Amazon SageMakerオートパイロットは、表形式のデータに基づいて最適な ML モデルを自動的に構築、トレーニング、調整するローコード機械学習 (ML) サービスであり、現在、 AmazonSageMakerパイプラインは、ML 向けの最初の専用の継続的インテグレーションおよび継続的デリバリー (CI/CD) サービスです。 これにより、Autopilot を使用して ML モデルを構築し、モデルを後続の CI/CD ステップに統合するエンドツーエンドのフローを自動化できます。
これまでのところ、Pipelines 内で Autopilot 実験を開始するには、Pipelines とのカスタム統合コードを記述してモデル構築ワークフローを構築する必要があります ラムダ or 処理 ステップ。 詳細については、次を参照してください。 Amazon SageMaker パイプラインを使用して、Amazon SageMaker Autopilot ML モデルを実験から本番環境に移行する.
Pipelines 内のネイティブ ステップとしての Autopilot のサポートにより、自動化されたトレーニング ステップを追加できるようになりました (AutoMLStep) をパイプラインで使用し、Autopilot の実験を呼び出します。 合体練習モード. たとえば、Pipelines を使用して不正検出ユースケースのトレーニングと評価の ML ワークフローを構築している場合、AutoML ステップを使用して Autopilot 実験を開始できるようになりました。これにより、複数の試行が自動的に実行され、特定の入力データセットで最適なモデルが検出されます。 . を使用して最適なモデルが作成された後、 モデルステップ、そのパフォーマンスは、を使用してテスト データで評価できます。 変換ステップ フォルダーとその下に 処理ステップ Pipelines 内のカスタム評価スクリプト用。 最終的に、モデルは SageMaker モデルレジストリに登録できます。 モデルステップ と組み合わせて 条件ステップ.
この投稿では、エンドツーエンドの ML ワークフローを作成して、パイプラインで新しく開始された AutoML ステップを使用して SageMaker で生成された ML モデルをトレーニングおよび評価し、それを SageMaker モデル レジストリに登録する方法を示します。 最高のパフォーマンスを持つ ML モデルは、SageMaker エンドポイントにデプロイできます。
データセットの概要
公開されているものを使用します UCI Adult 1994 Census Income データセット 個人の年収が 50,000 ドルを超えるかどうかを予測します。 これはバイナリ分類の問題です。 収入ターゲット変数のオプションは、<=50K または >50K です。
