ノボノルディスク は、毎日 34 万人以上の患者に届けられる命を救う医薬品の製造を担う、世界をリードする製薬会社です。 彼らは、環境的に持続可能であり、社会的に持続可能であり、財政的に持続可能であるように努力しなければならないというトリプルボトムラインに従ってこれを行います. AWS とデータの使用の組み合わせは、これらすべてのターゲットをサポートします。
データは、ノボ ノルディスクのバリュー チェーン全体に浸透しています。 基礎研究、製造ライン、販売およびマーケティング、臨床試験、ファーマコビジランスから、患者向けのデータ駆動型アプリケーションまで。 したがって、データの保存、保護、および最大の価値を提供する方法での使用に関する基盤を確立することは、ビジネスの成果を改善するための中心的な推進力の XNUMX つです。
と共に AWSプロフェッショナルサービス、最新のデータ アーキテクチャを使用して、データと分析のソリューションを構築しています。 ノボ ノルディスクと AWS プロフェッショナル サービスのコラボレーションは、戦略的かつ長期的な緊密な連携であり、両組織の開発者は何年にもわたって密接に協力してきました。 データおよび分析環境は、データ メッシュの中核となる原則に基づいて構築されています。つまり、データのドメイン所有権の分散化、製品としてのデータ、セルフサービス データ インフラストラクチャ、連合計算ガバナンスです。 これにより、環境のユーザーは、最高のビジネス成果をもたらす方法でデータを操作できます。 これを進化的アーキテクチャの要素と組み合わせて、AWS が継続的に新しいサービスと機能を開発する際にさまざまな機能を適応できるようにします。
この一連の投稿では、ノボ ノルディスクと AWS プロフェッショナル サービスがどのようにデータと分析のエコシステムを構築し、ペタバイト規模でイノベーションを加速したかを学びます。
- この最初の投稿では、全体的な設計によって個々のコンポーネントがモジュール式にまとめられるようになった方法を学びます。 データ メッシュ アーキテクチャに基づいてデータ管理ソリューションを構築する方法について詳しく説明します。
- XNUMX つ目の投稿では、ソリューション全体を構成するシステム間に信頼ネットワークを構築する方法について説明します。 属性ベースのアクセス制御の使用と組み合わせて、イベント駆動型アーキテクチャを使用して、許可の境界が大規模に尊重されるようにする方法を示します。
- XNUMX 回目の投稿では、エンドユーザーがデータ ガバナンスを損なうことなく、選択したツールからデータを利用する方法を示します。 これには、Okta の設定方法が含まれます。 AWSレイクフォーメーション、および Microsoft Power BI を使用して、SAML ベースのフェデレーション使用を可能にします。 アマゾンアテナ エンタープライズ ビジネス インテリジェンス (BI) アクティビティ用。
医薬品に準拠した環境
製薬業界として、GxP コンプライアンスはノボ ノルディスクの義務です。 GxP は、欧州医薬品庁、米国食品医薬品局などの規制当局によって定義された「Good x Practice」品質ガイドラインおよび規制の一般的な略語です。 これらのガイドラインは、医薬品が意図した用途に対して安全で効果的であることを保証するように設計されています。 データ環境のコンテキストでは、GxP コンプライアンスには、意思決定とプロセスで使用されるデータの整合性管理の実装が含まれ、時間の経過とともに継続的にコンプライアンスを確保するために変更管理プロセスを実装する方法をガイドするために使用されます。
