Apache Flink アプリケーションを実行する場合 Apache Flink 向け Amazon マネージドサービス、サーバーレスの性質を利用するというユニークな利点があります。これは、コスト最適化の演習はいつでも実行できることを意味します。計画段階で実行する必要はなくなりました。 Apache Flink のマネージド サービスを使用すると、ボタンをクリックするだけでコンピューティングを追加および削除できます。
Apache Flink は、重要なビジネス アプリケーションで数百の企業と、ワークロードにストリーム処理のニーズがある何千もの開発者によって使用されているオープン ソースのストリーム処理フレームワークです。可用性と拡張性が高く、最も要求の厳しいストリーム処理アプリケーションに高スループットと低遅延を提供します。 Apache Flink のこれらのスケーラブルなプロパティは、クラウドのコストを最適化するための鍵となります。
Apache Flink のマネージド サービスは、Apache Flink アプリケーションの構築と管理の複雑さを軽減するフルマネージド サービスです。 Apache Flink のマネージド サービスは、永続的なアプリケーションの状態、メトリクス、ログなどを提供する基盤となるインフラストラクチャと Apache Flink コンポーネントを管理します。
この投稿では、Apache Flink のマネージド サービスのコスト モデル、Apache Flink アプリケーションのコストを節約する領域について学び、データ処理パイプラインについて全体的に理解を深めることができます。コストの理解、アプリケーションがオーバープロビジョニングされているかどうかの理解、自動スケーリングについての考え方、コストを節約するために Apache Flink アプリケーションを最適化する方法について深く掘り下げます。最後に、Apache Flink がお客様のユースケースに適したテクノロジーであるかどうかを判断するために、ワークロードに関する重要な質問をします。
Apache Flink のマネージド サービスでのコストの計算方法
Apache Flink アプリケーションのマネージド サービスに関するコストを最適化するには、マネージド サービスの価格設定に何が含まれているかをよく理解すると役立ちます。
Apache Flink アプリケーションのマネージド サービスは、1 つの仮想 CPU と 4 GB のメモリで構成されるコンピューティング インスタンスである Kinesis Processing Unit (KPU) で構成されます。アプリケーションに割り当てられる KPU の合計数は、直接制御する XNUMX つのパラメーターを乗算して決定されます。
- 平行度 – Apache Flink アプリケーションの並列処理のレベル
- KPUごとの並列処理 – 各並列処理専用のリソースの数
KPU の数は、KPU = Parallelism / ParallelismPerKPU という単純な式で決定され、次の整数に切り上げられます。
