Amazon EMR サーバーレス は、Apache Spark や Apache Hive などの最新のオープン ソース フレームワークを使用する分析アプリケーションの操作を簡素化するサーバーレス ランタイム環境を提供します。 EMR サーバーレスを使用すると、これらのフレームワークでアプリケーションを実行するためにクラスターを構成、最適化、保護、または操作する必要がありません。 変化するデータ量や処理要件に合わせてリソースのサイズを数秒で変更する自動スケーリングにより、あらゆる規模で分析ワークロードを実行できます。 EMR サーバーレスは、アプリケーションに適切な量の容量を提供するためにリソースを自動的にスケールアップおよびスケールダウンします。料金は使用した分だけお支払いいただきます。
AWSステップ関数 は、開発者が一連のイベント駆動のステップとしてアプリケーションの視覚的なワークフローを構築できるようにするサーバーレス オーケストレーション サービスです。 Step Functions は、サーバーレス ワークフローのステップが確実に実行され、ステージ間で情報が受け渡され、エラーが自動的に処理されることを保証します。
AWS Step Functions と Amazon EMR サーバーレスの統合により、ビッグデータのワークフローの管理と調整が容易になります。 この統合が行われる前は、ジョブのステータスを手動でポーリングするか、API 呼び出しを通じて待機メカニズムを実装する必要がありました。 「ジョブの実行 (.sync)」統合のサポートにより、EMR サーバーレス ジョブをより効率的に管理できるようになりました。 .sync を使用すると、Step Functions ワークフローは、EMR サーバーレス ジョブが完了するのを待ってから次のステップに進むことができるため、ジョブの実行が事実上ステート マシンの一部になります。 同様に、「要求応答」パターンは、ジョブをトリガーし、すぐに応答を返す場合に便利です。 Step Functions ワークフローの範囲。 この統合により、ジョブのステータスを監視するための追加の手順が不要になり、アーキテクチャが簡素化され、システム全体がより効率的になり、管理が容易になります。
この投稿では、次を使用して PySpark アプリケーションをオーケストレーションする方法について説明します。 Amazon EMR サーバーレス および AWSステップ関数。 EMR サーバーレス上で Spark ジョブを実行します。 Citi Bike データセット のデータ Amazon シンプル ストレージ サービス (Amazon S3) バケットを作成し、集計結果を Amazon S3 に保存します。
ソリューションの概要
このソリューションを、次の例を使用して説明します。 Citi Bike データセット。 このデータセットには、乗車可能なタイプ、開始駅、開始時刻、終了駅、終了時刻、シティ バイカーの乗車に関するその他のさまざまな要素などの多数のパラメーターが含まれています。 私たちの目的は、特定の月における自転車旅行の最小、最大、平均時間を見つけることです。
このソリューションでは、入力データが S3 入力パスから読み取られ、PySpark コードで変換と集計が適用され、要約された出力が S3 出力パスに書き込まれます。 s3://<bucket-name>/serverlessout/.
