企業がさまざまなソースから収集するデータの量が増加するにつれて、進化する分析ニーズに対応するために、そのデータの構造と構成を時間の経過とともに変更する必要があることがよくあります。ただし、従来のデータ レイクでのスキーマとテーブル パーティションの変更は、テーブル全体の名前変更や再作成、大規模なデータセットの再処理が必要となり、中断と時間のかかる作業になる可能性があります。これにより、機敏性が損なわれ、洞察を得るまでの時間が妨げられます。
スキーマの進化により、既存のデータを書き換えることなく、列の追加、削除、名前変更、変更が可能になります。これは、動きの速い企業がデータ構造を強化して新しいユースケースをサポートするために非常に重要です。たとえば、e コマース企業は、分析を強化するために、新しい顧客人口統計属性や注文ステータス フラグを追加する場合があります。 アパッチ氷山 は、革新的なメタデータ テーブル進化アーキテクチャを通じて、下位互換性のある方法でこれらのスキーマ変更を管理します。
同様に、パーティションの進化により、パーティションの追加、削除、分割をシームレスに行うことができます。たとえば、e コマース マーケットプレイスでは、最初に注文データを日ごとに分割する場合があります。注文が蓄積され、日ごとのクエリが非効率になると、注文が日と顧客 ID のパーティションに分割される場合があります。テーブル パーティショニングは、クエリのパフォーマンスを高めるために大きなデータセットを最も効率的に整理します。 Iceberg を使用すると、企業は面倒な再構築手順を必要とせずに、パーティションを段階的に調整できる柔軟性が得られます。新しいパーティションは、ダウンタイムを発生させたり、既存のデータ ファイルを書き換えたりすることなく、完全に互換性のある方法で追加できます。
この投稿では、Iceberg を活用する方法を示します。 Amazon シンプル ストレージ サービス (Amazon S3)、 AWSグルー, AWSレイクフォーメーション, AWS IDおよびアクセス管理 (IAM) シームレスな進化をサポートするトランザクション データ レイクを実装します。データの分析情報の進化に応じてスキーマとパーティションを簡単に調整できるようにすることで、ビジネスの成功に必要な将来を見据えた柔軟性の恩恵を受けることができます。
ソリューションの概要
この使用例では、架空の大規模な e コマース会社が毎日数千件の注文を処理します。注文の受信、更新、キャンセル、出荷、配送、返品が行われると、オンプレミス システムで変更が行われ、データ アナリストがクエリを実行できるように、それらの変更を S3 データ レイクにレプリケートする必要があります。 アマゾンアテナ。変更にはスキーマの更新も含まれる場合があります。さまざまな組織のセキュリティ要件により、Lake Formation を通じてアナリストに対するきめ細かいアクセス制御を管理する必要があります。
次の図は、ソリューションのアーキテクチャを示しています。
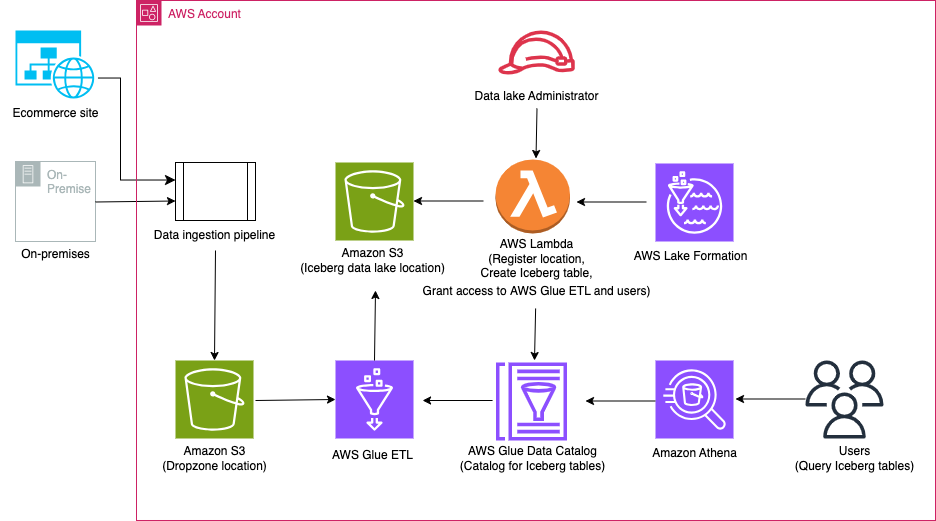
ソリューションのワークフローには、次の主要な手順が含まれます。
- データ取り込みパイプラインを使用して、オンプレミスから Dropzone の場所にデータを取り込みます。
- AWS Glue を使用して、Dropzone の場所から Iceberg にデータをマージします。
- Athena を使用してデータをクエリします。
前提条件
このチュートリアルでは、次の前提条件を満たしている必要があります。
AWS CloudFormation を使用してインフラストラクチャをセットアップする
インフラストラクチャを作成するには AWS CloudFormation テンプレートを使用して、次の手順を実行します。
- 管理者として AWS アカウントにログインします。
- AWS CloudFormation コンソールを開きます。
- 選択する 発射スタック:

- スタック名、名前を入力します (この投稿では、icebergdemo1)。
- 選択する Next.
- 次のパラメータの情報を入力します。
DatalakeUserNameDatalakeUserPasswordDatabaseNameTableNameDatabaseLFTagKeyDatabaseLFTagValueTableLFTagKeyTableLFTagValue
- 選択する Next.
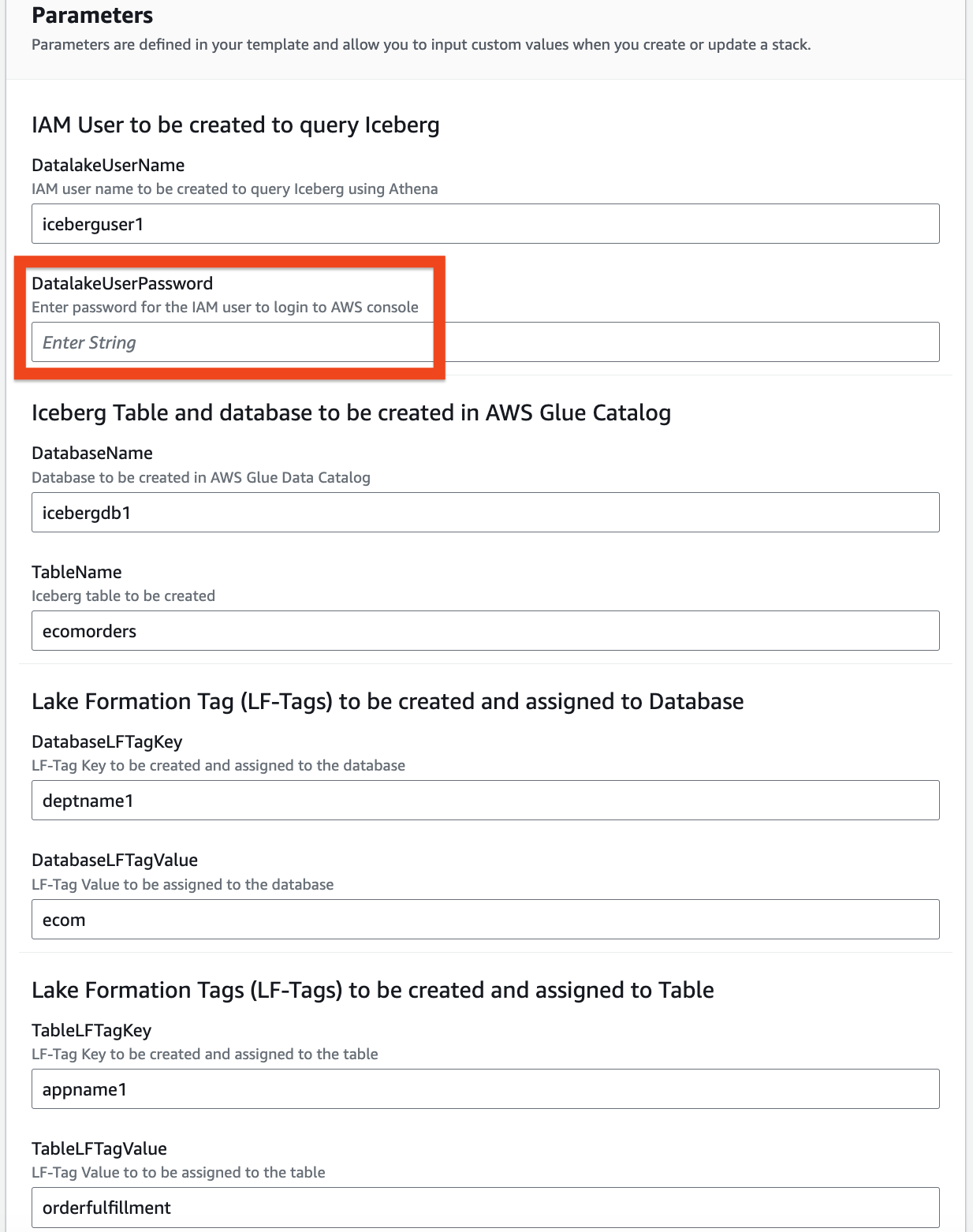
- 選択する 次も.
