개요
이 기사에서는 Image Semantic Segmentation의 컴퓨터 비전 기술을 살펴보겠습니다. 복잡해 보이지만 단계별로 분석하고 Hugging Face 컬렉션의 DPT(Dense Prediction Transformer)를 사용하여 구현한 이미지 의미론적 분할이라는 흥미로운 개념을 소개하겠습니다. DPT를 사용하면 새로운 단계가 도입됩니다. 컴퓨터 비전 특이한 능력을 가진.
학습 목표
- DPT와 원거리 연결에 대한 기존 이해의 비교.
- Python에서 DPT를 사용하여 깊이 예측을 통해 의미론적 분할을 구현합니다.
- DPT 디자인을 살펴보고 고유한 특성을 이해하세요.
이 기사는 데이터 과학 블로그.
차례
이미지 의미론적 분할이란 무엇입니까?
이미지가 있고 그것이 나타내는 내용에 따라 그 안에 있는 모든 픽셀에 레이블을 지정하고 싶다고 상상해 보십시오. 이것이 이미지 의미론적 분할의 기본 아이디어입니다. 컴퓨터 비전에 사용될 수 있으며, 자동차와 나무를 구별하거나 이미지의 일부를 분리할 수 있습니다. 이것은 스마트하게 픽셀에 라벨을 붙이는 것에 관한 것입니다. 그러나 실제 과제는 개체 간의 컨텍스트와 관계를 이해하는 데 있습니다. 이를 이미지 처리에 대한 기존 접근 방식과 비교해 보겠습니다.
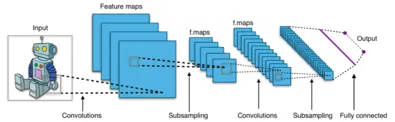
컨볼 루션 신경망 (CNN)
첫 번째 혁신은 다음을 사용하는 것이었습니다. 컨볼 루션 신경망 이미지와 관련된 작업을 처리합니다. 그러나 CNN에는 특히 이미지에서 장거리 연결을 캡처하는 데 한계가 있습니다. 이미지의 다양한 요소가 장거리에서 어떻게 서로 상호 작용하는지 이해하려고 한다고 상상해 보십시오. 이것이 바로 전통적인 CNN이 어려움을 겪는 부분입니다. 이곳은 우리가 DPT를 축하하는 곳입니다. 강력한 변환기 아키텍처에 기반을 둔 이러한 모델은 연관성을 포착하는 기능을 보여줍니다. 다음에는 DPT를 살펴보겠습니다.
DPT(밀집 예측 변환기)란 무엇입니까?
이 개념을 이해하려면 우리가 예전에 알고 있던 Transformers의 힘을 결합한다고 상상해보십시오. NLP 이미지 분석 작업. 이것이 바로 Dense Prediction Transformers의 개념입니다. 그들은 이미지 세계의 슈퍼 탐정과 같습니다. 이미지의 픽셀에 라벨을 붙일 뿐만 아니라 각 픽셀의 깊이를 예측하는 기능도 있습니다. 이는 각 개체가 이미지에서 얼마나 멀리 떨어져 있는지에 대한 정보를 제공합니다. 우리는 이것을 아래에서 볼 것입니다.
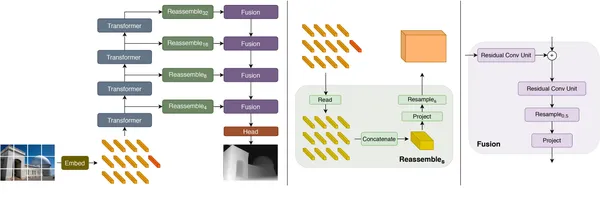
DPT 아키텍처의 도구 상자
DPT는 각각 "인코더" 및 "디코더" 레이어를 포함하는 다양한 유형으로 제공됩니다. 여기서 인기 있는 두 가지를 살펴보겠습니다.
