今日のデジタル時代において、データはあらゆる組織の成功の中心です。 データ交換に最も一般的に使用される形式の XNUMX つは XML です。 XML ファイルの分析は、いくつかの理由から重要です。 まず、XML ファイルは、金融、医療、政府などの多くの業界で使用されています。 XML ファイルを分析すると、組織はデータに関する洞察を得ることができ、より適切な意思決定を行い、業務を改善できるようになります。 多くのアプリケーションやシステムは標準データ形式として XML を使用しているため、XML ファイルの分析はデータ統合にも役立ちます。 XML ファイルを分析することで、組織はさまざまなソースからのデータを簡単に統合し、システム全体で一貫性を確保できます。ただし、XML ファイルには半構造化され、高度にネストされたデータが含まれているため、特にファイルが大きく、情報の分析が困難になります。複雑で高度にネストされたスキーマ。
XML ファイルはアプリケーションには適していますが、分析エンジンには最適ではない可能性があります。 クエリのパフォーマンスを強化し、下流の分析エンジンへの簡単なアクセスを可能にするため。 アマゾンアテナ、XML ファイルを Parquet のような列形式に前処理することが重要です。 この変換により、分析ワークフローの効率と使いやすさが向上します。 この投稿では、次を使用して XML データを処理する方法を示します。 AWSグルー そしてアテナ。
ソリューションの概要
XML ファイル処理ワークフローを合理化できる XNUMX つの異なる手法を検討します。
- テクニック 1: AWS Glue クローラーと AWS Glue ビジュアルエディターを使用する – AWS Glue ユーザーインターフェイスをクローラーと組み合わせて使用し、XML ファイルのテーブル構造を定義できます。 このアプローチはユーザーフレンドリーなインターフェイスを提供し、データ管理にグラフィカルなアプローチを好む個人に特に適しています。
- テクニック 2: 推論および固定スキーマで AWS Glue DynamicFrames を使用する – クローラーには、XNUMX 行の XML ファイルを処理する際に制限があります。 1 MB。 この制限を克服するために、AWS Glue ノートブックを使用して AWS Glue を構築します。
DynamicFrames、推論スキーマと固定スキーマの両方を利用します。 この方法により、サイズが 1 MB を超える行を含む XML ファイルを効率的に処理できます。
どちらのアプローチでも、最終的な目標は、XML ファイルを Apache Parquet 形式に変換し、Athena を使用したクエリにすぐに使用できるようにすることです。 これらの手法を使用すると、XML データの処理速度とアクセスしやすさが向上し、貴重な洞察を簡単に得ることができます。
前提条件
このチュートリアルを開始する前に、次の前提条件を満たしている必要があります (これらは両方の手法に適用されます)。
- XML ファイルをダウンロードする テクニック1.xml & テクニック2.xml.
- ファイルを Amazon シンプル ストレージ サービス (Amazon S3) バケット。 これらは、異なるフォルダー内の同じ S3 バケットにアップロードすることも、異なる S3 バケットにアップロードすることもできます。
- 作る AWS IDおよびアクセス管理 の指示に従って、ETL ジョブまたはノートブックの (IAM) ロール AWSGlueStudioのIAM権限を設定します.
- インライン ポリシーをロールに追加するには、 すでに: PassRole アクション:
- S3 バケットへのアクセス権を持つロールにアクセス許可ポリシーを追加します。
前提条件が完了したので、最初の手法の実装に進みましょう。
テクニック 1: AWS Glue クローラーとビジュアルエディターを使用する
次の図は、ソリューションの実装に使用できる単純なアーキテクチャを示しています。
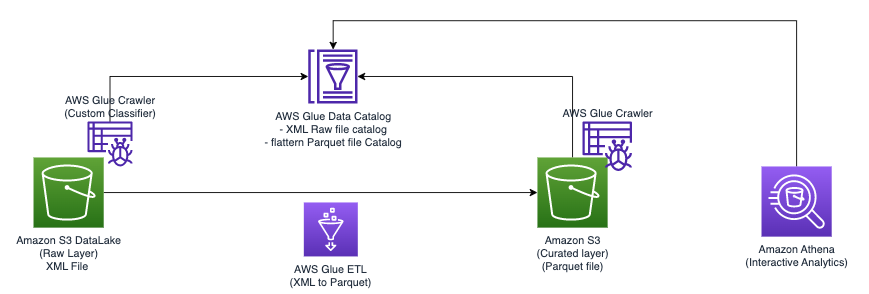
AWS Glue と Athena を使用して Amazon S3 に保存された XML ファイルを分析するには、次の高レベルの手順を完了します。
- AWS Glue クローラーを作成して XML メタデータを抽出し、AWS Glue データ カタログにテーブルを作成します。
- AWS Glue の抽出、変換、ロード (ETL) ジョブを使用して、XML データを Athena に適した形式 (Parquet など) に処理および変換します。
- AWS Glue コンソールまたは AWSコマンドラインインターフェイス (AWS CLI)。
- 処理されたデータ (Parquet 形式) を Athena テーブルで使用し、SQL クエリを有効にします。
- Athena のユーザーフレンドリーなインターフェイスを使用して、Amazon S3 に保存されているデータに対する SQL クエリを使用して XML データを分析します。
このアーキテクチャは、AWS Glue と Athena を使用して Amazon S3 上の XML データを分析するための、スケーラブルでコスト効率の高いソリューションです。 複雑なインフラストラクチャ管理を行わずに大規模なデータセットを分析できます。
XML ファイルのメタデータを抽出するには、AWS Glue クローラーを使用します。 汎用 XML 分類用にデフォルトの AWS Glue 分類子を選択できます。 XML データ構造とスキーマを自動的に検出するため、一般的な形式に役立ちます。
このソリューションではカスタム XML 分類子も使用します。 特定の XML スキーマまたは形式向けに設計されており、正確なメタデータの抽出が可能です。 これは、非標準の XML 形式の場合や、分類を詳細に制御する必要がある場合に最適です。 カスタム分類子により、必要なメタデータのみが抽出されるようになり、下流の処理および分析タスクが簡素化されます。 このアプローチにより、XML ファイルの使用が最適化されます。
次のスクリーンショットは、タグを含む XML ファイルの例を示しています。

