アマゾンケンドラ 機械学習 (ML) を利用したインテリジェントな検索サービスです。 幅広いリポジトリに保存されているドキュメントにインデックスを付け、ユーザーが検索したキーワードまたは自然言語の質問に基づいて、最も関連性の高いドキュメントを見つけます。 シナリオによっては、検索を行うユーザーのコンテキストに基づいて検索結果をフィルター処理する必要があります。 そのユーザーまたはユーザー グループに固有のドキュメントを上位の検索結果として見つけるには、さらに絞り込む必要があります。
このブログ投稿では、特定のユーザーまたはユーザー グループに適用されるカスタム検索結果の取得に焦点を当てています。 たとえば、ある教育機関の教員はさまざまな学部に所属しており、コンピューター サイエンス学部に所属する教授がアプリケーションにサインインして、「」というキーワードで検索するとします。教員コース」の場合、データ ソースの可用性に基づいて、同じ部門に関連するドキュメントが上位の結果として表示されます。
ソリューションの概要
この問題を解決するには、索引付けおよび検索対象の文書に関連付けられている XNUMX つ以上の固有のメタデータ情報を識別できます。 ユーザーが Amazon Lex チャットボット、ユーザー コンテキスト情報は、 アマゾンコグニート. Amazon Lex チャットボットは、直接統合または AWSラムダ 関数。 AWS Lambda 関数を使用すると、Amazon Kendra API 呼び出しをきめ細かく制御できます。 これにより、Amazon Lex チャットボットから Amazon Kendra にコンテキスト情報を渡して、検索クエリを微調整できます。
Amazon Kendra では、次を使用してドキュメント メタデータ属性を提供します。 カスタム属性. 取り込みプロセス中にドキュメント メタデータをカスタマイズするには、 AmazonKendra開発者ガイド. ドキュメント メタデータの生成とインデックス作成の手順が完了したら、メタデータ属性を使用して検索結果を絞り込むことに集中する必要があります。 これに基づいて、たとえば、コンピューター サイエンス部門のユーザーが、その部門との関連性に応じてランク付けされた検索結果を取得できるようにすることができます。 つまり、その部署に関連する文書がある場合、その文書は検索結果リストの一番上にあり、部署情報や一致しない部署がない他の文書よりも優先されます。
では、このソリューションを構築する方法を詳しく見ていきましょう。
ソリューションウォークスルー

図 1: 提案されたソリューションのアーキテクチャ図
このブログでユース ケースを示すために使用されるサンプル アーキテクチャを図 1 に示します。 Amazon シンプル ストレージ サービス (Amazon S3) バケット。 AWS Lambda 関数を介して Amazon Kendra インデックスに接続する Amazon Lex を使用して、シンプルなチャットボットをセットアップします。 ユーザーは、Amazon Cognito を利用して認証し、Amazon Lex チャットボット ユーザー インターフェイスへのアクセスを取得します。 デモでは、Amazon Cognito に 1 つの異なる部門に属する XNUMX 人の異なるユーザーがいます。 この設定を使用すると、部門 A のユーザー XNUMX を使用してサインインすると、検索結果は部門 A に属するフィルターされたドキュメントになり、部門 B のユーザーの場合はその逆になります。
前提条件
Amazon Lex チャットボットを Amazon Kendra インデックスと統合する前に、ソリューションの基本的な構成要素をセットアップする必要があります。 大まかに言うと、このデモを有効にするには、次の手順を実行する必要があります。
- 適切なドキュメントとフォルダー構造で S3 バケット データ ソースをセットアップします。 S3 バケットの作成手順については、次を参照してください。 AWS ドキュメント – バケットの作成. 必要なドキュメント メタデータをドキュメントと共に S3 バケットに静的に保存します。 ドキュメントのドキュメント メタデータを S3 バケットに保存する方法を理解するには、以下を参照してください。 AWS ドキュメント – Amazon S3 ドキュメントのメタデータ。 サンプルのメタデータ ファイルは次のようになります。
- 次の手順に従って、Amazon Kendra インデックスを設定します。 AWS ドキュメント – インデックスの作成.
