2023 年は多忙な年でした AmazonOpenSearchサービス! OpenSearch Service が開始したリリースの詳細については、 2023の前半.
2023 年後半に、OpenSearch Service に XNUMX つの新しいサポートが追加されました。 Opensearch バージョン: 2.9 および 2.11 これら XNUMX つのバージョンでは、検索スペース、機械学習 (ML) 検索スペース、移行、およびサービスの運用面に新機能が導入されています。
ゼロ ETL 統合のリリースにより、 Amazon シンプル ストレージ サービス (Amazon S3)、Amazon S3 からデータを移動することなく、OpenSearch Service を使用してデータレイクにあるデータを分析し、ダッシュボードを構築してデータをクエリできます。
OpenSearch Service は、新しいゼロ ETL 統合も発表しました。 Amazon DynamoDB DynamoDB プラグインを介して Amazon OpenSearch の取り込み。 OpenSearch Ingestion はブートストラップを処理し、DynamoDB ソースからデータを継続的にストリーミングします。
OpenSearch Serverless は、 Amazon OpenSearch サーバーレス用のベクトル エンジン 時系列コレクションのエクスペリエンスを強化し、開発環境のコストを管理し、ワークロードの需要に合わせてリソースを迅速に拡張するための他の機能と併せて使用します。
この投稿では、検索、可観測性、セキュリティ分析、移行によってビジネスを強化する OpenSearch Service の新しいリリースについて説明します。
OpenSearch Service を使用してコスト効率の高いソリューションを構築する
Amazon S3 のゼロ ETL 統合により、OpenSearch Service でデータを適切にクエリできるようになり、ストレージのコストを節約できます。データの移動は、異なるデータ ストア間でデータをレプリケートする必要があるため、コストがかかる操作です。これにより、データ フットプリントが増加し、コストが増加します。データを移動すると、あるソースから新しい宛先にデータを移行するためのパイプラインを管理するオーバーヘッドも追加されます。
OpenSearch Service には、インフラストラクチャ コストのさらなる最適化に役立つ、データ ノードの新しいインスタンス タイプ (Im4gn および OR1) も追加されました。最大 30 TB の不揮発性メモリ (NVMe) ソリッド ステート ドライブ (SSD) を備えた Im4gn インスタンスは、高密度ストレージと優れたパフォーマンスを提供します。 OR1 インスタンスは、セグメント レプリケーションとリモート バッキング ストレージを使用して、インデックス作成の負荷が高いワークロードのスループットを大幅に向上させます。
DynamoDB から OpenSearch サービスへのゼロ ETL
2023 年 XNUMX 月に、DynamoDB と OpenSearch Ingestion は、OpenSearch Service のゼロ ETL 統合を導入しました。 OpenSearch サービス ドメインと OpenSearch サーバーレス コレクションは、DynamoDB データに対して全文検索やベクトル検索などの高度な検索機能を提供します。数回クリックするだけで、 AWSマネジメントコンソールにより、DynamoDB から OpenSearch Service にデータをシームレスにロードして同期できるようになり、データを抽出、変換、ロードするためのカスタム コードを作成する必要がなくなります。
直接クエリ (Amazon S3 データのゼロ ETL、プレビュー中)
OpenSearch Service は、運用データを分析するツールを切り替えることなく、Amazon S3 および S3 ベースのデータレイクの運用ログをクエリできる新しい方法を発表しました。以前は、OpenSearch の豊富な分析機能と視覚化機能を利用してデータを理解し、異常を特定し、潜在的な脅威を検出するには、Amazon S3 から OpenSearch Service にデータをコピーする必要がありました。
ただし、サービス間でデータを継続的にレプリケートするとコストがかかる可能性があり、運用作業が必要になります。 OpenSearch Service のダイレクト クエリ機能を使用すると、データ自体を移動することなく、Amazon S3 に保存されている操作ログ データにアクセスできます。データを移動せずに、データに対して複雑なクエリや視覚化を実行できるようになりました。
OpenSearch サービスによる Im4gn のサポート
Im4gn インスタンスは、大規模なデータセットを管理し、vCPU あたりの高いストレージ密度を必要とするワークロード向けに最適化されています。 Im4gn インスタンスには、Large から 16xlarge までのサイズがあり、NVMe SSD ディスク サイズは最大 30 TB です。 Im4gn インスタンスは上に構築されています AWSNitroシステム SSD は、最高のパフォーマンスを実現する高スループット、低遅延のディスク アクセスを提供します。 OpenSearch サービス Im4gn インスタンスは、すべての OpenSearch バージョンと Elasticsearch バージョン 7.9 以降をサポートします。詳細については、を参照してください。 Amazon OpenSearch Service でサポートされているインスタンス タイプ.