- レビュー セクションで、入力した値を確認します。
- 選択 AWS CloudFormationがカスタム名でIAMリソースを作成する可能性があることを認めます 選択して 送信.
数分後に、スタックのステータスが次のように変わります。 CREATE_COMPLETE.
あなたがに行くことができます 「出力」タブ スタックのプロビジョニングされたすべてのリソースを確認します。リソースには、指定したスタック名が接頭辞として付けられます (この投稿では、 icebergdemo1).
Lambda を使用して Iceberg テーブルを作成し、Lake Formation を使用してアクセスを許可する
Iceberg テーブルを作成し、そのテーブルへのアクセスを許可するには、次の手順を実行します。
- に移動します リソース CloudFormation スタックの Icebergdemo1 タブに移動し、という名前の論理 ID を検索します。
LambdaFunctionIceberg. - 関連付けられた物理 ID のハイパーリンクを選択します。
Lambda 関数にリダイレクトされます icebergdemo1-Lambda-Create-Iceberg-and-Grant-access.
- ソフトウェア設定ページで、下図のように タブを選択 環境変数 左ペインに表示されます。

- ソフトウェア設定ページで、下図のように Code タブで関数コードを検査できます。
この関数は、 AWS SDK for Python(Boto3) リソースをプロビジョニングするための API。次のタスクを実行するために、プロビジョニングされたデータ レイク管理者の役割を想定しています。
- グラント DATA_LOCATION_ACCESS 登録されたデータ レイクの場所に対するデータ レイク管理者ロールへのアクセス
- 創造する 湖層タグ (LF タグ)
- AWS Glue を使用して AWS Glue データカタログにデータベースを作成する CREATE_DATABASE API
- LFタグをデータベースに割り当てる
- LF-Tags を使用したデータベースへの DESCRIBE アクセスをデータレイク IAM ユーザーと AWS Glue ETL IAM ロールに付与します。
- AWS Glue を使用して Iceberg テーブルを作成する テーブルの作成 API:
- テーブルに LF タグを割り当てる
- データレイク IAM ユーザーに Iceberg テーブルの LF-Tags に対する DESCRIBE および SELECT を付与します。
- Iceberg テーブル LF-Tags に対する ALL、DESCRIBE、SELECT、INSERT、DELETE、および ALTER アクセスを AWS Glue ETL IAM ロールに付与します。
- ソフトウェア設定ページで、下図のように ホイール試乗 タブを選択 ホイール試乗 関数を実行します。

関数が完了すると、「関数の実行: 成功しました。」というメッセージが表示されます。
Lake Formation は、分析と機械学習用のデータを一元管理、保護し、グローバルに共有するのに役立ちます。 Lake Formation を使用すると、Amazon S3 上のデータレイク データとデータ カタログ内のそのメタデータに対するきめ細かいアクセス制御を管理できます。
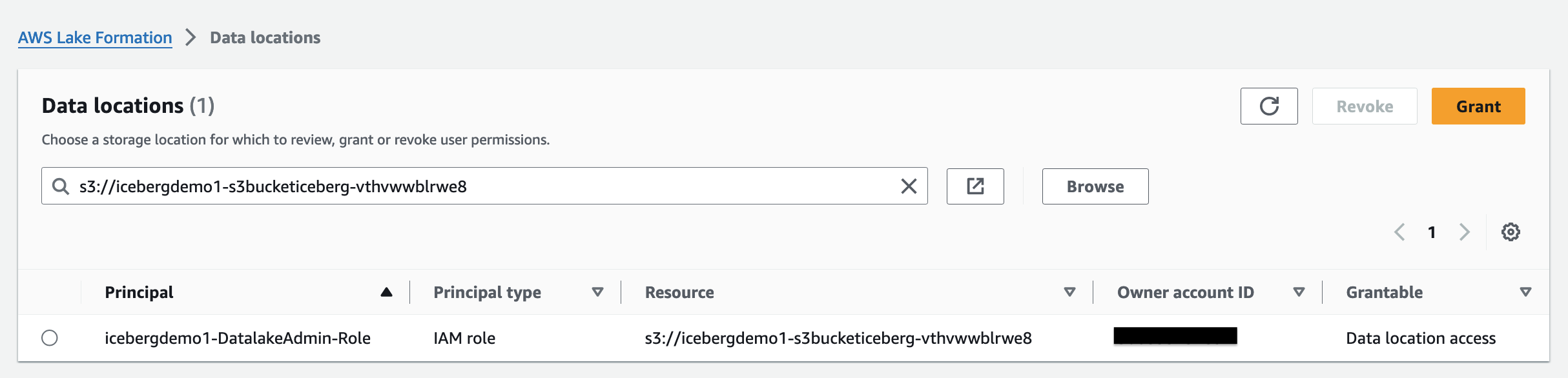
Amazon S3 の場所を Iceberg ストレージとしてデータレイクに追加するには、 場所を登録する レイクフォーメーションと。その後、Lake Formation 権限を使用して、この場所を指す Data Catalog オブジェクトと、その場所の基礎となるデータに対するきめ細かいアクセス制御を行うことができます。
CloudFormation スタックはデータ レイクの場所を登録しました。

データの場所の権限 Lake Formation では、プリンシパルが、指定された登録済み Amazon S3 の場所を指すデータ カタログ リソースを作成および変更できるようになります。データの場所の権限は Lake Formation に加えて機能します データ許可 データレイク内の情報を保護します。
Lake Formation タグベースのアクセス制御 (LF-TBAC) 属性に基づいて権限を定義する認可戦略です。 Lake Formation では、これらの属性は LF タグと呼ばれます。 LF タグを Data Catalog リソース、Lake Formation プリンシパル、およびテーブル列に添付できます。これらの LF タグを使用して、Lake Formation リソースに対するアクセス許可を割り当てたり取り消したりできます。 Lake Formation は、プリンシパルのタグがリソース タグと一致する場合に、それらのリソースに対する操作を許可します。
Lake Formation コンソールから Iceberg テーブルを確認する
Iceberg テーブルを確認するには、次の手順を実行します。
- Lake Formation コンソールで、 データベース ナビゲーションペインに表示されます。
- 詳細ページを開く
icebergdb1.
