중에 사용할 수 있도록 액세스 키 ID와 비밀 액세스 키를 기록해 두세요.
- 사용자를 클릭한 후
탄력적 컨테이너 레지스트리(ECR)
ECR은 AWS에서 제공하는 관리형 Docker 컨테이너 레지스트리 서비스입니다. Docker 이미지를 저장하기 위한 저장소가 됩니다. 다음 단계에 따라 ECR을 설정할 수 있습니다.
- AWS Management Console에서 Amazon ECR 서비스로 이동합니다.
- 새 저장소를 생성하고 이름을 지정한 후 저장소 설정을 구성하세요.
- ECR 저장소의 URI를 기록해 두십시오. Docker 이미지 푸시에 필요합니다.
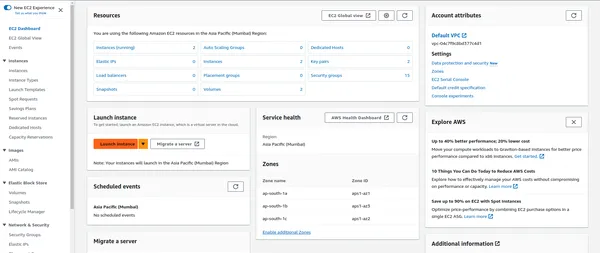
탄력적 컴퓨팅 클라우드(EC2)
EC2는 클라우드에서 확장 가능한 컴퓨팅 용량을 제공하고 PySpark 애플리케이션을 호스팅합니다. EC2 인스턴스를 설정하려면:
- AWS Management Console에서 EC2 서비스로 이동합니다.
- 워크로드에 적합한 인스턴스 유형을 선택하여 새 EC2 인스턴스를 시작합니다.
- 인스턴스 세부 정보 및 스토리지 옵션을 구성합니다.
- EC2 인스턴스에 안전하게 연결하려면 기존 키 페어를 생성하거나 선택하세요.
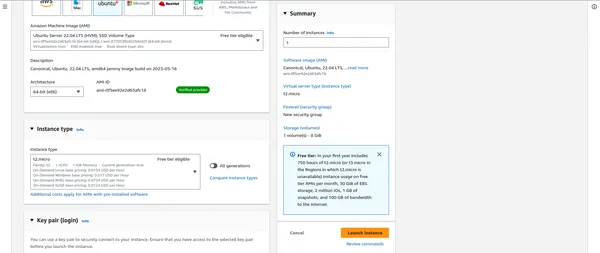
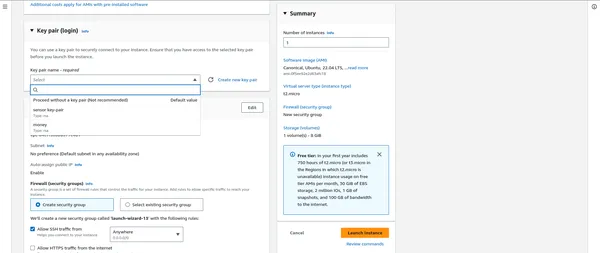
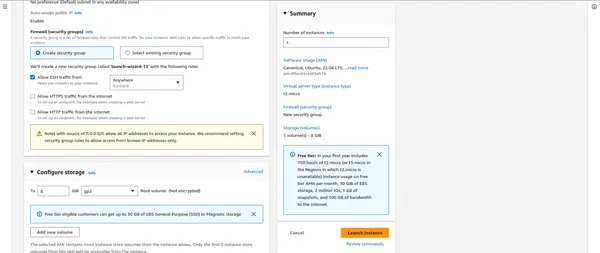
"""" 여기에서 보안 그룹 """을 연결한 후 중요합니다.
