今日のデータ主導の世界では、多様なプラットフォーム間でデータを簡単に移動および分析できる機能が不可欠です。 アマゾンアプリフローフルマネージドのデータ統合サービスである は、AWS のサービス、SaaS (Software as a Service) アプリケーション、そして現在は Google BigQuery 間のデータ転送の合理化の最前線に立っています。 このブログ投稿では、新しい機能を探索します Google BigQuery コネクタ Amazon AppFlow を使用して、Google のデータ ウェアハウスから Google のデータ ウェアハウスにデータを転送するプロセスがどのように簡素化されるかを確認してください。 Amazon Simple Storage Service(Amazon S3)、マルチクラウド データ アクセスの民主化など、データ専門家や組織に大きなメリットをもたらします。
Amazon AppFlowの概要
アマゾンアプリフロー Google BigQuery、Salesforce、SAP、Hubspot、ServiceNow などの SaaS アプリケーションと、Amazon S3 などの AWS サービスとの間でデータを安全に転送するために使用できるフルマネージド統合サービスです。 Amazonレッドシフト、数回クリックするだけで完了します。 Amazon AppFlow を使用すると、スケジュールに従って、ビジネス イベントに応じて、またはオンデマンドで、選択した頻度でほぼあらゆる規模のデータ フローを実行できます。 追加の手順を行わずに、フィルタリングや検証などのデータ変換機能を構成して、フロー自体の一部としてすぐに使用できる豊富なデータを生成できます。 Amazon AppFlow は、移動中のデータを自動的に暗号化し、Amazon AppFlow と統合されている SaaS アプリケーションのパブリック インターネット上を流れるデータを制限できます。 AWS プライベートリンク、セキュリティの脅威にさらされる可能性を減らします。
Google BigQuery コネクタの紹介
新しい Google BigQuery コネクタ Amazon AppFlow は、Google のデータ ウェアハウスの分析機能を利用し、BigQuery からのデータを簡単に統合、分析、保存、またはさらに処理して実用的な洞察に変換することを目指す組織に可能性を明らかにします。
アーキテクチャ
Amazon AppFlow を使用して Google BigQuery から Amazon S3 にデータを転送するアーキテクチャを確認してみましょう。

- データ ソースを選択します: アマゾンアプリフロー、データ ソースとして Google BigQuery を選択します。 データを抽出するテーブルまたはデータセットを指定します。
- フィールドのマッピングと変換: Amazon AppFlow の直感的なビジュアルインターフェイスを使用してデータ転送を設定します。 データフィールドをマップし、必要に応じて変換を適用して、データを要件に合わせることができます。
- 転送頻度: 柔軟性と自動化をサポートするために、データを転送する頻度 (毎日、毎週、毎月など) を決定します。
- 宛先: データの宛先として S3 バケットを指定します。 Amazon AppFlow はデータを効率的に移動し、Amazon S3 ストレージ内でデータにアクセスできるようにします。
- 消費: 使用 アマゾンアテナ Amazon S3 のデータを分析します。
前提条件
このソリューションで使用されるデータセットは、 シンセア、合成患者集団シミュレータおよびオープンソース プロジェクト Apacheライセンス2.0。 このデータを Google BigQuery に読み込むか、既存のデータセットを使用します。
Amazon AppFlow を Google BigQuery アカウントに接続する
この投稿では、Google アカウント、適切な権限を持つ OAuth クライアント、および Google BigQuery データを使用します。 Amazon AppFlow から Google BigQuery アクセスを有効にするには、事前に新しい OAuth クライアントを設定する必要があります。 手順については、を参照してください。 Amazon AppFlow 用の Google BigQuery コネクタ.
Amazon S3 をセットアップする
Amazon S3 内のすべてのオブジェクトはバケットに保存されます。 データを Amazon S3 に保存する前に、次のことを行う必要があります。 S3バケットを作成する 結果を保存します。
Amazon AppFlow 結果用の新しい S3 バケットを作成する
S3バケットを作成するには、次の手順を実行します。
- AWS マネジメントコンソールで アマゾンS3、選択する バケットを作成する.