アプリケーションごとの追加 KPU もオーケストレーションに対して課金され、データ処理には直接使用されません。
KPU の合計数によって、アプリケーションに割り当てられるリソース、CPU、メモリ、およびアプリケーション ストレージの数が決まります。 KPU ごとに、アプリケーションは 1 つの vCPU と 4 GB のメモリを受け取ります。そのうち 3 GB はデフォルトで実行中のアプリケーションに割り当てられ、残りの 1 GB はアプリケーションの状態ストア管理に使用されます。各 KPU には、アプリケーションに接続された 50 GB のストレージも付属しています。 Apache Flink は、アプリケーションの状態を構成可能な制限までメモリ内に保持し、接続されたストレージに波及させます。
3 番目のコスト要素は、永続的なアプリケーションのバックアップです。 スナップショット。これは完全にオプションであり、非常に多くのスナップショットを保持しない限り、全体のコストに与える影響は小さくなります。
この記事の執筆時点では、米国東部 (オハイオ) AWS リージョンの各 KPU の料金は 0.11 時間あたり 0.10 ドル、接続されたアプリケーション ストレージの料金は 0.023 GB あたり月額 XNUMX ドルです。永続的なアプリケーション バックアップ (スナップショット) のコストは、XNUMX GB あたり月額 XNUMX ドルです。参照する Apache Flink 向け Amazon マネージドサービスの料金 最新の価格とさまざまな地域については、こちらをご覧ください。
次の図は、Apache Flink のマネージド サービスで実行中のアプリケーションのコスト コンポーネントの相対的な割合を示しています。 KPU の数は、並列処理および KPU ごとの並列処理パラメータによって制御します。永続的なアプリケーションのバックアップ ストレージは示されていません。
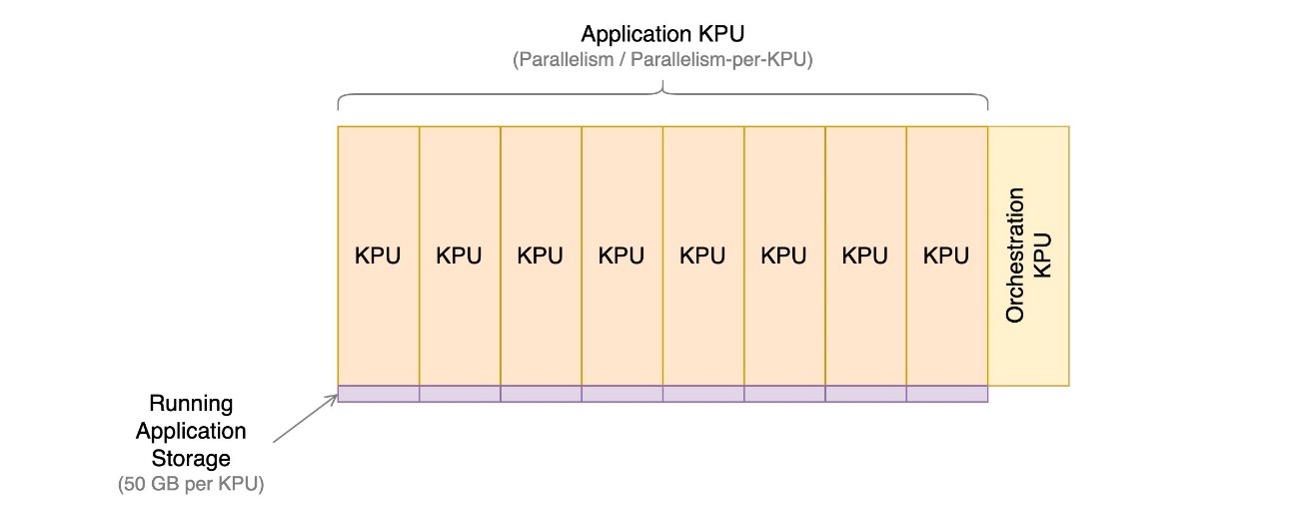
次のセクションでは、コストを監視し、アプリケーション リソースの使用を最適化し、スループット プロファイルを処理するために必要な KPU の数を見つける方法を検討します。
AWS Cost Explorer と請求書の理解
現在の Apache Flink のマネージド サービスの支出を確認するには、次を使用できます。 AWSコストエクスプローラー.
Cost Explorer コンソールでは、日付範囲、使用量の種類、およびサービスでフィルター処理して、Apache Flink アプリケーションのマネージド サービスの支出を分離できます。次のスクリーンショットは、前のセクションで説明した価格カテゴリに分類された過去 12 か月のコストを示しています。これらの月の多くの支出の大部分は、以下のインタラクティブ KPU によるものでした。 Apache Flink Studio 向け Amazon マネージドサービス.
