概要
大規模な言語モデル (LLM) と Generative AI は、人工知能と自然言語処理における革新的なブレークスルーを表します。 人間の言語を理解して生成し、テキスト、画像、音声、合成データなどのコンテンツを生成できるため、さまざまなアプリケーションで非常に汎用性が高くなります。 生成 AI は、コンテンツ作成の自動化と強化、ユーザー エクスペリエンスのパーソナライズ、ワークフローの合理化、創造性の促進により、現実世界のアプリケーションにおいて非常に重要な役割を果たします。 この記事では、企業がエンタープライズ ナレッジ グラフを使用して効果的にプロンプトを確立することで、どのように Open LLM と統合できるかに焦点を当てます。
学習目標
- LLM/Gen-AI システムと対話しながら、グラウンディングとプロンプト構築に関する知識を習得します。
- Grounding のエンタープライズとの関連性、オープン Gen-AI システムとの統合によるビジネス価値を例を挙げて理解します。
- XNUMX つの主要なグラウンディング競合ソリューションのナレッジ グラフとベクター ストアをさまざまな面で分析し、どちらがいつ適しているかを理解します。
- パーソナライズされた推奨顧客シナリオに向けて、ナレッジ グラフ、学習データ モデリング、および JAVA でのグラフ モデリングを活用して、基礎と即時構築のサンプル エンタープライズ デザインを学習します。
この記事は、の一部として公開されました データサイエンスブログソン.
目次
大規模言語モデルとは何ですか?
大規模言語モデルは、大量のテキスト/非構造化データに対して深層学習技術を使用してトレーニングされた高度な AI モデルです。 これらのモデルは、人間の言語と対話し、人間のようなテキスト、画像、音声を生成し、さまざまな処理を実行できます。 自然言語処理 タスク。
対照的に、言語モデルの定義は、テキスト コーパスの分析に基づいて単語のシーケンスに確率を割り当てることを指します。 言語モデルは、単純な N-gram モデルからより洗練されたニューラル ネットワーク モデルまでさまざまです。 ただし、「大規模言語モデル」という用語は、通常、深層学習技術を使用し、数百万から数十億に及ぶ多数のパラメーターを持つモデルを指します。 これらのモデルは言語の複雑なパターンを捉え、人間が書いたものと区別できないテキストを生成することができます。
プロンプトとは何ですか?
LLM または同様のチャットボット AI システムへのプロンプトは、AI との会話または対話を開始するために提供されるテキストベースの入力またはメッセージです。 LLM は多用途であり、さまざまなビッグ データを使用してトレーニングされており、さまざまなタスクに使用できます。 したがって、プロンプトのコンテキスト、範囲、品質、明確さは、LLM システムから受け取る応答に大きく影響します。
グラウンディング/RAGとは何ですか?
自然言語 LLM 処理のコンテキストにおけるグラウンディング、別名検索拡張生成 (RAG) は、よりカスタマイズされた正確な応答を改善および取得するために LLM に提供するコンテキスト、追加のメタデータ、およびスコープでプロンプトを強化することを指します。 この接続により、AI システムは必要な範囲とコンテキストに合わせた方法でデータを理解し、解釈できるようになります。 LLM に関する調査によると、LLM の応答の質はプロンプトの質に依存します。
これは、生のデータと、人間の理解および範囲を絞ったコンテキストと一致する方法でそのデータを処理および解釈する AI の能力との間のギャップを埋めるため、AI の基本的な概念です。 これにより、AI システムの品質と信頼性が向上し、正確で有用な情報や応答を提供する能力が向上します。
LLM の欠点は何ですか?
