概要
作物の収量予測は不可欠です 予測分析 農業における技術。 これは、農家や農業経営者が特定の季節の作物収穫量を予測するのに役立つ農業慣行であり、いつ作物を植え、いつ収穫すれば作物の収量が向上します。 予測分析 は、農業業界における意思決定の向上に役立つ強力なツールです。 作物収量の予測、リスクの軽減、肥料コストの削減などに使用できます。ML とフラスコ展開を使用した作物収量の予測では、気象条件、土壌の品質、結実、結実量などの分析が行われます。

学習目標
- 受粉シミュレーション モデリングを使用して作物の収量を予測するエンドツーエンドのプロジェクトを簡単に説明します。
- データ探索、前処理、モデリング、評価、展開など、データ サイエンス プロジェクトのライフサイクルの各ステップを追跡します。
- 最後に、Flask API を使用してモデルを render と呼ばれるクラウド サービス プラットフォームにデプロイします。
それでは、このエキサイティングな現実世界の問題ステートメントから始めましょう。
この記事は、の一部として公開されました データサイエンスブログ。
目次
プロジェクトの説明
このプロジェクトに使用されるデータセットは、ワイルドブルーベリーの予測に影響を与える次のようなさまざまな要因を分析および研究するために、空間明示的シミュレーション コンピューティング モデルを使用して生成されました。
- 工場の空間配置
- 他家交配と自家受粉
- ミツバチの種の構成
- 気象条件(単独および組み合わせ)は、農業生態系における野生ブルーベリーの受粉効率と収量に影響を与えます。
このシミュレーション モデルは、過去 30 年間に米国メイン州とカナダ沿岸で収集された野外観察と実験データによって検証されており、現在では仮説検証や野生ブルーベリーの収量予測の推定に役立つツールとなっています。 このシミュレートされたデータは、作物収量予測に関するさまざまな実験のために現場から収集された実際のデータを研究者に提供するだけでなく、開発者やデータ サイエンティストが現実世界を構築するためのデータを提供します。 機械学習 作物収量予測のためのモデル。

受粉シミュレーションモデルとは何ですか?
受粉シミュレーション モデリングは、コンピューター モデルを使用して受粉のプロセスをシミュレートするプロセスです。 受粉シミュレーションには次のようなさまざまな使用例があります。
- 気候変動、生息地の喪失、農薬など、受粉に対するさまざまな要因の影響を研究する
- 受粉に適した景観の設計
- 受粉が作物収量に及ぼす影響を予測する
受粉シミュレーション モデルを使用すると、花間の花粉粒の移動、受粉イベントのタイミング、およびさまざまな受粉戦略の有効性を研究できます。 この情報は受粉率と作物の収量を改善するために使用でき、農家が最適な収量で効率的に作物を生産するのにさらに役立ちます。
受粉シミュレーション モデルはまだ開発中ですが、農業の将来において重要な役割を果たす可能性があります。 受粉の仕組みを理解することで、この重要なプロセスをより適切に保護し、管理できるようになります。
私たちのプロジェクトでは、「」のようなさまざまな機能を備えたデータセットを使用します。クローンサイズ'、'ミツバチ'、'雨の日'、'平均雨日数」など、作物の収量を推定するために受粉シミュレーションプロセスを使用して作成されました。
問題提起
このプロジェクトでは、私たちのタスクは、毎日のタスクを実行することによって、他の 17 個の特徴に基づいて歩留まり変数 (ターゲット特徴) を段階的に分類することです。 評価指標は RMSE スコアリングされます。 Python の Flask フレームワークを使用してモデルをクラウドベースのプラットフォームにデプロイします。
前提条件
このプロジェクトは、データ サイエンスと機械学習の中級学習者がポートフォリオ プロジェクトを構築するのに適しています。 以下のスキルに精通していれば、この分野の初心者でもこのプロジェクトに取り組むことができます。
- Python プログラミング言語、および scikit-learn ライブラリを使用した機械学習アルゴリズムの知識
- を使用した Web サイト開発の基本的な理解 PythonのFlaskフレームワーク
- 理解する 不具合 評価指標
データの説明
このセクションでは、プロジェクトのデータセットのすべての変数を調べます。
- クローンサイズ — m2 — 畑のブルーベリークローンの平均サイズ
- ミツバチ — ミツバチ/m2/分 — 圃場におけるミツバチの密度
- バンブルズ — ミツバチ/m2/分 — 畑のマルハナバチ密度
- アンドレナ — ミツバチ/m2/分 — 畑のアンドレナミツバチの密度
- オスミア — ミツバチ/m2/分 — 圃場におけるオスミアミツバチの密度
- MaxOfUpperTRange — ℃ —開花期の上層日気温の最高記録
- MinOfUpperTRange — ℃ — 上層日気温の最低記録
- 上部TRangeの平均 — ℃ — 上部帯の日気温の平均
- MaxOfLowerTRange — ℃ — 下域日気温の最高記録
- MinOfLowerTRange — ℃ — 下域日気温の最低記録
- AverageOfLowerTRange — ℃ — 日下帯の気温の平均値
- 雨の日 — 日 — 開花期中の降水量がゼロより大きい日数の合計
- 平均雨日数 — 日 — 開花期全体の雨の日の平均
- フルーツセット — 結実の移行時期
- フルーツマス — 結実量
- 種子 — 結実内の種子の数
- 産出 — 作物収量 (目標変数)
作物予測のユースケースにおけるこのデータの価値は何ですか?
