데이터 과학 인터뷰는 깊이가 다양합니다. 일부 인터뷰는 정말 깊이 들어가고 고급 모델 또는 까다로운 미세 조정에 대한 지식에 대해 후보자를 테스트합니다. 그러나 많은 인터뷰는 후보자의 기본 지식을 테스트하기 위해 엔트리 레벨에서 수행됩니다. 이 기사에서는 그러한 인터뷰에서 논의할 수 있는 질문을 보게 될 것입니다. 질문은 매우 간단하지만 논의는 기계 학습의 기초에 대한 많은 흥미로운 측면을 제시합니다.
질문: 선형 회귀와 로지스틱 회귀의 차이점은 무엇입니까?
이름이 매우 비슷하게 들리는 사실부터 시작하여 둘 사이에는 실제로 많은 유사점이 있습니다. 둘 다 모델 기능으로 선을 사용합니다. 그래프도 매우 비슷해 보입니다.
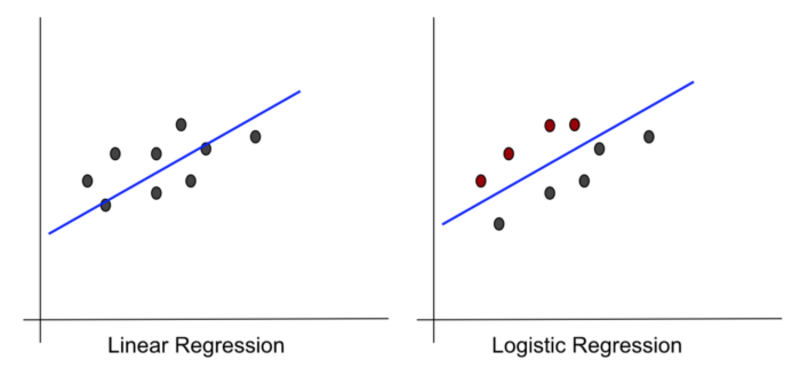
작성자 별 이미지
그러나 이러한 유사성에도 불구하고 방법과 적용면에서 매우 다릅니다. 이제 이러한 차이점을 강조하겠습니다. 비교를 위해 기계 학습 모델을 논의할 때 일반적으로 고려되는 다음 사항을 사용합니다.
- 가설 또는 모델 패밀리
- 입력 및 출력
- 손실 기능
- 최적화 기술
- 어플리케이션
이제 이러한 각 지점에서 선형 회귀(LinReg)와 로지스틱 회귀(LogReg)를 비교할 것입니다. 올바른 방향으로 토론을 진행하기 위해 응용 프로그램부터 시작하겠습니다.

작성자 별 이미지
선형 회귀는 다른 수량을 기반으로 수량을 추정하는 데 사용됩니다. 예를 들어 학생으로서 여름 방학 동안 레모네이드 가판대를 운영한다고 상상해 보십시오. 당신은 충분한 양의 레몬과 설탕을 살 수 있도록 내일 몇 잔의 레모네이드가 팔릴지 알고 싶습니다. 레모네이드 판매에 대한 오랜 경험을 통해 판매가 하루의 최고 온도와 강한 관계가 있음을 알아냈습니다. 따라서 예상 최대 온도를 사용하여 레모네이드 판매를 예측하려고 합니다. 이것은 일반적으로 ML 문헌에서 예측이라고 하는 고전적인 LinReg 애플리케이션입니다.
LinReg는 또한 특정 입력이 출력에 어떤 영향을 미치는지 알아내는 데 사용됩니다. 레모네이드 노점의 예에서 최대 온도와 해당 날짜가 휴일인지 여부라는 두 가지 입력이 있다고 가정합니다. 최대 온도 또는 휴일 중 판매에 더 많은 영향을 미치는 것이 무엇인지 알고 싶습니다. LinReg는 이를 식별하는 데 유용합니다.