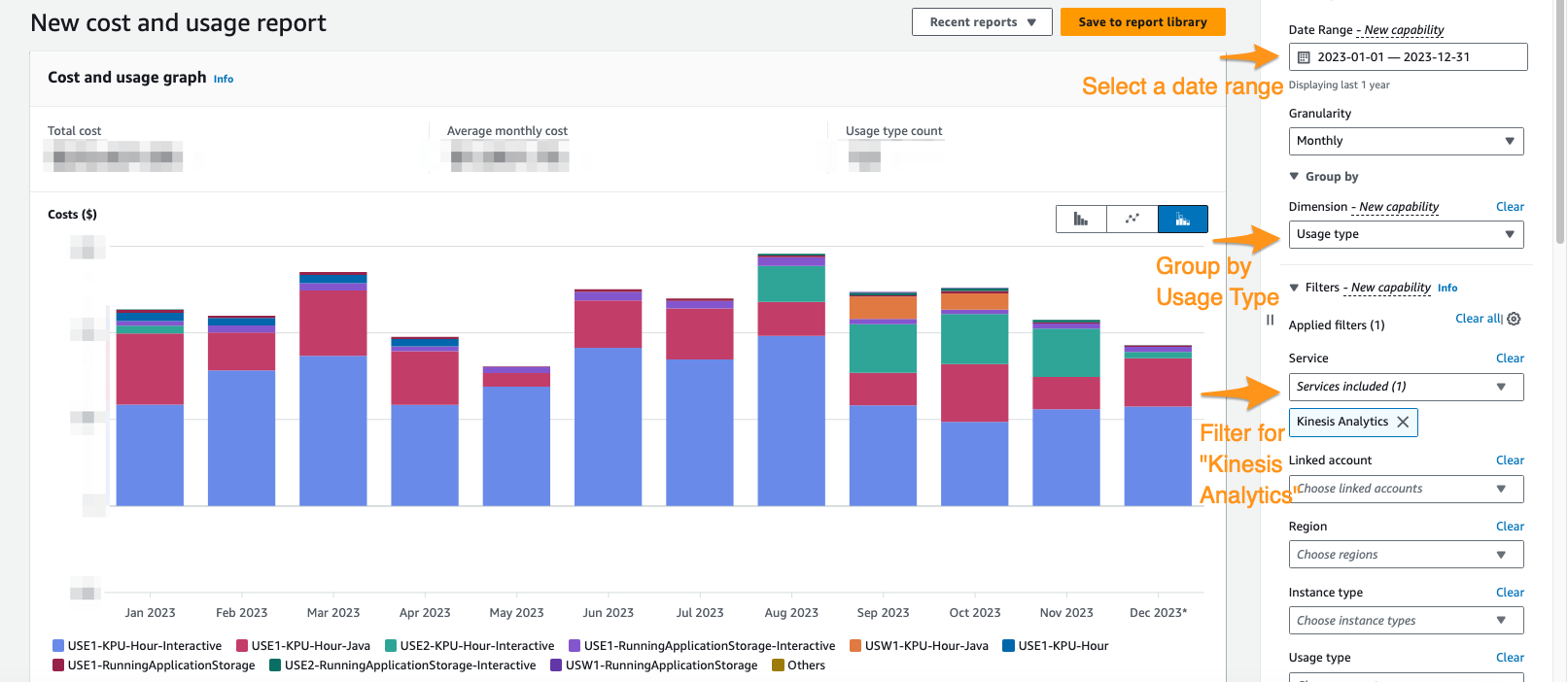
Cost Explorer を使用すると、請求書の理解に役立つだけでなく、自動的に、またはスループット要件によって予想を超えてスケールされた可能性がある特定のアプリケーションをさらに最適化するのにも役立ちます。アプリケーションに適切にタグ付けすると、この支出をアプリケーションごとに分類して、どのアプリケーションがコストを占めているかを確認することもできます。
リソースの過剰プロビジョニングまたは非効率的な使用の兆候
Apache Flink アプリケーションのマネージド サービスに関連するコストを最小限に抑えるための簡単なアプローチには、アプリケーションで使用する KPU の数を減らすことが含まれます。ただし、徹底的に評価およびテストしないと、この削減がパフォーマンスに悪影響を与える可能性があることを認識することが重要です。アプリケーションがオーバープロビジョニングされているかどうかを迅速に判断するには、CPU とメモリの使用量、アプリケーションの機能、データ分散などの主要な指標を調べます。ただし、これらの指標はオーバープロビジョニングの可能性を示唆する可能性がありますが、KPU の数を調整する前にパフォーマンス テストを実施し、スケーリング パターンを検証することが重要です。
メトリック
分析する アプリケーションのメトリクス on アマゾンクラウドウォッチ オーバープロビジョニングの明確な兆候を明らかにすることができます。もし containerCPUUtilization & containerMemoryUtilization アプリケーションのトラフィック パターンに関して統計的に有意な期間にわたって、メトリクスが一貫して 20% 未満に留まっている場合は、スケールダウンしてより多くのデータをより少ないマシンに割り当てることが現実的である可能性があります。一般に、次のような場合にアプリケーションのサイズが適切であると考えられます。 containerCPUUtilization 50 ~ 75% の間で推移します。それでも containerMemoryUtilization 一日を通して変動し、コードの最適化の影響を受ける可能性があります。かなりの期間にわたって一貫して低い値は、潜在的なオーバープロビジョニングを示している可能性があります。
KPU ごとの並列処理が十分に活用されていない
アプリケーションがオーバープロビジョニングされていることを示すもう 1 つの微妙な兆候は、アプリケーションが純粋に I/O バウンドであるか、データベースへの単純な呼び出しや CPU を集中的に使用しない操作のみを行う場合です。この場合、Apache Flink のマネージド サービス内で KPU ごとの並列処理パラメーターを使用して、より多くのタスクを単一の処理ユニットにロードできます。
