概要
今日のデジタル環境では、金融サービス、オンライン マーケットプレイス、およびユーザーの身元確認を必要とするその他の分野で活動する企業にとって、顧客確認 (KYC) 規制を順守することが最も重要です。従来、KYC プロセスは手動の文書検証に依存していましたが、これは時間がかかり、エラーが発生しやすいアプローチです。このガイドでは、顔認識と分析に特化した AWS の強力なクラウドベース AI サービスである Amazon Rekognition がオンライン KYC 戦略にどのように変革をもたらし、合理化され、安全で、コスト効率の高いプロセスに変革できるかを詳しく説明します。

学習目標
- さまざまな業界における顧客確認 (KYC) 規制の重要性と、手動検証プロセスに関連する課題を理解します。
- 顔認識と分析に特化したクラウドベースの AI サービスとしての Amazon Rekognition の機能を調べてください。
- ユーザーのオンボーディングなど、Amazon Rekognition を使用した ID 検証の実装に必要な手順を学びます。 テキスト抽出、生体検出、顔分析、顔照合。
- セキュリティ対策の強化、ユーザー認証プロセスの合理化、ユーザー エクスペリエンスの向上のために、AI を活用した本人確認を活用する重要性を理解します。
この記事は、の一部として公開されました データサイエンスブログ。
目次
KYCの課題を理解する
KYC 規制により、企業はユーザーの身元を確認することが義務付けられています。 詐欺を軽減する、マネーロンダリング、その他の金融犯罪。この検証には通常、政府発行の身分証明書の収集と検証が含まれます。これらの規制は安全な金融エコシステムを維持するために不可欠ですが、手動による検証プロセスでは次のような課題が生じます。
- パンデミックの影響: パンデミック中、金融セクターは移動が制限されていたため、新規顧客のオンボーディングにおいて大きな課題に直面しました。したがって、手動で一括検証することはできません。したがって、オンライン KYC を実装することで、ビジネスはそのような将来のイベントに備えることができます。
- ヒューマンエラー: 手動による検証ではエラーが発生しやすく、不正な登録がすり抜けてしまう可能性があります。
- IDの管理: ドキュメントは印刷されたコピーであるため、その管理はますます困難になっています。コピーは紛失、焼失、盗難、悪用などの可能性があります。
Amazon Rekognition とは何ですか?
Amazon Rekognition は、アマゾン ウェブ サービス (AWS) が提供する強力な画像およびビデオ分析サービスです。高度な機械学習アルゴリズムを利用して画像やビデオの視覚コンテンツを分析し、開発者が貴重な洞察を抽出し、物体検出、顔認識、本人確認などのさまざまなタスクを実行できるようにします。以下の単純化した図は、関連する機能とサービスをよく示しています。
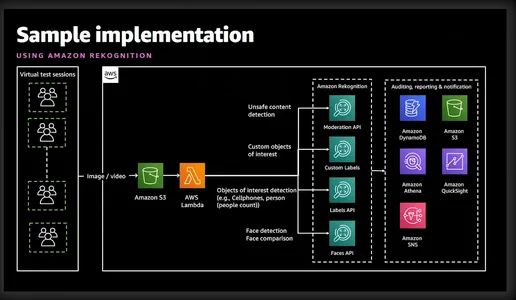
Amazon Rekognition による本人確認
実装について説明する前に、オンライン KYC の本人確認の実装に関する概要と手順について説明します。
- ユーザーのオンボーディング: このプロセスはビジネスに固有のものになります。ただし、少なくとも、名、ミドルネーム、姓、生年月日、ID カードの有効期限、パスポート サイズの写真が必要です。この情報はすべて、ユーザーに国民 ID カードの画像をアップロードするよう依頼することで収集できます。
- テキストの抽出: AWS Textract サービスは、アップロードされた ID カードから上記の情報をすべて正確に抽出できます。これだけでなく、Textract にクエリを実行して ID カードから特定の情報を取得することもできます。
- ライブネスと顔認識: KYC を行おうとしているユーザーが画面上でアクティブであり、ライブネス セッションの開始時にライブであることを確認するため。 Amazon Rekognition は、画像またはビデオ ストリーム内の顔を正確に検出して比較できます。
- 顔の分析: 顔をキャプチャすると、年齢、性別、感情、顔のランドマークなどの顔の属性に関する詳細な洞察が得られます。これだけでなく、ユーザーがサングラスをかけているかどうか、または顔が他の物体で覆われているかどうかも検証されます。
- 顔のマッチング: Liveness を検証した後、国民 ID カードから抽出された参照画像と Liveness セッションからの現在の画像に基づいて顔照合を実行して個人の身元を確認できます。
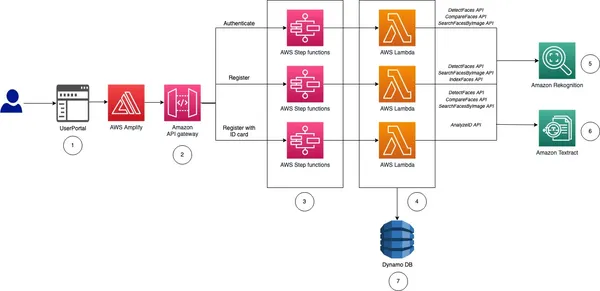