データセットには、トレーニングと検証用に 32,561 行、テスト用に 16,281 行、それぞれ 15 列が含まれています。 これには、個人に関する人口統計情報が含まれます。 class 所得階級を示す対象列として。
| 列名 | 説明 |
| 年齢 | 連続的な |
| ワーククラス | 私立、非営利の自営、株式会社自営業、連邦政府、地方政府、州政府、無給、無職 |
| fnlwgt | 連続的な |
| 教育 | 学士号、一部の大学、11 番目、HS 卒業生、教授学校、Assoc-acdm、Assoc-voc、9 番目、7 番目から 8 番目、12 番目、修士号、1 番目から 4 番目、10 番目、博士号、5 番目から 6 番目、幼稚園 |
| 教育-num | 連続的な |
| 配偶者の有無 | 既婚市民配偶者、離婚、未婚、別居、未亡人、既婚配偶者不在、既婚AF配偶者 |
| 職業 | 技術サポート、クラフト修理、その他のサービス、販売、エグゼクティブ管理、専門職、ハンドラー - クリーナー、機械操作 - 検査、管理 - 事務、農業 - 釣り、輸送 - 移動、プライベートハウス - サービス、防衛軍、軍隊 |
| 関係 | 妻、実子、夫、別居、他親族、未婚 |
| レース | ホワイト、アジア太平洋諸島人、アメリカインディアンエスキモー、その他、ブラック |
| セックス | 女性、男性 |
| 資本利得 | 連続的な |
| キャピタルロス | 連続的な |
| 週数時間 | 連続的な |
| 母国 | 米国、カンボジア、イギリス、プエルトリコ、カナダ、ドイツ、米国外(グアム-USVIなど)、インド、日本、ギリシャ、南、中国、キューバ、イラン、ホンジュラス、フィリピン、イタリア、ポーランド、ジャマイカ、ベトナム、メキシコ、ポルトガル、アイルランド、フランス、ドミニカ共和国、ラオス、エクアドル、台湾、ハイチ、コロンビア、ハンガリー、グアテマラ、ニカラグア、スコットランド、タイ、ユーゴスラビア、エルサルバドル、トリナダード・トバゴ、ペルー、ホン、オランダ・オランダ |
| class | 収入クラス、<=50K または >50K |
ソリューションの概要
パイプラインを使用してさまざまなオーケストレーションを行います パイプラインのステップ Autopilot モデルのトレーニングに必要です。 私たちは、 自動操縦実験 このチュートリアルで説明されているように、AutoML ステップの一部として。
このエンドツーエンドのオートパイロット トレーニング プロセスには、次の手順が必要です。
- を使用して Autopilot トレーニング ジョブを作成および監視する
AutoMLStep. - を使用して SageMaker モデルを作成する
ModelStep. このステップでは、前のステップで Autopilot によってレンダリングされた最適なモデルのメタデータとアーティファクトを取得します。 - を使用して、テスト データセットでトレーニング済みの Autopilot モデルを評価します。
