개요
의 세계에서 인공 지능, 기계가 기존 지식을 기반으로 구축하고 전문 지식을 통해 새로운 과제를 해결할 수 있도록 하는 학습 기술을 상상해 보세요. 이 독특한 기술을 전이 학습이라고 합니다. 최근 몇 년 동안 생성 모델의 기능과 응용 분야가 확장되는 것을 목격했습니다. 전이 학습을 사용하여 생성 모델 교육을 단순화할 수 있습니다. 다양한 예술 형식을 익힌 숙련된 예술가가 자신의 다양한 기술을 활용하여 손쉽게 걸작을 창조할 수 있다고 상상해 보십시오. 마찬가지로, 전이 학습은 기계가 한 영역에서 획득한 지식을 사용하여 다른 영역에서 뛰어난 성능을 발휘할 수 있도록 해줍니다. 지식을 전달하는 이 환상적이고 놀라운 능력은 인공지능에 무한한 가능성의 세계를 열어주었습니다.
학습 목표
이 기사에서 우리는
- 전이 학습의 개념에 대한 통찰력을 얻고 이것이 기계 학습 세계에서 제공하는 이점을 알아보세요.
- 또한 전이학습이 효과적으로 활용되는 다양한 실제 응용 사례를 살펴보겠습니다.
- 그런 다음 가위바위보 손동작을 분류하기 위한 모델을 구축하는 단계별 프로세스를 이해합니다.
- 모델을 효과적으로 훈련하고 테스트하기 위해 전이 학습 기술을 적용하는 방법을 알아보세요.
이 기사는 데이터 과학 Blogathon.
차례
전학 학습
어렸을 때 처음으로 자전거 타는 법을 열심히 배우고 싶다고 상상해 보세요. 균형을 유지하고 배우는 것이 어려울 것입니다. 그 때에는 처음부터 모든 것을 배워야 합니다. 균형을 유지하고, 핸들을 잡고, 브레이크를 사용하는 등 모든 것이 가장 좋을 것입니다. 많은 시간이 걸리며 여러 번의 실패한 시도 끝에 마침내 모든 것을 배우게 될 것입니다.
마찬가지로, 오토바이를 배우고 싶다면 지금 상상해보세요. 이 경우 어린 시절처럼 처음부터 모든 것을 배울 필요는 없습니다. 이제 당신은 이미 많은 것을 알고 있습니다. 균형을 유지하는 방법, 핸들을 조종하는 방법, 브레이크를 사용하는 방법과 같은 몇 가지 기술을 이미 갖추고 있습니다. 이제 이 모든 기술을 전수하고 기어 사용과 같은 추가 기술을 배워야 합니다. 훨씬 쉽게 만들고 배우는 데 시간이 덜 걸립니다. 이제 기술적인 관점에서 전이학습을 이해해 보겠습니다.
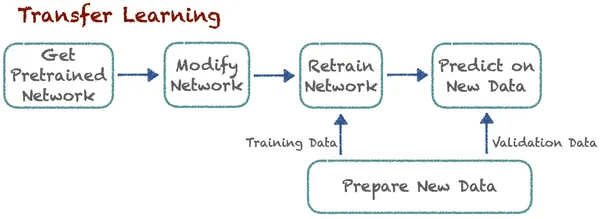
전이 학습은 전문가가 이미 발견한 관련 수업의 지식을 전이하여 새로운 작업의 학습을 향상시킵니다. 이 기술을 사용하면 알고리즘이 사전 훈련된 모델을 사용하여 새 작업을 기억할 수 있습니다. 고양이와 개를 분류하는 알고리즘이 있다고 가정해 보겠습니다. 이제 전문가들은 자동차와 트럭을 분류하기 위해 약간의 수정을 가한 동일한 사전 학습 모델을 사용합니다. 여기서의 기본 아이디어는 분류입니다. 여기서 새로운 작업을 학습하는 것은 이전에 알려진 교훈에 의존합니다. 알고리즘은 이전에 학습된 지식을 저장하고 액세스할 수 있습니다.
전이 학습의 이점
- 더 빠른 학습: 모델이 처음부터 학습하는 것이 아니기 때문에 새로운 작업을 학습하는 데 시간이 거의 걸리지 않습니다. 사전 훈련된 지식을 사용하여 훈련 시간과 계산 리소스를 크게 줄입니다. 모델은 먼저 시작해야 합니다. 이런 식으로 학습 속도가 빨라지는 이점이 있습니다.
