近年、データ レイクが主流のアーキテクチャとなっており、データ品質の検証はデータの再利用性と一貫性を向上させるための重要な要素となっています。 AWS Glue データ品質 データ検証に必要な労力を数日から数時間に削減し、データ検証の実行に必要なリソースに関するコンピューティングに関する推奨事項、統計、洞察を提供します。
AWS Glue データ品質は以下に基づいて構築されています ディークーは、データ品質メトリクスを計算し、データ品質の制約とデータ分布の変更を検証するために Amazon で開発および使用されているオープンソース ツールです。これにより、アルゴリズムを実装するのではなく、データがどのように見えるかを説明することに集中できます。
この投稿では、事前定義されたテスト データセットに対して、ますます複雑になるデータ品質ルールセットを実行したベンチマーク結果を提供します。結果の一部として、AWS Glue Data Quality が抽出、変換、ロード (ETL) ジョブのランタイム、データ処理ユニット (DPU) の観点から測定されたリソースに関する情報を提供する方法、およびコストを追跡する方法を示します。 AWS Cost Explorer でカスタムコストレポートを定義することで、ETL パイプラインの AWS Glue Data Quality を実行できます。
ソリューションの概要
AWS Glue Data Quality が入力データセットに応じてどのように自動的にスケーリングするかを調べるために、テスト データセットを定義することから始めます。
データセットの詳細
テスト データセットには、Parquet 形式で保存された 104 列と 1 万行が含まれています。あなたはできる データセットをダウンロードする または、で提供されている Python スクリプトを使用してローカルで再作成します。 倉庫。ジェネレーター スクリプトを実行することを選択した場合は、 パンダ & 擬態 Python 環境内のパッケージ:
データセット スキーマは、組み込みの AWS Glue データ品質の組み合わせを使用するのに十分な属性を得るために、数値変数、カテゴリ変数、文字列変数の組み合わせです。 ルールの種類。このスキーマは、商品ティッカー、取引高、価格予測などの金融市場データに見られる最も一般的な属性の一部を複製します。
データ品質ルールセット
組み込みの AWS Glue Data Quality ルール タイプの一部を分類して、ベンチマーク構造を定義します。カテゴリでは、ルールが行レベルの検査を必要としない列チェック (単純ルール)、行ごとの分析 (中ルール)、またはデータ型チェックを実行するかどうかを考慮し、最終的には行の値を他のデータ ソースと比較します (複雑なルール) )。次の表は、これらのルールをまとめたものです。
| 単純な規則 | 中ルール | 複雑なルール |
| 列数 | DistinctValuesCount | 列の値 |
| 列データ型 | 完了しました | 完全 |
| 列が存在します | 合計 | 参照整合性 |
| 列名一致パターン | 標準偏差 | 列相関 |
| 行数 | 平均 | 行数の一致 |
| 列の長さ | . | . |
データ品質ルールセットを実行する 8 つの異なる AWS Glue ETL ジョブを定義します。各ジョブには、異なる数のデータ品質ルールが関連付けられています。各ジョブにも関連するものがあります ユーザー定義のコスト配分タグ これは、後で AWS Cost Explorer でデータ品質コスト レポートを作成するために使用します。
次の表に、各ルールセットのプレーン テキスト定義を示します。
| 職種名 | 単純な規則 | 中ルール | 複雑なルール | ルールの数 | タグ | 定義 |
| ルールセット-0 | 0 | 0 | 0 | 0 | dqジョブ:rs0 | – |
| ルールセット-1 | 0 | 0 | 1 | 1 | dqジョブ:rs1 | リンク |
| ルールセット-5 | 3 | 1 | 1 | 5 | dqジョブ:rs5 | リンク |
| ルールセット-10 | 6 | 2 | 2 | 10 | dqジョブ:rs10 | リンク |
| ルールセット-50 | 30 | 10 | 10 | 50 | dqジョブ:rs50 | リンク |
| ルールセット-100 | 50 | 30 | 20 | 100 | dqジョブ:rs100 | リンク |
| ルールセット-200 | 100 | 60 | 40 | 200 | dqジョブ:rs200 | リンク |
| ルールセット-400 | 200 | 120 | 80 | 400 | dqジョブ:rs400 | リンク |
データ品質ルールセットを含む AWS Glue ETL ジョブを作成する
アップロードします テストデータセット 〜へ Amazon シンプル ストレージ サービス (Amazon S3) と、AWS Glue Data Quality で参照整合性ルールを評価するために使用する XNUMX つの追加の CSV ファイル (isocodes.csv & 交換.csv) AWS Glue データカタログに追加された後。次の手順を実行します。
- Amazon S3 コンソールで、アカウントに新しい S3 バケットを作成し、 テストデータセット.
- という名前の S3 バケット内にフォルダーを作成します。
isocodesとアップロード isocodes.csv ファイルにソフトウェアを指定する必要があります。 - S3 バケットに Exchange という名前の別のフォルダーを作成し、 交換.csv ファイルにソフトウェアを指定する必要があります。
- AWS Glue コンソールで、フォルダーごとに 1 つずつ、2 つの AWS Glue クローラーを実行して、CSV コンテンツを AWS Glue データカタログに登録します (
data_quality_catalog)。手順については、を参照してください。 AWS Glue クローラーの追加。
AWS Glue クローラーは 2 つのテーブルを生成します (exchanges & isocodes) AWS Glue データカタログの一部として。