ご覧のとおり、Rekognition はキャプチャした自撮り写真を分析し、ユーザーがアップロードした政府発行の ID と比較することで、迅速なユーザー登録を促進します。 Rekognition 内の生存検出機能は、ユーザーに瞬きや頭を回すなどの特定のアクションの実行を促すことで、なりすましの試みを阻止するのに役立ちます。これにより、登録しているユーザーが本物の人物であり、巧妙に偽装された写真やディープフェイクではないことが保証されます。この自動化されたプロセスにより、オンボーディング時間が大幅に短縮され、ユーザー エクスペリエンスが向上します。 Rekognition は、手動検証に固有の人的エラーの可能性を排除します。さらに、顔認識アルゴリズムは高い精度を達成し、信頼性の高い本人確認を保証します。
実際に動作するのを見てとても興奮していると思いますので、すぐに始めましょう。
本人確認の実装: 自動 KYC ソリューション
ステップ 1: AWS アカウントのセットアップ
開始する前に、アクティブな AWS アカウントがあることを確認してください。まだサインアップしていない場合は、AWS ウェブサイトで AWS アカウントにサインアップできます。サインアップしたら、Rekognition サービスをアクティブ化します。 AWS は、このプロセスを容易にするための包括的なドキュメントとチュートリアルを提供します。
ステップ 2: IAM 権限を設定する
Python または AWS CLI を使用する場合は、この手順が必要です。 Rekognition、S3、Textract へのアクセス許可を与える必要があります。これはコンソールから実行できます。
ステップ 3: ユーザーの国民 ID をアップロードする
CLI、Python、グラフィカル インターフェイスを使用してこれを説明します。グラフィカルインターフェイスのコードをお探しの場合は、AWS に素晴らしいコードがアップロードされています。 git の例。この記事では、グラフィカル インターフェイスを表示するために同じコードをデプロイしました。
aws textract analyze-id --document-pages
'{"S3Object":{"Bucket":"bucketARN","Name":"id.jpg"}}'"IdentityDocuments": [
{
"DocumentIndex": 1,
"IdentityDocumentFields": [
{
"Type": {
"Text": "FIRST_NAME"
},
"ValueDetection": {
"Text": "xyz",
"Confidence": 93.61839294433594
}
},
{
"Type": {
"Text": "LAST_NAME"
},
"ValueDetection": {
"Text": "abc",
"Confidence": 96.3537826538086
}
},
{
"Type": {
"Text": "MIDDLE_NAME"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.16631317138672
}
},
{
"Type": {
"Text": "SUFFIX"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.16964721679688
}
},
{
"Type": {
"Text": "CITY_IN_ADDRESS"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.17261505126953
}
},
{
"Type": {
"Text": "ZIP_CODE_IN_ADDRESS"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.17854309082031
}
},
{
"Type": {
"Text": "STATE_IN_ADDRESS"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.15782165527344
}
},
{
"Type": {
"Text": "STATE_NAME"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.16664123535156
}
},
{
"Type": {
"Text": "DOCUMENT_NUMBER"
},
"ValueDetection": {
"Text": "123456",
"Confidence": 95.29527282714844
