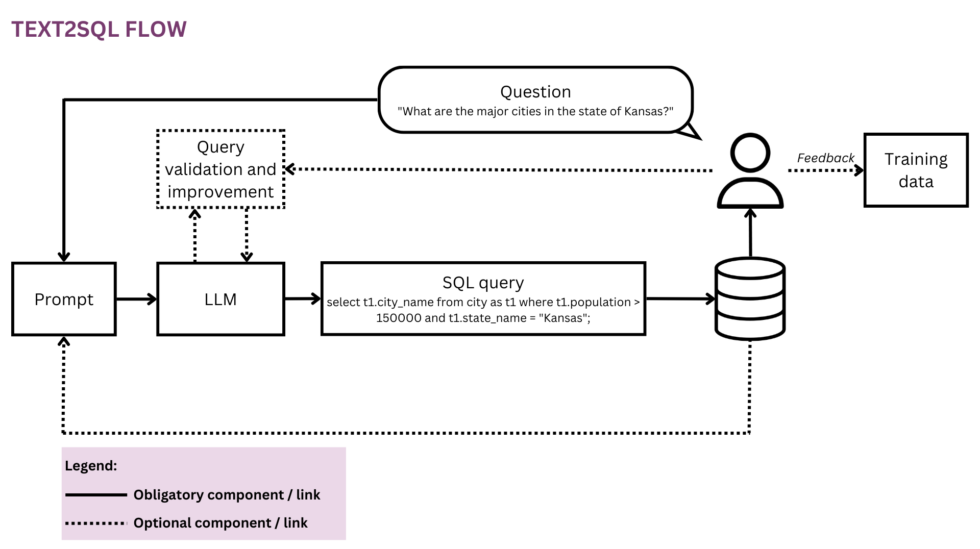
図 1: Text2SQL フローの表現
私たちの世界がよりグローバルでダイナミックになるにつれて、企業は情報に基づいた、客観的かつタイムリーな意思決定を行うためにデータへの依存度をますます高めています。 ただし、現時点では、組織データの可能性を最大限に引き出すことは、一部のデータ サイエンティストやアナリストの特権であることがよくあります。 ほとんどの従業員は、従来のデータ サイエンス ツールキット (SQL、Python、R など) を習得していません。 目的のデータにアクセスするには、アナリストまたは BI チームがビジネス上の質問の散文をデータの言語に「翻訳」する追加のレイヤーを経由します。 このプロセスでは摩擦や非効率が生じる可能性が高く、たとえば、データの配信が遅れたり、質問がすでに古くなっている場合でも配信される可能性があります。 要件が分析クエリに正確に変換されないと、途中で情報が失われる可能性があります。 さらに、高品質の洞察を生成するには反復的なアプローチが必要ですが、ループ内の追加のステップごとに推奨されません。 その一方で、データサイエンティストの次の「告白」で説明されているように、これらのアドホックなやり取りは、高価なデータ人材に混乱をもたらし、より戦略的なデータ作業から遠ざけます。
私が Square にいたとき、チームがもっと小さかったときは、恐ろしい「分析オンコール」のローテーションがありました。 それは厳密に週単位でローテーションされており、もしあなたの番だったら、その週に行われる「実際の」仕事はほとんどなく、社内のさまざまな製品チームや運用チームからの臨時の質問に対応することにほとんどの時間を費やすことになることがわかっていました。会社 (SQL モンキーニング、私たちはそれをそう呼んでいました)。 分析チームではマネージャーの役割をめぐって熾烈な競争があり、これは完全にマネージャーがこのローテーションから除外された結果だと思います。オンコール業務を行わないというニンジンに匹敵する地位の賞はありません。[1]
確かに、データ担当者と何度も対話する必要がなく、データと直接対話できたら素晴らしいと思いませんか? このビジョンは、人間が最も直感的で普遍的なコミュニケーション チャネルである言語を使用してデータを操作できるようにする会話型インターフェイスによって実現されています。 質問を解析した後、アルゴリズムは質問を、SQL などの選択したクエリ言語で構造化された論理形式にエンコードします。 したがって、技術者以外のユーザーでも、BI チームを介して迂回することなく、データを使用してチャットし、具体的で関連性のあるタイムリーな情報を迅速に入手できます。 この記事では、Text2SQL のさまざまな実装側面を検討し、現時点で最高のパフォーマンスを達成する大規模言語モデル (LLM) を使用した最新のアプローチに焦点を当てます (代替アプローチに関する調査については、[2] を参照)。 LLM を超えて、リーダーが参照されます [3])。 この記事は、AI 機能を計画および構築する際に考慮すべき主な要素の次の「メンタル モデル」に従って構成されています。
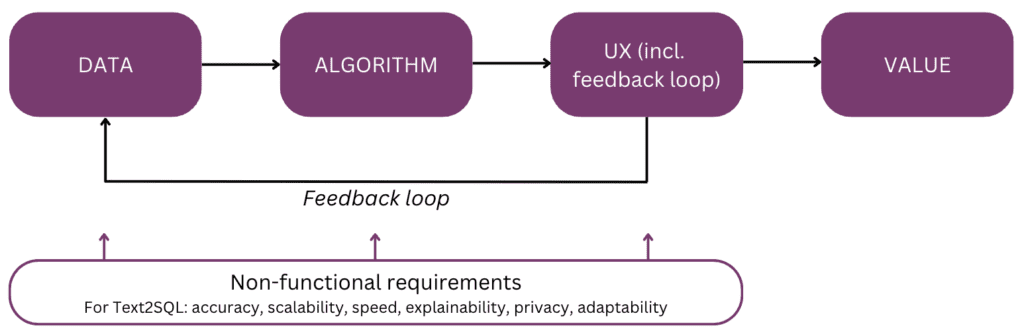
まずは目的を念頭に置き、その価値、つまり Text2SQL 機能をデータ製品または分析製品に組み込む理由を要約しましょう。 主なメリットは次の XNUMX つです。
- ビジネスユーザー 組織データに直接かつタイムリーにアクセスできます。