重いワークロードのインデックス作成のための OpenSearch Optimized Instance ファミリである OR1 の紹介
2023 年 XNUMX 月に OpenSearch サービスを開始 OR1、OpenSearch Optimized Instance ファミリは、内部ベンチマークで既存のインスタンスと比較して価格パフォーマンスが最大 30% 向上し、Amazon S3 を使用して 11 9 の耐久性を提供します。 OR1 インスタンスを持つドメインでは、 Amazon Elastic Blockストア (Amazon EBS) ボリュームをプライマリストレージに使用し、データが到着すると Amazon S3 に同期的にコピーされます。 OR1 インスタンスは OpenSearch を使用します セグメントレプリケーション機能 レプリカ シャードが Amazon S3 から直接データを読み取ることができるようにすることで、プライマリ シャードとレプリカ シャードの両方でインデックス作成にかかるリソース コストを回避します。 OR1 インスタンス ファミリーは、障害発生時の自動データ回復もサポートしています。 OR1 インスタンス タイプのオプションの詳細については、を参照してください。 現在世代のインスタンスタイプ OpenSearch サービス内。
セキュリティ分析機能でビジネスを可能にする
OpenSearch Service の Security Analytics プラグインは、すぐに使用できる機能をサポートしています 事前にパッケージ化されたログの種類 また、潜在的なセキュリティ インシデントを検出するためのセキュリティ検出ルール (SIGMA ルール) を提供します。
OpenSearch 2.9 では、Security Analytics プラグインに顧客ログ タイプのサポートと、 オープン サイバーセキュリティ スキーマ フレームワーク (OCSF) データ形式。この新しいサポートにより、OCSF データを保存した検出器を構築できます。 アマゾン セキュリティ レイク セキュリティの調査結果を分析し、潜在的なインシデントを軽減します。 Security Analytics プラグインには、独自のカスタム ログ タイプを作成し、カスタム検出ルールを作成する機能も追加されました。
ML を活用した検索ソリューションを構築する
2023 年、OpenSearch Service は、次世代の検索アプリケーションの構築に必要な重労働の排除に投資しました。検索パイプライン、検索プロセッサ、AI/ML コネクタなどの機能を備えた OpenSearch Service により、ニューラル検索、ハイブリッド検索、パーソナライズされた結果を活用した検索アプリケーションの迅速な開発が可能になりました。さらに、kNN プラグインの機能強化により、ベクトル データの保存と取得が改善されました。 OpenSearch Service 用に新しくリリースされたオプションのプラグインにより、追加の言語アナライザーとのシームレスな統合が可能になり、 Amazonパーソナライズ.
検索パイプライン
検索パイプライン 検索クエリを強化し、検索結果を改善する新しい方法を提供します。検索パイプラインを定義し、そこにクエリを送信します。検索パイプラインを定義するときに、次のように指定します。 プロセッサ クエリを変換および拡張し、結果を再ランク付けします。事前構築されたクエリ プロセッサには、日付変換、集計、文字列操作、データ型変換が含まれます。検索パイプラインの結果プロセッサは、次のフェーズにレンダリングする前に、結果をその場でインターセプトして適応させます。パイプラインの要求処理と応答処理は両方ともコーディネーター ノードで実行されるため、シャード レベルの処理はありません。
オプションのプラグイン
OpenSearch Service を使用すると、プレインストールされたサービスを関連付けることができます オプションの OpenSearch プラグイン ドメインで使用します。オプションのプラグイン パッケージは、特定の OpenSearch バージョンと互換性があり、そのバージョンのドメインにのみ関連付けることができます。利用可能なプラグインは、 パッケージ OpenSearch サービス コンソールのページ。オプションのプラグインには、OpenSearch Service を Amazon Personalize と統合する Amazon Personalize プラグインと、Nori、Sudachi、STConvert、Pinyin などの新しい言語アナライザーが含まれます。
新しい言語アナライザーのサポート
OpenSearch Service は 4 つの新しいサポートを追加しました 言語アナライザープラグイン: ノリ (韓国語)、スダチ (日本語)、ピンイン (中国語)、STConvert 分析 (中国語)。これらは、OpenSearch バージョンを実行しているドメインに関連付けることができるオプションのプラグインとして、すべての AWS リージョンで利用できます。使用できます パッケージ OpenSearch Service コンソールのページにアクセスして、これらのプラグインをドメインに関連付けるか、Associate Package API を使用します。
ニューラル検索機能
神経検索 は、OpenSearch Service バージョン 2.9 以降で一般的に利用可能です。ニューラル検索を使用すると、モデル提供フレームワークを使用してリモートでホストされている ML モデルと統合できます。検索中にニューラル クエリを使用すると、ニューラル検索はクエリ テキストをベクトル エンベディングに変換し、ベクトル検索を使用してクエリとドキュメント エンベディングを比較し、最も近い結果を返します。取り込み中に、ニューラル検索はドキュメント テキストをベクトル埋め込みに変換し、テキストとそのベクトル埋め込みの両方をベクトル インデックスにインデックス付けします。
Amazon Personalize との統合
OpenSearch Service では、OpenSearch バージョン 2.9 以降で Amazon Personalize と統合するためのオプションのプラグインが導入されました。 Amazon Personalize 検索ランキング用の OpenSearch Service プラグインを使用すると、Amazon Personalize が提供するディープラーニング機能を利用して、ウェブサイトおよびアプリケーション検索からのエンドユーザーエンゲージメントとコンバージョンを向上させることができます。オプションのプラグインとして、 パッケージは OpenSearch バージョン 2.9 以降と互換性がありますであり、そのバージョンのドメインにのみ関連付けることができます。
