この投稿は、ナショナル フットボール リーグのジョナサン ユング、マイク バンド、マイケル チー、トンプソン ブリスと共著しています。
A カバレッジスキーム オフェンシブ パスを阻止する任務を負った各サッカー ディフェンダーのルールと責任を指します。 これは、サッカーの守備戦略を理解し、分析するための核となるものです。 すべてのパス プレーのカバレッジ スキームを分類することで、チーム、放送局、ファンにフットボールの試合の洞察を提供できます。 たとえば、プレーコーラーの好みを明らかにし、それぞれのコーチやチームが対戦相手の強みに基づいて戦略を継続的に調整する方法をより深く理解できるようにし、カバレッジの独自性などの新しい防御指向の分析の開発を可能にします (セスら。)。 ただし、プレーごとにこれらのカバレッジを手動で特定することは、サッカーの専門家が試合の映像を注意深く検査する必要があるため、面倒で困難です。 コストとターンアラウンド タイムを削減するために効果的かつ効率的にスケーリングできる、自動化されたカバレッジ分類モデルが必要です。
NFLの 次世代統計 は、NFL フットボール ゲームのすべてのプレーヤーとプレイのリアルタイムの位置、速度などをキャプチャし、ゲームのさまざまな側面をカバーするさまざまな高度な統計情報を取得します。 Next Gen Stats チームと Amazon MLソリューションラボ、プレーヤーの追跡データに基づいて防御カバレッジスキームを正確に識別する機械学習 (ML) を利用したカバレッジ分類の統計を開発しました。 カバレッジ分類モデルは、次を使用してトレーニングされます。 アマゾンセージメーカー、そして統計はされています 2022年のNFLシーズンに向けて発売.
この投稿では、この ML モデルの技術的な詳細を深く掘り下げます。 正確で説明可能な ML モデルを設計して、プレーヤーの追跡データからカバレッジ分類を行う方法について説明し、続いて定量的評価とモデル説明の結果を示します。
問題の定式化と課題
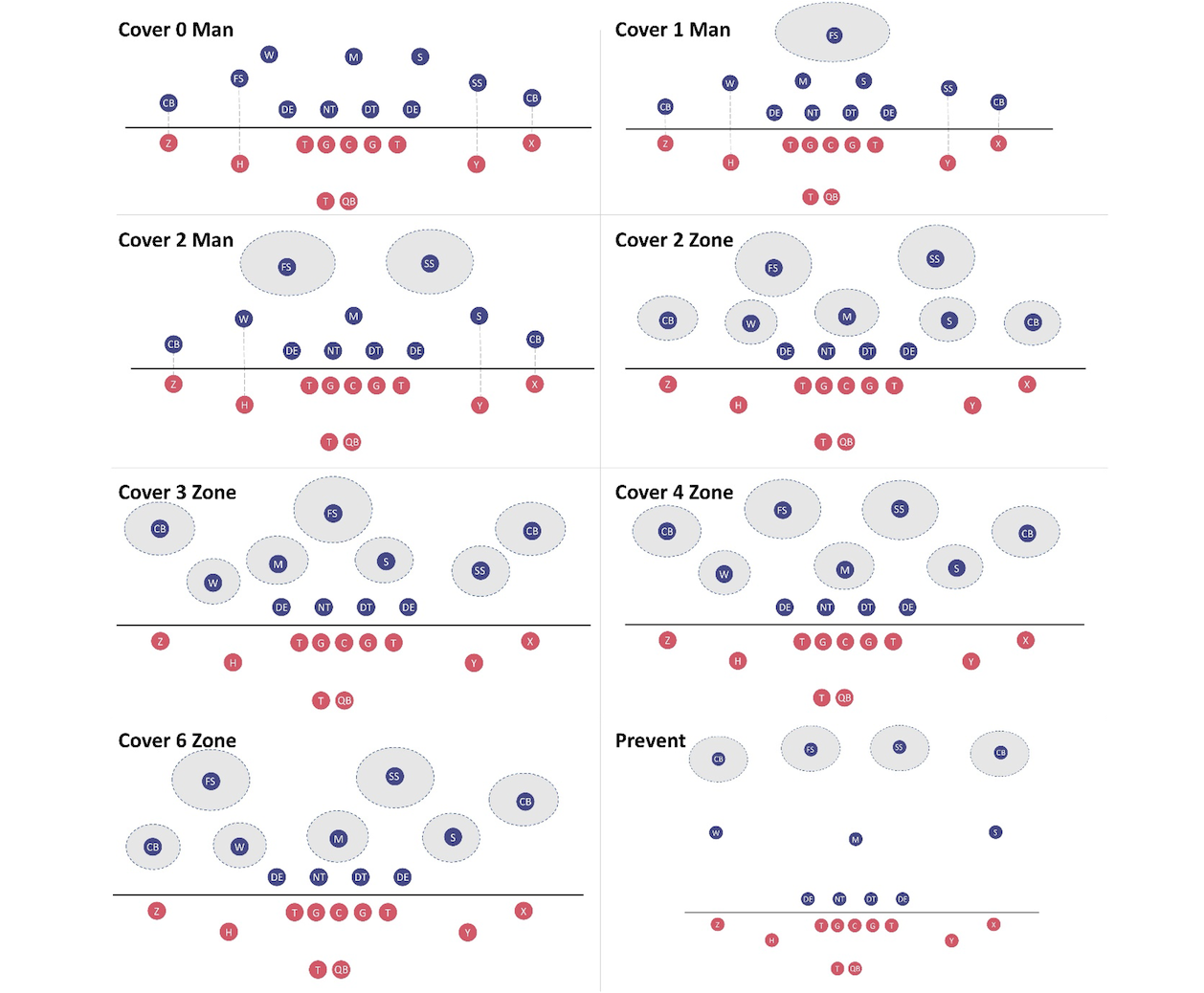
ディフェンシブ カバレッジの分類は、0 種類のマン カバレッジ (各ディフェンス プレーヤーが特定のオフェンス プレーヤーをカバーする) と 1 種類のゾーン カバレッジ (各ディフェンス プレーヤーがフィールド上の特定の領域をカバーする) を含むマルチクラス分類タスクとして定義します。 これらの 2 つのクラスは、次の図に視覚的に示されています: Cover 2 Man、Cover 3 Man、Cover 4 Man、Cover 6 Zone、Cover XNUMX Zone、Cover XNUMX Zone、Cover XNUMX Zone、および Prevent (ゾーン カバレッジも)。 青色の円は、特定のタイプのカバレッジに配置されたディフェンシブ プレーヤーです。 赤い円は攻撃的なプレーヤーです。 プレーヤーの頭字語の完全なリストは、この投稿の最後の付録に記載されています。
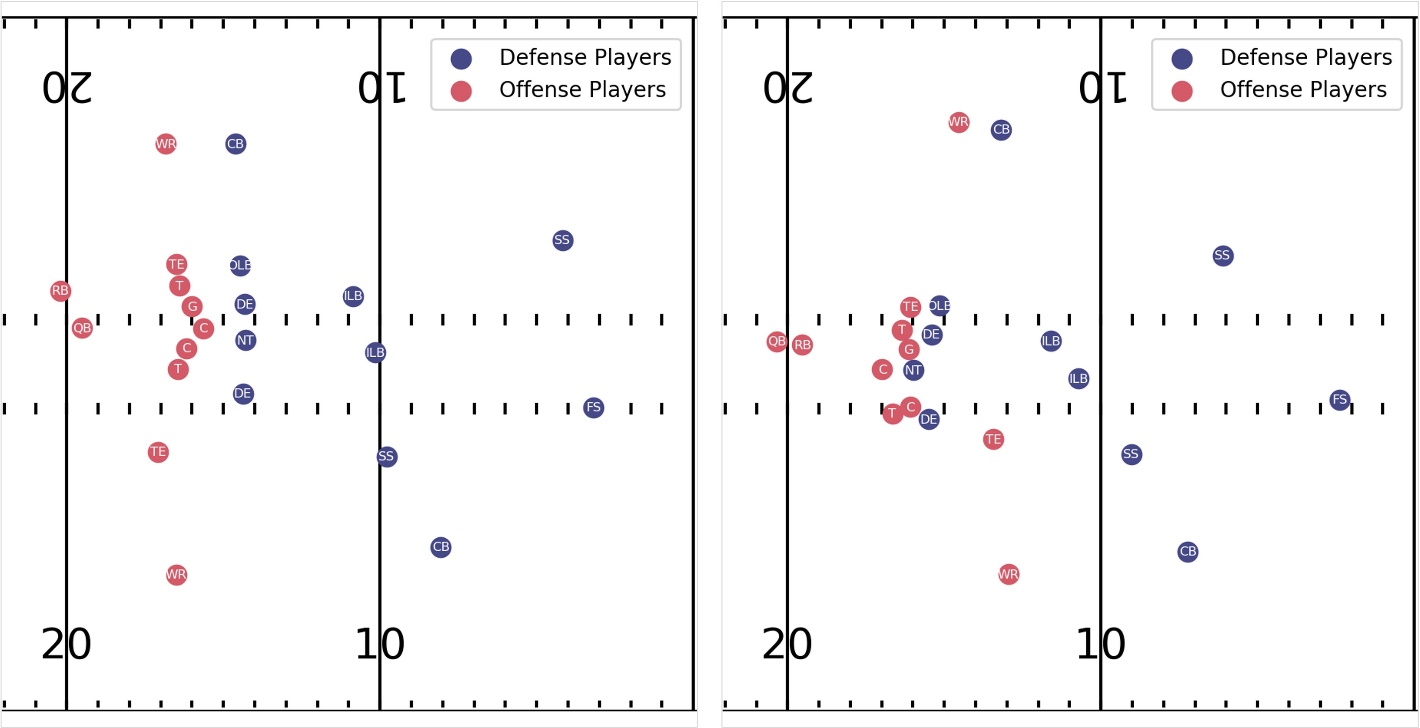