나중에 사용할 수 있도록 AWS 설정 값 저장
AWS_ACCESS_KEY_ID: AKIAYOURSAMPLEACCESSKEY
AWS_ECR_LOGIN_URI: 123456789012.dkr.ecr.region.amazonaws.com
AWS_REGION: us-east-1
AWS_SECRET_ACCESS_KEY: YOURSAMPLESECRETACCESSKEY12345
ECR_REPOSITORY_NAME: your-ecr-repository-nameGitHub 비밀 및 변수 설정
이제 AWS 설정 값이 준비되었으므로 GitHub 비밀 및 변수를 사용하여 GitHub 리포지토리에서 이를 안전하게 구성할 차례입니다. 이는 PySpark 배포 프로세스에 추가 보안 계층과 편의성을 추가합니다.
AWS 값을 설정하려면 다음 단계를 따르세요.
GitHub 저장소에 액세스하세요
- PySpark 프로젝트를 호스팅하는 GitHub 저장소로 이동하면 됩니다.
저장소 설정에 액세스
- 저장소 내에서 "설정" 탭을 클릭하세요.
비밀 관리
- 왼쪽 사이드바에 '비밀'이라는 옵션이 있습니다. 이를 클릭하면 GitHub 비밀 관리 인터페이스에 액세스할 수 있습니다.
새 비밀 추가
- 여기에서 AWS 설정 값을 비밀로 추가할 수 있습니다.
- 새로운 비밀을 생성하려면 “새 저장소 비밀”을 클릭하세요.
- 각 AWS 값에 대해 값의 목적에 해당하는 이름(예: "AWS_ACCESS_KEY_ID", "AWS_SECRET_ACCESS_KEY", "AWS_REGION" 등)으로 보안 비밀을 생성합니다.
- "값" 필드에 실제 값을 입력합니다.
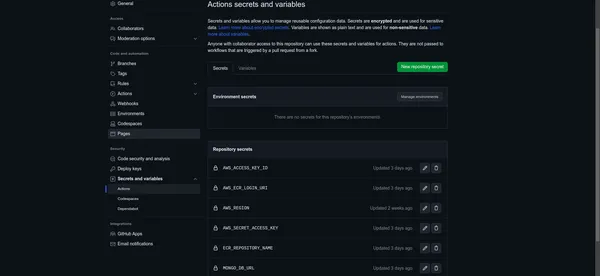
당신의 비밀을 저장하세요
- 각 값에 대해 "비밀 추가" 버튼을 클릭하여 GitHub 비밀로 저장하세요.
AWS 암호가 GitHub에 안전하게 저장되어 있으면 GitHub Actions 워크플로에서 이를 쉽게 참조하고 배포 중에 AWS 서비스에 안전하게 액세스할 수 있습니다.
모범 사례
- GitHub 비밀은 암호화되어 있으며 필요한 권한이 있는 승인된 사용자만 액세스할 수 있습니다. 이를 통해 민감한 AWS 값의 보안이 보장됩니다.
- GitHub 비밀을 사용하면 코드나 구성 파일에 민감한 정보가 직접 노출되는 것을 방지하여 프로젝트 보안을 강화할 수 있습니다.
이제 AWS 설정 값이 GitHub 리포지토리에 안전하게 구성되어 PySpark 배포 워크플로에 쉽게 사용할 수 있습니다.
코드 구조 이해
Docker를 사용하여 AWS에 PySpark를 효과적으로 배포하려면 프로젝트 코드의 구조를 파악하는 것이 중요합니다. 코드베이스를 구성하는 구성 요소를 분석해 보겠습니다.
├── .github
│ ├── workflows
│ │ ├── build.yml
├── airflow
├── configs
├── consumerComplaint
│ ├── cloud_storage
│ ├── components
│ ├── config
│ │ ├── py_sparkmanager.py
│ ├── constants
│ ├── data_access
│ ├── entity
│ ├── exceptions
│ ├── logger
│ ├── ml
│ ├── pipeline
│ ├── utils
├── output
│ ├── .png
├── prediction_data
├── research
│ ├── jupyter_notebooks
├── saved_models
│ ├── model.pkl
├── tests
├── venv
├── Dockerfile
├── app.py
├── requirements.txt
├── .gitignore
├── .dockerignore
애플리케이션 코드(app.py)
- app.py는 PySpark 애플리케이션 실행을 담당하는 기본 Python 스크립트입니다.