- このデータセットは、野生のブルーベリー植物の空間的特徴、ミツバチの種類、気象状況に関する実用的な情報を提供します。 したがって、研究者や開発者は、ブルーベリーの収量を早期に予測するための機械学習モデルを構築できます。
- このデータセットは、野外観察データはあるものの、作物収量予測の入力として実際のデータの使用とコンピューター シミュレーションで生成されたデータを比較することにより、さまざまな機械学習アルゴリズムのパフォーマンスをテストおよび評価したいと考えている他の研究者にとって不可欠です。
- さまざまなレベルの教育者は、機械学習分類のトレーニングにデータセットを使用できます。 回帰 農業業界の問題。
データセットの読み込み
このセクションでは、作業している環境にデータセットを読み込みます。 kaggle 環境にデータセットを読み込みます。 kaggle データセットを使用するか、ローカル マシンにダウンロードしてローカル環境で実行します。
データセットソース: ここをクリック
データセットをロードし、プロジェクトのライブラリをロードするコードを見てみましょう。
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.feature_selection import mutual_info_regression, SelectKBest
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split, cross_val_score, KFold from sklearn.model_selection import GridSearchCV, RepeatedKFold
from sklearn.ensemble import AdaBoostRegressor, GradientBoostingRegressor from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
import sklearn
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
import statsmodels.api as sm
from xgboost import XGBRegressor
import shap # setting up os env in kaggle import os
for dirname, _, filenames in os.walk('/kaggle/input'): for filename in filenames: print(os.path.join(dirname, filename)) # read the csv file and load first 5 rows in the platform df = pd.read_csv("/kaggle/input/wildblueberrydatasetpollinationsimulation/
WildBlueberryPollinationSimulationData.csv", index_col='Row#')
df.head()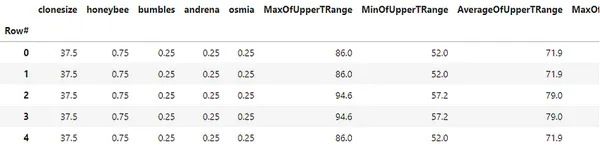
# print the metadata of the dataset
df.info() # data description
df.describe()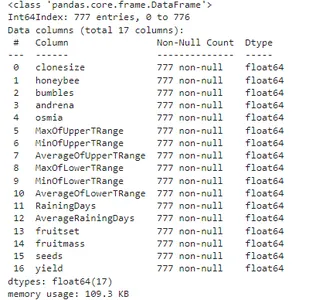
上記のようなコード 'df.info()' 行数、NULL 値の数、各変数のデータ型などを含むデータフレームの概要を提供します。 'df.describe()' データセット内の各変数の平均、中央値、数、パーセンタイルなどのデータセットの記述統計を提供します。
探索的データ分析
このセクションでは、作物データセットの探索的データ分析を見て、データセットから洞察を導き出します。
データセットのヒートマップ
# create featureset and target variable from the dataset
features_df = df.drop('yield', axis=1)
tar = df['yield'] # plot the heatmap from the dataset
plt.figure(figsize=(15,15))
sns.heatmap(df.corr(), annot=True, vmin=-1, vmax=1)
plt.show()
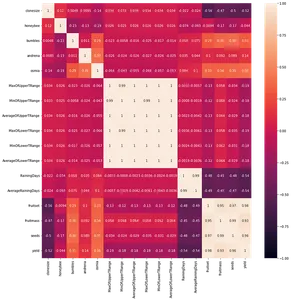
上のプロットは、データセットの相関係数を視覚化したものです。 Python の seaborn ライブラリを使用すると、わずか 3 行のコードで視覚化できます。
ターゲット変数の分布
# plot the boxplot using seaborn library of the target variable 'yield'
plt.figure(figsize=(5,5))
sns.boxplot(x='yield', data=df)
plt.show()
上記のコードは、箱ひげ図を使用してターゲット変数の分布を表示します。 分布の中央値は約 6000 で、収量が最も低い外れ値がいくつかあることがわかります。
データセットのカテゴリ特徴による分布
# matplotlib subplot for the categorical feature nominal_df = df[['MaxOfUpperTRange','MinOfUpperTRange','AverageOfUpperTRange','MaxOfLowerTRange', 'MinOfLowerTRange','AverageOfLowerTRange','RainingDays','AverageRainingDays']] fig, ax = plt.subplots(2,4, figsize=(20,13))
for e, col in enumerate(nominal_df.columns): if e<=3: sns.boxplot(data=df, x=col, y='yield', ax=ax[0,e]) else: sns.boxplot(data=df, x=col, y='yield', ax=ax[1,e-4]) plt.show()