このデータ環境は組織全体のチームをサポートするため、個々のデータ所有者は各自のデータに対する説明責任を保持する必要があります。 機能は、データ所有者がデータを管理する際の自律性と透明性を提供するように設計されており、この責任を負うことができます。 これには、個人を特定できる情報 (PII) データやその他の機密性の高いワークロードを処理する機能が含まれます。 環境のトレーサビリティを提供するために、監査機能が追加されました。これについては、この投稿で詳しく説明します。
ソリューションの概要
完全なソリューションは、ペタバイト規模の分散型データ ガバナンス モデルを使用してデータと分析を可能にするために連携する、独立したサービスの無秩序なランドスケープです。 概略的には、次の図のように表すことができます。

アーキテクチャは、データ管理、仮想化、消費という XNUMX つの独立したレイヤーに分割されます。 エンドユーザーは消費層に座り、選択したツールで作業します。 これは、AWS ネイティブ リソースの多くをアプリケーション プリミティブに抽象化することを目的としています。 消費レイヤーは、データへのアクセスを抽象化する仮想化レイヤーに統合されます。 仮想化レイヤーの目的は、データ消費とデータ管理ソリューションの間を変換することです。 データへのアクセスは、データ管理ソリューションと呼ばれるものによって管理されます。 この投稿の後半で、汎用性の高いデータ管理ソリューションの XNUMX つについて説明します。 このアーキテクチャの各レイヤーは互いに独立しており、明確に定義されたインターフェイスのみに依存しています。
このアーキテクチャの中心は、アクセスがカプセル化されていることです。 AWS IDおよびアクセス管理 (IAM) ロール セッション。 データ管理レイヤーは、IAM ロールに適切なアクセス許可とガバナンスを提供することに重点を置き、仮想化レイヤーはロールへのアクセスを提供し、消費レイヤーは選択したツールでのロールの使用を抽象化します。
技術アーキテクチャ
アーキテクチャ全体の XNUMX つの層のそれぞれに明確な役割がありますが、単一の実装はありません。 それらを抽象クラスと考えてください。 それらは具体的なクラスで実装でき、私たちの場合、基本的な AWS のサービスと機能に依存しています。 XNUMX つの層のそれぞれについて見ていきましょう。
データ管理レイヤー
データ管理レイヤーは、データへのアクセスとデータのガバナンスを提供します。 次の図に示すように、データ管理レイヤーの最小限の構造は、 Amazon シンプル ストレージ サービス (Amazon S3) バケットと、S3 バケットへのアクセスを許可する IAM ロール。 この構造は、Lake Formation による詳細な許可、監査を含むように拡張できます。 AWS クラウドトレイル、およびからのセキュリティ応答機能 AWSセキュリティハブ. 次の図は、単一のデータ管理ソリューションに単一のスパンがないことも示しています。 多数の AWS アカウントにまたがり、任意の数の IAM ロールの組み合わせで構成できます。
この図では、これらの役割の信頼ポリシーを意図的に示していません。これは、これらの役割が仮想化レイヤーとデータ管理レイヤーの間の共同責任であるためです。 これがどのように機能するかについては、このシリーズの次の投稿で詳しく説明します。 データ エンジニアリングの専門家は、多くの場合、データ管理レイヤーと直接やり取りし、そこで使用するデータをキュレートして準備します。
仮想化レイヤー