- これで安心 データサイエンティストとアナリスト ビジネス ユーザーからのアドホックなリクエストの負担から解放され、高度なデータの課題に集中できるようになります。
- これにより、 ビジネス データをより流動的かつ戦略的な方法で活用し、最終的にはデータを意思決定の強固な基盤に変えることができます。
では、Text2SQL を検討する可能性のある製品シナリオは何でしょうか? 主な設定は次の XNUMX つです。
- あなたが提供しているのは、 スケーラブルなデータ/BI 製品 そして、より多くのユーザーが技術的ではない方法でデータにアクセスできるようにして、使用量とユーザー ベースの両方を拡大したいと考えています。 例として、ServiceNow には次のものがあります。 データクエリをより大規模な会話サービスに統合, アトラン 最近しました 自然言語データ探索を発表.
- あなたは、企業内のデータ アクセスを民主化するために、データ/AI スペースに何かを構築したいと考えています。その場合、潜在的に、 Text2SQL を中心とした MVP。 プロバイダーのような AI2SQL & Text2sql.ai すでにこの領域に参入しています。
- あなたはに取り組んでいます カスタムBIシステム そして、個々の企業での使用を最大限に活用し、民主化したいと考えています。
次のセクションで説明するように、Text2SQL には重要な事前設定が必要です。 ROI を見積もるには、サポートされる意思決定の性質と利用可能なデータを考慮します。 Text2SQL は、データが急速に変化し、投資、マーケティング、製造、エネルギー業界などの意思決定に積極的かつ頻繁に使用される動的な環境では絶対的な勝利を収めることができます。 このような環境では、ナレッジ管理のための従来のツールは静的すぎるため、データや情報にアクセスするためのより流暢な方法は、企業が競争上の優位性を生み出すのに役立ちます。 データに関して言えば、Text2SQL はデータベースに次のような最大の価値を提供します。
- 大きく成長中これにより、利用されるデータが増えるにつれて Text2SQL の価値が時間の経過とともに明らかになります。
- 高品質のこれにより、Text2SQL アルゴリズムはデータ内の過度のノイズ (不一致、空の値など) に対処する必要がなくなります。 一般に、アプリケーションによって自動的に生成されたデータは、人間によって作成および維持されるデータよりも高い品質と一貫性を備えています。
- 意味的に成熟した 生のデータとは対照的に、人間はメンタル モデルに存在する中心的な概念、関係、メトリクスに基づいてデータをクエリできるようになります。 セマンティックな成熟度は、生データを概念的構造に適合させる追加の変換ステップによって達成できることに注意してください (セクション「データベース情報によるプロンプトの強化」を参照)。
以下では、データ、アルゴリズム、ユーザー エクスペリエンス、および Text2SQL 機能の関連する非機能要件について詳しく説明します。 この記事は、プロダクト マネージャー、UX デザイナー、Text2SQL の取り組みを始めたばかりのデータ サイエンティストやエンジニアを対象に書かれています。 こうした人々にとって、本書は開始のためのガイドを提供するだけでなく、関連するトレードオフを含め、製品、テクノロジー、ビジネスの間のインターフェイスに関する議論のための共通の知識基盤も提供します。 すでに実装の上級者である場合は、最後にある参考資料でさまざまな詳細な情報を確認できます。
