
著者による画像
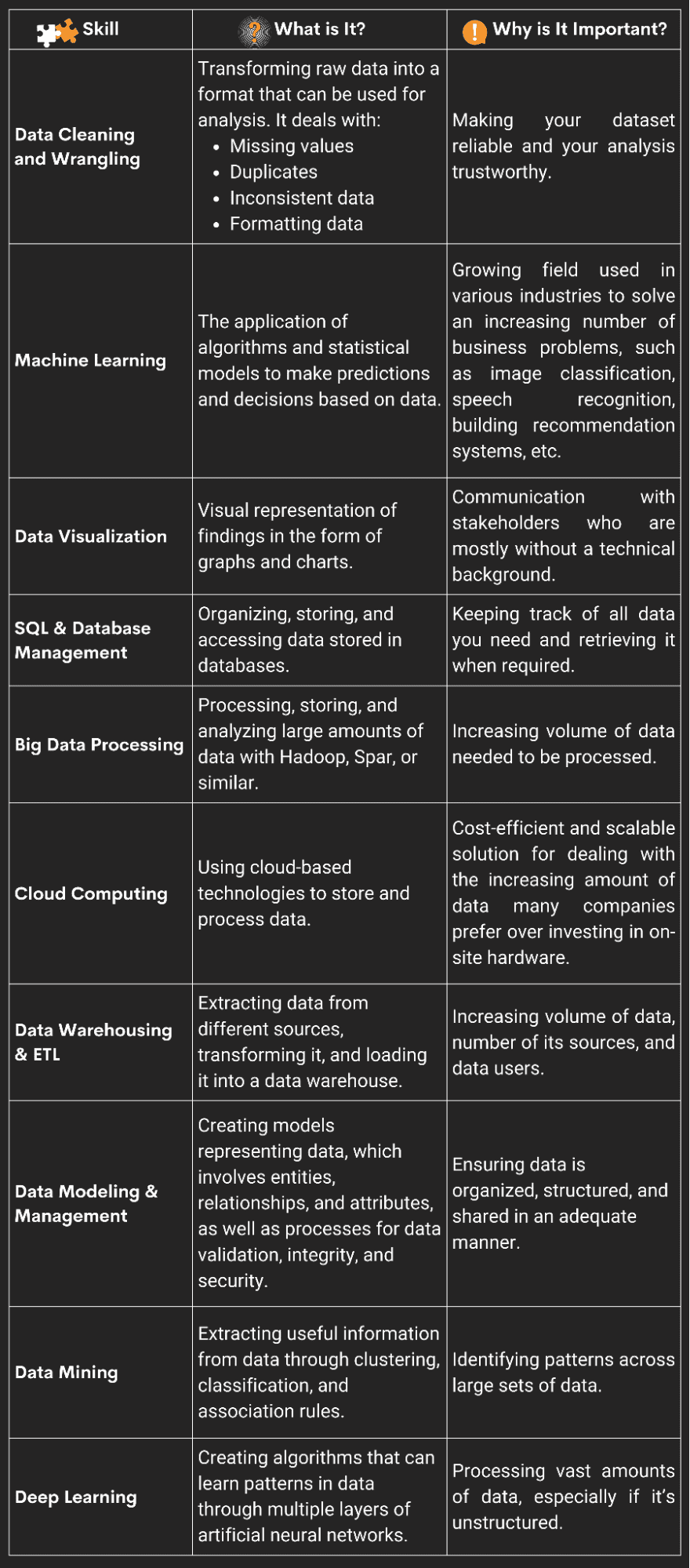
時代は変わりつつあります。 2023 年にデータ サイエンティストになりたい場合は、すでに習得しているはずの多数の既存のスキルだけでなく、名簿に追加する必要がある新しいスキルがいくつかあります。
なぜこれほど幅広いスキルセットが必要なのですか? 問題の一部は、ジョブ スコープ クリープです。 データ サイエンティストとは何か、何をすべきかは誰にもわかりません。将来の雇用主はもちろんです。 そのため、データを持つものはすべてデータ サイエンスのカテゴリに分類され、対処する必要があります。
データのクリーニング、変換、統計分析、視覚化、伝達、予測の方法を知っている必要があります。 それだけでなく、新しいテクノロジー (または最近主流になったテクノロジー) もあなたの仕事の責任に追加される可能性があります。
この記事では、データ サイエンティストになるために 19 年に知っておく必要がある上位 2023 のスキルを分析します。
ここでは、最も重要な XNUMX の概要を説明します。
著者による画像
これらのスキルは、仕事に就き、面接を突破し、時代の先を行き、その昇進のために交渉するのに役立ちます. 各セクションでは、各スキルとは何か、なぜ重要なのかを簡単にまとめ、これらのスキルを学ぶ場所をいくつか紹介します。
それは データ サイエンティストの仕事の 80%、データ クリーニングとラングリングは、データ サイエンティストが 2023 年に習得できる最も重要なスキルの XNUMX つです。
データのクリーニングとラングリングとは?
