AWSグルー は、分析、機械学習 (ML)、アプリケーション開発のための複数のソースからのデータの検出、準備、移動、統合を簡単に行うことができるサーバーレス データ統合サービスです。
AWS Glue の顧客は多くの場合、厳しいセキュリティ要件を満たす必要があります。これには、ジョブに許可されているネットワーク接続のロックダウンや、別のサービスにアクセスするために特定の VPC 内での実行が含まれる場合があります。 VPC 内で実行するには、ジョブを単一のサブネットに割り当てる必要がありますが、最適なサブネットは時間の経過とともに (たとえば、使用状況や可用性に基づいて) 変化する可能性があるため、実行時に決定することをお勧めします。自分なりの戦略で。
ApacheAirflowのAmazonマネージドワークフロー (Amazon MWAA) は、マネージド Airflow ワークフローを実行する AWS サービスです。これにより、AWS Glue ジョブなどのタスクの実行方法を調整するカスタム ロジックを作成できます。
この投稿では、実行時にジョブに割り当てられる VPC サブネットを動的に構成可能に選択して、Airflow ワークフローの一部として AWS Glue ジョブを実行する方法を示します。
ソリューションの概要
VPC 内で実行するには、AWS Glue ジョブに少なくともネットワーク構成を含む接続を割り当てる必要があります。どの接続でも VPC、サブネット、セキュリティ グループを指定できますが、簡単にするために、この投稿ではタイプ: NETWORK の接続を使用します。これはネットワーク構成を定義するだけであり、外部システムは関与しません。
ジョブに単一の接続によって割り当てられた固定サブネットがある場合、サービスが停止した場合に備えて、 アベイラビリティーゾーン または、他の理由でサブネットが利用できない場合、ジョブは実行できません。さらに、AWS Glue ジョブの各ノード (ドライバーまたはワーカー) には、サブネットから割り当てられた IP アドレスが必要です。多くの大規模なジョブを同時に実行すると、IP アドレスが不足し、ジョブが意図したよりも少ないノードで実行されたり、まったく実行されなかったりする可能性があります。
AWS Glue の抽出、変換、ロード (ETL) ジョブを使用すると、複数のネットワーク構成で複数の接続を指定できます。ただし、ジョブは常にリストされた順序で接続のネットワーク構成を使用しようとし、最初に合格したものを選択します。 健康診断 ジョブを開始するには少なくとも 2 つの IP アドレスが必要ですが、これは最適なオプションではない可能性があります。
このソリューションを使用すると、接続の順序を動的に変更し、選択の優先順位を定義することで、その動作を強化およびカスタマイズできます。再試行が必要な場合は、前回の実行以降に条件が変更されている可能性があるため、戦略に基づいて接続の優先順位が再度設定されます。
その結果、ネットワークのセキュリティと接続の要件を満たしながら、サブネット IP アドレスの不足や機能停止によるジョブの実行失敗や容量不足を防ぐことができます。
次の図は、ソリューションのアーキテクチャを示しています。

前提条件
投稿の手順に従うには、にログインできるユーザーが必要です。 AWSマネジメントコンソール Amazon MWAA へのアクセス権限を持っており、 アマゾン バーチャル プライベート クラウド (Amazon VPC)、および AWS Glue。ソリューションのデプロイ先として選択した AWS リージョンには、VPC と 2 つの Elastic IP アドレスを作成する容量が必要です。どちらのタイプのリソースのデフォルトのリージョン クォータは 5 であるため、コンソール経由で増加をリクエストする必要がある場合があります。
また、 AWS IDおよびアクセス管理 (IAM) ロールは、AWS Glue ジョブをまだ持っていない場合に実行するのに適しています。手順については、を参照してください。 AWSGlueのIAMロールを作成します.
Airflow 環境と VPC をデプロイする
まず、2 つのパブリック サブネットと 2 つのプライベート サブネットを持つ新しい VPC の作成を含む、新しい Airflow 環境をデプロイします。これは、Amazon MWAA にはアベイラビリティーゾーンの障害耐性が必要であるため、リージョン内の 2 つの異なるアベイラビリティーゾーン上の 2 つのサブネットで実行する必要があるためです。パブリック サブネットは、NAT ゲートウェイがプライベート サブネットにインターネット アクセスを提供できるようにするために使用されます。
次の手順を完了します。
- 作る AWS CloudFormation 次のテンプレートをコピーして、コンピュータにテンプレートを保存します。 クイックスタートガイド ローカルテキストファイルにコピーします。
- AWS CloudFormationコンソールで、 スタック ナビゲーションペインに表示されます。
- 選択する スタックを作成 オプション付き 新しいリソースを使用(標準).