この詳細な教育コンテンツが役立つ場合は、次のことができます。 AIリサーチメーリングリストに登録する 新しい素材がリリースされたときに警告が表示されます。
1。 データ
機械学習の取り組みはすべてデータから始まるため、トレーニングと予測中に使用される入力データとターゲット データの構造を明確にすることから始めます。 この記事では、図 2 の Text1SQL フローを実行中の表現として使用し、現在検討されているコンポーネントと関係を黄色で強調表示します。
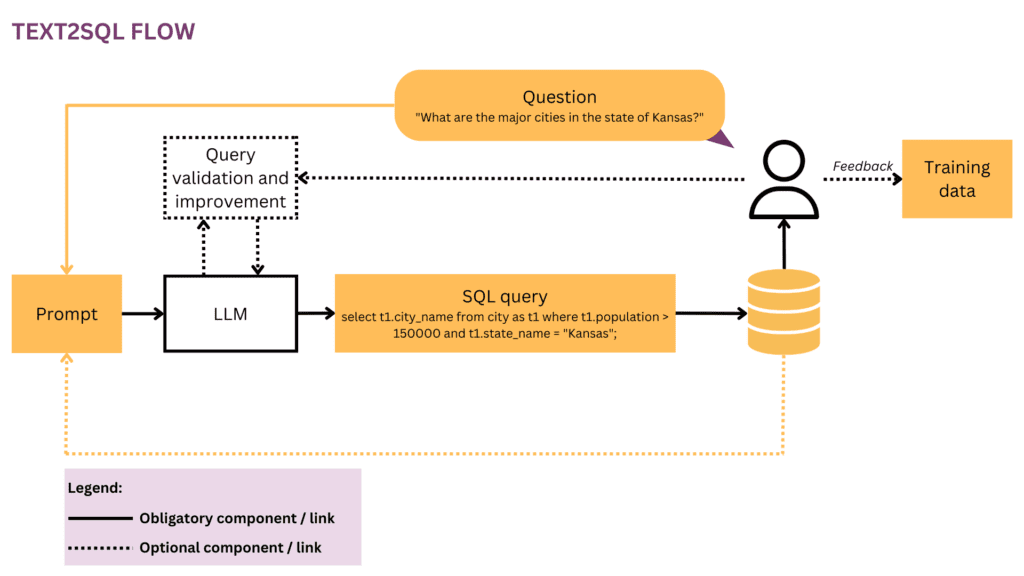
1.1 データの形式と構造
通常、生の Text2SQL 入出力ペアは、自然言語の質問と対応する SQL クエリで構成されます。次に例を示します。
質問「各ユーザーの名前とフォロワー数をリストします。」
SQLクエリ:
user_profile から名前、フォロワーを選択
トレーニング データ空間では、質問と SQL クエリの間のマッピングは多対多です。
- SQL クエリは、自然言語でさまざまな質問にマッピングできます。 たとえば、上記のクエリ セマンティクスは次のように表現できます。ユーザーごとの名前とフォロワー数を表示します"、"各ユーザーのフォロワーは何人いますか?」など。
- SQL 構文は汎用性が高く、ほぼすべての質問を複数の方法で SQL で表現できます。 最も単純な例は、WHERE 句の順序の違いです。 より高度な観点から言えば、SQL クエリの最適化を行ったことがある人なら誰でも、多くの道が同じ結果につながり、意味的に同等のクエリがまったく異なる構文を持つ可能性があることを知っているでしょう。
Text2SQL のトレーニング データを手動で収集するのは特に面倒です。 アノテーター側に SQL の習熟が必要なだけでなく、感情分析やテキスト分類などのより一般的な言語タスクよりも、3 例あたりの時間が長くなります。 十分な量のトレーニング例を確保するために、データ拡張を使用できます。たとえば、LLM を使用して同じ質問の言い換えを生成できます。 [2] は、TextXNUMXSQL データ拡張技術のより完全な調査を提供します。
1.2 プロンプトにデータベース情報を追加する
Text2SQL は、非構造化データと構造化データの間のインターフェイスにあるアルゴリズムです。 最適なパフォーマンスを得るには、トレーニング中と予測中に両方のタイプのデータが存在する必要があります。 具体的には、アルゴリズムはクエリ対象のデータベースについて認識し、データベースに対して実行できる方法でクエリを作成できなければなりません。 この知識には次のものが含まれます。
- データベースの列とテーブル
- テーブル間の関係(外部キー)
- データベースの内容
データベースの知識を組み込むには 2 つのオプションがあります。XNUMX つは、トレーニング データを特定のデータベース用に作成された例に制限することができます。この場合、スキーマは SQL クエリとその質問へのマッピングから直接学習されます。 この単一データベース設定により、個々のデータベースや会社に合わせてアルゴリズムを最適化できます。 ただし、モデルは顧客またはデータベースごとに微調整する必要があるため、スケーラビリティに対する野心は台無しになります。 あるいは、マルチデータベース設定では、データベース スキーマを入力の一部として提供して、アルゴリズムを新しいまだ見たことのないデータベース スキーマに「一般化」することができます。 