KPU パラメータごとの並列処理は、コンピューティングおよびメモリ リソース (KPU) の単位あたりのワークロード密度の尺度として表示できます。 KPU あたりの並列処理をデフォルト値の 1 より大きくすると、処理がより高密度になり、XNUMX つの KPU により多くの並列プロセスが割り当てられます。
次の図は、アプリケーションの並列処理を一定 (たとえば 4) に保ち、KPU あたりの並列処理を増やす (たとえば 1 から 2) ことによって、アプリケーションが同じレベルの並列実行で使用するリソースを減らす方法を示しています。
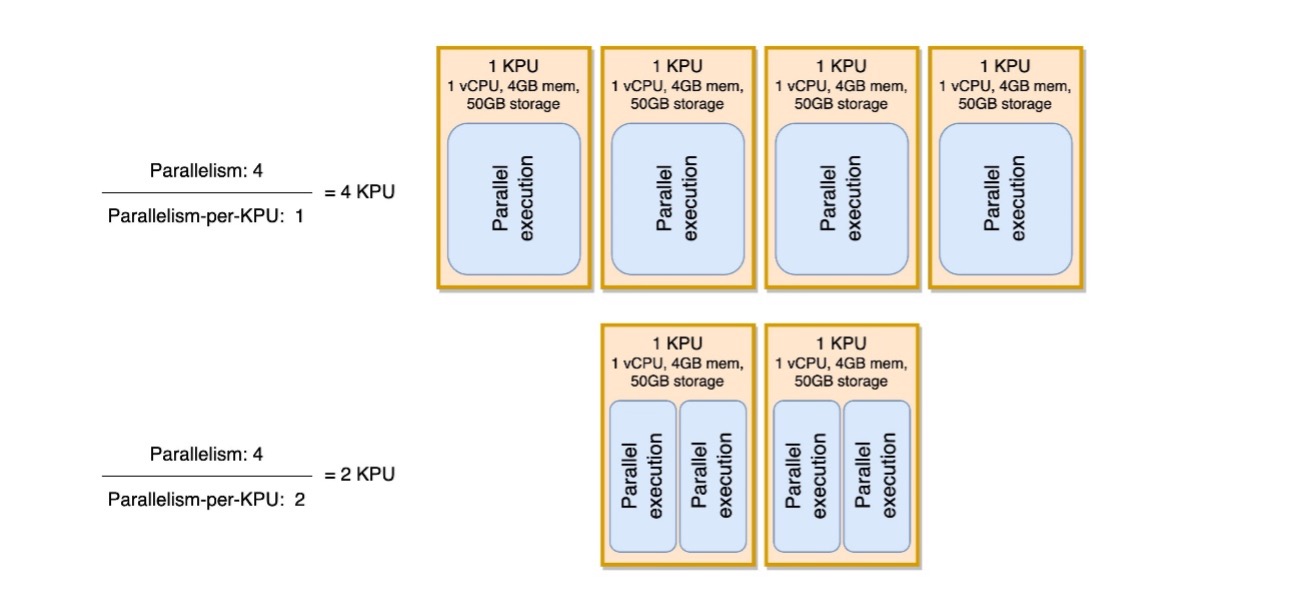
この投稿のすべての推奨事項と同様、KPU ごとの並列処理を増やす決定は細心の注意を払う必要があります。 KPU 値ごとの並列処理を増やすと、単一の KPU にかかる負荷が増加する可能性があるため、その負荷を許容できる必要があります。 I/O バウンドの操作によって CPU やメモリの使用率が有意に増加することはありませんが、データに対して多くの複雑な操作を計算するプロセス関数は、リソースを過剰に消費する可能性があるため、単一の KPU に照合する理想的な操作ではありません。パフォーマンスをテストし、これがアプリケーションにとって良いオプションであるかどうかを評価します。
サイズ選びのアプローチ方法
Apache Flink アプリケーション用のマネージド サービスを立ち上げる前に、アプリケーションに割り当てる必要がある KPU の数を見積もるのが難しい場合があります。一般に、見積もりを行う前に、トラフィック パターンをよく理解しておく必要があります。メガバイト/秒の取り込み速度ベースでトラフィック パターンを理解すると、開始点を概算するのに役立ちます。
一般に、アプリケーションが処理する 1 MB/秒あたり 10 つの KPU から開始できます。たとえば、アプリケーションが 10 MB/秒 (平均) を処理する場合、アプリケーションの開始点として XNUMX KPU を割り当てます。これは非常に高度な近似値であり、一般的な推定に有効であることがわかっていることに留意してください。ただし、パフォーマンス テストを実行し、長期にわたるメトリクス (CPU、メモリ、レイテンシー、全体的なジョブ パフォーマンス) に基づいて、これが長期的に適切なサイジングであるかどうかを評価する必要もあります。
