データ駆動型のビジネスを構築するには、データ カタログ内のエンタープライズ データ資産を民主化することが重要です。 統合されたデータ カタログを使用すると、データセットをすばやく検索して、データ スキーマ、データ形式、場所を把握できます。 の AWSGlueデータカタログ 異なるシステムがメタデータを保存および検索して、データサイロ内のデータを追跡できる統一リポジトリを提供します。
ApacheFlink は、スケーラブルなストリーミング ETL、分析、およびイベント駆動型アプリケーションに広く使用されているデータ処理エンジンです。 耐障害性を備えた正確な時間と状態の管理を提供します。 Flink は、統合された API またはアプリケーションを使用して、バインドされたストリーム (バッチ) と無制限のストリーム (ストリーム) を処理できます。 データが Apache Flink で処理された後、ダウンストリーム アプリケーションは、統合されたデータ カタログを使用してキュレートされたデータにアクセスできます。 統一されたメタデータを使用すると、データ処理アプリケーションとデータ消費アプリケーションの両方が、同じメタデータを使用してテーブルにアクセスできます。
この投稿では、Amazon EMR の Apache Flink を AWS Glue Data Catalog と統合して、リアルタイムでストリーミング データを取り込み、ビジネス分析のためにほぼリアルタイムでデータにアクセスできるようにする方法を示します。
Apache Flink コネクタとカタログ アーキテクチャ
Apache Flink は、コネクタとカタログを使用して、データとメタデータを操作します。 次の図は、データの読み取り/書き込み用の Apache Flink コネクタと、メタデータの読み取り/書き込み用のカタログのアーキテクチャを示しています。

データの読み取り/書き込みのために、Flink にはインターフェースがあります DynamicTableSourceFactory 読み取り用と DynamicTableSinkFactory 書き込み用。 別の Flink コネクタは、異なるストレージ内のデータにアクセスするための XNUMX つのインターフェイスを実装します。 たとえば、Flink FileSystem コネクタには FileSystemTableFactory Hadoop Distributed File System (HDFS) または Amazon シンプル ストレージ サービス (Amazon S3)、Flink HBase コネクタには HBase2DynamicTableFactory HBase でデータの読み取り/書き込みを行い、Flink Kafka コネクタには KafkaDynamicTableFactory Kafka でデータを読み書きする。 参照できます テーブルと SQL コネクタ 。
メタデータの読み取り/書き込みのために、Flink にはカタログ インターフェースがあります。 Flink には、カタログ用の XNUMX つの組み込み実装があります。 GenericInMemoryCatalog カタログ データをメモリに保存します。 JdbcCatalog JDBC がサポートするリレーショナル データベースにカタログ データを格納します。 この記事の執筆時点では、MySQL および PostgreSQL データベースが JDBC カタログでサポートされています。 HiveCatalog カタログ データを Hive メタストアに格納します。 HiveCatalog 使用されます HiveShim 異なる Hive バージョンの互換性を提供します。 Hive メタストアまたは AWS Glue データ カタログを使用するように、さまざまなメタストア クライアントを設定できます。 この記事では、 アマゾンEMR 財産 hive.metastore.client.factory.class 〜へ com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory (参照してください AWS Glue Data Catalog を Hive のメタストアとして使用する) AWS Glue Data Catalog を使用して Flink カタログ データを保存できるようにします。 参照する カタログ 。
Kafka などのほとんどの Flink 組み込みコネクタ アマゾンキネシス, Amazon DynamoDB、Elasticsearch、または FileSystem は、Flink を使用できます HiveCatalog メタデータを AWS Glue データカタログに保存します。 ただし、Apache Iceberg などの一部のコネクタ実装には、独自のカタログ管理メカニズムがあります。 FlinkCatalog in Iceberg は、Flink でカタログ インターフェイスを実装します。 FlinkCatalog in Iceberg には、独自のカタログ実装へのラッパーがあります。 次の図は、Apache Flink、Iceberg コネクタ、およびカタログの関係を示しています。 詳細については、次を参照してください。 カタログの作成とカタログの使用 & カタログ.

