ゲーム、小売、金融から製造、ヘルスケア、旅行に至るまで、世界中で生成されるデータの量は急増し続けています。組織は、絶え間なく流入するデータを迅速に利用して、ビジネスや顧客のためにイノベーションを起こすさらなる方法を模索しています。データを確実にキャプチャ、処理、分析し、無数のデータ ストアにすべてリアルタイムでロードする必要があります。
Apache Kafka は、こうしたリアルタイム ストリーミングのニーズによく選ばれています。ただし、アプリケーションのニーズに応じて自動的に拡張する他のデータ処理コンポーネントとともに Kafka クラスターをセットアップするのは困難な場合があります。ピーク トラフィックのプロビジョニングが不足してダウンタイムが発生したり、ベース ロードのプロビジョニングが過剰になって無駄が生じたりするリスクがあります。 AWS は、次のような複数のサーバーレス サービスを提供しています。 ApacheKafkaのAmazonマネージドストリーミング (Amazon MSK)、 Amazon データ ファイアホース, Amazon DynamoDB, AWSラムダ ニーズに応じて自動的にスケールします。
この投稿では、これらのサービスのいくつかを使用する方法について説明します。 MSK サーバーレス、リアルタイムのニーズを満たすサーバーレス データ プラットフォームを構築します。
ソリューションの概要
シナリオを想像してみましょう。あなたは、複数の地域に展開されているインターネット サービス プロバイダーの数千のモデムを管理する責任を負っています。顧客の生産性と満足度に大きな影響を与えるモデムの接続品質を監視したいと考えています。導入環境には、ダウンタイムを最小限に抑えるために監視および保守する必要があるさまざまなモデムが含まれています。各デバイスは、CPU 使用率、メモリ使用量、アラーム、接続ステータスなどの 1 KB のレコードを毎秒数千件送信します。パフォーマンスをリアルタイムで監視し、問題を迅速に検出して軽減できるように、このデータにリアルタイムでアクセスしたいと考えています。また、機械学習 (ML) モデルが予知保全評価を実行し、最適化の機会を見つけて需要を予測するために、このデータに長期的にアクセスする必要もあります。
オンサイトでデータを収集するクライアントは Python で記述されており、すべてのデータを Apache Kafka トピックとして Amazon MSK に送信できます。アプリケーションの低遅延かつリアルタイムのデータ アクセスのために、次を使用できます。 ラムダとDynamoDB。長期のデータ保管には、マネージドサーバーレスコネクタサービスを使用できます。 Amazon データ ファイアホース データをデータレイクに送信します。
次の図は、このエンドツーエンドのサーバーレス アプリケーションを構築する方法を示しています。
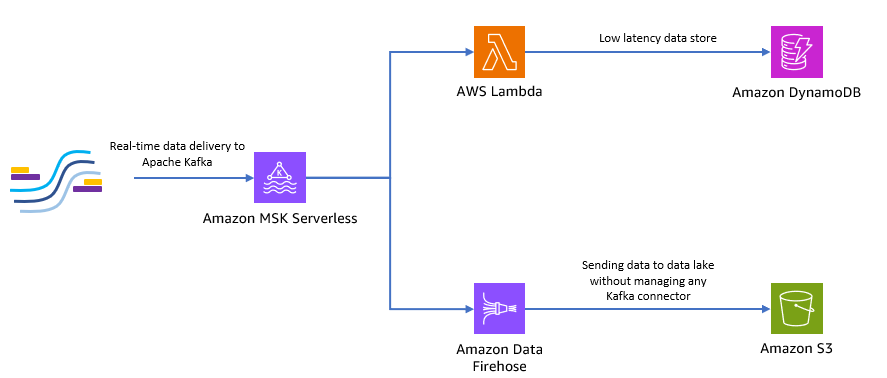
次のセクションの手順に従って、このアーキテクチャを実装してみましょう。
Amazon MSK でサーバーレス Kafka クラスターを作成する
Amazon MSK を使用して、モデムからリアルタイムのテレメトリ データを取り込みます。 Amazon MSK では、サーバーレス Kafka クラスターの作成が簡単です。を使用すると数分しかかかりません AWSマネジメントコンソール またはAWS SDK。コンソールを使用するには、以下を参照してください。 MSK サーバーレス クラスターの使用を開始する。サーバーレスクラスターを作成すると、 AWS IDおよびアクセス管理 (IAM) ロールとクライアント マシン。
Python を使用して Kafka トピックを作成する
クラスターとクライアント マシンの準備ができたら、クライアント マシンに SSH で接続し、Kafka Python と Python 用の MSK IAM ライブラリをインストールします。
- 次のコマンドを実行して Kafka Python をインストールし、 MSK IAM ライブラリ:
- という新しいファイルを作成します
createTopic.py. - 次のコードをこのファイルにコピーして、
bootstrap_servers®ionクラスターの詳細を含む情報。取得手順については、bootstrap_serversMSK クラスターの情報については、「」を参照してください。 Amazon MSK クラスターのブートストラップ ブローカーを取得する.