次のビジュアライゼーションは、プレイの開始時 (左) と同じプレイの途中 (右) でのすべての攻撃的および防御的プレーヤーの位置を示すプレイの例を示しています。 正確なカバレッジ識別を行うには、スナップ前のディフェンダーの整列方法や、ボールがスナップされた後のオフェンス プレーヤーの動きの調整など、時間の経過に伴う多数の情報を考慮する必要があります。 これは、モデルがプレイヤー間の時空間的、そしてしばしば微妙な動きと相互作用をキャプチャするという課題をもたらします。
私たちのパートナーシップが直面するもう XNUMX つの重要な課題は、展開されたカバレッジ スキームに関する固有のあいまいさです。 一般的に知られている XNUMX つのカバレッジ スキームを超えて、手動チャート作成とモデル分類の両方で XNUMX つの一般的なクラスの間であいまいさにつながる、より具体的なカバレッジ コールの調整を特定しました。 改善されたトレーニング戦略とモデルの説明を使用して、これらの課題に取り組みます。 次のセクションで、私たちのアプローチについて詳しく説明します。
説明可能なカバレッジ分類フレームワーク
次の図に全体的なフレームワークを示します。プレーヤーの追跡データとカバレッジ ラベルの入力は図の上部から始まります。
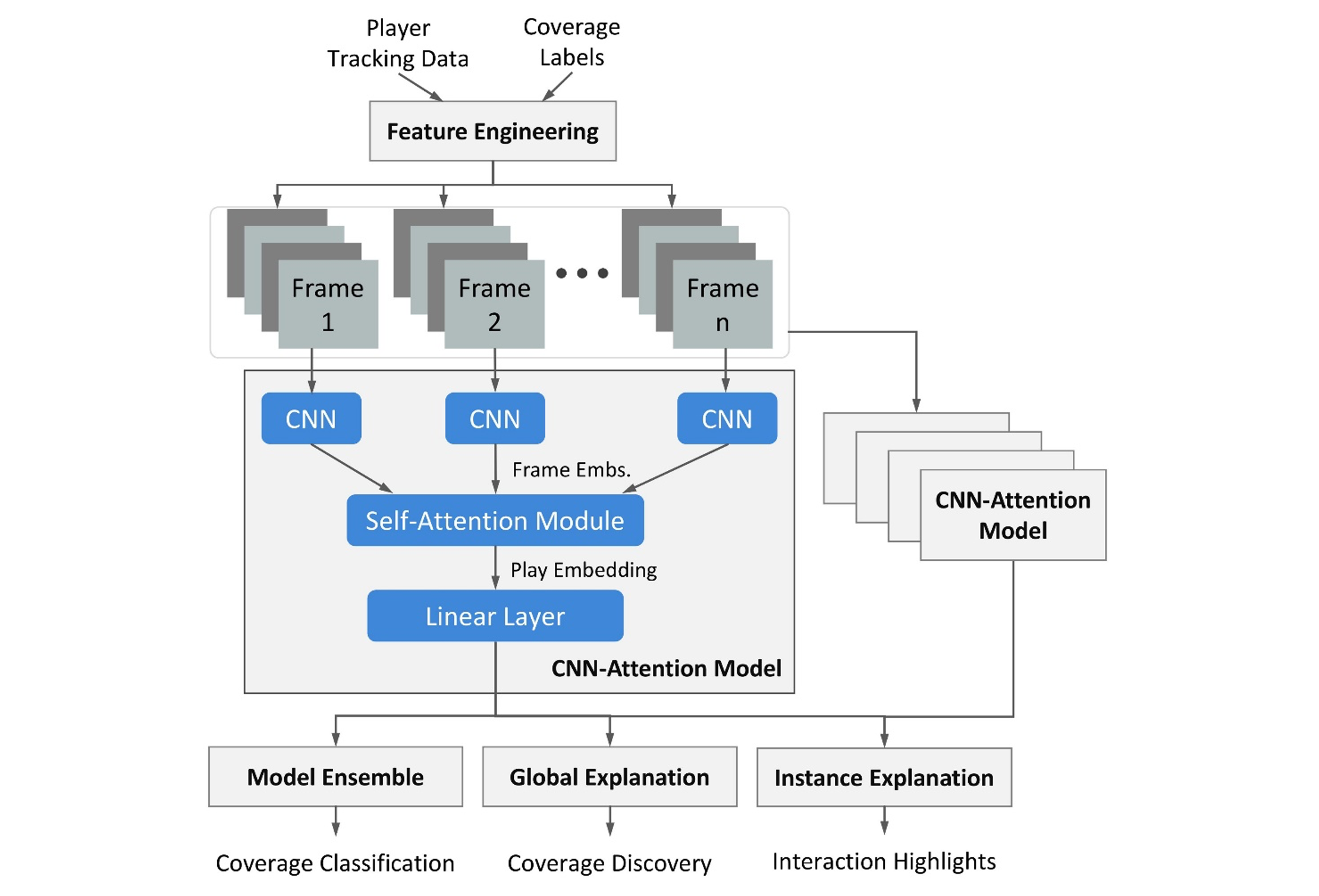
機能エンジニアリング
ゲーム トラッキング データは、プレーヤーの位置、速度、加速度、向きなど、毎秒 10 フレームでキャプチャされます。 私たちの機能エンジニアリングは、モデル消化の入力として一連のプレイ機能を構築します。 特定のフレームについて、私たちの機能は 2020 Big Data Bowl Kaggle Zoo ソリューション (ゴルディーエフ等。): 時間ステップごとに、防御側のプレーヤーを行に、攻撃側のプレーヤーを列に配置して画像を作成します。 したがって、画像のピクセルは、交差するプレーヤーのペアの特徴を表します。 と違う ゴルディーエフ等。、フレーム表現のシーケンスを抽出し、プレイを特徴付けるミニビデオを効果的に生成します。
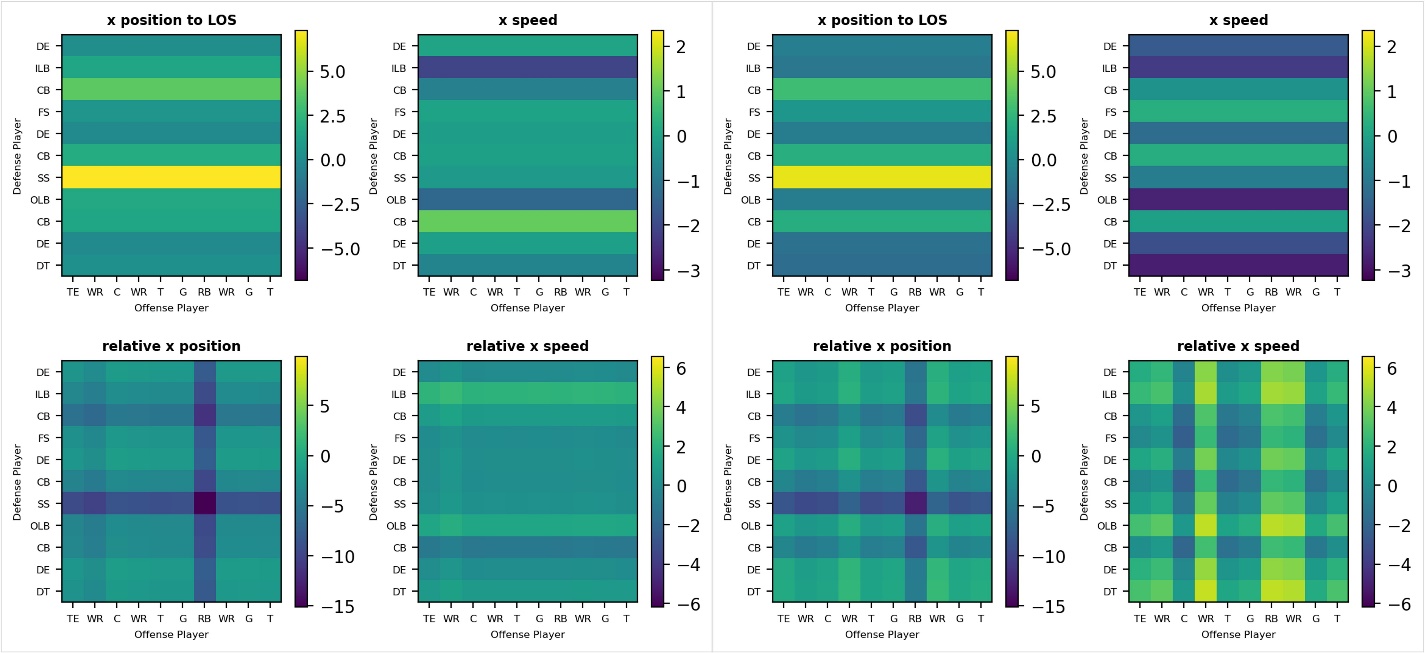
次の図は、プレイ例の XNUMX つのスナップショットに対応して、時間の経過とともに機能がどのように進化するかを視覚化したものです。 見やすくするために、抽出したすべての機能のうち XNUMX つの機能のみを示しています。 図中の「LOS」はスクリメージ ラインを表し、x 軸はサッカー フィールドの右側の水平方向を表します。 カラーバーで示される特徴値が、プレーヤーの動きに応じて時間の経過とともにどのように変化するかに注目してください。 全体として、次のように XNUMX つの機能セットを構築します。
- x 軸 (サッカー場の右側の水平方向) と y 軸 (サッカー場の上部の垂直方向) 上のディフェンダーの位置、速度、加速度、方向から構成されるディフェンダーの特徴
- 同じ属性で構成されるが、防御側と攻撃側のプレーヤーの違いとして計算される、防御側と攻撃側の相対的な特徴
CNN モジュール