- DPT-스윈-변압기: 10개의 인코더 레이어와 5개의 디코더 레이어가 있는 메가 트랜스포머를 생각해 보세요. 이미지 수준의 요소 간 관계를 이해하는 데 탁월합니다.
- DPT-ResNet: 이것은 18개의 인코더 레이어와 5개의 디코더 레이어를 가진 영리한 탐정과 같습니다. 이미지의 공간 구조를 그대로 유지하면서 멀리 있는 물체 사이의 연결을 찾아내는 데 탁월합니다.
주요 특징들
다음은 몇 가지 주요 기능을 사용하여 DPT가 작동하는 방식을 자세히 살펴보겠습니다.
- 계층적 특징 추출: 기존 CNN(Convolutional Neural Networks)과 마찬가지로 DPT는 입력 이미지에서 특징을 추출합니다. 그러나 이미지가 다양한 세부 수준으로 구분되는 계층적 접근 방식을 따릅니다. 로컬 및 글로벌 컨텍스트를 모두 캡처하는 데 도움이 되는 것이 바로 이 계층 구조이며, 이를 통해 모델은 다양한 규모의 개체 간의 관계를 이해할 수 있습니다.
- 자기 주의 메커니즘: 이는 모델이 이미지 내의 장거리 종속성을 캡처하고 픽셀 간의 복잡한 관계를 학습할 수 있도록 하는 원래 Transformer 아키텍처에서 영감을 얻은 DPT의 백본입니다. 각 픽셀은 다른 모든 픽셀의 정보를 고려하여 모델이 이미지에 대한 전체적인 이해를 제공합니다.
DPT를 사용한 이미지 의미론적 분할의 Python 데모
아래에서 DPT 구현을 살펴보겠습니다. 먼저 Colab에 사전 설치되지 않은 라이브러리를 설치하여 환경을 설정해 보겠습니다. 이에 대한 코드를 찾을 수 있습니다 여기에서 지금 확인해 보세요. 또는에서 https://github.com/inuwamobarak/semantic-segmentation
먼저 환경을 설치하고 설정합니다.
!pip install -q git+https://github.com/huggingface/transformers.git다음으로, 훈련하려는 모델을 준비합니다.
## Define model # Import the DPTForSemanticSegmentation from the Transformers library
from transformers import DPTForSemanticSegmentation # Create the DPTForSemanticSegmentation model and load the pre-trained weights
# The "Intel/dpt-large-ade" model is a large-scale model trained on the ADE20K dataset
model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")이제 분할에 사용할 이미지를 로드하고 준비합니다.
# Import the Image class from the PIL (Python Imaging Library) module
from PIL import Image import requests # URL of the image to be downloaded
url = 'https://img.freepik.com/free-photo/happy-lady-hugging-her-white-friendly-dog-while-walking-park_171337-19281.jpg?w=740&t=st=1689214254~exp=1689214854~hmac=a8de6eb251268aec16ed61da3f0ffb02a6137935a571a4a0eabfc959536b03dd' # The `stream=True` parameter ensures that the response is not immediately downloaded, but is kept in memory
response = requests.get(url, stream=True) # Create the Image class
image = Image.open(response.raw) # Display image
image
from torchvision.transforms import Compose, Resize, ToTensor, Normalize # Set the desired height and width for the input image
net_h = net_w = 480 # Define a series of image transformations
transform = Compose([ # Resize the image Resize((net_h, net_w)), # Convert the image to a PyTorch tensor ToTensor(), # Normalize the image Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]), ])여기에서 다음 단계는 이미지에 일부 변형을 적용하는 것입니다.
