本日、メタを使用して Code Llama モデルを微調整する機能を発表できることを嬉しく思います。 Amazon SageMaker ジャンプスタート。大規模言語モデル (LLM) の Code Llama ファミリーは、7 億から 70 億のパラメーターの規模にわたる、事前トレーニングされ、微調整されたコード生成モデルのコレクションです。微調整された Code Llama モデルは、ベースの Code Llama モデルよりも優れた精度と説明可能性を提供します。これは、テストで明らかです。 HumanEval および MBPP データセット。 SageMaker JumpStart を使用して、Code Llama モデルを微調整してデプロイできます。 Amazon SageMakerスタジオ 数回クリックするか、SageMaker Python SDK を使用するだけの UI。 Llama モデルの微調整は、 ラマレシピ GitHub リポジトリ PyTorch FSDP、PEFT/LoRA、および Int8 量子化技術を使用して Meta からデータを取得します。
この投稿では、ワンクリック UI と次の SDK エクスペリエンスを通じて、SageMaker JumpStart 経由で Code Llama の事前トレーニング済みモデルを微調整する方法を説明します。 GitHubリポジトリ.
SageMaker JumpStart とは
SageMaker JumpStart を使用すると、機械学習 (ML) 実践者は、公開されている基盤モデルの幅広い選択肢から選択できます。 ML 実践者は基礎モデルを専用のモデルにデプロイできます。 アマゾンセージメーカー ネットワーク分離環境からインスタンスを抽出し、モデルのトレーニングとデプロイメントに SageMaker を使用してモデルをカスタマイズします。
コードラマとは何ですか
