生成 AI アプリケーションを構築するには、大規模言語モデル (LLM) を新しいデータで強化することが不可欠です。ここで、検索拡張生成 (RAG) テクニックが登場します。 RAG は、外部ドキュメント (Wikipedia など) を使用して知識を強化し、知識集約的なタスクで最先端の結果を達成する機械学習 (ML) アーキテクチャです。 。これらの外部データ ソースを取り込むために、ベクトル データベースが進化しました。これにより、データ ソースのベクトル埋め込みを保存し、類似性検索が可能になります。
この投稿では、RAG 抽出、変換、ロード (ETL) 取り込みパイプラインを構築して、大量のデータを AmazonOpenSearchサービス クラスタ化して使用する PostgreSQL用のAmazonリレーショナルデータベースサービス(Amazon RDS) ベクター データ ストアとして pgvector 拡張子を付けます。各サービスは、k 最近傍 (k-NN) または近似最近傍 (ANN) アルゴリズムと距離メトリックを実装して、類似性を計算します。の統合を紹介します。 レイ RAG コンテキスト ドキュメント検索メカニズムに組み込まれます。 Ray は、オープンソースの Python の汎用分散コンピューティング ライブラリです。これにより、分散データ処理で大量のデータのエンベディングを生成および保存し、複数の GPU 間で並列処理を行うことができます。これらの GPU を備えた Ray クラスターを使用して、各サービスの並列取り込みとクエリを実行します。
この実験では、Amazon RDS 上の OpenSearch サービスと pgvector 拡張機能の次の側面を分析しようとします。
- ベクター ストアとして、RAG の数千万のレコードを含む大規模なデータセットを拡張および処理する機能
- RAG の取り込みパイプラインでボトルネックが発生する可能性がある
- OpenSearch Service と Amazon RDS の取り込み時間とクエリ取得時間で最適なパフォーマンスを達成する方法
ベクター データ ストアと生成 AI アプリケーションの構築におけるその役割について詳しくは、以下を参照してください。 生成 AI アプリケーションにおけるベクター データストアの役割.
OpenSearch サービスの概要
OpenSearch Service は、ビジネスおよび運用データの安全な分析、検索、インデックス作成を行うためのマネージド サービスです。 OpenSearch Service は、テキスト データとベクトル データに複数のインデックスを作成する機能を備えたペタバイト規模のデータをサポートします。最適化された構成により、クエリの高い再現率を目指します。 OpenSearch サービスは、ANN および正確な k-NN 検索をサポートします。 OpenSearch サービスは、次のアルゴリズムの選択をサポートしています。 NMSLIB, フェイス, ルセン k-NN 検索を強化するライブラリ。 Hierarchical Navigable Small World (HNSW) アルゴリズムを使用して OpenSearch の ANN インデックスを作成しました。これは、HNSW アルゴリズムが大規模なデータセットにとってより優れた検索方法とみなされているためです。インデックス アルゴリズムの選択の詳細については、を参照してください。 OpenSearch を使用した XNUMX 億規模のユース ケースに対応する k-NN アルゴリズムを選択する.
pgvector を使用した Amazon RDS for PostgreSQL の概要
pgvector 拡張機能は、オープンソースのベクトル類似性検索を PostgreSQL に追加します。 pgvector 拡張機能を利用することで、PostgreSQL はベクトル埋め込みの類似性検索を実行でき、企業に迅速で熟練したソリューションを提供します。 pgvector は 100 種類のベクトル類似性検索を提供します。XNUMX つは再現率が XNUMX% になる完全最近傍検索、もう XNUMX つは再現率のトレードオフで完全検索よりも優れたパフォーマンスを提供する近似最近隣 (ANN) です。インデックスに対する検索の場合、検索で使用するセンターの数を選択できます。センターが多いほど、パフォーマンスと引き換えに再現率が向上します。
ソリューションの概要
次の図は、ソリューションのアーキテクチャを示しています。

主要なコンポーネントをさらに詳しく見てみましょう。
データセット
OSCAR データをコーパスとして使用し、サンプル質問を提供するために SQUAD データセットを使用します。これらのデータセットは、まず Parquet ファイルに変換されます。次に、Ray クラスターを使用して、Parquet データを埋め込みに変換します。作成されたエンベディングは、pgvector を使用して OpenSearch Service と Amazon RDS に取り込まれます。
OSCAR (Open Super-large Crawled Aggregated corpus) は、言語分類とフィルタリングによって得られる巨大な多言語コーパスです。 一般的なクロール を使用したコーパス 不潔な 建築。データは、元の形式と重複排除された形式の両方で言語ごとに配布されます。 Oscar Corpus データセットは約 609 億 4.5 万レコードで、生の JSONL ファイルとして約 1.8 TB を占めます。その後、JSONL ファイルは Parquet 形式に変換され、合計サイズが 25 TB に最小化されます。取り込み時の時間を節約するために、データセットをさらに XNUMX 万レコードにスケールダウンしました。
