概要
人工知能 (AI) は、主に大規模言語モデル (LLM) の台頭により、ここ数年で大幅に成長しました。 これらの洗練された AI システムは、豊富な人間の言語を含む膨大なデータセットでトレーニングされ、無数の技術の進歩を推進してきました。 GPT-3 (Generative Pre-trained Transformer 3) などの LLM の規模と複雑さは、LLM を自然言語の理解と生成の最前線に押し上げました。 この記事では、電子メールの応答生成と並べ替えに革命をもたらす LLM の重要な役割による電子メールの効率性に焦点を当てます。 デジタル コミュニケーション環境が進化するにつれて、電子メールに対する効率的でコンテキストを認識したパーソナライズされた応答の必要性がますます重要になっています。 LLM コミュニケーションの生産性を向上させ、反復的なタスクを自動化し、人間の創意工夫を強化するソリューションを提供することで、この状況を再構築する可能性を秘めています。
学習目標
- 言語モデルの進化を追跡し、重要なマイルストーンを識別し、基本システムから GPT-3.5 などの高度なモデルまでの発展を把握します。
- 大規模な言語モデルのトレーニングの複雑さを理解します。 彼らは、微調整と転移学習における課題と革新的なソリューションを模索しながら、データの準備、モデル アーキテクチャ、および必要な計算リソースを積極的に理解します。
- 大規模な言語モデルが電子メール通信をどのように変革するかを調査します。
- 言語モデルが電子メールの並べ替えプロセスを最適化する方法を確認します。
この記事は、の一部として公開されました データサイエンスブログ。
目次
大規模な言語モデルを理解する
LLM として知られる大きな言語モデルは、人工知能、特に人間の言語の理解において大きな進歩をもたらします。 彼らは人間のような文章を理解して作成するのが得意です。 彼らはさまざまな言語タスクに優れているため、人々は彼らに興奮しています。 LLM の概念を理解するには、LLM とは何か、および LLM がどのように機能するかという XNUMX つの重要な側面を詳しく調べることが重要です。
大規模言語モデルとは何ですか?
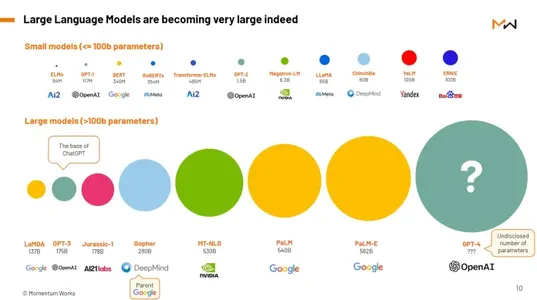
大規模な言語モデルの中心は、広範なネットワーク接続を備えた優れたコンピューター プログラムのようなものです。 それらを際立たせているのは、そのスケールの大きさです。 これらは、書籍や記事から Web サイトやソーシャル メディアの投稿に至るまで、あらゆるものを網羅する膨大で多様なテキスト データセットで事前トレーニングされています。 この事前トレーニング段階では、人間の言語の複雑さにさらされ、文法、構文、意味論、さらには常識的な推論さえも学ぶことができます。 重要なのは、LLM は学習したテキストをただ繰り返すだけでなく、一貫した文脈に関連した応答を生成できることです。
LLM の最も注目すべき例の XNUMX つは次のとおりです。 GPT-3GPT-3 は、Generative Pre-trained Transformer 3 の略です。GPT-175 は、驚異的な数のパラメーター (正確には XNUMX 億プロセス) を誇り、最も重要な言語モデルの XNUMX つとなっています。 これらのパラメーターはニューラル ネットワーク内の重みと接続を表し、前の単語によって提供されるコンテキストに基づいてモデルが文内の次の単語を予測できるように微調整されます。 この予測機能は、電子メール応答の生成からコンテンツ作成および翻訳サービスに至るまで、さまざまなアプリケーションに利用されます。
本質的に、GPT-3 のような LLM は、最先端の AI テクノロジーと人間の言語の複雑さが交差する位置にあります。 テキストを流暢に理解して生成できるため、さまざまな業界やアプリケーションに広範な影響を与える多用途ツールとなります。
GPT-3 のようなトレーニング プロセスとモデル
大規模な言語モデルのトレーニング プロセスは、複雑でリソースを大量に消費する作業です。 それは、さまざまなソースとドメインを含む、インターネットから大規模なテキスト データセットを取得することから始まります。 これらのデータセットは、モデルを構築するための基盤として機能します。 トレーニング プロセス中に、モデルは、前のコンテキストを考慮して単語または単語のシーケンスの可能性を予測する方法を学習します。 このプロセスは、モデルのニューラル ネットワークを最適化し、パラメーターの重みを調整して予測誤差を最小限に抑えることによって実現されます。
GPT-3 アーキテクチャの概要
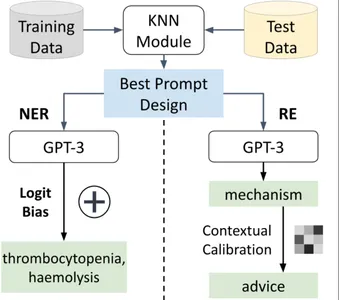