- 이는 PySpark 작업의 진입점이며 애플리케이션의 핵심 역할을 합니다.
- 이 스크립트를 맞춤설정하여 데이터 처리 파이프라인, 작업 예약 등을 정의할 수 있습니다.
도커 파일
- Dockerfile에는 PySpark 애플리케이션용 Docker 이미지를 빌드하기 위한 지침이 포함되어 있습니다.
- 기본 이미지를 지정하고, 필요한 종속성을 추가하고, 애플리케이션 코드를 컨테이너에 복사하고, 런타임 환경을 설정합니다.
- 이 파일은 원활한 배포를 위해 애플리케이션을 컨테이너화하는 데 중요한 역할을 합니다.
요구사항(requirements.txt)
- 요구사항.txt에는 PySpark 애플리케이션에 필요한 Python 패키지 및 종속성이 나열되어 있습니다.
- 이러한 패키지는 Docker 컨테이너 내에 설치되어 애플리케이션이 원활하게 실행되도록 합니다.
GitHub 작업 작업 흐름
- GitHub Actions 워크플로는 프로젝트 저장소 내의 .github/workflows/에 정의되어 있습니다.
- 빌드, 테스트 및 배포 프로세스를 자동화합니다.
- main.yml과 같은 워크플로 파일은 코드 푸시 또는 풀 요청과 같은 특정 이벤트가 발생할 때 실행할 단계를 간략하게 설명합니다.
py_sparkmanager.py 빌드
import os
from dotenv import load_dotenv
from pyspark.sql import SparkSession # Load environment variables from .env
load_dotenv() access_key_id = os.getenv("AWS_ACCESS_KEY_ID")
secret_access_key = os.getenv("AWS_SECRET_ACCESS_KEY") # Initialize SparkSession
spark_session = SparkSession.builder.master('local[*]').appName('consumer_complaint') .config("spark.executor.instances", "1") .config("spark.executor.memory", "6g") .config("spark.driver.memory", "6g") .config("spark.executor.memoryOverhead", "8g") .config('spark.jars.packages', "com.amazonaws:aws-java-sdk:1.7.4, org.apache.hadoop:hadoop-aws:2.7.3") .getOrCreate() # Configure SparkSession for AWS S3 access
spark_session._jsc.hadoopConfiguration().set("fs.s3a.awsAccessKeyId", access_key_id)
spark_session._jsc.hadoopConfiguration().set("fs.s3a.awsSecretAccessKey", secret_access_key)
spark_session._jsc.hadoopConfiguration().set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
spark_session._jsc.hadoopConfiguration().set("com.amazonaws.services.s3.enableV4", "true")
spark_session._jsc.hadoopConfiguration().set("fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.BasicAWSCredentialsProvider")
spark_session._jsc.hadoopConfiguration().set("fs.s3a.endpoint", "ap-south-1.amazonaws.com")
spark_session._jsc.hadoopConfiguration().set("fs.s3.buffer.dir", "tmp")
이 코드는 SparkSession을 설정하고, AWS S3 액세스를 위해 구성하고, 환경 변수에서 AWS 자격 증명을 로드하므로 PySpark 애플리케이션에서 AWS 서비스를 원활하게 사용할 수 있습니다.
PySpark Docker 이미지 준비(IMP)
이 섹션에서는 PySpark 애플리케이션을 캡슐화하여 이식 가능하고 확장 가능하며 AWS에 배포할 수 있도록 준비하는 Docker 이미지를 생성하는 방법을 살펴보겠습니다. Docker 컨테이너는 PySpark 애플리케이션에 일관된 환경을 제공하여 다양한 설정에서 원활한 실행을 보장합니다.