- グローバルに一意の値を入力してください バケットの名前; 例えば、
appflow-bq-sample. - 選択する バケットを作成します。
Amazon Athena の結果用に新しい S3 バケットを作成する
S3バケットを作成するには、次の手順を実行します。
- AWS マネジメントコンソールで アマゾンS3、選択する バケットを作成する.
- グローバルに一意の値を入力してください バケットの名前; 例えば、
athena-results. - 選択する バケットを作成します。
AWS Glue データカタログのユーザーロール (IAM ロール)
フローで転送するデータをカタログ化するには、適切なユーザー ロールが必要です。 AWS Identity and Access Management(IAM)。 このロールを Amazon AppFlow に提供して、 AWSGlueデータカタログ、テーブル、データベース、パーティション。
必要な権限を持つ IAM ポリシーの例については、を参照してください。 Amazon AppFlow の ID ベースのポリシーの例。
設計のウォークスルー
次に、実際の使用例を見て、Amazon AppFlow Google BigQuery to Amazon S3 コネクタがどのように機能するかを見てみましょう。 このユースケースでは、Amazon AppFlow を使用して履歴データを Google BigQuery から Amazon S3 にアーカイブし、長期保存して分析します。
Amazon AppFlowをセットアップする
新しい Amazon AppFlow フローを作成して、Google Analytics から Amazon S3 にデータを転送します。
- ソフトウェア設定ページで、下図のように Amazon AppFlow コンソール、選択する フローを作成する.
- フローの名前を入力します。 例えば、
my-bq-flow. - 必要な追加 タグ; たとえば、 キー 入力します
envとのために 値 入力しますdev.

- 選択する Next.
- ソース名、選択する Google ビッグクエリ.
- 選択する 新しい接続を作成する.
- OAuth を入力してください 顧客ID & クライアントシークレット、次に接続に名前を付けます。 例えば、
bq-connection.
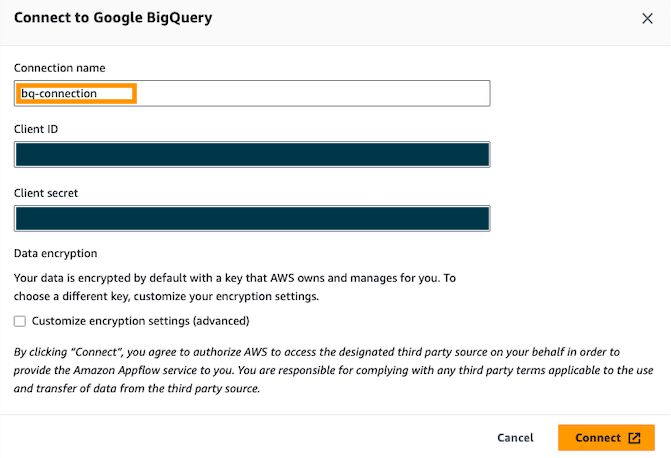
- ポップアップ ウィンドウで、amazon.com による Google BigQuery API へのアクセスを許可することを選択します。
![]()
- Google BigQuery オブジェクトの選択、選択する 表.
- Google BigQuery サブオブジェクトを選択してください、選択する BigQueryプロジェクト名.
- Google BigQuery サブオブジェクトを選択してください、選択する DatabaseName.
- Google BigQuery サブオブジェクトを選択してください、選択する テーブル名.
- 宛先名、選択する アマゾンS3.
- バケットの詳細, 前提条件で、Amazon AppFlow の結果を保存するために作成した Amazon S3 バケットを選択します。
- 入力します
rawとして 接頭辞.