Apache Hudi には、独自のカタログ管理機能もあります。 両方 HoodieCatalog & HoodieHiveCatalog Flink でカタログ インターフェイスを実装します。 HoodieCatalog HDFS などのファイル システムにメタデータを格納します。 HoodieHiveCatalog 設定するかどうかに応じて、Hive メタストアまたは AWS Glue データカタログにメタデータを保存します hive.metastore.client.factory.class 使用する com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory. 次の図は、Apache Flink、Hudi コネクタ、およびカタログの関係を示しています。 詳細については、次を参照してください。 カタログを作成.

Iceberg と Hudi はカタログ管理メカニズムが異なるため、この投稿では Flink と AWS Glue Data Catalog の統合の XNUMX つのシナリオを示します。
- Glue Data Catalog のメタデータを使用して Flink の Iceberg テーブルに読み取り/書き込み
- Glue Data Catalog のメタデータを使用した Flink の Hudi テーブルへの読み取り/書き込み
- Glue Data Catalog のメタデータを使用して、Flink の他のストレージ形式に読み取り/書き込み
ソリューションの概要
次の図は、この投稿で説明したソリューションの全体的なアーキテクチャを示しています。

このソリューションでは、 MySQL用AmazonRDS binlog を使用して、トランザクションの変更をリアルタイムで抽出します。 Amazon EMR Flink CDC コネクタは、binlog データを読み取り、データを処理します。 変換されたデータは Amazon S3 に保存できます。 AWS Glue Data Catalog を使用して、テーブル スキーマやテーブルの場所などのメタデータを保存します。 次のようなダウンストリーム データ コンシューマ アプリケーション アマゾンアテナ または Amazon EMR Trino は、ビジネス分析のためにデータにアクセスします。
以下は、このソリューションをセットアップする大まかな手順です。
- 有効にします
binlogAmazon RDS for MySQL の場合、データベースを初期化します。 - AWS Glue データカタログを使用して EMR クラスターを作成します。
- Amazon EMR の Apache Flink CDC を使用して変更データキャプチャ (CDC) データを取り込みます。
- 処理されたデータをメタデータとともに Amazon S3 に保存し、AWS Glue Data Catalog に保存します。
- すべてのテーブル メタデータが AWS Glue データ カタログに保存されていることを確認します。
- ビジネス分析のために Athena または Amazon EMR Trino でデータを消費します。
- Amazon RDS for MySQL のソース レコードを更新および削除し、データ レイク テーブルの反映を検証します。
前提条件
この投稿では AWS IDおよびアクセス管理 次のサービスに対するアクセス許可を持つ (IAM) ロール:
- Amazon RDS for MySQL (5.7.40)
- アマゾン EMR (6.9.0)
- アマゾンアテナ
- AWSGlueデータカタログ
- アマゾンS3
Amazon RDS for MySQL の binlog を有効にしてデータベースを初期化する
Amazon RDS for MySQL で CDC を有効にするには、Amazon RDS for MySQL のバイナリログを設定する必要があります。 参照する MySQL バイナリ ログの構成 詳細については。 データベースも作成します salesdb MySQLでテーブルを作成します customer, orderなどを使用して、データ ソースを設定します。
- Amazon RDS コンソールで、 パラメータグループ ナビゲーションペインに表示されます。
- MySQL の新しいパラメーター グループを作成します。
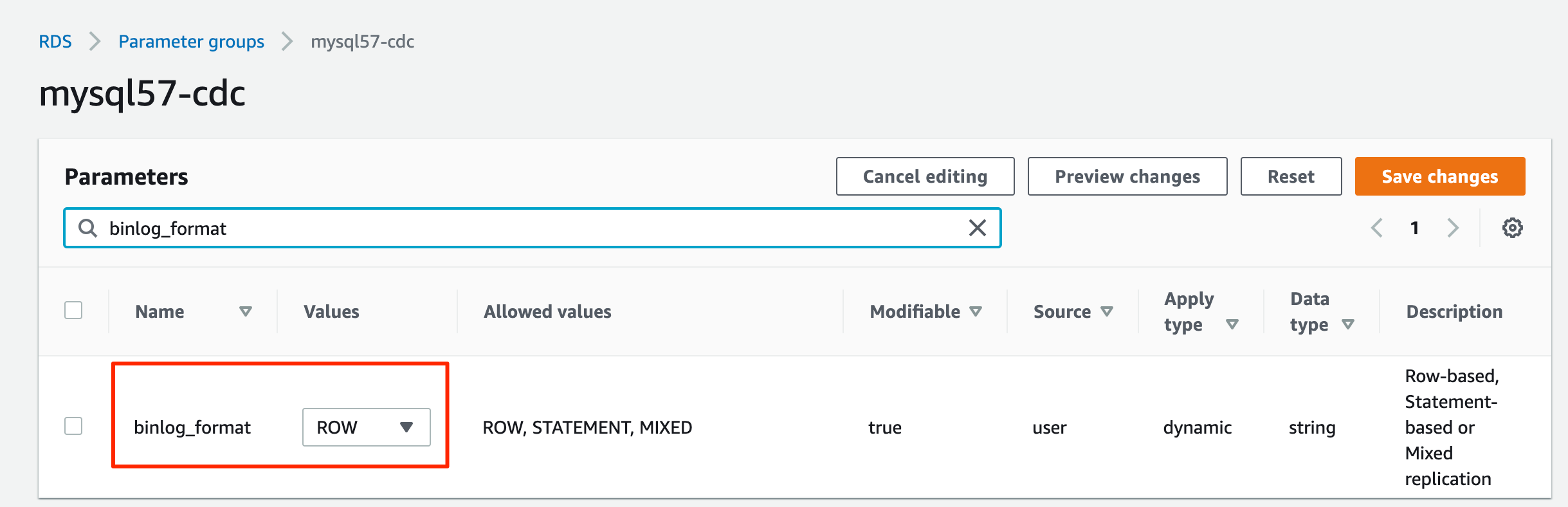
- 作成したパラメータ グループを編集して設定します
binlog_format=ROW.
- 作成したパラメータ グループを編集して設定します
binlog_row_image=full.