LogReg는 주로 분류에 사용됩니다. 분류는 입력을 가능한 많은 바스켓 중 하나로 분류하는 작업입니다. 분류는 인간 지능의 핵심이므로 '지능의 대부분은 분류'라고 해도 과언이 아닙니다. 분류의 좋은 예는 임상 진단입니다. 믿을 수 있는 연로한 가정의를 생각해 보십시오. 한 여성이 들어와 끊임없는 기침을 호소합니다. 의사는 가능한 많은 조건 중에서 결정하기 위해 다양한 검사를 실시합니다. 인후 감염과 같은 일부 가능한 조건은 상대적으로 무해합니다. 그러나 일부는 결핵이나 심지어 폐암과 같은 심각한 질병입니다. 다양한 요인에 따라 의사는 그녀가 겪고 있는 것이 무엇인지 결정하고 적절한 치료를 시작합니다. 이것은 직장에서의 분류입니다.
추정과 분류는 모두 계산이 아니라 추측 작업이라는 점을 명심해야 합니다. 이러한 유형의 작업에는 정확하거나 정답이 없습니다. 추측 작업은 기계 학습 시스템이 잘하는 것입니다.
ML 시스템은 패턴을 감지하여 추측 문제를 해결합니다. 그들은 주어진 데이터에서 패턴을 감지하고 추정이나 분류와 같은 작업을 수행하는 데 사용합니다. 자연 현상에서 발견되는 중요한 패턴은 관계 패턴입니다. 이 패턴에서 한 수량은 다른 수량과 관련됩니다. 이 관계는 대부분의 경우 수학 함수로 근사화할 수 있습니다.
주어진 데이터에서 수학 함수를 식별하는 것을 '학습' 또는 '훈련'이라고 합니다. 학습에는 두 단계가 있습니다.
- 함수의 '유형'(예: 선형, 지수, 다항식)은 사람이 선택합니다.
- 학습 알고리즘은 주어진 데이터에서 매개변수(예: 선의 기울기 및 절편)를 학습합니다.
따라서 ML 시스템이 데이터에서 학습한다고 말할 때 그것은 부분적으로만 사실입니다. 기능 유형을 선택하는 첫 번째 단계는 수동이며 모델 설계의 일부입니다. 함수의 종류를 '가설' 또는 '모델군'이라고도 합니다.
LinReg와 LogReg 모두에서 모델군은 선형 함수입니다. 아시다시피 직선에는 기울기와 절편이라는 두 가지 매개변수가 있습니다. 그러나 이것은 함수가 하나의 입력만 받는 경우에만 해당됩니다. 대부분의 실제 문제에는 하나 이상의 입력이 있습니다. 이러한 경우에 대한 모델 함수를 선이 아닌 선형 함수라고 합니다. 선형 함수에는 학습해야 할 매개변수가 더 많습니다. 모델에 n개의 입력이 있는 경우 선형 함수에는 n+1개의 매개변수가 있습니다. 언급한 바와 같이 이러한 매개변수는 주어진 데이터에서 학습됩니다. 이 기사의 목적을 위해 계속해서 함수가 두 개의 매개변수가 있는 간단한 라인이라고 가정합니다. LogReg의 모델 함수는 조금 더 복잡합니다. 선이 있지만 다른 기능과 결합됩니다. 우리는 이것을 잠시 후에 보게 될 것입니다.
위에서 말했듯이 LinReg와 LogReg는 훈련 데이터라고 하는 주어진 데이터에서 선형 함수의 매개변수를 학습합니다. 학습 데이터에는 무엇이 포함되어 있습니까?
학습 데이터는 일부 RWP(실제 현상)를 기록하여 준비됩니다. 예를 들어, 낮 최고 기온과 레모네이드 판매 사이의 관계는 RWP입니다. 기본 관계에 대한 가시성이 없습니다. 우리가 볼 수 있는 것은 매일 온도와 판매의 값입니다. 관찰을 기록하는 동안 일부 수량을 RWP의 입력으로 지정하고 나머지는 출력으로 지정합니다. 레모네이드 예에서 우리는 최대 온도를 입력으로, 레모네이드 판매를 출력으로 부릅니다.

작성자 별 이미지
훈련 데이터에는 입력과 출력 쌍이 포함되어 있습니다. 이 예에서 데이터에는 일일 최고 온도 행과 판매된 레모네이드 잔이 있습니다. LinReg에 대한 입력 및 출력이 됩니다.