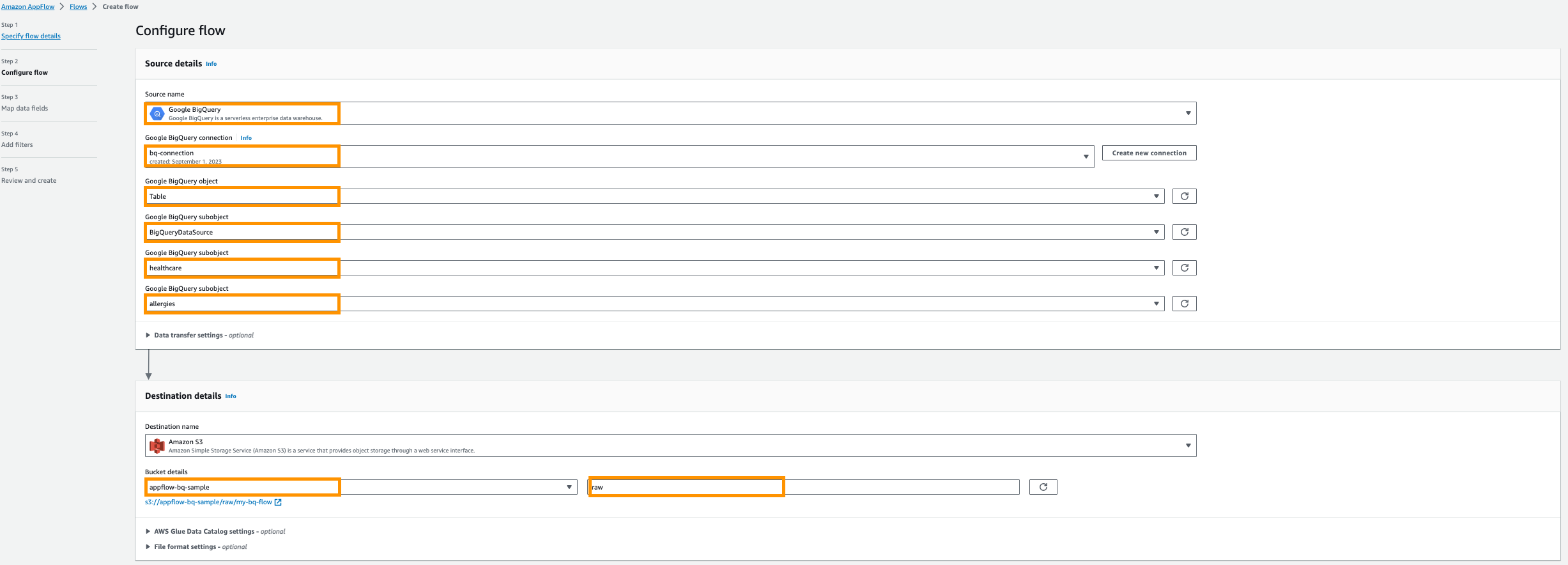
- 次に提供するのは、 AWSGlueデータカタログ さらに分析するためのテーブルを作成するための設定。
- 現在地に最も近い ユーザー役割 (IAM ロール) が前提条件で作成されます。
- 新しく作る データベース 例えば、
healthcare. - 提供する テーブルプレフィックス たとえば、
bq.

- 選択 オンデマンドで実行.