- 향상된 성능 : 전이 학습을 사용하는 모델은 특히 처음부터 모든 것을 학습하는 모델에 비해 관련 작업에 대해 사전 훈련된 모델을 미세 조정할 때 더 나은 성능을 달성합니다. 이로 인해 정확성과 효율성이 높아졌습니다.
- 데이터 효율성: 우리는 딥러닝 모델을 훈련하려면 많은 데이터가 필요하다는 것을 알고 있습니다. 그러나 전이 학습 모델은 소스 도메인에서 지식을 상속하므로 더 작은 데이터 세트가 필요합니다. 따라서 대량의 레이블이 지정된 데이터에 대한 필요성이 줄어듭니다.
- 자원 절약: 대규모 모델을 처음부터 구축하고 유지 관리하는 것은 리소스 집약적일 수 있습니다. 전이 학습을 통해 조직은 기존 리소스를 효과적으로 활용할 수 있습니다. 그리고 훈련할 충분한 데이터를 얻기 위해 많은 리소스가 필요하지 않습니다.
- 지속적인 학습: 전이학습을 통해 지속적인 학습이 가능합니다. 모델은 새로운 데이터, 작업 또는 환경을 지속적으로 학습하고 적응할 수 있습니다. 따라서 기계 학습에 필수적인 지속적인 학습을 달성합니다.
- 최첨단 결과: 전이 학습은 최첨단 결과를 달성하는 데 중요한 역할을 했습니다. 수많은 머신러닝 대회와 벤치마크에서 최고 수준의 결과를 달성했습니다. 이제 이 분야의 표준 기술이 되었습니다.
전이 학습의 응용
전이 학습은 기존 지식을 활용하여 새로운 것을 더욱 쉽게 학습하는 것과 유사합니다. 이는 컴퓨터 프로그램의 기능을 향상시키기 위해 다양한 영역에서 널리 사용되는 강력한 기술입니다. 이제 전이 학습이 중요한 역할을 하는 몇 가지 공통 영역을 살펴보겠습니다.
컴퓨터 시각 인식:
많은 컴퓨터 비전 작업에서는 전문가가 특정 객체 인식 작업을 위해 ResNet, VGG 또는 MobileNet과 같은 사전 훈련된 모델을 미세 조정하는 객체 감지 분야에서 전이 학습을 널리 사용합니다. FaceNet 및 OpenFace와 같은 일부 모델은 전이 학습을 사용하여 다양한 조명 조건, 포즈 및 각도에서 얼굴을 인식합니다. 사전 훈련된 모델은 이미지 분류 작업에도 적용됩니다. 여기에는 의료 영상 분석, 야생 동물 모니터링, 제조 품질 관리가 포함됩니다.
자연어 처리 (NLP) :
다음과 같은 전이 학습 모델이 있습니다. BERT 와 GPT 이러한 모델은 감정 분석을 위해 미세 조정됩니다. Google의 Transformer 모델은 다양한 상황에서 텍스트의 감정을 이해할 수 있도록 전이 학습을 사용하여 언어 간 텍스트를 번역합니다.
자율 주행 차 :
전이 학습의 적용 자치 차량 자동차 산업에서 빠르게 발전하고 중요한 개발 영역입니다. 이 영역에는 전이 학습이 사용되는 많은 세그먼트가 있습니다. 일부에는 객체 감지, 객체 인식, 경로 계획, 행동 예측, 센서 융합, 교통 제어 등이 있습니다.
콘텐츠 생성:
콘텐츠 생성 전이 학습의 흥미로운 응용 프로그램입니다. GPT-3(Generative Pre-trained Transformer 3)은 방대한 양의 텍스트 데이터에 대해 학습되었습니다. 다양한 도메인에서 창의적인 콘텐츠를 생성할 수 있습니다. GPT-3 및 기타 모델은 예술, 음악, 스토리텔링, 코드 생성을 포함한 창의적인 콘텐츠를 생성합니다.
추천 시스템:
우리 모두는 이 제품의 장점을 알고 있습니다. 추천 시스템. 이는 우리의 삶을 조금 더 단순하게 만들어줍니다. 그렇습니다. 여기서도 전이 학습을 사용합니다. Netflix, YouTube를 포함한 많은 온라인 플랫폼에서는 전이 학습을 사용하여 사용자 선호도에 따라 영화와 비디오를 추천합니다.