GPT-3 のような大規模言語モデル (LLM) は大きな注目を集め、さまざまなアプリケーションで使用されていますが、いくつかの短所や欠点もあります。 LLM の主な欠点には次のようなものがあります。
1. バイアスと公平性: LLM はトレーニング データからバイアスを継承することがよくあります。 その結果、偏ったコンテンツや差別的なコンテンツが生成され、有害な固定観念が強化され、既存の偏見が永続化する可能性があります。
2. 幻覚: LLM は、生成するコンテンツを実際には理解していません。 トレーニング データのパターンに基づいてテキストを生成します。 つまり、事実に誤りがある情報や無意味な情報が生成される可能性があり、医療診断や法的アドバイスなどの重要な用途には適していません。
3. 計算リソース: LLM のトレーニングと実行には、GPU や TPU などの特殊なハードウェアを含む膨大な計算リソースが必要です。 そのため、開発と維持にコストがかかります。
4. データのプライバシーとセキュリティ: LLM は、テキスト、画像、音声などの説得力のある偽のコンテンツを生成できます。 これにより、不正なコンテンツの作成や個人になりすますために悪用される可能性があるため、データのプライバシーとセキュリティが危険にさらされます。
5. 倫理的懸念:ディープフェイクや自動コンテンツ生成など、さまざまなアプリケーションで LLM を使用すると、悪用の可能性や社会への影響について倫理的な問題が生じます。
6. 規制上の課題: LLM テクノロジーの急速な発展は規制の枠組みを上回っており、LLM に関連する潜在的なリスクと課題に対処するための適切なガイドラインと規制を確立することが困難になっています。
これらの短所の多くは LLM に固有のものではなく、LLM がどのように開発、展開、使用されるかを反映していることに注意することが重要です。 これらの欠点を軽減し、LLM を社会に対してより責任があり有益なものにするための努力が続けられています。 ここで、グラウンディングとマスキングが活用され、企業にとって大きな利点となります。
グラウンディングの企業との関連性
企業は、大規模言語モデル (LLM) をミッションクリティカルなアプリケーションに導入することに力を入れています。 彼らは、LLM がさまざまなドメインにわたって恩恵を受ける可能性がある潜在的な価値を理解しています。 LLM の構築、事前トレーニング、微調整は非常に高価であり、煩雑です。 むしろ、業界で利用可能なオープン AI システムを使用して、エンタープライズ ユースケースに関するプロンプトをグラウンディングしてマスクすることができます。
したがって、グラウンディングは企業にとって主要な考慮事項であり、驚くべきビジネス価値を外部に引き出すことができるため、対応の質を向上させるだけでなく、幻覚、データセキュリティ、コンプライアンスの懸念を克服することの両方において、企業にとってより関連性があり、役立ちます。 LLM は、現在自動化が課題となっている数多くのユースケースに市場で利用可能です。
企業へのメリット
LLM を使用してグラウンディングを実装することには、企業にとっていくつかの利点があります。
1. 信頼性の向上: LLM によって生成された情報とコンテンツが検証済みのデータ ソースに基づいていることを保証することで、企業はコミュニケーション、レポート、コンテンツの信頼性を高めることができます。 これは、顧客、クライアント、ステークホルダーとの信頼を築くのに役立ちます。
2. 意思決定の改善: エンタープライズ アプリケーション、特にデータ分析や意思決定支援に関連するアプリケーションでは、データ基盤を備えた LLM を使用すると、より信頼性の高い洞察が得られます。 これにより、より適切な情報に基づいた意思決定が可能になり、戦略計画とビジネスの成長にとって非常に重要になります。
3. 企業コンプライアンス: 多くの業界は、データの正確性とコンプライアンスに関する規制要件の対象となります。 LLM によるデータ基盤は、これらのコンプライアンス基準を満たすのに役立ち、法的または規制上の問題のリスクを軽減します。
4. 高品質のコンテンツの生成: LLM は、マーケティング、カスタマー サポート、製品説明などのコンテンツ作成でよく使用されます。 データグラウンディングにより、生成されたコンテンツが事実に基づいて正確であることが保証され、虚偽または誤解を招く情報や幻覚が広まるリスクが軽減されます。