仮想化レイヤーの目的は、誰が何を実行できるかを追跡することです。 それ自体には機能はありませんが、要件をデータ管理エコシステムから消費レイヤーに、またはその逆に変換します。 これにより、消費レイヤーのエンドユーザーは、アクセス許可に従って、XNUMX つ以上のデータ管理エコシステム上のデータにアクセスして操作できます。 このレイヤーは、アクセス許可モデル、ロールの想定、ストレージの場所など、データ アクセスに関する技術的な詳細をエンド ユーザーから抽象化します。 他のレイヤーへのインターフェースを所有し、抽象化のロジックを実施します。 六角形のアーキテクチャのコンテキストでは (参照 AWS Lambda を使用した進化的アーキテクチャの開発)、インターフェイス レイヤーは、ドメイン ロジック、ポート、およびアダプターの役割を果たします。 他の XNUMX つのレイヤーはアクターです。 データ管理レイヤーは、レイヤーの状態を仮想化レイヤーに伝達し、逆に、信頼するサービス ランドスケープに関する情報を受け取ります。 仮想化レイヤーのアーキテクチャを次の図に示します。

消費層
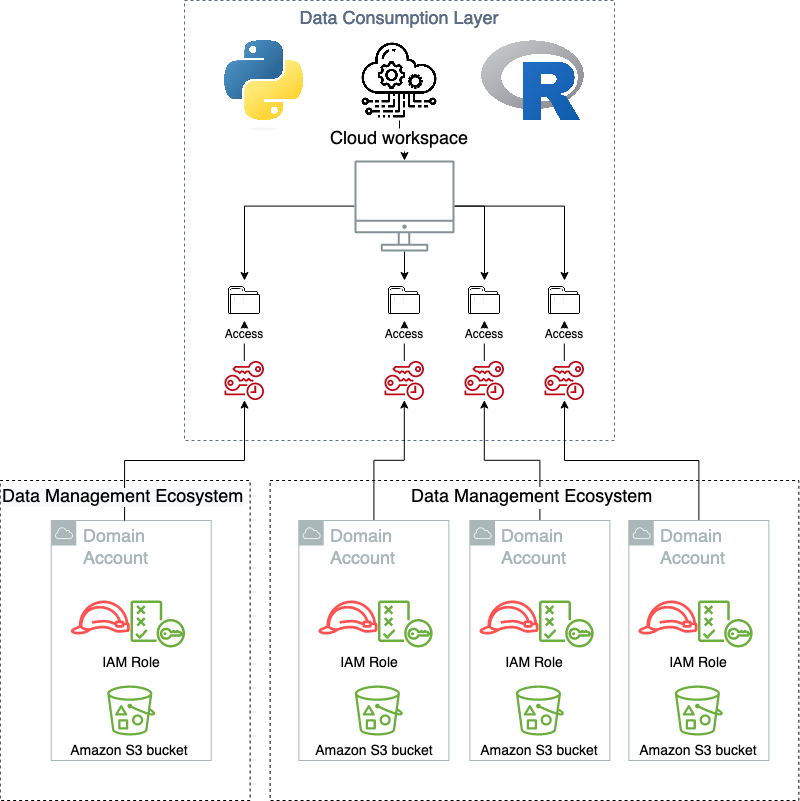
消費レイヤーは、データ製品のエンドユーザーが座っている場所です。 これは、データ サイエンティスト、ビジネス インテリジェンス アナリスト、またはデータを消費して価値を生み出すサード パーティである可能性があります。 このタイプのアーキテクチャでは、コンシューム レイヤーにフックベースのサインイン フローがあり、サインイン時にアプリケーションへの承認を変更できることが重要です。 これは、AWS 固有の要件をターゲット アプリケーションに変換するためです。 クライアント側アプリケーションのセッションが正常に開始された後、データ層の抽象化を実装するのはアプリケーション自体次第です。これはアプリケーション固有であるためです。 そして、これは追加の重要なデカップリングであり、一部の責任が分散型ユニットにプッシュされます。 多くの最新のサービスとしてのソフトウェア (SaaS) アプリケーションは、これらの組み込みメカニズムをサポートしています。 データブリック or Domino Data Lab、一方、より伝統的なクライアント側アプリケーションのような RStudioサーバー これに対するより限定的なネイティブ サポートがあります。 ネイティブ サポートがない場合は、OS ユーザー セッションに変換して抽象化を有効にすることができます。 消費レイヤーは、次の図に概略的に示されています。

消費層を意図したとおりに使用すると、ユーザーは仮想化層が存在することを知りません。 次の図は、データ アクセス パターンを示しています。
モジュール性
六角形のアーキテクチャ パターンを採用し、消費層とデータ管理層の両方をプライマリ アクターとセカンダリ アクターに委任することの主な利点の XNUMX つは、新しいソリューションを必要とする新しい機能がリリースされたときに、それらを変更または置換できることを意味します。 これにより、多くの異なるタイプのプロデューサー/コンシューマー タイプのシステムを接続して同時に機能させることができる、ハブ アンド スポーク タイプのパターンが得られます。 この例として、Novo Nordisk で実行されている現在のソリューションは、複数の同時データ管理ソリューションをサポートしており、消費層で同種の方法で公開されています。 これには、データ レイク、この投稿で紹介するデータ メッシュ ソリューション、およびいくつかの独立したデータ管理ソリューションの両方が含まれます。 また、これらは、カスタム マネージドの自己ホスト型アプリケーションから SaaS オファリングまで、複数のタイプの消費アプリケーションに公開されています。
データ管理エコシステム