カスタム分類子を作成する
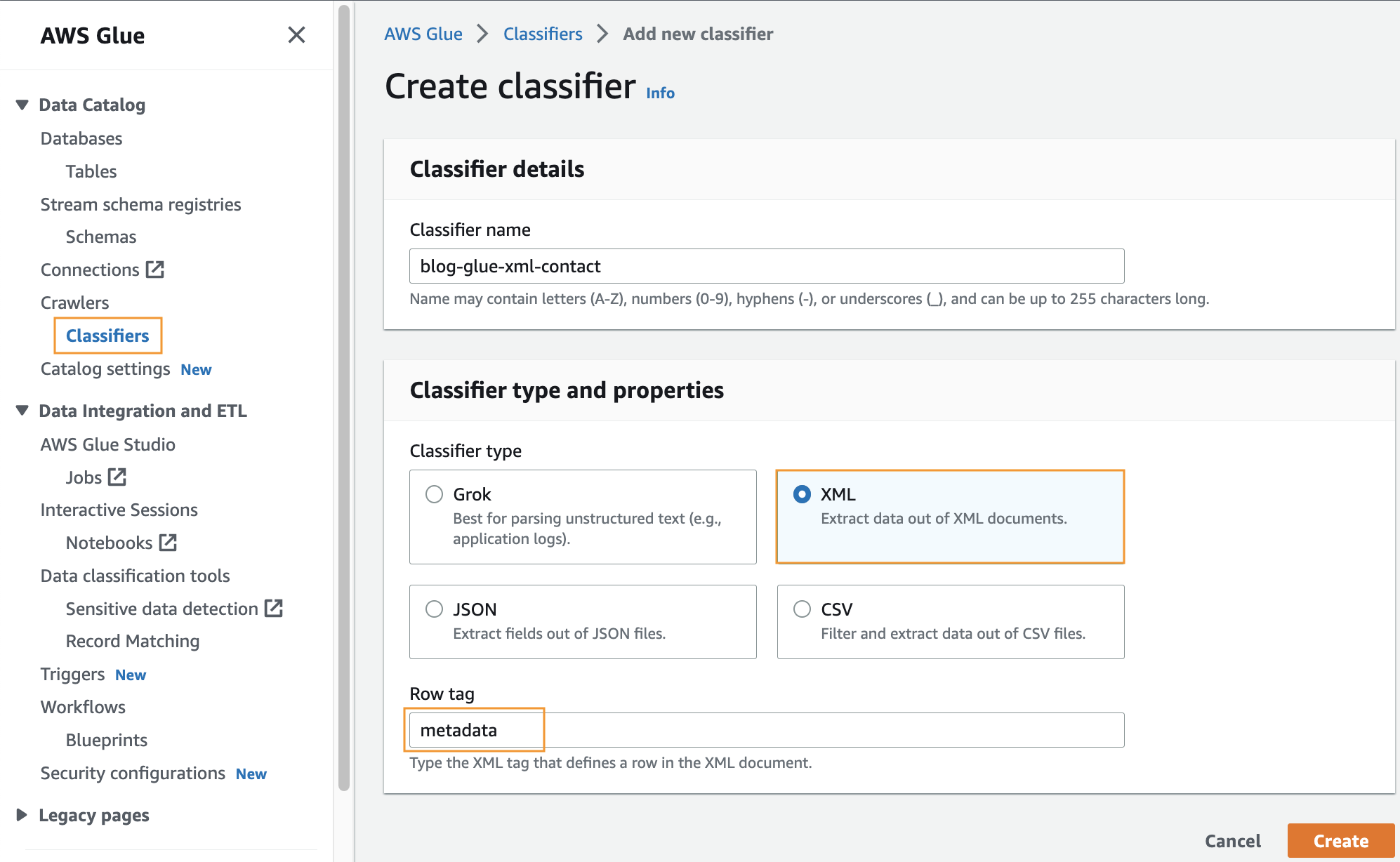
このステップでは、カスタム AWS Glue 分類子を作成して、XML ファイルからメタデータを抽出します。 次の手順を実行します。
- AWS Glueコンソールの、 Crawlers ナビゲーション ペインで、 分類器.
- 選択する 分類子を追加する.
- 選択 XML 分類子のタイプとして。
- 分類子の名前を入力します。
blog-glue-xml-contact. - 行タグ、メタデータを含むルート タグの名前を入力します (例:
metadata). - 選択する 創造する.
XML ファイルをクロールするための AWS Glue クローラーを作成する
このセクションでは、前の手順で作成した顧客分類子を使用して XML ファイルからメタデータを抽出する Glue Crawler を作成します。
データベースを作成する
- に行きます AWSGlueコンソール、選択する データベース ナビゲーションペインに表示されます。
- ソフトウェアの制限をクリック データベースを追加します。
- 次のような名前を付けます。
blog_glue_xml - 選択する 創造する データベース
クローラーを作成する
最初のクローラーを作成するには、次の手順を実行します。
- AWS Glue コンソールで、選択します Crawlers ナビゲーションペインに表示されます。
- 選択する クローラーを作成する.
- ソフトウェア設定ページで、下図のように クローラーのプロパティを設定する ページで、新しいクローラの名前を指定します (例:
blog-glue-parquet)、次に選択 Next. - ソフトウェア設定ページで、下図のように データソースと分類器を選択する 未だに 下 データソースの構成.
- 選択する データストアを追加する.
- S3パス、参照してください
s3://${BUCKET_NAME}/input/geologicalsurvey/.
フォルダー内のファイルではなく、必ず XML フォルダーを選択してください。
- 残りのオプションはデフォルトのままにして選択します。 S3 データ ソースを追加する.
- 詳細 カスタム分類子 – オプション、blog-glue-xml-contact を選択し、次に選択します Next 残りのオプションはデフォルトのままにします。
- IAM ロールを選択するか、 新しいIAMロールを作成する、接尾辞を追加します
glue-xml-contact(例えば、AWSGlueServiceNotebookRoleBlog)、およびを選択します Next. - ソフトウェア設定ページで、下図のように 出力とスケジューリングを設定する ページ、下 出力構成、選択する
blog_glue_xmlfor 対象データベース. - 入力します
console_テーブルに追加されるプレフィックスとして (オプション) およびその下に クローラースケジュール、周波数を に設定したままにします。 オンデマンド. - 選択する Next.
- すべてのパラメータを確認して選択します クローラーを作成する.
クローラーを実行する
クローラーを作成したら、次の手順を実行して実行します。
- AWS Glue コンソールで、選択します Crawlers ナビゲーションペインに表示されます。
- 作成したクローラーを開いて選択します ラン.
クローラーが完了するまでに 1 ~ 2 分かかります。