OpenSearch の k-NN FAISS による効率的なクエリ フィルタリング
OpenSearch サービスは、バージョン 2.9 以降で OpenSearch の k-NN FAISS を使用した効率的なクエリ フィルタリングを導入しました。オープンサーチの 効率的なベクトルクエリフィルター この機能は、最適なフィルタリング戦略 (近似最近傍 (ANN) による事前フィルタリングまたは正確な k 近傍 (k-NN) によるフィルタリング) をインテリジェントに評価し、正確で低遅延のベクトル検索クエリを提供するための最適な戦略を決定します。以前の OpenSearch バージョンでは、FAISS エンジンのベクトル クエリはポスト フィルタリング手法を使用していました。これにより、大規模なフィルタリングされたクエリが可能になりましたが、要求された「k」数よりも少ない結果が返される可能性がありました。効率的なベクトルクエリフィルター 低遅延で正確な結果を提供しますにより、ベクトル手法と語彙手法にわたるハイブリッド検索を使用できるようになります。
OpenSearch サービスのバイト量子化ベクトル
newで バイト量子化ベクトル 2.9 で導入されたこの機能により、品質 (リコール) の低下を最小限に抑えながら、メモリ要件を 4 分の 32 に削減し、検索遅延を大幅に短縮できます。この機能を使用すると、ベクトルに使用される通常の 8 ビット浮動小数点が量子化されるか、32 ビットの符号付き整数に変換されます。多くのアプリケーションでは、既存の浮動小数点ベクトル データを品質をほとんど損なうことなく量子化できます。ベンチマークを比較すると、XNUMX ビット浮動小数点ではなくバイト ベクトルを使用すると、ストレージとメモリの使用量が大幅に削減され、同時にインデックス作成のスループットが向上し、クエリの待ち時間が短縮されることがわかります。内部 ベンチマーク ストレージ使用量が最大 78% 削減され、RAM 使用量が最大 59% 削減されたことが示されました (glove-200-angular データセットの場合)。角度データセットの再現率値は、ユークリッド データセットの再現率値よりも低かった。
AI/ML コネクタ
OpenSearch 2.9 以降をサポート ML モデルとの統合 AWS のサービスまたはサードパーティのプラットフォームでホストされます。これにより、システム管理者やデータ サイエンティストは、OpenSearch Service ドメインの外部で ML ワークロードを実行できるようになります。 ML コネクタには、サポートされている ML ブループリントのセットが付属しています。これは、API リクエストを特定のコネクタに送信するときに指定する必要があるパラメータのセットを定義するテンプレートです。 OpenSearch Service は、次のようないくつかのプラットフォーム用のコネクタを提供します。 アマゾンセージメーカー、 アマゾンの岩盤, OpenAI チャット GPT, 密着。
OpenSearch Service コンソールの統合
OpenSearch 2.9 以降では、コンソールに新しい統合機能が追加されました。統合により提供されるのは、 AWS CloudFormation を構築するためのテンプレート セマンティック検索 SageMaker または Amazon Bedrock でホストされている ML モデルに接続することによるユースケース。 CloudFormation テンプレートはモデル エンドポイントを生成し、テンプレートへの入力として指定した OpenSearch Service ドメインにモデル ID を登録します。
ハイブリッド検索と範囲正規化
正規化プロセッサ & ハイブリッドクエリ 2023 年初めにリリースされた XNUMX つの機能をベースに構築されています—神経検索 & 検索パイプライン。語彙クエリと意味クエリはさまざまなスケールで関連性スコアを返すため、ハイブリッド検索クエリを微調整するのは困難でした。
OpenSearch Service 2.11 は、ハイブリッド検索の組み合わせおよび正規化プロセッサをサポートするようになりました。字句検索クエリと自然言語ベースの k-NN ベクトル検索クエリを組み合わせたハイブリッド検索クエリを実行できるようになりました。 OpenSearch Service では、複数のスコアリングの組み合わせと正規化手法を使用して、ハイブリッド検索結果の関連性を最大限に高めることもできます。
Amazon Bedrock を使用したマルチモーダル検索
OpenSearch Service 2.11 は、マルチモーダル埋め込みモデルを使用してテキストおよび画像データを検索できるようにするマルチモーダル検索のサポートを開始します。ベクトル埋め込みを生成するには、 text_image_embedding プロセッサ、ドキュメント フィールド内のテキストまたは画像のバイナリをベクトル埋め込みに変換します。ニューラル クエリ句は、 k-NN プラグイン API or DSL のクエリ クエリ。テキスト検索と画像検索を組み合わせて実行します。新しい OpenSearch Service 統合機能を使用すると、マルチモーダル検索をすぐに開始できます。
ニューラルスパース検索
セマンティック検索の新しい効率的な方法であるニューラル スパース検索は、OpenSearch Service 2.11 で利用可能です。ニューラル スパース検索は、バイエンコーダーとドキュメントのみの 10.4 つのモードで動作します。バイエンコーダー モードでは、ドキュメントと検索クエリの両方がディープ エンコーダーを通過します。ドキュメントのみモードでは、ドキュメントのみがディープ エンコーダーを通過し、検索クエリはトークン化されます。ドキュメント専用のスパース エンコーダーは、デンス エンコーディング インデックスのサイズの 7.2% のインデックスを生成します。バイエンコーダーの場合、インデックス サイズは、高密度エンコード インデックスのサイズの XNUMX% です。ニューラル スパース検索は、スパース ベクトル埋め込みを作成するスパース エンコーディング モデルによって有効になります。 <token: weight> テキストエントリとスパースベクトル内の対応する重みを表すペア。スパース ニューラル検索用の事前トレーニング済みモデルの詳細については、を参照してください。 スパースエンコーディングモデル.