アプリケーションに適切なサイジングを見つけるには、Apache Flink アプリケーションをスケールアップおよびスケールダウンする必要があります。前述したように、Apache Flink のマネージド サービスでは、並列処理と KPU ごとの並列処理という 2 つの個別の制御があります。これらのパラメータによって、アプリケーション内の並列処理のレベルと、利用可能な全体的なコンピューティング、メモリ、ストレージ リソースが決まります。
推奨されるテスト方法は、適切なサイジングを見つけるために実験しながら、並列処理または KPU ごとの並列処理を個別に変更することです。一般に、リソース全体を増やすことなく、並列 I/O バウンド操作の数を増やすには、KPU ごとの並列処理のみを変更します。それ以外の場合は、ワークロードに適したサイジングを見つけるために、並列処理のみを変更してください (結果として KPU が変更されます)。
また、ワイルドカード*を使用すると、任意の文字にマッチし、XNUMXつのコマンドで複数のファイルを削除することができます。 演算子レベルで並列処理を設定する ソース、シンク、またはスケーリング メカニズムから独立して制限する必要があるその他のオペレーターを制限します。これは、10 個のパーティションを持つ Apache Kafka トピックから読み取る Apache Flink アプリケーションに使用できます。とともに setParallelism() このメソッドを使用すると、KafkaSource を 10 に制限できますが、Kafka ソースのアイドル タスクを作成せずに、Apache Flink アプリケーションのマネージド サービスを 10 より高い並列度にスケールできます。他のデータ処理のケースでは、演算子の並列性を静的な値に静的に設定するのではなく、アプリケーション全体のスケーリングに応じてスケーリングされるように、アプリケーションの並列性の関数として設定することをお勧めします。
スケーリングとオートスケーリング
Apache Flink のマネージド サービスでは、並列処理または KPU ごとの並列処理を変更すると、アプリケーション構成が更新されます。これにより、アプリケーションは自動的に スナップショット (無効になっていない限り)、アプリケーションを停止し、新しいサイズ設定で再起動し、スナップショットから状態を復元します。スケーリング操作によってデータの損失や不整合が発生することはありませんが、インフラストラクチャの追加または削除中にデータ処理が短期間停止します。これは、実稼働環境で再スケーリングするときに考慮する必要があることです。
テストと最適化のプロセス中は、無効にすることをお勧めします。 自動スケーリング 並列処理と KPU ごとの並列処理を変更して、最適な値を見つけます。前述したように、手動スケーリングはアプリケーション構成の単なる更新であり、 AWSマネジメントコンソール または API を使用して、 UpdateApplication アクション.