- クローラーが完了したら、選択します データベース ナビゲーションペインに表示されます。
- クレートしたデータベースを選択し、テーブル名を選択すると、クローラーによって抽出されたスキーマが表示されます。

AWS Glue ジョブを作成して XML を Parquet 形式に変換する
このステップでは、AWS Glue Studio ジョブを作成して、XML ファイルを Parquet ファイルに変換します。 次の手順を実行します。
- AWS Glue コンソールで、選択します Jobs > Create New Job ナビゲーションペインに表示されます。
- ジョブを作成選択 真っ白なキャンバスを使ったビジュアル.
- 選択する 創造する.
- ジョブの名前を次のように変更します
blog_glue_xml_job.
これで、空の AWS Glue Studio ビジュアルジョブエディターが完成しました。 エディターの上部には、さまざまなビューのタブがあります。
- 選択する スクリプト タブをクリックすると、AWS Glue ETL スクリプトの空のシェルが表示されます。
ビジュアル エディターで新しいステップを追加すると、スクリプトは自動的に更新されます。
- 選択する 仕事の詳細 タブをクリックすると、すべてのジョブ構成が表示されます。
- IAMの役割、選択する
AWSGlueServiceNotebookRoleBlog. - 接着剤バージョン、選択する Glue 4.0 – Spark 3.3、Scala 2、Python 3 をサポート.
- 作成セッションプロセスで 要求された労働者数 2へ。
- 作成セッションプロセスで リトライ回数 0へ。
- 選択する ビジュアル タブをクリックしてビジュアルエディターに戻ります。
- ソフトウェア設定ページで、下図のように ソース ドロップダウンメニュー、選択 AWSGlueデータカタログ.
- ソフトウェア設定ページで、下図のように データ ソース プロパティ – データ カタログ タブで、次の情報を入力します。
- データベース、選択する
blog_glue_xml. - 表、クローラーが作成した名前 console_ で始まるテーブルを選択します (例:
console_geologicalsurvey).
- データベース、選択する
- ソフトウェア設定ページで、下図のように ノードのプロパティ タブで、次の情報を入力します。
- 変更する 名前 〜へ
geologicalsurveyデータセット。 - 選択する Action そして変身 スキーマの変更 (マッピングの適用).
- 選択する ノードのプロパティ 変換の名前を「スキーマの変更 (マッピングの適用)」から「スキーマの変更 (マッピングの適用)」に変更します。
ApplyMapping. - ソフトウェア設定ページで、下図のように ターゲット メニュー、選択 S3.
- 変更する 名前 〜へ
- ソフトウェア設定ページで、下図のように データソースのプロパティ– S3 タブで、次の情報を入力します。
- フォーマット選択 寄せ木細工の床.
- 圧縮タイプ選択 非圧縮.
- S3ソースタイプ選択 S3の場所.
- S3 URL、 入る
s3://${BUCKET_NAME}/output/parquet/. - 選択する ノードのプロパティ そして名前を次のように変更します
Output.
- 選択する Save ジョブを保存します。
- 選択する ラン ジョブを実行します。
次のスクリーンショットは、ビジュアル エディターでのジョブを示しています。

Parquet ファイルをクロールするための AWS Gue クローラーを作成する
このステップでは、AWS Glue クローラーを作成し、AWS Glue Studio ジョブを使用して作成した Parquet ファイルからメタデータを抽出します。 今回は、デフォルトの分類子を使用します。 次の手順を実行します。
- AWS Glue コンソールで、選択します Crawlers ナビゲーションペインに表示されます。
- 選択する クローラーを作成する.
- ソフトウェア設定ページで、下図のように クローラーのプロパティを設定する ページで、新しいクローラーの名前 (blog-glue-parquet-contact など) を入力し、選択します。 Next.
- ソフトウェア設定ページで、下図のように データソースと分類器を選択する 未だに for データソースの構成.
- 選択する データストアを追加する.
- S3パス、参照してください
s3://${BUCKET_NAME}/output/parquet/.
必ず選択してください parquet フォルダー内のファイルではなくフォルダーです。
- 前提条件セクションで作成した IAM ロールを選択するか、 新しいIAMロールを作成する (例えば、
AWSGlueServiceNotebookRoleBlog)、およびを選択します Next. - ソフトウェア設定ページで、下図のように 出力とスケジューリングを設定する ページ、下 出力構成、選択する
blog_glue_xmlfor データベース. - 入力します
parquet_テーブルに追加されるプレフィックスとして (オプション) およびその下に クローラースケジュール、周波数を に設定したままにします。 オンデマンド. - 選択する Next.
- すべてのパラメータを確認して選択します クローラーを作成する.
これで、クローラーを実行できるようになります。完了までに 1 ~ 2 分かかります。