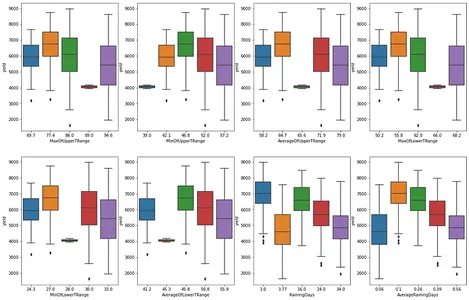
データセット内のミツバチの種類の分布
# matplotlib subplot technique to plot distribution of bees in our dataset
plt.figure(figsize=(15,10))
plt.subplot(2,3,1)
plt.hist(df['bumbles'])
plt.title("Histogram of bumbles column")
plt.subplot(2,3,2)
plt.hist(df['andrena'])
plt.title("Histogram of andrena column")
plt.subplot(2,3,3)
plt.hist(df['osmia'])
plt.title("Histogram of osmia column")
plt.subplot(2,3,4)
plt.hist(df['clonesize'])
plt.title("Histogram of clonesize column")
plt.subplot(2,3,5)
plt.hist(df['honeybee'])
plt.title("Histogram of honeybee column")
plt.show()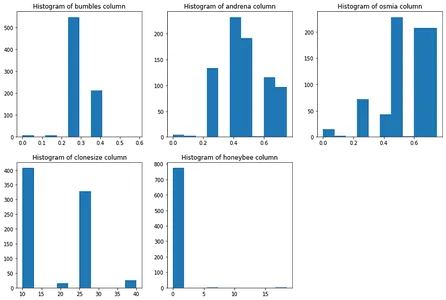
分析に関する観察結果のいくつかを書き留めてみましょう。
- T 範囲の上限と下限の列は相互に相関します
- 雨の日と平均的な雨の日は相互に相関しています
- 'フルーツマス'、'結実'、'シーズ' は相関しています
- 'へま' 列は非常に不均衡ですが、'アンドレナ'と'オスミア' 列はそうではありません
- 「Honeybee」も「」に比べてアンバランスな柱です。クローンサイズ'
データの前処理とデータの準備
このセクションでは、モデリングのためにデータセットを前処理します。 「相互情報回帰」を実行してデータセットから最適な特徴を選択し、データセット内のミツバチの種類に対してクラスタリングを実行し、効率的な機械学習モデリングのためにデータセットを標準化します。
相互情報回帰
# run the MI scores of the dataset
mi_score = mutual_info_regression(features_df, tar, n_neighbors=3,random_state=42)
mi_score_df = pd.DataFrame({'columns':features_df.columns, 'MI_score':mi_score})
mi_score_df.sort_values(by='MI_score', ascending=False)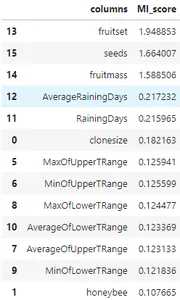
上記のコードは、ピアソン係数を使用して相互回帰を計算し、ターゲット変数と最も相関のある特徴を見つけます。 最も相関性の高いフィーチャを降順で確認でき、ターゲット フィーチャとの相関性が最も高いものを確認できます。 次に、ミツバチの種類をクラスタリングして新しいフィーチャを作成します。
K 平均法を使用したクラスタリング
# clustering using kmeans algorithm
X_clus = features_df[['honeybee','osmia','bumbles','andrena']] # standardize the dataset using standard scaler
scaler = StandardScaler()
scaler.fit(X_clus)
X_new_clus = scaler.transform(X_clus) # K means clustering clustering = KMeans(n_clusters=3, random_state=42)
clustering.fit(X_new_clus)
n_cluster = clustering.labels_ # add new feature to feature_Df features_df['n_cluster'] = n_cluster
df['n_cluster'] = n_cluster
features_df['n_cluster'].value_counts() ---------------------------------[Output]----------------------------------
1 368
0 213
2 196
Name: n_cluster, dtype: int64上記のコードはデータセットを標準化し、クラスタリング アルゴリズムを適用して行を 3 つの異なるグループにグループ化します。
Min-Max スケーラーを使用したデータ正規化
features_set = ['AverageRainingDays','clonesize','AverageOfLowerTRange', 'AverageOfUpperTRange','honeybee','osmia','bumbles','andrena','n_cluster'] # final dataframe X = features_df[features_set]
y = tar.round(1) # train and test dataset to build baseline model using GBT and RFs by scaling the dataset
mx_scaler = MinMaxScaler()
X_scaled = pd.DataFrame(mx_scaler.fit_transform(X))