LogReg가 수행하는 작업은 분류이므로 출력은 클래스여야 합니다. 0과 1이라는 두 개의 클래스가 있다고 가정해 보겠습니다. 그러면 모델의 출력도 0 또는 1이어야 합니다.
그러나 출력을 지정하는 이 방법은 그다지 적합하지 않습니다. 다음 다이어그램을 참조하십시오.
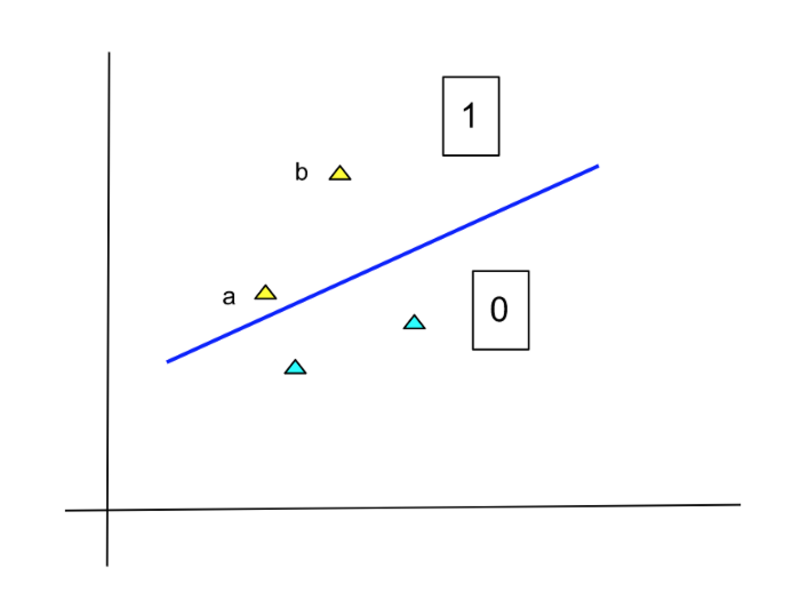
작성자 별 이미지
노란색 점은 클래스 1에 속하고 하늘색 점은 0에 속합니다. 선은 두 클래스를 구분하는 모델 함수입니다. 이 구분 기호에 따르면 노란색 점(a 및 b)은 모두 클래스 1에 속합니다. 그러나 지점 b의 구성원은 지점 a보다 훨씬 더 확실합니다. 모델이 단순히 0과 1을 출력하면 이 사실이 손실됩니다.
이 상황을 수정하기 위해 LogReg 모델은 특정 클래스에 속하는 각 포인트의 확률을 생성합니다. 위의 예에서 클래스 1에 속하는 'a' 지점의 확률은 낮고 'b' 지점의 확률은 높습니다. 확률은 0과 1 사이의 숫자이므로 LogReg의 출력도 마찬가지입니다.
이제 다음 다이어그램을 참조하십시오.
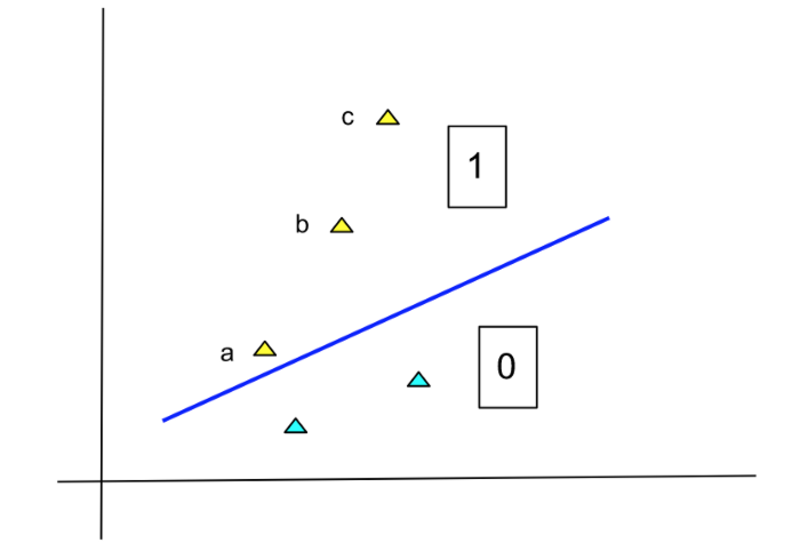
작성자 별 이미지
이 다이어그램은 점 c가 추가된 이전 다이어그램과 동일합니다. 이 점 또한 클래스 1에 속하며 사실 b점보다 더 확실합니다. 그러나 선으로부터의 거리에 비례하여 점의 확률을 높이는 것은 잘못된 것입니다. 직관적으로 선에서 일정 거리를 벗어나면 해당 지점의 구성원에 대해 어느 정도 확신할 수 있습니다. 확률을 더 높일 필요는 없습니다. 이는 최대값이 1이 될 수 있는 확률의 특성과 일치합니다.