# Transform input image
pixel_values = transform(image) pixel_values = pixel_values.unsqueeze(0)다음은 포워드 패스입니다.
import torch # Disable gradient computation
with torch.no_grad(): # Perform a forward pass through the model outputs = model(pixel_values) # Obtain the logits (raw predictions) from the output logits = outputs.logits이제 이미지를 배열 묶음으로 인쇄합니다. 이를 의미론적 예측을 통해 이미지 옆으로 변환하겠습니다.
import torch # Interpolate the logits to the original image size
prediction = torch.nn.functional.interpolate( logits, size=image.size[::-1], # Reverse the size of the original image (width, height) mode="bicubic", align_corners=False
) # Convert logits to class predictions
prediction = torch.argmax(prediction, dim=1) + 1 # Squeeze the prediction tensor to remove dimensions
prediction = prediction.squeeze() # Move the prediction tensor to the CPU and convert it to a numpy array
prediction = prediction.cpu().numpy()이제 의미론적 예측을 수행합니다.
from PIL import Image # Convert the prediction array to an image
predicted_seg = Image.fromarray(prediction.squeeze().astype('uint8')) # Apply the color map to the predicted segmentation image
predicted_seg.putpalette(adepallete) # Blend the original image and the predicted segmentation image
out = Image.blend(image, predicted_seg.convert("RGB"), alpha=0.5)
거기에는 의미론이 예측되는 이미지가 있습니다. 자신만의 이미지로 실험해 볼 수 있습니다. 이제 DPT에 적용된 몇 가지 평가를 살펴보겠습니다.
DPT에 대한 성능 평가
DPT는 다양한 연구 작업과 논문에서 테스트되었으며 Cityscapes, PASCAL VOC 및 ADE20K 데이터세트와 같은 다양한 이미지 플레이그라운드에서 사용되었으며 기존 CNN 모델보다 성능이 뛰어납니다. 이 데이터 세트 및 연구 논문에 대한 링크는 아래 링크 섹션에 있습니다.
Cityscapes에서 DPT-Swin-Transformer는 mIoU(평균 교차점) 지표에서 79.1%를 기록했습니다. PASCAL VOC에서 DPT-ResNet은 새로운 벤치마크인 82.8%의 mIoU를 달성했습니다. 이 점수는 이미지를 깊이 있게 이해하는 DPT의 능력을 입증합니다.
DPT의 미래와 앞으로 다가올 일
DPT는 이미지 이해의 새로운 시대입니다. DPT에 대한 연구는 우리가 이미지를 보고 상호 작용하는 방식을 변화시키고 새로운 가능성을 가져오고 있습니다. 간단히 말해서, DPT를 사용한 이미지 의미론적 분할은 이미지를 디코딩하는 방식을 변화시키는 획기적인 기술이며 앞으로 더 많은 일을 할 것입니다. 픽셀 레이블부터 깊이 이해까지 DPT는 컴퓨터 비전 세계에서 가능한 것입니다. 좀 더 자세히 살펴보겠습니다.
정확한 깊이 추정
DPT의 가장 중요한 기여 중 하나는 이미지에서 깊이 정보를 예측하는 것입니다. 이러한 발전에는 3D 장면 재구성, 증강 현실 및 객체 조작과 같은 응용 프로그램이 있습니다. 이는 장면 내 객체의 공간적 배열에 대한 중요한 이해를 제공합니다.
동시 의미론적 분할 및 깊이 예측
DPT는 통합 프레임워크에서 의미론적 분할과 깊이 예측을 모두 제공할 수 있습니다. 이를 통해 이미지에 대한 전체적인 이해가 가능해지며 의미론적 정보와 깊이 있는 지식 모두에 대한 응용이 가능해집니다. 예를 들어 자율주행에서 이 조합은 안전한 탐색에 필수적입니다.
데이터 수집 노력 감소
DPT는 깊이 데이터에 대한 광범위한 수동 라벨링의 필요성을 완화할 수 있는 잠재력을 가지고 있습니다. 깊이 맵이 포함된 훈련 이미지는 픽셀별 깊이 주석 없이도 깊이를 예측하는 방법을 학습할 수 있습니다. 이는 데이터 수집과 관련된 비용과 노력을 크게 줄여줍니다.