データの使用を拡大し、自由度を高めるために、Novo Nordisk は AWS プロフェッショナル サービスと共同で、Novo Nordisk Enterprise DataHub (NNEDH) という名前のデータ管理およびガバナンス環境を構築しました。 NNEDH は、分散型分散データ アーキテクチャと、エンタープライズ ビジネス データ カタログやデータ共有ワークフローなどのデータ管理機能を実装しています。 NNEDH は、前述の概念フレームワークにおけるデータ管理エコシステムの一例です。
分散型アーキテクチャ: 集中型データ レイクから分散型アーキテクチャへ
ノボ ノルディスクの一元化されたデータ レイクは、世界中の 2.3 以上のビジネス データ ドメインからの 30 PB のデータで構成され、バリュー チェーン全体で 2000 人以上の内部ユーザーにサービスを提供しています。 数年間、正常に実行されています。 これは、現在サポートされているデータ管理エコシステムの XNUMX つです。
一元化されたデータ アーキテクチャ内で、各データ ドメインからのデータは、XNUMX つの中央の場所 (XNUMX つのデータ ストレージでホストされる中央のデータ レイク) でコピー、保存、および処理されます。 このパターンは、データの所有権を中央チームに保持するため、大規模な場合に課題があります。 大規模な場合、このモデルは、データの所有権がドメインに最も近い専門家に十分に固定されていないため、データ駆動型の組織への移行を遅らせます。
モノリシック データ レイク アーキテクチャを次の図に示します。
分散型分散データ アーキテクチャ内では、各ドメインからのデータは、独自のデータ ストレージとコンピューティング アカウントでドメイン内に保持されます。 この場合、データはドメインの専門家の近くに保管されます。彼らは自分のデータを最もよく知っており、最終的には自分のデータに基づいて構築されたデータ プロダクトの所有者だからです。 多くの場合、ビジネス アナリストと緊密に連携してデータ プロダクトを構築するため、データ プロダクトの消費者にとって優れたデータが何を意味するかを理解しています。 この場合、データの責任も分散され、各ドメインには独自のデータ所有者があり、データの真の所有者に説明責任が課せられます。 ただし、このモデルは、組織データを管理する IT チームのオーバーヘッドが増えるため、XNUMX つのビジネス ユニットと数十人のユーザーしかいない組織など、小規模では機能しない可能性があります。 大規模な組織、または成長と拡張を望む中小規模の組織に適しています。
Novo Nordisk のデータ メッシュ アーキテクチャを次の図に示します。

データドメインとデータ資産
組織全体でデータ ドメインのスケーラビリティを実現するには、標準のアクセス許可モデルとデータ アクセス パターンが必須です。 この標準は、特定のユースケースのブロッカーになる可能性があるような方法で制限しすぎてはなりませんが、データ管理レイヤーと仮想化レイヤーの間で同じインターフェイスを使用するような方法で標準化する必要があります。
NNEDH のデータ ドメインは、 環境. 環境は、少なくとも XNUMX つの AWS アカウントと XNUMX つの AWS リージョンで構成されます。 これは、データ ドメイン チームが協力してデータ プロダクトを構築できる職場です。 NNEDH コントロール プレーンを、ドメインのデータとコンピューティングが存在する AWS アカウントにリンクします。 データ アクセス許可も環境レベルで定義され、データ ドメインの所有者によって管理されます。 環境には、データ管理とガバナンス レイヤー、データ資産、およびデータ処理用のオプションのブループリントという XNUMX つの主要コンポーネントがあります。