さまざまなデータベースで TextXNUMXSQL を使用したい場合は、必ずこのアプローチを採用する必要がありますが、それにはかなりの迅速なエンジニアリング作業が必要になることに留意してください。 適切なビジネス データベースの場合、プロンプトにすべての情報を含めることは非常に非効率であり、プロンプトの長さの制限によりおそらく不可能です。 したがって、迅速な定式化を担当する機能は、特定の質問に対して最も「役立つ」データベース情報のサブセットを選択し、潜在的に未確認のデータベースに対してこれを実行できるほど賢明である必要があります。
最後に、データベース構造が重要な役割を果たします。 データベースを十分に制御できるシナリオでは、直感的な構造からモデルを学習させることで、モデルの作業を容易にすることができます。 経験則として、ビジネス ユーザーがビジネスについてどのように話しているかをデータベースに反映すればするほど、モデルはそこからより適切かつ迅速に学習できるようになります。 したがって、正規化されたデータやその他の方法で分散されたデータを広いテーブルやデータ ボルトにまとめたり、明示的かつ明確な方法でテーブルや列に名前を付けたりするなど、データに追加の変換を適用することを検討してください。事前にエンコードできるすべてのビジネス知識は、モデルに対する確率学習の負担を軽減し、より良い結果を達成するのに役立ちます。
2。 アルゴリズム

Text2SQL は次のタイプです。 セマンティック解析 — テキストの論理表現へのマッピング。 したがって、アルゴリズムは自然言語だけでなく、ターゲット表現 (この場合は SQL) も「学習」する必要があります。 具体的には、次の知識を習得する必要があります。
- SQL 構文とセマンティクス
- データベース構造
- 自然言語理解(NLU)
- 自然言語と SQL クエリ間のマッピング (構文、語彙、意味)
2.1 入力における言語のばらつきの解決
Text2SQL の入力における主な課題は、言語の柔軟性にあります。「データの形式と構造」セクションで説明したように、同じ質問をさまざまな方法で言い換えることができます。 さらに、実際の会話のコンテキストでは、スペルや文法の間違い、不完全で曖昧な入力、多言語入力などの多くの問題に対処する必要があります。

GPT モデル、T5、CodeX などの LLM は、この課題の解決にますます近づいています。 膨大な量の多様なテキストから学習し、多数の言語パターンや不規則性に対処する方法を学びます。 最終的には、表面的な形式は異なっていても、意味的には似ている質問を一般化できるようになります。 LLM は、そのまま (ゼロショット) または微調整後に適用できます。 前者は便利ですが、精度が低くなります。 後者はより多くのスキルと作業を必要としますが、精度を大幅に向上させることができます。
精度の点では、予想どおり、最もパフォーマンスの高いモデルは、CodeX モデルを含む GPT ファミリの最新モデルです。 2023 年 4 月、GPT-5 は以前の最先端のものと比べて 85.3% 以上の劇的な精度向上をもたらし、4% の精度を達成しました (「値を使用した実行」という指標において) [2]。 オープンソース陣営では、Text5SQL パズルを解決するための最初の試みは、NLU タスクに優れた BERT などの自動エンコーディング モデルに焦点を当てていました [6、7、5]。しかし、生成 AI に関する誇大広告の中で、最近のアプローチは焦点を当てています。 T5 モデルなどの自己回帰モデルの場合。 