ニューラル スパース検索はコストを削減し、検索の関連性を向上させ、待ち時間を短縮します。新しい OpenSearch Service 統合機能を使用すると、ニューラル スパース検索をすぐに開始できます。
OpenSearch インジェストの更新
OpenSearch インジェスト は、データを OpenSearch サービス ドメインおよび OpenSearch サーバーレス コレクションに配信する、フルマネージドで自動スケールされた取り込みパイプラインです。 2023 年のリリース以来、OpenSearch Ingestion はデータの変換と移動を簡単にする新機能を追加し続けています。 サポートされているソース OpenSearch Service、OpenSearch Serverless、Amazon S3 などのダウンストリームの宛先に。
OpenSearch インジェストの新しい移行機能
2023 年 7 月、OpenSearch Ingestion は、自己管理型 Elasticsearch バージョン XNUMX.x ドメインから OpenSearch Service の最新バージョンへのデータ移行をサポートする新機能のリリースを発表しました。
OpenSearch インジェストは、OpenSearch バージョン 2.x を実行している OpenSearch Service 管理ドメインから OpenSearch サーバーレス コレクションへのデータの移行もサポートしています。
OpenSearch インジェストを使用して次のことを行う方法を学びます。 データを OpenSearch サービスに移行する.

OpenSearch インジェストによるデータ耐久性の向上
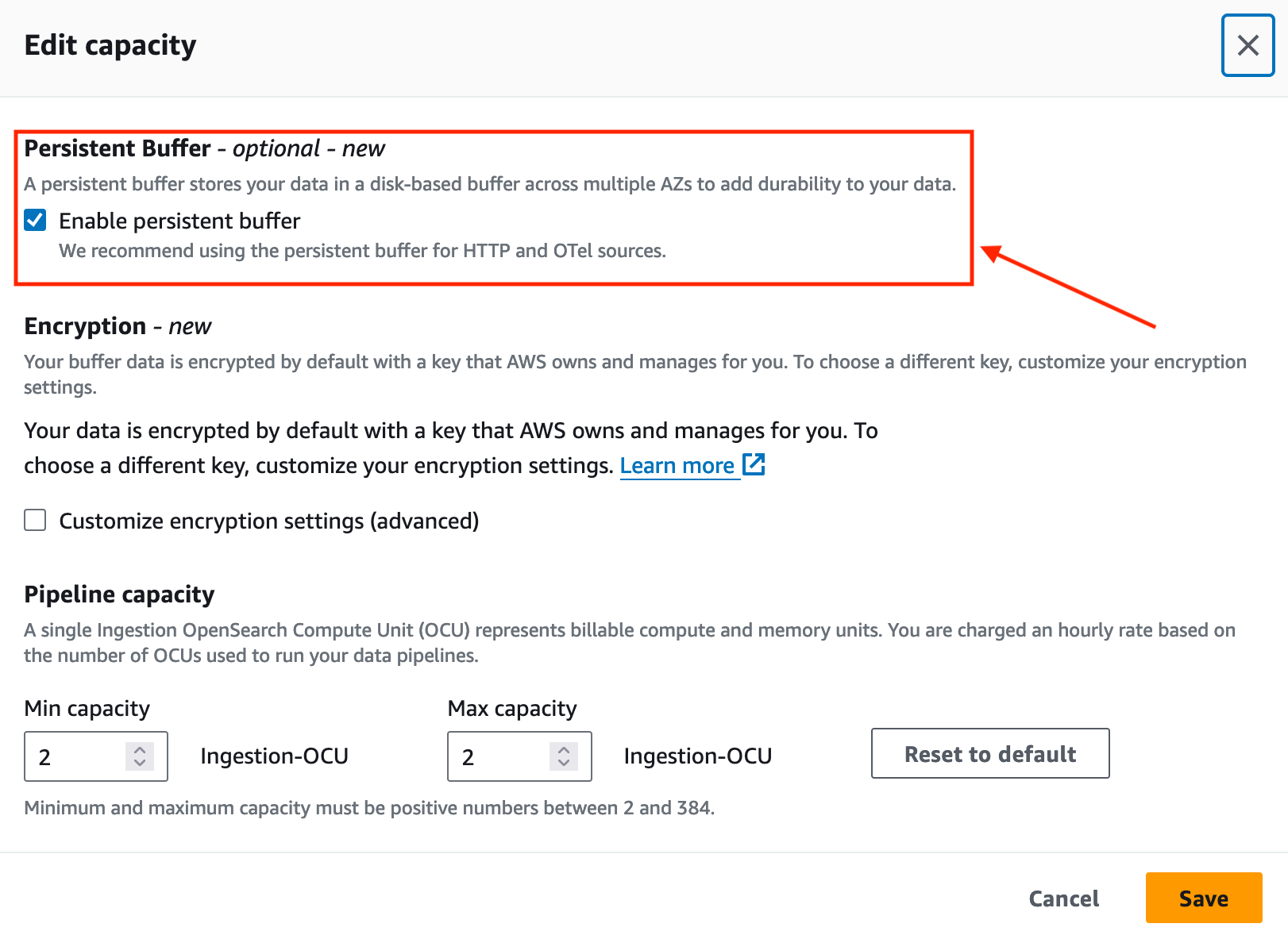
2023 年 XNUMX 月、OpenSearch Ingestion は、HTTP ソース (HTTP、Fluentd、FluentBit) や OpenTelemetry コレクターなどのプッシュベースのソースに対して永続的なバッファリングを導入しました。
デフォルトでは、OpenSearch インジェストはメモリ内バッファリングを使用します。永続的なバッファリングを使用すると、OpenSearch Ingestion は、より復元力の高いディスクベースのストアにデータを保存します。既存の取り込みパイプラインがある場合は、次のスクリーンショットに示すように、これらのパイプラインに対して永続的なバッファリングを有効にすることができます。
新しいプラグインのサポート
2023 年初頭に、OpenSearch Ingestion は次のサポートを追加しました。 ApacheKafkaのAmazonマネージドストリーミング (アマゾンMSK)。 OpenSearch インジェストでは、 カフカプラグイン Amazon MSK から OpenSearch Service 管理対象ドメインまたは OpenSearch サーバーレス コレクションにデータをストリーミングします。 Amazon MSK をデータソースとして設定する方法の詳細については、を参照してください。 Apache Kafka の Amazon Managed Streaming で OpenSearch インジェスト パイプラインを使用する.
OpenSearch サーバーレスの更新