- 次の手順に従って、S3 バケットをデータ ソースとしてインデックスに追加します。 AWS ドキュメント – Amazon S3 データ ソースの使用. Amazon Kendra がメタデータ情報を認識し、部門情報をファセットできるようにします。
- Amazon Kendra インデックスのカスタム属性が次のように設定されていることを確認する必要があります。 facetable、検索可能、表示可能. これは、Amazon Kendra コンソールで行うことができます。 データ管理 選択 ファセット定義. AWS コマンドライン インターフェイス (AWS CLI) を使用してこれを行うには、 ケンドラ更新インデックス
- XNUMX 人のユーザーで Amazon Cognito ユーザープールをセットアップします。 カスタム属性をユーザーに関連付けて、部門の値を取得します。
- ユースケースを推進するために必要なインテント、スロット、発話でシンプルな Amazon Lex v2 チャットボットを構築します。 このブログでは、基本的なボットの設定に関する詳細なガイダンスは提供しません。ブログの焦点は、フロントエンドから Amazon Kendra インデックスにユーザー コンテキスト情報を送信する方法を理解することです。 シンプルな Amazon Lex ボットの作成の詳細については、 ボットのドキュメントの作成. ブログの残りの部分では、Amazon Lex チャットボットには次のものがあると想定しています。
- 意図 – SearchCourses
- 発話 – 「{subject_types} で利用できるコースは何ですか?」
- スロット – 選択年 (値を持つことができます – 選択、非選択)
- ユーザーがチャットボットの認証と対話に使用するチャットボット インターフェイスを作成する必要があります。 を使用できます。 サンプル Amazon Lex Web インターフェイス (lex-web-ui) 開始するために AWS によって提供されます。 これにより、ユーザー認証のために Amazon Cognito が既に統合されており、必要なコンテキスト情報と Amazon Cognito JWT ID トークンがバックエンドの Amazon Lex チャットボットに渡されるため、統合のテストプロセスが簡素化されます。
基本的な構成要素が整ったら、次のステップは、Amazon Lex チャットボットのインテント フルフィルメントと Amazon Kendra インデックスを結び付ける AWS Lambda 関数を作成することです。 このブログの残りの部分では、特にこのステップに焦点を当て、この統合を実現する方法について詳しく説明します。
ユーザーコンテキストを渡すために Amazon Lex を Amazon Kendra と統合する
前提条件が整ったので、Amazon Lex チャットボットを Amazon Kendra インデックスと統合する作業を開始できます。 統合の一環として、次のタスクを実行する必要があります。
- となる AWS Lambda 関数を作成します。 Amazon Lex チャットボットに接続. この Lambda 関数では、受信した入力イベントを解析して、イベント オブジェクトのセッション属性の一部として渡される Amazon Cognito ID トークンから、ユーザー ID やユーザーの追加属性などのユーザー情報を抽出します。
- Amazon Kendra クエリを形成するためのすべての情報が整ったら、検索結果ビューを絞り込むために使用するすべてのカスタム属性を含めて、Amazon Kendra インデックスにクエリを送信します。
- 最後に、Amazon Kendra クエリが結果を返したら、適切な Amazon Lex レスポンス オブジェクトを生成して、検索結果のレスポンスをユーザーに送り返します。
- AWS Lambda 関数を Amazon Lex チャットボットに関連付けて、チャットボットがユーザーからクエリを受け取るたびに AWS Lambda 関数をトリガーするようにします。
これらの手順について、以下で詳しく見ていきましょう。
AWS Lambda 関数でユーザー コンテキストを抽出する