}
},
{
"Type": {
"Text": "EXPIRATION_DATE"
},
"ValueDetection": {
"Text": "22 OCT 2024",
"NormalizedValue": {
"Value": "2024-10-22T00:00:00",
"ValueType": "Date"
},
"Confidence": 95.7198486328125
}
},
{
"Type": {
"Text": "DATE_OF_BIRTH"
},
"ValueDetection": {
"Text": "1 SEP 1994",
"NormalizedValue": {
"Value": "1994-09-01T00:00:00",
"ValueType": "Date"
},
"Confidence": 97.41930389404297
}
},
{
"Type": {
"Text": "DATE_OF_ISSUE"
},
"ValueDetection": {
"Text": "23 OCT 2004",
"NormalizedValue": {
"Value": "2004-10-23T00:00:00",
"ValueType": "Date"
},
"Confidence": 96.1384506225586
}
},
{
"Type": {
"Text": "ID_TYPE"
},
"ValueDetection": {
"Text": "PASSPORT",
"Confidence": 98.65157318115234
}
}上記のコマンドは、AWS Textract Analyst-id コマンドを使用して、S3 に既にアップロードされているイメージから情報を抽出します。出力 JSON には境界ボックスも含まれているため、主要な情報のみを表示するために切り詰めています。ご覧のとおり、テキスト値の信頼レベルとともに必要な情報がすべて抽出されています。
Python 関数の使用
textract_client = boto3.client('textract', region_name='us-east-1')
def analyze_id(document_file_name)->dict:
if document_file_name is not None:
with open(document_file_name, "rb") as document_file:
idcard_bytes = document_file.read()
'''
Analyze the image using Amazon Textract.
'''
try:
response = textract_client.analyze_id(
DocumentPages=[
{'Bytes': idcard_bytes},
])
return response
except textract_client.exceptions.UnsupportedDocumentException:
logger.error('User %s provided an invalid document.' % inputRequest.user_id)
raise InvalidImageError('UnsupportedDocument')
except textract_client.exceptions.DocumentTooLargeException:
logger.error('User %s provided document too large.' % inputRequest.user_id)
raise InvalidImageError('DocumentTooLarge')
except textract_client.exceptions.ProvisionedThroughputExceededException:
logger.error('Textract throughput exceeded.')
raise InvalidImageError('ProvisionedThroughputExceeded')
except textract_client.exceptions.ThrottlingException:
logger.error('Textract throughput exceeded.')
raise InvalidImageError('ThrottlingException')
except textract_client.exceptions.InternalServerError:
logger.error('Textract Internal Server Error.')