자세히 알아보기 : 딥 러닝을 위한 전이 학습 이해
생성 모델 향상
생성 모델은 빠르게 발전하는 인공 지능 분야에서 가장 흥미롭고 혁신적인 개념 중 하나입니다. 여러 면에서 전이 학습은 다음과 같은 생성 AI 모델의 기능과 성능을 향상시킬 수 있습니다. GAN(생성적 적대 네트워크) or VAE(변형 자동 인코더). 전이 학습의 주요 이점 중 하나는 모델이 획득한 지식을 다양한 관련 작업에 사용할 수 있다는 것입니다. 생성 모델에는 광범위한 교육이 필요하다는 것을 알고 있습니다. 더 나은 결과를 얻으려면 대규모 데이터세트에서 교육하는 것이 필수적이며, 이는 전이 학습에서 강력하게 지지하는 방식입니다. 모델은 처음부터 시작하는 대신 기존 지식을 사용하여 활동을 시작할 수 있습니다.
GAN 또는 VAE의 경우 전문가는 더 광범위한 데이터 세트 또는 도메인에서 모델의 판별기 또는 인코더-디코더 부분을 사전 훈련할 수 있습니다. 이렇게 하면 훈련 과정의 속도가 빨라질 수 있습니다. 생성 모델은 일반적으로 고품질 콘텐츠를 생성하기 위해 방대한 양의 도메인별 데이터가 필요합니다. 전이 학습은 더 작은 데이터 세트만 필요하므로 이 문제를 해결할 수 있습니다. 또한 생성 모델의 지속적인 학습과 적응을 촉진합니다.
전이 학습은 이미 생성적 AI 모델을 개선하는 데 실용적인 응용 프로그램을 찾았습니다. GPT-3과 같은 텍스트 기반 모델을 적용하여 이미지를 생성하고 코드를 작성하는 데 사용되었습니다. GAN의 경우 전이 학습은 초현실적인 이미지를 생성하는 데 도움이 될 수 있습니다. 생성적 AI가 계속 향상됨에 따라 전이 학습은 훨씬 더 뛰어난 작업을 수행하는 데 매우 중요해질 것입니다.
모바일넷 V2
Google은 컴퓨터 비전 및 딥 러닝 애플리케이션에 널리 사용되는 강력한 사전 훈련된 신경망 아키텍처인 MobileNetV2를 만들었습니다. 그들은 처음에 이 모델이 이미지를 신속하게 처리하고 분석하여 다양한 작업에서 최첨단 성능을 달성하도록 의도했습니다. 이제 많은 컴퓨터 비전 작업에서 선호되는 옵션이 되었습니다. MobileNetV2는 가볍고 효율적으로 특별히 설계되었습니다. 상대적으로 적은 수의 매개변수를 사용하여 매우 정확하고 인상적인 결과를 얻습니다.
효율성에도 불구하고 MobileNetV2는 다양한 컴퓨터 비전 작업에서 높은 정확도를 유지합니다. MobileNetV2는 역 잔차 개념을 도입합니다. 레이어의 출력이 입력에 추가되는 기존 잔차와 달리 반전 잔차는 바로가기 연결을 사용하여 정보를 프로덕션에 추가합니다. 모델을 더 깊고 효율적으로 만듭니다.
반전된 잔차는 레이어의 출력이 입력에 추가되는 기존 잔차와 달리 바로가기 연결을 사용하여 프로덕션에 정보를 추가합니다. 이 사전 훈련된 MobileNetV2 모델을 사용하여 특정 애플리케이션에 맞게 미세 조정할 수 있습니다. 따라서 많은 시간과 계산 자원을 절약하여 계산 비용을 절감합니다. 효율성과 효율성으로 인해 MobileNetV2는 산업 및 연구 분야에서 널리 사용됩니다. TensorFlow Hub는 사전 훈련된 MobileNetV2 모델에 대한 쉬운 액세스를 제공합니다. 모델을 Tensorflow 기반 프로젝트에 쉽게 통합할 수 있습니다.
가위바위보 분류
건물을 시작해 보겠습니다. 기계 학습 가위바위보 분류 작업을 위한 모델입니다. 전이학습(Transfer Learning) 기법을 활용하여 구현하겠습니다. 이를 위해 우리는 MobileNet V2 사전 훈련된 모델을 사용합니다.

가위바위보 데이터세트
'가위바위보' 데이터세트는 2,892개의 이미지로 구성된 모음입니다. 세 가지 다른 포즈를 취하는 다양한 손으로 구성되어 있습니다. 이것들은,
- 바위: 꽉 쥔 주먹.
- 종이: 열린 손바닥.
- 가위: 두 개의 확장된 손가락이 V 모양을 형성합니다.
이미지에는 다양한 인종, 연령, 성별의 사람들의 손이 포함되어 있습니다. 모든 사진은 동일한 흰색 배경을 가지고 있습니다. 이러한 다양성은 기계 학습 및 컴퓨터 비전 애플리케이션을 위한 귀중한 리소스가 됩니다. 이는 과적합과 과소적합을 모두 방지하는 데 도움이 됩니다.