- パラメータグループを使用して RDS for MySQL DB インスタンスを作成します。
- の値を書き留めます。
hostname,username,password、後で使用します。 - 次のコマンドを実行して、Amazon S3 から MySQL データベース初期化スクリプトをダウンロードします。
- RDS for MySQL データベースに接続し、
salesdb.sqlコマンドを実行してデータベースを初期化し、RDS for MySQL データベース構成に従ってホスト名とユーザー名を指定します。
AWS Glue データカタログを使用して EMR クラスターを作成する
Amazon EMR 6.9.0 から、Flink テーブル API/SQL は AWS Glue Data Catalog と統合できます。 Flink と AWS Glue の統合を使用するには、Amazon EMR 6.9.0 以降のバージョンを作成する必要があります。
- ファイルを作成する
iceberg.propertiesAmazon EMR Trino と Data Catalog の統合用。 テーブル形式が Iceberg の場合、ファイルには次の内容が含まれている必要があります。
- アップロード
iceberg.propertiesたとえば、S3バケットにDOC-EXAMPLE-BUCKET.
Amazon EMR Trino と Iceberg を統合する方法の詳細については、次を参照してください。 Trino で Iceberg クラスターを使用する.
- ファイルを作成する
trino-glue-catalog-setup.shTrino と Data Catalog の統合を構成します。 使用するtrino-glue-catalog-setup.shブートストラップ スクリプトとして。 ファイルには次の内容が含まれている必要があります (DOC-EXAMPLE-BUCKETS3バケット名を使用):
- アップロード
trino-glue-catalog-setup.shS3 バケットに (DOC-EXAMPLE-BUCKET).
参照する 追加のソフトウェアをインストールするためのブートストラップ アクションを作成する ブートストラップ スクリプトを実行します。
- ファイルを作成する
flink-glue-catalog-setup.shFlink と Data Catalog の統合を構成します。 - スクリプト ランナーを使用して、
flink-glue-catalog-setup.shステップ関数としてのスクリプト。
ファイルには次の内容が含まれている必要があります (ここでの JAR ファイル名は Amazon EMR 6.9.0 を使用しています。それ以降のバージョンの JAR 名は変更される可能性があるため、Amazon EMR のバージョンに従って必ず更新してください)。