SQuAD (スタンフォード質問応答データセット) は、ウィキペディアの一連の記事に対してクラウド ワーカーによって提起された質問で構成される読解データセットです。すべての質問に対する答えはテキストの一部です。 スパン、対応する文章を読んでいるか、質問に答えられない可能性があります。を使用しております 分隊、としてライセンスされています CC-BY-SA 4.0、サンプル質問を提供します。約 100,000 件の質問があり、そのうち 50,000 件以上の答えられない質問は、答えられる質問に似せてクラウド ワーカーによって作成されています。
取り込みとベクトル埋め込みの作成のためのレイ クラスター
私たちのテストでは、エンベディングの作成時に GPU がパフォーマンスに最も大きな影響を与えることがわかりました。したがって、Ray クラスターを使用して生のテキストを変換し、埋め込みを作成することにしました。 レイ は、ML エンジニアと Python 開発者が Python アプリケーションを拡張し、ML ワークロードを高速化できるようにするオープンソースの統合コンピューティング フレームワークです。私たちのクラスターは 5 つの g4dn.12xlarge で構成されていました アマゾン エラスティック コンピューティング クラウド (Amazon EC2) インスタンス。各インスタンスは、4 つの NVIDIA T4 Tensor コア GPU、48 vCPU、および 192 GiB のメモリで構成されました。テキスト レコードの場合、最終的にそれぞれを 1,000 個の部分に分割し、100 個のチャンクが重複するようにしました。これはレコードあたり約 200 になります。埋め込みの作成に使用されるモデルについては、次のように決定しました。 all-mpnet-base-v2 768 次元のベクトル空間を作成します。
インフラストラクチャのセットアップ
インフラストラクチャをセットアップするために、次の RDS インスタンス タイプと OpenSearch サービス クラスター構成を使用しました。
RDS インスタンス タイプのプロパティは次のとおりです。
- インスタンスタイプ: db.r7g.12xlarge
- 割り当てられたストレージ: 20 TB
- マルチ AZ: True
- ストレージの暗号化: True
- パフォーマンス インサイトを有効にする: True
- パフォーマンスインサイトの保持期間: 7 日間
- ストレージタイプ: gp3
- プロビジョンド IOPS: 64,000
- インデックスタイプ: IVF
- リスト数: 5,000
- 距離機能:L2
OpenSearch サービス クラスターのプロパティは次のとおりです。
- バージョン:2.5
- データノード: 10
- データ ノード インスタンス タイプ: r6g.4xlarge
- プライマリノード: 3
- プライマリ ノード インスタンス タイプ: r6g.xlarge
- インデックス: HNSW エンジン:
nmslib - 更新間隔: 30秒
ef_construction:007- メートル: 16
- 距離機能:L2
パフォーマンスのボトルネックを回避するために、OpenSearch Service クラスターと RDS インスタンスの両方に大規模な構成を使用しました。
を使用してソリューションをデプロイします。 AWSクラウド開発キット (AWS CDK) スタック、次のセクションで概要を説明します。
AWS CDK スタックをデプロイする
AWS CDK スタックを使用すると、データの取り込みに OpenSearch Service または Amazon RDS を選択できます。
前提条件
インストールを続行する前に、cdk、bin、src.tc で、Amazon RDS と OpenSearch Service のブール値を好みに応じて true または false に変更します。
サービスにリンクされたものも必要です AWS IDおよびアクセス管理 OpenSearch Service ドメインの (IAM) ロール。詳細については、を参照してください。 Amazon OpenSearch サービス構築ライブラリ。次のコマンドを実行してロールを作成することもできます。
この AWS CDK スタックは次のインフラストラクチャをデプロイします。
- VPC
- ジャンプホスト (VPC 内)
- OpenSearch サービス クラスター (取り込みに OpenSearch サービスを使用する場合)
- RDS インスタンス (取り込みに Amazon RDS を使用する場合)
- An AWS システム マネージャー Ray クラスターを展開するためのドキュメント
- An Amazon シンプル ストレージ サービス (Amazon S3)バケット
- An AWSグルー OSCAR データセット JSONL ファイルを Parquet ファイルに変換するジョブ
- アマゾンクラウドウォッチ ダッシュボード
データをダウンロードする
ジャンプ ホストから次のコマンドを実行します。
git リポジトリを複製する前に、Hugging Face プロファイルがあり、OSCAR データ コーパスにアクセスできることを確認してください。 OSCAR データのクローンを作成するには、ユーザー名とパスワードを使用する必要があります。
JSONL ファイルを Parquet に変換する
AWS CDK スタックが AWS Glue ETL ジョブを作成しました oscar-jsonl-parquet OSCAR データを JSONL から Parquet 形式に変換します。
を実行した後、 oscar-jsonl-parquet ジョブでは、Parquet 形式のファイルが S3 バケットの Parquet フォルダーに存在する必要があります。
質問をダウンロードする
ジャンプ ホストから質問データをダウンロードし、S3 バケットにアップロードします。
Ray クラスターをセットアップする
AWS CDK スタックのデプロイの一部として、という名前の Systems Manager ドキュメントを作成しました。 CreateRayCluster.