도커 파일
PySpark용 Docker 이미지 구축의 핵심은 잘 정의된 Dockerfile입니다. 이 파일은 Python 및 PySpark 종속성을 포함하여 컨테이너 환경을 설정하기 위한 지침을 지정합니다.
FROM python:3.8.5-slim-buster
# Use an Ubuntu base image
FROM ubuntu:20.04 # Set JAVA_HOME and install OpenJDK 8
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
RUN apt-get update -y && apt-get install -y openjdk-8-jdk && apt-get install python3-pip -y && apt-get clean && rm -rf /var/lib/apt/lists/* # Set environment variables for your application
ENV AIRFLOW_HOME="/app/airflow"
ENV PYSPARK_PYTHON=/usr/bin/python3
ENV PYSPARK_DRIVER_PYTHON=/usr/bin/python3 # Create a directory for your application and set it as the working directory
WORKDIR /app # Copy the contents of the current directory to the working directory in the container
COPY . /app # Install Python dependencies from requirements.txt
RUN pip3 install -r requirements.txt # Set the entry point to run your app.py script
CMD ["python3", "app.py"]
Docker 이미지 빌드
Dockerfile이 준비되면 다음 명령을 사용하여 Docker 이미지를 빌드할 수 있습니다.
docker build -t your-image-name교체 귀하의 이미지 이름 Docker 이미지에 원하는 이름과 버전을 입력하세요.
로컬 이미지 확인
이미지를 빌드한 후 다음 명령을 사용하여 로컬 Docker 이미지를 나열할 수 있습니다.
docker images docker ps -a docker system dfDocker에서 PySpark 실행
Docker 이미지가 준비되면 Docker 컨테이너에서 PySpark 애플리케이션을 실행할 수 있습니다. 다음 명령을 사용하십시오.
docker run -your-image-name“”” 언젠가 docker 실행 명령이 작동하지 않습니다. 아래 명령을 따르십시오. “””
docker run 80:8080 your-image-name docker run 8080:8080 your-image-name
AWS에 PySpark 배포
이 섹션에서는 Docker 컨테이너를 사용하여 AWS에 PySpark 애플리케이션을 배포하는 방법을 안내합니다. 이 배포에는 PySpark 클러스터 생성을 위한 Amazon Elastic Compute Cloud(EC2) 인스턴스 시작이 포함됩니다.
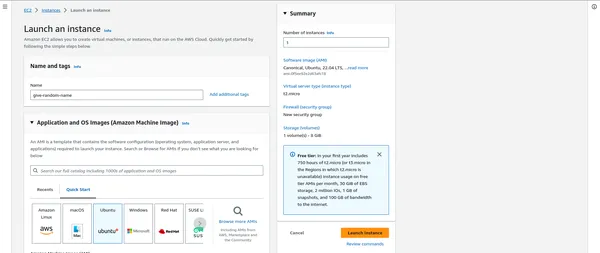
EC2 인스턴스 시작
- EC2 대시보드에서 "인스턴스 시작"을 클릭하세요.
- 요구 사항에 맞는 Amazon 머신 이미지(AMI)(대개 Linux 기반)를 선택할 수 있습니다.
- 워크로드에 따라 인스턴스 유형(예: m5.large, c5.xlarge)을 선택합니다.
- 클러스터의 인스턴스 수를 포함한 인스턴스 세부 정보를 구성합니다.
- 필요에 따라 스토리지, 태그 및 보안 그룹을 추가합니다.
이것이 제가 위에서 언급한 전부입니다.
EC2 인스턴스에 연결
- 인스턴스가 실행되면 SSH를 통해 PySpark 클러스터를 관리할 수 있습니다.