Code Llama は、コードに特化したバージョンです。 ラマ2 これは、コード固有のデータセットで Llama 2 をさらにトレーニングし、同じデータセットからより多くのデータを長時間サンプリングすることによって作成されました。 Code Llama は、強化されたコーディング機能を備えています。コードと自然言語プロンプトの両方から、コードとコードに関する自然言語を生成できます (たとえば、「フィボナッチ数列を出力する関数を書いてください」)。コード補完やデバッグにも使用できます。 Python、C++、Java、PHP、Typescript (JavaScript)、C#、Bash など、現在使用されている最も一般的なプログラミング言語の多くをサポートしています。
Code Llama モデルを微調整する理由
メタ公開された Code Llama パフォーマンス ベンチマーク HumanEval と MBPP Python、Java、JavaScript などの一般的なコーディング言語用。 HumanEval での Code Llama Python モデルのパフォーマンスは、38B Python モデルの 7% から 57B Python モデルの 70% まで、さまざまなコーディング言語とタスクにわたってさまざまなパフォーマンスを示しました。さらに、SQL 評価ベンチマークで明らかなように、SQL プログラミング言語で微調整された Code Llama モデルはより良い結果を示しています。これらの公開されたベンチマークは、Code Llama モデルを微調整することの潜在的な利点を強調し、パフォーマンス、カスタマイズ、特定のコーディング ドメインとタスクへの適応を向上させます。
SageMaker Studio UI を介したノーコード微調整
SageMaker Studio を使用して Llama モデルの微調整を開始するには、次の手順を実行します。
- SageMaker Studio コンソールで、次を選択します。 ジャンプスタート ナビゲーションペインに表示されます。
オープンソース モデルからプロプライエタリ モデルまで、350 を超えるモデルのリストが見つかります。
- Code Llama モデルを検索します。