関連するデータベースの LF タグが表示されます。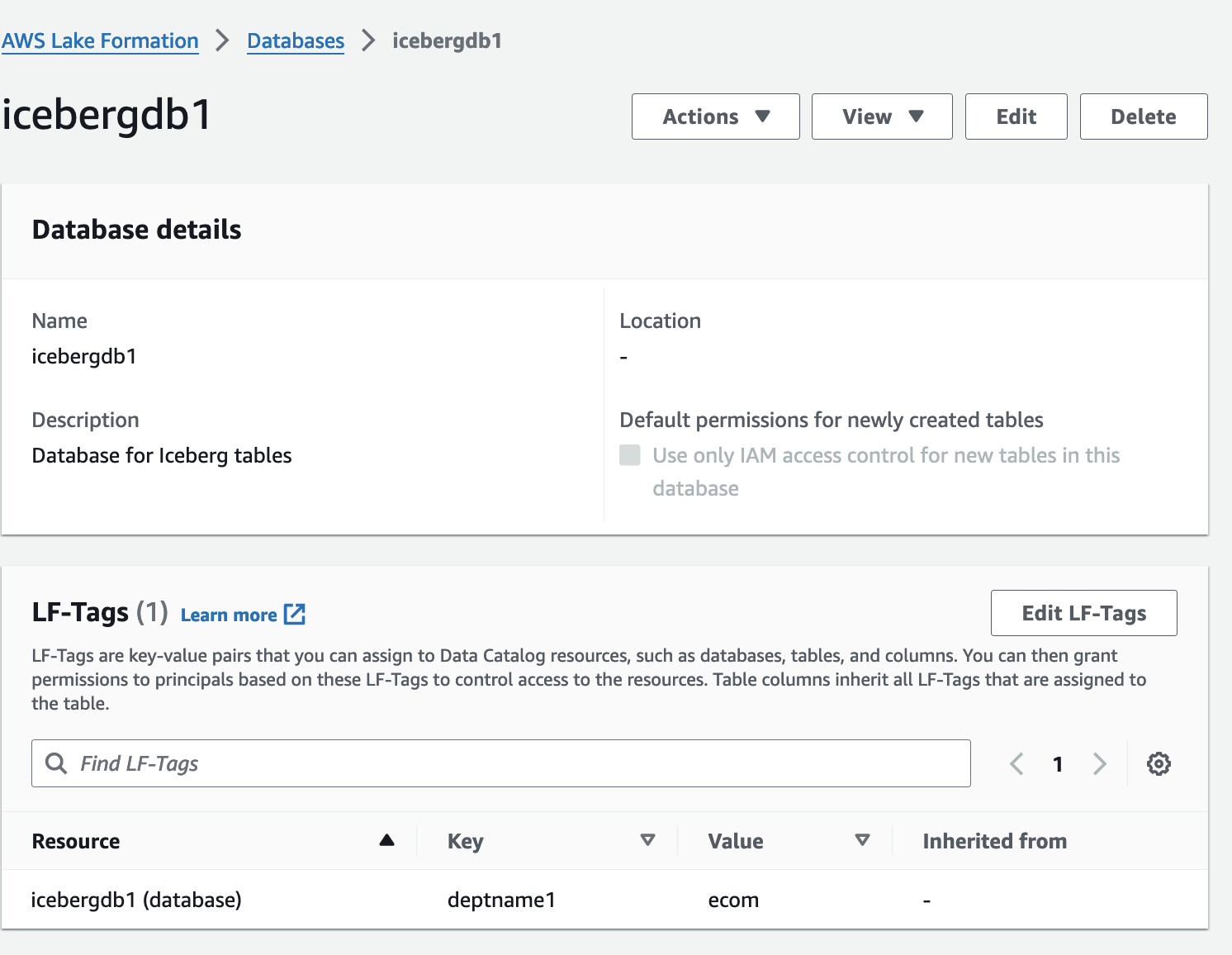
- 選択する テーブル類 ナビゲーションペインに表示されます。
- 詳細ページを開く
ecomorders.
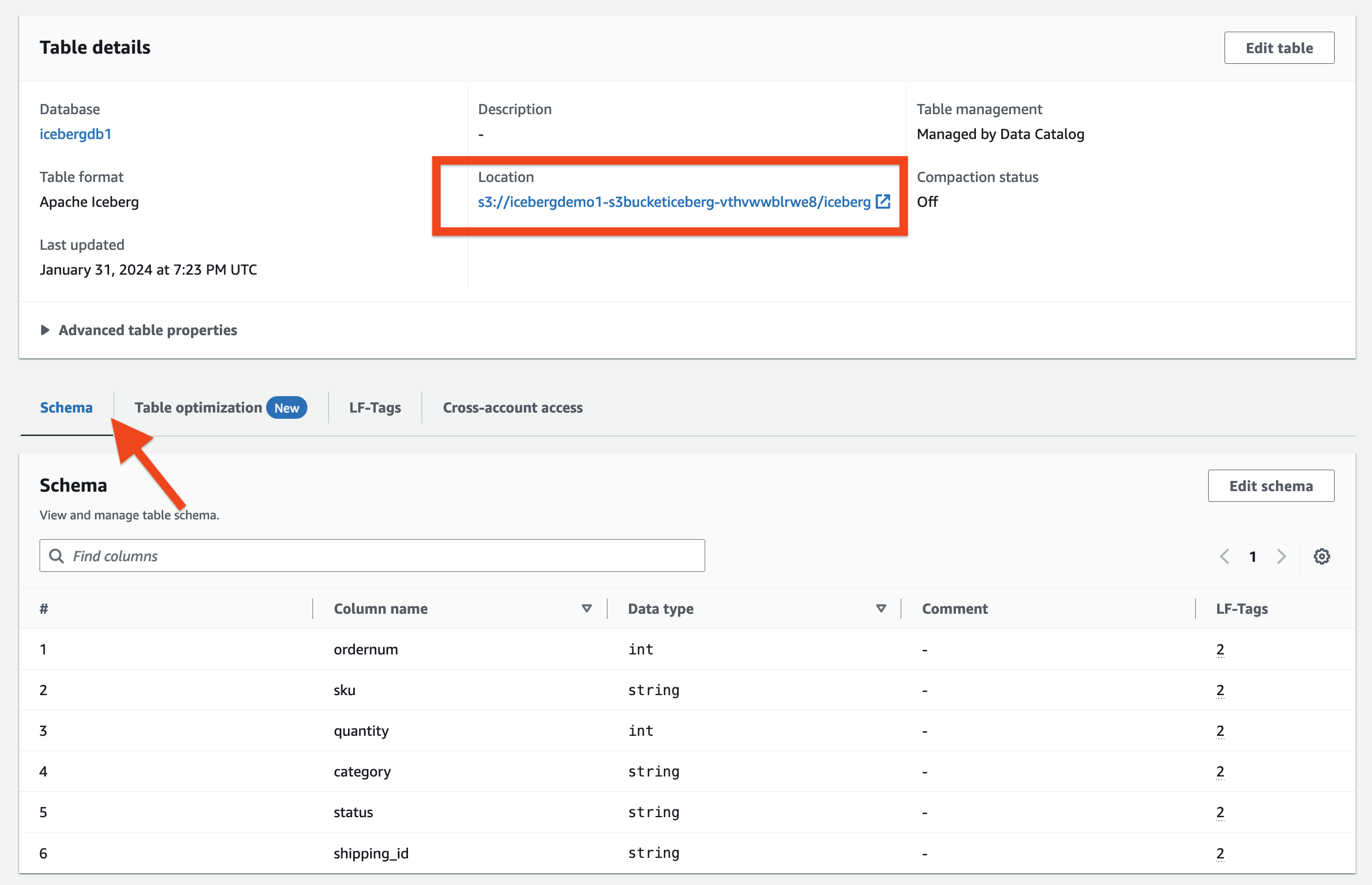
テーブルの詳細 セクションでは、次のことがわかります。
- 表形式 として表示 アパッチ氷山
- テーブル管理 として表示 データカタログによる管理
- 会場 Iceberg テーブルのデータ レイクの場所をリストします。
LFタグ セクションでは、関連するテーブル LF-Tags を確認できます。
テーブルの詳細 セクション、展開 高度なテーブルのプロパティ 以下を表示するには:
metadata_locationIcebergテーブルのメタデータファイルの場所を指しますtable_typeとして表示ICEBERG
ソフトウェア設定ページで、下図のように スキーマ タブでは、Iceberg テーブルに定義されている列を表示できます。
Iceberg を AWS Glue データカタログおよび Amazon S3 と統合する
Iceberg は、ディレクトリではなくテーブル内の個々のデータ ファイルを追跡します。テーブルに明示的なコミットがある場合、Iceberg はデータ ファイルを作成し、テーブルに追加します。 Iceberg はテーブルの状態をメタデータ ファイルに保持します。テーブルの状態に変更があると、古いメタデータをアトミックに置き換える新しいメタデータ ファイルが作成されます。メタデータ ファイルは、テーブル スキーマ、パーティション構成、およびその他のプロパティを追跡します。
Iceberg では、Amazon S3 などのオブジェクト ストアと互換性のある操作をサポートするファイル システムを必要としています。
Iceberg はテーブルの内容のスナップショットを作成します。各スナップショットは、ある時点でのテーブル内のデータ ファイルの完全なセットです。スナップショット内のデータ ファイルは、テーブル内の各データ ファイルの行、そのパーティション データ、およびそのメトリックを含む 1 つ以上のマニフェスト ファイルに保存されます。
次の図は、この階層を示しています。
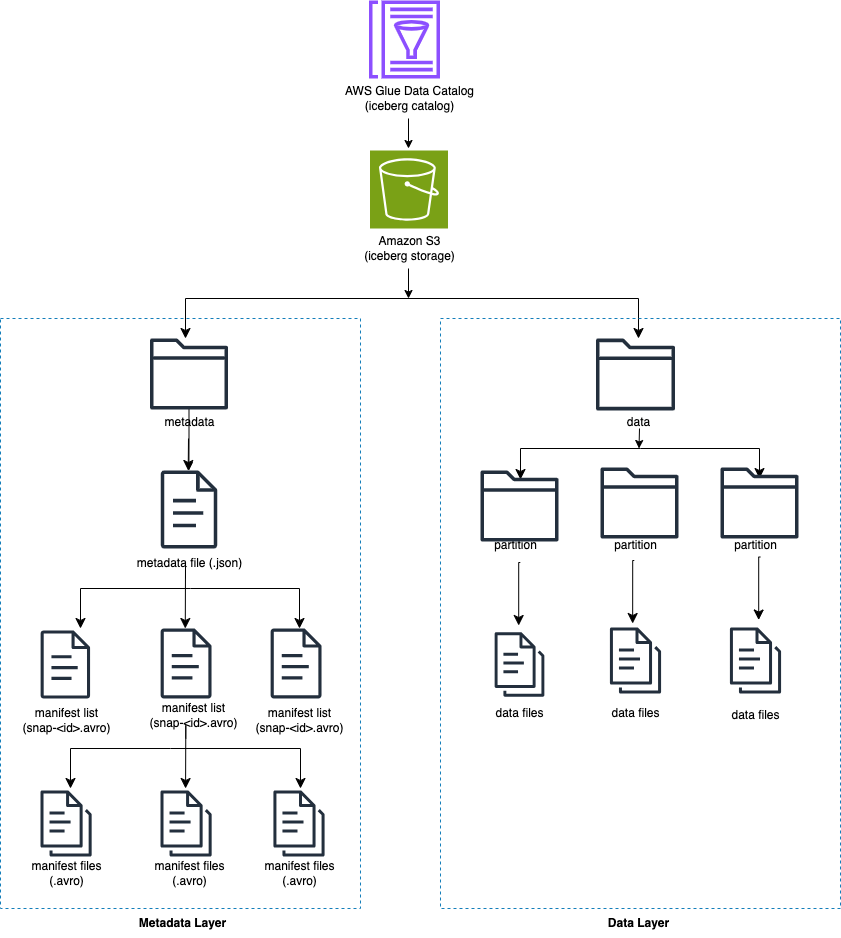
Iceberg テーブルを作成すると、最初にメタデータ フォルダーが作成され、メタデータ フォルダー内にメタデータ ファイルが作成されます。データ フォルダーは、データを Iceberg テーブルにロードすると作成されます。

Iceberg メタデータ ファイルの内容
Iceberg メタデータ ファイルには、次のような多くの情報が含まれています。
- フォーマットバージョン – Iceberg テーブルのバージョン
- 会場 – Amazon S3 テーブルの場所
- スキーマ – テーブル上のすべての列の名前とデータ型
- パーティション仕様 – パーティション化された列
- 並べ替え順序 – 列のソート順序
- プロパティ – テーブルのプロパティ