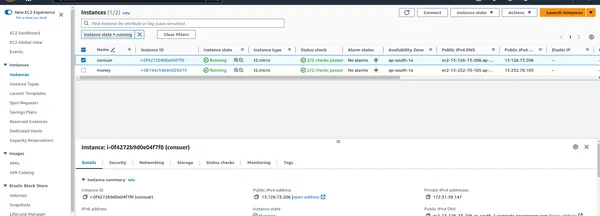
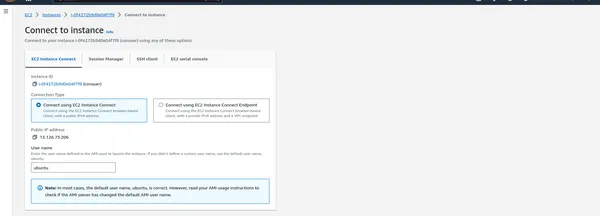
아래 명령을 작성하세요
Docker 설치 스크립트 다운로드
curl -fsSL https://get.docker.com -o get-docker.sh루트 권한으로 Docker 설치 스크립트 실행
sudo sh get-docker.sh현재 사용자를 docker 그룹에 추가합니다('ubuntu'를 사용자 이름으로 바꾸십시오).
sudo usermod -aG docker ubuntu새 셸 세션을 실행하거나 'newgrp'를 사용하여 변경 사항을 활성화하세요.
newgrp dockerGitHub 자체 호스팅 실행기 구축
CI/CD 워크플로 실행을 담당하는 GitHub Actions용 자체 호스팅 실행기를 설정하겠습니다. 자체 호스팅 실행기는 인프라에서 실행되며 특정 구성이 필요하거나 로컬 리소스에 대한 액세스가 필요한 워크플로를 실행하는 데 적합합니다.
자체 호스팅 Runner 설정
- 설정 클릭
- 작업 -> 러너를 클릭합니다.
- 새로운 자체 호스팅 Runner
EC2 머신에 아래 명령을 작성합니다.
- 폴더 생성: 이 명령은 actions-runner라는 디렉터리를 생성하고 현재 디렉터리를 새로 생성된 폴더로 변경합니다.
$ mkdir actions-runner && cd actions-runner
- 최신 실행기 패키지 다운로드: 이 명령은 Linux x64용 GitHub Actions 실행기 패키지를 다운로드합니다. 다운로드할 패키지의 URL을 지정하고 파일 이름 actions-runner-linux-x64-2.309.0.tar.gz로 저장합니다.
$ curl -o actions-runner-linux-x64-2.309.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.309.0/actions-runner-linux-x64-2.309.0.tar.gz
- 선택 사항: 해시 유효성 검사: 이 명령은 해시 유효성을 검사하여 다운로드한 패키지의 무결성을 확인합니다. 다운로드한 패키지의 SHA-256 해시를 계산하고 이를 알려진 예상 해시와 비교합니다. 일치하면 패키지가 유효한 것으로 간주됩니다.
$ echo "2974243bab2a282349ac833475d241d5273605d3628f0685bd07fb5530f9bb1a actions-runner-linux-x64-2.309.0.tar.gz" | shasum -a 256 -c
- 설치 프로그램 추출: 이 명령은 tarball(압축 아카이브)인 다운로드한 패키지의 콘텐츠를 추출합니다.
$ tar xzf ./actions-runner-linux-x64-2.309.0.tar.gz
- 마지막 단계로 실행하세요. 이 명령은 제공된 구성 설정으로 실행기를 시작합니다. 지정된 리포지토리에 대해 GitHub Actions 워크플로를 실행하도록 실행기를 설정합니다.
$ ./run.sh
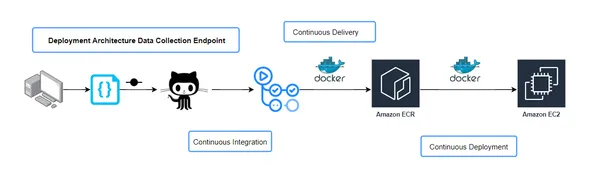
CICD(지속적 통합 및 지속적 전달) 워크플로 구성
CI/CD 파이프라인에서 build.yaml 파일은 애플리케이션을 빌드하고 배포하는 데 필요한 단계를 정의하는 데 중요합니다. 이 구성 파일은 코드 구축, 테스트 및 배포 방법을 포함하여 CI/CD 프로세스의 워크플로를 지정합니다. build.yaml 구성의 중요한 측면과 그 중요성을 살펴보겠습니다.