ここでは、ブートストラップではなく Amazon EMR ステップを使用して、このスクリプトを実行していることに注意してください。 Amazon EMR Flink がプロビジョニングされた後、Amazon EMR ステップ スクリプトが実行されます。
- アップロード
flink-glue-catalog-setup.shS3 バケットに (DOC-EXAMPLE-BUCKET).
参照する Amazon EMR で Flink to Hive メタストアを設定する Flink および Hive メタストアの構成方法の詳細については、 を参照してください。 参照する Amazon EMR クラスターでコマンドとスクリプトを実行する Amazon EMR ステップ スクリプトの実行の詳細については、
- アプリケーション Hive、Flink、および Trino を使用して EMR 6.9.0 クラスターを作成します。
を使用して EMR クラスターを作成できます。 AWSコマンドラインインターフェイス (AWS CLI)または AWSマネジメントコンソール. 手順については、該当するサブセクションを参照してください。
AWS CLI で EMR クラスターを作成する
AWS CLI を使用するには、次の手順を完了します。
- ファイルを作成する
emr-flink-trino-glue.jsonData Catalog を使用するように Amazon EMR を設定します。 ファイルには次の内容が含まれている必要があります。
- 次のコマンドを実行して、EMR クラスターを作成します。 あなたの地元を提供してください
emr-flink-trino-glue.json親フォルダーのパス、S3 バケット、EMR クラスターのリージョン、EC2 キー名、および EMR ログの S3 バケット。
コンソールで EMR クラスターを作成する
コンソールを使用するには、次の手順を実行します。
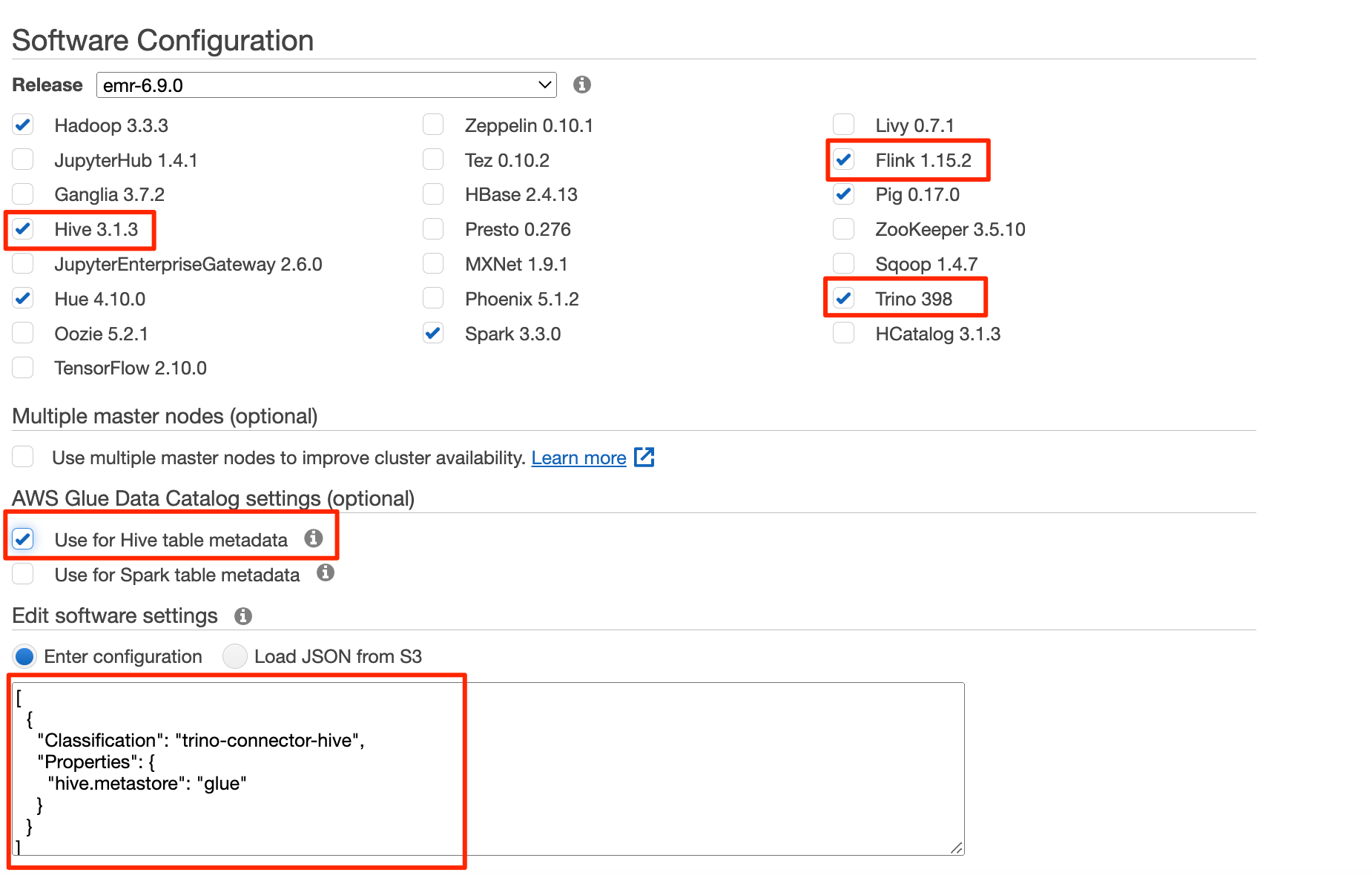
- Amazon EMR コンソールで、EMR クラスターを作成し、 Hive テーブルのメタデータに使用 for AWSGlueデータカタログ 設定を行います。
- 次のコードを使用して構成設定を追加します。
- ステップ セクションに、というステップを追加します。 カスタム JAR.
- 作成セッションプロセスで JAR の場所 〜へ
s3://<region>.elasticmapreduce/libs/script-runner/script-runner.jarここで、 EMR クラスターが存在するリージョンです。 - 作成セッションプロセスで Arguments 以前にアップロードした S3 パスに。