5. 誤った情報の削減: フェイクニュースと誤った情報の時代において、データグラウンディングは、企業が生成または共有するコンテンツが検証済みのデータソースに基づいていることを保証することで、誤った情報の拡散と戦うのに役立ちます。
6. 顧客満足: 正確で信頼できる情報を顧客に提供することで、企業の製品やサービスに対する顧客の満足度と信頼を高めることができます。
7. リスク軽減: データ根拠は、不正確または不完全な情報に基づいて意思決定を行うリスクを軽減するのに役立ち、経済的または評判への損害につながる可能性があります。
例: 顧客の製品推奨シナリオ
openAI chatGPT を使用して、データグラウンディングがエンタープライズユースケースにどのように役立つかを見てみましょう
基本的なプロンプト
Generate a short email adding coupons on recommended products to customer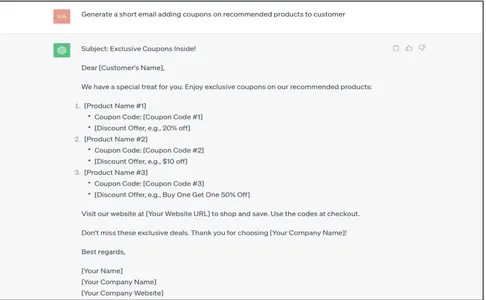
ChatGPT によって生成される応答は非常に一般的で、コンテキスト化されておらず、生の状態です。 これは、適切な企業顧客データを使用して手動で更新/マッピングする必要があり、費用がかかります。 データグラウンディング技術を使用してこれをどのように自動化できるかを見てみましょう。
たとえば、企業がすでに企業顧客データと、顧客向けのクーポンや推奨事項を生成できるインテリジェントな推奨システムを保持しているとします。 上記のプロンプトを適切なメタデータで強化することで、上記のプロンプトを非常に適切に実行することができます。これにより、chatGPT から生成された電子メール テキストは、希望するものとまったく同じになり、手動介入なしで顧客に電子メールを送信するように自動化できます。
グラウンディング エンジンが顧客データから適切なエンリッチメント メタデータを取得し、以下のプロンプトを更新すると仮定します。 接地されたプロンプトに対する ChatGPT 応答がどのようになるかを見てみましょう。
接地されたプロンプト
Generate a short email adding below coupons and products to customer Taylor and wish him a Happy holiday season from Team Aatagona, Atagona.com
Winter Jacket Mens - [https://atagona.com/men/winter/jackets/123.html] - 20% off
Rodeo Beanie Men’s - [https://atagona.com/men/winter/beanies/1234.html] - 15% off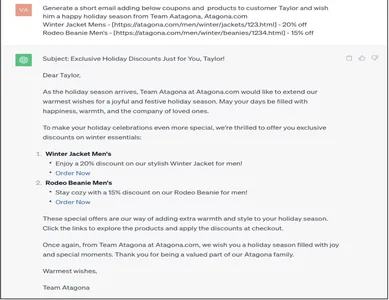
地上プロンプトで生成される応答は、まさに企業が顧客に通知したいと考えている方法です。 Gen AI からの電子メール応答に埋め込まれる充実した顧客データは、企業のスケールアップと維持に驚くべき自動化です。
ソフトウェア システム向けのエンタープライズ LLM 接地ソリューション
エンタープライズ システムでデータをグラウンディングするには複数の方法があり、これらの手法を組み合わせて使用すると、効果的なデータ グラウンディングとユース ケースに固有の迅速な生成が可能になります。 検索拡張生成 (グラウンディング) を実装するための潜在的なソリューションとしての XNUMX つの主な候補は次のとおりです。
- アプリケーション データ|ナレッジ グラフ
- ベクトル埋め込みとセマンティック検索
これらのソリューションの使用法は、ユースケースと適用するグラウンディングによって異なります。 たとえば、ベクトル ストアで提供される応答は不正確で曖昧な場合がありますが、ナレッジ グラフは正確かつ正確に返され、人間が判読できる形式で保存されます。
上記に加えて、他のいくつかの戦略を組み合わせることができます。
- 外部API、検索エンジンとの連携
- データマスキングおよびコンプライアンス遵守システム
- 内部データストアやシステムとの統合
- 複数のソースからのデータをリアルタイムで統合する
このブログでは、エンタープライズ アプリケーション データ グラフをどのように実現できるかについて、サンプル ソフトウェア設計を見てみましょう。
エンタープライズナレッジグラフ