次に、 AWS IDおよびアクセス管理 (わたし) 役割 これは、実行時に ETL ジョブによって想定されます。
- IAM コンソールで、という名前の新しい IAM ロールを作成します。
AWSGlueDataQualityPerformanceRole - 信頼できるエンティティタイプ選択 AWSサービス.
- サービスまたはユースケース、選択する のり.
- 選択する Next.

- 権限ポリシー、 入る
AWSGlueServiceRole - 選択する Next.

- 新しいインライン ポリシーを作成してアタッチします (
AWSGlueDataQualityBucketPolicy)以下の内容となります。プレースホルダーを、前に作成した S3 バケット名に置き換えます。
次に、AWS Glue ETL ジョブの 1 つを作成します。 ruleset-5.
- AWS Glueコンソールの、 ETL ジョブ ナビゲーション ペインで、 ビジュアルETL.
- ジョブを作成 セクションでは、選択 ビジュアルETL.x

- ビジュアルエディターで、 データソース – S3バケット ソースノード:
- S3 URL、テスト データセットを含む S3 フォルダーを入力します。
- データフォーマット、選択する 寄せ木細工の床.

- 新しいアクションノードを作成し、 変換: データカタログの評価:
- ノードの親、作成したノードを選択します。
- 加えます ルールセット 5 の定義 下 ルールセットエディタ.

- 最後までスクロールして下へ パフォーマンス構成、イネーブル データをキャッシュする.

- 仕事の詳細、用 IAMの役割、選択する
AWSGlueDataQualityPerformanceRole.
- タグ セクション、定義 dqジョブ としてタグ付け rs5.
このタグは、データ品質 ETL ジョブごとに異なります。これらを AWS Cost Explorer で使用して、ETL ジョブのコストを確認します。

- 選択する Save.
- 残りのルールセットに対してこれらの手順を繰り返して、すべての ETL ジョブを定義します。

AWS Glue ETL ジョブを実行する
ETL ジョブを実行するには、次の手順を実行します。
- AWS Glue コンソールで、選択します ビジュアルETL 下 ETL ジョブ ナビゲーションペインに表示されます。
- ETL ジョブを選択し、 ジョブを実行する.
- すべての ETL ジョブに対してこの手順を繰り返します。
![AWS Glue ジョブを 1 つ選択し、右上の [ジョブの実行] を選択します](https://zephyrnet.com/wp-content/uploads/2024/03/measure-performance-of-aws-glue-data-quality-for-etl-pipelines-amazon-web-services-10.png)
ETL ジョブが完了すると、 ジョブ実行の監視 ページにジョブの詳細が表示されます。次のスクリーンショットに示すように、 DPU 時間 列はETLジョブごとに提供されます。