データのクリーニングとラングリングは、生データを分析に使用できる形式に変換するプロセスです。 これには、欠損値の処理、重複の削除、一貫性のないデータの処理、および分析の準備が整った方法でのデータの書式設定が含まれます。
通常、データのクリーニングとは、不良/不正確な値を取り除き、空白を埋め、重複を見つけ、その他の方法でデータセットが期待できるほどきれいで確実に正確であることを確認することを指します。 それをラングリングする (またはマンギング、マッサージ、またはそのような他の奇妙な動詞) とは、分析可能な形にすることを意味します。 それを別の見やすい形式に変換またはマップします。
2023 年にデータ サイエンティストになることが重要な理由
データサイエンティストに何をしているのか尋ねると、彼らが最初に言及することの XNUMX つは、データのクリーニングとラングリングです。 データがきれいで分析可能な形で手に入るわけではないため、データを整理する方法を知ることは非常に重要です。
データをクリーニングしてラングリングする機能により、分析結果が信頼できるものになり、誤った結論が導き出されるのを防ぐことができます。
この重要なスキルはどこで学べますか?
データのクリーニングとラングリングを学ぶための優れたオプションがたくさんあります。 ハーバードは、 ここから EdXで。 また、50 億を超える Web ページで構成される Web クロール データである Common Crawl のような無料の生のデータセットをクリーニングしてラングリングすることで、自分で練習することもできます (こちら)、またはブラジルの気象データ (こちら).
いいえ、ただの流行語ではありません! 機械学習は、将来のデータサイエンティストにとって知っておくべき非常に重要なスキルです。
機械学習とは何ですか?
機械学習は、データに基づいて予測と決定を行うためのアルゴリズムと統計モデルのアプリケーションです。
これは、明示的にプログラムしなくても、データから学習することでコンピューターが特定のタスクのパフォーマンスを向上できるようにする人工知能のサブフィールドです。 自動化に役立ちます。 どの業界でも見かけます。
2023 年にデータ サイエンティストになることが重要な理由
機械学習は急速に成長している分野であり、複雑な問題を解決し、さまざまな業界で予測を行うための重要なツールになっているため、2023 年には機械学習について知っておく必要があります。
機械学習アルゴリズムを使用して、画像を分類し、音声を認識し、自然言語処理を行い、レコメンデーション システムを作成できます。 これらの ML 支援タスクを実行していない (または実行したくない) 業界を見つけるのは難しいでしょう。
機械学習に習熟していれば、データ サイエンティストは、大規模で複雑なデータ セットから貴重な洞察を抽出し、より良いビジネス上の意思決定を推進できる予測モデルを開発できます。
この重要なスキルはどこで学べますか?
のリポジトリがあります XNUMX 以上の機械学習プロジェクト ScrataScratch で、このスキルを履歴書で披露してください。 TensorFlow には、 機械学習を学習するための優れた無料リソースのセット。

著者による画像
このスキルは一目瞭然です。 数値を分析すると、主要な利害関係者は、見栄えの良いグラフやチャートで結果を理解したいと思うでしょう。
データの視覚化とは何ですか?
データの視覚化とは、データを理解しやすくするためにチャート、グラフ、およびその他のグラフィックを作成することです。 クリーンアップ、ラングリング、または予測したばかりの数値を取得し、それらをある種の視覚的な形式に変換して、他の人と傾向を伝えたり、傾向を見つけやすくしたりします.