- 選択する テンプレートファイルをアップロードする をクリックして、ローカル テンプレート ファイルを選択します。
- 選択する Next.
- 環境の名前を入力してセットアップ手順を完了し、残りのパラメータはデフォルトのままにします。
- 最後のステップで、リソースが作成されることを確認し、 送信.
作成には、スタックのステータスが次のように変わるまで 20 ~ 30 分かかる場合があります。 CREATE_COMPLETE.
最も時間がかかるリソースは Airflow 環境です。作成中は、Airflow UI を開く必要があるまで、次の手順を続行できます。
- スタック上 リソース タブで、VPC と 2 つのプライベート サブネット (
PrivateSubnet1&PrivateSubnet2)、次のステップで使用します。
AWS Glue 接続を作成する
CloudFormation テンプレートは 2 つのプライベート サブネットをデプロイします。このステップでは、AWS Glue ジョブを実行できるように、それぞれへの AWS Glue 接続を作成します。 Amazon MWAA は最近、共有 VPC 上で Airflow クラスターを実行する機能を追加しました。これにより、コストが削減され、ネットワーク管理が簡素化されます。詳細については、以下を参照してください。 Amazon MWAA での共有 VPC サポートの導入.
接続を作成するには、次の手順を実行します。
- AWS Glue コンソールで、選択します データ接続 ナビゲーションペインに表示されます。
- 選択する 接続を作成する.
- 選択する ネットワーク データソースとして。
- VPC とプライベート サブネットを選択します (
PrivateSubnet1) CloudFormation スタックによって作成されます。 - デフォルトのセキュリティグループを使用します。
- 選択する Next.
- 接続名として次のように入力します。
MWAA-Glue-Blog-Subnet1. - 詳細を確認して作成を完了します。
- を使用してこれらの手順を繰り返します
PrivateSubnet2接続に名前を付けますMWAA-Glue-Blog-Subnet2.
AWSGlueジョブを作成します
ここで、後で Airflow ワークフローによってトリガーされる AWS Glue ジョブを作成します。ジョブは前のセクションで作成した接続を使用しますが、通常のようにジョブに直接割り当てるのではなく、このシナリオではジョブ接続リストを空のままにして、実行時にどれを使用するかをワークフローに決定させます。
この場合のジョブ スクリプトは重要ではなく、接続に応じてサブネットの 1 つでジョブが実行されることを示すことだけを目的としています。
- AWS Glue コンソールで、選択します ETL ジョブ ナビゲーションペインで、を選択します スクリプトエディタ.
- デフォルトのオプション (Spark エンジンと 新鮮なスタート)と選択 スクリプトの作成.
- プレースホルダー スクリプトを次の Python コードに置き換えます。
- ジョブの名前を次のように変更します
AirflowBlogJob. - ソフトウェア設定ページで、下図のように 仕事の詳細 タブ、 IAMの役割、任意のロールを選択し、ワーカー数として 2 を入力します (倹約のため)。
- これらの変更を保存してジョブを作成します。
AWS Glue 権限を Airflow 環境ロールに付与する
CloudFormation テンプレートによって Airflow 用に作成されたロールは、ワークフローを実行するための基本的なアクセス許可を提供しますが、AWS Glue などの他のサービスと対話するための基本的なアクセス許可は提供しません。運用プロジェクトでは、これらの追加のアクセス許可を使用して独自のテンプレートを定義しますが、この投稿では、簡単にするために、追加のアクセス許可をインライン ポリシーとして追加します。次の手順を実行します。
- IAMコンソールで、 役割 ナビゲーションペインに表示されます。
- テンプレートによって作成されたロールを見つけます。 CloudFormation スタックに割り当てた名前で始まり、その後に
-MwaaExecutionRole-. - ロールの詳細ページで、 権限を追加 メニュー、選択 インラインポリシーを作成する.