- 実行する
createTopic.pyという名前の新しい Kafka トピックを作成するスクリプトmytopicサーバーレスクラスター上で:
Python を使用してレコードを生成する
サンプル モデム テレメトリ データを生成してみましょう。
- という新しいファイルを作成します
kafkaDataGen.py. - 次のコードをこのファイルにコピーして、
BROKERS®ionクラスターの詳細を含む情報:
- 実行する
kafkaDataGen.pyランダム データを継続的に生成し、指定された Kafka トピックにパブリッシュするには、次のようにします。
イベントを Amazon S3 に保存する
ここで、すべての生のイベント データを Amazon シンプル ストレージ サービス (Amazon S3) 分析用のデータレイク。同じデータを使用して ML モデルをトレーニングできます。の Amazon Data Firehose との統合 これにより、Amazon MSK は Apache Kafka クラスターから S3 データレイクにデータをシームレスにロードできます。 Kafka から Amazon S3 にデータを継続的にストリーミングするには、次の手順を実行します。これにより、独自のコネクタ アプリケーションを構築または管理する必要がなくなります。
- Amazon S3 コンソールで、新しいバケットを作成します。既存のバケットを使用することもできます。
- S3 バケットに次の名前の新しいフォルダーを作成します。
streamingDataLake. - Amazon MSK コンソールで、MSK サーバーレスクラスターを選択します。
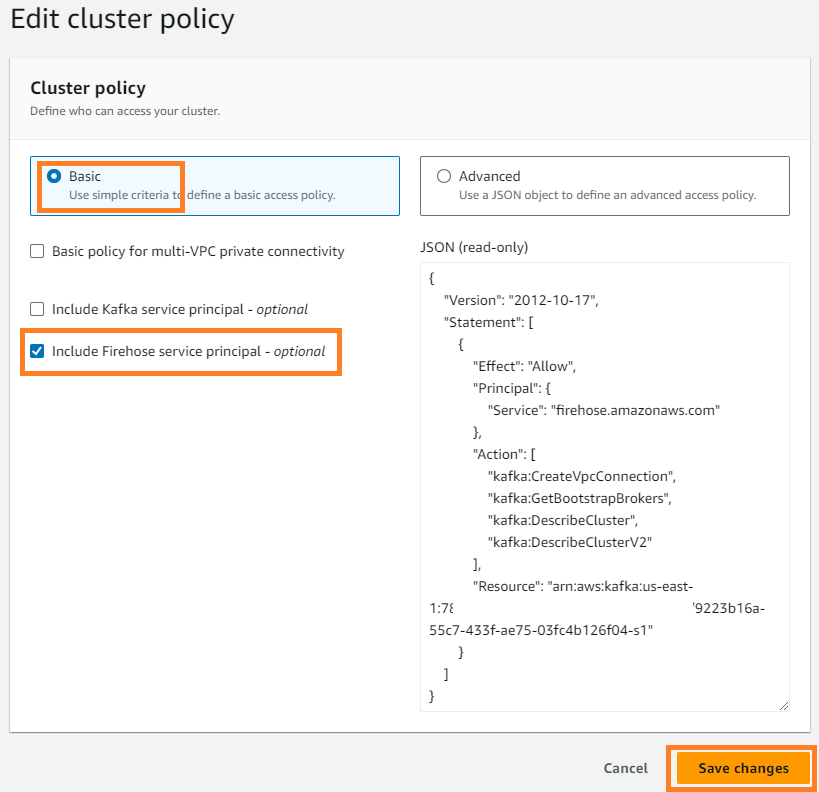
- ソフトウェア設定ページで、下図のように メニュー、選択 クラスター ポリシーの編集.