장면 이해
이를 통해 기계는 로봇이 효과적으로 탐색하고 상호 작용하는 데 중요한 XNUMX차원 환경을 이해할 수 있습니다. 제조 및 물류와 같은 산업에서 DPT는 로봇이 공간 관계를 더 깊이 이해하여 물체를 조작할 수 있도록 함으로써 자동화를 촉진할 수 있습니다.
Dense Prediction Transformers는 이미지의 의미론적 이해와 함께 정확한 깊이 정보를 제공하여 컴퓨터 비전 분야를 재편하고 있습니다. 그러나 세밀한 깊이 추정, 일반화, 불확실성 추정, 편향 완화 및 실시간 최적화와 관련된 문제를 해결하는 것은 미래에 DPT의 혁신적인 영향을 완전히 실현하는 데 필수적입니다.
결론
Dense Prediction Transformers를 사용한 이미지 의미론적 분할은 픽셀 라벨링과 공간 통찰력을 혼합하는 여정입니다. DPT와 이미지 의미론적 분할의 결합은 컴퓨터 비전 연구에 흥미로운 길을 열어줍니다. 이 기사에서는 아키텍처부터 성능, 컴퓨터 비전의 의미론적 분할의 미래를 재구성할 유망한 잠재력에 이르기까지 DPT의 근본적인 복잡성을 밝히려고 노력했습니다.
주요 요점
- DPT는 픽셀을 넘어 공간적 맥락을 이해하고 깊이를 예측합니다.
- DPT는 거리와 3D 통찰력을 캡처하는 기존 이미지 인식보다 성능이 뛰어납니다.
- DPT는 인식하는 이미지를 재정의하여 사물과 관계에 대한 더 깊은 이해를 가능하게 합니다.
자주 묻는 질문
A1: DPT는 주로 이미지 분석을 위해 설계되었지만 기본 원칙은 다른 형태의 데이터에 대한 적응에 영감을 줄 수 있습니다. 변환기를 통해 컨텍스트와 관계를 캡처한다는 아이디어는 도메인에 잠재적으로 적용할 수 있습니다.
A2: DPT는 가상 환경에서 보다 정확한 개체 순서 지정 및 상호 작용을 통해 증강 현실의 잠재력을 보유하고 있습니다.
A3: CNN과 같은 전통적인 이미지 인식 방법은 맥락이나 공간 레이아웃을 완전히 파악하지 않고 이미지의 개체에 라벨을 지정하는 데 중점을 두지만 DPT 모델은 개체를 식별하고 깊이를 예측하여 이를 더욱 발전시킵니다.
A4: 응용 프로그램은 광범위합니다. 자동차가 복잡한 환경을 이해하고 탐색할 수 있도록 지원하여 자율 주행을 향상할 수 있습니다. 정확하고 세밀한 분석을 통해 의료영상 촬영을 진행할 수 있습니다. 그 외에도 DPT는 로봇 공학의 객체 인식을 향상시키고, 사진의 장면 이해를 향상시키며, 심지어 증강 현실 경험에도 도움을 줄 수 있는 잠재력을 가지고 있습니다.
A5: 예, DPT 아키텍처에는 다양한 유형이 있습니다. 두 가지 중요한 예로는 DPT-Swin-Transformer와 DPT-ResNet이 있습니다. 여기서 DPT-Swin-Transformer는 다양한 수준에서 이미지 요소 간의 관계를 이해할 수 있는 계층적 주의 메커니즘을 가지고 있습니다. 그리고 DPT-ResNet은 잔여 주의 메커니즘을 통합하여 이미지의 공간 구조를 보존하면서 장거리 종속성을 캡처합니다.
모래밭:
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/09/image-semantic-segmentation-using-dense-prediction-transformers/