最適なサイジングを見つけた後、取り込まれたスループットが大幅に変化すると予想される場合は、自動スケーリングを有効にすることを決定できます。
Apache Flink のマネージド サービスでは、複数のタイプの自動スケーリングを使用できます。
- すぐに使える自動スケーリング – これを有効にすると、アプリケーションの並列処理を自動的に調整できます。
containerCPUUtilizationメトリック。新しいアプリケーションでは、自動スケーリングがデフォルトで有効になっています。自動スケーリングアルゴリズムの詳細については、を参照してください。 自動スケーリング. - きめ細かいメトリックベースの自動スケーリング – これは実装が簡単です。自動化は、次のような事実上あらゆる指標に基づいて行うことができます。 カスタムメトリック アプリケーションが公開します。
- スケジュールされたスケーリング – これは、1 日または曜日の特定の時間にワークロードのピークが予想される場合に便利です。
すぐに使用できる自動スケーリングと詳細なメトリックベースのスケーリングは相互に排他的です。きめ細かいメトリクスベースの自動スケーリングとスケジュールされたスケーリングの詳細、および完全に動作するコード例については、以下を参照してください。 Apache Flink 向け Amazon マネージド サービスのメトリクスベースおよびスケジュールされたスケーリングを有効にする.
コードの最適化
Apache Flink アプリケーションのマネージド サービスのコスト削減にアプローチするもう 1 つの方法は、コードの最適化です。最適化されていないコードでは、同じ計算を実行するためにより多くのマシンが必要になります。コードを最適化すると、全体的なリソース使用率が低下し、それに応じてスケールダウンやコスト削減が可能になる可能性があります。
コードのパフォーマンスを理解するための最初のステップは、Apache Flink 内の組み込みユーティリティを使用することです。 フレームグラフ.
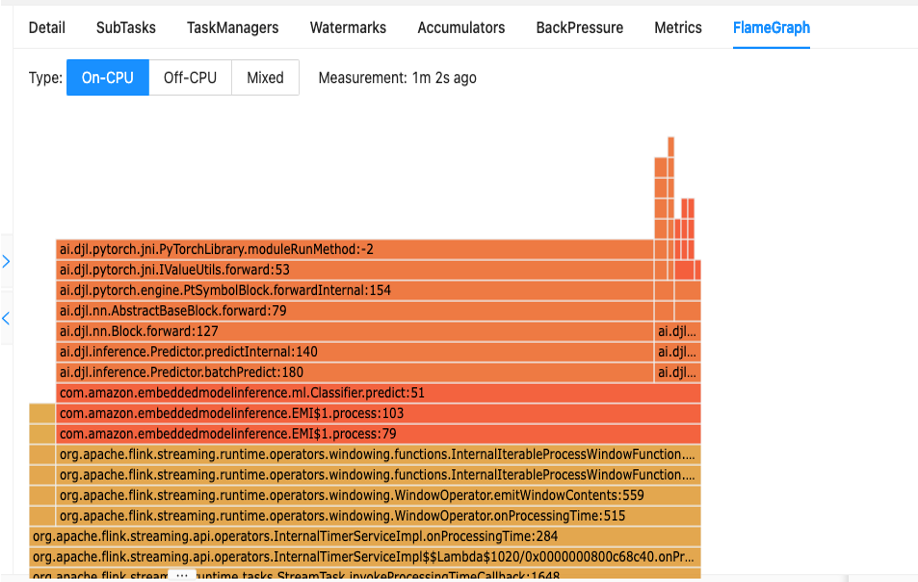
Flame Graphs は、Apache Flink ダッシュボードからアクセスでき、スタック トレースを視覚的に表現します。メソッドが呼び出されるたびに、スタック トレース内のそのメソッド呼び出しを表すバーは、合計サンプル数に比例して大きくなります。これは、フレーム グラフに非常に長いバーがある非効率的なコード部分がある場合、このコードをより効率的にする方法を検討する必要がある可能性があることを意味します。さらに、次のこともできます。 Amazon CodeGuruプロファイラー 〜へ Apache Flink のマネージド サービスで実行されている Apache Flink アプリケーションを監視および最適化する.