畳み込みニューラル ネットワーク (CNN) を利用して、オープン ソースのフットボール (ボールドウィン等。) および Big Data Bowl Kaggle Zoo ソリューション (ゴルディーエフ等。)。 特徴量エンジニアリングから得られた画像は、CNN による各プレイ フレームのモデリングを容易にしました。 Zoo ソリューションで使用される畳み込み (Conv) ブロックを変更しました (ゴルディーエフ等。) 浅い 1 層 CNN と深い 1 層 CNN で構成される分岐構造を持つ。 畳み込み層は内部で XNUMX×XNUMX カーネルを使用します。カーネルが各プレーヤー ペアを個別に調べることで、モデルがプレーヤーの順序付けに対して不変であることを保証します。 簡単にするために、すべてのプレー サンプルについて、NFL ID に基づいてプレーヤーを並べ替えます。 フレーム埋め込みを CNN モジュールの出力として取得します。
時間モデリング
わずか数秒の短い再生期間内に、カバレッジを識別するための重要な指標として豊富な時間ダイナミクスが含まれています。 Zoo ソリューションで使用されているフレームベースの CNN モデリング (ゴルディーエフ等。)、一時的な進行を説明していません。 この課題に取り組むために、自己注意モジュール (バスワニ等。)、時間モデリングのために CNN の上に積み上げられます。 トレーニング中に、個々のフレームを異なる方法で重み付けすることにより、それらを集約することを学習します (アラマー等。)。 定量的評価において、従来の双方向 LSTM アプローチと比較します。 出力としての学習された注意の埋め込みは、プレイ全体の埋め込みを取得するために平均化されます。 最後に、全結合層を結合して、プレーのカバレッジ クラスを決定します。
モデル アンサンブルとラベルの平滑化
XNUMX つのカバレッジ スキーム間のあいまいさとそれらの不均衡な分布により、カバレッジ間の明確な分離が困難になります。 モデル アンサンブルを利用して、モデル トレーニング中にこれらの課題に取り組みます。 私たちの研究では、最も単純なアンサンブル手法の XNUMX つである投票ベースのアンサンブルが、実際にはより複雑なアプローチよりも優れていることがわかりました。 この方法では、各基本モデルは同じ CNN アテンション アーキテクチャを持ち、異なるランダム シードから独立してトレーニングされます。 最終的な分類では、すべての基本モデルからの出力の平均を取ります。
さらに、ラベルの平滑化を組み込みます (ミュラーら。) クロスエントロピー損失に変換して、手動チャート ラベルの潜在的なノイズを処理します。 ラベルの平滑化は、注釈付きのカバレッジ クラスを残りのクラスにわずかに向けます。 アイデアは、偏った注釈に過適合するのではなく、モデルが固有のカバレッジのあいまいさに適応することを奨励することです。
定量的評価
モデルのトレーニングと検証には 2018 ~ 2020 シーズンのデータを使用し、モデルの評価には 2021 シーズンのデータを使用します。 各シーズンは約 17,000 回の再生で構成されます。 トレーニング中に最適なモデルを選択するために XNUMX 分割の交差検証を実行し、複数のモデル アーキテクチャとトレーニング パラメーターで最適な設定を選択するためにハイパーパラメーターの最適化を実行します。