GPT-3 (「Generative Pre-trained Transformer 3」) は、OpenAI によって開発された最先端の言語モデルです。 そのアーキテクチャは、セルフアテンション メカニズムを採用することで自然言語処理タスクに革命をもたらした Transformer モデルに基づいています。
変圧器のアーキテクチャ: Vaswani らによって導入された Transformer アーキテクチャ。 2017 年には GPT-3 において極めて重要な役割を果たします。 これは自己注意力に依存しており、モデルが予測を行う際にシーケンス内のさまざまな単語の重要性を比較検討できるようになります。 このアテンション メカニズムにより、モデルは文のコンテキスト全体を考慮し、長距離の依存関係を効果的に捕捉できるようになります。
GPT-3のスケール: GPT-3 の特に注目すべき点は、その前例のない規模です。 175 億もの膨大な数のパラメータを誇り、当時としては最大の言語モデルとなっています。 この巨大なスケールは、複雑な言語パターンを理解して生成する能力に貢献し、さまざまな自然言語処理タスクにわたって汎用性が高くなります。
階層化されたアーキテクチャ: GPT-3 のアーキテクチャは深く階層化されています。 これは、互いに積み重ねられた多数のトランス層で構成されます。 各層は入力テキストの理解をさらに深め、モデルが階層的な特徴と抽象的な表現を把握できるようにします。 このアーキテクチャの深さは、言語の複雑なニュアンスを捉える GPT-3 の能力に貢献しています。
細部への注意: GPT-3 の複数の層は、詳細な注意を払う能力に貢献しています。 このモデルは、特定のコンテキスト内の特定の単語、フレーズ、または構文構造に対処できます。 このきめ細かな注意メカニズムは、一貫した文脈に関連したテキストを生成するモデルの機能にとって非常に重要です。
適応性: GPT-3 のアーキテクチャにより、タスク固有のトレーニングなしでさまざまな自然言語処理タスクに適応できます。 さまざまなデータセットでの事前トレーニングにより、モデルを適切に一般化でき、言語翻訳、要約、質問応答などのタスクに適用できるようになります。
GPT-3のアーキテクチャの重要性
- 汎用性: 階層化されたアーキテクチャと膨大な数のパラメーターにより、GPT-3 は比類のない多用途性を実現し、タスク固有の微調整を行わなくても、さまざまな言語関連タスクで優れた性能を発揮できるようになります。
- 文脈理解: 自己注意メカニズムと階層構造により、GPT-3 は文脈を深く理解してテキストを理解して生成することができ、微妙な言語構造の処理に熟達します。
- アダプティブラーニング: GPT-3 のアーキテクチャは適応学習を促進し、大規模な再トレーニングなしでモデルが新しいタスクに適応できるようにします。 この適応性は、自然言語処理において特徴的な重要な機能です。
GPT-3 のアーキテクチャは、Transformer モデルに基づいて構築され、そのスケールと深さによって際立っており、さまざまなアプリケーションにわたって人間のようなテキストを理解して生成する際に大規模な言語モデルの機能を大幅に進歩させた驚異的な技術です。
機能とアプリケーション
大規模言語モデル (LLM) は、幅広い自然言語の理解および生成機能を備えています。 これらの機能により、電子メール応答生成での利用を含む、数多くのアプリケーションへの扉が開かれます。 これらの点をさらに詳しく見てみましょう。
1. 電子メール応答の生成: LLM は、言語理解および生成機能を活用して、電子メール応答プロセスを自動化および強化する上で重要な有用性を提供します。
2. コンテンツ作成: LLM は、記事、ブログ投稿、ソーシャル メディアの更新などのクリエイティブなコンテンツを生成するための強力なツールです。 特定の文体を模倣し、さまざまな口調に適応し、魅力的で文脈に関連したコンテンツを作成できます。
3. チャットボットのインタラクション: LLM は、インテリジェントなチャットボットのバックボーンとして機能します。 動的でコンテキストを認識した会話に参加し、ユーザーに情報、支援、サポートを提供できます。 これは、顧客サービス アプリケーションで特に役立ちます。
4. 要約サービス: LLM は、大量のテキストを簡潔な要約に抽出することに優れています。 これは、ニュースの集約、ドキュメントの要約、およびコンテンツのキュレーション アプリケーションで役立ちます。
5. 翻訳サービス: LLM は、多言語の理解を活用して、正確で文脈的に適切な翻訳サービスを提供できます。 これは、グローバルコミュニケーションにおける言語の壁を取り除くのに有益です。
6. 法的文書の作成: 法律分野では、LLM は標準的な法的文書、契約書、合意書の草案作成を支援できます。 法律用語や書式規則に準拠したテキストを生成できます。