- ブートストラップアクション セクションでは、選択 カスタムアクション.
- 作成セッションプロセスで スクリプトの場所 アップロードした S3 パスに。

- 以降の手順を続行して、EMR クラスターの作成を完了します。
Amazon EMR で Apache Flink CDC を使用して CDC データを取り込む
Flink CDC コネクタは、データベース スナップショットの読み取りをサポートし、構成されたテーブルの更新をキャプチャします。 ダウンロードにより、MySQL 用の Flink CDC コネクタをデプロイしました。 flink-sql-connector-mysql-cdc-2.2.1.jar EMR クラスターを作成するときに Flink ライブラリに入れます。 Flink CDC コネクタは、Flink Hive カタログを使用して、Flink CDC テーブル スキーマを Hive メタストアまたは AWS Glue データ カタログに保存できます。 この投稿では、Data Catalog を使用して Flink CDC テーブルを保存します。
Flink CDC を使用して RDS for MySQL データベースとテーブルを取り込み、Data Catalog にメタデータを保存するには、次の手順を実行します。
- EMR プライマリ ノードに SSH で接続します。
- 次のコマンドを実行し、S3 バケット名を指定して、YARN セッションで Flink を開始します。
- 次のコマンドを実行して、Flink SQL クライアント CLI を開始します。
- カタログ タイプを次のように指定して、Flink Hive カタログを作成します。
hiveS3 バケット名を指定します。
AWS Glue Data Catalog を使用して EMR Hive カタログを構成しているため、Flink Hive カタログで作成されたすべてのデータベースとテーブルは Data Catalog に保存されます。
- 前に作成した RDS for MySQL インスタンスのホスト名、ユーザー名、およびパスワードを指定して、Flink CDC テーブルを作成します。
RDS for MySQL のユーザー名とパスワードはテーブル プロパティとしてデータ カタログに保存されるため、有効にする必要があることに注意してください。 AWS Lake Formation による AWS Glue データベース/テーブル認証 機密データを保護します。
- 作成したテーブルに対してクエリを実行します。
次のスクリーンショットのようなクエリ結果が得られます。