最初に行う必要があるのは、Amazon Lex チャットボット インテントと Amazon Kendra インデックスの間のブリッジとして機能する Lambda 関数をコーディングしてセットアップすることです。 の 入力イベント形式 ドキュメンテーションは、完全な入力 Javascript Object Notation (JSON) 入力イベント構造を提供します。 認証システムがユーザー ID を HTTP POST リクエストとして Amazon Lex に提供する場合、値は “userId” JSON オブジェクトのキー。 Amazon Cognito を使用して認証が実行されると、 “sessionState”.”sessionAttributes”.”idtokenjwt” key には、JSON Web Token (JWT) トークン オブジェクトが含まれます。 Python で AWS Lambda 関数をプログラミングしている場合、イベント オブジェクトから属性を読み取る XNUMX 行のコードは次のようになります。
JWT トークンはエンコードされます。 JWT トークンをデコードすると、Amazon Cognito ユーザーに関連付けられたカスタム属性の値を読み取ることができます。 参照する Amazon Cognito JSON Web Token の署名をデコードして検証するにはどうすればよいですか? JWT トークンをデコードして検証し、カスタム値を取得する方法を理解する。 トークンからクレームを取得したら、次のようにカスタム属性を抽出できます。 “department” Python では、次のようになります。
サードパーティ ID プロバイダー (IDP) を使用してチャットボットに対する認証を行う場合、IDP が必要な属性を含むトークンを送信することを確認する必要があります。 トークンには、部門、グループ メンバーシップなどのカスタム属性に必要なデータが含まれている必要があります。これは、セッション コンテキスト変数で Amazon Lex チャットボットに渡されます。 チャットボット インターフェースとして lex-web-ui を使用している場合は、 lex-web-ui readme の認証情報管理セクション Amazon Cognito が lex-web-ui とどのように統合されているかを理解するためのドキュメント。 サードパーティの ID プロバイダーを Amazon Cognito ID プールと統合する方法を理解するには、次のドキュメントを参照してください。 ID プール (フェデレーション ID) 外部 ID プロバイダー.
ユーザーからのクエリ トピックについては、Amazon Lex によって識別されたスロットの値を読み取ることで、イベント オブジェクトから抽出できます。 スロットの実際の値は、キーを持つ属性から読み取ることができます “sessionState”.”intent”.”slots”.”slot name”.”value”.”interpretedValue” 識別されたデータ型に基づきます。 このブログの例では、Python を使用して、次のコード行を使用してクエリ値を読み取ることができます。
に記載されているように 入力イベント形式のドキュメント、スロット値は、異なるデータ型の複数のエントリを持つことができるオブジェクトです。 特定の値のデータ型は、 “'sessionState”.”intent”.”slots”.”slot name”.”shape”. 属性が空または欠落している場合、データ型は文字列です。 このブログの例では、Python を使用して、次のコード行を使用してクエリ値を読み取ることができます。
スロットのデータ形式がわかれば、' の値を解釈できます。スロット値' で特定されたデータ型に基づく 「スロットタイプ」.
AWS Lambda から Amazon Kendra インデックスをクエリする
入力イベント オブジェクトからすべての関連情報を抽出できたので、Lambda 内で Amazon Kendra クエリを作成する必要があります。 Amazon Kendra では、特定の属性を介してクエリをフィルタリングできます。 を使用して Amazon Kendra にクエリを送信すると、 クエリAPIの場合、文書属性を属性フィルターとして指定して、ユーザーの検索結果がそのフィルターに一致する値に基づくようにすることができます。 属性の階層に対してクエリを実行する必要がある場合は、フィルターを論理的に組み合わせることができます。 サンプルでフィルター処理されたクエリは次のようになります。
Amazon Kendra でのフィルタリングクエリをより詳細に理解するには、以下を参照してください。 AWS ドキュメント – クエリのフィルタリング. 上記のクエリに基づいて、Amazon Kendra からの検索結果は、メタデータ属性が "書類" 指定されたフィルターの値と一致します。 Python では、これは次のようになります。
前述のように、参照してください。 Amazon ケンドラ クエリ API ドキュメントを参照して、ユーザー検索をフィルタリングするための複雑なフィルター条件など、クエリに提供できるさまざまな属性をすべて理解してください。