데이터 세트 로드 및 탐색
기본 필수 라이브러리를 가져오는 것부터 시작해 보겠습니다. 이 프로젝트에는 tensorflow, tensorflow 허브, 데이터 세트를 위한 tensorflow 데이터 세트, 시각화를 위한 matplotlib, numpy 및 os가 필요합니다.
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
import matplotlib.pylab as plt
import numpy as np
import os
텐서플로우 데이터세트를 사용하여 "가위바위보" 데이터세트를 로드합니다. 여기서는 XNUMX개의 매개변수를 제공합니다. 로드해야 하는 데이터 세트의 이름을 언급해야 합니다. 여기는 가위바위보입니다. 데이터세트에 대한 정보를 요청하려면 with_info를 True로 설정하세요. 다음으로 지도 형식으로 데이터 세트를 로드하려면 as_supervised를 True로 설정합니다.
그리고 마지막으로 로드하려는 분할을 정의합니다. 여기서는 파티션을 훈련하고 테스트해야 합니다. 데이터세트와 정보를 해당 변수에 로드합니다.
datasets, info = tfds.load( name='rock_paper_scissors', # Specify the name of the dataset you want to load. with_info=True, # To request information about the dataset as_supervised=True, # Load the dataset in a supervised format. split=['train', 'test'] # Define the splits you want to load.
)
정보 인쇄
이제 정보를 인쇄해 보세요. 데이터세트의 모든 세부정보가 게시됩니다. 이름, 버전, 설명, 원본 데이터 세트 리소스, 기능, 총 이미지 수, 분할 번호, 작성자 및 기타 세부 정보입니다.
info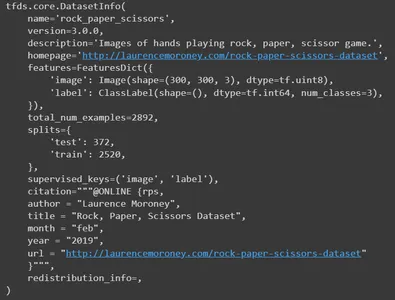
이제 훈련 데이터세트에서 일부 샘플 이미지를 인쇄해 보겠습니다.
train, info_train = tfds.load(name='rock_paper_scissors', with_info=True, split='train')
tfds.show_examples(info_train,train)
먼저 아이들과 함께 "가위바위보" 데이터세트를 로드합니다. 훈련 및 테스트 분할을 별도로 지정하는 Load() 함수. 그런 다음 .concatenate() 메서드를 사용하여 훈련 데이터세트와 테스트 데이터세트를 연결합니다. 마지막으로 버퍼 크기가 3000인 .shuffle() 메서드를 사용하여 결합된 데이터세트를 섞습니다. 이제 훈련 데이터와 테스트 데이터를 결합하는 단일 데이터세트 변수가 생겼습니다.
dataset=datasets[0].concatenate(datasets[1])
dataset=dataset.shuffle(3000)Skip() 및 take() 메서드를 사용하여 전체 데이터 세트를 훈련, 테스트 및 검증 데이터 세트로 분할해야 합니다. 검증을 위해 데이터세트의 처음 600개 샘플을 사용합니다. 그런 다음 초기 600개의 이미지를 제외하여 임시 데이터 세트를 생성합니다. 이 임시 데이터 세트에서는 테스트를 위해 처음 400장의 사진을 선택합니다. 다시 말하지만, 훈련 데이터세트에서는 처음 400개의 이미지를 건너뛴 후 임시 데이터세트의 모든 사진을 찍습니다.
데이터 분할 방법을 요약하면 다음과 같습니다.
- rsp_val: 검증을 위한 600개 예시.
- rsp_test: 테스트용 샘플 400개.
- rsp_train: 훈련을 위한 나머지 예시입니다.
rsp_val=dataset.take(600)
rsp_test_temp=dataset.skip(600)
rsp_test=rsp_test_temp.take(400)
rsp_train=rsp_test_temp.skip(400)그럼 훈련 데이터 세트에 얼마나 많은 이미지가 있는지 살펴보겠습니다.
len(list(rsp_train)) #1892
#It has 1892 images in total데이터 전처리
이제 데이터 세트에 대해 몇 가지 전처리를 수행해 보겠습니다. 이를 위해 함수 척도를 정의하겠습니다. 이미지와 해당 라벨을 인수로 전달합니다. 캐스트 메소드를 사용하여 이미지의 데이터 유형을 float32로 변환합니다. 그런 다음 다음 단계에서는 이미지의 픽셀 값을 정규화해야 합니다. 이미지의 픽셀 값을 [0, 1] 범위로 조정합니다. 이미지 크기 조정은 모든 입력 이미지가 딥 러닝 모델을 훈련할 때 종종 필요한 정확한 크기를 갖도록 보장하는 일반적인 전처리 단계입니다. 따라서 [224,224] 크기의 이미지를 반환하겠습니다. 라벨의 경우 원핫 인코딩을 수행합니다. 세 가지 클래스(Rock, Paper, Scissors)가 있는 경우 레이블은 원-핫 인코딩된 벡터로 변환됩니다. 이 벡터가 반환됩니다.