アプリケーションを設計するときは、特定の時点での特定の操作に必要な最高レベルの API を使用することをお勧めします。 Apache Flink は、Flink SQL、テーブル API、 Datastream API、および ProcessFunction API は、ますます複雑さと責任のレベルが高まっています。アプリケーション全体を Flink SQL または Table API で作成できる場合、これを使用すると、状態と計算を手動で管理するのではなく、Apache Flink フレームワークを活用できます。
データの偏り
Apache Flink ダッシュボードでは、Apache Flink のマネージド サービス ジョブに関するその他の役立つ情報を収集できます。
ダッシュボードでは、求人応募グラフ内の個々のタスクを検査できます。それぞれの青いボックスはタスクを表し、各タスクはサブタスク、つまりそのタスクの分散作業単位で構成されます。この方法で、サブタスク間のデータの偏りを特定できます。
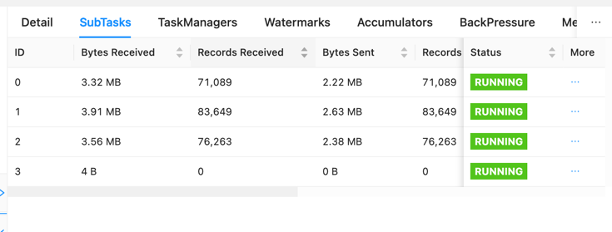
データ スキューは、あるサブタスクに別のサブタスクよりも多くのデータが送信されていること、およびより多くのデータを受信しているサブタスクが他のサブタスクよりも多くの作業を実行していることを示す指標です。データ スキューのこのような症状がある場合は、ソースを特定することでデータ スキューを解消することができます。たとえば、 GroupBy or KeyedStream キーに歪みがある可能性があります。これは、データがキー間で均等に分散されず、その結果、Apache Flink コンピューティング インスタンス間で作業が不均等に分散されることを意味します。グループ化するシナリオを想像してください。 userIdただし、アプリケーションは 1 人のユーザーから他のユーザーよりもはるかに多くのデータを受け取ります。これにより、データ スキューが発生する可能性があります。これを解消するには、別のグループ化キーを選択してサブタスク間でデータを均等に分散します。別のキーを選択するにはコードを変更する必要があることに注意してください。
データの偏りが解消されたら、元の状態に戻ることができます。 containerCPUUtilization & containerMemoryUtilization KPU の数を減らすためのメトリクス。
コード最適化のその他の領域には、外部システムにアクセスしていることを確認することが含まれます。 非同期 I/O API または、データ ストリーム結合を介して行うこともできます。これは、データ ストアへの同期クエリによって速度の低下やチェックポイント設定の問題が発生する可能性があるためです。さらに、以下を参照してください。 パフォーマンスのトラブルシューティング アプリケーションのバックプレッシャーを引き起こす可能性のあるチェックポイントやロギングの遅さで発生する可能性がある問題に対応します。
Apache Flink が適切なテクノロジであるかどうかを判断する方法
アプリケーションが Apache Flink フレームワークと Apache Flink のマネージド サービスの背後にある強力な機能を使用していない場合は、より単純なものを使用することでコストを節約できる可能性があります。
Apache Flink のキャッチフレーズは「データ ストリーム上のステートフル コンピューティング」です。この文脈におけるステートフルとは、Apache Flink 状態構造を使用していることを意味します。 Apache Flink の State を使用すると、過去に見たメッセージを長期間記憶しておくことができ、ストリーミング結合、重複排除、1 回限りの処理、ウィンドウ処理、遅延データの処理などが可能になります。これは、メモリ内の状態ストアを使用して行われます。 Apache Flink のマネージド サービスでは、 RocksDB その状態を維持するために。
アプリケーションにステートフルな操作が含まれていない場合は、次のような代替手段を検討できます。 AWSラムダ、コンテナ化されたアプリケーション、または アマゾン エラスティック コンピューティング クラウド アプリケーションを実行している (Amazon EC2) インスタンス。このような場合、Apache Flink の複雑さは必要ない可能性があります。キャッシュされたデータや独立したストリーム位置メモリを必要とするエンリッチメント手順などのステートフルな計算では、Apache Flink のステートフル機能が保証される場合があります。データ保持の長期化やその他のステートフル要件によって、アプリケーションが将来ステートフルになる可能性がある場合は、Apache Flink を使い続ける方が簡単になる可能性があります。ストリーム処理機能として Apache Flink を重視する組織は、すべてのアプリケーションが同じ方法でデータを処理できるように、ステートフル アプリケーションとステートレス アプリケーションに対して Apache Flink を使い続けることを好む場合があります。 Apache Flink から代替手段に移行する前に、XNUMX 回限りの処理、ファンアウト機能、分散計算などのオーケストレーション機能も考慮する必要があります。