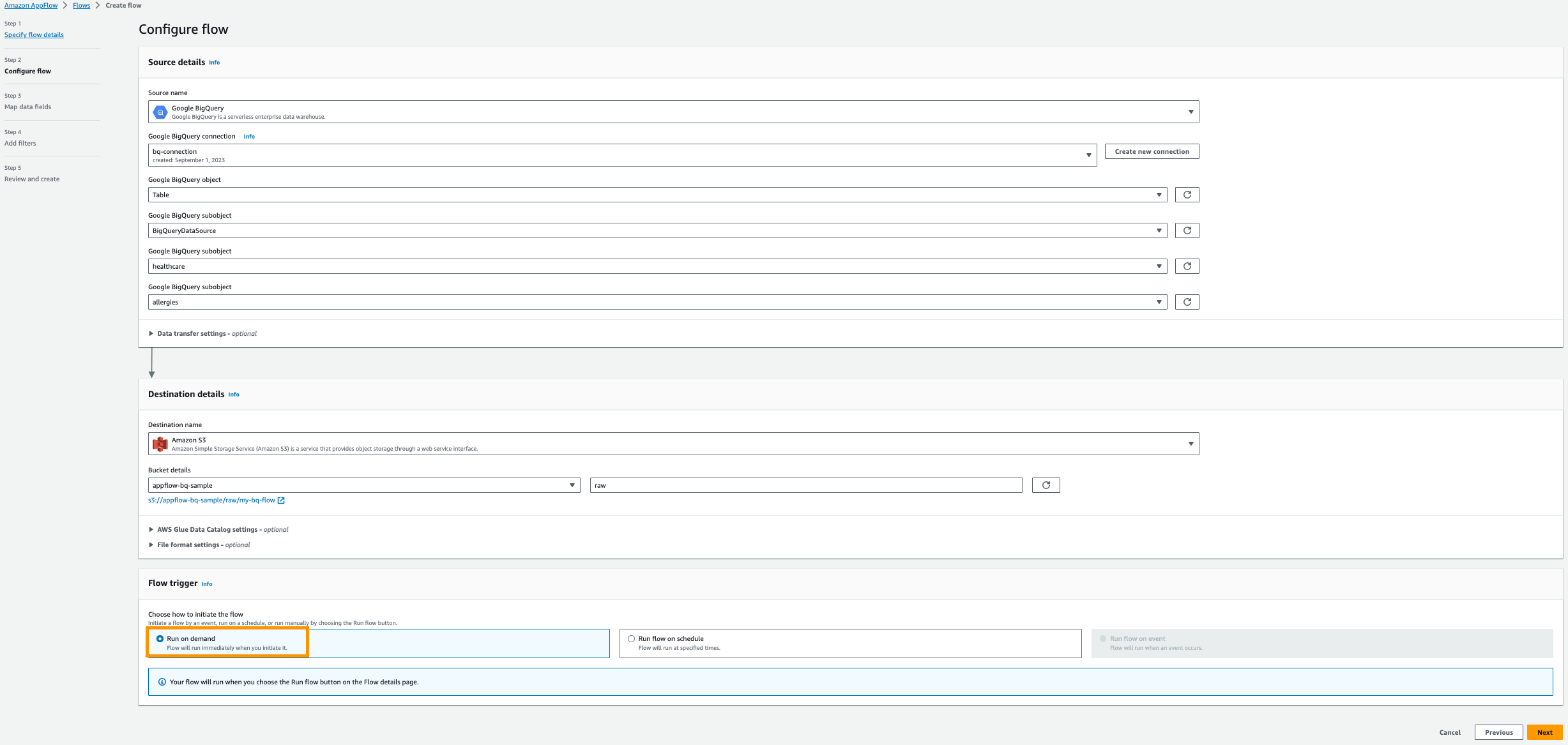
- 選択する 次へ。
- 選択 フィールドを手動でマッピングする.
- 次の XNUMX つのフィールドを選択します。 ソースフィールド名 表から アレルギー:
- 開始
- 患者
- Code
- 説明
- タイプ
- カテゴリー
- 選択する フィールドを直接マッピングする.