Code Llama モデルが表示されない場合は、シャットダウンして再起動することで SageMaker Studio のバージョンを更新できます。バージョンアップデートの詳細については、以下を参照してください。 Studio アプリをシャットダウンして更新する。を選択して、他のモデル バリエーションを見つけることもできます。 すべてのコード生成モデルを調べる または、検索ボックスで Code Llama を検索します。
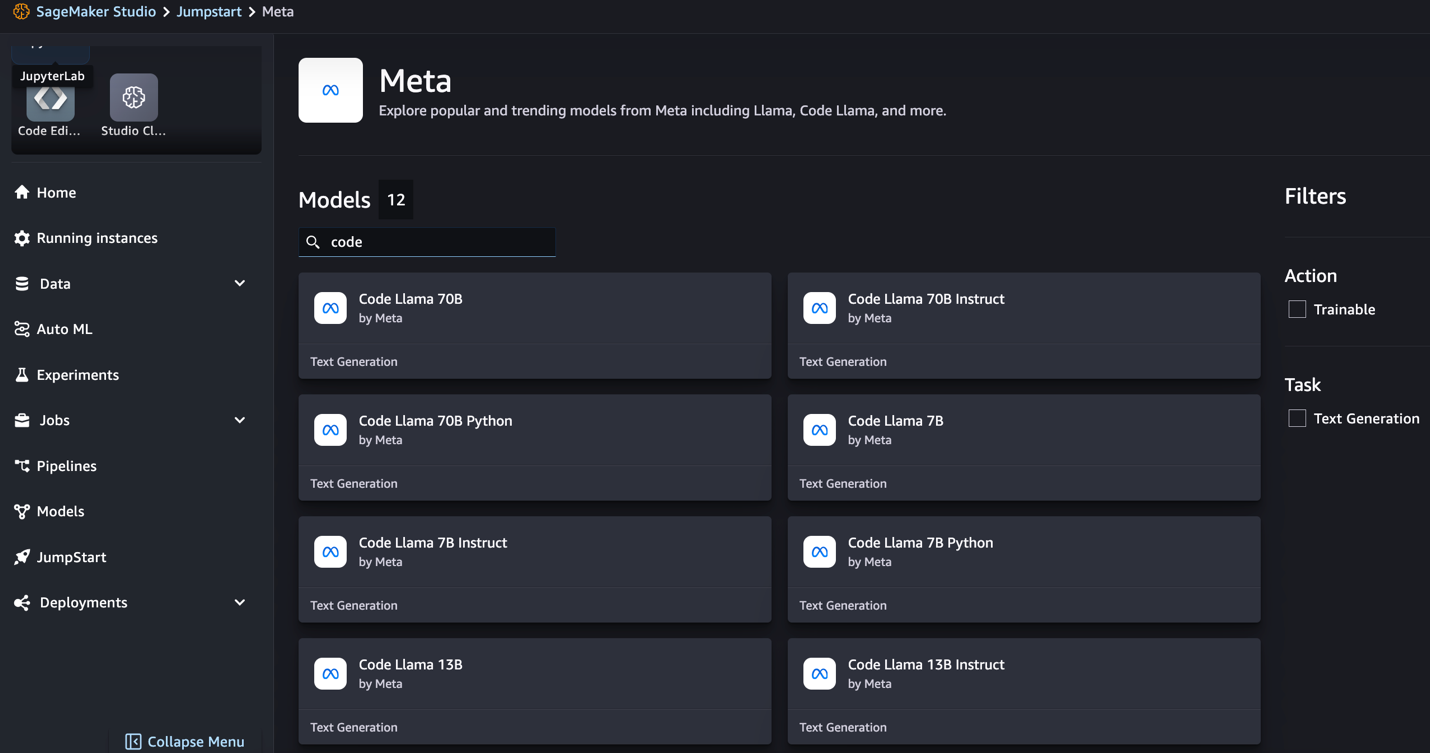
SageMaker JumpStart は現在、Code Llama モデルの命令の微調整をサポートしています。次のスクリーンショットは、Code Llama 2 70B モデルの微調整ページを示しています。
- トレーニングデータセットの場所を指定できます。 Amazon シンプル ストレージ サービス (Amazon S3) 微調整用のトレーニングおよび検証データセットを含むバケット。
- デプロイメント構成、ハイパーパラメータ、セキュリティ設定を設定して微調整します。
- 選択する トレーニング SageMaker ML インスタンスで微調整ジョブを開始します。
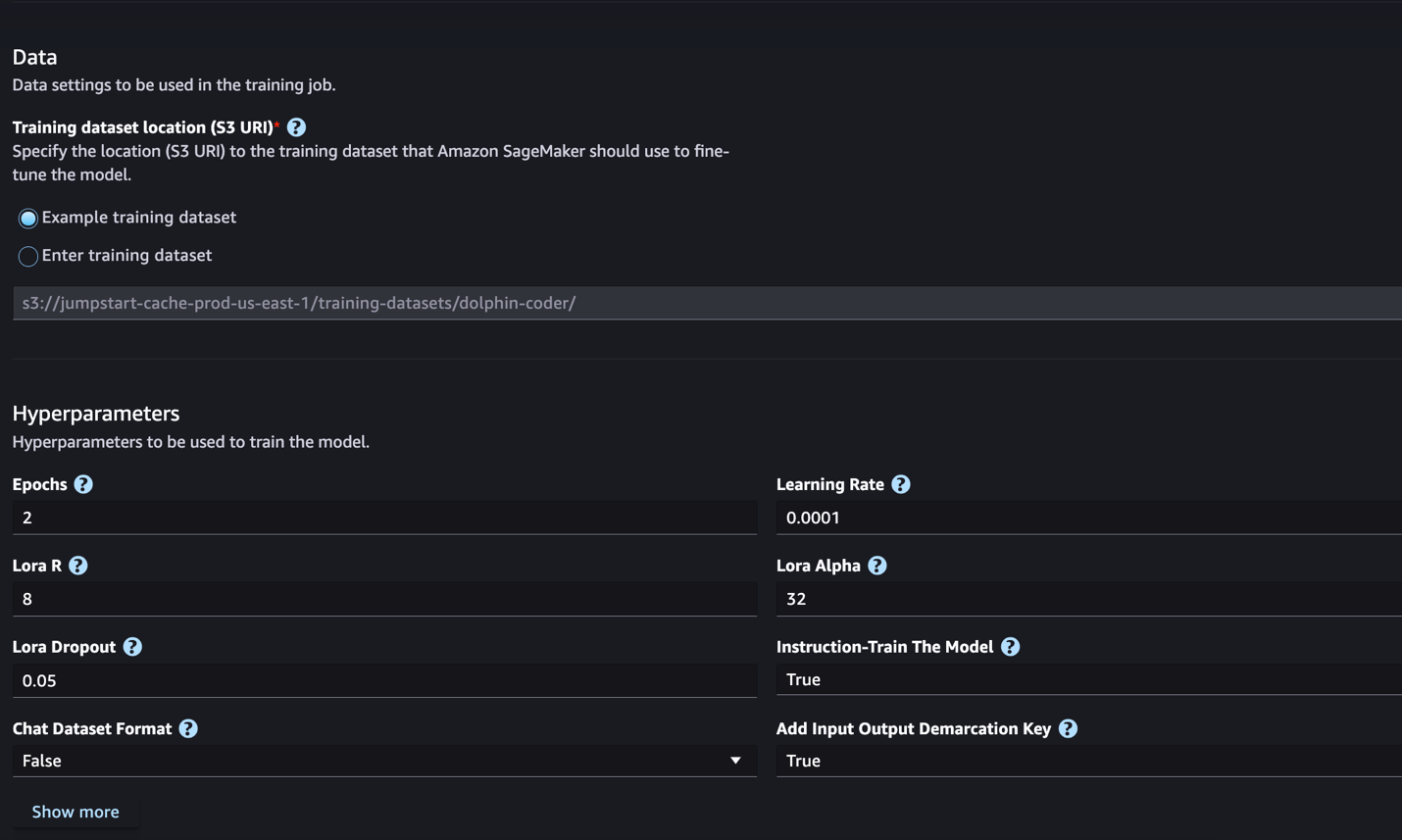
次のセクションでは、命令の微調整のために準備する必要があるデータセット形式について説明します。
- モデルを微調整したら、SageMaker JumpStart のモデル ページを使用してモデルをデプロイできます。
次のスクリーンショットに示すように、微調整が完了すると、微調整されたモデルをデプロイするオプションが表示されます。

SageMaker Python SDK を介して微調整する
このセクションでは、命令形式のデータセット上で SageMaker Python SDK を使用して Code LIama モデルを微調整する方法を示します。具体的には、命令を使用して記述された一連の自然言語処理 (NLP) タスクに合わせてモデルが微調整されます。これは、ゼロショット プロンプトを含む目に見えないタスクに対するモデルのパフォーマンスを向上させるのに役立ちます。
微調整ジョブを完了するには、次の手順を実行します。微調整コード全体は、 GitHubリポジトリ.