モデルのパフォーマンスを評価するために、カバレッジの精度、F1 スコア、トップ 2 の精度、およびより簡単な人間とゾーンのタスクの精度を計算します。 で使用されている CNN ベースの Zoo モデル ボールドウィン等。 カバレッジ分類に最も関連性が高く、ベースラインとして使用します。 さらに、比較研究のために時間モデリング コンポーネントを組み込んだベースラインの改良版を検討します。双方向 LSTM を使用して時間モデリングを実行する CNN-LSTM モデルと、アンサンブルとラベルのない単一の CNN アテンション モデルです。スムージング コンポーネント。 結果を次の表に示します。
| モデル | 試験精度 8 カバレッジ (%) | トップ 2 精度 8 カバレッジ (%) | F1スコア 8つのカバレッジ | 試験精度 男 vs. ゾーン (%) |
| ベースライン: 動物園モデル | 68.8 0.4± | 87.7 0.1± | 65.8 0.4± | 88.4 0.4± |
| CNN-LSTM | 86.5 0.1± | 93.9 0.1± | 84.9 0.2± | 94.6 0.2± |
| CNN-アテンション | 87.7 0.2± | 94.7 0.2± | 85.9 0.2± | 94.6 0.2± |
| 私たちのもの: 5 つの CNN アテンション モデルのアンサンブル | 88.9 0.1± | 97.6 0.1± | 87.4 0.2± | 95.4 0.1± |
時間モデリング モジュールを組み込むことで、単一フレームに基づくベースラインの Zoo モデルが大幅に改善されることがわかります。 CNN-LSTM モデルの強力なベースラインと比較して、自己注意モジュール、モデル アンサンブル、ラベリング スムージングを組み合わせた提案されたモデリング コンポーネントは、パフォーマンスを大幅に改善します。 最終的なモデルは、評価尺度によって示されるようにパフォーマンスが高いです。 さらに、トップ 2 の精度が非常に高く、トップ 1 の精度との大きな差があることがわかりました。 これは、カバレッジのあいまいさが原因である可能性があります。最上位の分類が正しくない場合、2 番目の推測は人間による注釈と一致することがよくあります。
モデルの説明と結果
カバレッジのあいまいさを明らかにし、モデルが特定の結論に到達するために何を利用したかを理解するために、モデルの説明を使用して分析を実行します。 これは XNUMX つの部分で構成されています。学習したすべての埋め込みをまとめて分析するグローバルな説明と、モデルによってキャプチャされた最も重要なシグナルを分析するために個々のプレイにズームインするローカルな説明です。
グローバルな説明
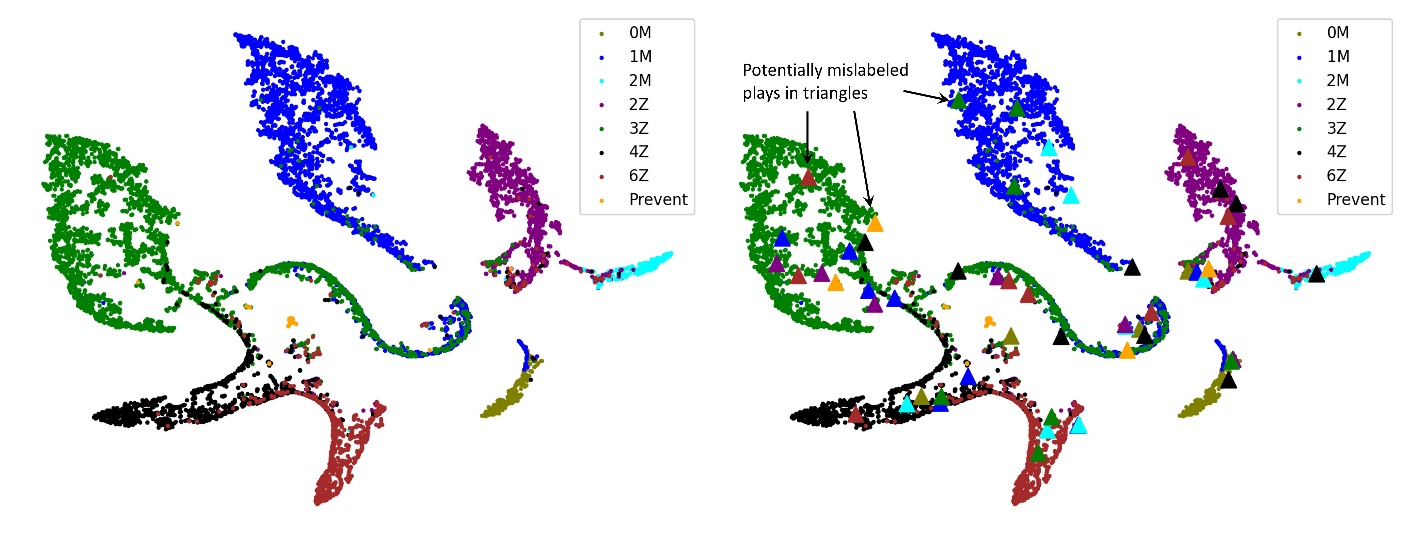
この段階では、カバレッジ分類モデルから学習したプレイの埋め込みをグローバルに分析して、手作業によるレビューが必要なパターンを発見します。 t 分布確率的近隣埋め込み (t-SNE) (マーテン等。) プレイの埋め込みを 2D 空間に射影する類似の埋め込みのペアは、それらの分布に高い確率を持っています。 安定した 2D 投影を抽出するために、内部パラメーターを試します。 次の図 (左) は、9,000 回のプレイの階層化されたサンプルからの埋め込みを視覚化したもので、各ドットは特定のプレイを表しています。 各カバレッジ スキームの大部分が適切に分離されており、モデルによって得られた分類機能が実証されていることがわかります。 XNUMX つの重要なパターンを観察し、さらに調査します。