もう 6 つの考慮事項は、レイテンシー要件です。 Apache Flink はリアルタイム データ処理に優れているため、1 時間または XNUMX 日のレイテンシ要件を持つアプリケーションに Apache Flink を使用することは意味がありません。一時的なバッチプロセスに切り替えることでコストを削減 Amazon シンプル ストレージ サービス たとえば (Amazon S3) は重要です。
まとめ
この投稿では、Apache Flink のマネージド サービスのコスト削減策を試みる際に考慮すべきいくつかの側面について説明しました。マネージド サービスに対する全体的な支出を特定する方法、KPU をスケールダウンするときに監視するいくつかの有用なメトリクス、スケールダウンのためにコードを最適化する方法、Apache Flink がユースケースに適しているかどうかを判断する方法について説明しました。
これらのコスト削減戦略を実装すると、コスト効率が向上するだけでなく、合理化され適切に最適化された Apache Flink 導入も実現します。全体的な支出を常に意識し、主要な指標を使用し、リソースのスケールダウンについて情報に基づいた意思決定を行うことで、パフォーマンスを犠牲にすることなく、コスト効率の高い運用を実現できます。 Apache Flink の状況をナビゲートするとき、それが特定のユースケースに適合するかどうかを継続的に評価することが極めて重要になります。これにより、データ処理のニーズに合わせてカスタマイズされた効率的なソリューションを実現できます。
この投稿で説明した推奨事項のいずれかがワークロードに共鳴する場合は、それらを試してみることをお勧めします。指定されたメトリクスと、ワークロードをより深く理解する方法に関するヒントがあれば、Apache Flink のマネージド サービスで Apache Flink ワークロードを効率的に最適化するために必要なものが得られます。以下は、この投稿を補足するために使用できるいくつかの役立つリソースです。
著者について
 ジェレミー・バー 過去 10 年間、ソフトウェア エンジニア、機械学習エンジニア、そして最近ではデータ エンジニアとしてテレメトリ データ領域で働いてきました。 AWS では、ストリーミング スペシャリスト ソリューション アーキテクトとして、Apache Kafka (Amazon MSK) 用の Amazon マネージド ストリーミングと Apache Flink 用の Amazon マネージド サービスの両方をサポートしています。
ジェレミー・バー 過去 10 年間、ソフトウェア エンジニア、機械学習エンジニア、そして最近ではデータ エンジニアとしてテレメトリ データ領域で働いてきました。 AWS では、ストリーミング スペシャリスト ソリューション アーキテクトとして、Apache Kafka (Amazon MSK) 用の Amazon マネージド ストリーミングと Apache Flink 用の Amazon マネージド サービスの両方をサポートしています。
 ロレンツォ・ニコラ AWS のシニア ストリーミング ソリューション アーキテクトとして働いており、EMEA 全体の顧客をサポートしています。彼は 25 年以上にわたってクラウドネイティブでデータ集約型のシステムを構築しており、コンサルティング会社や FinTech 製品会社の両方を通じて金融業界で働いています。彼はオープンソース テクノロジーを幅広く活用し、Apache Flink などのいくつかのプロジェクトに貢献してきました。
ロレンツォ・ニコラ AWS のシニア ストリーミング ソリューション アーキテクトとして働いており、EMEA 全体の顧客をサポートしています。彼は 25 年以上にわたってクラウドネイティブでデータ集約型のシステムを構築しており、コンサルティング会社や FinTech 製品会社の両方を通じて金融業界で働いています。彼はオープンソース テクノロジーを幅広く活用し、Apache Flink などのいくつかのプロジェクトに貢献してきました。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/real-time-cost-savings-for-amazon-managed-service-for-apache-flink/