ソリューションは次のように実装されます。
- Spark ランタイムを使用して EMR サーバーレス アプリケーションを作成します。 アプリケーションの作成後、そのアプリケーションにデータ処理ジョブを送信できます。 この API ステップは、アプリケーションの作成が完了するまで待機します。
- PySpark ジョブを送信し、その完了を待ちます。
StartJobRun(.sync) API。 これにより、ジョブを Amazon EMR サーバーレス アプリケーションに送信し、ジョブが完了するまで待つことができます。 - PySpark ジョブが完了すると、要約された出力が S3 出力ディレクトリで利用可能になります。
- ジョブでエラーが発生した場合、ステート マシン ワークフローは失敗を示します。 ステート マシン内の特定のエラーを検査できます。 さらに詳細な分析が必要な場合は、EMR Studio コンソールで EMR ジョブの失敗ログを確認することもできます。
前提条件
開始する前に、次の前提条件があることを確認してください。
- An AWSアカウント
- 管理者アクセス権を持つ IAM ユーザー
- S3バケット
ソリューションアーキテクチャ
プロセス全体を自動化するために、オーケストレーション用の Step Functions とデータ変換用の Amazon EMR サーバーレスを統合する次のアーキテクチャを使用します。 要約された出力は、Amazon S3 バケットに書き込まれます。
次の図は、この使用例のアーキテクチャを示しています。

展開手順
このチュートリアルを開始する前に、デプロイに使用されるロールに、ソリューションの一部として必要なリソースを作成するための関連するアクセス許可がすべて付与されていることを確認してください。 適切な権限を持つロールは、次の手順を使用して CloudFormation テンプレートを通じて作成されます。
ステップ 1: Step Functions ステート マシンを作成する
Step Functions ステート マシン ワークフローは、コードを直接使用する方法と、Step Functions Studio のグラフィカル インターフェイスを使用する方法の 1 つの方法で作成できます。 ステート マシンを作成するには、以下のオプション 2 またはオプション XNUMX のいずれかの手順に従います。
オプション 1: コードを通じてステート マシンを直接作成する
Step Functions ステート マシンと必要な IAM ロールを作成するには、次の手順を実行します。
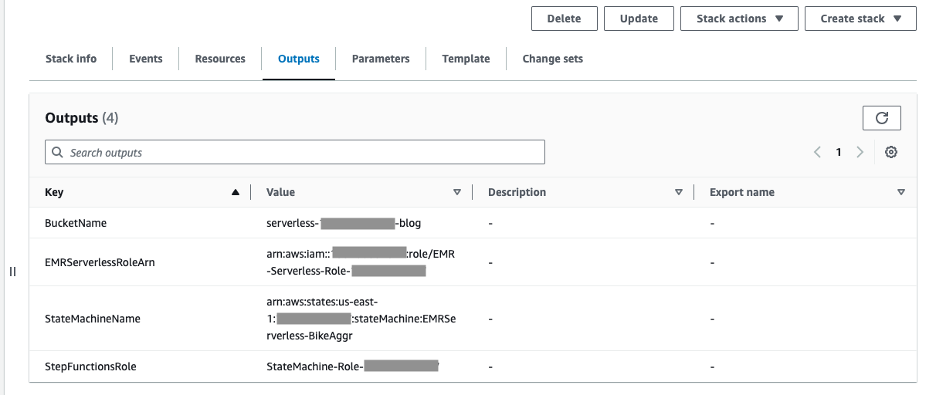
- これを使用して CloudFormation スタックを起動します 。 Cloud Formation コンソールでスタック名を指定し、デフォルトを受け入れてスタックを作成します。 一度 クラウドフォーメーション デプロイメントが完了すると、次のリソースが作成されます。 EMR サービスにリンクされたロール EMR サーバーレスにアクセスするために、この CloudFormation スタックによって自動的に作成されます。
- PySpark スクリプトをアップロードし、EMR サーバーレス ジョブからの出力データを書き込むための S3 バケット。 S3 バケットでデフォルトの暗号化を有効にして新しいオブジェクトを暗号化するとともに、アクセス ログを有効にしてバケットに対して行われたすべてのリクエストを記録することをお勧めします。 これらの推奨事項に従うと、セキュリティが向上し、バケットへのアクセスが可視化されます。
- EMR サーバーレス ランタイム ロール。EMR サーバーレス ジョブの実行時に必要な特定のリソースに対する詳細なアクセス許可を提供します。
- Step Functions ステートマシンによって使用される AWS リソースにアクセスするための AWS Step Functions アクセス許可を付与するロール。
- EMR サーバーレス ステップを備えたステート マシン。