LogReg 모델이 이러한 출력을 생성할 수 있으려면 라인 함수가 다른 함수에 연결되어야 합니다. 이 두 번째 함수는 시그모이드라고 하며 방정식은 다음과 같습니다.
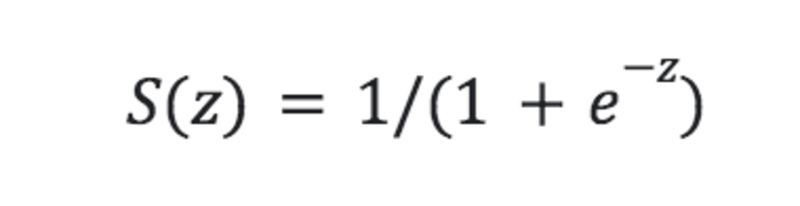
작성자 별 이미지
따라서 LogReg 모델은 다음과 같습니다.
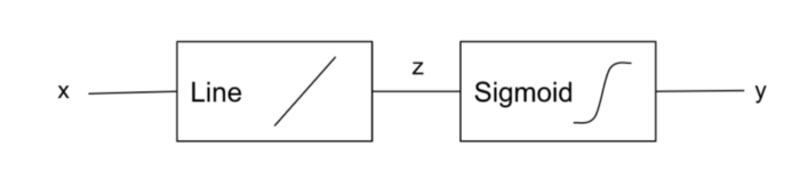
작성자 별 이미지
시그모이드 함수는 '로지스틱'이라고도 하며 '로지스틱 회귀'라는 이름이 붙은 이유입니다.
세 개 이상의 클래스가 있는 경우 LogReg의 출력은 벡터입니다. 출력 벡터의 요소는 입력이 특정 클래스일 확률입니다. 예를 들어, 임상 진단 모델의 첫 번째 요소의 값이 0.8이면 모델이 환자가 감기에 걸릴 확률이 80%라고 생각한다는 의미입니다.
우리는 LinReg와 LogReg 모두 훈련 데이터에서 선형 함수의 매개변수를 학습하는 것을 보았습니다. 이러한 매개 변수를 어떻게 학습합니까?
그들은 '최적화'라는 방법을 사용합니다. 최적화는 주어진 문제에 대해 가능한 많은 솔루션을 생성하여 작동합니다. 우리의 경우 가능한 솔루션은 (기울기, 절편) 값의 집합입니다. 성능 측정을 사용하여 이러한 각 솔루션을 평가합니다. 이 척도에서 최고로 입증된 솔루션이 최종적으로 선택됩니다.
ML 모델 학습에서 성능 측정을 '손실'이라고 부르기도 하며 이를 계산하는 데 도움이 되는 함수를 '손실 함수'라고 합니다. 우리는 이것을 다음과 같이 나타낼 수 있습니다:
Loss = Loss_Function (Parameters_being_evaluated)'손실'과 '손실 함수'라는 용어는 부정적인 의미를 내포하고 있습니다. 즉, 손실 값이 낮을수록 더 나은 솔루션을 나타냅니다. 즉, 학습은 손실을 최소화하는 매개변수를 찾는 것을 목표로 하는 최적화입니다.
이제 LinReg 및 LogReg를 최적화하는 데 사용되는 일반적인 손실 함수를 볼 수 있습니다. 실제로는 다양한 손실 함수가 사용되므로 가장 일반적인 손실 함수에 대해 논의할 수 있습니다.