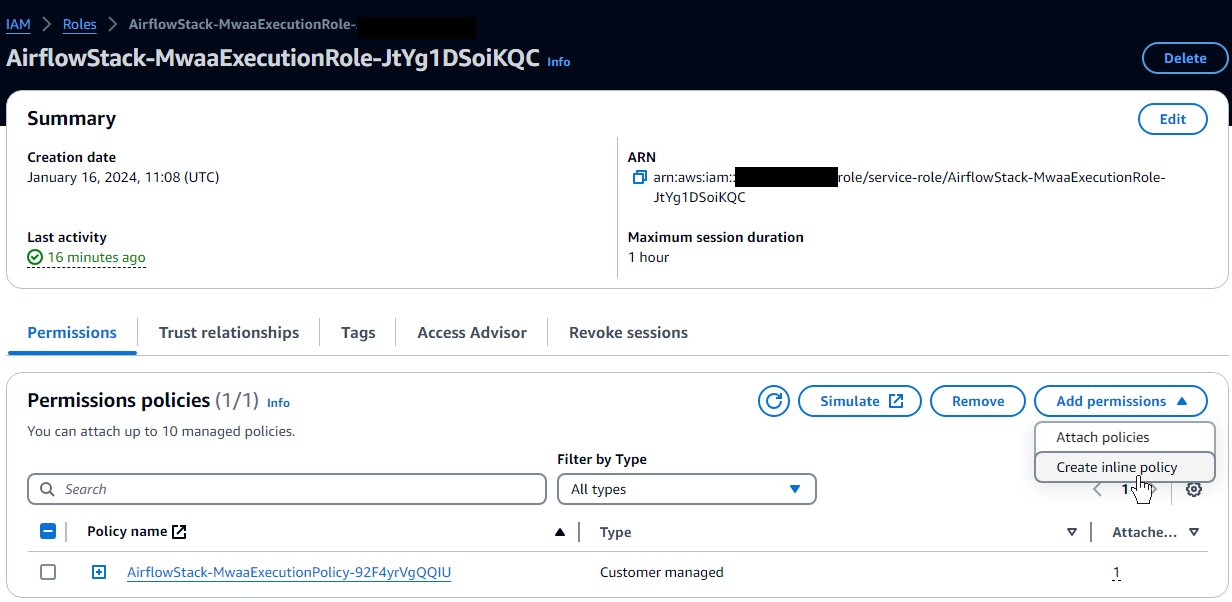
- Visual モードから JSON モードに切り替え、テキスト ボックスに次の JSON を入力します。持っている AWS Glue ロールが、以下で始まる規則に従っていることを前提としています。
AWSGlueServiceRole。セキュリティを強化するために、ワイルドカード リソースをec2:DescribeSubnetsCloudFormation スタックからの 2 つのプライベート サブネットの ARN によるアクセス許可。 - 選択する Next.
- 入力します
GlueRelatedPermissionsポリシー名として入力し、作成を完了します。
この例では、ETL スクリプト ジョブを使用します。ビジュアル ジョブの場合、保存時にスクリプトが自動的に生成されるため、Airflow ロールには、設定されたスクリプト パスに書き込む権限が必要です。 Amazon シンプル ストレージ サービス (Amazon S3)。
エアフロー DAG を作成する
Airflow ワークフローは、有向非巡回グラフ (DAG) に基づいています。DAG は、関係するさまざまなタスクとその相互依存関係をプログラムで指定する Python ファイルによって定義されます。 DAG を作成するには、次のスクリプトを実行します。
- という名前のローカル ファイルを作成します。
glue_job_dag.pyテキストエディタを使用します。
次の各手順では、ファイルに入力するコード スニペットとその動作の説明を示します。
- 次のスニペットは、必要な Python モジュールのインポートを追加します。モジュールはすでに Airflow にインストールされています。そうでない場合は、
requirements.txtファイルを使用して、どのモジュールをインストールするかを Airflow に指示します。また、コードが後で使用する Boto3 クライアントも定義します。デフォルトでは、Airflow と同じロールとリージョンが使用されるため、ロールの前に必要な追加の権限を設定します。 - 次のスニペットでは、接続順序戦略を実装する 3 つの関数を追加します。これは、優先順位を確立するために指定された接続を並べ替える方法を定義します。これは単なる例です。ニーズに応じて、カスタム コードを構築して独自のロジックを実装できます。コードはまず、各接続サブネットで使用可能な IP をチェックし、ジョブをフル キャパシティーで実行するのに十分な IP を使用できるものと、ジョブに必要な少なくとも 2 つの使用可能な IP があるために使用できるものを分離します。始める。戦略が次のように設定されている場合