7. 教育コンテンツの生成: LLM は、授業計画、クイズ、学習ガイドなどの教材の作成を支援します。 さまざまな学力レベルや科目に合わせたコンテンツを生成できます。
8. コード生成: LLM は、自然言語記述に基づいてコード スニペットを生成できます。 これは、迅速で正確なコードの提案を求めるプログラマーや開発者にとって特に便利です。
これらの例は、LLM の多用途なアプリケーションを強調し、通信プロセスを合理化し、タスクを自動化し、さまざまなドメインにわたるコンテンツ作成を強化する能力を示しています。
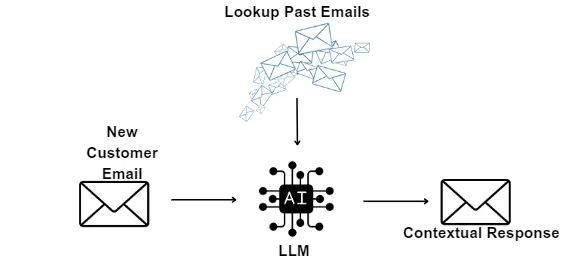
電子メールコミュニケーションの強化
効果的な電子メール コミュニケーションは、現代の職業上および個人的なやり取りの基礎です。 大規模言語モデル (LLM) は、自動応答、多言語サポート、翻訳、コンテンツの要約、センチメント分析などのさまざまな機能とアプリケーションを通じて、このコミュニケーションを強化する上で極めて重要な役割を果たします。
自動化された応答と効率性
LLM は、自動応答を通じて電子メール通信の効率を大幅に向上させることができます。 電子メール システムで使用すると、一般的な問い合わせやメッセージに対する自動返信を生成できます。 たとえば、誰かがパスワード リセット リクエストを送信した場合、LLM は必要な指示を含む応答を迅速に作成できるため、人間の応答者の作業負荷が軽減されます。
これらの自動応答は日常的なタスクに限定されません。 LLM は、より複雑なクエリも処理できます。 たとえば、受信メールの内容を分析し、その意図を理解して、パーソナライズされた状況に応じた適切な応答を生成できます。 これにより、送信者と受信者の両方の時間が節約され、応答が常に正確であることが保証されます。
多言語サポートと翻訳
ますますグローバル化が進む世界では、電子メールによるコミュニケーションは複数の言語にまたがることがよくあります。 LLM は、多言語サポートと翻訳サービスの提供に優れています。 電子メールをある言語から別の言語に翻訳することで言語の壁を越え、コミュニケーションをよりアクセスしやすく、包括的なものにすることができます。
LLM は言語に対する深い理解を活用して、翻訳が文字通りかつ文脈的に適切であることを保証します。 言語間を移行する場合でも、元のメッセージのトーンと意図を維持できます。 この機能は、異文化コミュニケーションに携わる国際的な企業、組織、個人にとって非常に貴重です。
コンテンツの要約と感情分析
電子メールには長文かつ詳細な情報が含まれることがよくあります。 LLM は、コンテンツの要約を通じてこの課題に取り組む能力を備えています。 電子メールの内容を分析し、重要なポイントや重要な情報を強調した簡潔な要約を提供できます。 これは、長いメッセージの本質を素早く把握する必要がある多忙な専門家にとって特に便利です。
さらに、LLM は受信メールのセンチメント分析を実行できます。 これらはメッセージの感情的な調子を評価し、ユーザーが肯定的な感情か否定的な感情かを識別するのに役立ちます。 この分析は、緊急の電子メールや感情的な電子メールへの応答に優先順位を付け、重要な問題に迅速かつ効果的に対処するために不可欠です。
結論として、LLM は応答を自動化し、言語の壁を取り除き、電子メールの内容の理解を簡素化することにより、電子メール コミュニケーションの強化に大きく貢献します。 これらの機能により効率が向上し、より効果的でパーソナライズされた電子メールのやり取りが可能になります。
メールの分類と整理
個人でも仕事でも、増え続ける電子メールを管理するには、効率的な電子メールの分類と整理が不可欠です。 Large Language Model (LLM) は、スパム フィルタリングと優先順位の並べ替え、分類と自動タグ付け、会話スレッドの識別などの機能を通じて電子メール管理に大きく貢献します。
スパムフィルタリングと優先順位の並べ替え
電子メールに関する大きな問題はスパムです。スパムによって受信トレイがいっぱいになり、重要なメッセージが隠れてしまう可能性があります。 LLM は、この課題に対処する上で重要な役割を果たします。 高度なアルゴリズムを使用して、受信メールのコンテンツ送信者のその他の特徴や情報を分析し、それらがスパムである可能性が高いか、正規のメッセージであるかを判断できます。
LLM は、内容とコンテキストに基づいて電子メールの優先順位付けを支援することもできます。 たとえば、「緊急」や「重要」などのキーワードを含む電子メールを識別し、すぐに注意を払うことができます。 このプロセスを自動化することで、LLM はユーザーが重要なメッセージに集中できるようにし、生産性と応答性を向上させます。
分類と自動タグ付け