処理されたデータを Amazon S3 に保存し、メタデータを Data Catalog に保存する
Amazon RDS for MySQL でリレーショナル データベース データを取り込んでいるため、生データが更新または削除される場合があります。 データの更新と削除をサポートするために、Apache Iceberg や Apache Hudi などのデータ レイク テクノロジを選択して、処理されたデータを保存できます。 前述したように、Iceberg と Hudi ではカタログ管理が異なります。 Flink を使用して、AWS Glue データカタログのメタデータを含む Iceberg テーブルと Hudi テーブルを読み書きする両方のシナリオを示します。
非 Iceberg および非 Hudi の場合、FileSystem Parquet ファイルを使用して、Flink 組み込みコネクタがデータ カタログを使用する方法を示します。
Glue Data Catalog のメタデータを使用して Flink の Iceberg テーブルに読み取り/書き込み
次の図は、この構成のアーキテクチャを示しています。

- 指定することにより、Data Catalog を使用して Flink Iceberg カタログを作成します。
catalog-implasorg.apache.iceberg.aws.glue.GlueCatalog.
Iceberg の Flink と Data Catalog の統合の詳細については、次を参照してください。 のりカタログ.
- Flink SQL クライアント CLI で、S3 バケット名を指定して次のコマンドを実行します。
- 処理されたデータを格納する Iceberg テーブルを作成します。
- 処理されたデータを Iceberg に挿入します。
Glue Data Catalog のメタデータを使用した Flink の Hudi テーブルへの読み取り/書き込み
次の図は、この構成のアーキテクチャを示しています。

次の手順を完了します。
- 指定して、Hive カタログを使用する Hudi のカタログを作成します。
modeashms.
EMR クラスターを作成したときに Data Catalog を使用するように Amazon EMR を設定済みであるため、この Hudi Hive カタログは内部で Data Catalog を使用します。 Hudi の Flink と Data Catalog の統合の詳細については、次を参照してください。 カタログを作成.
- Flink SQL クライアント CLI で、S3 バケット名を指定して次のコマンドを実行します。
- Data Catalog を使用して Hudi テーブルを作成し、S3 バケット名を指定します。
- 処理されたデータを Hudi に挿入します。
Glue Data Catalog のメタデータを使用して、Flink の他のストレージ形式に読み取り/書き込み
次の図は、この構成のアーキテクチャを示しています。

前のステップで既に Flink Hive カタログを作成しているので、そのカタログを再利用します。
- Flink SQL クライアント CLI で、次のコマンドを実行します。
SQL ダイアレクトを Hive に変更して、Hive 構文でテーブルを作成します。
- 次の SQL でテーブルを作成し、S3 バケット名を指定します。
Parquet ファイルは更新された行をサポートしていないため、CDC データからデータを使用することはできません。 ただし、Iceberg または Hudi からのデータを使用することはできます。
- 次のコードを使用して、Iceberg テーブルにクエリを実行し、Parquet テーブルにデータを挿入します。
すべてのテーブル メタデータが Data Catalog に格納されていることを確認する
AWS Glue コンソールに移動して、すべてのテーブルが Data Catalog に保存されていることを確認できます。
- AWS Glue コンソールで、選択します データベース をクリックして、作成したすべてのデータベースを一覧表示します。

- データベースを開き、すべてのテーブルがそのデータベースにあることを確認します。

ビジネス分析のために Athena または Amazon EMR Trino でデータを消費する
Athena または Amazon EMR Trino を使用して、結果データにアクセスできます。
Athena を使用してデータをクエリする
Athena を使用してデータにアクセスするには、次の手順を実行します。
- Athena クエリ エディターを開きます。
- 選択する
flink_glue_iceberg_dbfor データベース.
あなたは customer_summary テーブルがリストされています。
- 次の SQL スクリプトを実行して、Iceberg 結果テーブルを照会します。
クエリの結果は、次のスクリーンショットのようになります。

- Hudi テーブルの場合は、変更します データベース 〜へ
flink_glue_hudi_db同じ SQL クエリを実行します。

- Parquet テーブルの場合は、変更します データベース 〜へ
flink_hive_parquet_db同じ SQL クエリを実行します。

Amazon EMR Trino でデータをクエリする
Amazon EMR Trino で Iceberg にアクセスするには、EMR プライマリ ノードに SSH 接続します。
- 次のコマンドを実行して、Trino CLI を開始します。
Amazon EMR Trino は、AWS Glue データカタログのテーブルをクエリできるようになりました。
- 次のコマンドを実行して、結果テーブルをクエリします。
クエリの結果は、次のスクリーンショットのようになります。