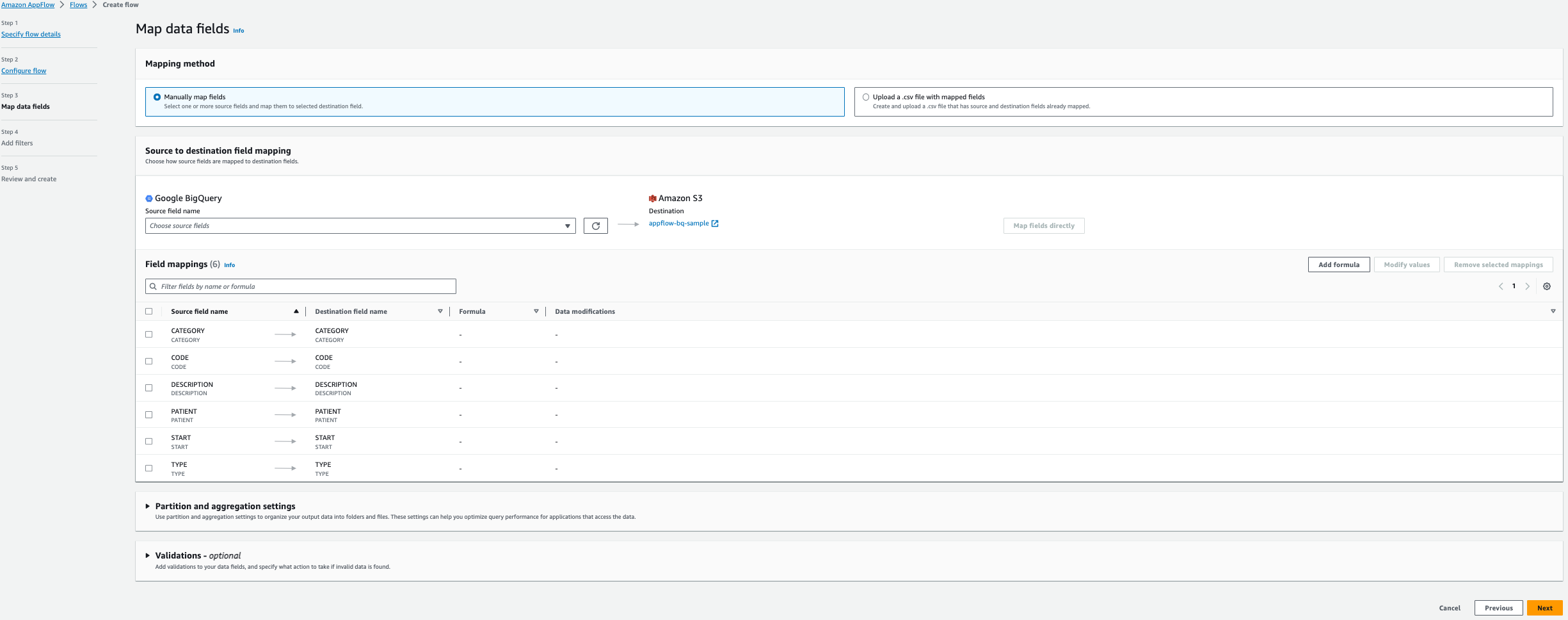
- 選択する Next.
- In フィルターの追加 セクションでは、選択 Next.
- 選択する フローを作成する.
フローを実行する
新しいフローを作成したら、オンデマンドで実行できます。
- ソフトウェア設定ページで、下図のように Amazon AppFlow コンソール、選択する
my-bq-flow. - 選択する 実行フロー.

このチュートリアルでは、理解しやすいように、オンデマンドでジョブを実行することを選択します。 実際には、スケジュールされたジョブを選択し、新しく追加されたデータのみを定期的に抽出できます。
Amazon Athena を介したクエリ
オプションの AWS Glue データカタログ設定を選択すると、Data Catalog によってデータのカタログが作成され、Amazon Athena がクエリを実行できるようになります。
クエリ結果の場所を構成するように求められた場合は、次の場所に移動します。 設定 タブを選択して 管理 。 下 設定を管理する、前提条件で作成した Athena 結果バケットを選択し、 Save.