OpenSearch Serverless は、埋め込みを保存し、類似性検索を実行するためのタイプ ベクトル検索の新しいコレクションのサポートを導入することにより、OpenSearch でのサーバーレス エクスペリエンスを引き続き強化しました。 OpenSearch Serverless は、クエリ スループットのスパイクに対処するためのシャード レプリカのスケーリングをサポートするようになりました。また、時系列コレクションを使用している場合は、データ保持要件に合わせてカスタム データ保持ポリシーを設定できるようになりました。
OpenSearch サーバーレス用ベクトル エンジン
2023 年 XNUMX 月に、 Amazon OpenSearch サーバーレス用のベクトル エンジン。ベクター エンジンを使用すると、基盤となるベクター データベース インフラストラクチャを管理する必要がなく、最新の ML 拡張検索エクスペリエンスと生成人工知能 (生成 AI) アプリケーションを簡単に構築できます。また、同じクエリ内でベクトル検索と全文検索を組み合わせたハイブリッド検索を実行できるため、個別のデータ ストアや複雑なアプリケーション スタックを管理および維持する必要がなくなります。
OpenSearch サーバーレスの低コストの開発およびテスト環境
OpenSearch Serverless は、レプリカの実行を回避できるようにすることで、開発およびテストのワークロードをサポートするようになりました。レプリカを削除すると、可用性のみを目的として別のアベイラビリティーゾーンに冗長 OCU を設ける必要がなくなります。可用性が問題にならない開発およびテストに OpenSearch Serverless を使用している場合は、最小 OCU を 4 から 2 に減らすことができます。
OpenSearch Serverless は、データ ライフサイクル ポリシーを使用した時間ベースの自動データ削除をサポートします
2023 年 XNUMX 月、OpenSearch Serverless は、時系列コレクションとインデックスのデータ保持管理のサポートを発表しました。新しい自動時間ベースのデータ削除機能を使用すると、データを保持する期間を指定できます。 OpenSearch Serverless は、この構成に基づいてデータのライフサイクルを自動的に管理します。詳細については、を参照してください。 Amazon OpenSearch Serverless が時間ベースの自動データ削除をサポートするようになりました.
OpenSearch Serverless がシャード レベルでのレプリカのスケールアップのサポートを発表
OpenSearch Serverless は、リリース時に、データ サイズの増大に応じて自動的に容量を増やすことをサポートしていました。とともに 新しいシャードレプリカのスケーリング OpenSearch Serverless 機能では、クエリ レートの突然の急増による負荷がかかるシャードを自動的に検出し、新しいシャード レプリカを動的に追加して、高速な応答時間を維持しながらクエリ スループットの増加に対応します。このアプローチは、単に新しいインデックス レプリカを追加するよりもコスト効率が高いことがわかります。
OCU の使用状況を監視するための AWS ユーザー通知
今回のリリースにより、OCU 使用率が検索または取り込みに対して設定された最大制限に近づいた場合、または設定された制限に達した場合に通知を送信するようにシステムを設定できるようになりました。新しい AWS ユーザー通知の統合を使用すると、容量のしきい値に違反するたびに通知を送信するようにシステムを設定できます。ユーザー通知機能により、サービスを常時監視する必要がなくなります。詳細については、「」を参照してください。 AWS ユーザー通知を使用した Amazon OpenSearch サーバーレスのモニタリング.