워크플로우 개요
build.yaml 파일은 CI/CD 파이프라인 중에 실행되는 작업을 간략하게 설명합니다. 이는 애플리케이션 구축 및 테스트와 애플리케이션이 다양한 환경에 배포되는 지속적인 전달을 포함하는 지속적인 통합 단계를 정의합니다.
연속 통합 (CI)
이 단계에는 일반적으로 코드 컴파일, 단위 테스트, 코드 품질 확인과 같은 작업이 포함됩니다. build.yaml 파일은 이러한 작업을 수행하는 데 필요한 도구, 스크립트 및 명령을 지정합니다. 예를 들어 코드 품질을 보장하기 위해 단위 테스트 실행을 트리거할 수 있습니다.
지속적 전달(CD)
성공적인 CI 후 CD 단계에는 준비 또는 프로덕션과 같은 다양한 환경에 애플리케이션을 배포하는 작업이 포함됩니다. build.yaml 파일은 배포 위치와 시기, 사용할 구성 등 배포 방법을 지정합니다.
의존성 관리
build.yaml 파일에는 프로젝트 종속성에 대한 세부정보가 포함되는 경우가 많습니다. 이는 외부 라이브러리나 종속성을 가져올 위치를 정의하며, 이는 애플리케이션의 성공적인 빌드 및 배포에 중요할 수 있습니다.
환경 변수
CI/CD 워크플로에는 API 키 또는 연결 문자열과 같은 환경별 구성이 필요한 경우가 많습니다. build.yaml 파일은 각 파이프라인 단계에 대해 이러한 환경 변수가 설정되는 방법을 정의할 수 있습니다.
알림 및 경고
CI/CD 프로세스 중에 오류나 문제가 발생하는 경우 알림 및 경고가 필수적입니다. build.yaml 파일은 이러한 경고를 보내는 방법과 대상을 구성하여 문제가 즉시 해결되도록 할 수 있습니다.
아티팩트 및 출력
CI/CD 워크플로에 따라 build.yaml 파일은 생성되어야 하는 아티팩트 또는 빌드 출력과 저장 위치를 지정할 수 있습니다. 이러한 아티팩트는 배포 또는 추가 테스트에 사용될 수 있습니다.
build.yaml 파일과 해당 구성 요소를 이해하면 프로젝트 요구 사항에 맞게 CI/CD 워크플로를 효과적으로 관리하고 사용자 지정할 수 있습니다. 이는 코드 변경부터 프로덕션 배포까지 전체 자동화 프로세스에 대한 청사진입니다.
CI/CD 파이프라인
build.yaml 구성의 특정 세부사항과 CI/CD 파이프라인에 맞는 방식을 기반으로 콘텐츠를 추가로 사용자 정의할 수 있습니다.