LinReg 매개변수의 최적화를 위해 가장 일반적인 손실 함수는 SSE(Sum of Squares Error)라고 합니다. 이 함수는 다음 입력을 받습니다.
1) 모든 훈련 데이터 포인트. 각 포인트에 대해 다음을 지정합니다.
a) 최대 데이터 온도와 같은 입력,
b) 판매된 레모네이드 잔의 수와 같은 산출량
2) 매개변수가 있는 선형 방정식
그런 다음 함수는 다음 공식을 사용하여 손실을 계산합니다.
SSE Loss = Sum_for_all_points(
Square_of(
output_of_linear_equation_for_the_inputs — actual_output_from_the_data point
))LogReg에 대한 최적화 측정은 매우 다른 방식으로 정의됩니다. SSE 함수에서 다음 질문을 합니다.
If we use this line for fitting the training data, how much error will it make?LogReg 최적화를 위한 측정을 설계할 때 다음 사항을 묻습니다.
If this line is the separator, how likely is it that we will get the distribution of classes that is seen in the training data?따라서 이 척도의 출력은 우도입니다. 측정 함수의 수학적 형식은 로그를 사용하므로 로그 우도(LL)라는 이름을 부여합니다. 출력에 대해 논의하는 동안 LogReg 함수에 지수 항(e가 z로 '올려진' 항)이 포함됨을 확인했습니다. 대수는 이러한 지수를 효과적으로 처리하는 데 도움이 됩니다.
최적화가 LL을 최대화해야 한다는 것이 직관적으로 명확해야 합니다. 다음과 같이 생각하십시오. 훈련 데이터를 가장 가능성 있게 만드는 선을 찾고 싶습니다. 그러나 실제로는 최소화할 수 있는 측정을 선호하므로 LL의 음수를 취합니다. 따라서 우리는 NLL(Negative Log Likelihood) 손실 함수를 얻습니다. 하지만 저에 따르면 이를 손실 함수라고 부르는 것은 그다지 정확하지 않습니다.
따라서 LinReg에 대한 SSE와 LogReg에 대한 NLL의 두 가지 손실 함수가 있습니다. 이러한 손실 함수에는 많은 이름이 있으므로 해당 용어를 숙지해야 합니다.
선형 회귀와 로지스틱 회귀는 모양과 소리가 매우 유사하지만 실제로는 상당히 다릅니다. LinReg는 추정/예측에 사용되고 LogReg는 분류에 사용됩니다. 둘 다 기본으로 선형 함수를 사용하는 것은 사실이지만 LogReg는 로지스틱 함수를 더 추가합니다. 훈련 데이터를 소비하고 모델 출력을 생성하는 방식이 다릅니다. 둘은 또한 매우 다른 손실 함수를 사용합니다.
자세한 내용은 조사할 수 있습니다. 왜 SSE인가? 가능성은 어떻게 계산됩니까? 여기서는 더 많은 수학을 피하기 위해 최적화 방법을 사용하지 않았습니다. 그러나 LogReg의 최적화에는 일반적으로 반복 경사 하강법이 필요한 반면 LinReg는 일반적으로 빠른 폐쇄형 솔루션으로 수행할 수 있다는 점을 명심해야 합니다. 다른 기사에서 이러한 점과 더 많은 점에 대해 논의할 수 있습니다.
데베시 라자드히악스 지난 XNUMX년 동안 인공 지능 분야에서 일해 왔습니다. Cere Labs는 AI의 다양한 측면을 연구하기 위해 그가 설립한 회사입니다. Cere Labs는 Deep Learning, Machine Learning 및 Cognitive Computing을 기반으로 Cerescope라는 AI 플랫폼을 만들었습니다. 이 플랫폼은 금융 서비스, 의료, 소매, 제조 등을 위한 솔루션을 구축하는 데 사용되었습니다.
실물. 허가를 받아 다시 게시했습니다.
- 코인스마트. 유럽 최고의 비트코인 및 암호화폐 거래소.Click Here
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2022/11/comparing-linear-logistic-regression.html?utm_source=rss&utm_medium=rss&utm_campaign=comparing-linear-and-logistic-regression