- ソフトウェア設定ページで、下図のように Amazon Athena コンソール、データ ソースを選択します。
AWSDataCatalog. - 次に、 データベース as
healthcare. - これで、AWS Glue クローラーによって作成されたテーブルを選択してプレビューできるようになりました。

- 次のクエリに示すように、カスタム クエリを実行して上位 10 位のアレルギーを検索することもできます。
Note: 以下のクエリでは、テーブル名を置き換えます。この場合は bq_appflow_mybqflow_1693588670_latest、AWS アカウントで生成されたテーブルの名前に置き換えます。
- 選択する クエリを実行する.
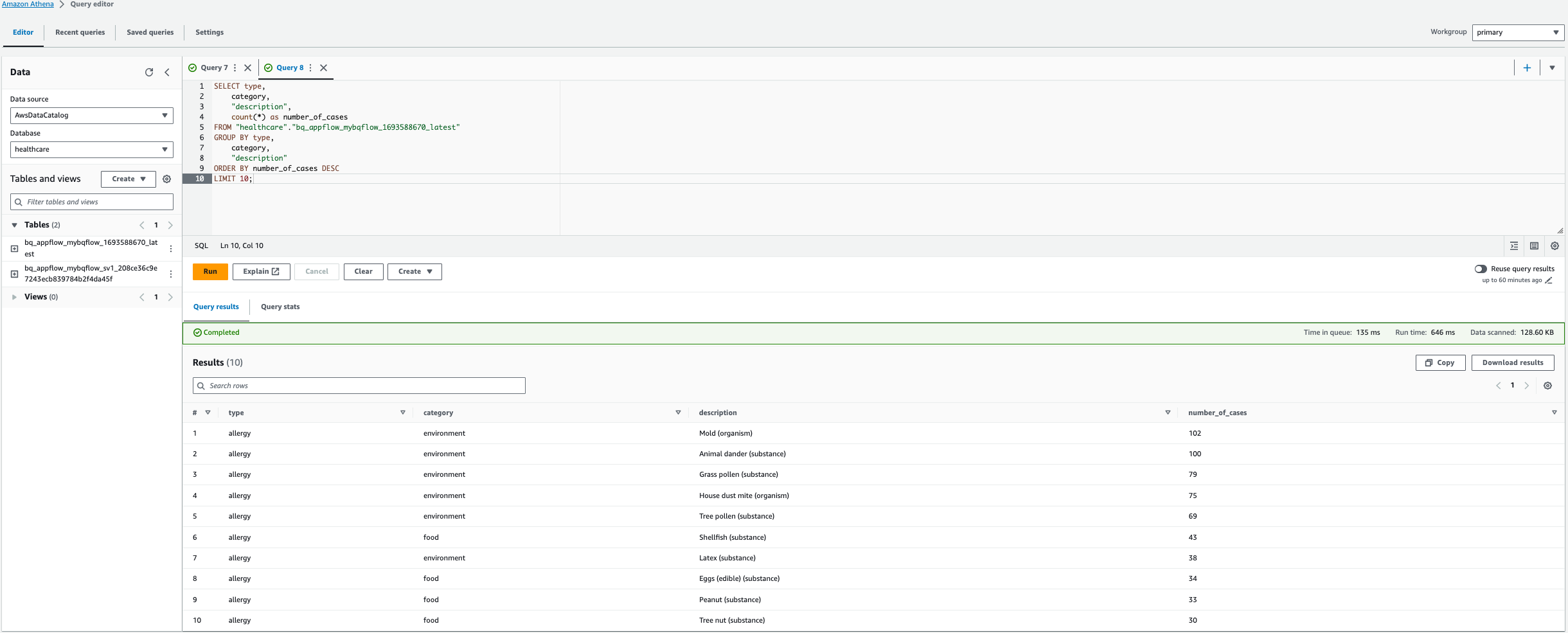
この結果は、アレルギーの症例数の上位 10 位を示しています。
クリーンアップ
料金の発生を回避するには、次の手順を実行して AWS アカウント内のリソースをクリーンアップします。
- Amazon AppFlowコンソールで、 流れ ナビゲーションペインに表示されます。
- フローのリストから、フローを選択します
my-bq-flow、削除します。 - フローを削除するには、delete と入力します。
- 選択する Connections ナビゲーションペインに表示されます。
- 選択する Google ビッグクエリ コネクタのリストから、
bq-connector、削除します。 - コネクタを削除するには、delete と入力します。
- IAMコンソールで、 役割 ナビゲーションページで、AWS Glue クローラー用に作成したロールを選択して削除します。
- Amazon Athena コンソールで:
- データベース配下に作成したテーブルを削除します
healthcareAWS Glue クローラーを使用します。 - データベースを削除する
healthcare
- データベース配下に作成したテーブルを削除します
- Amazon S3 コンソールで、作成した Amazon AppFlow 結果バケットを検索し、選択します 空の オブジェクトを削除してから、バケットを削除します。
- Amazon S3 コンソールで、作成した Amazon Athena 結果バケットを検索し、選択します 空の オブジェクトを削除してから、バケットを削除します。
- Google BigQuery リソースを含むプロジェクトを削除して、Google アカウント内のリソースをクリーンアップします。 ドキュメントに従って、 Google リソースをクリーンアップする.
まとめ