name: workflow on: push: branches: - main paths-ignore: - 'README.md' permissions: id-token: write contents: read jobs: integration: name: Continuous Integration runs-on: ubuntu-latest steps: - name: Checkout Code uses: actions/checkout@v3 - name: Lint code run: echo "Linting repository" - name: Run unit tests run: echo "Running unit tests" build-and-push-ecr-image: name: Continuous Delivery needs: integration runs-on: ubuntu-latest steps: - name: Checkout Code uses: actions/checkout@v3 - name: Install Utilities run: | sudo apt-get update sudo apt-get install -y jq unzip - name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ${{ secrets.AWS_REGION }} - name: Login to Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - name: Build, tag, and push image to Amazon ECR id: build-image env: ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} ECR_REPOSITORY: ${{ secrets.ECR_REPOSITORY_NAME }} IMAGE_TAG: latest run: | # Build a docker container and # push it to ECR so that it can # be deployed to ECS. docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG . docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG echo "::set-output name=image::$ECR_REGISTRY/$ECR_REPOSITORY :$IMAGE_TAG" Continuous-Deployment: needs: build-and-push-ecr-image runs-on: self-hosted steps: - name: Checkout uses: actions/checkout@v3 - name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ${{ secrets.AWS_REGION }} - name: Login to Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - name: Pull latest images run: | docker pull ${{secrets.AWS_ECR_LOGIN_URI}}/${{ secrets. ECR_REPOSITORY_NAME }}:latest - name: Stop and remove sensor container if running run: | docker ps -q --filter "name=sensor" | grep -q . && docker stop sensor && docker rm -fv sensor - name: Run Docker Image to serve users run: | docker run -d -p 80:8080 --name=sensor -e 'AWS_ACCESS_KEY_ID= ${{ secrets.AWS_ACCESS_KEY_ID }} ' -e 'AWS_SECRET_ACCESS_KEY=${{ secrets.AWS_SECRET_ACCESS_KEY }}' -e 'AWS_REGION=${{ secrets.AWS_REGION }}' ${{secrets.AWS_ECR_LOGIN_URI}}/ ${{ secrets.ECR_REPOSITORY_NAME }}:latest - name: Clean previous images and containers run: | docker system prune -f참고 : 모든 분할선은 하나로 결합
문제가 발생하면 마지막에 언급한 GitHub 저장소를 따르세요.
지속적 배포 작업:
- 이 작업은 "Build-and-Push-ECR-Image 작업"에 따라 달라지며 자체 호스팅 실행기에서 실행되도록 구성됩니다.
- 코드를 확인하고 AWS 자격 증명을 구성합니다.
- Amazon ECR에 로그인합니다.
- 지정된 ECR 저장소에서 최신 Docker 이미지를 가져옵니다.
- 실행 중인 경우 "sensor"라는 Docker 컨테이너를 중지하고 제거합니다.
- 지정된 설정, 환경 변수 및 앞서 가져온 Docker 이미지를 사용하여 "sensor"라는 Docker 컨테이너를 실행합니다.
- 마지막으로 docker system prune을 사용하여 이전 Docker 이미지와 컨테이너를 정리합니다.
코드 변경 시 워크플로 실행 자동화
전체 CI/CD 프로세스를 원활하게 만들고 코드 변경에 응답하도록 하려면 코드 커밋 또는 푸시 시 워크플로를 자동으로 트리거하도록 리포지토리를 구성할 수 있습니다. 저장소에 변경 사항을 저장하고 푸시할 때마다 CI/CD 파이프라인이 마법을 부리기 시작합니다.
워크플로 실행을 자동화하면 수동 개입 없이 애플리케이션이 최신 변경 사항으로 최신 상태를 유지할 수 있습니다. 이러한 자동화는 개발 효율성을 크게 향상시키고 코드 변경에 대한 신속한 피드백을 제공하므로 개발 주기 초기에 문제를 더 쉽게 파악하고 해결할 수 있습니다.
코드 변경 시 자동화된 워크플로 실행을 설정하려면 다음 단계를 따르세요.
git add . git commit -m "message" git push origin main결론
이 종합 가이드에서는 EC2 및 ECR을 사용하여 AWS에 PySpark를 배포하는 복잡한 프로세스를 안내했습니다. 컨테이너화와 지속적인 통합 및 전달을 활용하는 이 접근 방식은 대규모 데이터 분석 및 처리 작업을 관리하기 위한 강력하고 적응 가능한 솔루션을 제공합니다. 이 블로그에 설명된 단계를 따르면 클라우드 환경에서 PySpark의 모든 기능을 활용하고 AWS가 제공하는 확장성과 유연성을 활용할 수 있습니다.