- 選択 Firehose サービス プリンシパルを含める 選択して 変更を保存します.
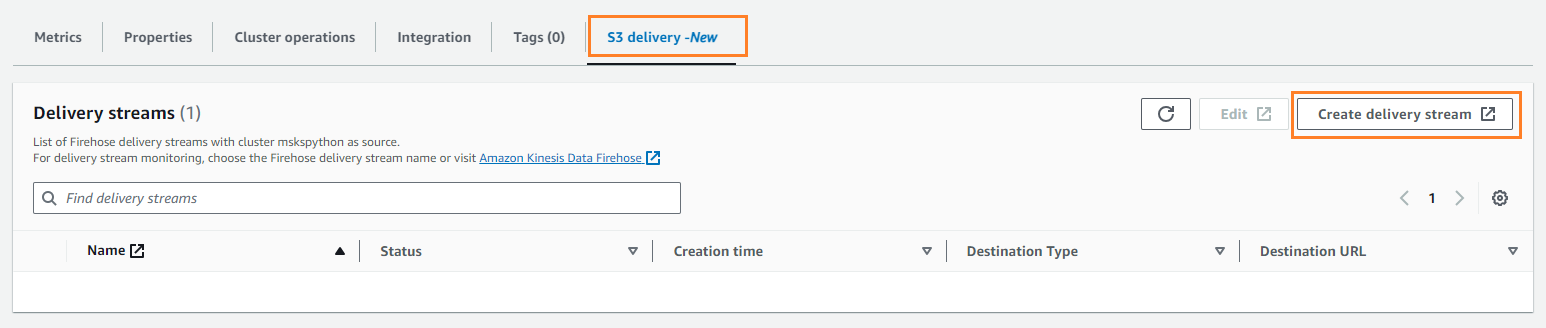
- ソフトウェア設定ページで、下図のように S3配信 タブを選択 配信ストリームを作成する.
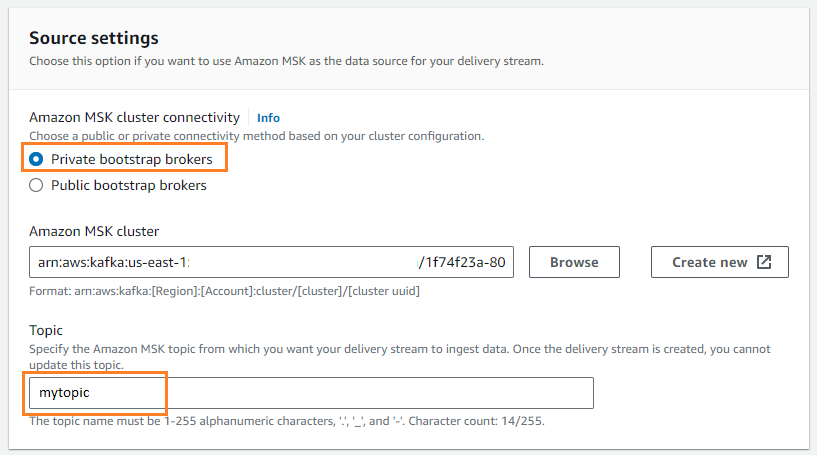
- ソース、選択する アマゾンMSK.
- 開催場所、選択する アマゾンS3.

- Amazon MSK クラスターの接続選択 プライベートブートストラップブローカー.
- ご用件、トピック名を入力します (この投稿では、
mytopic).
- S3バケット、選択する ブラウズ S3 バケットを選択します。
- 入力します
streamingDataLakeS3 バケットのプレフィックスとして使用します。 - 入力します
streamingDataLakeErrS3 バケットのエラー出力プレフィックスとして使用します。

- 選択する 配信ストリームを作成する.