예를 들어 라벨이 1(Paper)이면 [0, 1, 0]으로 변환됩니다. 여기서 각 요소는 클래스에 해당합니다. "1"은 해당 특정 클래스(용지)에 해당하는 위치에 배치됩니다. 마찬가지로 바위 레이블의 경우 벡터는 [1, 0, 0]이 되고 가위의 경우 벡터는 [0, 0, 1]이 됩니다.
암호
def scale(image, label): image = tf.cast(image, tf.float32) image /= 255.0 return tf.image.resize(image,[224,224]), tf.one_hot(label, 3)이제 훈련, 테스트, 검증을 위해 일괄 처리되고 사전 처리된 데이터 세트를 생성하는 함수를 정의합니다. 세 가지 데이터 세트 모두에 미리 정의된 척도 함수를 적용합니다. 배치 크기를 64로 정의하고 인수로 전달합니다. 이는 모델이 개별 사례가 아닌 일괄 데이터에 대해 훈련되는 경우가 많은 딥 러닝에서 흔히 발생합니다. 과적합을 방지하려면 열차 데이터세트를 섞어야 합니다. 마지막으로 세 가지 확장된 데이터 세트를 모두 반환합니다.
def get_dataset(batch_size=64): train_dataset_scaled = rsp_train.map(scale).shuffle(1900).batch(batch_size) test_dataset_scaled = rsp_test.map(scale).batch(batch_size) val_dataset_scaled = rsp_val.map(scale).batch(batch_size) return train_dataset_scaled, test_dataset_scaled, val_dataset_scaledget_dataset 함수를 사용하여 세 개의 데이터세트를 개별적으로 로드합니다. 그런 다음 학습 및 검증 데이터 세트를 캐시합니다. 캐싱은 특히 데이터세트를 저장할 충분한 메모리가 있는 경우 데이터 로딩 성능을 향상시키는 유용한 기술입니다. 캐싱은 훈련 및 검증 단계에서 더 빠른 액세스를 위해 데이터가 메모리에 로드되고 유지된다는 것을 의미합니다. 이렇게 하면 특히 훈련 프로세스에 여러 에포크가 포함된 경우 스토리지에서 동일한 데이터를 반복적으로 로드하는 것을 방지하므로 훈련 속도가 빨라질 수 있습니다.
train_dataset, test_dataset, val_dataset = get_dataset()
train_dataset.cache()
val_dataset.cache()사전 학습된 모델 로드
Tensorflow Hub를 사용하여 사전 훈련된 MobileNet V2 기능 추출기를 로드합니다. 그리고 그것을 레이어로 구성합니다. 케라스 모델. 이 MobileNet 모델은 대규모 데이터 세트에 대해 훈련되었으며 이미지에서 특징을 추출하는 데 사용할 수 있습니다. 이제 MobileNet V2 기능 추출기를 사용하여 keras 레이어를 생성합니다. 여기서는 input_shape를 (224, 224, 3)으로 지정합니다. 이는 모델이 224×224 픽셀 크기와 2가지 색상 채널(RGB)의 입력 이미지를 기대한다는 것을 나타냅니다. 이 레이어의 훈련 가능 속성을 False로 설정합니다. 이렇게 하면 훈련 프로세스 중에 사전 훈련된 MobileNet VXNUMX 모델을 미세 조정하지 않을 것임을 나타냅니다. 하지만 그 위에 사용자 정의 레이어를 추가할 수 있습니다.