まず、命令の微調整に必要なデータセットの形式を見てみましょう。トレーニング データは JSON 行 (.jsonl) 形式でフォーマットする必要があります。各行はデータ サンプルを表す辞書です。すべてのトレーニング データは 1 つのフォルダーに存在する必要があります。ただし、複数の .jsonl ファイルに保存できます。以下は JSON 行形式のサンプルです。
トレーニング フォルダーには、 template.json 入力形式と出力形式を記述したファイル。以下はテンプレートの例です。
テンプレートと一致させるには、JSON 行ファイル内の各サンプルに次のものが含まれている必要があります。 system_prompt, question, response 田畑。このデモでは、 Dolphin Coder データセット ハグフェイスより。
データセットを準備して S3 バケットにアップロードしたら、次のコードを使用して微調整を開始できます。
次のコードに示すように、微調整されたモデルを推定器から直接デプロイできます。詳細については、「」のノートを参照してください。 GitHubリポジトリ.
微調整テクニック
Llama などの言語モデルのサイズは 10 GB、さらには 100 GB を超えます。 このような大規模なモデルを微調整するには、非常に多くの CUDA メモリを備えたインスタンスが必要です。 さらに、これらのモデルのトレーニングは、モデルのサイズが原因で非常に時間がかかる可能性があります。 したがって、効率的な微調整を行うために、次の最適化を使用します。
- 低ランク適応 (LoRA) – これは、大規模モデルを効率的に微調整するためのパラメータ効率的微調整 (PEFT) の一種です。この方法では、モデル全体をフリーズし、調整可能なパラメーターまたはレイヤーの小さなセットのみをモデルに追加します。たとえば、Llama 7 2B の 7 億個のパラメータすべてをトレーニングする代わりに、パラメータの 1% 未満を微調整できます。これにより、勾配、オプティマイザーの状態、その他のトレーニング関連情報をパラメーターの 1% のみ保存するだけで済むため、メモリ要件が大幅に削減されます。さらに、これはトレーニング時間とコストの削減にも役立ちます。この方法の詳細については、以下を参照してください。 LoRA: 大規模言語モデルの低ランク適応.
- Int8 量子化 – LoRA などの最適化を行ったとしても、Llama 70B などのモデルは依然としてトレーニングするには大きすぎます。トレーニング中にメモリ フットプリントを減らすために、トレーニング中に Int8 量子化を使用できます。通常、量子化により浮動小数点データ型の精度が低下します。これにより、モデルの重みを保存するために必要なメモリは減少しますが、情報が失われるためパフォーマンスが低下します。 Int8 量子化では 8 分の XNUMX 精度のみが使用されますが、単にビットを削除するわけではないため、パフォーマンスの低下は生じません。データをあるタイプから別のタイプに丸めます。 IntXNUMX 量子化について詳しくは、を参照してください。 LLM.int8(): 大規模なトランスフォーマーのための 8 ビット行列乗算.
- 完全にシャードされたデータ並列 (FSDP) – これはデータ並列トレーニング アルゴリズムの一種で、データ並列ワーカー間でモデルのパラメーターをシャード化し、オプションでトレーニング計算の一部を CPU にオフロードできます。 パラメーターは異なる GPU 間でシャーディングされますが、各マイクロバッチの計算は GPU ワーカーに対してローカルです。 パラメーターをより均一にシャーディングし、トレーニング中に通信と計算をオーバーラップさせることで最適化されたパフォーマンスを実現します。
次の表は、設定が異なる各モデルの詳細をまとめたものです。
| モデル | デフォルト設定 | ローラ + FSDP | LORA + FSDP なし | Int8 量子化 + LORA + FSDP なし |
| コードラマ2 7B | ローラ + FSDP | 有り | 有り | 有り |
| コードラマ2 13B | ローラ + FSDP | 有り | 有り | 有り |
| コードラマ2 34B | INT8 + LORA + FSDPなし | いいえ | いいえ | 有り |
| コードラマ2 70B | INT8 + LORA + FSDPなし | いいえ | いいえ | 有り |
Llama モデルの微調整は、以下によって提供されるスクリプトに基づいています。 GitHubレポ.