AWS Glue データカタログで、Parquet ファイル用に新しく作成されたスキーマをプレビューできます。これは、XML ファイルのスキーマに似ています。

現在、Athena での使用に適したデータを所有しています。 次のセクションでは、Athena を使用してデータクエリを実行します。
Athena を使用して Parquet ファイルをクエリする
Athena はクエリをサポートしていません XMLファイル形式そのため、より効率的なデータのクエリと使用のために XML ファイルを Parquet に変換しました。 ドット表記 複合型と入れ子構造をクエリします。
次のコード例では、ドット表記を使用してネストされたデータをクエリします。

テクニック 1 が完了したので、テクニック 2 について学習しましょう。
テクニック 2: 推論および固定スキーマで AWS Glue DynamicFrames を使用する
前のセクションでは、AWS Glue クローラーを使用してテーブルを生成し、AWS Glue ジョブを使用してファイルを Parquet 形式に変換し、Athena を使用して Parquet データにアクセスして、小さな XML ファイルを処理するプロセスについて説明しました。 ただし、クローラは、XML ファイルを処理する際に制限に遭遇します。 サイズ1 MB。 このセクションでは、個々のイベントを抽出し、Athena を使用して分析を実行するために追加の解析が必要になる、より大きな XML ファイルのバッチ処理のトピックを詳しく掘り下げます。
私たちのアプローチには、AWS Glue を介して XML ファイルを読み取ることが含まれます ダイナミックフレーム、推論スキーマと固定スキーマの両方を使用します。 次に、以下を使用して個々のイベントを Parquet 形式で抽出します。 関係化 これにより、Athena を使用してシームレスにクエリと分析を行うことができるようになります。
このソリューションを実装するには、次の高レベルの手順を実行します。
- XML ファイルを読み取って分析するための AWS Glue ノートブックを作成します。
-
DynamicFramesInferSchemaXML ファイルを読み取ります。 - 関数リレーショナルを使用して、配列のネストを解除します。
- データを Parquet 形式に変換します。
- Athena を使用して Parquet データをクエリします。
- 前の手順を繰り返しますが、今回はスキーマを渡します。
DynamicFrames使用する代わりにInferSchema.
電気自動車人口データ XML ファイルには、 response ルートレベルでタグを付けます。 このタグには次の配列が含まれています row タグ、その中にネストされています。 行タグは、別の行タグのセットを含む配列であり、メーカー、モデル、その他の関連詳細など、車両に関する情報を提供します。 次のスクリーンショットは例を示しています。

AWS Glue ノートブックを作成する
AWS Glue ノートブックを作成するには、次の手順を実行します。
- Video Cloud Studioで AWS グルースタジオ コンソール、選択 Jobs > Create New Job ナビゲーションペインに表示されます。
- 選択 ジュピターノート 選択して 創造する.

- AWS Glue ジョブの名前を入力します (例:
blog_glue_xml_job_Jupyter. - 前提条件で作成したロールを選択します (
AWSGlueServiceNotebookRoleBlog).

AWS Glue ノートブックには、データベースにクエリを実行し、出力を Amazon S3 に書き込む方法を示す既存のサンプルが付属しています。
- 次のスクリーンショットに示すようにタイムアウト (分単位) を調整し、セルを実行して AWS Glue インタラクティブセッションを作成します。

基本的な変数を作成する
インタラクティブ セッションを作成した後、ノートブックの最後に、次の変数を含む新しいセルを作成します (独自のバケット名を指定します)。
XML ファイルを読み取ってスキーマを推測する
スキーマを渡さない場合、 DynamicFrame、ファイルのスキーマを推測します。 動的フレームを使用してデータを読み取るには、次のコマンドを使用できます。
DynamicFrame スキーマを出力する
次のコードを使用してスキーマを出力します。

スキーマは、次のような入れ子構造を示しています。 row 複数の要素を含む配列。 この構造を線にネスト解除するには、AWS Glue を使用できます。 関係化 変身:
行配列内に含まれる情報のみに興味があり、次のコマンドを使用してスキーマを表示できます。