- PySpark スクリプトを使用して S3 バケットを準備するには、次のコマンドを開きます。 AWS クラウドシェル AWS コンソールの右上隅にあるツールバーから、CloudShell で次の AWS CLI コマンドを実行します (必ず置き換えてください) < > AWS アカウント ID を使用):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/bikeaggregator.py s3://serverless-<<ACCOUNT-ID>>-blog/scripts/
![]()

- 入力データを含む S3 バケットを準備するには、CloudShell で次の AWS CLI コマンドを実行します (必ず置き換えてください) < > AWS アカウント ID を使用):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/201306-citibike-tripdata.csv s3://serverless-<<ACCOUNT-ID>>-blog/data/ --copy-props none

オプション 2: Workflow Studio を使用して Step Functions ステート マシンを作成する
前提条件
Workshop Studio でステート マシンを作成する前に、関連するすべてのロールとリソースがソリューションの一部として作成されていることを確認してください。
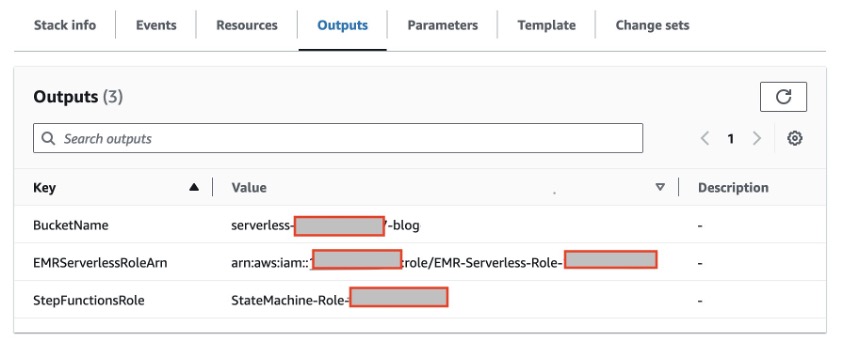
- 必要な IAM ロールと S3 バケットを AWS アカウントにデプロイするには、これを使用して CloudFormation スタックを起動します。 。 一度 クラウドフォーメーション デプロイメントが完了すると、次のリソースが作成されます。
- PySpark スクリプトをアップロードし、出力データを書き込むための S3 バケット。 S3 バケットでデフォルトの暗号化を有効にして新しいオブジェクトを暗号化するとともに、アクセス ログを有効にしてバケットに対して行われたすべてのリクエストを記録することをお勧めします。 これらの推奨事項に従うと、セキュリティが向上し、バケットへのアクセスが可視化されます。
- EMR サーバーレス ランタイム ロール。EMR サーバーレス ジョブの実行時に必要な特定のリソースに対する詳細なアクセス許可を提供します。
- Step Functions ステートマシンによって使用される AWS リソースにアクセスするための AWS Step Functions アクセス許可を付与するロール。
- PySpark スクリプトを使用して S3 バケットを準備するには、次のコマンドを開きます。 AWS クラウドシェル AWS コンソールの右上にあるツールバーから、CloudShell で次の AWS CLI コマンドを実行します (必ず置き換えてください) < > AWS アカウント ID を使用):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/bikeaggregator.py s3://serverless-<<ACCOUNT-ID>>-blog/scripts/
![]()

- 入力データを含む S3 バケットを準備するには、CloudShell で次の AWS CLI コマンドを実行します (必ず置き換えてください) < > AWS アカウント ID を使用):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/201306-citibike-tripdata.csv s3://serverless-<<ACCOUNT-ID>>-blog/data/ --copy-props none

Step Functions ステート マシンを作成するには、次の手順を実行します。
- ソフトウェア設定ページで、下図のように Step Functionsコンソール、選択する ステートマシンを作成します。
- 続ける ブランク テンプレートを選択し、 選択.