トレーニング用にサポートされているハイパーパラメータ
Code Llama 2 の微調整では、多数のハイパーパラメーターがサポートされており、それぞれが微調整されたモデルのメモリ要件、トレーニング速度、パフォーマンスに影響を与える可能性があります。
- 時代 – 微調整アルゴリズムがトレーニング データセットを通過するパスの数。 1 より大きい整数である必要があります。デフォルトは 5 です。
- Learning_rate – トレーニング例の各バッチを処理した後にモデルの重みが更新される速度。 0 より大きい正の浮動小数点数でなければなりません。デフォルトは 1e-4 です。
- 命令調整済み – モデルを命令トレーニングするかどうか。でなければなりません
TrueorFalse。 デフォルトはFalse. - per_device_train_batch_size – トレーニングの GPU コア/CPU ごとのバッチ サイズ。 正の整数である必要があります。 デフォルトは 4 です。
- per_device_eval_batch_size – 評価用の GPU コア/CPU ごとのバッチ サイズ。 正の整数である必要があります。 デフォルトは 1 です。
- max_train_samples – デバッグ目的またはより迅速なトレーニングの場合は、トレーニング サンプルの数をこの値に切り捨てます。 値 -1 は、すべてのトレーニング サンプルを使用することを意味します。 正の整数または -1 である必要があります。 デフォルトは -1 です。
- max_val_samples – デバッグ目的または迅速なトレーニングのために、検証サンプルの数をこの値に切り捨てます。 値 -1 は、すべての検証サンプルを使用することを意味します。 正の整数または -1 である必要があります。 デフォルトは -1 です。
- max_input_length – トークン化後の入力シーケンスの最大合計長。 これより長いシーケンスは切り捨てられます。 -1 の場合、
max_input_length最小値の 1024 とトークナイザーによって定義された最大モデル長に設定されます。 正の値に設定すると、max_input_lengthは指定された値の最小値に設定され、model_max_lengthトークナイザーによって定義されます。 正の整数または -1 である必要があります。 デフォルトは -1 です。 - validation_split_ratio – 検証チャネルが
none、トレイン データから分割されたトレイン検証の比率は 0 ~ 1 の間である必要があります。デフォルトは 0.2 です。 - train_data_split_seed – 検証データが存在しない場合、入力トレーニング データがアルゴリズムで使用されるトレーニング データと検証データにランダムに分割されることが修正されます。 整数である必要があります。 デフォルトは 0 です。
- preprocessing_num_workers – 前処理に使用するプロセスの数。 もし
None、メインプロセスは前処理に使用されます。 デフォルトはNone. - ロラ_r – Lora R. 正の整数である必要があります。 デフォルトは 8 です。
- lora_alpha – ローラ・アルファ。 正の整数である必要があります。 デフォルトは32です
- lora_dropout – ローラ・ドロップアウト。 0 から 1 までの正の浮動小数点数でなければなりません。デフォルトは 0.05 です。
- int8_quantization - もし
True、モデルはトレーニングのために 8 ビット精度でロードされます。 7B と 13B のデフォルトは次のとおりです。False。 70BのデフォルトはTrue. - イネーブル_fsdp – True の場合、トレーニングでは FSDP が使用されます。 7B および 13B のデフォルトは True です。 70B のデフォルトは False です。ご了承ください
int8_quantizationFSDP ではサポートされていません。
ハイパーパラメータを選択するときは、次の点を考慮してください。
- 設定
int8_quantization=Trueメモリ要件が軽減され、トレーニングの高速化につながります。 - 減少
per_device_train_batch_size&max_input_lengthメモリ要件が軽減されるため、より小さなインスタンスで実行できます。 ただし、非常に低い値を設定すると、トレーニング時間が長くなる可能性があります。 - Int8 量子化を使用していない場合 (
int8_quantization=False)、FSDP を使用します (enable_fsdp=True) より迅速かつ効率的なトレーニングを実現します。