- 現在のスナップショット ID – 現在のスナップショット
- ヒント – テーブル参照
- スナップショット – スナップショットのリスト。各スナップショットには次の情報が含まれます。
- シーケンス番号 – 時系列順のスナップショットのシーケンス番号 (最大の番号は現在のスナップショットを表し、1 は最初のスナップショットを表します)
- スナップショットID – スナップショット ID
- タイムスタンプ-ミリ秒 – スナップショットがコミットされたときのタイムスタンプ
- 要約 – コミットされた変更の概要
- マニフェストリスト – マニフェストのリスト。このファイル名は snap-< snapshot-id > で始まります
- スキーマID – 時系列でのスキーマのシーケンス番号 (最大の番号が現在のスキーマを表します)
- スナップショットログ – 時系列順のスナップショットのリスト
- メタデータログ – メタデータ ファイルの時系列順のリスト
メタデータ ファイルには、テーブルのデータとスキーマに対するすべての履歴変更が含まれています。メタファイル ファイルの内容を直接確認するのは、時間がかかる作業です。幸いなことに、次のクエリを実行できます。 Athena を使用した Iceberg メタデータ.
AWS Glue の Iceberg フレームワーク
AWS Glue 4.0 は、Lake Formation に登録された Iceberg テーブルをサポートしています。 AWS Glue ETL ジョブでは、次のコードが必要です。 Iceberg フレームワークを有効にする:
基盤となるデータへの読み取り/書き込みアクセスについては、Lake Formation 権限に加えて、AWS Glue ETL ジョブを実行する AWS Glue IAM ロールが付与されました。 湖の形成: GetDataAccess IAM 許可。この権限により、Lake Formation はデータにアクセスするための一時的な認証情報のリクエストを許可します。
CloudFormation スタックは、1 つの AWS Glue ETL ジョブをプロビジョニングしました。各ジョブの名前はスタック名 (icebergdemoXNUMX) で始まります。ジョブを表示するには、次の手順を実行します。
- 管理者として AWS アカウントにログインします。
- AWS Glue コンソールで、選択します ETL ジョブ ナビゲーションペインに表示されます。
- で仕事を探す
icebergdemo1名前に。
Dropzone のデータを Iceberg テーブルにマージする
私たちのユースケースでは、同社は毎日、e コマースの注文データをオンプレミスの場所から Amazon S3 Dropzone の場所に取り込みます。次の図に示すように、CloudFormation スタックは 3 日間のサンプル注文を含む XNUMX つのファイルをロードしました。 Dropzone の場所にデータが表示されます s3://icebergdemo1-s3bucketdropzone-kunftrcblhsk/data.