X_scaled.columns = X.columns
上記のコードは、正規化された特徴セットを表します。X_scaled' とターゲット変数 'y' モデリングに使用されます。
モデリングと評価
このセクションでは、モデルの望ましい精度とパフォーマンスを得るために、勾配ブースティング モデリングとハイパーパラメーター調整を使用した機械学習モデリングについて見ていきます。 また、statsmodels ライブラリと形状モデル エクスプローラーを使用した最小二乗回帰モデリングを見て、目標作物収量の予測にどの特徴が最も重要であるかを視覚化します。
機械学習モデリングのベースライン
# let's fit the data to the models lie adaboost, gradientboost and random forest
model_dict = {"abr": AdaBoostRegressor(), "gbr": GradientBoostingRegressor(), "rfr": RandomForestRegressor() } # Cross value scores of the models
for key, val in model_dict.items(): print(f"cross validation for {key}") score = cross_val_score(val, X_scaled, y, cv=5, scoring='neg_mean_squared_error') mean_score = -np.sum(score)/5 sqrt_score = np.sqrt(mean_score) print(sqrt_score) -----------------------------------[Output]------------------------------------
cross validation for abr
730.974385377955
cross validation for gbr
528.1673164806733
cross validation for rfr
608.0681265123212上記の機械学習モデリングでは、勾配ブースティング リグレッサーでは最小の平均二乗誤差が得られ、Adaboost リグレッサーでは最高の誤差が得られました。 次に、勾配ブースティング モデルをトレーニングし、scikit-learn トレインを使用して誤差を評価し、分割方法をテストします。
# split the train and test data
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42) # gradient boosting regressor modeling
bgt = GradientBoostingRegressor(random_state=42)
bgt.fit(X_train,y_train)
preds = bgt.predict(X_test)
score = bgt.score(X_train,y_train)
rmse_score = np.sqrt(mean_squared_error(y_test, preds))
r2_score = r2_score(y_test, preds)
print("RMSE score gradient boosting machine:", rmse_score) print("R2 score for the model: ", r2_score) -----------------------------[Output]-------------------------------------------
RMSE score gradient boosting machine: 363.18286194620714
R2 score for the model: 0.9321362721127562ここでは、モデルのハイパーパラメーター調整を行わない勾配ブースティング モデリングの RMSE スコアが約 363 であることがわかります。一方、モデルの R2 は約 93% であり、ベースライン精度よりも優れたモデル精度です。 さらに、ハイパーパラメーターを調整して、機械学習モデルの精度を最適化します。
ハイパーパラメータの調整
# K-fold split the dataset
kf = KFold(n_splits = 5, shuffle=True, random_state=0) # params grid for tuning the hyperparameters
param_grid = {'n_estimators': [100,200,400,500,800], 'learning_rate': [0.1,0.05,0.3,0.7], 'min_samples_split': [2,4], 'min_samples_leaf': [0.1,0.4], 'max_depth': [3,4,7] } # GBR estimator object estimator = GradientBoostingRegressor(random_state=42) # Grid search CV object clf = GridSearchCV(estimator=estimator, param_grid=param_grid, cv=kf, scoring='neg_mean_squared_error', n_jobs=-1)
clf.fit(X_scaled,y) # print the best the estimator and params
best_estim = clf.best_estimator_
best_score = clf.best_score_
best_param = clf.best_params_
print("Best Estimator:", best_estim)