パフォーマンスを確認する
次の表は、同じテスト データセットに対して 104 つの異なるデータ品質ルールセットを実行する場合の期間、DPU 時間、および推定コストをまとめたものです。すべてのルールセットは、前述のテスト データセット全体 (1 列、XNUMX 万行) を使用して実行されていることに注意してください。
| ETL ジョブ名 | ルールの数 | タグ | 期間(秒) | DPU 時間数 | DPU の数 | 費用($) |
| ルールセット-400 | 400 | dqジョブ:rs400 | 445.7 | 1.24 | 10 | $0.54 |
| ルールセット-200 | 200 | dqジョブ:rs200 | 235.7 | 0.65 | 10 | $0.29 |
| ルールセット-100 | 100 | dqジョブ:rs100 | 186.5 | 0.52 | 10 | $0.23 |
| ルールセット-50 | 50 | dqジョブ:rs50 | 155.2 | 0.43 | 10 | $0.19 |
| ルールセット-10 | 10 | dqジョブ:rs10 | 152.2 | 0.42 | 10 | $0.18 |
| ルールセット-5 | 5 | dqジョブ:rs5 | 150.3 | 0.42 | 10 | $0.18 |
| ルールセット-1 | 1 | dqジョブ:rs1 | 150.1 | 0.42 | 10 | $0.18 |
| ルールセット-0 | 0 | dqジョブ:rs0 | 53.2 | 0.15 | 10 | $0.06 |
空のルールセットの評価コストはゼロに近いですが、AWS Glue Data Quality ジョブに関連付けられた IAM ロールと Amazon S3 のテスト データセットへの読み取り権限を検証する簡単なテストとして使用できるため、このルールセットが組み込まれています。データ品質ジョブのコストは、100 を超えるルールを含むルールセットを評価した後にのみ増加し始めますが、その数以下では一定のままです。
ベンチマーク内の最大のルールセット (400 ルール) のデータ品質の実行コストは、依然として 0.50 ドルをわずかに上回っていることがわかります。
AWS Cost Explorer でのデータ品質コスト分析
AWS Cost Explorer でデータ品質 ETL ジョブタグを確認するには、以下を行う必要があります。 ユーザー定義のコスト配分タグをアクティブにする 最初。
ユーザー定義タグを作成してリソースに適用した後、アクティブ化のためにタグ キーがコスト配分タグ ページに表示されるまでに最大 24 時間かかる場合があります。タグ キーがアクティブになるまでに最大 24 時間かかる場合があります。
- AWS 上で コストエクスプローラー コンソール、選択 Cost Explorer の保存済みレポート ナビゲーションペインに表示されます。
- 選択する 新しいレポートを作成する.

- 選択 コストと使用量 レポートタイプとして。
- 選択する レポートを作成する.
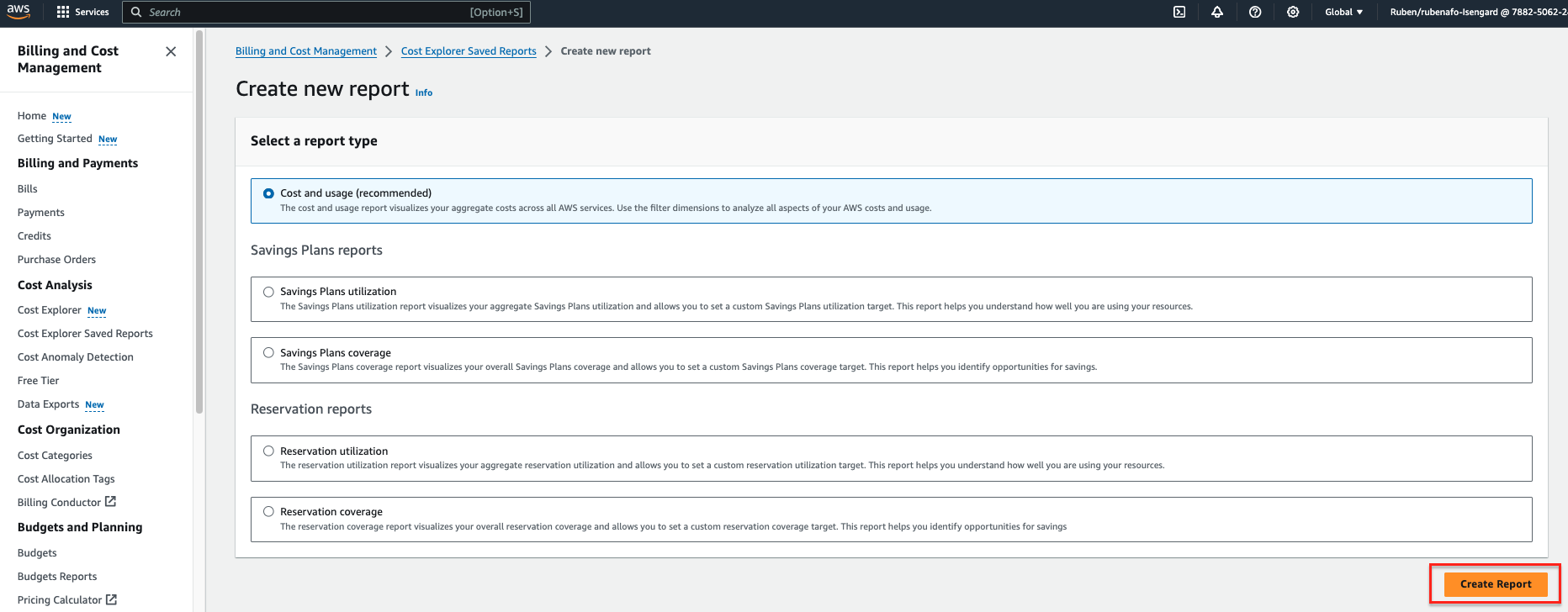
- 日付範囲、日付範囲を入力します。
- 粒度¸選ぶ 毎日.
- 次元、選択する タグ次に、
dqjobタグ。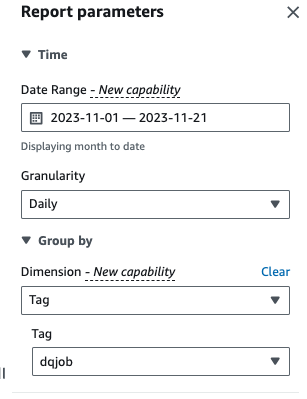
- 適用されたフィルターを選択してください
dqjobタグと、データ品質ルールセットで使用される 0 つのタグ (rs1、rs5、rs10、rs50、rs100、rs200、rs400、および rsXNUMX)。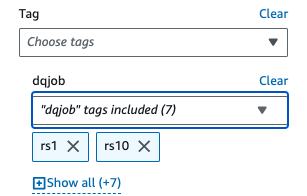
- 選択する 申し込む.
コストと使用状況レポートが更新されます。 X 軸は、データ品質ルールセット タグをカテゴリとして示します。の コストと使用量 AWS Cost Explorer のグラフが更新され、ETL ジョブごとに集計された、実行された最新のデータ品質 ETL ジョブの合計月間コストが表示されます。