feature_extractor = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4"
feature_extractor_layer = hub.KerasLayer(feature_extractor, input_shape=(224,224,3))
feature_extractor_layer.trainable = False건물 모델
이제 MobileNet V2 기능 추출 레이어에 레이어를 추가하여 TensorFlow Keras Sequential 모델을 구축할 차례입니다. feature_extractor_layer에 드롭아웃 레이어를 추가하겠습니다. 여기서는 드롭아웃 비율을 0.5로 설정하겠습니다. 이 정규화 방법은 과적합을 방지하기 위해 수행하는 방법입니다. 학습 중에 드롭아웃 비율을 0.5로 설정하면 모델은 평균 50%의 단위를 삭제합니다. 이후 XNUMX개의 출력 단위가 있는 Dense 레이어를 추가하고, 이 단계에서는 'softmax' 활성화 함수를 사용합니다. 'Softmax'는 다중 클래스 분류 문제를 해결하기 위해 널리 사용되는 활성화 함수입니다. 각 입력 이미지의 클래스(바위보, 종이, 가위)에 대한 확률 분포를 계산합니다. 그런 다음 모델 요약을 인쇄합니다.
model = tf.keras.Sequential([ feature_extractor_layer, tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(3,activation='softmax')
]) model.summary()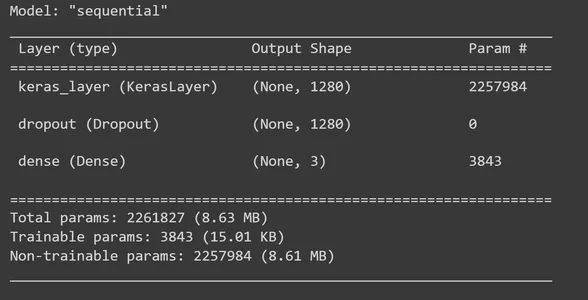
이제 모델을 컴파일할 시간입니다. 이를 위해 Adam 최적화 프로그램과 C.ategoricalCrossentropy 손실 함수를 사용합니다. from_logits=True 인수는 모델의 출력이 확률 분포 대신 원시 로짓(정규화되지 않은 점수)을 생성함을 나타냅니다. 훈련 중에 모니터링하기 위해 정확도 측정항목을 사용합니다.
model.compile( optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True), metrics=['acc'])콜백이라는 함수는 각 배치 또는 에포크의 끝을 포함하여 다양한 훈련 단계에서 실행될 수 있습니다. 이러한 맥락에서 우리는 학습 중에 배치 수준에서 손실 및 정확도 값을 수집하고 기록하기 위한 목적으로 TensorFlow Keras에서 사용자 정의 콜백을 정의합니다.
class CollectBatchStats(tf.keras.callbacks.Callback): def __init__(self): self.batch_losses = [] self.batch_acc = [] def on_train_batch_end(self, batch, logs=None): self.batch_losses.append(logs['loss']) self.batch_acc.append(logs['acc']) self.model.reset_metrics()이제 생성된 클래스의 객체를 생성합니다. 그런 다음 fit_generator 메서드를 사용하여 모델을 훈련합니다. 이를 위해서는 필요한 매개변수를 제공해야 합니다. 훈련에 필요한 에포크 수, 검증 데이터 세트 및 콜백 설정을 언급하는 훈련 데이터 세트가 필요합니다.
batch_stats_callback = CollectBatchStats() history = model.fit_generator(train_dataset, epochs=5, validation_data=val_dataset, callbacks = [batch_stats_callback])시각화
matplotlib를 사용하여 CollectBatchStats 콜백에서 수집한 데이터를 사용하여 훈련 단계에 대한 훈련 손실을 플로팅합니다. 훈련이 진행됨에 따라 현장에서 손실이 어떻게 최적화되는지 관찰할 수 있습니다.
plt.figure()
plt.ylabel("Loss")
plt.xlabel("Training Steps")
plt.ylim([0,2])
plt.plot(batch_stats_callback.batch_losses)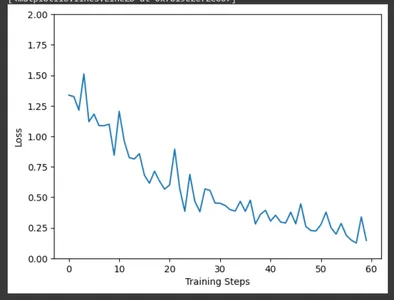
마찬가지로 훈련 단계에 대한 정확도를 플롯합니다. 여기에서도 훈련이 진행됨에 따라 정확도가 증가하는 것을 볼 수 있습니다.
plt.figure()
plt.ylabel("Accuracy")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(batch_stats_callback.batch_acc)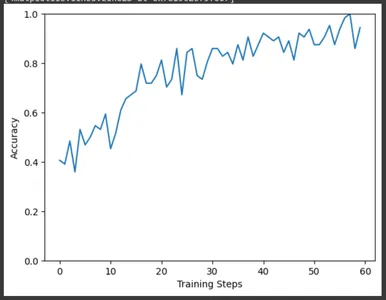
평가 및 결과
이제 테스트 데이터세트를 사용하여 모델을 평가할 차례입니다. 결과 변수에는 모델 컴파일 중에 정의한 테스트 손실 및 기타 측정항목을 포함한 평가 결과가 포함됩니다. 결과 배열에서 테스트 손실과 테스트 정확도를 추출하여 인쇄합니다. 우리 모델의 손실은 0.14이고 정확도는 약 96%입니다.