トレーニングでサポートされているインスタンス タイプ
次の表は、さまざまなモデルのトレーニングでサポートされているインスタンス タイプをまとめたものです。
| モデル | デフォルトのインスタンスタイプ | サポートされているインスタンスの種類 |
| コードラマ2 7B | ml.g5.12xラージ |
ml.g5.12xlarge、 ml.g5.24xlarge、 ml.g5.48xlarge、 ml.p3dn.24xlarge、 ml.g4dn.12xlarge |
| コードラマ2 13B | ml.g5.12xラージ |
ml.g5.24xlarge、 ml.g5.48xlarge、 ml.p3dn.24xlarge、 ml.g4dn.12xlarge |
| コードラマ2 70B | ml.g5.48xラージ |
ml.g5.48xラージ ml.p4d.24xlarge |
インスタンス タイプを選択するときは、次の点を考慮してください。
- G5 インスタンスは、サポートされているインスタンス タイプの中で最も効率的なトレーニングを提供します。 したがって、利用可能な G5 インスタンスがある場合は、それを使用する必要があります。
- トレーニング時間は、GPU の数と利用可能な CUDA メモリの量に大きく依存します。 したがって、同じ数の GPU を持つインスタンス (ml.g5.2xlarge と ml.g5.4xlarge など) でのトレーニングはほぼ同じになります。 したがって、トレーニングには安価なインスタンス (ml.g5.2xlarge) を使用できます。
- p3 インスタンスを使用する場合、これらのインスタンスでは bfloat32 がサポートされていないため、トレーニングは 16 ビット精度で実行されます。 したがって、p3 インスタンスでトレーニングする場合、トレーニング ジョブは g5 インスタンスと比較して XNUMX 倍の CUDA メモリを消費します。
インスタンスごとのトレーニングのコストについては、以下を参照してください。 Amazon EC2 G5インスタンス.
評価
評価は、微調整されたモデルのパフォーマンスを評価するための重要なステップです。微調整されていないモデルに対する微調整されたモデルの改善を示すために、定性的評価と定量的評価の両方を提示します。定性的評価では、微調整されたモデルと微調整されていないモデルの両方からの応答例を示します。定量的な評価では、 HumanEvalは、正しく正確な結果を生成する能力をテストするための Python コードを生成するために OpenAI によって開発されたテスト スイートです。 HumanEval リポジトリは MIT ライセンスの下にあります。すべての Code LIama モデルの Python バリアントをさまざまなサイズにわたって微調整しました (Code LIama Python 7B、13B、34B、および 70B)。 Dolphin Coder データセット)を評価し、次のセクションで評価結果を示します。
定性的評価
微調整されたモデルをデプロイしたら、エンドポイントを使用してコードを生成できるようになります。次の例では、ベースおよび微調整された Code LIama 34B Python バリアントの両方からのテスト サンプルの応答を示します。 Dolphin Coder データセット:
微調整された Code Llama モデルは、前述のクエリのコードを提供することに加えて、アプローチの詳細な説明と疑似コードを生成します。
コード Llama 34b Python の未調整の応答:
コード Llama 34B Python の微調整された応答
グラウンドトゥルース
興味深いことに、Code Llama 34B Python の微調整バージョンは、最も長い回文部分文字列に対する動的プログラミング ベースのソリューションを提供します。これは、選択したテスト例のグラウンド トゥルースで提供されるソリューションとは異なります。私たちの微調整されたモデルは、動的プログラミングベースのソリューションを理由付けし、詳細に説明します。一方、微調整されていないモデルは、調整直後に潜在的な出力を幻覚します。 print ステートメント (左側のセルに表示) の出力 axyzzyx は、指定された文字列内の最長の回文ではありません。時間の複雑さの点では、動的プログラミング ソリューションは通常、最初のアプローチよりも優れています。動的計画法ソリューションの時間計算量は O(n^2) です。ここで、n は入力文字列の長さです。これは、同じく O(n^2) の二次時間計算量を持ちましたが、あまり最適化されていないアプローチを使用した、微調整されていないモデルからの最初の解よりも効率的です。