電子メールを関連するフォルダーまたはラベルに分類して整理すると、電子メール管理が合理化されます。 LLM は、内容、件名、その他の属性に基づいて電子メールを分類することに熟達しています。 たとえば、財務、マーケティング、カスタマー サポート、または特定のプロジェクトに関連する電子メールを、それぞれのフォルダーに自動的に分類できます。
さらに、LLM は関連するキーワードやラベルを使用して電子メールに自動タグ付けできるため、ユーザーは後で特定のメッセージを簡単に検索できます。 この機能により、電子メールのアクセシビリティが向上し、特に過去の通信やドキュメントを参照する必要がある場合に、ユーザーが情報を迅速に取得できるようになります。
会話スレッドの識別
電子メールでの会話は複数のメッセージにまたがることが多いため、メッセージを識別して一貫したスレッドに整理することが不可欠です。 LLM は会話スレッドの識別に優れています。 電子メールの内容、受信者リスト、タイムスタンプを分析して、関連するメッセージをスレッドにグループ化できます。
LLM は電子メールをスレッド形式で表示することで、ユーザーが会話のコンテキストと履歴を一目で理解できるようにします。 この機能は、議論や意思決定の進行状況を追跡することが重要である共同作業環境では貴重です。
要約すると、LLM は、スパム フィルタリング、メッセージの優先順位付け、電子メールの分類とタグ付け、会話スレッドの識別とグループ化を自動化することにより、電子メールの分類と整理を強化します。 これらの機能は時間を節約し、より組織的で効率的な電子メール管理プロセスに貢献します。
ユーザー支援とパーソナライゼーション
ユーザー アシスタンスとパーソナライゼーションは、現代の電子メール コミュニケーションの重要な側面です。 大規模言語モデル (LLM) は、検索支援やリマインダー アラート、パーソナライズされた推奨事項、データ セキュリティとプライバシーの考慮事項など、これらの分野で貴重な機能を提供します。
検索支援とリマインダーアラート
LLM は、電子メールの検索を支援し、リマインダー アラートを提供することでユーザー エクスペリエンスを向上させます。 ユーザーが受信トレイ内の特定の電子メールや情報を探している場合、LLM は関連するキーワード、フレーズ、またはフィルターを提案することで検索の精度を向上させることができます。 この機能により、重要なメッセージの取得が合理化され、電子メール管理がより効率的になります。
リマインダー アラートは、LLM のもう XNUMX つの貴重な機能です。 重要なメールや注意が必要なタスクの通知を送信することで、ユーザーが整理整頓を維持できるようになります。 LLM は、キーワード、日付、またはユーザー定義の基準を特定してこれらのリマインダーをトリガーし、重要な項目が見落とされないようにすることができます。
パーソナライズされた推奨事項
パーソナライゼーションは、効果的な電子メール コミュニケーションの重要な推進力です。 LLM は、さまざまな方法で電子メールのやり取りをパーソナライズできます。 たとえば、電子メールを作成する場合、これらのモデルは補完を提案したり、ユーザーの書き方やコンテキストに合わせたテンプレートを提供したりできます。 これは、ユーザーが受信者の心に響く応答を作成するのに役立ちます。
さらに、LLM は電子メールの内容を分析して、パーソナライズされた推奨事項を提供できます。 たとえば、電子メールのコンテキストに基づいて、関連する添付ファイルや関連記事を提案できます。 このパーソナライゼーションにより、電子メール通信がより便利で関連性のあるものになり、ユーザー エクスペリエンスが向上します。
データセキュリティとプライバシーに関する懸念
LLM には多くの利点がありますが、データのセキュリティとプライバシーに関する懸念が生じます。 これらのモデルでは、電子メールのコンテンツにアクセスする必要があり、場合によっては機密情報を保存または処理する場合があります。 ユーザーと組織は、これらの懸念事項に責任を持って対処する必要があります。
機密電子メールデータを不正アクセスから保護するには、暗号化やアクセス制御などのデータセキュリティ対策を講じる必要があります。 さらに、組織は LLM がデータ保護規制と倫理ガイドラインに準拠していることを確認する必要があります。 倫理的な考慮事項には、ユーザーのプライバシーの保護、データ収集の最小限化、電子メールのコンテンツの使用方法に関する透明性の提供などが含まれます。
LLM は、検索機能の改善、リマインダー アラートの提供、パーソナライズされた推奨事項の提供などにより、電子メール コミュニケーションにおけるユーザー アシスタンスとパーソナライゼーションに貢献します。 ただし、これらのテクノロジを責任を持って安全に使用するには、これらの利点とデータ セキュリティおよびプライバシーの考慮事項のバランスをとることが重要です。
倫理的配慮