次の図 (右) に示すように、一部のプレイは他のカバレッジ タイプに混在しています。 これらのプレイは誤ってラベル付けされている可能性があり、手動で検査する必要があります。 K-Nearest Neighbors (KNN) 分類器を設計して、これらのプレイを自動的に識別し、エキスパート レビューに送信します。 結果は、それらのほとんどが実際に誤ってラベル付けされたことを示しています。
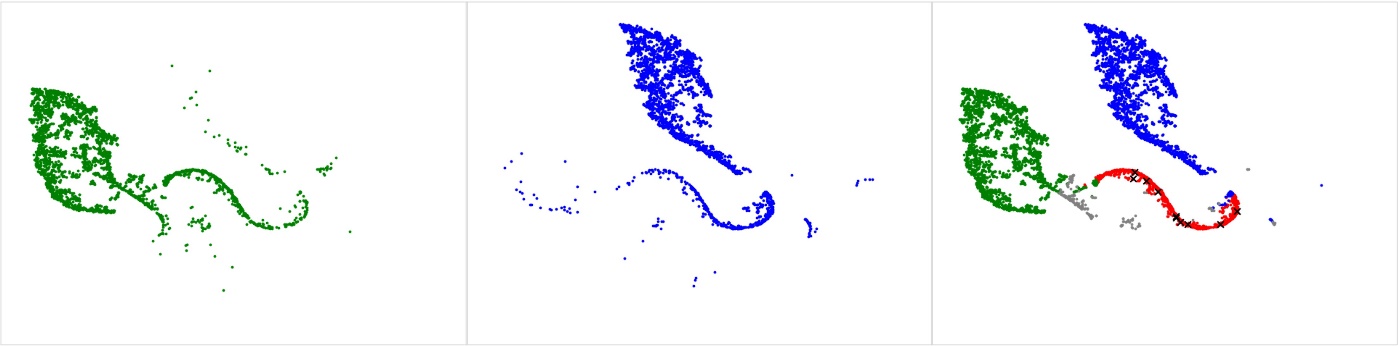
次に、特定のシナリオでカバレッジのあいまいさを明示する、カバレッジ タイプ間でいくつかの重複領域を観察します。 例として、次の図では、Cover 3 Zone (左側の緑色のクラスター) と Cover 1 Man (中央の青色のクラスター) を分離しています。 これらは 10 つの異なるシングルハイ カバレッジの概念であり、主な違いは人対ゾーン カバレッジです。 これら 3 つのクラス間のあいまいさをクラスターの重複領域として自動的に識別するアルゴリズムを設計します。 結果は、次の右の図の赤い点として視覚化され、手動で確認するために、ランダムにサンプリングされた XNUMX のプレイが黒い「x」でマークされています。 私たちの分析によると、この地域のほとんどのプレイ例には、何らかのパターン マッチングが含まれています。 これらのプレーでは、カバレッジの責任は、攻撃的なレシーバーのルートがどのように分布しているかに左右され、調整により、プレーがゾーンとマンのカバレッジが混在しているように見える可能性があります. 私たちが特定したそのような調整の XNUMX つは、カバー XNUMX ゾーンに適用されます。これは、片側のコーナーバック (CB) がマン カバレッジ (「Man Everywhere he Goes」または MEG) に固定され、もう一方が従来のゾーン ドロップを持っている場合です。
インスタンスの説明
第 XNUMX 段階では、インスタンスの説明が関心のある個々のプレーにズームインし、特定されたカバレッジ スキームに最も貢献するフレームごとのプレーヤー インタラクションのハイライトを抽出します。 これは、Guided GradCAM アルゴリズム (Ramprasaath等。)。 信頼度の低いモデルの予測では、インスタンスの説明を利用します。
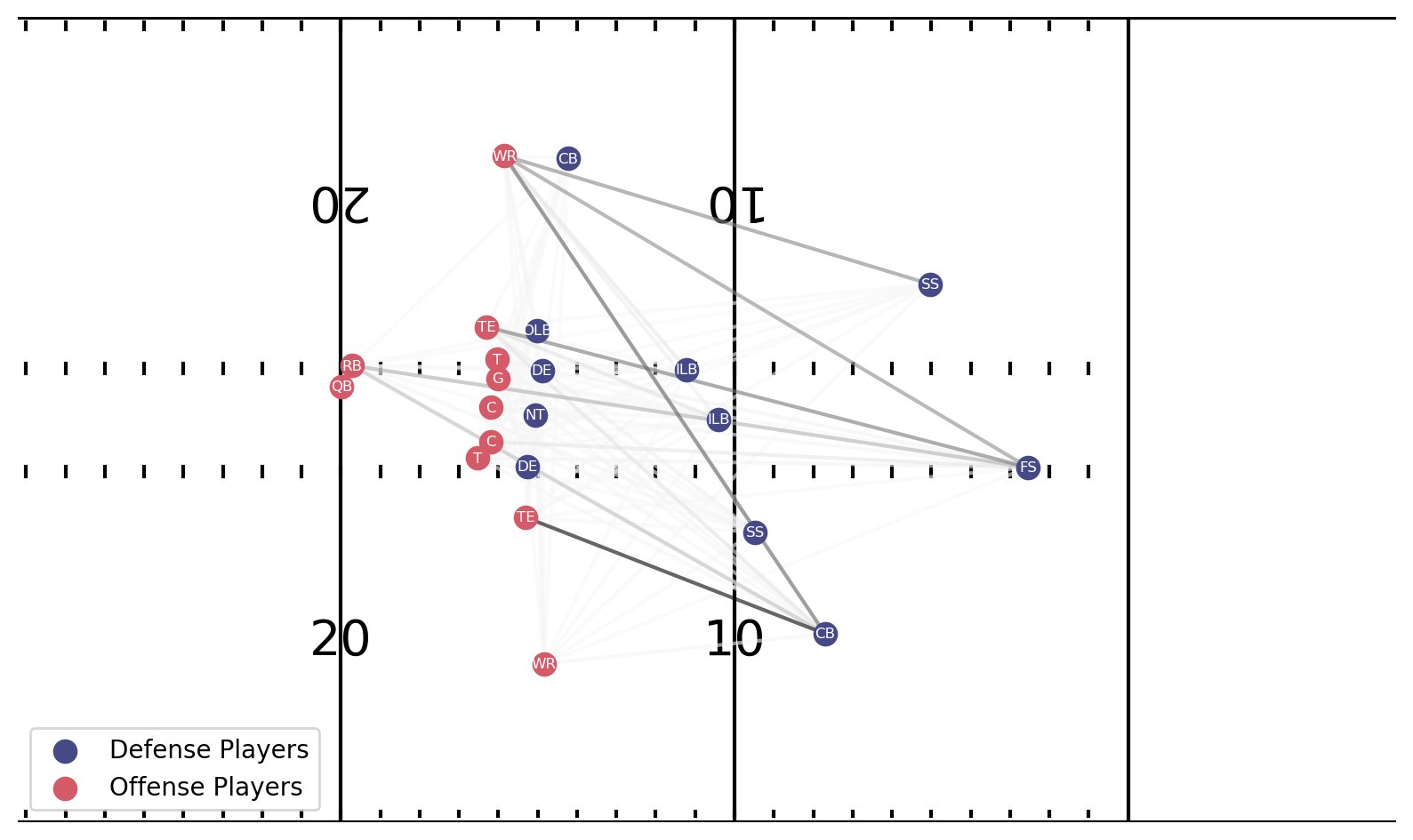
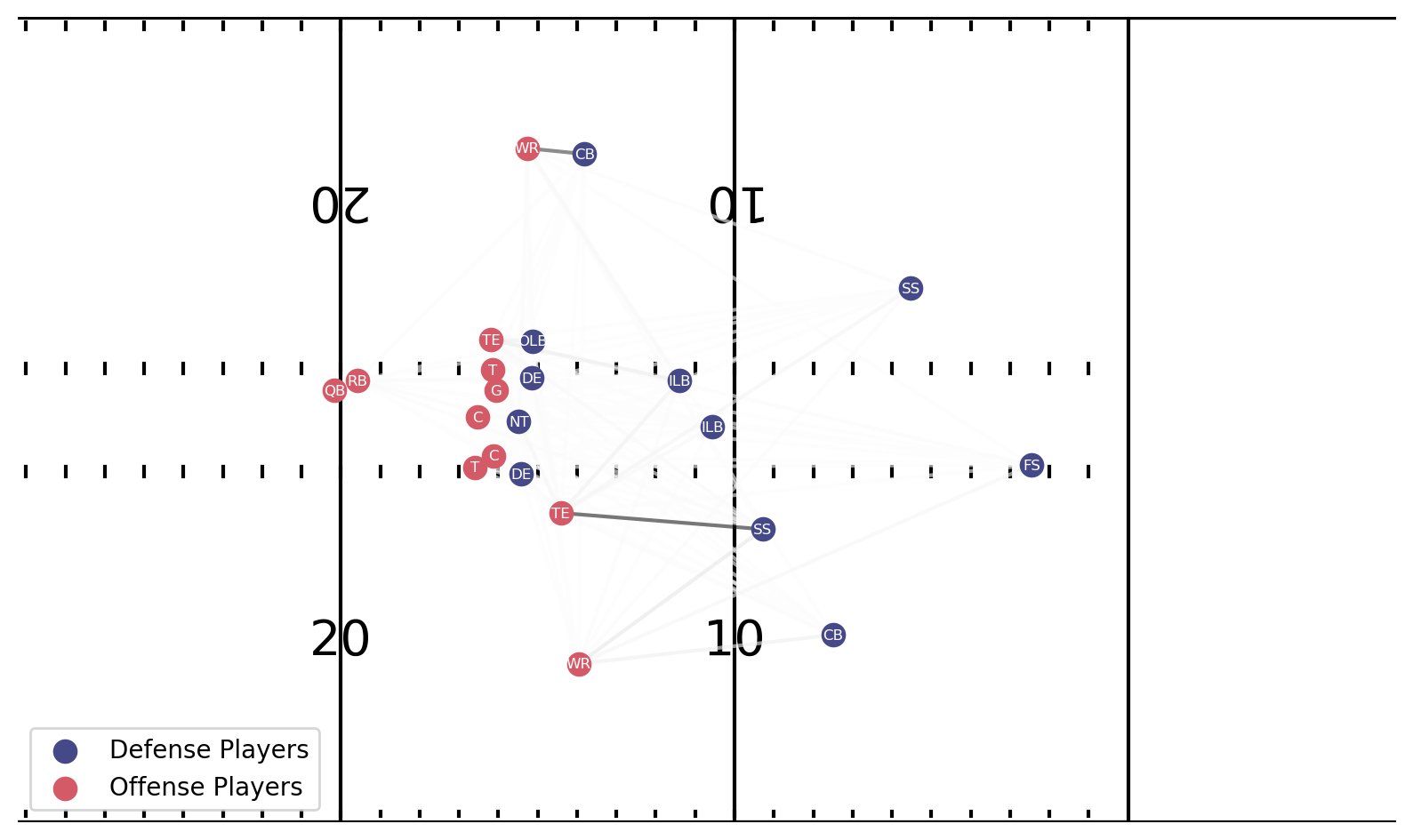
記事の冒頭で説明したプレイでは、モデルはカバー 3 ゾーンを 44.5% の確率で予測し、カバー 1 マンを 31.3% の確率で予測しました。 次の図に示すように、両方のクラスの説明結果を生成します。 線の太さは、モデルの識別に寄与する相互作用の強さを示します。
カバー 3 ゾーンの説明の一番上のプロットは、ボール スナップの直後です。 オフェンス側の右側にいる CB は、QB に面してその場にとどまっているため、最も強い相互作用線を持っています。 彼は結局、彼を深く脅かす彼の側のレシーバーと四角くなり、一致します。