これは期待できそうです! Code LIama Python バリアントの 10% のみを微調整したことを思い出してください。 Dolphin Coder データセット。他にも探索すべきことがたくさんあります。
応答には徹底的な指示がありましたが、ソリューションで提供された Python コードが正しいかどうかを調べる必要があります。次に、と呼ばれる評価フレームワークを使用します。 人間の評価 コード LIama から生成された応答に対して統合テストを実行し、その品質を体系的に検査します。
HumanEvalによる定量評価
HumanEval は、論文で説明されているように、Python ベースのコーディング問題に対する LLM の問題解決能力を評価するための評価ハーネスです。 コード上でトレーニングされた大規模な言語モデルの評価。具体的には、関数シグネチャ、docstring、本体、単体テストなどの提供された情報に基づいてコードを生成する言語モデルの能力を評価する 164 個のオリジナルの Python ベースのプログラミング問題で構成されています。
Python ベースのプログラミングの質問ごとに、SageMaker エンドポイントにデプロイされた Code LIama モデルに質問を送信して、k 個の回答を取得します。次に、HumanEval リポジトリ内の統合テストで k 個の応答をそれぞれ実行します。 k 個の応答のうちいずれかの応答が統合テストに合格した場合、そのテスト ケースは成功したとみなします。それ以外の場合は失敗します。そして、このプロセスを繰り返して、成功したケースの割合を最終的な評価スコアとして計算します。 pass@k。標準的な実践に従って、評価では k を 1 に設定し、質問ごとに XNUMX つの応答のみを生成し、それが統合テストに合格するかどうかをテストします。
以下はHumanEvalリポジトリを利用するサンプルコードです。 SageMaker エンドポイントを使用してデータセットにアクセスし、単一の応答を生成できます。詳細については、「」のノートを参照してください。 GitHubリポジトリ.
次の表は、さまざまなモデル サイズにおける、微調整された Code LIama Python モデルの非微調整モデルに対する改善点を示しています。正確性を確保するために、微調整されていない Code LIama モデルも SageMaker エンドポイントにデプロイし、Human Eval 評価を実行します。の パス@1 数値 (次の表の最初の行) は、レポートで報告された数値と一致します。 コードラマの研究論文。 推論パラメータは一貫して次のように設定されます。 "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
結果からわかるように、微調整されたすべての Code LIama Python バリアントは、微調整されていないモデルと比べて大幅な改善を示しています。特に、Code LIama Python 70B は、微調整されていないモデルよりも約 12% 優れています。
| . | 7B パイソン | 13B パイソン | 34B | 34B パイソン | 70B パイソン |
| 事前トレーニング済みモデルのパフォーマンス (pass@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| 微調整されたモデルのパフォーマンス (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
これで、独自のデータセットで Code LIama モデルの微調整を試すことができます。
クリーンアップ
SageMaker エンドポイントを実行し続けたくない場合は、次を使用して削除できます。 AWS SDK for Python(Boto3), AWSコマンドラインインターフェイス (AWS CLI)、または SageMaker コンソール。詳細については、「」を参照してください。 エンドポイントとリソースの削除. さらに、次のことができます。 SageMaker Studio リソースをシャットダウンします。 それはもう必要ありません。
まとめ