- アクションメニュー 左側の Step Functions には、デザイン キャンバスのワークフロー グラフにドラッグ アンド ドロップできる AWS サービス API のリストが表示されます。 タイプ EMR サーバレス セクションに サーチ をドラッグ Amazon EMR サーバーレス CreateApplication 状態をワークフロー グラフに追加します。
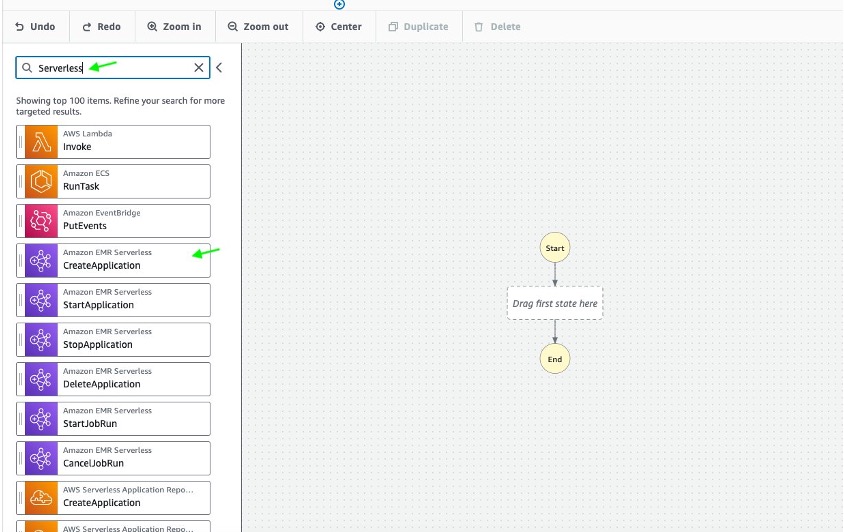
- キャンバスで、 Amazon EMR サーバーレス CreateApplication 状態を使用してそのプロパティを設定します。 の 検査官 右側のパネルには構成オプションが表示されます。 次の構成値を指定します。
- 以下のスクリーンショットに示すように、ジョブタイプを 州名 〜へ EMRサーバーレスアプリケーションの作成
- 次の値を指定します。 API パラメータ。 これにより、デフォルトの構成設定を使用して、Amazon EMR リリース 6.12.0 に基づいた Apache Spark を使用した EMR サーバーレス アプリケーションが作成されます。
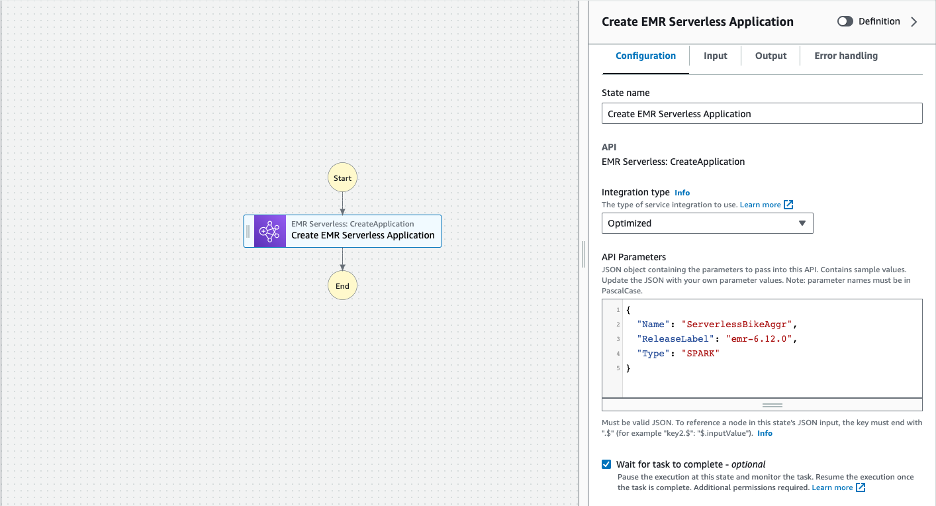
- クリック タスクが完了するまで待ちます – オプション チェックボックスをオンにすると、EMR サーバーレス アプリケーションの作成状態が完了するまで待機してから、次の状態を実行します。
- 次の状態、 選択する 新しい状態を追加 ドロップダウンからオプションを選択します。
- ドラッグ EMR サーバーレス StartJobRun ワークフローの左側のブラウザーの状態から次の状態へ。
- リネーム 州名 〜へ PySpark ジョブを送信する
- 次の値を指定します。 API パラメータ をクリックし タスクが完了するまで待ちます – オプション (必ず交換してください < > AWS アカウント ID を使用します)。
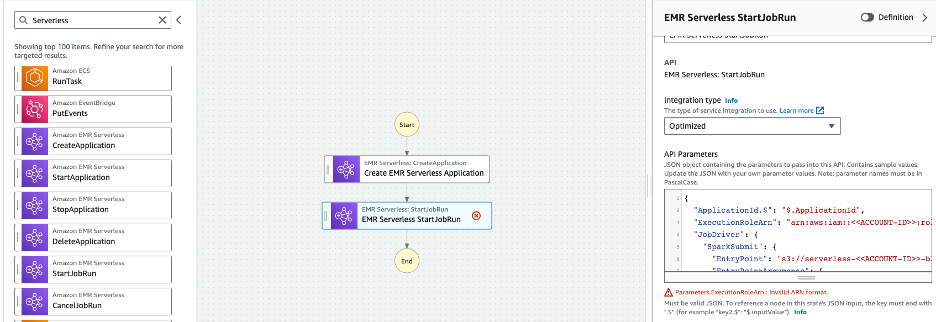