raise InvalidImageError('ProvisionedThroughputExceeded')
result = analyze_id('id.jpeg')
print(result) # print raw outputグラフィカルインターフェイスの使用
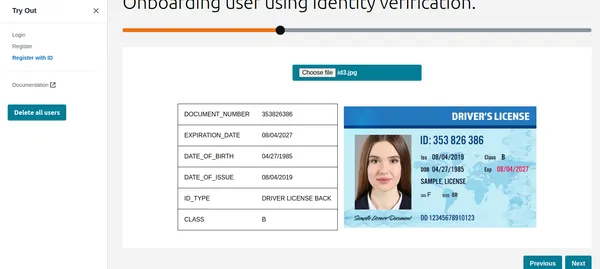

ご覧のとおり、Textract はすべての関連情報を取得し、ID タイプも表示します。この情報は、顧客またはユーザーを登録するために使用できます。しかしその前に、Liveness チェックを実行して、それが本物の人物であることを確認しましょう。
生存チェック
ユーザーが下の画像の「チェックインの開始」をクリックすると、最初に顔を検出し、画面上に顔が 1 つだけある場合は Liveness セッションを開始します。プライバシー上の理由から、Liveness セッション全体を表示することはできません。ただし、これを確認できます デモビデオのリンク。 Liveness セッションでは、信頼度 (%) で結果が提供されます。 Liveness セッションが失敗するしきい値を設定することもできます。このような重要なアプリケーションの場合、しきい値を 95% に維持する必要があります。
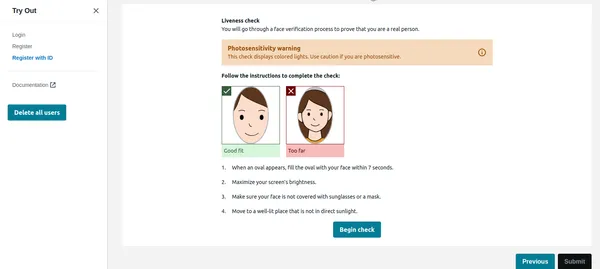
自信とは別に、Liveness セッションでは感情や顔で検出された異物も提供されます。ユーザーがサングラスをかけている場合、または怒りなどの表情をしている場合、アプリケーションは画像を拒否することができます。
Pythonコード
rek_client = boto3.client('rekognition', region_name='us-east-1')
sessionid = rek_client.create_face_liveness_session(Settings={'AuditImagesLimit':1,
'OutputConfig': {"S3Bucket": 'IMAGE_BUCKET_NAME'}})
session = rek_client.get_face_liveness_session_results(
SessionId=sessionid)
顔の比較
ユーザーが Liveness セッションを正常に完了すると、アプリケーションはその顔を ID から検出された顔と比較する必要があります。これはアプリケーションの最も重要な部分です。顔とIDが一致しないユーザーは登録したくない。アップロードされた ID から検出された顔は、参照画像として機能するコードによって S3 にすでに保存されています。同様に、liveness セッションからの顔も S3 に保存されます。まず CLI の実装を確認してみましょう。
CLI コマンド
aws rekognition compare-faces
--source-image '{"S3Object":{"Bucket":"imagebucket","Name":"reference.jpg"}}'
--target-image '{"S3Object":{"Bucket":"imagebucket","Name":"liveness.jpg"}}'
--similarity-threshold 0.9
出力
{
"UnmatchedFaces": [],
"FaceMatches": [
{
"Face": {
"BoundingBox": {
"Width": 0.12368916720151901,
"Top": 0.16007372736930847,
"Left": 0.5901257991790771,
"Height": 0.25140416622161865
},
"Confidence": 99.0,
"Pose": {
"Yaw": -3.7351467609405518,
"Roll": -0.10309021919965744,
"Pitch": 0.8637830018997192
},
"Quality": {
"Sharpness": 95.51618957519531,
"Brightness": 65.29893493652344
},
"Landmarks": [
{
"Y": 0.26721030473709106,
"X": 0.6204193830490112,
"Type": "eyeLeft"
},
{
"Y": 0.26831310987472534,
"X": 0.6776827573776245,
"Type": "eyeRight"
},
{
"Y": 0.3514654338359833,
"X": 0.6241428852081299,
"Type": "mouthLeft"
},
{
"Y": 0.35258132219314575,
"X": 0.6713621020317078,
"Type": "mouthRight"
},
{
"Y": 0.3140771687030792,
"X": 0.6428444981575012,
"Type": "nose"
}
]
},
"Similarity": 100.0
}
],
"SourceImageFace": {
"BoundingBox": {
"Width": 0.12368916720151901,
"Top": 0.16007372736930847,
"Left": 0.5901257991790771,
"Height": 0.25140416622161865
},
"Confidence": 99.0
}
}
上で見られるように、一致しない顔は存在せず、顔は 99% の信頼レベルで一致することが示されています。また、追加の出力として境界ボックスも返しました。次に、Python の実装を見てみましょう。
Pythonコード
rek_client = boto3.client('rekognition', region_name='us-east-1')
response = rek_client.compare_faces(
SimilarityThreshold=0.9,
SourceImage={
'S3Object': {
'Bucket': bucket,
'Name': idcard_name
}
},
TargetImage={
'S3Object': {
'Bucket': bucket,
'Name': name
}
})
if len(response['FaceMatches']) == 0:
IsMatch = 'False'
Reason = 'Property FaceMatches is empty.'