result=model.evaluate(test_dataset)
test_loss = result[0] # Test loss
test_accuracy = result[1] # Test accuracy
print(f"Test Loss: {test_loss}")
print(f"Test Accuracy: {test_accuracy}") #Test Loss: 0.14874716103076935
#Test Accuracy: 0.9674999713897705
일부 테스트 이미지에 대한 예측을 살펴보겠습니다. 이 루프는 rsp_test 데이터 세트의 처음 XNUMX개 샘플을 반복합니다. scale 함수를 적용하여 이미지와 라벨을 전처리합니다. 브랜드의 이미지 스케일링과 원-핫 인코딩을 수행합니다. 실제 레이블(원-핫 인코딩 형식에서 변환됨)과 예측 레이블(예측에서 가장 높은 확률을 갖는 클래스 기반)을 인쇄합니다.
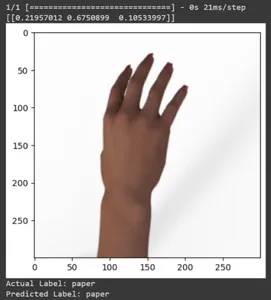
for test_sample in rsp_test.take(10): image, label = test_sample[0], test_sample[1] image_scaled, label_arr= scale(test_sample[0], test_sample[1]) image_scaled = np.expand_dims(image_scaled, axis=0) img = tf.keras.preprocessing.image.img_to_array(image) pred=model.predict(image_scaled) print(pred) plt.figure() plt.imshow(image) plt.show() print("Actual Label: %s" % info.features["label"].names[label.numpy()]) print("Predicted Label: %s" % info.features["label"].names[np.argmax(pred)])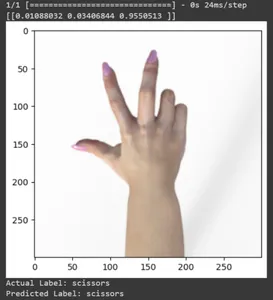
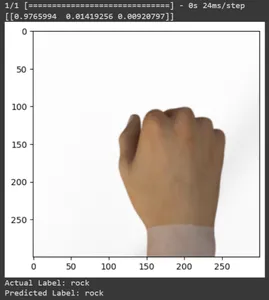
모든 테스트 이미지의 예측을 인쇄해 보겠습니다. 훈련된 TensorFlow Keras 모델을 사용하여 전체 테스트 데이터 세트에 대한 예측을 생성한 다음 각 예측에 대해 가장 높은 확률로 클래스 레이블(클래스 인덱스)을 추출합니다.
np.argmax(model.predict(test_dataset),axis=1)모델 예측에 대한 혼동 행렬을 인쇄합니다. 혼동 행렬은 모델의 예측이 레이블과 어떻게 일치하는지에 대한 자세한 분석을 제공합니다. 분류 모델의 성능을 평가하는 데 유용한 도구입니다. 각 클래스에 참양성, 참음성, 거짓양성을 제공합니다.
for f0,f1 in rsp_test.map(scale).batch(400): y=np.argmax(f1, axis=1) y_pred=np.argmax(model.predict(f0),axis=1) print(tf.math.confusion_matrix(labels=y, predictions=y_pred, num_classes=3)) #Output tf.Tensor(
[[142 3 0] [ 1 131 1] [ 0 1 121]], shape=(3, 3), dtype=int32) 훈련된 모델 저장 및 로드
훈련된 모델을 저장합니다. 따라서 모델을 사용해야 할 때 처음부터 모든 것을 가르칠 필요가 없습니다. 모델을 로드하여 예측에 사용해야 합니다.
model.save('./path/', save_format='tf')모델을 로드하여 확인해 보겠습니다.
loaded_model = tf.keras.models.load_model('path')마찬가지로 이전에 했던 것처럼 테스트 데이터 세트의 일부 샘플 이미지를 사용하여 모델을 테스트해 보겠습니다.