TransformStep. - 以前の実行からの出力を比較します
TransformStepを使用して実際のターゲットラベルを使用ProcessingStep. - ML モデルを SageMakerモデルレジストリ
ModelStep、以前に取得した評価メトリックが定義済みのしきい値を超えた場合ConditionStep. - テスト目的で、ML モデルを SageMaker エンドポイントとしてデプロイします。
アーキテクチャ
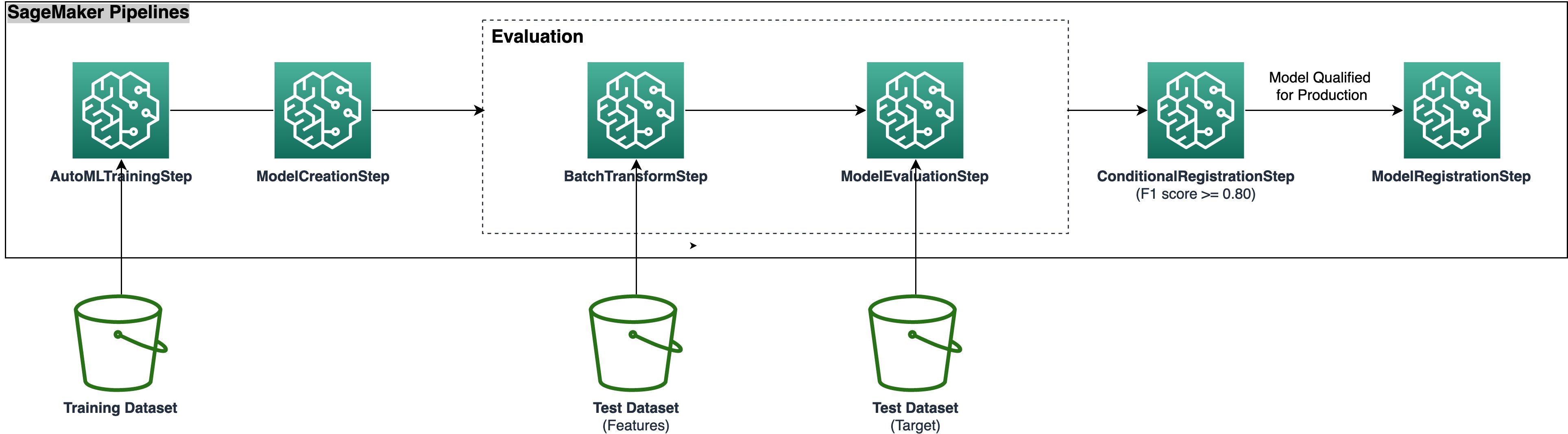
以下のアーキテクチャ図は、再現可能で自動化されたスケーラブルな SageMaker Autopilot トレーニング パイプラインにすべてのステップをパッケージ化するために必要なさまざまなパイプライン ステップを示しています。 データファイルは S3 バケットから読み取られ、パイプラインステップが順番に呼び出されます。
チュートリアル
この投稿では、パイプラインの手順について詳しく説明しています。 コードを確認し、各ステップのコンポーネントについて説明します。 ソリューションをデプロイするには、 サンプルノートでは、パイプラインを使用して Autopilot MLOps ワークフローを実装するための段階的な手順を説明しています。
前提条件
次の前提条件を完了します。
データセットを使用する準備ができたら、Autopilot を使用して ML モデルを自動的に構築およびトレーニングするための反復可能なプロセスを確立するために、パイプラインをセットアップする必要があります。 私たちは、 SageMaker SDK エンドツーエンドの ML トレーニング パイプラインをプログラムで定義、実行、追跡します。
パイプラインの手順
以下のセクションでは、AutoML トレーニング、モデル作成、バッチ推論、評価、最適なモデルの条件付き登録など、SageMaker パイプラインのさまざまなステップについて説明します。 次の図は、パイプライン フロー全体を示しています。

AutoML トレーニング ステップ
An AutoML オブジェクト Autopilot トレーニングジョブの実行を定義するために使用され、次を使用して SageMaker パイプラインに追加できます。 AutoMLStep 次のコードに示すように、クラス。 アンサンブル トレーニング モードを指定する必要がありますが、必要に応じて他のパラメーターを調整できます。 たとえば、AutoML ジョブに ML を自動的に推論させる代わりに、 問題の種類 & 客観的指標、これらを指定することでハードコーディングできます problem_type & job_objective AutoML オブジェクトに渡されるパラメーター。