大規模言語モデル (LLM) を電子メール応答の生成と並べ替えに統合する際に、いくつかの倫理的考慮事項が最前線に置かれます。 これには、自動応答におけるバイアスへの対処や、責任ある AI の使用とコンプライアンスの確保が含まれます。
自動応答におけるバイアス
これらのモデルを使用して電子メールを作成する場合の大きな懸念は、誤って不公平な意見が含まれる可能性があることです。 LLM は、偏った言葉や偏見のある言葉が含まれている可能性のある膨大なデータセットから学習します。 その結果、これらのモデルによって生成される自動応答は、意図していない場合でも、誤って固定観念を永続させたり、偏った動作を示したりする可能性があります。
この問題に対処するには、バイアスの検出と軽減のメカニズムを実装することが不可欠です。 これには、偏ったコンテンツを削除するためのトレーニング データセットの慎重な管理、公平性を念頭に置いたモデルの微調整、自動応答の定期的な監視と監査が含まれる場合があります。 偏見を減らすために積極的に取り組むことで、LLM が公正で敬意を持った包括的な対応を確実に行うことができます。
責任ある AI の使用とコンプライアンス
電子メール通信に LLM を導入する場合、責任ある AI の使用が最も重要です。 倫理ガイドラインや GDPR (一般データ保護規則) などのデータ保護規制の遵守は最優先事項でなければなりません。
- ユーザーの同意: 電子メール通信で LLM を使用することについてユーザーに通知し、必要に応じて同意を得る必要があります。 データ処理と電子メール応答生成における AI の役割に関する透明性は非常に重要です。
- データのプライバシー: ユーザーデータの保護は基本です。 組織は、機密性の高い電子メールのコンテンツを保護するために、堅牢なデータ セキュリティ対策を実装する必要があります。 データは匿名化され、ユーザーのプライバシーを尊重して処理される必要があります。
- 監査可能性: LLM のアクションは監査可能である必要があり、ユーザーや組織が自動応答がどのように生成されたかを追跡し、説明責任を確保できるようにする必要があります。
- 人間による監視: LLM は多くのタスクを自動化できますが、依然として人間による監視が不可欠です。 人間の審査担当者は、倫理および組織の基準を満たすように自動応答を監視および修正する必要があります。
- 継続的な改善: 責任ある AI の使用には、モデルとシステムを改善するための継続的な取り組みが含まれます。 倫理的な AI 実践を維持するには、定期的な監査、フィードバック ループ、調整が必要です。
結論として、電子メール応答の生成と分類に LLM を使用する場合の倫理的考慮事項には、自動応答におけるバイアスへの対処、責任ある AI 使用の確保、データ保護規制の遵守が含まれます。 公平性、透明性、ユーザーのプライバシーを優先することで、電子メール通信における倫理基準を維持しながら、LLM の可能性を活用できます。
実際のアプリケーション
大規模言語モデル (LLM) は、次のケース スタディや例を含む、現実世界のさまざまなシナリオで実用的で影響力のあるアプリケーションを発見しました。
1. カスタマーサポートとヘルプデスク: 多くの企業がこれらのモデルを使用して顧客サービスを支援しています。 たとえば、グローバルな e コマース プラットフォームでは、LLM を使用して、製品の在庫状況、注文の追跡、返品に関する一般的な顧客の問い合わせへの応答を自動化しています。 これにより、応答時間が大幅に短縮され、顧客満足度が向上しました。
2. コンテンツの生成: 大手報道機関は、ジャーナリストによるニュース記事の作成を支援するために LLM を採用しています。 LLM は、大規模なデータセットを迅速に要約し、背景情報を提供し、ニュース記事の可能性のある角度を提案できます。 これにより、コンテンツの作成が加速され、ジャーナリストは分析とレポートに集中できるようになります。
3. 言語翻訳サービス: ある国際組織は、世界規模の会議やカンファレンスでのリアルタイムの言語翻訳に LLM を利用しています。 LLM は、話し言葉や書き言葉のコンテンツを即座に複数の言語に翻訳し、異なる言語を話す参加者間の効果的なコミュニケーションを促進します。
4. 電子メール応答の生成: 多忙な法律事務所は、LLM を使用して、クライアントからの問い合わせに対する最初の応答の生成を自動化しています。 LLM は、法的調査の性質を理解し、予備的な回答の草案を作成し、弁護士の即時対応が必要な事件にフラグを立てることができます。 これにより、クライアントの通信が合理化され、効率が向上します。
5. 仮想パーソナル アシスタント: テクノロジー企業は、仮想パーソナル アシスタント アプリに LLM を統合しました。 ユーザーは電子メール、メッセージ、またはタスクをアシスタントに口述することができ、LLM はユーザー入力に基づいて一貫したテキストを生成します。 このハンズフリーのアプローチにより、アクセシビリティと利便性が向上します。