データ管理とガバナンスのために、データ ドメインは Lake Formation に依存しています。 AWSグルー、および CloudTrail です。 これらのコンポーネントの導入方法と設定は、データ ドメイン全体で標準化されています。 このように、NNEDH コントロール プレーンは、標準化された方法でデータ ドメインへの接続と管理を提供できます。
環境内に存在する各ドメインのデータ資産は、データ製品を構築するために使用される関連データのコレクションであるデータセットに編成されます。 これには、データ形式、サイズ、作成時間などのテクニカル メタデータと、プロデューサー、データ分類、ビジネス定義などのビジネス メタデータが含まれます。 データ プロダクトは、3 つまたは複数のデータセットを使用できます。 これは、マネージド SXNUMX バケットと AWS Glue データ カタログを通じて実装されます。
データ処理はさまざまな方法で実装できます。 NNEDH は、データ アセットへの事前定義された接続を備えたデータ パイプラインの青写真を提供し、データ プロダクトの配信を高速化します。 データドメインのユーザーは、この投稿で前述したように、ブループリントで事前定義されていない AWS サービスを使用したり、消費レイヤーに実装された他の分析ツールからデータセットにアクセスしたりするなど、ドメインで他のコンピューティング機能を自由に使用できます。
データ ドメインのペルソナと役割
NNEDH では、データ ドメインのアクセス許可レベルは、事前定義されたペルソナ (データ所有者、データ スチュワード、開発者、閲覧者など) によって管理されます。 各ペルソナは、事前定義されたアクセス許可レベルを持つ IAM ロールに関連付けられています。 これらの権限は、これらのロールのユーザーの一般的なニーズに基づいています。 ただし、データ ドメインの柔軟性を高めるために、必要に応じてこれらのアクセス許可をカスタマイズおよび拡張できます。
各ペルソナに関連付けられているアクセス許可は、データ ドメインの AWS アカウントで許可されているアクションにのみ関連しています。 データ資産に対する説明責任のために、資産へのデータ アクセスは、IAM ロールではなく特定のリソース ポリシーによって管理されます。 各データセットの所有者、または所有者から委任されたデータ スチュワードのみが、データ アクセスを許可または取り消すことができます。
データセット レベルでは、必須のペルソナはデータ所有者です。 通常、データ プロダクト マネージャーとして、XNUMX 人または複数のデータ スチュワードと緊密に連携します。 データスチュワードは、データ製品ドメインのデータ主題の専門家であり、収集されたデータとメタデータを解釈して、深いビジネス洞察を引き出し、製品を構築する責任があります。 データ スチュワードは、各データ ドメインのビジネス ユーザーと技術チームの間を橋渡しします。
エンタープライズ ビジネス データ カタログ
自由を実現し、組織のデータ資産を発見できるようにするために、Web ベースのポータル データ カタログが実装されています。 データ ドメイン上に構築されたデータセットから単一のリポジトリ メタデータにインデックスを付け、組織全体のデータ サイロを解消します。 データ カタログは、さまざまなドメインにわたるデータの検索と発見、およびデータ共有の自動化とガバナンスを可能にします。
ビジネス データ カタログは、組織内のデータ ガバナンス プロセスを実装します。 これにより、データの所有権が保証されます。組織内の誰かが、データの発生元、定義、ビジネス属性、関係、および依存関係について責任を負います。