モデル作成ステップ
AutoML ステップでは、さまざまな ML モデルの候補を生成し、それらを組み合わせて、最適な ML モデルを取得します。 モデル アーティファクトとメタデータは自動的に保存され、 get_best_auto_ml_model() AutoML トレーニング ステップのメソッド。 これらを使用して、Model ステップの一部として SageMaker モデルを作成できます。
バッチ変換および評価ステップ
私たちは、使用 変圧器オブジェクト for バッチ推論 これは、評価目的で使用できます。 出力予測は、Scikit-learn メトリクス関数を使用して、実際のラベルまたはグラウンド トゥルース ラベルと比較されます。 に基づいて結果を評価します。 F1スコア. パフォーマンス メトリックは JSON ファイルに保存され、後続の手順でモデルを登録するときに参照されます。
条件付き登録手順
このステップでは、事前定義された評価メトリクスのしきい値を超えた場合に、新しいオートパイロット モデルを SageMaker モデル レジストリに登録します。
パイプラインを作成して実行する
ステップを定義したら、それらを SageMaker パイプラインに結合します。
ステップは順番に実行されます。 パイプラインは、Autopilot と Pipelines を使用して AutoML ジョブのすべてのステップを実行し、トレーニング、モデル評価、モデル登録を行います。
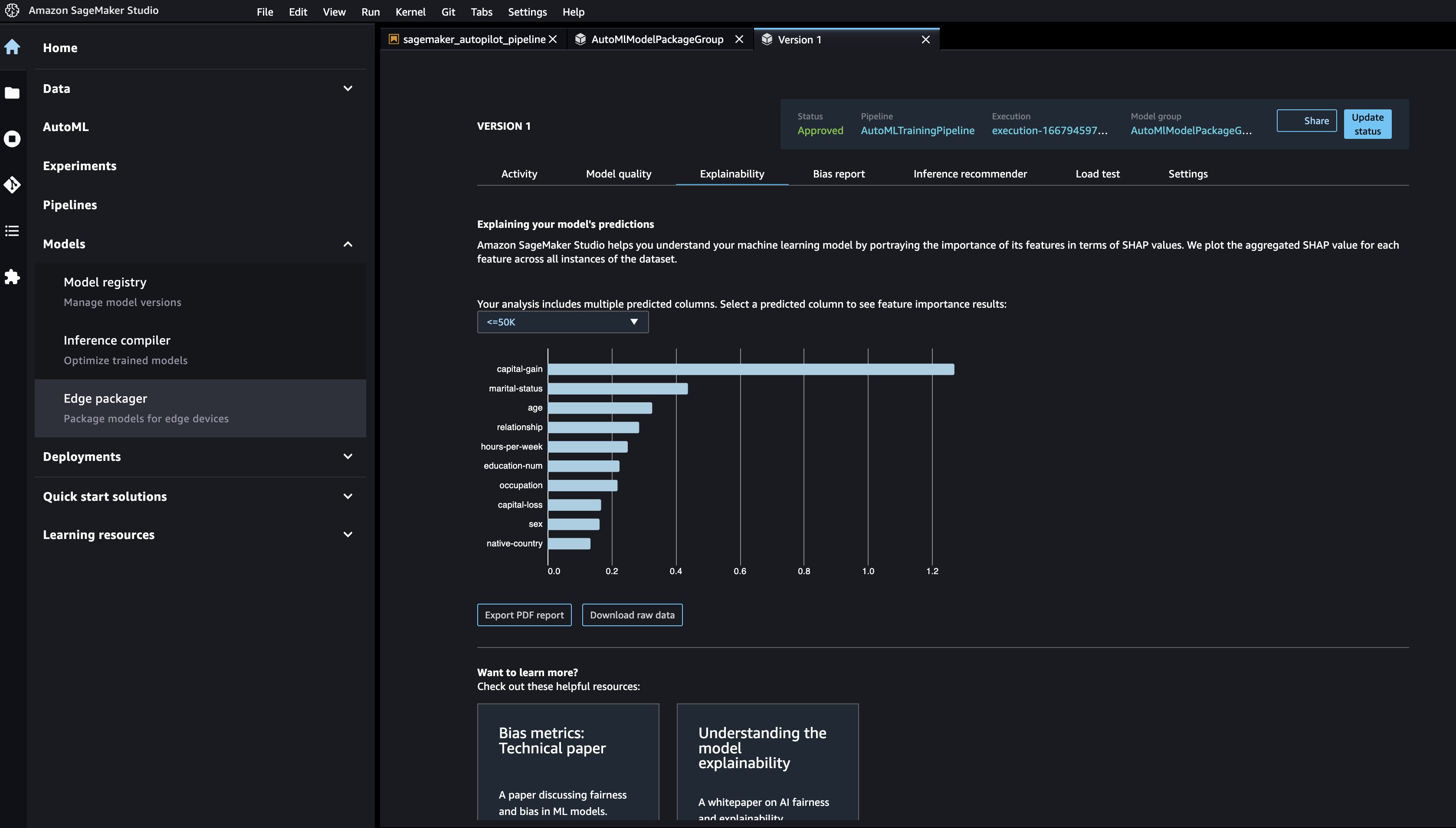
Studio コンソールのモデル レジストリに移動して開くと、新しいモデルを表示できます。 AutoMLModelPackageGroup. トレーニング ジョブの任意のバージョンを選択して、 モデルの品質 タブには何も表示されないことに注意してください。

説明可能性レポートは、 説明可能 タブをクリックして、モデルの予測を理解します。
で作成されたすべてのモデルの基になる Autopilot 実験を表示するには AutoMLStep、 AutoML ページを開き、ジョブ名を選択します。

モデルを展開する
ML モデルのパフォーマンスを手動で確認したら、新しく作成したモデルを SageMaker エンドポイントにデプロイできます。 このために、SageMaker モデルレジストリに保存されたモデル設定を使用して、モデルエンドポイントを作成するノートブックでセルを実行できます。
このスクリプトはデモンストレーション目的で共有されていることに注意してください。ただし、ML 推論の本番環境へのデプロイには、より堅牢な CI/CD パイプラインに従うことをお勧めします。 詳細については、次を参照してください。 Amazon SageMakerパイプラインを使用したMLワークフローの構築、自動化、管理、スケーリング.