- 現在地に最も近い 設定 ステート マシンのタブを上からクリックし、次の構成を変更します。
- 変更する ステートマシン名 〜へ EMRServerless-BikeAggr 「詳細」にあります。
- 「権限」セクションで、次を選択します。 ステートマシン-ロール-< > のドロップダウンから 実行ロール。 (必ず交換してください < > AWS アカウント ID を使用).
- 引き続きステップを追加します ジョブの成功を確認する 次の図に示すように、スタジオから。
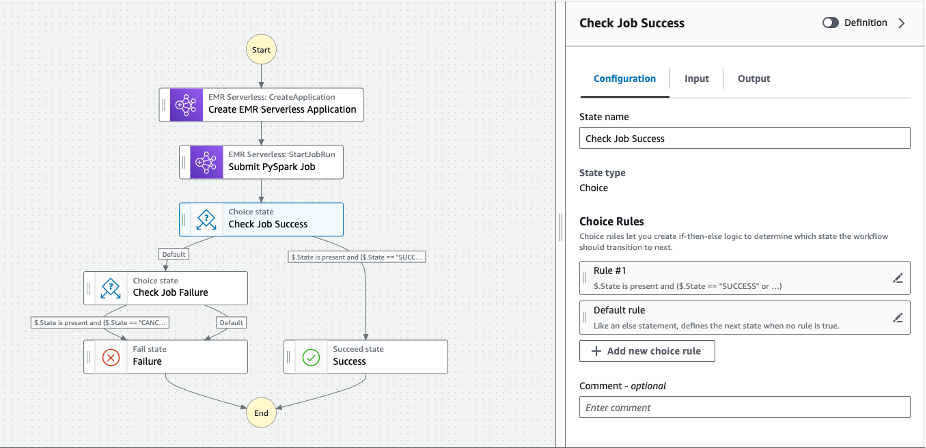
- クリック 創造する EMR サーバーレス ジョブをオーケストレーションするための Step Functions ステート マシンを作成します。
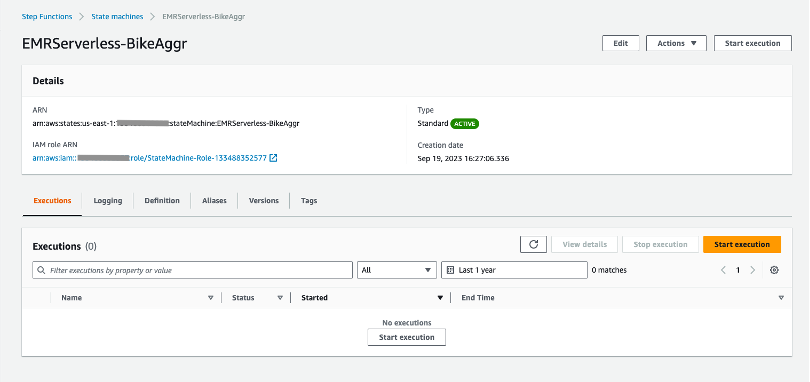
ステップ 2: Step Functions を呼び出す
ステップ関数が作成されたので、 実行を開始します ボタン:
ステップ関数が呼び出されると、次のスクリーンショットに示すように、その実行フローが表示されます。 私たちが選んだから タスクが完了するまで待ちます このステップの config (.sync API) を使用すると、次のステップは開始されず、EMR サーバーレス アプリケーションが作成されるまで待機します (青色は作成中の Amazon EMR サーバーレス アプリケーションを表します)。

EMR サーバーレス アプリケーションの作成に成功したら、そのアプリケーションに PySpark ジョブを送信します。
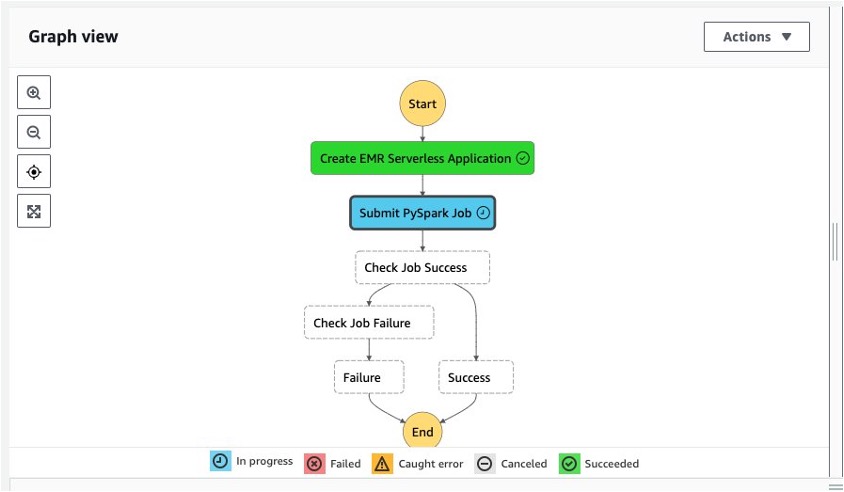
EMR サーバーレス ジョブが完了すると、 PySparkを送信する ジョブ ステップが緑色に変わります。 これは、私たちが選択したからです タスクが完了するまで待ちます このステップの構成 (.sync API を使用)。

EMR サーバーレス アプリケーション ID と PySpark ジョブ実行 ID 出力 のタブ PySpark ジョブを送信する ステップ。
ステップ 3: 検証