T2 はマルチタスク学習を使用して事前トレーニングされているため、新しい言語タスクに簡単に適応できます。 セマンティック解析のさまざまなバリエーション。 ただし、自己回帰モデルには、セマンティック解析タスクに関しては本質的な欠陥があります。自己回帰モデルには制約のない出力空間があり、出力を制約するセマンティック ガードレールがありません。つまり、動作において驚くほど創造的になる可能性があります。 これは、自由形式のコンテンツを生成する場合には素晴らしい機能ですが、制約があり、適切に構造化されたターゲット出力を期待する TextXNUMXSQL のようなタスクにとっては厄介です。
2.2 クエリの検証と改善
LLM 出力を制限するために、クエリを検証および改善するための追加メカニズムを導入できます。 これは、PICARD システムで提案されているように、追加の検証ステップとして実装できます。[8] PICARD は、部分的な SQL クエリが完了後に有効な SQL クエリにつながるかどうかを検証できる SQL パーサーを使用します。 LLM による各生成ステップで、クエリを無効にするトークンは拒否され、最も確率の高い有効なトークンが保持されます。 このアプローチは決定論的であるため、パーサーが正しい SQL ルールを遵守している限り、SQL の 100% の有効性が保証されます。 また、クエリの検証を生成から切り離すことで、両方のコンポーネントを互いに独立して維持し、LLM をアップグレードおよび変更できるようになります。
もう 9 つのアプローチは、構造および SQL の知識を LLM に直接組み込むことです。 たとえば、Graphix [5] はグラフ認識層を使用して、構造化された SQL 知識を TXNUMX モデルに注入します。 このアプローチの確率的な性質により、システムは正しいクエリに偏りますが、成功の保証はありません。
最後に、LLM はクエリを自律的にチェックして改善できるマルチステップ エージェントとして使用できます [10]。 思考連鎖プロンプトで複数のステップを使用することで、エージェントは自身のクエリの正しさを振り返り、欠陥を改善するようタスクを課すことができます。 検証されたクエリがまだ実行できない場合は、SQL 例外トレースバックを、改善のための追加フィードバックとしてエージェントに渡すことができます。
バックエンドで行われるこれらの自動化された方法以外にも、クエリチェックプロセス中にユーザーを関与させることも可能です。 これについては、「ユーザー エクスペリエンス」のセクションで詳しく説明します。
2.3評価
Text2SQL アルゴリズムを評価するには、テスト (検証) データセットを生成し、そのデータセット上でアルゴリズムを実行し、結果に関連する評価メトリクスを適用する必要があります。 トレーニング、開発、および検証データに分割された単純なデータセットは、質問とクエリのペアに基づいており、次善の結果が得られます。 検証クエリはトレーニング中にモデルに明らかになり、一般化スキルに関して過度に楽観的な見方につながる可能性があります。 あ クエリベースの分割では、トレーニング中と検証中の両方でクエリが表示されないようにデータセットが分割されており、より正確な結果が得られます。