カバー 1 マンの説明の一番下のプロットは、プレイ アクション フェイクが発生しているため、しばらく後に表示されます。 最も強力な相互作用の XNUMX つは、オフェンスの左にいる CB との相互作用です。CB は WR と一緒にドロップしています。 プレーの映像は、彼がQBに目を向けてから、ひっくり返り、彼を深く脅かしているWRと一緒に走っていることを明らかにしています. オフェンス側の右の SS も、TE が内側に侵入するとシャッフルを開始するため、彼の側の TE と強い相互作用を持っています。 彼はフォーメーションを横切って彼を追いかけることになりますが、TE は彼をブロックし始め、プレーがランパスオプションである可能性が高いことを示しています。 これは、モデルの分類の不確実性を説明しています。TE は設計上 SS に固執しており、データにバイアスが生じています。
まとめ
Amazon ML Solutions Lab と NFL の Next Gen Stats チームは共同で、最近発表された防御範囲分類統計を開発しました。 2022 NFL フットボール シーズンに向けて発売. この投稿では、高速な時間的進行のモデリング、カバレッジ クラスのあいまいさを処理するためのトレーニング戦略、グローバル レベルとインスタンス レベルの両方でエキスパート レビューを高速化するための包括的なモデルの説明など、この統計の ML 技術的詳細を紹介しました。
このソリューションにより、放送局がゲーム内で初めてライブの守備範囲の傾向と分割を利用できるようになります。 同様に、このモデルにより、NFL は試合後の結果の分析を改善し、試合に至るまでの主要な対戦をより適切に特定することができます。
ML の使用を促進するためのサポートが必要な場合は、 Amazon MLソリューションラボ プログラム。
付録
| プレーヤーの位置の頭字語 | |
| 守備位置 | |
| W | 「意志」のあるラインバッカー、または弱い側のLB |
| M | 「マイク」ラインバッカー、またはミドルLB |
| S | 「サム」ラインバッカー、またはストロングサイドLB |
| CB | コーナーバック |
| DE | ディフェンシブエンド |
| DT | ディフェンシブタックル |
| NT | ノーズタックル |
| FS | 無料の安全性 |
| SS | 強力な安全性 |
| S | 安全性 |
| LB | ラインバッカー |
| HE B | インサイド ラインバッカー |
| OLB | アウトサイドラインバッカー |
| MLB | ミドルラインバッカー |
| 攻撃的なポジション | |
| X | 通常、オフェンスではナンバー 1 のワイド レシーバーであり、LOS に配置されます。 トリップのフォーメーションでは、このレシーバーはバックサイドに分離して配置されることがよくあります。 |
| Y | 通常、タイトエンドの先発であるこのプレーヤーは、インラインで X とは反対側に配置されることがよくあります。 |
| Z | 通常、スロット レシーバーのほうが多いこのプレーヤーは、多くの場合、スクリメージ ラインから外れて、フィールドのタイト エンドと同じ側に配置されます。 |