ビジネス データ カタログの中心的な構造はデータセットです。 ビジネス カタログ内の検索ユニットであり、技術メタデータとビジネス メタデータの両方を備えています。 構造化データから技術メタデータを収集するために、AWS Glue クローラーを利用して、CSV、JSON、Avro、Apache Parquet などの最も一般的なデータ形式からデータ構造を認識して抽出します。 データ型、作成日、形式などの情報を提供します。 ビジネス ユーザーは、ビジネス コンテキスト、タグ、およびデータ分類の説明を追加することで、メタデータを充実させることができます。
データセット定義と関連するメタデータは、 Amazon Auroraサーバーレス データベースと AmazonOpenSearchサービス、データ カタログでテキスト クエリを実行できるようにします。
データ共有
NNEDH はデータ共有ワークフローを実装し、Lake Formation を使用して AWS アカウント間でピアツーピアのデータ共有を可能にします。 ワークフローは次のとおりです。
- データ コンシューマは、データセットへのアクセスを要求します。
- データ所有者は、アクセス要求を承認することでアクセスを許可します。 アクセス要求の承認をデータ スチュワードに委任できます。
- アクセス要求が承認されると、プロデューサー アカウントの Lake Formation の特定のデータセットに新しいアクセス許可が追加されます。
次の図は、データ共有ワークフローを概略的に示しています。

セキュリティと監査
ノボ ノルディスクのデータ メッシュ内のデータは、ノボ ノルディスクのビジネス アカウントが所有する AWS アカウントにあります。 データ メッシュの構成と状態は次の場所に保存されます。 Amazon リレーショナル データベース サービス (アマゾン RDS)。 Novo Nordisk のセキュリティ アーキテクチャを次の図に示します。

NNEDH のデータへのアクセスと編集は、監査目的でログに記録する必要があります。 誰がデータを変更したか、いつ変更が行われたか、どの変更が適用されたかを知る必要があります。 さらに、その時点でその人が変更を許可した理由を答えることができる必要があります。
これらの要件を満たすために、次のコンポーネントを使用します。
- API 呼び出しをログに記録するための CloudTrail。 特に、S3 バケットとオブジェクトの CloudTrail データ イベント ログを有効にします。 ログ記録を有効にすることで、データ レイク内の任意のファイルへの変更を、変更を行った人物まで追跡できます。 の使用を強制します ソース ID ユーザーのトレーサビリティを確保するための IAM ロール セッションの場合。
- Amazon RDS を使用して、データ メッシュの構成を保存します。 RDS データベースに対するクエリをログに記録します。 このログを CloudTrail と組み合わせることで、特定の人が特定の時間に Amazon S3 のファイルを変更できる理由についての質問に答えることができます。
- アマゾンクラウドウォッチ メッシュ全体のアクティビティを記録します。
これらのロギング メカニズムに加えて、S3 バケットは次のプロパティを使用して作成されます。
- バケットは、サーバー側の暗号化を使用して暗号化されます AWSキー管理サービス (AWS KMS) および顧客管理のキー
- Amazon S3 のバージョニングはデフォルトで有効化されています
NNEDH のデータへのアクセスは、個々のユーザーではなくグループ レベルで制御されます。 このグループは、Novo Nordisk ディレクトリ グループで定義されたグループに対応します。 データ レイク内のデータを変更した人物を追跡するために、投稿で説明されているソース ID メカニズムを使用します。 IAM ロール アクティビティを企業アイデンティティに関連付ける方法.