randomを実行すると、前述の各接続グループ内の順序がランダム化され、他の接続が追加されます。戦略があるとすれば、capacity、無料のほとんどの IP から最も少ない IP の順にそれらを並べ替えます。 - 次のコードは、ジョブ実行タスクを使用して DAG 自体を作成します。このタスクは、戦略で定義された接続順序でジョブを更新し、実行して、結果を待ちます。ジョブ名、接続、および戦略は Airflow 変数から取得されるため、簡単に構成および更新できます。指数バックオフが設定された 2 回の再試行があるため、タスクが失敗した場合は、接続の選択を含む完全なタスクが繰り返されます。おそらく、現時点での最良の選択は別の接続であるか、以前にランダムに選択されたサブネットが現在障害を受けているアベイラビリティーゾーン内にあり、別の接続を選択することで回復できる可能性があります。
Airflow ワークフローを作成する
次に、作成したばかりの AWS Glue ジョブを呼び出すワークフローを作成します。
- Amazon S3 コンソールで、CloudFormation テンプレートによって作成されたバケットを見つけます。このバケットには、スタック名で始まり、
-environmentbucket-(例えば、myairflowstack-environmentbucket-ap1qks3nvvr4). - そのバケット内に、という名前のフォルダーを作成します。
dags、そのフォルダー内に DAG ファイルをアップロードしますglue_job_dag.py前のセクションで作成したもの。 - Amazon MWAA コンソールで、CloudFormation スタックを使用してデプロイした環境に移動します。
ステータスがまだの場合 利用できます、その状態になるまで待ちます。 CloudFormation スタックをデプロイしてから、30 分以上かかることはありません。
- 表上の環境リンクを選択すると、環境の詳細が表示されます。
前の手順で使用したバケットとフォルダーから DAG を取得するように構成されています。 Airflow はそのフォルダーの変更を監視します。
- 選択する オープンエアフローUI 新しいタブを開いて Airflow UI にアクセスし、統合された IAM セキュリティを使用してログインします。
作成した DAG ファイルに問題がある場合は、影響を受けた行を示すエラーがページの上部に表示されます。その場合は手順を見直して再度アップロードしてください。数秒後、それが解析され、エラー バナーが更新または削除されます。
- ソフトウェア設定ページで、下図のように メニュー、選択 Variables.
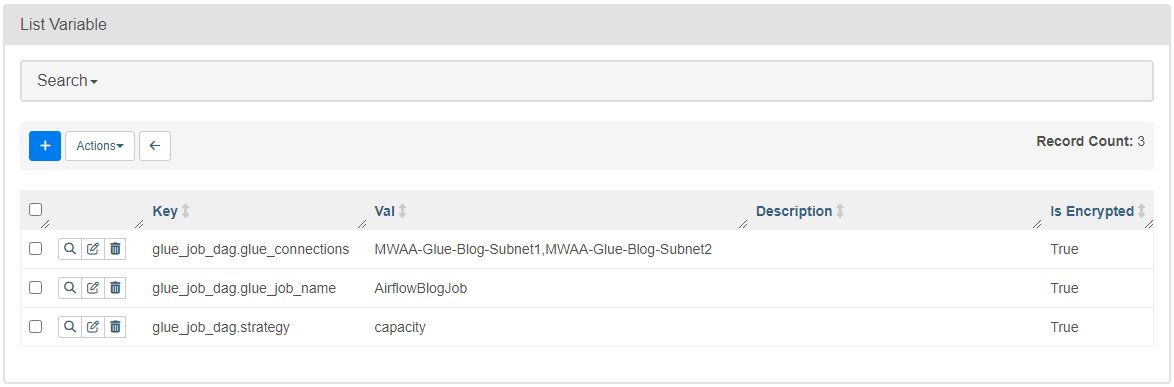
- 次のキーと値を持つ 3 つの変数を追加します。
- キー
glue_job_dag.glue_connections価値ありMWAA-Glue-Blog-Subnet1,MWAA-Glue-Blog-Subnet2. - キー
glue_job_dag.glue_job_name価値ありAirflowBlogJob. - キー
glue_job_dag.strategy価値ありcapacity.