print("Best score:", np.sqrt(-best_score)) -----------------------------------[Output]----------------------------------
Best Estimator: GradientBoostingRegressor(max_depth=7, min_samples_leaf=0.1, n_estimators=500, random_state=42)
Best score: 306.57274619213206調整された勾配ブースティング モデルの誤差が以前のものよりさらに減少し、ML モデルのパラメーターが最適化されたことがわかります。
形状モデルの説明者
機械学習の説明可能性は、今日の ML モデリングの非常に重要な側面です。 一方、ML モデルは多くの分野で有望な結果をもたらしていますが、その固有の複雑さにより、特定の予測や決定にどのように到達したかを理解することが困難になっています。 Shap ライブラリは ' を使用します立派な' 値を使用して、どの特徴がターゲット値の予測に影響を与えるかを測定します。 では、「」を見てみましょう。SHAP' 勾配ブースティング モデルのモデル説明プロット。
# shaply tree explainer
shap_tree = shap.TreeExplainer(bgt)
shap_values = shap_tree.shap_values(X_test)
shap.summary_plot(shap_values, X_test)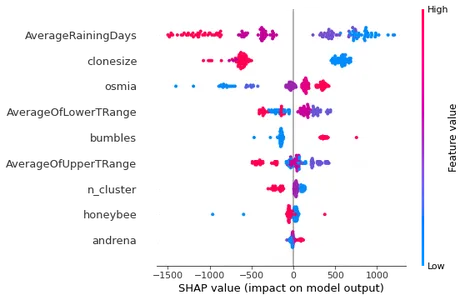
上記の出力プロットでは、次のことが明らかです。 平均雨日数 は、ターゲット変数の予測値を説明する最も影響力のある変数です。 一方 アンドレナ 特徴は予測変数の結果にほとんど影響しません。
FlaskAPIを使用したモデルのデプロイメント
このセクションでは、FlaskAPI を使用して機械学習モデルを render.com というクラウド サービス プラットフォームにデプロイします。 デプロイメントの前に、クラウド上にデプロイできる API を作成するために、joblib 拡張子を付けてモデル ファイルを保存する必要があります。
モデルファイルの保存
# remove the 'n_cluster' feature from the dataset
X_train_n = X_train.drop('n_cluster', axis=1)
X_test_n = X_test.drop('n_cluster', axis=1) # train a model for flask API creation =
xgb_model = XGBRegressor(max_depth=9, min_child_weight=7, subsample=1.0)
xgb_model.fit(X_train_n, y_train)
pr = xgb_model.predict(X_test_n)
err = mean_absolute_error(y_test, pr)
rmse_n = np.sqrt(mean_squared_error(y_test, pr)) # after training, save the model using joblib library
joblib.dump(xgb_model, 'wbb_xgb_model2.joblib')
ご覧のとおり、上記のコードでモデル ファイルを保存し、GitHub リポジトリにアップロードする Flask アプリ ファイルとモデル ファイルを作成する方法を示しています。
アプリケーションリポジトリの構造
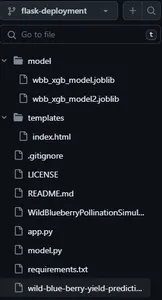
上の画像は、次のファイルとディレクトリを含むアプリケーション リポジトリのスナップショットです。
- app.py — Flask アプリケーション ファイル
- モデル.py — モデル予測ファイル
- Requirements.txt — アプリケーションの依存関係
- モデルディレクトリ — 保存されたモデル ファイル
- テンプレートディレクトリ — フロントエンド UI ファイル
app.pyファイル
from flask import Flask, render_template, Response
from flask_restful import reqparse, Api
import flask import numpy as np
import pandas as pd
import ast import os
import json from model import predict_yield curr_path = os.path.dirname(os.path.realpath(__file__)) feature_cols = ['AverageRainingDays', 'clonesize', 'AverageOfLowerTRange', 'AverageOfUpperTRange', 'honeybee', 'osmia', 'bumbles', 'andrena'] context_dict = { 'feats': feature_cols, 'zip': zip, 'range': range, 'len': len, 'list': list,
} app = Flask(__name__)
api = Api(app) # # FOR FORM PARSING
parser = reqparse.RequestParser()
parser.add_argument('list', type=list) @app.route('/api/predict', methods=['GET','POST'])
def api_predict(): data = flask.request.form.get('single input') # converts json to int i = ast.literal_eval(data) y_pred = predict_yield(np.array(i).reshape(1,-1)) return {'message':"success", "pred":json.dumps(int(y_pred))} @app.route('/')