2023 年にデータ サイエンティストになることが重要な理由
2023 年、データ サイエンティストにとって、データを視覚化できることは非常に重要です。 これは、一見すると明らかではないデータの隠れたパターンや傾向を明らかにするための秘密の超能力を持っているようなものです。 そして最高の部分は? 魅力的で記憶に残る方法で、調査結果を他のユーザーと共有できます。 データ サイエンティストとして、さまざまな経験レベルのグループで作業しますが、図は数字の列よりもはるかに簡単に理解できます。
したがって、洞察や発見を効果的に伝えることができるデータサイエンティストになりたい場合は、データ視覚化の技術を習得することが重要です。
この重要なスキルはどこで学べますか?
これがリストです データを学ぶための無料の場所。
SQL は構造化照会言語です。 データ サイエンティストは、SQL を使用して SQL データベースを操作したり、データベースを管理したり、データ ストレージ タスクを実行したりします。
SQL およびデータベース管理とは何ですか?
SQL は、構造化データへのアクセスと操作を可能にする非常に人気のある言語です。 これは、SQL で一般的に行われるデータベース管理と密接に関連しています。 データベース管理とは、基本的に、ある場所からデータを整理、保存、取得する方法です。 SQL データベースはその XNUMX つです。 トップバックエンドテクノロジー 2023 年に学習する必要があるため、データ サイエンスだけではありません。
2023 年にデータ サイエンティストになることが重要な理由
データ サイエンティストは、すべてのデータを追跡し、整理されていることを確認し、誰かが必要なときに取得する必要があります。 それが、SQL とデータベース管理によって実現できることです。
この重要なスキルはどこで学べますか?
Coursera トンを持っています 優れた手頃な価格のデータベース管理/管理コースを試すことができます。 いくつかのプレビューを見ることもできます SQLインタビューの質問 これは、知識をテストするのに役立ちます。
ビッグデータはバズワードですが、実際の概念でもあります – オラクル 定義 それは、「より多くの種類を含み、より多くの量と速度で到達するデータ」、または XNUMX つの V を持つデータです。
ビッグデータ処理とは
ビッグ データ処理とは、Hadoop や Spark などのテクノロジを使用して大量のデータを処理、保存、分析する機能です。
2023 年にデータ サイエンティストになることが重要な理由
2023 年には、ビッグデータを処理する能力がデータ サイエンティストにとって重要になります。 生成されるデータの量は指数関数的に増加し続けており、このデータを効果的に処理および分析できることは、情報に基づいた意思決定を行い、貴重な洞察を得るために不可欠です。 ビッグ データ処理技術を深く理解しているデータ サイエンティストは、大規模なデータ セットを簡単に処理し、そこに含まれる情報を最大限に活用できます。
また、その流行語のおかげで、履歴書に「ビッグデータ」をぶつけても問題ありません。
どこで学べますか?
私はSimpliarn'sが大好きです YouTube チュートリアル シリーズ このコンセプトに。

著者による画像
面白いことに、より多くの製品やサービスがクラウドに移行するにつれて、クラウド コンピューティングはほとんどすべての技術職の仕事の要件になります。 DevOps またはデータサイエンティスト。
クラウドコンピューティングとは
クラウド コンピューティングとは、AWS、Azure、Google Cloud などのクラウドベースのテクノロジーとプラットフォームを使用してデータを保存および処理することです。 いつでもどこからでもアクセスできる仮想倉庫のようなものです。 データやコンピューティング リソースをローカル マシンやサーバーに格納する代わりに、クラウド コンピューティングを使用すると、組織 (およびデータ サイエンティスト) はインターネット経由でこれらのリソースにアクセスできます。
2023 年にデータ サイエンティストになることが重要な理由
強調し続けているように、データ サイエンティストとして扱うことが期待されるデータの量は増え続けています。 オンプレミスで処理するのではなく、クラウドで処理する企業が増えるでしょう。 このデータをスケーラブルかつ効率的な方法で保存および処理する機能がますます重要になっています。
クラウド コンピューティングは、これに対する効果的なソリューションを提供し、データ サイエンティストが高価なハードウェアやインフラストラクチャを必要とせずに、膨大な量のコンピューティング リソースとデータ ストレージにアクセスできるようにします。
どこで学べますか?