| H | 伝統的にフルバックであるこのプレーヤーは、現代のリーグではサードワイドレシーバーまたはセカンドタイトエンドであることが多い. 彼らはフォーメーション全体で整列できますが、ほとんどの場合、スクリメージ ラインから外れています。 チームによっては、この選手をFに指定することもできます。 |
| T | 注目のランニングバック。 空のフォーメーション以外では、このプレーヤーはバックフィールドに整列し、ハンドオフを受ける脅威になります。 |
| QB | クォーターバック |
| C | センター |
| G | ガード |
| RB | ランニングバック |
| FB | フルバック |
| WR | ワイドレシーバ |
| TE | タイトエンド |
| LG | 左ガード |
| RG | ライトガード |
| T | タックル |
| LT | 左タックル |
| RT | 右タックル |
参考文献
- Tej Seth、Ryan Weisman、「PFF データ調査: 各チームのカバレッジ スキームの一意性と、それがコーチングの変更に与える影響」、 https://www.pff.com/news/nfl-pff-data-study-coverage-scheme-uniqueness-for-each-team-and-what-that-means-for-coaching-changes
- ベン・ボールドウィン。 「R のトーチを使用した NFL プレーヤーの追跡データを使用したコンピューター ビジョン: CNN を使用したカバレッジ分類」。 https://www.opensourcefootball.com/posts/2021-05-31-computer-vision-in-r-using-torch/
- ドミトリー・ゴルデーエフ、フィリップ・シンガー。 「第 1 位のソリューション The Zoo.」 https://www.kaggle.com/c/nfl-big-data-bowl-2020/discussion/119400
- Vaswani、Ashish、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Łukasz Kaiser、Illia Polosukhin。 「必要なのは注意だけです。」 神経情報処理システムの進歩 30(2017)。
- ジェイ・アラマー。 「ザ・イラストレイテッド・トランスフォーマー」。 https://jalammar.github.io/illustrated-transformer/
- ミュラー、ラファエル、サイモン・コーンブリス、ジェフリー・E・ヒントン。 「ラベル スムージングはどのような場合に役立ちますか?」 神経情報処理システムの進歩 32 (2019).
- ファン・デル・マーテン、ローレンス、ジェフリー・ヒントン。 「t-SNE を使用したデータの視覚化。」 機械学習研究 9、いいえ。 11(2008)
- Selvaraju、Ramprasaath R.、Michael Cogswell、Abhishek Das、Ramakrishna Vedantam、Devi Parikh、Dhruv Batra。 「Grad-cam: 勾配ベースのローカリゼーションによるディープ ネットワークからの視覚的な説明。」 の コンピュータビジョンに関するIEEE国際会議の議事録、pp。 618-626。 3.