OpenSearch ダッシュボードでエクスペリエンスを向上
OpenSearch Service の OpenSearch 2.9 では、OpenSearch ダッシュボードでデータを簡単に迅速に分析できるようにする新機能が導入されました。これらの新機能には、OpenSearch 統合を備えたすぐに使える新しい事前構成ダッシュボードや、ダッシュボード内の既存の視覚化からアラートと異常検出を作成する機能が含まれます。
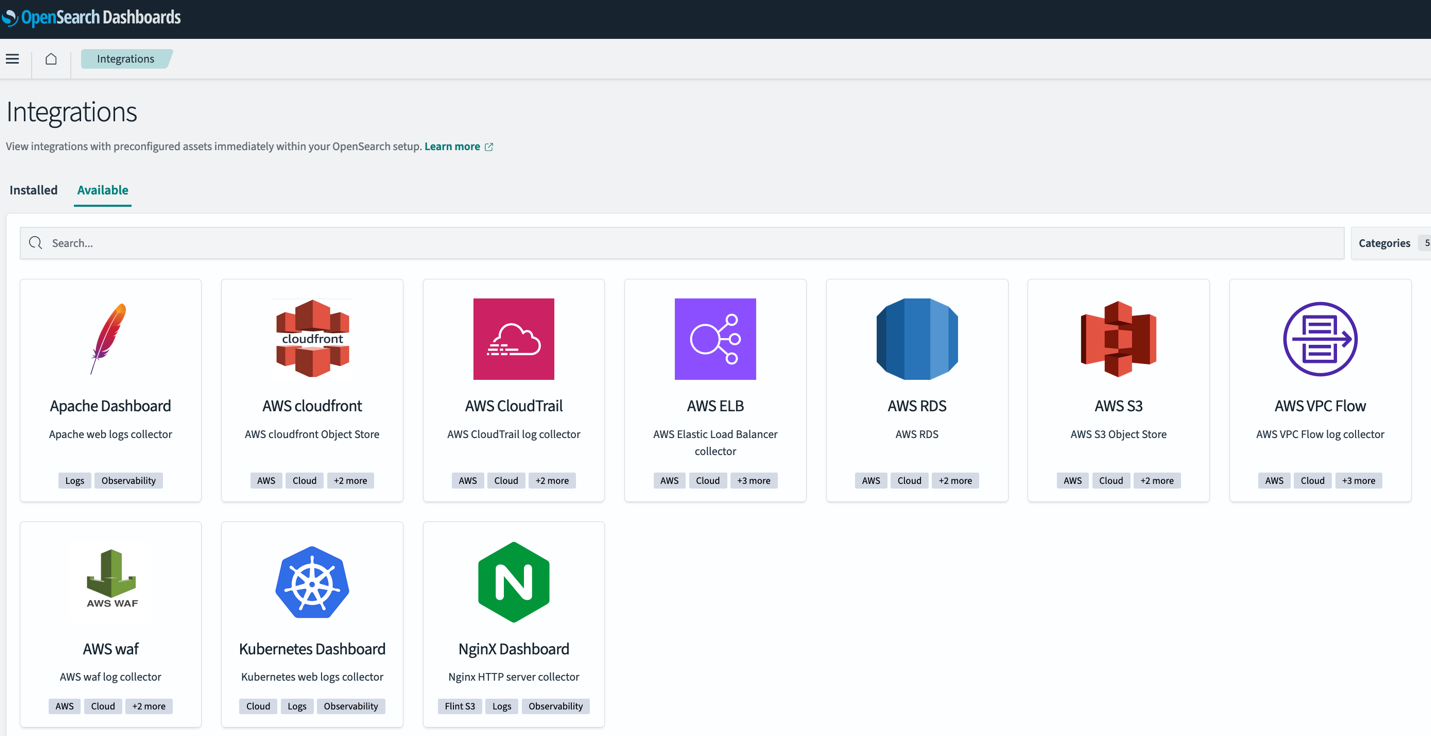
OpenSearch ダッシュボードの統合
OpenSearch 2.9 では、OpenSearch ダッシュボードに OpenSearch 統合のサポートが追加されました。 OpenSearch の統合には事前構成されたダッシュボードが含まれているため、次のような一般的なソースからのデータの分析をすぐに開始できます。 AWS クラウドフロント, AWS WAF, AWS クラウドトレイル, アマゾン バーチャル プライベート クラウド (Amazon VPC) フローログ。
OpenSearch ダッシュボードのアラートと異常
OpenSearch Service 2.9 では、新しいアラート モニターを 折れ線グラフの視覚化 OpenSearch ダッシュボード内。 OpenSearch で以前に作成した既存のモニターまたは検出器をダッシュボードの視覚化に関連付けることもできます。
この新機能は、ダッシュボードとアラートまたは異常検出プラグインの両方の間のコンテキストの切り替えを減らすのに役立ちます。サービスの平均データ量の低下を検出するためのアラート モニターを追加するには、次のダッシュボードを参照してください。

OpenSearch が地理空間集計サポートを拡張
OpenSearch バージョン 2.9 では、OpenSearch Service に XNUMX 種類のサポートが追加されました。 ジオシェイプ API を介したデータ集約: geo_bounds, ジオハッシュ, geo_tile.