- キー
動的サブネット割り当てを使用してジョブを実行する
これで、ワークフローを実行し、接続を動的に並べ替える戦略を確認する準備が整いました。
- Airflow UIで、[ DAG、行上で
glue_job_dag、再生アイコンを選択します。 - ソフトウェア設定ページで、下図のように ブラウズ メニュー、選択 タスクインスタンス.
- インスタンス テーブルで右にスクロールして、
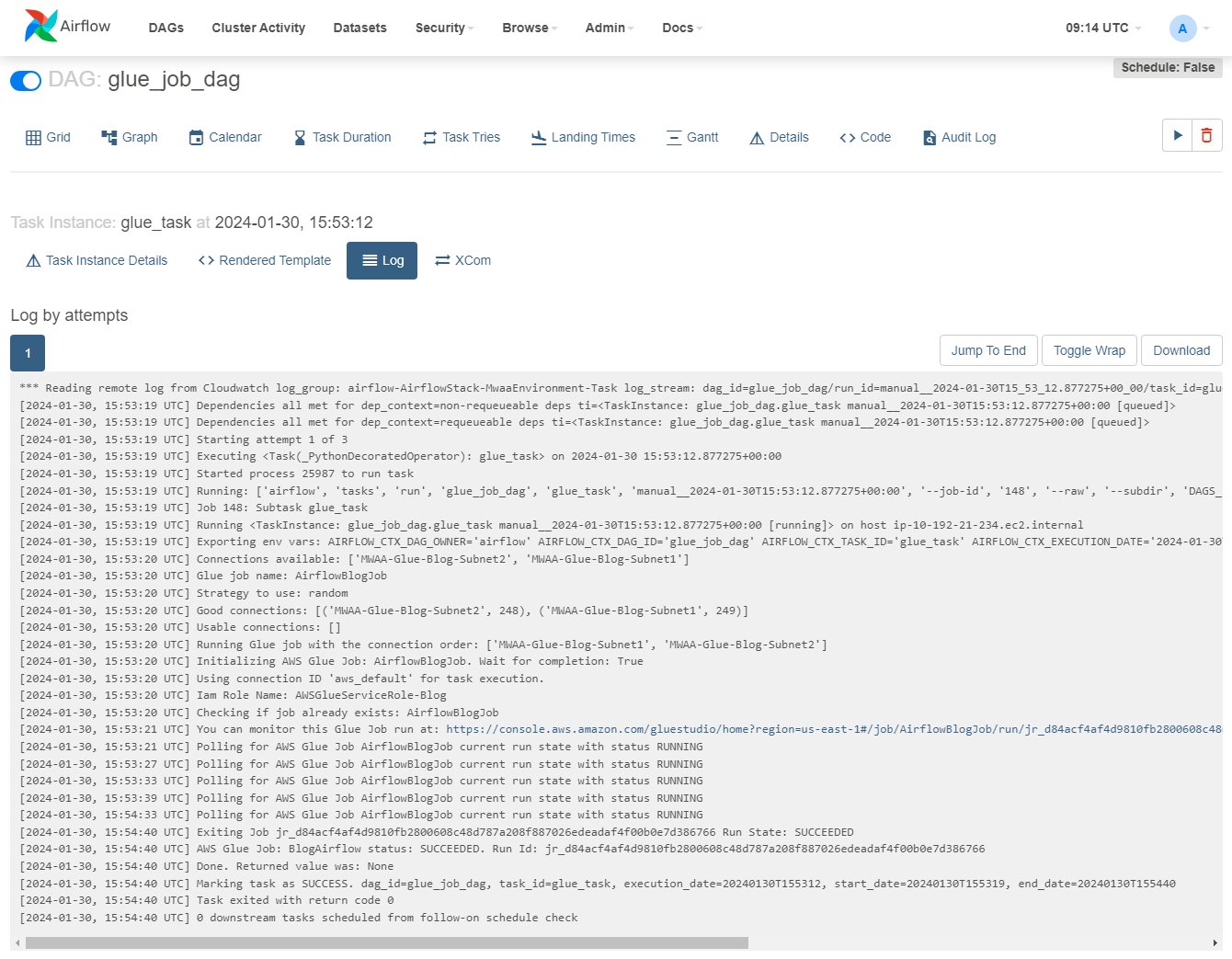
Log Urlその上のアイコンを選択してログを開きます。
タスクが実行されるとログが更新されます。 「Running Glue job with the connection order:」で始まる行と、その前の行に接続 IP と割り当てられたカテゴリの詳細が表示されていることがわかります。エラーが発生した場合は、このログに詳細が表示されます。
- AWS Glue コンソールで、選択します ETL ジョブ ナビゲーションペインでジョブを選択します
AirflowBlogJob. - ソフトウェア設定ページで、下図のように Active Runs タブで実行インスタンスを選択し、 出力ログ リンクをクリックすると、新しいタブが開きます。
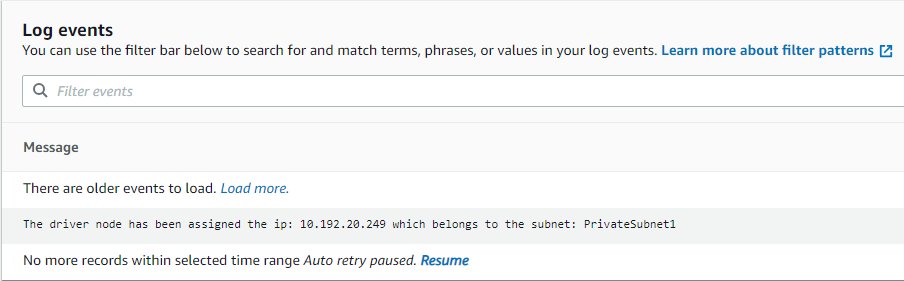
- 新しいタブで、ログ ストリーム リンクを使用して開きます。
ドライバーに割り当てられた IP と、ドライバーが属するサブネットが表示されます。これは、Airflow によって示された接続と一致する必要があります (ログが表示されない場合は、 履歴書 そのため、利用可能になるとすぐに更新されます)。
- Airflow UI で、Airflow 変数を編集します
glue_job_dag.strategyに設定するにはrandom. - DAG を複数回実行して、順序がどのように変化するかを確認します。
クリーンアップ
デプロイメントが不要になった場合は、追加料金が発生しないようにリソースを削除してください。