facenotMatch = False
for match in response['FaceMatches']:
similarity:float = match['Similarity']
if similarity > 0.9:
IsMatch = True,
Reason = 'All checks passed.'
else:
facenotMatch = True
上記のコードは、しきい値を 90% に保ちながら、ID カードと Liveness セッションから検出された顔を比較します。顔が一致すると、IsMatch 変数が True に設定されます。したがって、3 回の関数呼び出しで XNUMX つの顔を比較できます。どちらもすでに SXNUMX バケットにアップロードされています。
したがって、最後に、有効なユーザーを登録し、KYC を完了することができます。ご覧のとおり、これは完全に自動化され、ユーザーによって開始され、他の人は関与しません。このプロセスにより、現在の手動プロセスと比較してユーザーのオンボーディングも短縮されました。
ステップ 4: GPT などのドキュメントをクエリする
私が気に入ったのは、Textract の非常に便利な機能の 1 つで、「ID 番号は何ですか」などの具体的な質問ができる点です。 AWS CLI を使用してこれを行う方法を説明します。
aws textract analyze-document --document '{"S3Object":{"Bucket":"ARN","Name":"id.jpg"}}'
--feature-types '["QUERIES"]' --queries-config '{"Queries":[{"Text":"What is the Identity No"}]}'以前はanalyze-id関数を使用していましたが、現在はanalyze-documentを使用してドキュメントをクエリしていることに注意してください。これは、analyze-id 関数によって抽出されない特定のフィールドが ID カードにある場合に非常に便利です。 analyze-id 関数はすべての米国の ID カードで適切に機能しますが、インド政府の ID カードでも同様に機能します。ただし、一部のフィールドが抽出されない場合でも、クエリ機能を使用できます。
AWS は、DynamoDB に保存されているユーザー ID、ユーザー ID、顔 ID を管理するために Cognito サービスを使用します。 AWS サンプル コードでは、同じユーザーが別の ID またはユーザー名を使用して再登録できないように、既存のデータベースの画像も比較します。この種の検証は、堅牢な自動 KYC システムには必須です。
まとめ
自動化された自己 KYC に AWS Rekognition を採用することで、ユーザーのオンボーディングプロセスを、面倒なハードルからスムーズで安全なエクスペリエンスに変えることができます。 Amazon Rekognition は、高度な顔認識機能を備えた本人確認システムを実装するための堅牢なソリューションを提供します。その機能を活用することで、開発者はセキュリティ対策を強化し、ユーザー認証プロセスを合理化し、さまざまなアプリケーションや業界にわたってシームレスなユーザー エクスペリエンスを提供できます。
上記の包括的なガイドを読めば、Amazon Rekognition を効果的に使用して ID 検証を実装する準備が整います。 AI を活用した ID 検証の力を活用し、デジタル ID 管理の領域で新たな可能性を解き放ちます。
主要な取り組み
- Amazon Rekognition は高度な顔認識および分析機能を提供し、合理化された安全な本人確認プロセスを促進します。
- 政府発行の ID カードから重要な情報を抽出し、生存性チェックを実行することで、ユーザーのオンボーディングを自動化できます。
- 実装手順には、AWS サービスのセットアップ、IAM 権限の構成、テキスト抽出と顔の比較のための Python 関数またはグラフィカル インターフェイスの利用が含まれます。
- リアルタイムの生存チェックにより、検証中にユーザーが立ち会っていることが保証されるため、セキュリティが強化されます。また、顔の比較により、参照画像と照合して ID が検証されます。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/03/how-to-implement-identity-verification-using-amazon-rekognition/