まとめ
この投稿では、Novo Nordisk が最新のデータ アーキテクチャを構築して、データ駆動型のユース ケースの配信を高速化した方法を紹介しました。 これには、バリュー チェーン全体で 2,000 人を超える内部ユーザーの使用をペタバイト規模にスケーリングするための分散データ アーキテクチャと、コンプライアンス要件を満たすために環境でのデータ アカウンタビリティとトレーサビリティを処理する分散セキュリティおよび監査アーキテクチャが含まれます。
このシリーズの次の投稿では、ノボ ノルディスクの最新のデータ アーキテクチャの大規模な分散型データ ガバナンスと制御の実装について説明します。
著者について
 ジョナタン・セルシング は天体物理学の博士号を取得した元研究科学者で、クラウドに移行しました。 彼は現在、Novo Nordisk のリード クラウド エンジニアであり、データと分析のワークロードを大規模に実現しています。 クラウドベースのワークロードの総所有コストを削減することに重点を置いて、クラウドの利点を最大限に活用しながら、将来の医薬品の研究を可能にするソリューションを設計、構築、維持しています。
ジョナタン・セルシング は天体物理学の博士号を取得した元研究科学者で、クラウドに移行しました。 彼は現在、Novo Nordisk のリード クラウド エンジニアであり、データと分析のワークロードを大規模に実現しています。 クラウドベースのワークロードの総所有コストを削減することに重点を置いて、クラウドの利点を最大限に活用しながら、将来の医薬品の研究を可能にするソリューションを設計、構築、維持しています。
 ハッセンリアヒ AWS プロフェッショナル サービスのシニア データ アーキテクトです。 彼は、大規模なデータ管理に関する数学とコンピューター サイエンスの博士号を取得しています。 彼は AWS のお客様と協力して、データ駆動型のソリューションを構築しています。
ハッセンリアヒ AWS プロフェッショナル サービスのシニア データ アーキテクトです。 彼は、大規模なデータ管理に関する数学とコンピューター サイエンスの博士号を取得しています。 彼は AWS のお客様と協力して、データ駆動型のソリューションを構築しています。
 アンワル・リサール パリを拠点とするシニア機械学習コンサルタントです。 彼は AWS のお客様と協力して、ビジネスを持続的に成長させるためのデータおよび AI ソリューションを開発しています。
アンワル・リサール パリを拠点とするシニア機械学習コンサルタントです。 彼は AWS のお客様と協力して、ビジネスを持続的に成長させるためのデータおよび AI ソリューションを開発しています。
 モーセ・アーサー 数学と計算研究のバックグラウンドを持ち、グラフマイニングに特化した計算知能の博士号を取得しています。 彼は現在、ノボ ノルディスクのクラウド プロダクト エンジニアであり、デジタル化された医療製品を生産するノボ ノルディスクのグローバル工場向けに、GxP 準拠のエンタープライズ データ レイクと分析プラットフォームを構築しています。
モーセ・アーサー 数学と計算研究のバックグラウンドを持ち、グラフマイニングに特化した計算知能の博士号を取得しています。 彼は現在、ノボ ノルディスクのクラウド プロダクト エンジニアであり、デジタル化された医療製品を生産するノボ ノルディスクのグローバル工場向けに、GxP 準拠のエンタープライズ データ レイクと分析プラットフォームを構築しています。
 アレッサンドロ・フィオール AWS プロフェッショナル サービスのシニア データ アーキテクトです。 データおよび分析ソリューションを提供してきた 10 年以上の経験を持つ彼は、企業がデータから価値を引き出すことを促進する最新のスケーラブルなデータ プラットフォームの設計と構築に情熱を注いでいます。
アレッサンドロ・フィオール AWS プロフェッショナル サービスのシニア データ アーキテクトです。 データおよび分析ソリューションを提供してきた 10 年以上の経験を持つ彼は、企業がデータから価値を引き出すことを促進する最新のスケーラブルなデータ プラットフォームの設計と構築に情熱を注いでいます。
 クマリ・ラマー は、AWS プロフェッショナル サービスのアジャイル認定および PMP 認定のシニア エンゲージメント マネージャーです。 彼女は、クロスシステム分析と機械学習モデルを高速化するデータと AI/ML ソリューションを提供し、企業がデータ主導の意思決定を行い、新しいイノベーションを推進できるようにします。
クマリ・ラマー は、AWS プロフェッショナル サービスのアジャイル認定および PMP 認定のシニア エンゲージメント マネージャーです。 彼女は、クロスシステム分析と機械学習モデルを高速化するデータと AI/ML ソリューションを提供し、企業がデータ主導の意思決定を行い、新しいイノベーションを推進できるようにします。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/how-novo-nordisk-built-a-modern-data-architecture-on-aws/