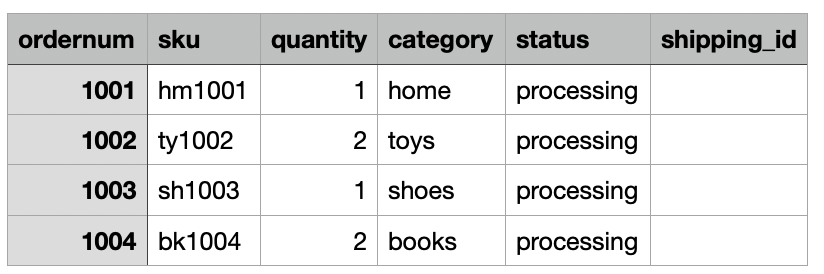


AWS Glue ETL ジョブ icebergdemo1-GlueETL1-merge データを Iceberg テーブルにマージするために毎日実行されます。 Iceberg 上のデータを追加または更新するための次のロジックがあります。
- 入力データから Spark DataFrame を作成します。
- 新しい注文の場合は、テーブルに追加します
- テーブルに一致する注文がある場合は、ステータスを更新し、
shipping_id:
AWS Glue マージジョブを実行するには、次の手順を実行します。
- AWS Glue コンソールで、選択します ETL ジョブ ナビゲーションペインに表示されます。
- ETL ジョブを選択します
icebergdemo1-GlueETL1-merge. - ソフトウェア設定ページで、下図のように ドロップダウン メニューから選択します パラメータを指定して実行する.
- ソフトウェア設定ページで、下図のように 実行パラメータ ページ、に行く ジョブパラメータ.
-
--dropzone_pathパラメータで、入力データの S3 の場所を指定します (icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge1). - ジョブを実行して、すべての注文 (1001、1002、1003、および 1004) を追加します。
-
--dropzone_path parameter、S3 の場所を次のように変更します。icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge2. - ジョブを再度実行して注文 2001 と 2002 を追加し、注文 1001、1002、および 1003 を更新します。
-
--dropzone_pathパラメータで、S3 の場所を次のように変更します。icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge3. - ジョブを再度実行して注文 3001 を追加し、注文 1001、1003、2001、および 2002 を更新します。
テーブルのデータ フォルダーに移動して、Glue ETL ジョブを使用してデータをテーブルにマージしたときに Iceberg によって書き込まれたデータ ファイルを確認します。 icebergdemo1-GlueETL1-merge.

Athena を使用して Iceberg をクエリする