geoshape フィールド タイプを使用すると、点、多角形、線文字列などのさまざまな地理形式で位置データのインデックスを作成できます。新しい集計タイプを使用すると、メトリックおよびマルチバケット地理空間集計を使用してインデックスからドキュメントをより柔軟に集計できるようになります。
OpenSearch サービスの運用に関する最新情報
OpenSearch Service により、ドメイン管理ノードを変更するときに Blue/Green デプロイメントを実行する必要がなくなりました。さらに、このサービスでは、OpenSearch Service ドメイン内の変更を追跡するための新しい Auto-Tune メトリクスのサポートにより、Auto-Tune イベントが改善されました。
OpenSearch Service で、Blue/Green デプロイを行わずにドメイン マネージャー ノードを更新できるようになりました
2 年前半の時点で、OpenSearch Service を使用すると、Blue/Green デプロイメントを必要とせずに、専用クラスター マネージャー ノードのインスタンス タイプまたはインスタンス数を変更できるようになりました。この機能強化により、データの移動を回避しながら、ドメイン操作の中断を最小限に抑えながら、より迅速な更新が可能になります。
以前は、OpenSearch Service 上の専用クラスター マネージャー ノードを更新するには、Blue/Green デプロイメントを使用して変更を加える必要がありました。ブルー/グリーン展開はドメインへの中断を避けることを目的としていますが、展開ではドメイン上の追加リソースが使用されるため、トラフィックが少ない時間帯に実行することをお勧めします。 Blue/Green デプロイメントを必要とせずにクラスター マネージャーのインスタンス タイプまたはインスタンス数を更新できるようになりました。そのため、ドメイン操作の潜在的な中断を回避しながら、これらの更新をより迅速に完了できます。ドメイン マネージャーのインスタンス タイプと数の両方を変更した場合でも、OpenSearch サービスは引き続き Blue/Green デプロイメントを使用して変更を加えます。ドライラン オプションを使用すると、変更に Blue/Green デプロイが必要かどうかを確認できます。
強化された自動調整エクスペリエンス
2023 年 XNUMX 月に、OpenSearch Service に新しい Auto-Tune メトリクスが追加され、Auto-Tune によるドメイン パフォーマンスの最適化をより明確に把握できる Auto-Tune イベントが改善されました。
Auto-Tune は、OpenSearch Service ドメイン リソースを自動的に更新して効率とパフォーマンスを向上させる適応型リソース管理システムです。たとえば、Auto-Tune は、ノード上のキュー サイズ、キャッシュ サイズ、Java 仮想マシン (JVM) 設定などのメモリ関連の構成を最適化します。
今回のリリースにより、変更履歴を監査できるだけでなく、変更履歴をリアルタイムで追跡できるようになりました。 アマゾンクラウドウォッチ コンソール。
さらに、OpenSearch Service は、変更の詳細を公開するようになりました。 アマゾンイベントブリッジ Auto-Tune 設定が推奨される場合、または OpenSearch Service ドメインに適用される場合。これらの Auto-Tune イベントは、 通知 OpenSearch サービス コンソールのページ。
新しい移行アシスタント ソリューションで OpenSearch Service への移行を加速します
2023 年 XNUMX 月、OpenSearch チームは新しいオープンソース ソリューションを開始しました。Amazon OpenSearch Service の移行アシスタント。このソリューションは、自己管理型の Elasticsearch および OpenSearch ドメインから OpenSearch Service へのデータ移行をサポートし、移行ソースとして Elasticsearch 7.x (<=7.10)、OpenSearch 1.x、および OpenSearch 2.x をサポートします。このソリューションにより、ソースと宛先の間の既存のライブ データの移行が容易になります。
まとめ
この投稿では、検索、可観測性、セキュリティ分析、移行によるビジネスの革新に役立つ OpenSearch Service の新しいリリースについて説明しました。 OpenSearch Service、OpenSearch Ingestion、OpenSearch Serverless の各新機能をいつ使用するかについての情報を提供しました。
OpenSearch ダッシュボードと OpenSearch プラグイン、および新しいエキサイティングな OpenSearch アシスタントについて詳しくは、 オープンサーチプレイグラウンド.