評価指標に関して、Text2SQL で重視しているのは、ゴールド スタンダードと完全に同一のクエリを生成することではありません。 これ 「文字列の完全一致」 このメソッドは厳密すぎるため、異なる SQL クエリによって同じデータセットが返される可能性があるため、多くの偽陰性が生成されます。 代わりに、私たちは高い目標を達成したいと考えています 意味の正確さ そして、予測されたクエリと「ゴールドスタンダード」クエリが常に同じデータセットを返すかどうかを評価します。 この目標を近似する評価指標は XNUMX つあります。
- 正確に設定された一致精度: 生成された SQL クエリとターゲット SQL クエリがその構成要素に分割され、結果のセットが同一性について比較されます。[11] ここでの欠点は、SQL クエリ内の順序の変化のみが考慮され、意味的に同等のクエリ間のより顕著な構文の違いは考慮されていないことです。
- 実行精度: 生成された SQL クエリとターゲット SQL クエリから得られたデータセットが同一性について比較されます。 幸運があれば、異なるセマンティクスを持つクエリでも、特定のデータベース インスタンスでこのテストに合格する可能性があります。 たとえば、すべてのユーザーが 30 歳以上であるデータベースを想定すると、次の XNUMX つのクエリは、セマンティクスが異なるにもかかわらず、同じ結果を返します。
ユーザーから * を選択
年齢が 30 歳以上のユーザーから * を選択 - テストスイートの精度: テストスイートの精度は、実行精度のより高度で許容度の低いバージョンです。 クエリごとに、クエリ内の変数、条件、値に関して高度に区別されたデータベースのセット (「テスト スイート」) が生成されます。 次に、これらのデータベースごとに実行精度がテストされます。 このメトリクスは、テスト スイートの生成を設計するための追加の労力を必要としますが、評価における誤検知のリスクも大幅に軽減します。.【12]
3.ユーザーエクスペリエンス
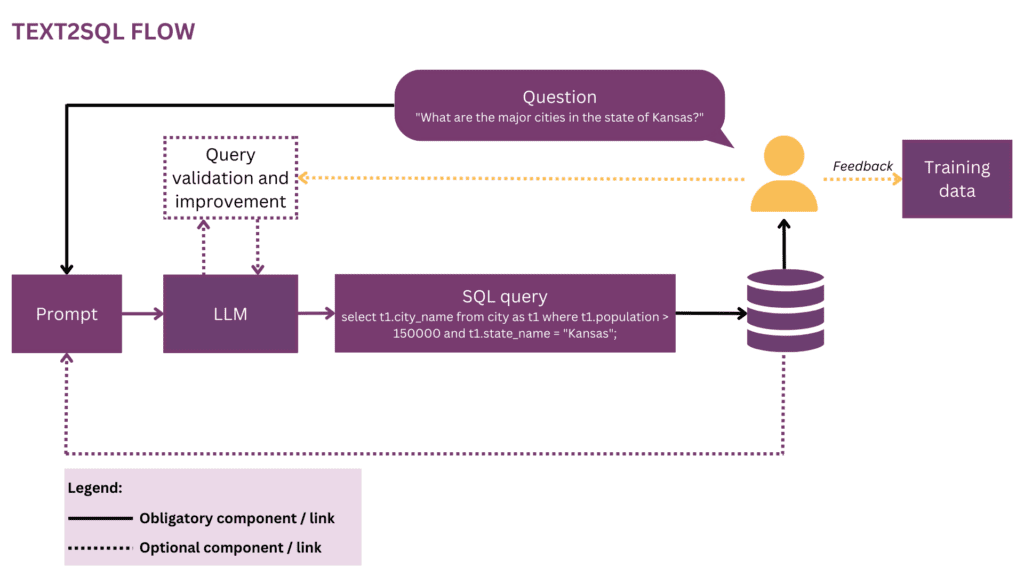
現在の最先端の Text2SQL では、運用システムへの完全にシームレスな統合は可能ではありません。代わりに、ユーザーの期待と行動を積極的に管理する必要があり、ユーザーはユーザーと対話していることを常に認識する必要があります。 AIシステム。
3.1 障害管理
Text2SQL は XNUMX つのモードで失敗する可能性があり、異なる方法で捕捉する必要があります。
- SQLエラー: 生成されたクエリは無効です。SQL が無効であるか、語彙的または意味論的な欠陥により特定のデータベースに対して実行できません。 この場合、ユーザーに結果を返すことはできません。
- セマンティックエラー: 生成されたクエリは有効ですが、質問のセマンティクスが反映されていないため、間違ったデータセットが返されます。
XNUMX 番目のモードは、「サイレント障害」 (ユーザーが気付かないエラー) のリスクが高いため、特に注意が必要です。 プロトタイプ ユーザーには、クエリや結果のデータの正しさを検証するための時間も技術スキルもありません。 現実世界での意思決定にデータが使用される場合、この種の失敗は壊滅的な結果をもたらす可能性があります。 これを回避するには、ユーザーを教育し、 ビジネスレベルのガードレール より大きな影響を与える決定を行うための追加のデータチェックなど、潜在的な影響を制限します。 一方、ユーザー インターフェイスを使用して人間とマシンの対話を管理し、ユーザーが問題のあるリクエストを検出して改善できるようにすることもできます。
3.2 人間と機械の相互作用