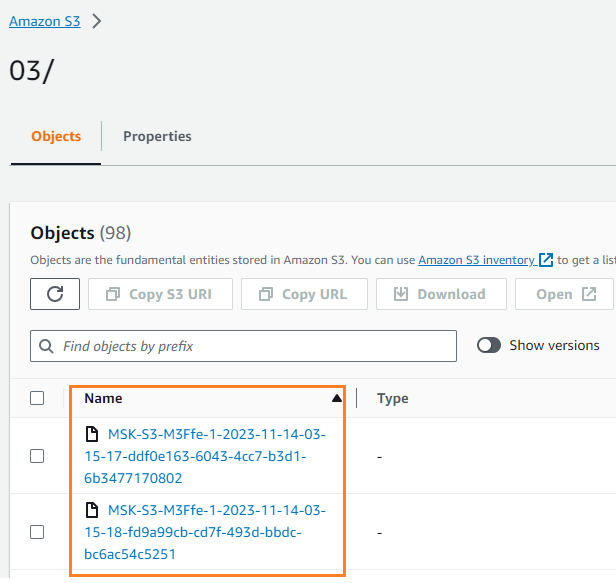
データが S3 バケットに書き込まれたことを確認できます。が表示されるはずです。 streamingDataLake ディレクトリが作成され、ファイルはパーティションに保存されます。
イベントを DynamoDB に保存する
最後のステップでは、最新のモデム データを DynamoDB に保存します。これにより、クライアント アプリケーションはモデムのステータスにアクセスし、どこからでもリモートでモデムと対話できるようになり、低遅延と高可用性が実現します。 Lambda は Amazon MSK とシームレスに連携します。 Lambda はイベントソースからの新しいメッセージを内部でポーリングし、ターゲットの Lambda 関数を同期的に呼び出します。 Lambda はメッセージをバッチで読み取り、イベント ペイロードとして関数に提供します。
まずはDynamoDBにテーブルを作成しましょう。参照する DynamoDB API 権限: アクション、リソース、条件のリファレンス クライアント マシンに必要な権限があることを確認します。
- という新しいファイルを作成します
createTable.py. - 次のコードをファイルにコピーして、
region情報:
- 実行する
createTable.pyというテーブルを作成するスクリプトdevice_statusDynamoDB の場合:
次に、Lambda 関数を構成しましょう。
- Lambdaコンソールで、 機能 ナビゲーションペインに表示されます。
- 選択する 関数を作成する.
- 選択 最初から作成者.
- 関数名¸ 名前を入力します (たとえば、
my-notification-kafka). - ランタイム、選択する Pythonの3.11.
- 権限選択 既存の役割を使用する で役割を選択します クラスターから読み取る権限.
- 関数を作成します。
Lambda 関数の設定ページで、ソース、宛先、アプリケーション コードを設定できるようになりました。
- 選択する トリガーを追加.
- トリガー構成、 入る
MSKAmazon MSK を Lambda ソース関数のトリガーとして設定します。 - MSK クラスター、 入る
myCluster. - 選択を解除 トリガーをアクティブにする、Lambda 関数をまだ設定していないためです。
- バッチサイズ、 入る
100. - 開始位置、選択する 最新.
- トピック名¸ 名前を入力します (たとえば、
mytopic). - 選択する Add.