ドキュメントを実行するには、次の手順を実行します。
- Systems Manager コンソールの次の場所にあります。 資料 ナビゲーション ペインで、 私が所有.
- Video Cloud Studioで
CreateRayClusterの資料をご参照ください。 - 選択する ラン.
コマンドの実行ページには、クラスターのデフォルト値が設定されています。
デフォルトの構成では、5 つの g4dn.12xlarge が要求されます。これをサポートするための制限がアカウントに設定されていることを確認してください。関連するサービス制限は、オンデマンド G および VT インスタンスの実行です。デフォルトは 64 ですが、この構成には 240 CPU が必要です。
- クラスター構成を確認した後、実行コマンドのターゲットとしてジャンプ ホストを選択します。
このコマンドは次の手順を実行します。
- Ray クラスター ファイルをコピーする
- Ray クラスターをセットアップする
- OpenSearch サービスのインデックスを設定する
- RDS テーブルをセットアップする
Systems Manager コンソールでコマンドの出力を監視できます。このプロセスの初回起動には 10 ~ 15 分かかります。
取り込みを実行する
ジャンプ ホストから Ray クラスターに接続します。
初めてホストに接続するときに、要件をインストールします。これらのファイルはヘッド ノードにすでに存在している必要があります。
いずれの取り込み方法でも、次のようなエラーが発生した場合は、資格情報の期限切れに関連しています。現在の回避策 (この記事の執筆時点) は、資格情報ファイルを Ray ヘッド ノードに配置することです。セキュリティ リスクを回避するために、専用ソフトウェアを開発する場合や実際のデータを操作する場合は、認証に IAM ユーザーを使用しないでください。代わりに、次のようなアイデンティティプロバイダーとのフェデレーションを使用してください。 AWS IAM Identity Center (AWS Single Sign-On の後継).
通常、認証情報はファイルに保存されます。 ~/.aws/credentials Linux および macOS システム上、および %USERPROFILE%.awscredentials Windows では使用できますが、これらはセッション トークンを使用した短期の資格情報です。また、デフォルトの認証情報ファイルをオーバーライドすることはできないため、新しい IAM ユーザーを使用して、セッション トークンなしで長期認証情報を作成する必要があります。
長期認証情報を作成するには、AWS アクセス キーと AWS シークレット アクセス キーを生成する必要があります。これは IAM コンソールから行うことができます。手順については、を参照してください。 IAM ユーザー認証情報を使用して認証する.
キーを作成したら、次を使用してジャンプ ホストに接続します。 セッションマネージャ、Systems Manager の機能を選択し、次のコマンドを実行します。
これで、取り込みステップを再実行できるようになりました。
OpenSearch サービスにデータを取り込む
OpenSearch サービスを使用している場合は、次のスクリプトを実行してファイルを取り込みます。
完了したら、シミュレートされたクエリを実行するスクリプトを実行します。
Amazon RDS にデータを取り込む
Amazon RDS を使用している場合は、次のスクリプトを実行してファイルを取り込みます。
完了したら、RDS インスタンスで完全なバキュームを実行してください。
次に、次のスクリプトを実行して、シミュレートされたクエリを実行します。
Ray ダッシュボードをセットアップする
Ray ダッシュボードをセットアップする前に、 AWSコマンドラインインターフェイス (AWS CLI) をローカルマシン上で実行します。手順については、を参照してください。 最新バージョンの AWS CLI をインストールまたは更新する.