列名には次のものが含まれます row.row、データセット内の配列構造と配列列に対応します。 この投稿では列の名前は変更しません。 その手順については、を参照してください。 AWS Glue を使用してデータファイル内の列名の動的マッピングと名前変更を自動化する: パート 1。 次に、次のコマンドを使用して、データを Parquet 形式に変換し、AWS Glue テーブルを作成できます。
AWSグルー DynamicFrame は、ETL スクリプトでデータ カタログ内のスキーマを作成および更新するために使用できる機能を提供します。 私たちが使用するのは、 updateBehavior パラメータを使用して、データ カタログにテーブルを直接作成します。 このアプローチでは、AWS Glue ジョブの完了後に AWS Glue クローラーを実行する必要はありません。

スキーマを設定してXMLファイルを読み取る
ファイルを読み取る別の方法は、スキーマを事前定義することです。 これを行うには、次の手順を実行します。
- AWS Glue データ型をインポートします。
- XML ファイルのスキーマを作成します。
- XML ファイルを読み取るときにスキーマを渡します。
- 以前と同様にデータセットのネストを解除します。
- データセットを Parquet に変換し、AWS Glue テーブルを作成します。
Athena を使用してテーブルにクエリを実行する
両方のテーブルを作成したので、Athena を使用してテーブルにクエリを実行できます。 たとえば、次のクエリを使用できます。