ユーザーは、さまざまな強度で AI システムに関与できます。 リクエストごとのインタラクションが増えると、より良い結果が得られますが、ユーザー エクスペリエンスの流動性も低下します。 誤ったクエリや結果がもたらす潜在的な悪影響に加えて、より正確な結果を得るために、そして長期的に製品の改善に役立てるために、ユーザーがフィードバックを何度も提供する意欲をどの程度高めるかについても考慮してください。
最も簡単であまり魅力のない方法は、信頼度スコアを使用することです。 生成されたトークンの確率の平均として信頼度を単純に計算するのは単純すぎますが、言語化されたフィードバックなどのより高度な方法を使用できます。 [13] 信頼度はインターフェースに表示され、危険なほど低い場合には明示的なアラートで強調表示されます。 このようにして、「現実世界」での適切なフォローアップの責任(それがデータの拒否、受け入れ、または追加のチェックであっても)はユーザーの肩にかかります。 これはベンダーにとっては安全な策ですが、この作業をユーザーに移管すると製品の価値が低下する可能性もあります。
14 番目の可能性は、信頼性が低い、曖昧な、または疑わしいクエリの場合に、ユーザーを説明のダイアログに参加させることです。 たとえば、システムは入力に対して正書法や文法の修正を提案し、特定の単語や文法構造の曖昧さを解消するように要求する場合があります。 また、ユーザーがクエリの修正を積極的に求めることもできるかもしれません:[XNUMX]
ユーザー: このスプリントにおける John のタスクを見せてください。
アシスタント: John が作成したタスク、または彼が取り組んでいるタスクを見たいですか?
ユーザー: ジョンが作成したタスク
アシスタント: OK、タスク ID は次のとおりです。

ユーザー: ありがとうございます。タスクに関する詳細情報も知りたいです。 緊急度順にも並べ替えてください。
アシスタント: 確かに、ここにはタスクと短い説明、担当者、期限が期限順に並べられています。
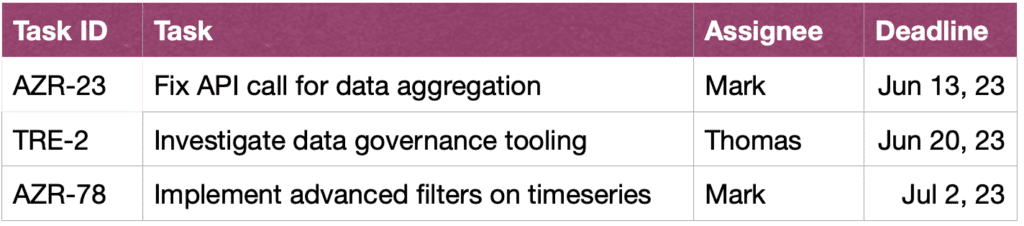
最後に、ユーザーによるクエリの理解を容易にするために、システムはクエリの明示的なテキスト再定式化を提供し、ユーザーにそれを確認または修正するよう求めることもできます。[15]
4.非機能要件
このセクションでは、Text2SQL の特定の非機能要件と、それらの間のトレードオフについて説明します。 このタスクにとって最も重要と思われる XNUMX つの要件、正確さ、拡張性、速度、説明可能性、プライバシー、長期にわたる適応性に焦点を当てます。
4.1精度
Text2SQL の場合、精度に対する要求は高くなります。 まず、Text2SQL は通常、予測が 3.1 つずつ行われる会話設定に適用されます。 したがって、通常、バッチ予測の誤差を相殺するのに役立つ「大数の法則」は役に立ちません。 XNUMX 番目に、構文と語彙の妥当性は「難しい」条件です。モデルは、潜在的に複雑な構文とセマンティクスを含む、整形式の SQL クエリを生成する必要があります。そうしないと、データベースに対してリクエストを実行できません。 これがうまくいき、クエリを実行できる場合でも、セマンティック エラーが含まれている可能性があり、間違ったデータセットが返される可能性があります (セクション XNUMX 障害管理を参照)。
4.2スケーラビリティ