ダッシュボードを設定するには、次の手順を実行します。
- インストール セッションマネージャープラグイン AWS CLI の場合。
- Isengard アカウントで、bash/zsh の一時認証情報をコピーし、ローカル ターミナルで実行します。
- マシンに session.sh ファイルを作成し、次の内容をファイルにコピーします。
- この session.sh ファイルが保存されているディレクトリに変更します。
- コマンドを実行する
Chmod +xファイルに実行権限を与えます。 - 次のコマンドを実行します。
例:
次のようなメッセージが表示されます。
ブラウザで新しいタブを開き、「localhost:8265」と入力します。
Ray ダッシュボードと、実行中のジョブとクラスターの統計が表示されます。ここからメトリクスを追跡できます。
たとえば、Ray ダッシュボードを使用してクラスターの負荷を観察できます。次のスクリーンショットに示すように、取り込み中、GPU は 100% に近い使用率で実行されています。
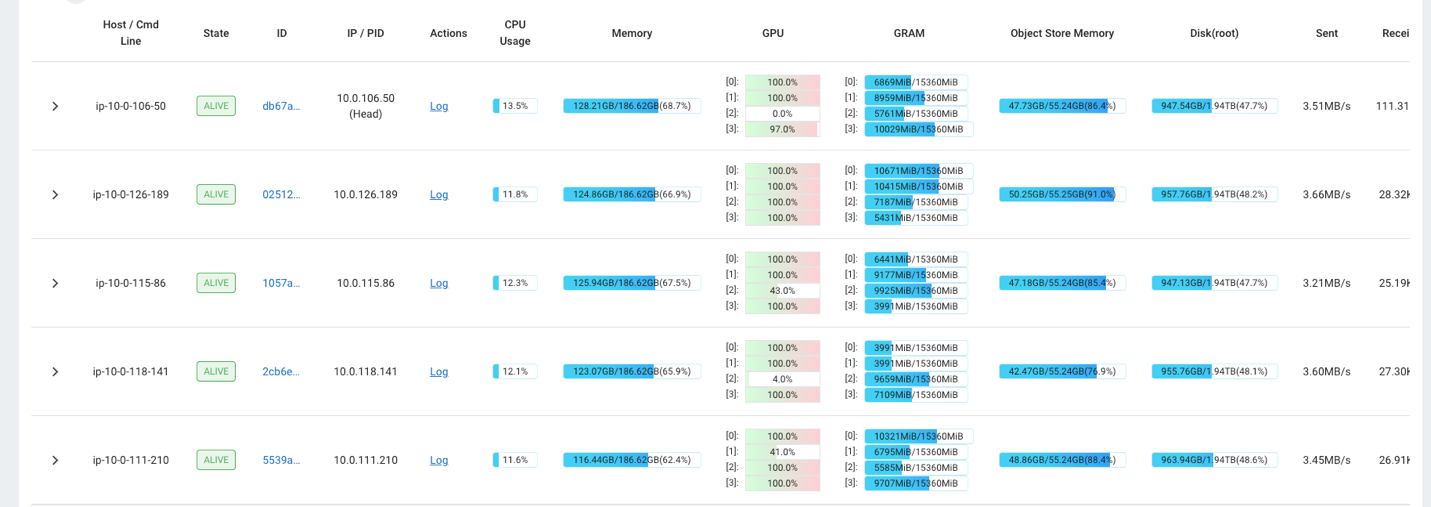
使用することもできます RAG_Benchmarks CloudWatch ダッシュボードでは、取り込み速度とクエリの応答時間を確認できます。
ソリューションの拡張性
このソリューションを拡張して、他の AWS またはサードパーティのベクター ストアをプラグインすることができます。新しいベクター ストアごとに、データ ストアの構成とデータの取り込みのためのスクリプトを作成する必要があります。パイプラインの残りの部分は、必要に応じて再利用できます。
まとめ
この投稿では、ベクトル化された RAG データを OpenSearch Service と pgvector 拡張機能を備えた Amazon RDS の両方にベクトル データストアとして配置するために使用できる ETL パイプラインを共有しました。このソリューションでは、Ray クラスターを使用して、大規模なデータ コーパスを取り込むために必要な並列処理を提供しました。この方法を使用すると、任意のベクター データベースを統合して RAG パイプラインを構築できます。
著者について
 ランディ・デフォー AWS のシニア プリンシパル ソリューション アーキテクトです。彼はミシガン大学で修士号を取得しており、そこで自動運転車のコンピューター ビジョンに取り組みました。彼はコロラド州立大学で MBA も取得しています。 Randy は、ソフトウェア エンジニアリングから製品管理に至るまで、テクノロジー分野でさまざまな役職を歴任してきました。彼は 2013 年にビッグデータ分野に参入し、その分野の探索を続けています。彼は ML 分野のプロジェクトに積極的に取り組んでおり、Strata や GlueCon などの多数のカンファレンスで発表しています。
ランディ・デフォー AWS のシニア プリンシパル ソリューション アーキテクトです。彼はミシガン大学で修士号を取得しており、そこで自動運転車のコンピューター ビジョンに取り組みました。彼はコロラド州立大学で MBA も取得しています。 Randy は、ソフトウェア エンジニアリングから製品管理に至るまで、テクノロジー分野でさまざまな役職を歴任してきました。彼は 2013 年にビッグデータ分野に参入し、その分野の探索を続けています。彼は ML 分野のプロジェクトに積極的に取り組んでおり、Strata や GlueCon などの多数のカンファレンスで発表しています。