まとめ
この投稿では、Autopilot、Pipelines、および Studio を使用して、表形式の ML モデル (AutoML) を自動的にトレーニングするための使いやすい ML パイプライン アプローチについて説明します。 AutoML は ML 実践者の効率を改善し、ML の実験から本番環境へのパスを加速します。ML に関する広範な専門知識は必要ありません。 ML モデルの作成、評価、登録に必要なそれぞれのパイプライン ステップの概要を説明します。 を試すことから始めましょう サンプルノート 独自のカスタム AutoML モデルをトレーニングしてデプロイします。
オートパイロットとパイプラインの詳細については、次を参照してください。 AmazonSageMakerAutopilotを使用してモデル開発を自動化する & AmazonSageMakerパイプライン.
立ち上げにご協力いただきました皆様に心より感謝申し上げます: 越聖華、ジョン・ヘ、アオ・グオ、シンルー・トゥ、ティアン・チン、ヤンダ・フー、ザンクイ・ルー、ディーウェン・チー。
著者について
 ジャニシャ・アナンド SageMaker Autopilot を含む SageMaker Low/No Code ML チームのシニア プロダクト マネージャーです。 彼女はコーヒーを楽しみ、アクティブに過ごし、家族と過ごす時間を楽しんでいます。
ジャニシャ・アナンド SageMaker Autopilot を含む SageMaker Low/No Code ML チームのシニア プロダクト マネージャーです。 彼女はコーヒーを楽しみ、アクティブに過ごし、家族と過ごす時間を楽しんでいます。
 マルセロ・アバーレ AWS AI の ML エンジニアです。 彼が手伝います Amazon MLソリューションラボ お客様は、スケーラブルな ML(-Ops) システムとフレームワークを構築します。 余暇には、サンフランシスコのベイエリアでハイキングやサイクリングを楽しんでいます。
マルセロ・アバーレ AWS AI の ML エンジニアです。 彼が手伝います Amazon MLソリューションラボ お客様は、スケーラブルな ML(-Ops) システムとフレームワークを構築します。 余暇には、サンフランシスコのベイエリアでハイキングやサイクリングを楽しんでいます。
 ジェレミー・コーエン はAWSのソリューションアーキテクトであり、顧客が最先端のクラウドベースのソリューションを構築するのを支援しています。 余暇には、ビーチを散歩したり、家族と一緒にベイエリアを探索したり、家の周りの物を修理したり、家の周りの物を壊したり、バーベキューを楽しんだりしています。
ジェレミー・コーエン はAWSのソリューションアーキテクトであり、顧客が最先端のクラウドベースのソリューションを構築するのを支援しています。 余暇には、ビーチを散歩したり、家族と一緒にベイエリアを探索したり、家の周りの物を修理したり、家の周りの物を壊したり、バーベキューを楽しんだりしています。
 盛華越 Amazon SageMaker のソフトウェア開発エンジニアです。 彼女は、顧客向けの ML ツールと製品の構築に注力しています。 仕事以外では、アウトドア、ヨガ、ハイキングを楽しんでいます。
盛華越 Amazon SageMaker のソフトウェア開発エンジニアです。 彼女は、顧客向けの ML ツールと製品の構築に注力しています。 仕事以外では、アウトドア、ヨガ、ハイキングを楽しんでいます。
- コインスマート。 ヨーロッパで最高のビットコインと暗号通貨取引所。ここをクリック
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/launch-amazon-sagemaker-autopilot-experiments-directly-from-within-amazon-sagemaker-pipelines-to-easily-automate-mlops-workflows/