クリーンアップ
インフラストラクチャをクリーンアップして追加料金を回避するには、次の手順を実行します。
- テスト データセットを保存するために最初に作成された S3 バケットを空にします。
- AWS Glue で作成した ETL ジョブを削除します。
- 削除
AWSGlueDataQualityPerformanceRoleIAM の役割。 - AWS Cost Explorer で作成したカスタム レポートを削除します。
まとめ
AWS Glue Data Quality は、ETL パイプラインの一部としてデータ品質検証を組み込む効率的な方法を提供し、データ量の増加に合わせて自動的にスケールします。組み込みのデータ品質ルール タイプは、データ品質チェックをカスタマイズし、未分化なロジックを実装する代わりにデータの外観に重点を置くための幅広いオプションを提供します。
このベンチマーク分析では、一般的なサイズの AWS Glue Data Quality ルールセットではオーバーヘッドがほとんどまたはまったくないのに対し、複雑なケースではコストが直線的に増加することを示しました。また、AWS Glue Data Quality ジョブにタグを付けて、AWS Cost Explorer でコスト情報を利用して迅速なレポートを作成できる方法も確認しました。
AWS Glue のデータ品質は 一般に入手可能 AWS Glue が利用可能なすべての AWS リージョンで。 AWS Glue データ品質と AWS Glue データカタログの詳細については、こちらをご覧ください。 AWS Glue データカタログから AWS Glue データ品質を開始する.
著者について
 ルーベン・アフォンソ AWS のグローバル金融サービス ソリューション アーキテクトです。彼は自動化と最適化に情熱を持って、分析と AI/ML の課題に取り組むことを楽しんでいます。仕事以外のときは、バルセロナ周辺の人里離れた隠れスポットを見つけるのが趣味です。
ルーベン・アフォンソ AWS のグローバル金融サービス ソリューション アーキテクトです。彼は自動化と最適化に情熱を持って、分析と AI/ML の課題に取り組むことを楽しんでいます。仕事以外のときは、バルセロナ周辺の人里離れた隠れスポットを見つけるのが趣味です。
 カリヤン・クマール・ニーランプディ(KK) AWS のスペシャリスト パートナー ソリューション アーキテクト (データ分析および生成 AI) です。彼はテクニカルアドバイザーとして機能し、さまざまな AWS パートナーと協力して、データ分析と AI/ML ワークロードに関するプラクティスの設計、実装、構築を行っています。仕事以外では、バドミントン愛好家であり料理の冒険家でもあり、地元の料理を探索したり、パートナーと一緒に旅行して新しい味や経験を発見しています。
カリヤン・クマール・ニーランプディ(KK) AWS のスペシャリスト パートナー ソリューション アーキテクト (データ分析および生成 AI) です。彼はテクニカルアドバイザーとして機能し、さまざまな AWS パートナーと協力して、データ分析と AI/ML ワークロードに関するプラクティスの設計、実装、構築を行っています。仕事以外では、バドミントン愛好家であり料理の冒険家でもあり、地元の料理を探索したり、パートナーと一緒に旅行して新しい味や経験を発見しています。

ゴンザロエレロス AWS Glue チームのシニアビッグデータアーキテクトです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/measure-performance-of-aws-glue-data-quality-for-etl-pipelines/