- Lambda 関数の詳細ページの Code タブで、次のコードを入力します。
- Lambda 関数をデプロイします。
- ソフトウェア設定ページで、下図のように タブを選択 編集 トリガーを編集します。
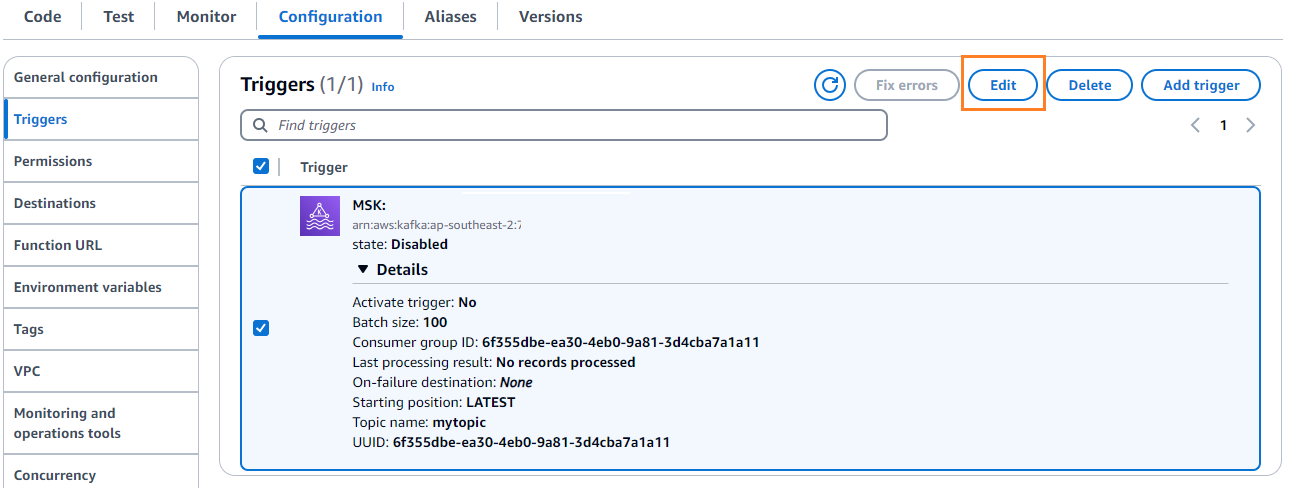
- トリガーを選択し、 Save.
- DynamoDBコンソールで、 アイテムを探索する ナビゲーションペインに表示されます。
- テーブルを選択します
device_status.
Lambda が Kafka トピックで生成されたイベントを DynamoDB に書き込んでいることがわかります。

まとめ
ストリーミング データ パイプラインは、リアルタイム アプリケーションを構築するために重要です。ただし、インフラストラクチャのセットアップと管理は困難な場合があります。この投稿では、Amazon MSK、Lambda、DynamoDB、Amazon Data Firehose などのサービスを使用して、AWS でサーバーレス ストリーミング パイプラインを構築する方法を説明しました。主な利点は、管理するサーバーが不要であること、インフラストラクチャの自動拡張性、フルマネージド サービスを使用した従量課金制モデルであることです。
独自のリアルタイム パイプラインを構築する準備はできていますか?無料の AWS アカウントを今すぐ始めましょう。サーバーレスの力を利用すると、AWS が差別化されていない重労働を処理しながら、ユーザーはアプリケーション ロジックに集中できます。 AWS で素晴らしいものを構築しましょう!
著者について
 マスドゥール・ラハマン・サイエム AWS のストリーミング データ アーキテクトです。 彼は世界中の AWS のお客様と協力して、現実世界のビジネス上の問題を解決するためのデータ ストリーミング アーキテクチャを設計および構築しています。 ストリーミング データ サービスと NoSQL を使用するソリューションの最適化を専門としています。 Sayem は、分散コンピューティングに非常に情熱を注いでいます。
マスドゥール・ラハマン・サイエム AWS のストリーミング データ アーキテクトです。 彼は世界中の AWS のお客様と協力して、現実世界のビジネス上の問題を解決するためのデータ ストリーミング アーキテクチャを設計および構築しています。 ストリーミング データ サービスと NoSQL を使用するソリューションの最適化を専門としています。 Sayem は、分散コンピューティングに非常に情熱を注いでいます。
 マイケル・オグイケ Amazon MSK のプロダクトマネージャーです。彼は、データを使用して行動を促す洞察を明らかにすることに情熱を持っています。彼は、幅広い業界の顧客がデータ ストリーミングを使用してビジネスを改善できるよう支援することに喜びを感じています。マイケルは、本やポッドキャストから行動科学や心理学について学ぶことも大好きです。
マイケル・オグイケ Amazon MSK のプロダクトマネージャーです。彼は、データを使用して行動を促す洞察を明らかにすることに情熱を持っています。彼は、幅広い業界の顧客がデータ ストリーミングを使用してビジネスを改善できるよう支援することに喜びを感じています。マイケルは、本やポッドキャストから行動科学や心理学について学ぶことも大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