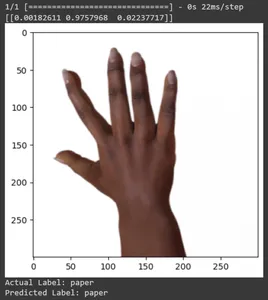
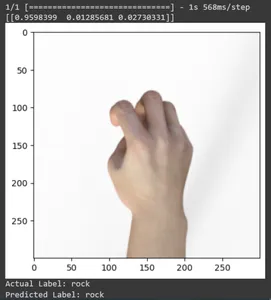
for test_sample in rsp_test.take(10): image, label = test_sample[0], test_sample[1] image_scaled, label_arr= scale(test_sample[0], test_sample[1]) image_scaled = np.expand_dims(image_scaled, axis=0) img = tf.keras.preprocessing.image.img_to_array(image) pred=loaded_model.predict(image_scaled) print(pred) plt.figure() plt.imshow(image) plt.show() print("Actual Label: %s" % info.features["label"].names[label.numpy()]) print("Predicted Label: %s" % info.features["label"].names[np.argmax(pred)])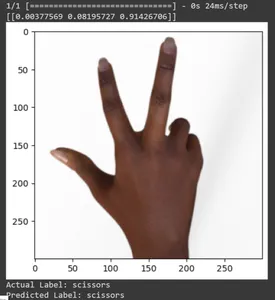
결론
이 기사에서는 가위바위보 분류 작업에 전이 학습을 적용했습니다. 이 작업을 위해 사전 훈련된 Mobilenet V2 모델을 사용했습니다. 우리 모델은 약 96%의 정확도로 성공적으로 작동하고 있습니다. 예측 이미지에서 모델이 얼마나 잘 예측하고 있는지 확인할 수 있습니다. 마지막 세 장의 사진은 손 포즈가 불완전하더라도 얼마나 완벽한지 보여줍니다. "가위"를 표현하려면 두 손가락 구성을 사용하는 대신 세 손가락을 엽니다. 'Rock'의 경우 주먹을 꽉 쥐지 마세요. 하지만 여전히 우리 모델은 해당 클래스를 이해하고 완벽하게 예측할 수 있습니다.
주요 요점
- 전이 학습은 지식을 전달하는 것입니다. 이전 작업에서 얻은 지식은 새로운 직업을 배우는 데 사용됩니다.
- 전이 학습은 기계 학습 분야에 혁명을 일으킬 수 있는 잠재력을 가지고 있습니다. 이는 학습 가속화 및 성능 향상을 포함하여 여러 가지 이점을 제공합니다.
- 전이 학습은 새로운 정보, 작업 또는 환경을 처리하기 위해 시간이 지남에 따라 모델이 변경될 수 있는 지속적인 학습을 촉진합니다.
- 머신러닝 모델의 효과성과 효율성을 높이는 유연하고 효과적인 방법입니다.
- 이 기사에서는 전이 학습, 그 이점 및 적용에 대한 모든 것을 배웠습니다. 또한 가위바위보 분류 작업을 수행하기 위해 새로운 데이터 세트에 사전 훈련된 모델을 사용하여 구현했습니다.
자주 묻는 질문
A. 전이학습(Transfer Learning)은 이미 발견된 관련 수업의 지식을 전이하여 새로운 과제에 대한 학습을 향상시키는 것입니다. 이 기술을 사용하면 알고리즘이 사전 훈련된 모델을 사용하여 새 작업을 기억할 수 있습니다.
A. 가위바위보 데이터세트를 데이터세트로 대체하여 이 프로젝트를 다른 이미지 분류 작업에 적용할 수 있습니다. 또한 새 작업의 요구 사항에 따라 모델을 미세 조정해야 합니다.
A. MobileNet V2는 TensorFlow Hub에서 사용할 수 있는 사전 학습된 특징 추출 모델입니다. 전이 학습 시나리오에서 실무자는 MobileNetV2를 기능 추출기로 활용하는 경우가 많습니다. 작업별 레이어를 그 위에 통합하여 특정 작업에 맞게 사전 훈련된 MobileNetV2 모델을 미세 조정합니다. 그의 접근 방식을 통해 다양한 컴퓨터 비전 작업에 대한 빠르고 효율적인 교육이 가능해졌습니다.
A. TensorFlow는 Google에서 개발한 오픈소스 머신러닝 프레임워크입니다. 기계 학습 모델과 집중 학습 모델을 구축하고 훈련하는 데 널리 사용됩니다.
A. 미세 조정은 사전 훈련된 모델을 가져와 더 낮은 학습률로 특정 작업에 대해 추가로 훈련시키는 공유 전이 학습 기술입니다. 이를 통해 모델은 지식을 대상 작업의 미묘한 차이에 맞게 조정할 수 있습니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/10/transfer-learning-a-rock-paper-scissors-case-study/