 デビッド·クリスチャン 南カリフォルニアを拠点とするプリンシパル ソリューション アーキテクトです。彼は情報セキュリティの学士号を取得しており、自動化に情熱を持っています。彼の重点分野は、DevOps の文化と変革、コードとしてのインフラストラクチャ、および回復力です。 AWS に入社する前は、セキュリティ、DevOps、システム エンジニアリングの役割を担い、大規模なプライベート クラウド環境とパブリック クラウド環境を管理していました。
デビッド·クリスチャン 南カリフォルニアを拠点とするプリンシパル ソリューション アーキテクトです。彼は情報セキュリティの学士号を取得しており、自動化に情熱を持っています。彼の重点分野は、DevOps の文化と変革、コードとしてのインフラストラクチャ、および回復力です。 AWS に入社する前は、セキュリティ、DevOps、システム エンジニアリングの役割を担い、大規模なプライベート クラウド環境とパブリック クラウド環境を管理していました。
 プラチ クルカルニ AWS のシニア ソリューション アーキテクトです。彼女の専門は機械学習で、さまざまな AWS ML、ビッグデータ、分析サービスを使用したソリューションの設計に積極的に取り組んでいます。 Prachi は、ヘルスケア、福利厚生、小売、教育などの複数の分野での経験があり、製品エンジニアリングとアーキテクチャ、管理、カスタマー サクセスのさまざまな役職で働いてきました。
プラチ クルカルニ AWS のシニア ソリューション アーキテクトです。彼女の専門は機械学習で、さまざまな AWS ML、ビッグデータ、分析サービスを使用したソリューションの設計に積極的に取り組んでいます。 Prachi は、ヘルスケア、福利厚生、小売、教育などの複数の分野での経験があり、製品エンジニアリングとアーキテクチャ、管理、カスタマー サクセスのさまざまな役職で働いてきました。
 リチャグプタ AWS のソリューションアーキテクトです。彼女は、顧客向けのエンドツーエンド ソリューションの構築に情熱を注いでいます。彼女の専門は、機械学習と、それを使用してオペレーショナル エクセレンスを実現し、ビジネス収益を促進する新しいソリューションを構築する方法です。 AWS に入社する前は、ソフトウェア エンジニアおよびソリューション アーキテクトとして、大手通信事業者向けのソリューションを構築していました。仕事以外では、彼女は新しい場所を探索するのが好きで、冒険的な活動が大好きです。
リチャグプタ AWS のソリューションアーキテクトです。彼女は、顧客向けのエンドツーエンド ソリューションの構築に情熱を注いでいます。彼女の専門は、機械学習と、それを使用してオペレーショナル エクセレンスを実現し、ビジネス収益を促進する新しいソリューションを構築する方法です。 AWS に入社する前は、ソフトウェア エンジニアおよびソリューション アーキテクトとして、大手通信事業者向けのソリューションを構築していました。仕事以外では、彼女は新しい場所を探索するのが好きで、冒険的な活動が大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