AWS Lambda 関数で Amazon Kendra レスポンスを処理する
Amazon Kendra インデックス内のクエリが成功すると、クエリ API からの応答として JSON オブジェクトが返されます。 すべての属性の詳細を含む応答オブジェクトの完全な構造は、 Amazon ケンドラ クエリ API ドキュメンテーション。 を読むことができます “TotalNumberOfResults” 送信したクエリに対して返された結果の総数を確認します。 SDK では最大 100 個のアイテムしか取得できないことに注意してください。 クエリ結果は “ResultItems” の配列としての属性クエリ結果項目」オブジェクト。 から “QueryResultItem”、すぐに関心のある属性は “DocumentTitle”, “DocumentExcerpt”, “DocumentURI”. Python では、以下のコードを使用して、最初からこれらの値を抽出できます。 “ResultItems” Amazon Kendra レスポンス:
理想的には、次の値を確認する必要があります。 “TotalNumberOfResults” を繰り返します “ResultItems” 関心のあるすべての結果を取得するための配列。 次に、Amazon Lex チャットボットに送信される有効な AWS Lambda 応答オブジェクトに適切にパックする必要があります。 予想される Amazon Lex v2 チャットボットの応答の構造は、 応答形式セクション. 応答オブジェクトをチャットボットに返す前に、少なくとも次の属性を入力する必要があります。
- sessionState オブジェクト – このオブジェクトの必須属性は
“dialogAction”. これは、チャットボットが次に移行する必要がある状態/アクションを定義するために使用されます。 必要な結果をすべて取得し、プレゼンテーションの準備が整ったために会話が終了した場合は、閉じるように設定します。 応答が関連するチャットボットのインテントと、チャットボットが移行する必要があるフルフィルメント状態を示す必要があります。 これは次のように行うことができます。
- メッセージ オブジェクト – Amazon Kendra クエリから抽出した値に基づいて、応答にメッセージ オブジェクトを入力して、検索結果をチャットボットに送信する必要があります。 これを実現するための例として、次のコードを使用できます。
AWS Lambda 関数を Amazon Lex チャットボットに接続する
この時点で、受信イベントからユーザー コンテキストを抽出し、ユーザー コンテキストに基づいて Amazon Kendra に対してフィルター処理されたクエリを実行し、Amazon Lex チャットボットに応答できる完全な AWS Lambda 関数が用意されています。 次のステップは、Amazon Lex チャットボットを設定して、この AWS Lambda 関数をインテント フルフィルメント プロセスの一部として使用することです。 これは、次の文書化された手順に従って実行できます。 Lambda 関数をボット エイリアスにアタッチする. この時点で、チャットボットと対話するユーザーに基づいてコンテキストクエリを実行できる Amazon Kendra インデックスと統合された、完全に機能する Amazon Lex チャットボットが完成しました。
この例では、User2 と User 1 の 2 人のユーザーがいます。ユーザー 1 はコンピューター サイエンス部門のユーザーで、ユーザー 2 は土木工学部門のユーザーです。 部門に関連するコンテキスト情報に基づいて、図 2 は、XNUMX つのチャットボットの対話のスクリーンショットを並べて、同じ会話がどのように異なる結果をもたらすかを示しています。
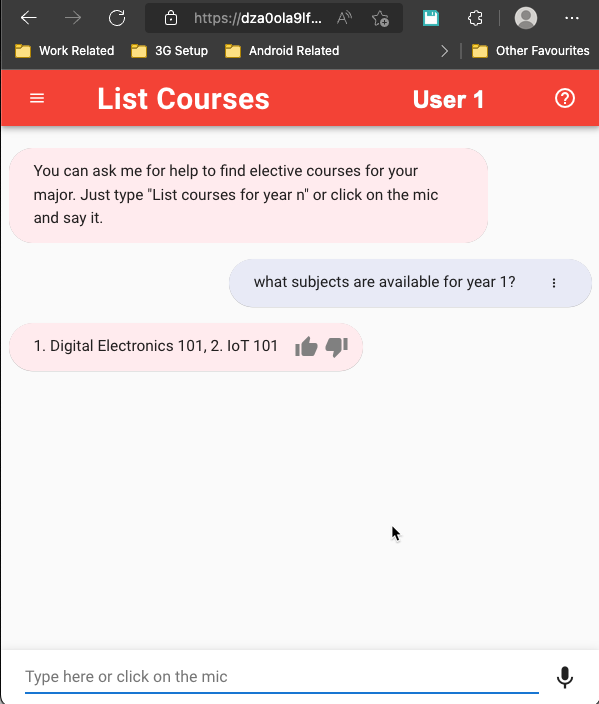 |
 |
図 2: 複数のユーザー チャット セッションを並べて比較
掃除
セットアップ例に従った場合は、作成したリソースをクリーンアップして、長期的に追加料金が発生しないようにする必要があります。 リソースのクリーンアップを実行するには、次のことを行う必要があります。
- Amazon Kendra インデックスと関連する Amazon S3 データ ソースを削除する
- Amazon Lex チャットボットを削除する
- S3 バケットを空にする
- S3 バケットを削除する
- 次の手順に従って、Lambda 関数を削除します。 クリーンアップセクション.