ナレッジ グラフは、さまざまなエンティティの意味情報とそれらの間の関係を表すことができます。 エンタープライズの世界では、顧客、製品などに関する知識が保存されます。 企業の顧客グラフは、データを効果的にグラウンディングし、充実したプロンプトを生成するための強力なツールとなります。 ナレッジ グラフによりグラフベースの検索が可能になり、ユーザーはリンクされた概念やエンティティを通じて情報を探索できるようになり、より正確で多様な検索結果が得られます。
ベクターデータベースとの比較
接地ソリューションの選択は、ユースケースに応じて異なります。 ただし、グラフにはベクトルに比べて次のような利点がいくつかあります。
| 基準 | グラフのグラウンディング | ベクトル接地 |
| 分析クエリ | データ グラフは構造化データや分析クエリに適しており、抽象的なグラフ レイアウトにより正確な結果が得られます。 | ベクター データ ストアは、主に非構造化データ、ベクター埋め込みによるセマンティック検索を操作し、類似性スコアリングに依存しているため、分析クエリではそれほどパフォーマンスが良くない可能性があります。 |
| 正確さと信頼性 | ナレッジ グラフはノードと関係を使用してデータを保存し、存在する情報のみを返します。 不完全または無関係な結果を回避します。 | ベクトル データベースは、主に類似性スコアと事前定義された結果制限に依存しているため、不完全または無関係な結果を提供する可能性があります。 |
| 幻覚の矯正 | ナレッジ グラフは透明性があり、人間が判読できるデータ表現を備えています。 これらは、誤った情報を特定して修正し、クエリの経路を追跡して修正するのに役立ち、LLM (大規模言語モデル) の精度を向上させます。 | ベクトル データベースは、読み取り可能な形式で保存されていないブラック ボックスとして見られることが多く、誤った情報の特定と修正が容易ではない可能性があります。 |
| セキュリティとガバナンス | ナレッジ グラフにより、データ生成、ガバナンス、GDPR などの規制を含むコンプライアンスの順守をより適切に制御できます。 | ベクター データベースは、その不透明な性質により、制限やガバナンスを課す際に課題に直面する可能性があります。 |
高レベルの設計
非常に高いレベルで、ナレッジ グラフとオープン LLM をグラウンディングに使用する企業をシステムがどのように検索できるかを見てみましょう。
基本レイヤーは、企業の顧客データとメタデータがさまざまなデータベース、データ ウェアハウス、データ レイクにわたって保存される場所です。 このデータからデータナレッジグラフを構築し、それをグラフデータベースに保存するサービスが存在する可能性があります。 分散クラウド ネイティブの世界には、これらのデータ ストアと対話する多数のエンタープライズ サービスやマイクロ サービスが存在する可能性があります。 これらのサービスの上には、基盤となるインフラを利用するさまざまなアプリケーションが存在する可能性があります。
アプリケーションには、シナリオやインテリジェントに自動化された顧客フローに AI を組み込むための多数のユースケースがあり、これには内部および外部の AI システムとの対話が必要です。 生成 AI シナリオの場合、企業がホリデー シーズン中にパーソナライズされた推奨製品のいくつかの割引を提案する電子メールを介して顧客をターゲットにしたいというワークフローの簡単な例を考えてみましょう。 AI をより効果的に活用して、一流の自動化によってこれを実現できます。
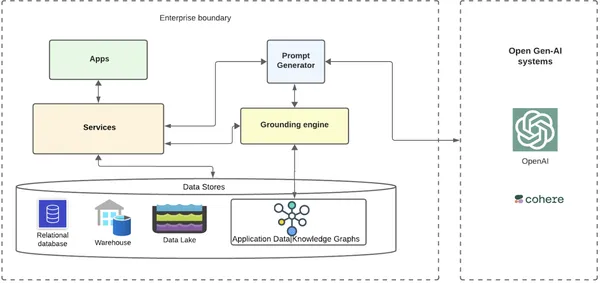
ワークフロー
- 電子メールを送信するワークフローは、顧客のコンテキスト化されたデータを含む根拠のあるプロンプトを送信することにより、オープン Gen-AI システムの助けを借りることができます。
- ワークフロー アプリケーションは、GenAI システムを利用して電子メール テキストを取得するリクエストをバックエンド サービスに送信します。
- バックエンド サービスはサービスをプロンプト ジェネレーター サービスにルーティングし、プロンプト ジェネレーター サービスは接地エンジンにルーティングします。
- グラウンディング エンジンは、サービスの XNUMX つからすべての顧客メタデータを取得し、顧客データのナレッジ グラフを取得します。
- グラウンディング エンジンは、ノードと関連関係全体にわたってグラフを走査し、必要な最終的な情報を抽出し、それをプロンプト ジェネレーターに送り返します。
- プロンプト ジェネレーターは、ユースケースの既存のテンプレートを使用して根拠のあるデータを追加し、企業が統合することを選択したオープン AI システム (OpenAI/Cohere など) に根拠のあるプロンプトを送信します。