ジョブが正常に完了したことを確認するには、次の場所に移動します。 EMRサーバーレスコンソール EMR サーバーレス アプリケーション ID を見つけます。 アプリケーション ID をクリックして、Step Functions から送信された PySpark ジョブ実行の実行の詳細を確認します。

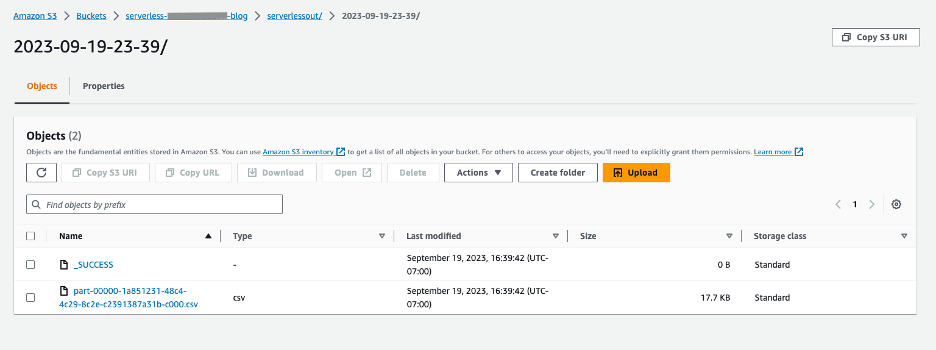
ジョブ実行の出力を確認するには、次の図に示すように、出力が .csv ファイルに保存される S3 バケットを確認します。
掃除
にログインします。 AWSマネジメントコンソール AWS アカウントへの不要な請求を避けるために、このデプロイメントによって作成された S3 バケットをすべて削除します。 例えば: s3://serverless-<<ACCOUNT-ID>>-blog/
次に、環境をクリーンアップし、ソリューション構成手順で作成した CloudFormation テンプレートを削除します。
このソリューションの一部として作成したステップ関数を削除します。
まとめ
この投稿では、Workflow Studio を使用して Step Functions で Amazon EMR サーバーレス Spark ジョブを起動し、Citi Bike データセットから集約された出力を作成し、レポートを生成するシンプルな ETL パイプラインを実装する方法について説明しました。
これが、このソリューションをデータセットで使用し、より複雑なビジネス ルールを適用して一時的なクラスターのユースケースを解決するための優れた出発点となることを願っています。
追加の質問やフィードバックはありますか? コメントを残す。 皆様のご意見やご提案をお待ちしております。
参考文献
著者について
 ナヴィーン・バララマン アマゾン ウェブ サービスのシニア クラウド アプリケーション アーキテクトです。 彼はコンテナ、サーバーレス、マイクロサービスの構築、そして顧客が AWS クラウドの力を活用できるよう支援することに情熱を注いでいます。