6. 教育支援: 教育分野では、オンライン学習プラットフォームが LLM を使用して、生徒の質問に対する即時の説明と回答を提供します。 生徒が数学の問題について質問がある場合でも、複雑な概念についての説明が必要な場合でも、LLM は即座に支援を提供し、自主学習を促進します。
課題と制限
大規模言語モデル (LLM) は、電子メール応答の生成と並べ替えに大きな利点をもたらしますが、課題と制限もあります。 これらの問題を理解することは、LLM が電子メール通信を責任を持って効果的に使用するために不可欠です。
モデルの限界と真の理解の欠如
これらのモデルの主な問題は、優れているにもかかわらず、物事を理解していないことです。 膨大なデータセットから学習したパターンと関連性に基づいてテキストを生成しますが、これには真の理解は必要ありません。 基本的な制限には次のようなものがあります。
- 文脈の理解の欠如: LLM は、文脈的に関連性があるように見えても、根本的に理解が欠けているテキストを生成する可能性があります。 たとえば、根底にある概念を理解していなくても、もっともらしく聞こえる説明を生み出すことができます。
- 不正確な情報: LLM は事実に反する応答を生成する可能性があります。 彼らは情報を事実確認したり検証したりする能力を持っていないため、誤った情報の伝播につながる可能性があります。
- 珍しいシナリオでの失敗: LLM は、トレーニング データで十分に表現されていない、まれなトピックや高度に専門化されたトピックや状況に苦戦することがあります。
LLM は電子メール応答の生成と分類に強力な機能を提供しますが、適切な理解の限界に関連する課題に直面しており、倫理的およびプライバシー上の懸念が生じます。 これらの課題に対処するには、AI の強みと責任ある使用慣行および人間の監視を組み合わせて、LLM の限界と倫理的リスクを軽減しながら、LLM の利点を最大化するバランスの取れたアプローチが必要です。
生成された応答の表示
ライブラリのインポート
- Transformers ライブラリから必要なライブラリをインポートします。
- 事前トレーニングされた GPT-2 モデルとトークナイザーをロードします。
# Import the necessary libraries from the Transformers library
from transformers import GPT2LMHeadModel, GPT2Tokenizer # Load the pre-trained GPT-2 model and tokenizer
model_name = "gpt2" # Specify GPT-2 model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
このセクションでは、GPT2LMHeadModel (GPT-2 モデル用) や GPT2Tokenizer などの重要なライブラリを Transformers ライブラリからインポートします。 次に、事前トレーニングされた GPT-2 モデルとトークナイザーを読み込みます。
入力プロンプト
- テキスト生成の開始点として入力プロンプトを定義します。
- 必要な入力を反映するようにプロンプトを変更します。
# Input prompt
prompt = "Once upon a time" # Modify the prompt to your desired input
ここでは、テキスト生成プロセスの初期テキストとして機能する入力プロンプトを定義します。 ユーザーは、特定の要件に合わせてプロンプトを変更できます。
入力をトークン化する
- トークナイザーを使用して、入力プロンプトをモデルが理解できるトークン化された形式 (数値 ID) に変換します。
# Tokenize the input and generate text
input_ids = tokenizer.encode(prompt, return_tensors="pt")
このセクションでは、GPT-2 トークナイザーを使用して入力プロンプトをトークン化し、モデルが理解できる数値 ID に変換します。
テキストの生成
- GPT-2 モデルを使用して、トークン化された入力に基づいてテキストを生成します。
- 最大長、シーケンス数、温度などのさまざまな生成パラメータを指定して、出力を制御します。
# Generate text based on the input
output = model.generate( input_ids, max_length=100, num_return_sequences=1, no_repeat_ngram_size=2, top_k=50, top_p=0.95, temperature=0.7