クリーンアップ
この投稿では、AWS Glue データカタログに IAM ロール、AWS Glue Jupyter ノートブック、および 3 つのテーブルを作成しました。 また、いくつかのファイルを SXNUMX バケットにアップロードしました。 これらのオブジェクトをクリーンアップするには、次の手順を実行します。
- IAM コンソールで、作成したロールを削除します。
- AWS Glue Studio コンソールで、カスタム分類子、クローラー、ETL ジョブ、および Jupyter ノートブックを削除します。
- AWS Glue データカタログに移動し、作成したテーブルを削除します。
- Amazon S3 コンソールで、作成したバケットに移動し、という名前のフォルダーを削除します。
temp,infer_schema,no_infer_schema.
主要な取り組み
AWS Glue には、と呼ばれる機能があります。 InferSchema AWS グルーで DynamicFrames。 データ フレームに含まれるデータに基づいて、データ フレームの構造を自動的に判断します。 対照的に、スキーマを定義するとは、データをロードする前にデータ フレームの構造がどうあるべきかを明示的に指定することを意味します。
XML はテキストベースの形式であるため、列のデータ型を制限しません。 これにより、InferSchema 関数で問題が発生する可能性があります。 たとえば、最初の実行では、列 A の値が 2 であるファイルは、列 A が整数である Parquet ファイルになります。 3 回目の実行では、新しいファイルには値 C を持つ列 A が含まれており、列 A を文字列として含む Parquet ファイルが作成されます。 現在、SXNUMX には XNUMX つのファイルがあり、それぞれに異なるデータ型の列 A が含まれているため、ダウンストリームで問題が発生する可能性があります。
入れ子構造や配列などの複雑なデータ型でも同じことが起こります。 たとえば、ファイルに次のタグ エントリが XNUMX つある場合、 transaction、構造体として推論されます。 ただし、別のファイルに同じタグがある場合は、配列として推論されます。
こうしたデータ型の問題にもかかわらず、 InferSchema スキーマがわからない場合、またはスキーマを手動で定義することが現実的でない場合に便利です。 ただし、大規模なデータセットや常に変化するデータセットには理想的ではありません。 スキーマの定義は、特に複雑なデータ型の場合により正確になりますが、手動での作業が必要であったり、データの変更に柔軟性がなかったりするなど、独自の問題があります。
InferSchema 不正なデータ型推論や null 値の処理の問題などの制限があります。 スキーマの定義には、手作業や潜在的なエラーなどの制限もあります。
スキーマを推論するか定義するかの選択は、プロジェクトのニーズによって異なります。 InferSchema は小規模なデータセットを迅速に探索するのに最適ですが、精度と一貫性が必要な大規模で複雑なデータセットにはスキーマを定義する方が適しています。 各方法のトレードオフと制約を考慮して、プロジェクトに最も適した方法を選択してください。
まとめ
この投稿では、AWS Glue を使用して XML データを管理するための XNUMX つの手法を検討しました。それぞれの手法は、遭遇する可能性のある特定のニーズや課題に対処するために調整されています。
テクニック 1 は、グラフィカル インターフェイスを好む人に使いやすい方法を提供します。 AWS Glue クローラーとビジュアルエディターを使用して、XML ファイルのテーブル構造を簡単に定義できます。 このアプローチはデータ管理プロセスを簡素化し、データを処理する簡単な方法を探している人にとって特に魅力的です。