- アップロードした Python スクリプトを削除すると、次のステップで S3 バケットが自動的に削除されるようになります。
- CloudFormation スタックを削除します。
- AWS Glue ジョブを削除します。
- ジョブが Amazon S3 に保存したスクリプトを削除します。
- この投稿の一部として作成した接続を削除します。
まとめ
この投稿では、AWS Glue と Amazon MWAA が連携して、運用と管理のオーバーヘッドを最小限に抑えながら、より高度なカスタム ワークフローを構築する方法を説明しました。このソリューションにより、特別な運用要件、ネットワーク要件、またはセキュリティ要件を満たすために AWS Glue ジョブの実行方法をより詳細に制御できるようになります。
独自の Amazon MWAA 環境は、次のような複数の方法でデプロイできます。 template この投稿、Amazon MWAA コンソール、または AWSCLI。また、ネットワークアーキテクチャと要件に基づいて、AWS Glue ジョブを調整するための独自の戦略を実装することもできます (たとえば、可能な限りデータに近い場所でジョブを実行するなど)。
著者について
 マイケル・グリーンスタイン 公共部門の分析スペシャリスト ソリューション アーキテクトです。
マイケル・グリーンスタイン 公共部門の分析スペシャリスト ソリューション アーキテクトです。
 ゴンザロエレロス AWS Glue チームのシニアビッグデータアーキテクトです。
ゴンザロエレロス AWS Glue チームのシニアビッグデータアーキテクトです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/combine-aws-glue-and-amazon-mwaa-to-build-advanced-vpc-selection-and-failover-strategies/