- 関連するリソースを削除して、lex-web-ui リソースを削除します。 AWS CloudFormation スタック
- Amazon Cognito リソースを削除する
まとめ
Amazon Kendra は、非常に正確なエンタープライズ検索サービスです。 自然言語処理機能とインテリジェントなチャットボットを組み合わせることで、ユーザー コンテキストに基づくカスタム出力を必要とするあらゆるユース ケースに対応する堅牢なソリューションが作成されます。 ここでは、複数の部門を持つ組織のサンプル ユース ケースを検討しましたが、このメカニズムは、最小限の変更で他の関連するユース ケースに適用できます。
始める準備はできましたか? の アクセンチュア AWS ビジネス グループ (AABG) は、顧客がデジタル イノベーションのペースを加速させ、クラウドの採用と変革から増加するビジネス価値を実現するのを支援します。 私たちのチームとつながる Accentureaws@amazon.com 顧客向けのインテリジェントなチャットボット ソリューションを構築する方法を学びます。
著者について
 ロヒット・サティヤナラーヤナ シンガポールの AWS のパートナー ソリューション アーキテクトであり、アクセンチュアとグローバルに連携する AWS GSI チームの一員です。 彼の趣味は、ファンタジーやサイエンス フィクションを読んだり、映画を見たり、音楽を聴いたりすることです。
ロヒット・サティヤナラーヤナ シンガポールの AWS のパートナー ソリューション アーキテクトであり、アクセンチュアとグローバルに連携する AWS GSI チームの一員です。 彼の趣味は、ファンタジーやサイエンス フィクションを読んだり、映画を見たり、音楽を聴いたりすることです。
 レオ・アン シニア ソリューション アーキテクトであり、プライベート クラウドとパブリック クラウドで費用対効果の高い高性能インフラストラクチャ ソリューションを設計および提供する能力を実証してきました。 彼は、顧客がクラウド テクノロジーを使用してビジネス上の課題に対処するのを支援することを楽しんでおり、機械学習を専門としており、顧客が AI/ML をビジネスの成果に活用できるよう支援することに重点を置いています。
レオ・アン シニア ソリューション アーキテクトであり、プライベート クラウドとパブリック クラウドで費用対効果の高い高性能インフラストラクチャ ソリューションを設計および提供する能力を実証してきました。 彼は、顧客がクラウド テクノロジーを使用してビジネス上の課題に対処するのを支援することを楽しんでおり、機械学習を専門としており、顧客が AI/ML をビジネスの成果に活用できるよう支援することに重点を置いています。
 ヘマラサカタリ Accenture のソリューション アーキテクトです。 彼女は、アクセンチュア AWS ビジネス グループ (AABG) 内のラピッド プロトタイピング チームの一員です。 彼女は、組織が AWS クラウドにビジネスを移行して運営するのを支援しています。 彼女は観葉植物を育てるのが好きで、長い自然遊歩道を歩くのが大好きです。
ヘマラサカタリ Accenture のソリューション アーキテクトです。 彼女は、アクセンチュア AWS ビジネス グループ (AABG) 内のラピッド プロトタイピング チームの一員です。 彼女は、組織が AWS クラウドにビジネスを移行して運営するのを支援しています。 彼女は観葉植物を育てるのが好きで、長い自然遊歩道を歩くのが大好きです。
 スルティ・マミディパリ Accenture の AWS ソリューション アーキテクトであり、クラウド ネイティブ アーキテクチャの採用を成功させるためにクライアントを支援しています。 仕事以外では、ガーデニング、料理、幼児と過ごす時間が大好きです。
スルティ・マミディパリ Accenture の AWS ソリューション アーキテクトであり、クラウド ネイティブ アーキテクチャの採用を成功させるためにクライアントを支援しています。 仕事以外では、ガーデニング、料理、幼児と過ごす時間が大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/building-ai-chatbots-using-amazon-lex-and-amazon-kendra-for-filtering-query-results-based-on-user-context/