この投稿では、SageMaker JumpStart を使用した Meta の Code Llama 2 モデルの微調整について説明しました。 SageMaker Studio の SageMaker JumpStart コンソールまたは SageMaker Python SDK を使用して、これらのモデルを微調整してデプロイできることを示しました。また、微調整手法、インスタンス タイプ、サポートされているハイパーパラメータについても説明しました。さらに、実施したさまざまなテストに基づいて、トレーニングを最適化するための推奨事項について概説しました。 XNUMX つのデータセットに対して XNUMX つのモデルを微調整した結果からわかるように、微調整を行うと、微調整を行わないモデルと比較して要約が向上します。次のステップとして、GitHub リポジトリで提供されているコードを使用して独自のデータセットでこれらのモデルを微調整して、ユースケースの結果をテストおよびベンチマークすることができます。
著者について
 XinHuang博士 Amazon SageMaker JumpStart および Amazon SageMaker 組み込みアルゴリズムの上級応用科学者です。 スケーラブルな機械学習アルゴリズムの開発に注力しています。 彼の研究対象は、自然言語処理、表形式データの説明可能なディープ ラーニング、およびノンパラメトリック時空クラスタリングの堅牢な分析の分野です。 彼は、ACL、ICDM、KDD カンファレンス、Royal Statistical Society: Series A で多くの論文を発表しています。
XinHuang博士 Amazon SageMaker JumpStart および Amazon SageMaker 組み込みアルゴリズムの上級応用科学者です。 スケーラブルな機械学習アルゴリズムの開発に注力しています。 彼の研究対象は、自然言語処理、表形式データの説明可能なディープ ラーニング、およびノンパラメトリック時空クラスタリングの堅牢な分析の分野です。 彼は、ACL、ICDM、KDD カンファレンス、Royal Statistical Society: Series A で多くの論文を発表しています。
 ヴィシャール・ヤラマンチャリ は、初期段階の生成 AI、ロボット工学、自動運転車の企業と協力するスタートアップ ソリューション アーキテクトです。 Vishaal は顧客と協力して最先端の ML ソリューションを提供しており、個人的には強化学習、LLM 評価、コード生成に興味を持っています。 AWS に入社する前は、Vishaal は UCI の学部生で、バイオインフォマティクスとインテリジェント システムに重点を置いていました。
ヴィシャール・ヤラマンチャリ は、初期段階の生成 AI、ロボット工学、自動運転車の企業と協力するスタートアップ ソリューション アーキテクトです。 Vishaal は顧客と協力して最先端の ML ソリューションを提供しており、個人的には強化学習、LLM 評価、コード生成に興味を持っています。 AWS に入社する前は、Vishaal は UCI の学部生で、バイオインフォマティクスとインテリジェント システムに重点を置いていました。
 ミーナクシスンダラム・タンダヴァラヤン AI/ML スペシャリストとして AWS で働いています。人間中心のデータと分析エクスペリエンスを設計、作成、促進することに情熱を持っています。 Meena は、AWS の戦略的顧客に目に見える競争上の利点を提供する持続可能なシステムの開発に重点を置いています。 Meena はコネクターおよびデザイン思考者であり、イノベーション、インキュベーション、民主化を通じて企業を新しい働き方に導くよう努めています。
ミーナクシスンダラム・タンダヴァラヤン AI/ML スペシャリストとして AWS で働いています。人間中心のデータと分析エクスペリエンスを設計、作成、促進することに情熱を持っています。 Meena は、AWS の戦略的顧客に目に見える競争上の利点を提供する持続可能なシステムの開発に重点を置いています。 Meena はコネクターおよびデザイン思考者であり、イノベーション、インキュベーション、民主化を通じて企業を新しい働き方に導くよう努めています。
 アシッシュ・ケタン博士 は、Amazon SageMaker 組み込みアルゴリズムを使用する上級応用科学者であり、機械学習アルゴリズムの開発を支援しています。 イリノイ大学アーバナシャンペーン校で博士号を取得。 彼は機械学習と統計的推論の活発な研究者であり、NeurIPS、ICML、ICLR、JMLR、ACL、および EMNLP カンファレンスで多くの論文を発表しています。
アシッシュ・ケタン博士 は、Amazon SageMaker 組み込みアルゴリズムを使用する上級応用科学者であり、機械学習アルゴリズムの開発を支援しています。 イリノイ大学アーバナシャンペーン校で博士号を取得。 彼は機械学習と統計的推論の活発な研究者であり、NeurIPS、ICML、ICLR、JMLR、ACL、および EMNLP カンファレンスで多くの論文を発表しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