- Trino CLI を終了します。
- Trino CLI を開始します。
hiveHudi テーブルを照会するためのカタログ:
- 次のコマンドを実行して、Hudi テーブルを照会します。
Amazon RDS for MySQL のソース レコードを更新および削除し、データ レイク テーブルの反映を検証する
RDS for MySQL データベースの一部のレコードを更新および削除し、変更が Iceberg および Hudi テーブルに反映されていることを確認できます。
- RDS for MySQL データベースに接続し、次の SQL を実行します。
- クエリ
customer_summaryAthena または Amazon EMR Trino を使用したテーブル。
更新および削除されたレコードは、Iceberg および Hudi テーブルに反映されます。

クリーンアップ
この演習が終了したら、次の手順を実行してリソースを削除し、コストの発生を防ぎます。
- RDS for MySQL データベースを削除します。
- EMR クラスターを削除します。
- Data Catalog で作成されたデータベースとテーブルを削除します。
- Amazon S3 のファイルを削除します。
まとめ
この投稿では、Amazon EMR の Apache Flink を AWS Glue データカタログと統合する方法を示しました。 Flink SQL コネクタを使用して、Kafka、CDC、HBase、Amazon S3、Iceberg、または Hudi などの別のストアでデータを読み書きできます。 メタデータを Data Catalog に保存することもできます。 Flink テーブル API には、同じコネクタとカタログの実装メカニズムがあります。 XNUMX つのセッションで、さまざまなタイプを指す複数のカタログ インスタンスを使用できます。 IcebergCatalog & HiveCatalog、クエリで then を同じ意味で使用します。 Flink テーブル API を使用してコードを記述し、Flink と Data Catalog を統合する同じソリューションを開発することもできます。
私たちのソリューションでは、RDS for MySQL バイナリ ログを Flink CDC で直接使用しました。 使用することもできます アマゾンMSKコネクト でバイナリログを消費する MySQL デベジム データを保存します ApacheKafkaのAmazonマネージドストリーミング (アマゾン MSK)。 参照する Amazon MSK Connect、Apache Flink、およびApache Hudiを使用して、低レイテンシのソースからデータレイクへのパイプラインを作成します 。
Amazon EMR Flink の統合されたバッチおよびストリーミング データ処理機能を使用すると、XNUMX つのコンピューティング エンジンでデータの取り込みと処理を行うことができます。 Amazon EMR に統合された Apache Iceberg と Hudi を使用すると、進化可能でスケーラブルなデータレイクを構築できます。 AWS Glue Data Catalog を使用すると、すべてのエンタープライズ データ カタログを統一された方法で管理し、データを簡単に使用できます。
この投稿の手順に従って、Amazon EMR Flink と AWS Glue データ カタログを使用して統合バッチおよびストリーミング ソリューションを構築します。 ご不明な点がございましたら、コメントを残してください。
著者について
 ジャンウェイ・リー シニア アナリティクス スペシャリストの TAM です。 彼は、AWS エンタープライズ サポートの顧客が最新のデータ プラットフォームを設計および構築するためのコンサルタント サービスを提供しています。
ジャンウェイ・リー シニア アナリティクス スペシャリストの TAM です。 彼は、AWS エンタープライズ サポートの顧客が最新のデータ プラットフォームを設計および構築するためのコンサルタント サービスを提供しています。

サムラット・デブ Amazon EMR のソフトウェア開発エンジニアです。 余暇には、新しい場所、異なる文化、食べ物を探索するのが大好きです。

プラブ ジョセフラジ は、Amazon EMR で働くシニア ソフトウェア開発エンジニアです。 彼は、Apache Hadoop と Apache Flink でソリューションを構築するチームを率いることに専念しています。 余暇には、プラブーは家族と過ごす時間を楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/build-a-unified-data-lake-with-apache-flink-on-amazon-emr/