良いニュースは、企業がさまざまなクラウドを所有しているためです。その多くは、無料でそれについて教えることに既得権を持っているため、それらのクラウドの使用法を学ぶことができます。 でログイン, Microsoft, Amazon すべてに優れたクラウド コンピューティング リソースがあります。
「ちょっと待って、データベースをカバーしただけじゃないの? データウェアハウスとは?」 私はあなたが尋ねると聞きます。
わかりました。 最も重要なデータ サイエンス スキルは、すべての頭字語と専門用語を正確に保つことだと感じることがあります。
データ ウェアハウジングと ETL とは
まず、データ ウェアハウスとデータベースを区別しましょう。
ウェアハウスには複数のシステムの現在および過去のデータが保存され、データベースにはプロジェクトを強化するために必要な現在のデータが保存されます。 データベースには、アプリケーションを強化するために必要な現在のデータが格納されますが、データ ウェアハウスには、データを分析するために、XNUMX つ以上のシステムの現在および履歴データが事前定義された固定スキーマに格納されます。
簡単に言えば、データベースは主に XNUMX つのプロジェクトのデータを格納するのに対し、データ ウェアハウスは多数の異なるプロジェクトのデータをまとめて使用することになります。
ETL は、抽出、変換、ロードの略で、データ ウェアハウジングを含むプロセスです。 ETL ツールは、必要なデータ ソース システムからデータを抽出し、ステージング領域で変換 (通常はクリーニング、操作、または「変更」) してから、データ ウェアハウスにロードします。
2023 年にデータ サイエンティストになることが重要な理由
この点はどのスキルでも繰り返してきた気がしますが、データは増えています。 企業はそれを切望しており、あなたがそれを管理することを期待しています。 構築可能なパイプラインでデータを管理する方法を知ることは重要です。
どこで学べますか?
SQL や Python などの特定の言語で適切な ETL を実行する方法を学ぶことをお勧めします。 Datacamp は よいもの パイソンで。 Microsoft は、より多くの 中級者向けチュートリアル SQL オプションを通過します。
すべてのデータ サイエンティストはモデルのスペシャリストです。 私はジゼル・ブンチェンについて話しているのではありません。 つまり、システム内でデータがどのように保存および編成されるかのモデルを作成するということです。
データのモデリングと管理とは?
データのモデリングと管理は、データを表現する数学的モデルを作成するプロセスであり、データの品質、正確性、および有用性を維持するための管理です。
これには、データ エンティティ、関係、および属性の定義と、データの検証、整合性、およびセキュリティのためのプロセスの実装が含まれます。
簡単に言えば、データ モデリングとは、基本的に、雇用主のシステムでデータを整理して接続する方法の青写真を作成することを意味します。 家の設計図を描くようなものと考えることができます。 設計図がさまざまな部屋とそれらがどのように接続されているかを示すように、データ モデリングは、さまざまな情報がどのように関連し、相互に接続されているかを示します。
これにより、データが一貫した効果的な方法で保存および使用されるようになります。
2023 年にデータ サイエンティストになることが重要な理由
データ サイエンティストは、データがアクセスしやすい方法で整理および構造化されていることを確認する責任があります。 データのモデリングと管理は、データの操作、共有、正確性の確認、データに基づく意思決定に役立ちます。
どこで学べますか?
マイクロソフトは良い intro 彼らのブログで、わずかXNUMX分の長さで高い評価を得ています。 始めるには良い場所です。

画像提供者
多くのデータ サイエンス用語は、モデリングやマイニングなどの他の専門職から奪われています。 それが何を意味し、なぜそれが重要なのかを見ていきましょう。
データマイニングとは
データ マイニングは、クラスタリング、分類、関連付けルールなどの手法を使用して、データから有用な情報を抽出するプロセスです。 あなたは、有益な黄金のナゲットを見つけるために、真のデータの洪水をふるいにかけています。 (このスキルには、データのパンニングの方が適しているかもしれません!)
2023 年にデータ サイエンティストになることが重要な理由
想像してみてください。あなたは 2023 年のデータ サイエンティストです。XNUMX 万もの異なるソースからデータが入ってきます。 これらすべてのデータ ファウンテンのパターンを特定するために、どのスキルを使用しますか?
データマイニングです。
どこで学べますか?
データ マイニングは通常、ビッグ データまたはデータ分析を扱うコースで扱われます。これは、これら XNUMX つのスキルのかなり重要な要素であるためです。 EdX カップルを提供します データマイニングを学ぶためのオプションの。
ディープラーニングは機械学習とは微妙に違う! 深層学習は、機械学習のサブフィールドです。
ディープラーニングとは何ですか?