Amazon AppFlow の Google BigQuery コネクタは、Google のデータ ウェアハウスから Amazon S3 にデータを転送するプロセスを合理化します。 この統合により、分析と機械学習、アーカイブ、長期保存が簡素化され、両方のプラットフォームの分析機能を活用しようとしているデータ専門家や組織に大きなメリットがもたらされます。
Amazon AppFlow を使用すると、データ統合の複雑さが解消され、データから実用的な洞察を導き出すことに集中できるようになります。 履歴データのアーカイブ、複雑な分析の実行、機械学習用のデータの準備のいずれの場合でも、このコネクタはプロセスを簡素化し、より幅広いデータ専門家がアクセスできるようにします。
Amazon AppFlow を使用して Google BigQuery から Amazon S3 にデータがどのように転送されるかに興味がある場合は、ステップごとに見てください。 ビデオチュートリアル。 このチュートリアルでは、接続の設定からデータ転送フローの実行までのプロセス全体を説明します。 Amazon AppFlow の詳細については、次のサイトをご覧ください。 アマゾンアプリフロー.
著者について
![]() カルティカイ・カトール アマゾン ウェブ サービスのグローバル ライフ サイエンスのソリューション アーキテクトです。 彼は、AWS 分析サービスに重点を置き、顧客のクラウド移行を支援することに情熱を注いでいます。 彼は熱心なランナーであり、ハイキングを楽しんでいます。
カルティカイ・カトール アマゾン ウェブ サービスのグローバル ライフ サイエンスのソリューション アーキテクトです。 彼は、AWS 分析サービスに重点を置き、顧客のクラウド移行を支援することに情熱を注いでいます。 彼は熱心なランナーであり、ハイキングを楽しんでいます。
 カメン・シャルランドジエフ は、シニア ビッグ データおよび ETL ソリューション アーキテクトであり、Amazon AppFlow の専門家です。 彼は、複雑なデータ統合の課題に直面している顧客の生活を楽にするという使命を担っています。 彼の秘密兵器? フルマネージドのローコード AWS サービスにより、コーディングなしで最小限の労力でジョブを実行できます。
カメン・シャルランドジエフ は、シニア ビッグ データおよび ETL ソリューション アーキテクトであり、Amazon AppFlow の専門家です。 彼は、複雑なデータ統合の課題に直面している顧客の生活を楽にするという使命を担っています。 彼の秘密兵器? フルマネージドのローコード AWS サービスにより、コーディングなしで最小限の労力でジョブを実行できます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/simplify-data-transfer-google-bigquery-to-amazon-s3-using-amazon-appflow/