ただし、特に 1 MB を超える行を持つ XML ファイルを処理する場合、クローラーには制限があることを認識しています。 ここでテクニック 2 が役に立ちます。 AWS Glue を利用することで DynamicFrames 推論スキーマと固定スキーマの両方を使用し、AWS Glue ノートブックを使用すると、あらゆるサイズの XML ファイルを効率的に処理できます。 この方法は、1 MB の制約を超える行を含む XML ファイルであってもシームレスな処理を保証する堅牢なソリューションを提供します。
データ管理の世界をナビゲートする際、これらのテクニックをツールキットに組み込むことで、プロジェクトの特定の要件に基づいて情報に基づいた意思決定を行うことができるようになります。 手法 1 のシンプルさを好むか、手法 2 のスケーラビリティを好むかに関係なく、AWS Glue は XML データを効果的に処理するために必要な柔軟性を提供します。
著者について
 ナブニット・シュクラ分析に重点を置く AWS スペシャリスト ソリューション アーキテクトとして働いています。 彼は、クライアントがデータから貴重な洞察を発見できるよう支援することに強い熱意を持っています。 専門知識を通じて、企業が情報に基づいたデータに基づいた選択を行えるようにする革新的なソリューションを構築しています。 注目すべきことに、Navnit Shukla は「AWS でのデータ ラングリング」というタイトルの本の著名な著者です。
ナブニット・シュクラ分析に重点を置く AWS スペシャリスト ソリューション アーキテクトとして働いています。 彼は、クライアントがデータから貴重な洞察を発見できるよう支援することに強い熱意を持っています。 専門知識を通じて、企業が情報に基づいたデータに基づいた選択を行えるようにする革新的なソリューションを構築しています。 注目すべきことに、Navnit Shukla は「AWS でのデータ ラングリング」というタイトルの本の著名な著者です。
 パトリック・ミュラー AWS でシニア データ ラボ アーキテクトとして働いています。 彼の主な責任は、顧客がアイデアを実稼働可能なデータ製品に変えるのを支援することです。 自由時間には、パトリックはサッカーをしたり、映画を見たり、旅行したりすることを楽しんでいます。
パトリック・ミュラー AWS でシニア データ ラボ アーキテクトとして働いています。 彼の主な責任は、顧客がアイデアを実稼働可能なデータ製品に変えるのを支援することです。 自由時間には、パトリックはサッカーをしたり、映画を見たり、旅行したりすることを楽しんでいます。
 アモー・ガイクワッド アマゾン ウェブ サービスのシニア ソリューション開発者です。 彼は、世界中の顧客が AWS 上で AI/ML ソリューションを構築およびデプロイできるよう支援しています。 彼の仕事は主にコンピュータ ビジョンと自然言語処理に焦点を当てており、顧客が持続可能性を実現するために AI/ML ワークロードを最適化できるよう支援しています。 アモグは、機械学習を専門とするコンピューター サイエンスの修士号を取得しています。
アモー・ガイクワッド アマゾン ウェブ サービスのシニア ソリューション開発者です。 彼は、世界中の顧客が AWS 上で AI/ML ソリューションを構築およびデプロイできるよう支援しています。 彼の仕事は主にコンピュータ ビジョンと自然言語処理に焦点を当てており、顧客が持続可能性を実現するために AI/ML ワークロードを最適化できるよう支援しています。 アモグは、機械学習を専門とするコンピューター サイエンスの修士号を取得しています。
 シーラ・ソノーネ AWS の上級常駐アーキテクトです。 彼女は、AWS の顧客がデータ、分析、AI/ML のワークロードと実装の高速化に関して情報に基づいた選択とトレードオフを行えるよう支援します。 余暇には、家族と過ごす時間を楽しんでおり、通常はテニスコートで過ごしています。
シーラ・ソノーネ AWS の上級常駐アーキテクトです。 彼女は、AWS の顧客がデータ、分析、AI/ML のワークロードと実装の高速化に関して情報に基づいた選択とトレードオフを行えるよう支援します。 余暇には、家族と過ごす時間を楽しんでおり、通常はテニスコートで過ごしています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/