def index(): # render the index.html templete return render_template("index.html", **context_dict) @app.route('/predict', methods=['POST'])
def predict(): # flask.request.form.keys() will print all the input from form test_data = [] for val in flask.request.form.values(): test_data.append(float(val)) test_data = np.array(test_data).reshape(1,-1) y_pred = predict_yield(test_data) context_dict['pred']= y_pred print(y_pred) return render_template('index.html', **context_dict) if __name__ == "__main__": app.run()上記のコードは、ユーザーからの入力を受け取り、フロントエンドで収穫量の予測を出力する Python ファイルです。
Model.py ファイル
import joblib import pandas as pd
import numpy as np
import os # load the model file
curr_path = os.path.dirname(os.path.realpath(__file__))
xgb_model = joblib.load(curr_path + "/model/wbb_xgb_model2.joblib") # function to predict the yield
def predict_yield(attributes: np.ndarray): """ Returns Blueberry Yield value""" # print(attributes.shape) # (1,8) pred = xgb_model.predict(attributes) print("Yield predicted") return pred[0] Model.py ファイルは実行時にモデルをロードし、予測の出力を提供します。
レンダリング時のデプロイメント
すべてのファイルが github リポジトリにプッシュされたら、簡単にアカウントを作成できます。 レンダリング.com app.py ファイルと他のアーティファクトを含むリポジトリのブランチをプッシュします。 あとはプッシュするだけで数秒でデプロイできます。 さらに、render には自動展開オプションも用意されており、展開ファイルに加えられる変更が Web サイトに自動的に反映されるようになります。
プロジェクトとコードの詳細については、こちらをご覧ください。 github リポジトリの。
まとめ
この記事では、機械学習アルゴリズムと FlaskAPI を使用したデプロイメントを使用してワイルド ブルーベリーの収量を予測するエンドツーエンドのプロジェクトについて学びました。 データセットの読み込みを開始し、続いて EDA、データ前処理、機械学習モデリング、クラウド サービス プラットフォームへの展開を行いました。
結果は、モデルが R93 の 2% で作物収量を予測できることを示しました。 Flask API を使用すると、モデルに簡単にアクセスし、それを使用して予測を行うことができます。 これにより、農家、研究者、政策立案者など、幅広いユーザーがアクセスできるようになります。 この記事から得られた教訓をいくつか見てみましょう。
- プロジェクトの問題ステートメントを定義し、エンドツーエンドの ML プロジェクト パイプラインを実行する方法を学びました。
- 探索的データ分析とモデリングのためのデータセットの前処理について学びました
- 最後に、機械学習アルゴリズムを機能セットに適用して、予測用のモデルをデプロイしました。
よくある質問
A. 農家や農業産業は、機械学習アプリケーションである作物収量予測を利用して、特定の年または季節の特定の作物収量を正確に予測および予測できます。 これにより、収穫期に備え、関連コストを効果的に管理できるようになります。
A. スマート農業では、用途に応じてさまざまなアルゴリズムを採用します。 これらのアルゴリズムには、デシジョン ツリー リグレッサー、ランダム フォレスト リグレッサー、勾配ブースティング リグレッサー、ディープ ニューラル ネットワークなどが含まれます。
A. AI と ML を使用して作物の収量を予測および予測し、季節中の収穫にかかる推定コストを予測します。 AI アルゴリズムは、作物の病気や植物の分類を検出し、作物の選別と流通をスムーズに行うのに役立ちます。
A.温度、昆虫の組成、作物の高さ、土壌の位置などのパラメータ、および降雨量や湿度などのさまざまな気象パラメータによって作物の収量が予測されます。
A. 農家と農業産業の成長を支援し、作物の収量を推定するため。 もう XNUMX つの目的は、政府機関が作物生産物の価格を決定し、作物収量の保管と流通に適切な措置を講じられるよう支援することです。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- EVMファイナンス。 分散型金融のための統一インターフェイス。 こちらからアクセスしてください。
- クォンタムメディアグループ。 IR/PR増幅。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/06/crop-yield-prediction-using-machine-learning-and-flask-deployment/