ディープ ラーニングは機械学習の一面であり、複数層の人工ニューラル ネットワークを通じてデータのパターンを学習できるアルゴリズムの作成に重点を置いています。 (ちなみに、人工ニューラル ネットワークは、人間の脳の構造と機能に類似するようにモデル化された機械学習アルゴリズムの一種です。)
2023 年にデータ サイエンティストになることが重要な理由
人工知能は 2023 年に向けてますます高度化しています。AI と ML の基礎を知るだけでは十分ではありません。明日は最先端ではないため、最先端にも精通している必要があります。 深層学習は数年前には目新しいものでしたが、今では必要になっています。
企業が本当に膨大な量のデータにアクセスできるようになると、データ サイエンティストはディープ ラーニングを使用することが期待されます。 画像とビデオの処理、またはコンピューター ビジョン アプリケーションに使用されます。
どこで学べますか?
私が好き Simpliarn のチュートリアル 出発点として。
知っておくと役立つ新進気鋭の技術やテクニックがたくさんあります。 これらは、敵対的生成ネットワークのようにさらに高度なものか、データ ストーリーテリングのようなソフトスキル ベースのものか、時系列予測のような分野に特化したものです。 ここでこれらを簡単に要約します。
- 自然言語処理(NLP): 人間の言語の処理と理解を処理する AI のサブフィールド。 チャットボットはこれを使用します。
- 時系列分析と予測: 時間の経過に伴うデータの研究と、統計モデルを使用して将来の出来事を予測すること。 このスキルを使用して、販売または収益の分析を行うことができます。
- 実験計画と A/B テスト: 仮説を検証し、データに基づいて意思決定を行うための制御された実験を設計および実施するプロセス。
- データ ストーリーテリング: データの洞察と調査結果を非技術的な利害関係者に効果的に伝える能力。 ますます多くの利害関係者が関心を持っています。 なぜ データに基づく意思決定の背後にあるため、これは重要です。
- 生成的敵対的ネットワーク(GAN): XNUMX つのニューラル ネットワークが連携して動作し、特定のデータセットに似た新しいデータを生成するようにトレーニングされる、ディープ ラーニング アーキテクチャの一種。
- 転移学習: モデルが XNUMX つのタスクで事前トレーニングされ、関連するタスクで微調整されることで、パフォーマンスが向上し、必要なトレーニング データの量が削減される機械学習手法。 よりリソースが限られている小規模な企業では、これが役立つことがわかります。
- 自動機械学習 (AutoML): 機械学習モデルの選択、トレーニング、デプロイのプロセスを自動化する方法。
- ハイパーパラメータ調整: 別の ML サブカテゴリ。 これは、学習率や隠れ層の数など、データから学習されないパラメーターを調整することによって、機械学習モデルのパフォーマンスを最適化するプロセスです。
- 説明可能な AI (XAI): 透過的で解釈可能なアルゴリズムとモデルの作成に重点を置いた AI の一部門であり、意思決定プロセスを人間が理解できるようにします。 繰り返しになりますが、利害関係者が何が起こっているのかを理解できるようにします。
2023 年にデータ サイエンティストになりたい場合、これらの 19 のスキルは絶対に重要です。 本当に素晴らしいニュースは、これらのスキルの多くは独学で習得できるということです。 データアナリストまたはビジネスアナリスト.
いくつかの学習方法:
- いつもYouTubeをチェック。 非常に多くの無料の包括的なリソースがあります。 ここにいくつかリストしましたが、事実上無限のビデオがあります。
- Coursera や EdX などのプラットフォームでは、講義シリーズが頻繁に開催されます。
- XNUMX を超える実際の面接の質問を練習用に用意しています。 コーディングベース & ノンコーディング。 私達はまた提供します データ プロジェクトの例.
2023 年にデータ サイエンティストになるために、これらのスキルを学ぶ旅をお楽しみください。
ネイト・ロシディ データサイエンティストであり、製品戦略に携わっています。 彼はまた、分析を教える非常勤教授であり、 ストラタスクラッチ、データサイエンティストがトップ企業からの実際の面接の質問で面接の準備をするのを支援するプラットフォーム。 彼とつながる Twitter:StrataScratch or LinkedIn.
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/04/top-19-skills-need-know-2023-data-scientist.html?utm_source=rss&utm_medium=rss&utm_campaign=top-19-skills-you-need-to-know-in-2023-to-be-a-data-scientist