CloudFormation スタックは、LF-Tags を使用した Iceberg テーブルへの読み取りアクセス権を持つ IAM ユーザー Iceberguser1 を作成しました。このユーザー経由で Athena を使用して Iceberg にクエリを実行するには、次の手順を実行します。
- としてログイン
iceberguser1AWSマネジメントコンソール. - Athenaコンソールで、 ワークグループ ナビゲーションペインに表示されます。
- CloudFormation がプロビジョニングしたワークグループを見つけます (
icebergdemo1-workgroup) - Athena エンジンのバージョン 3 を確認します。
Athena エンジン バージョン 3 は以下をサポートします。 氷山のファイル形式、Parquet、ORC、Avro など。
- Athena クエリエディターに移動します。
- ドロップダウン メニューからワークグループ Icebergdemo1-workgroup を選択します。
- データベース、選択する
icebergdb1。テーブルが表示されますecomorders. - 次のクエリを実行して、Iceberg テーブルのデータを表示します。
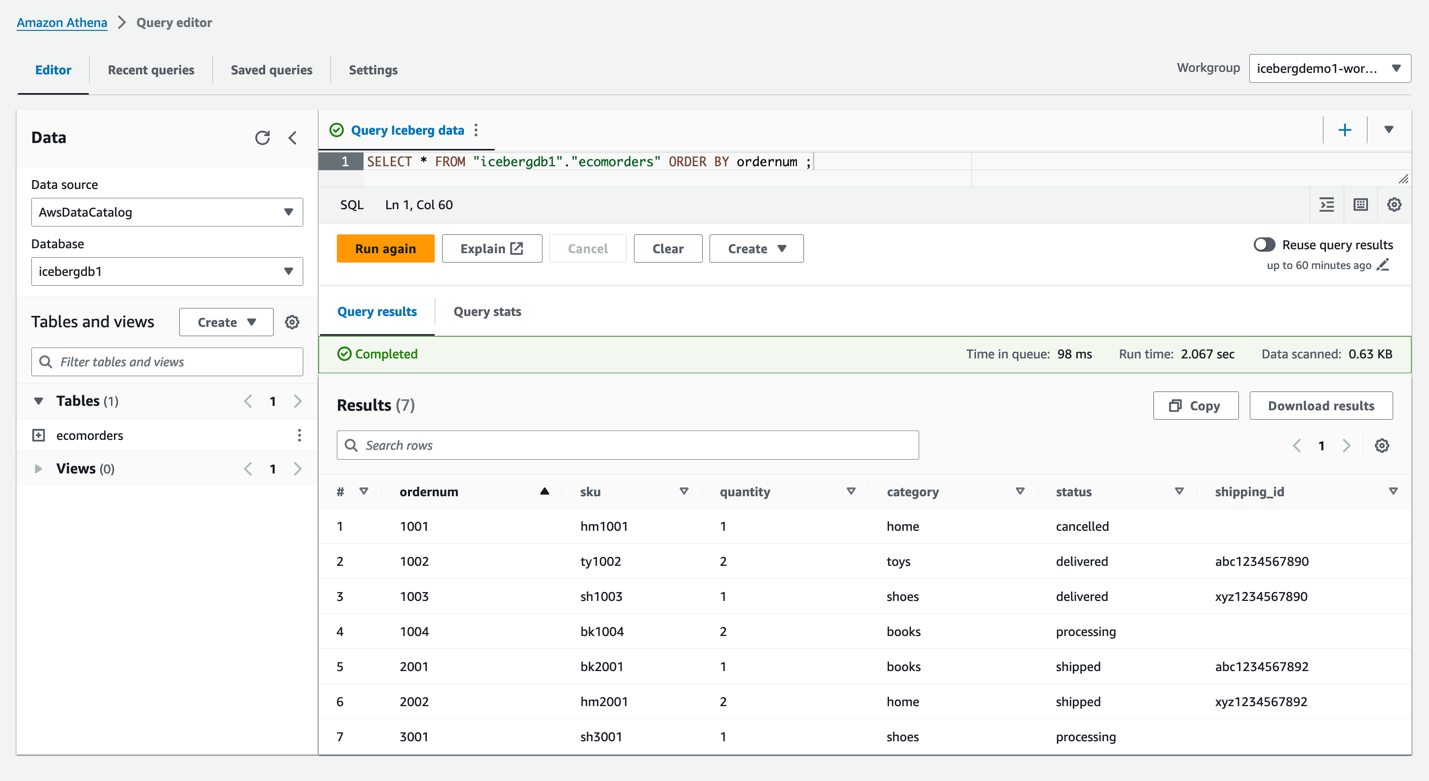
- 次のクエリを実行して、テーブルの現在のパーティションを確認します。
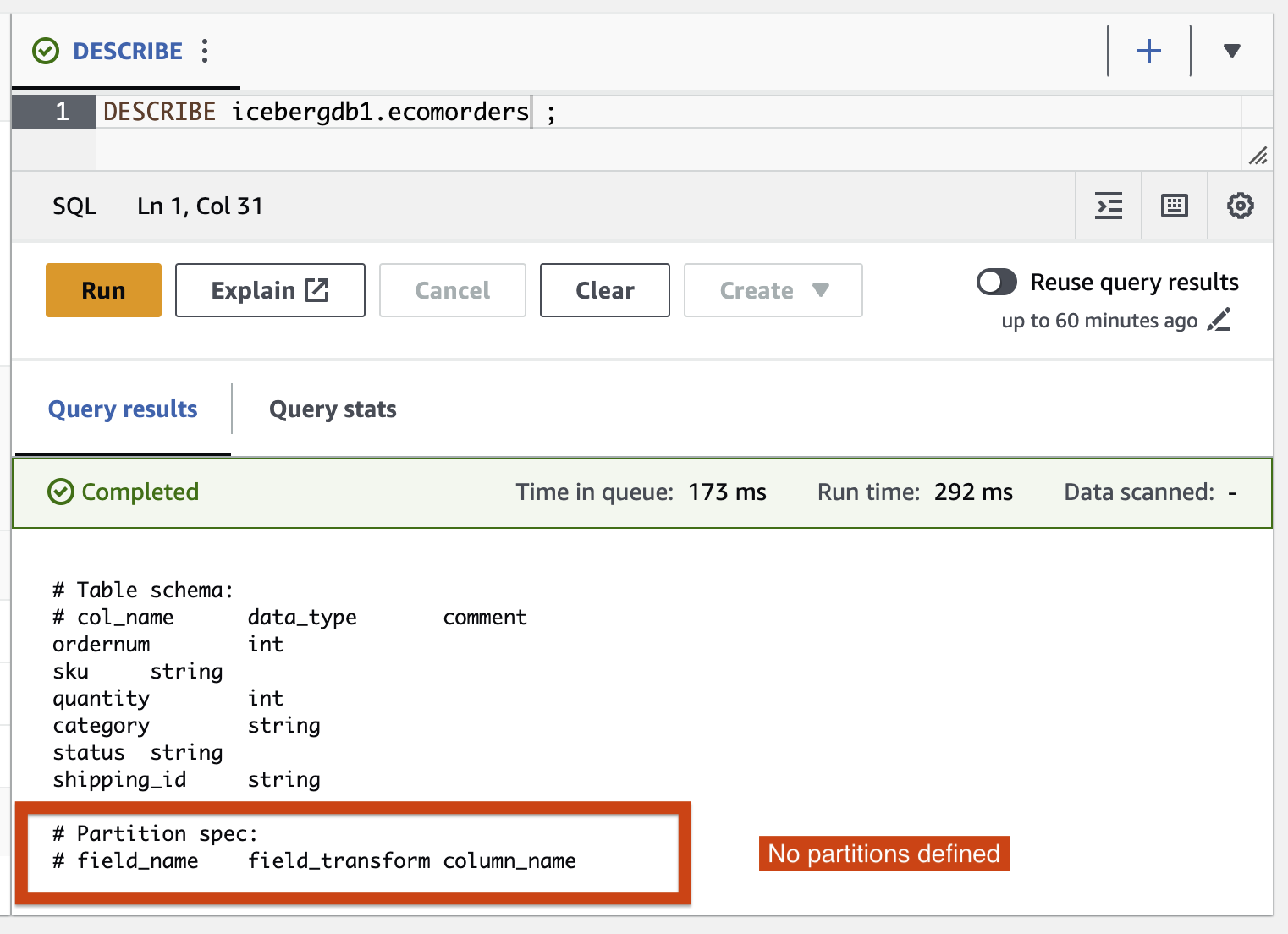
Partition-spec はテーブルがどのようにパーティション化されるかを記述します。この例では、テーブルにパーティションを定義していないため、パーティション化されたフィールドはありません。
氷山パーティションの進化
パーティション構造の変更が必要になる場合があります。たとえば、下流分析における一般的なクエリ パターンの傾向変化によるものです。従来のテーブルのパーティション構造の変更は、データ全体のコピーを必要とする重要な操作です。
Iceberg はこれを簡単に説明します。 Iceberg のパーティション構造を変更する場合、データ ファイルを書き直す必要はありません。以前のパーティションで書き込まれた古いデータは変更されません。新しいデータは、新しいレイアウトで新しい仕様を使用して書き込まれます。各パーティション バージョンのメタデータは個別に保持されます。
AWS Glue ETL ジョブを使用して、パーティション フィールド カテゴリを Iceberg テーブルに追加してみましょう icebergdemo1-GlueETL2-partition-evolution:
AWS Glue コンソールで ETL ジョブを実行します。 icebergdemo1-GlueETL2-partition-evolution。ジョブが完了したら、Athena を使用してパーティションをクエリできます。
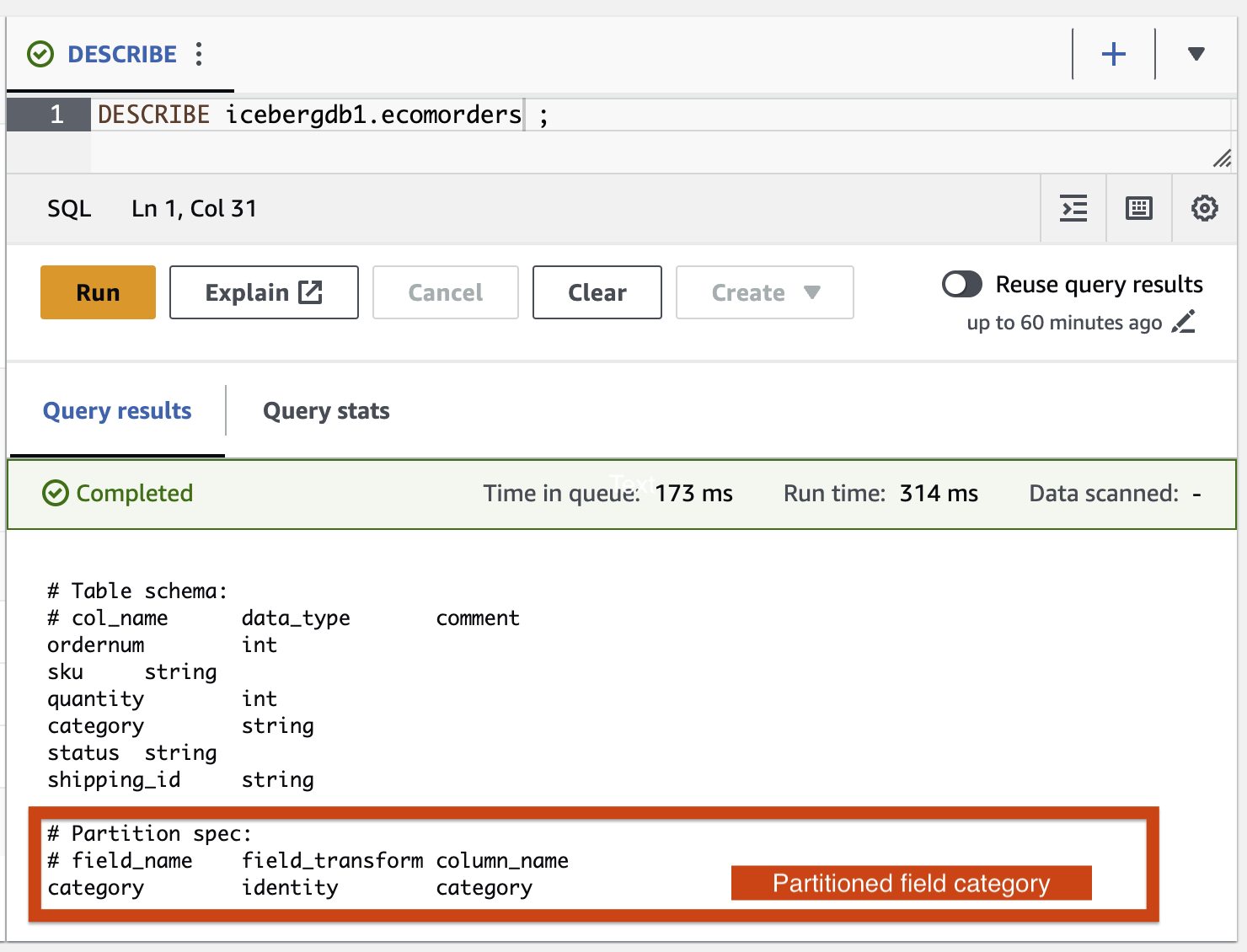
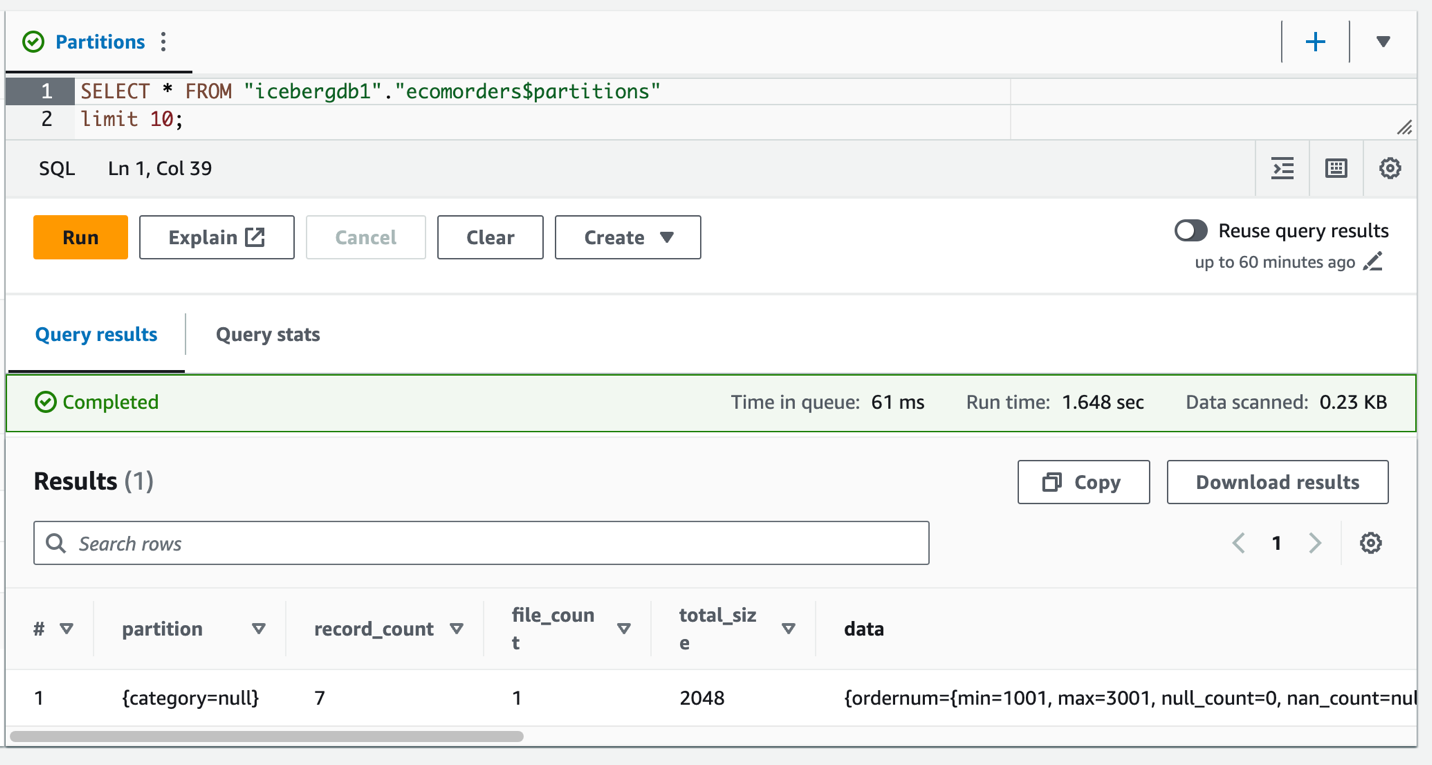
パーティション フィールド カテゴリが表示されますが、パーティション値は null です。パーティションの進化はメタデータ操作であり、データ ファイルを書き換えないため、データ フォルダーには新しいデータ ファイルはありません。データを追加または更新すると、対応するパーティション値が設定されていることがわかります。
氷山スキーマの進化
Iceberg は、インプレース テーブルの進化をサポートしています。あなたはできる テーブルスキーマを進化させる SQL と同じように。 Iceberg スキーマの更新はメタデータの変更であるため、スキーマの進化を実行するためにデータ ファイルを書き直す必要はありません。
Iceberg スキーマの進化を調査するには、ETL ジョブを実行します icebergdemo1-GlueETL3-schema-evolution AWS Glue コンソール経由。ジョブは次の SparkSQL ステートメントを実行します。
Athena クエリ エディターで、次のクエリを実行します。

Iceberg テーブルに対するスキーマの変更を確認できます。
- という新しい列が追加されました。
shipping_carrier - コラム
shipping_idに名前が変更されましたtracking_number - 列のデータ型
ordernumint から bigint に変更されました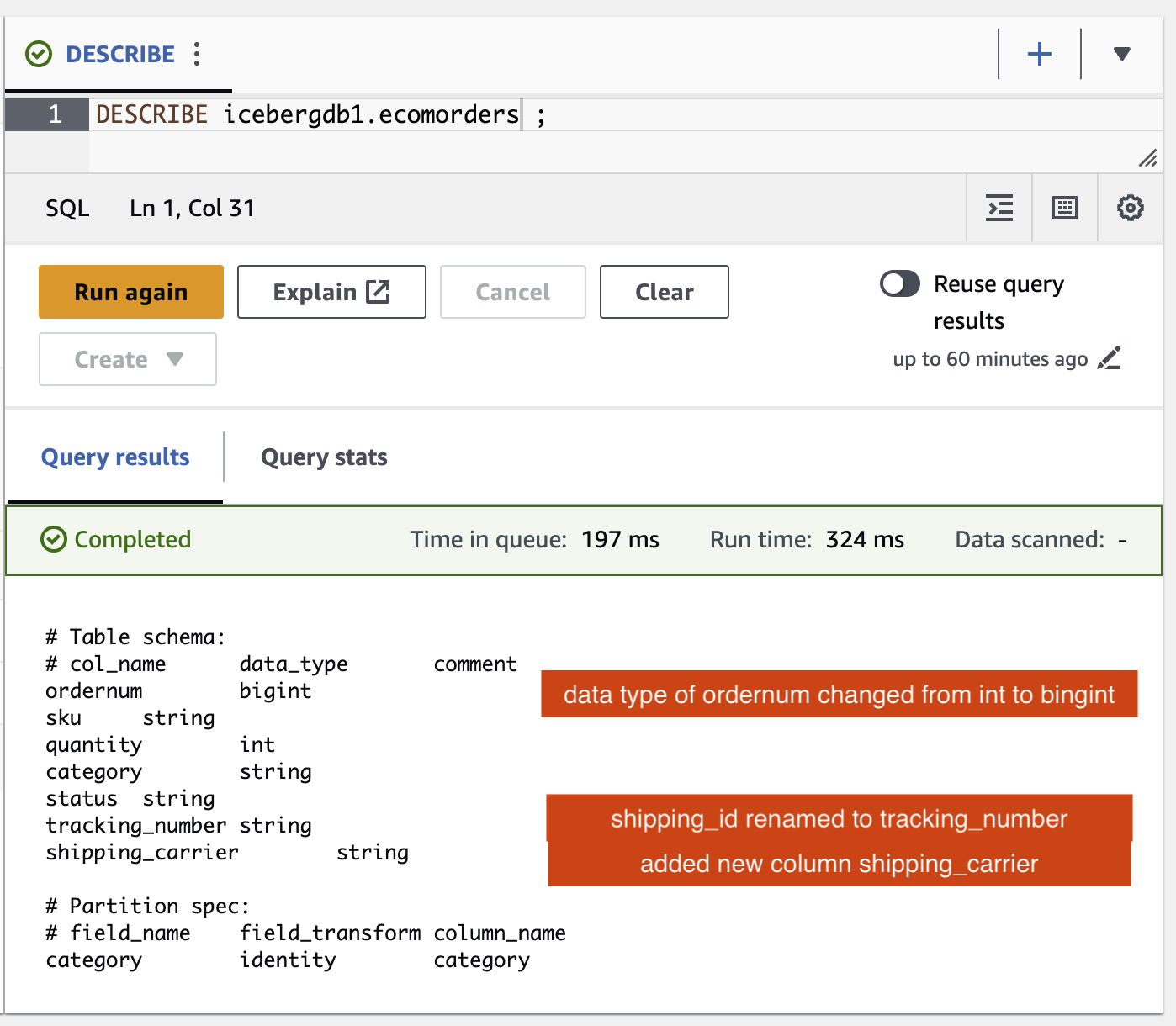
位置の更新
のデータ tracking_number 配送業者には追跡番号が連結されています。配送業者を維持するためにこのデータを分割したいと仮定しましょう。 shipping_carrier フィールドと追跡番号 tracking_number フィールド。
AWS Glue コンソールで ETL ジョブを実行します。 icebergdemo1-GlueETL4-update-table。ジョブは次の SparkSQL ステートメントを実行してテーブルを更新します。
Iceberg テーブルをクエリして、更新されたデータを確認します。 tracking_number & shipping_carrier.