著者について
 桓宋 は、Amazon Machine Learning Solutions Lab の応用科学者であり、さまざまな業種の影響の大きい顧客のユースケース向けのカスタム ML ソリューションの提供に取り組んでいます。 彼の研究対象は、グラフ ニューラル ネットワーク、コンピューター ビジョン、時系列分析、およびそれらの産業への応用です。
桓宋 は、Amazon Machine Learning Solutions Lab の応用科学者であり、さまざまな業種の影響の大きい顧客のユースケース向けのカスタム ML ソリューションの提供に取り組んでいます。 彼の研究対象は、グラフ ニューラル ネットワーク、コンピューター ビジョン、時系列分析、およびそれらの産業への応用です。
 モハマド・アル・ジャザリー Amazon Machine Learning Solutions Lab の応用科学者です。 彼は、AWS のお客様が ML ソリューションを特定して構築し、ロジスティクス、パーソナライゼーションとレコメンデーション、コンピューター ビジョン、不正防止、予測、サプライ チェーンの最適化などの分野でのビジネス上の課題に対処するのを支援しています。 AWS に入社する前は、ウェスト バージニア大学で MCS を取得し、Midea でコンピューター ビジョンの研究者として働いていました。 仕事以外では、サッカーとビデオ ゲームを楽しんでいます。
モハマド・アル・ジャザリー Amazon Machine Learning Solutions Lab の応用科学者です。 彼は、AWS のお客様が ML ソリューションを特定して構築し、ロジスティクス、パーソナライゼーションとレコメンデーション、コンピューター ビジョン、不正防止、予測、サプライ チェーンの最適化などの分野でのビジネス上の課題に対処するのを支援しています。 AWS に入社する前は、ウェスト バージニア大学で MCS を取得し、Midea でコンピューター ビジョンの研究者として働いていました。 仕事以外では、サッカーとビデオ ゲームを楽しんでいます。
 ハイボディン Amazon Machine Learning Solutions Lab の上級応用科学者です。 彼は、深層学習と自然言語処理に広く関心を持っています。 彼の研究は、実世界の問題に対してより効率的で信頼できるものにすることを目標に、新しい説明可能な機械学習モデルの開発に焦点を当てています。 彼は博士号を取得しました。 ユタ大学で博士号を取得し、Amazon に入社する前は、Bosch Research North America で上級研究科学者として働いていました。 仕事以外では、ハイキング、ランニング、家族との時間を楽しんでいます。
ハイボディン Amazon Machine Learning Solutions Lab の上級応用科学者です。 彼は、深層学習と自然言語処理に広く関心を持っています。 彼の研究は、実世界の問題に対してより効率的で信頼できるものにすることを目標に、新しい説明可能な機械学習モデルの開発に焦点を当てています。 彼は博士号を取得しました。 ユタ大学で博士号を取得し、Amazon に入社する前は、Bosch Research North America で上級研究科学者として働いていました。 仕事以外では、ハイキング、ランニング、家族との時間を楽しんでいます。
 リン・リーチョン AWS の Amazon ML Solutions Lab チームの応用科学マネージャーです。 彼女は戦略的な AWS の顧客と協力して、人工知能と機械学習を調査および適用して、新しい洞察を発見し、複雑な問題を解決しています。 彼女は博士号を取得しました。 マサチューセッツ工科大学出身。 仕事以外では、読書とハイキングを楽しんでいます。
リン・リーチョン AWS の Amazon ML Solutions Lab チームの応用科学マネージャーです。 彼女は戦略的な AWS の顧客と協力して、人工知能と機械学習を調査および適用して、新しい洞察を発見し、複雑な問題を解決しています。 彼女は博士号を取得しました。 マサチューセッツ工科大学出身。 仕事以外では、読書とハイキングを楽しんでいます。
 ジョナサン・ユング ナショナル フットボール リーグのシニア ソフトウェア エンジニアです。 彼は過去 XNUMX 年間、Next Gen Stats チームに所属し、生データのストリーミングから、データを処理するためのマイクロサービスの構築、処理されたデータを公開する API の構築まで、プラットフォームの構築を支援してきました。 彼は、Amazon Machine Learning Solutions Lab と協力して、データ自体に関するドメイン知識を提供するだけでなく、操作するためのクリーンなデータを提供しています。 仕事以外では、ロサンゼルスでのサイクリングやシエラ山脈でのハイキングを楽しんでいます。
ジョナサン・ユング ナショナル フットボール リーグのシニア ソフトウェア エンジニアです。 彼は過去 XNUMX 年間、Next Gen Stats チームに所属し、生データのストリーミングから、データを処理するためのマイクロサービスの構築、処理されたデータを公開する API の構築まで、プラットフォームの構築を支援してきました。 彼は、Amazon Machine Learning Solutions Lab と協力して、データ自体に関するドメイン知識を提供するだけでなく、操作するためのクリーンなデータを提供しています。 仕事以外では、ロサンゼルスでのサイクリングやシエラ山脈でのハイキングを楽しんでいます。
 マイク・バンド は、ナショナル フットボール リーグの次世代統計の調査および分析のシニア マネージャーです。 2018 年にチームに加わって以来、彼はファン、NFL 放送パートナー、32 クラブの選手追跡データから得られた重要な統計と洞察の構想、開発、伝達を担当してきました。 マイクは、シカゴ大学で分析学の修士号を取得し、フロリダ大学でスポーツ管理の学士号を取得し、ミネソタ バイキングスのスカウト部門と採用部門の両方での経験を活かして、豊富な知識と経験をチームにもたらします。フロリダゲーターフットボールの。
マイク・バンド は、ナショナル フットボール リーグの次世代統計の調査および分析のシニア マネージャーです。 2018 年にチームに加わって以来、彼はファン、NFL 放送パートナー、32 クラブの選手追跡データから得られた重要な統計と洞察の構想、開発、伝達を担当してきました。 マイクは、シカゴ大学で分析学の修士号を取得し、フロリダ大学でスポーツ管理の学士号を取得し、ミネソタ バイキングスのスカウト部門と採用部門の両方での経験を活かして、豊富な知識と経験をチームにもたらします。フロリダゲーターフットボールの。
 マイケル・チー ナショナル フットボール リーグで次世代統計とデータ エンジニアリングを監督するテクノロジー担当シニア ディレクターです。 彼は、イリノイ大学アーバナ シャンペーン校で数学とコンピューター サイエンスの学位を取得しています。 マイケルは 2007 年に初めて NFL に参加し、主にサッカー統計のテクノロジーとプラットフォームに注力してきました。 余暇には、家族と屋外で過ごす時間を楽しんでいます。
マイケル・チー ナショナル フットボール リーグで次世代統計とデータ エンジニアリングを監督するテクノロジー担当シニア ディレクターです。 彼は、イリノイ大学アーバナ シャンペーン校で数学とコンピューター サイエンスの学位を取得しています。 マイケルは 2007 年に初めて NFL に参加し、主にサッカー統計のテクノロジーとプラットフォームに注力してきました。 余暇には、家族と屋外で過ごす時間を楽しんでいます。
 トンプソン・ブリス ナショナル フットボール リーグのマネージャー、フットボール オペレーション、データ サイエンティストです。 彼は 2020 年 2021 月にデータ サイエンティストとして NFL に入社し、2019 年 2018 月に現在の役割に昇進しました。彼は XNUMX 年 XNUMX 月にニューヨーク市のコロンビア大学でデータ サイエンスの修士号を取得しました。彼は理学士号を取得しました。 XNUMX 年にウィスコンシン大学マディソン校で物理学と天文学の学士号を取得し、副専攻で数学とコンピューター サイエンスを学びました。
トンプソン・ブリス ナショナル フットボール リーグのマネージャー、フットボール オペレーション、データ サイエンティストです。 彼は 2020 年 2021 月にデータ サイエンティストとして NFL に入社し、2019 年 2018 月に現在の役割に昇進しました。彼は XNUMX 年 XNUMX 月にニューヨーク市のコロンビア大学でデータ サイエンスの修士号を取得しました。彼は理学士号を取得しました。 XNUMX 年にウィスコンシン大学マディソン校で物理学と天文学の学士号を取得し、副専攻で数学とコンピューター サイエンスを学びました。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/identifying-defense-coverage-schemes-in-nfls-next-gen-stats/