)
このコードは GPT-2 モデルを使用して、トークン化された入力に基づいてテキストを生成します。 max_length、num_return_sequences、no_repeat_ngram_size、top_k、top_p などのパラメータ、およびテキスト生成プロセスの温度制御の側面。
デコードして印刷
- トークナイザーを使用して、数値 ID から生成されたテキストを人間が判読できるテキストにデコードします。
- 生成されたテキストをコンソールに出力します。
# Decode and print the generated text
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
これらのコメントは、コードの各セクションの説明を提供し、GPT-2 モデルのロード、入力プロンプトの提供、テキストの生成、生成されたテキストのコンソールへの出力のプロセスをガイドします。
このセクションでは、トークナイザーを使用して、数値 ID から生成されたテキストを人間が判読可能なテキストにデコードします。 結果のテキストがコンソールに出力されます。
出力
- 提供された入力プロンプトに基づいて生成されたテキストがコンソールに出力されます。 これは、GPT-2 モデルのテキスト生成プロセスの結果です。
Once upon a time, in a land far away, there lived a wise old wizard. He had a magical staff that could grant any wish...この点は、コードの出力セクションの目的と内容を要約しています。
今後の方向性
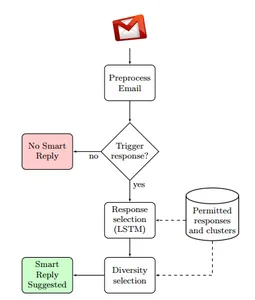
電子メールにおけるこれらの大きな言語モデルの将来はエキサイティングです。 これには、倫理的懸念に対処し、有益な使用を確保するために、AI の機能と責任ある AI の進歩を強化するための継続的な研究開発が含まれます。
継続的な研究開発
自然言語処理と LLM の分野は進化し続けています。 研究開発における今後の方向性は次のとおりです。
- モデルのサイズと効率: 研究者は、LLM をより効率的で環境に優しいものにする方法を模索しています。 これには、二酸化炭素排出量を削減するためのモデル アーキテクチャとトレーニング手法の最適化が含まれます。
- 微調整と転移学習: 特定のタスクまたはデータセットに合わせて LLM を微調整するための技術を洗練することに、引き続き焦点が当てられます。 これにより、組織はこれらのモデルを独自のニーズに適応させることができます。
- ドメインの専門化:
コンテキスト
ドメインの特化とは、特定のドメインまたは業界に対応するために大規模言語モデル (LLM) をカスタマイズすることを指します。 各業界やドメインには、多くの場合、独自の専門用語、用語、文脈上のニュアンスがあります。 汎用 LLM は強力ではありますが、専門分野の複雑さを完全には捉えていない可能性があります。
重要性:
- 関連性: 特定のドメイン向けに LLM をカスタマイズすると、モデルが特定の業界をよりよく理解し、特定の業界に関連性の高いコンテンツを生成できるようになります。
- 位置精度: 業界内での正確なコミュニケーションには、ドメイン固有の専門用語や専門用語が非常に重要となることがよくあります。 専門の LLM は、これらの用語を認識して適切に使用できるようにトレーニングできます。
- 文脈理解: 業界には、コミュニケーションに影響を与える独自の状況要因がある場合があります。 ドメインに特化した LLM は、これらの特定のコンテキストを取得して理解することを目的としています。
例:
法律分野では、その分野に特化した LLM が法律文書、契約書、判例法についてのトレーニングを受ける場合があります。 このカスタマイズにより、モデルは法律用語を理解し、複雑な法的構造を解釈し、法律専門家向けに状況に応じて適切なコンテンツを生成できるようになります。
マルチモーダル機能
コンテキスト:
マルチモーダル機能には、大規模言語モデル (LLM) とコンピューター ビジョンなどの他の人工知能 (AI) テクノロジーの統合が含まれます。 LLM は主にテキストの処理と生成に優れていますが、他のモダリティと組み合わせることで、テキストを超えたコンテンツを理解して生成する能力が強化されます。
重要性:
- 理解の強化: マルチモーダル機能により、LLM は画像、ビデオ、テキストなどの複数のソースからの情報を処理できます。 この全体的な理解は、より包括的で文脈を意識したコンテンツの生成に貢献します。
- 拡張されたユーティリティ: マルチモーダル機能を備えた LLM は、画像キャプション、ビデオ要約、視覚入力に基づくコンテンツ生成など、より幅広いアプリケーションに適用できます。