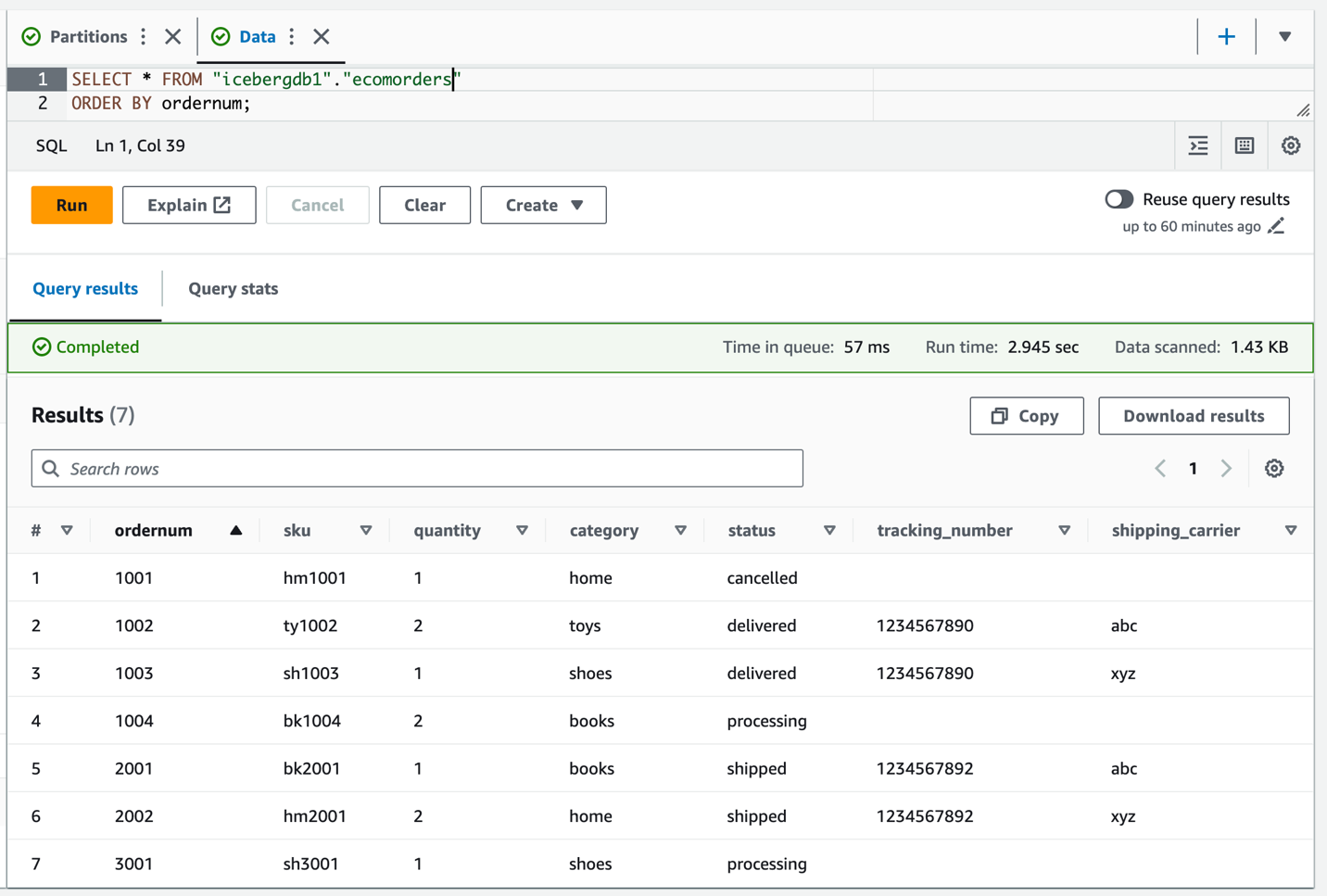
テーブル上のデータが更新されたので、カテゴリに設定されたパーティション値が表示されるはずです。

クリーンアップ
今後の料金発生を回避するには、作成したリソースをクリーンアップします。
- Lambda コンソールで、関数の詳細ページを開きます。
icebergdemo1-Lambda-Create-Iceberg-and-Grant-access. - 環境変数 セクションでキーを選択します
Task_To_Perform値を次のように更新しますCLEANUP. - データベース、テーブル、およびそれらに関連付けられた LF タグを削除する関数を実行します。
- AWS CloudFormation コンソールで、スタック Icebergdemo1 を削除します。
まとめ
この投稿では、AWS Glue API を使用して Iceberg テーブルを作成し、Lake Formation を使用してトランザクション データ レイク内の Iceberg テーブルへのアクセスを制御しました。 AWS Glue ETL ジョブを使用すると、Iceberg テーブルにデータをマージし、Iceberg テーブルを書き換えたり再作成したりすることなく、スキーマの進化とパーティションの進化を実行できました。 Athena を使用して、Iceberg データとメタデータをクエリしました。
この投稿のコンセプトとデモに基づいて、Iceberg、AWS Glue、Lake Formation、Amazon S3 を使用して企業内にトランザクション データ レイクを構築できるようになりました。
著者について
 サティア・アディムラ ボストンを拠点とする AWS のシニア データ アーキテクトです。データと分析における 20 年以上の経験を持つ Satya は、組織が大規模なデータからビジネス上の洞察を引き出すのを支援します。
サティア・アディムラ ボストンを拠点とする AWS のシニア データ アーキテクトです。データと分析における 20 年以上の経験を持つ Satya は、組織が大規模なデータからビジネス上の洞察を引き出すのを支援します。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/use-aws-glue-etl-to-perform-merge-partition-evolution-and-schema-evolution-on-apache-iceberg/