ナヴィーン・バララマン アマゾン ウェブ サービスのシニア クラウド アプリケーション アーキテクトです。 彼はコンテナ、サーバーレス、マイクロサービスの構築、そして顧客が AWS クラウドの力を活用できるよう支援することに情熱を注いでいます。
 カルティク・プラバカール AWS の Amazon EMR のシニア ビッグ データ ソリューション アーキテクトです。 彼は経験豊富な分析エンジニアであり、AWS のお客様と協力して、データの旅の成功を支援するためにベスト プラクティスと技術的なアドバイスを提供しています。
カルティク・プラバカール AWS の Amazon EMR のシニア ビッグ データ ソリューション アーキテクトです。 彼は経験豊富な分析エンジニアであり、AWS のお客様と協力して、データの旅の成功を支援するためにベスト プラクティスと技術的なアドバイスを提供しています。
 パルル・サクセナ アマゾン ウェブ サービスのビッグデータ スペシャリスト ソリューション アーキテクトであり、Amazon EMR、Amazon Athena、AWS Glue、AWS Lake Formation に重点を置いており、AWS プラットフォーム上で複雑なビッグデータ ワークロードを実行するためのアーキテクチャに関するガイダンスを顧客に提供しています。 余暇には、旅行をしたり、家族や友人と時間を過ごすことを楽しんでいます。
パルル・サクセナ アマゾン ウェブ サービスのビッグデータ スペシャリスト ソリューション アーキテクトであり、Amazon EMR、Amazon Athena、AWS Glue、AWS Lake Formation に重点を置いており、AWS プラットフォーム上で複雑なビッグデータ ワークロードを実行するためのアーキテクチャに関するガイダンスを顧客に提供しています。 余暇には、旅行をしたり、家族や友人と時間を過ごすことを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/orchestrate-amazon-emr-serverless-jobs-with-aws-step-functions/