AWS는 EC2 및 ECR부터 EMR과 같은 전문 서비스에 이르기까지 다양한 배포 옵션을 제공한다는 점에 유의하는 것이 중요합니다. 방법 선택은 궁극적으로 프로젝트의 고유한 요구 사항에 따라 달라집니다. 여기에 설명된 컨테이너화 접근 방식을 선호하든 다른 AWS 서비스를 선택하든, 핵심은 데이터 기반 애플리케이션에서 PySpark의 기능을 효과적으로 활용하는 것입니다. AWS를 플랫폼으로 사용하면 PySpark의 잠재력을 최대한 활용하여 데이터 분석 및 처리의 새로운 시대를 열 수 있습니다. AWS는 프로젝트의 고유한 요구 사항을 충족하기 위해 PySpark를 배포하기 위한 다양한 도구 키트를 제공하므로 EMR과 같은 서비스가 특정 사용 사례 및 기본 설정에 더 잘 맞는지 살펴보세요.
주요 요점
- Docker를 사용하여 AWS에 PySpark를 배포하면 빅 데이터 처리가 간소화되고 확장성과 자동화가 제공됩니다.
- GitHub Actions는 CI/CD 파이프라인을 단순화하여 원활한 코드 배포를 가능하게 합니다.
- EC2 및 ECR과 같은 AWS 서비스를 활용하면 강력한 PySpark 클러스터 관리가 보장됩니다.
- 이 튜토리얼에서는 데이터 집약적인 작업을 위해 클라우드 컴퓨팅의 성능을 활용할 수 있도록 준비합니다.
자주 묻는 질문
A. PySpark는 강력하고 광범위한 데이터 처리 프레임워크인 Apache Spark용 Python 라이브러리입니다. AWS에 PySpark를 배포하면 데이터 집약적인 작업을 위한 확장 가능하고 유연한 솔루션이 제공되므로 분산 데이터 분석에 이상적인 선택이 됩니다.
A. PySpark를 로컬로 실행할 수 있지만 대규모 데이터 세트를 효율적으로 처리하려면 클라우드 배포를 권장합니다. AWS는 PySpark 애플리케이션 확장에 필요한 인프라와 도구를 제공합니다.
A. GitHub Secrets를 사용하여 AWS 자격 증명을 저장하고 워크플로에서 안전하게 액세스하십시오. 이렇게 하면 자격 증명이 보호된 상태로 유지되고 코드에 노출되지 않습니다.
A. Docker 컨테이너는 다양한 플랫폼에서 일관된 환경을 제공하여 PySpark 애플리케이션이 개발, 테스트 및 프로덕션에서 동일한 방식으로 실행되도록 보장합니다. 또한 PySpark 애플리케이션 구축 및 배포 프로세스를 단순화합니다.
AWS에서 PySpark를 실행하는 비용은 사용된 EC2 인스턴스의 유형 및 수, 데이터 스토리지, 데이터 전송 등을 포함한 다양한 요소에 따라 달라집니다. 비용을 효율적으로 관리하려면 AWS 사용량을 모니터링하고 리소스를 최적화하는 것이 필수적입니다.
추가 학습을 위한 리소스
- GitHub 저장소: 이 튜토리얼에서 사용된 전체 소스 코드와 구성에 액세스하려면 소비자 불만 분쟁 예측 GitHub 저장소.
- 도커 문서: Docker와 컨테이너화에 대해 자세히 알아보세요. 공식 Docker 설명서. Docker를 마스터하기 위한 포괄적인 가이드, 모범 사례 및 팁을 찾을 수 있습니다.
- GitHub 작업 문서: 다음을 참조하여 GitHub Actions의 모든 기능을 활용해 보세요. GitHub Actions 문서. 이 리소스는 워크플로를 생성, 사용자 정의 및 자동화하는 데 도움이 됩니다.
- PySpark 공식 문서: PySpark에 대한 심층적인 지식을 얻으려면 다음을 탐색해 보세요. 공식 PySpark 문서. 빅데이터 처리를 위한 API, 함수, 라이브러리에 대해 알아보세요.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/11/what-are-the-best-practices-for-deploying-pyspark-on-aws/