この投稿で説明されている機能を確認してください。また、貴重なフィードバックをお寄せいただきありがとうございます。
著者について
 ジョン・ハンドラー カリフォルニア州パロアルトに拠点を置くアマゾン ウェブ サービスのシニア プリンシパル ソリューション アーキテクトです。 Jon は OpenSearch および Amazon OpenSearch Service と緊密に連携し、AWS クラウドへの移行を希望する検索およびログ分析のワークロードを抱える幅広い顧客にヘルプとガイダンスを提供します。 AWS に入社する前、Jon のソフトウェア開発者としてのキャリアには、大規模な e コマース検索エンジンのコーディングに 4 年間従事していました。 Jon は、ペンシルバニア大学で文学士号を取得し、ノースウェスタン大学でコンピュータ サイエンスと人工知能の理学修士号と博士号を取得しています。
ジョン・ハンドラー カリフォルニア州パロアルトに拠点を置くアマゾン ウェブ サービスのシニア プリンシパル ソリューション アーキテクトです。 Jon は OpenSearch および Amazon OpenSearch Service と緊密に連携し、AWS クラウドへの移行を希望する検索およびログ分析のワークロードを抱える幅広い顧客にヘルプとガイダンスを提供します。 AWS に入社する前、Jon のソフトウェア開発者としてのキャリアには、大規模な e コマース検索エンジンのコーディングに 4 年間従事していました。 Jon は、ペンシルバニア大学で文学士号を取得し、ノースウェスタン大学でコンピュータ サイエンスと人工知能の理学修士号と博士号を取得しています。
 ハジェル・ブアフィフ アマゾン ウェブ サービスの分析スペシャリスト ソリューション アーキテクトです。 彼女は Amazon OpenSearch Service に重点を置き、さまざまな業界でお客様が適切に設計された分析ワークロードを設計および構築できるよう支援しています。 ハジャーは屋外で時間を過ごし、新しい文化を発見することを楽しんでいます。
ハジェル・ブアフィフ アマゾン ウェブ サービスの分析スペシャリスト ソリューション アーキテクトです。 彼女は Amazon OpenSearch Service に重点を置き、さまざまな業界でお客様が適切に設計された分析ワークロードを設計および構築できるよう支援しています。 ハジャーは屋外で時間を過ごし、新しい文化を発見することを楽しんでいます。
 アルナ・ゴビンダラジュ Amazon OpenSearch スペシャリスト ソリューション アーキテクトであり、多くの商用およびオープンソースの検索エンジンと協力してきました。彼女は検索、関連性、ユーザー エクスペリエンスに情熱を注いでいます。エンドユーザーのシグナルと検索エンジンの動作を関連付けることに関する彼女の専門知識は、多くの顧客の検索エクスペリエンスを向上させるのに役立ちました。
アルナ・ゴビンダラジュ Amazon OpenSearch スペシャリスト ソリューション アーキテクトであり、多くの商用およびオープンソースの検索エンジンと協力してきました。彼女は検索、関連性、ユーザー エクスペリエンスに情熱を注いでいます。エンドユーザーのシグナルと検索エンジンの動作を関連付けることに関する彼女の専門知識は、多くの顧客の検索エクスペリエンスを向上させるのに役立ちました。
 プラシャントアグラワル Amazon OpenSearch Service のシニア検索スペシャリスト ソリューション アーキテクトです。 彼は顧客と緊密に協力してワークロードをクラウドに移行するのを支援し、既存の顧客がクラスターを微調整してパフォーマンスを向上させ、コストを節約するのを支援しています。 AWS に入社する前は、検索とログ分析のユースケースに OpenSearch と Elasticsearch を使用するさまざまな顧客を支援していました。 仕事をしていないときは、旅行をしたり、新しい場所を探索したりしています。 要するに、食べる→旅する→リピートするのが好き。
プラシャントアグラワル Amazon OpenSearch Service のシニア検索スペシャリスト ソリューション アーキテクトです。 彼は顧客と緊密に協力してワークロードをクラウドに移行するのを支援し、既存の顧客がクラスターを微調整してパフォーマンスを向上させ、コストを節約するのを支援しています。 AWS に入社する前は、検索とログ分析のユースケースに OpenSearch と Elasticsearch を使用するさまざまな顧客を支援していました。 仕事をしていないときは、旅行をしたり、新しい場所を探索したりしています。 要するに、食べる→旅する→リピートするのが好き。
 イスラム教徒のアブ・タハ は、シームレスな検索ワークロードの移行、最高のパフォーマンスを実現するためのクラスターの微調整、および費用対効果の確保を通じてクライアントをガイドすることに専念するシニア OpenSearch スペシャリスト ソリューション アーキテクトです。テクニカル アカウント マネージャー (TAM) としての経歴を持つ Muslim は、企業顧客のクラウド導入を支援し、さまざまなワークロードの最適化に豊富な経験をもたらしています。イスラム教徒は家族と時間を過ごしたり、旅行したり、新しい場所を探索したりすることを楽しんでいます。
イスラム教徒のアブ・タハ は、シームレスな検索ワークロードの移行、最高のパフォーマンスを実現するためのクラスターの微調整、および費用対効果の確保を通じてクライアントをガイドすることに専念するシニア OpenSearch スペシャリスト ソリューション アーキテクトです。テクニカル アカウント マネージャー (TAM) としての経歴を持つ Muslim は、企業顧客のクラウド導入を支援し、さまざまなワークロードの最適化に豊富な経験をもたらしています。イスラム教徒は家族と時間を過ごしたり、旅行したり、新しい場所を探索したりすることを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/amazon-opensearch-h2-2023-in-review/