- Open GenAI システムは、より関連性が高くコンテキストに応じた応答を企業に返し、電子メールで顧客に送信します。
これを XNUMX つの部分に分けて詳しく理解しましょう。
1. 顧客ナレッジグラフの生成
以下の設計は上記の例に適していますが、要件に応じてさまざまな方法でモデリングを行うことができます。
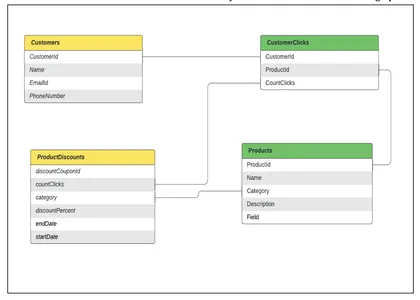
データモデリング: グラフ内のノードとしてモデル化されたさまざまなテーブルがあり、ノード間の関係としてテーブル間を結合すると仮定します。 上の例では、次のものが必要です。
- 顧客のデータを保持するテーブル、
- 製品データを保持するテーブル、
- パーソナライズされた推奨事項の CustomerInterests(Clicks) データを保持するテーブル
- ProductDiscounts データを保持するテーブル
このすべてのデータを複数のデータ ソースから取り込み、定期的に更新して顧客に効果的にアプローチするのは企業の責任です。
これらのテーブルをどのようにモデル化し、どのように顧客グラフに変換できるかを見てみましょう。
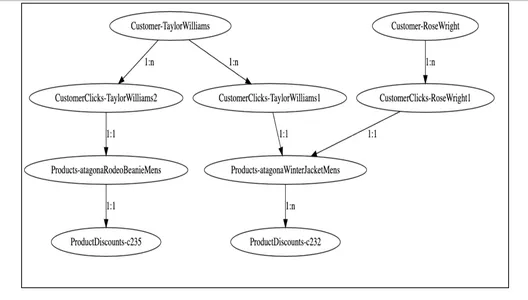
2. グラフモデリング
上記のグラフ ビジュアライザから、顧客ノードがクリック エンゲージメント データに基づいてさまざまな製品にどのように関連付けられ、さらに割引ノードとどのように関連付けられているかがわかります。 グラウンディング サービスでは、これらの顧客グラフをクエリし、関係を通じてこれらのノードを横断し、それぞれの顧客に適用される割引に関する必要な情報を取得するのが簡単です。
上記のサンプル グラフ ノードとリレーションシップ JAVA POJO は、以下のようになります。
public class KnowledgeGraphNode implements Serializable { private final GraphNodeType graphNodeType; private final GraphNode nodeMetadata;
} public interface GraphNode {
} public class CustomerGraphNode implements GraphNode { private final String name; private final String customerId; private final String phone; private final String emailId;
}
public class ClicksGraphNode implements GraphNode { private final String customerId; private final int clicksCount;
} public class ProductGraphNode implements GraphNode { private final String productId; private final String name; private final String category; private final String description; private final int price;
} public class ProductDiscountNode implements GraphNode { private final String discountCouponId; private final int clicksCount; private final String category; private final int discountPercent; private final DateTime startDate; private final DateTime endDate;
}
public class KnowledgeGraphRelationship implements Serializable { private final RelationshipCardinality Cardinality; } public enum RelationshipCardinality { ONE_TO_ONE, ONE_TO_MANY }このシナリオのサンプル生グラフは次のようになります。
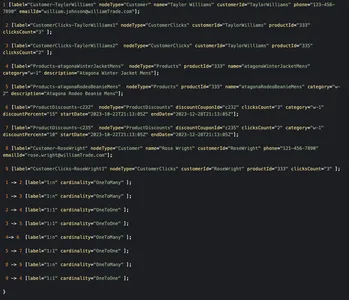