- コミュニケーションの改善: 視覚的な情報がテキスト コンテンツを補完するシナリオでは、マルチモーダル LLM は、意図されたメッセージをより豊かで正確に表現できます。
例:
ユーザーが複雑な技術的問題について説明する電子メール通信シナリオを考えてみましょう。 コンピューター ビジョン機能を備えたマルチモーダル LLM は、問題に関連する添付画像やスクリーンショットを分析して理解を深め、より多くの情報に基づいた状況に応じた適切な応答を生成できます。
責任ある AI の進歩
倫理的懸念に対処し、AI の責任ある使用を保証することは、電子メール通信における LLM の将来にとって最も重要です。
- バイアスの軽減: 現在進行中の研究は、LLM のバイアスを検出して軽減するための堅牢な方法を開発し、自動応答が公正で公平であることを保証することを目的としています。
- 倫理ガイドライン: 組織や研究者は、透明性、公平性、ユーザーの同意を重視して、電子メール通信で LLM を使用するための明確なガイドラインを開発しています。
- ユーザーの権限付与: ユーザーが環境設定を設定したり、自動提案をオーバーライドしたりできるようにするなど、LLM によって生成された応答と推奨事項をより詳細に制御できるようにすることは、ユーザーの自主性を尊重する方向です。
- プライバシー中心のアプローチ: プライバシー保護 AI 技術の革新は、電子メール通信に LLM の力を活用しながら、ユーザー データを保護することを目的としています。
要約すると、電子メール応答の生成と分類における LLM の将来は、その能力を向上させるための継続的な研究と、倫理的懸念に対処するための責任ある AI の進歩によって特徴付けられます。 これらの開発により、LLM は電子メール コミュニケーションを強化する上で貴重な役割を果たし続けると同時に、その使用が倫理原則やユーザーの期待に沿ったものであることを保証できるようになります。
まとめ
常に変化するオンライン コミュニケーションの世界において、電子メールは依然として重要な役割を果たしています。 大規模な言語モデルは、電子メール応答の生成と分類に革命をもたらすツールとして登場しました。 この記事では、言語モデルの進化の旅に乗り出し、初歩的なルールベースのシステムから最先端の GPT-3 モデルまでの目覚ましい進歩を追跡しました。
これらのモデルの基礎を理解した上で、私たちはモデルのトレーニング プロセスを調査し、モデルがどのようにして膨大な量のテキスト データを取り込み、人間のような言語理解と生成を達成するための計算能力を実現するかを明らかにしました。 これらのモデルは、自動応答を可能にし、多言語サポートを促進し、内容の要約とセンチメント分析を実行することにより、電子メール コミュニケーションを再定義しました。
結論として、大規模な言語モデルは電子メールの状況を再定義し、効率性と革新性を提供すると同時に、倫理的な使用に対する警戒を要求します。 将来的には、電子メールを介したコミュニケーション方法がさらに大きく変化する可能性が予想されます。
主要な取り組み
- 言語モデルはルールベースのシステムから GPT-3 のような高度なモデルに進化し、自然言語の理解と生成を再構築しました。
- 大規模な言語モデルは大規模なデータセットでトレーニングされ、人間のようなテキストを理解して生成するには大量の計算リソースが必要です。
- これらのモデルは、言語の理解と生成を強化し、応答を自動化し、多言語サポートを提供し、コンテンツの要約と感情分析を可能にする、電子メール通信への応用を見出します。
- 大規模な言語モデルは、スパムのフィルタリングによる電子メールの分類、メッセージの優先順位付け、コンテンツの分類、会話スレッドの識別に優れています。
- 検索支援、パーソナライズされた推奨事項を提供し、データ セキュリティの問題に対処し、電子メール エクスペリエンスを個々のユーザーに合わせて調整します。
よくある質問
A. 読者は多くの場合、自動化、効率化、ユーザー エクスペリエンスの向上など、電子メール通信に対するこれらのモデルの利点を理解したいと考えています。
A. 多言語機能は、これらのモデルの重要な側面です。 多言語でのコミュニケーションをどのように可能にするのかを説明することが不可欠です。
A. 公平かつ誠実な電子メールのやり取りを確保するには、応答の偏りや責任ある AI の使用などの倫理的考慮事項に対処することが重要です。
A. 読者は、誤解の可能性や必要な計算リソースなど、これらのモデルの制約を知りたいと思うかもしれません。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/11/the-next-frontier-of-email-efficiency-with-llms/