顧客ノード「Taylor Williams」からグラフをたどることで問題が解決され、適切な製品の推奨事項と対象となる割引が取得されます。
3. 業界で人気のGraphストア
市場には、エンタープライズ アーキテクチャに適したグラフ ストアが数多く存在します。 Neo4j、TigerGraph、Amazon Neptune、OrientDB がグラフ データベースとして広く採用されています。
グラフ データ レイクの新しいパラダイムを導入します。これにより、表形式データ (湖、倉庫、湖小屋の構造化データ) に対するグラフ クエリが可能になります。 これは、Zero-ETL を活用して、グラフ データ ストアにデータをハイドレートしたり永続化したりする必要がなく、以下に示す新しいソリューションで実現されます。
- PuppyGraph(グラフデータレイク)
- Timbr.ai
コンプライアンスと倫理的配慮
データ保護: 企業は、GDPR およびその他の PII コンプライアンスに従って顧客データを保存および使用する責任を負わなければなりません。 保存されたデータは、洞察を得たり AI を適用したりするために処理および再利用する前に、管理およびクレンジングする必要があります。
幻覚と和解:企業は、データ内の誤った情報を特定し、クエリの経路を追跡し、修正する調整サービスを追加することもできます。これにより、LLM の精度を向上させることができます。 ナレッジ グラフを使用すると、保存されたデータが透明で人間が判読できるため、これを実現するのは比較的簡単です。
制限的な保存ポリシー: オープン LLM システムとのやり取り中にデータ保護を遵守し、顧客データの悪用を防ぐには、企業がやり取りする外部システムが、要求されたプロンプト データをさらなる分析やビジネス目的で保持しないように、保持ポリシーをゼロにすることが非常に重要です。
まとめ
結論として、大規模言語モデル (LLM) は、人工知能と自然言語処理における目覚ましい進歩を表しています。 自然言語の理解と生成から複雑なタスクの支援まで、さまざまな業界やアプリケーションを変革できます。 ただし、LLM を成功させ、責任を持って使用するには、さまざまな主要分野における強力な基盤と基礎が必要です。
主要な取り組み
- 企業は、さまざまなシナリオで LLM を使用する際に、効果的なグラウンディングとプロンプトから大きな利益を得ることができます。
- ナレッジ グラフとベクトル ストアは一般的なグラウンディング ソリューションであり、どちらを選択するかはソリューションの目的によって異なります。
- ナレッジ グラフには、ベクター ストアよりも正確で信頼性の高い情報を含めることができるため、セキュリティ層やコンプライアンス層を追加することなく、エンタープライズ ユース ケースに優位性をもたらします。
- エンティティとリレーションシップを使用した従来のデータ モデリングを、ノードとエッジを使用したナレッジ グラフに変換します。
- エンタープライズ ナレッジ グラフとさまざまなデータ ソースを既存のビッグ データ ストレージ企業と統合します。
- ナレッジ グラフは分析クエリに最適です。 グラフ データ レイクを使用すると、表形式のデータをエンタープライズ データ ストレージ内のグラフとしてクエリできるようになります。
よくある質問
A. LLM は、DL 技術と大規模なデータ セットを使用して、新しいコンテンツを理解、要約、生成、予測する AI アルゴリズムです。
A. アプリケーション データ グラフは、ノードとエッジの形式でデータを格納するデータ構造です。 それらを異なるデータノード間の関係としてモデル化します。
A. ベクトル データベースは、テキスト、音声、ビデオなどの非構造化データを保存および管理します。 レコメンデーション エンジン、機械学習、Gen-AI などのアプリケーションの迅速なインデックス作成と取得に優れています。
A. ベクトル ストアでは、エンベディングは高次元ベクトル空間内のオブジェクト、単語、またはデータ ポイントの数値表現です。 これらの埋め込みは、アイテム間の意味的な関係と類似性をキャプチャし、効率的なデータ分析、類似性検索、機械学習タスクを可能にします。
A. 構造化データは、定義されたテーブルとスキーマでよく整理されています。 テキスト、画像、音声、ビデオなどの非構造化データは、形式がないため分析が困難です。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/11/the-role-of-enterprise-knowledge-graphs-in-llms/