スケーラビリティに関する主な考慮事項は、Text2SQL を 2 つまたは複数のデータベースに適用するかどうかです。後者の場合は、データベースのセットが既知で閉じているかどうかです。 「はい」の場合は、トレーニング中にこれらのデータベースに関する情報を含めることができるため、作業が容易になります。 ただし、スケーラブルな製品のシナリオでは、スタンドアロンの Text2SQL アプリケーションであれ、既存のデータ製品への統合であれ、アルゴリズムは新しいデータベース スキーマに即座に対応する必要があります。 また、このシナリオでは、学習しやすいようにデータベース構造を変換する機会も与えられません (リンク!)。 これらすべてが精度との大きなトレードオフにつながり、新しいデータベースのアドホック クエリを提供する現在の TextXNUMXSQL プロバイダーがまだ大幅な市場浸透を達成していない理由もこのことが説明される可能性があります。
4.3スピード
Text2SQL リクエストは通常、会話中にオンラインで処理されるため、ユーザーの満足度を高めるには速度の側面が重要です。 良い面としては、データのリクエストには一定の時間がかかり、必要な忍耐力が必要であるという事実をユーザーが認識していることがよくあります。 ただし、ユーザーが無意識のうちに人間のような会話速度を期待するチャット設定によって、この好意は損なわれる可能性があります。 モデルのサイズを縮小するなどの総当たり的な最適化手法は、精度に許容できない影響を与える可能性があるため、この期待を満たすために推論の最適化を検討してください。
4.4 説明可能性と透明性
理想的なケースでは、ユーザーはクエリがテキストからどのように生成されたかを追跡し、質問内の特定の単語や表現と SQL クエリなどのマッピングを確認できます。これにより、システムと対話するときにクエリを検証し、調整を行うことができます。 。 さらに、システムはクエリの明示的なテキスト再定式化を提供し、ユーザーにそれを確認または修正するよう求めることもできます。
4.5プライバシー
Text2SQL 関数はクエリの実行から分離できるため、返されたデータベース情報を非表示に保つことができます。 ただし、重要な問題は、プロンプトにデータベースに関する情報がどのくらい含まれるかということです。 (プライバシー レベルを下げることによる) XNUMX つのオプションは次のとおりです。
- 情報なし
- データベーススキーマ
- データベースの内容
プライバシーは精度とトレードオフになります。プロンプトに有用な情報を含める際の制約が少ないほど、より良い結果が得られます。
4.6 時間の経過に伴う適応性
Text2SQL を永続的な方法で使用するには、データ ドリフト、つまりモデルが適用されるデータの分布の変化に適応する必要があります。 たとえば、初期の微調整に使用されるデータが、BI システムの使用を開始したときのユーザーの単純なクエリ行動を反映していると仮定します。 時間が経つにつれて、ユーザーの情報ニーズはより洗練され、より複雑なクエリが必要になり、単純なモデルでは圧倒されてしまいます。 さらに、企業の変更の目標や戦略によって、情報ニーズがデータベースの他の領域に偏ってしまう可能性もあります。 最後に、Text2SQL 固有の課題はデータベースのドリフトです。 企業データベースが拡張されると、これまでにない新しい列やテーブルがプロンプトに表示されます。 マルチデータベース アプリケーション用に設計された Text2SQL アルゴリズムはこの問題を適切に処理できますが、単一データベース モデルの精度に大きな影響を与える可能性があります。 これらの問題はすべて、ユーザーの現在の現実世界の行動を反映するデータセットを微調整することで最もよく解決されます。 したがって、ユーザーの質問と結果、および使用状況から収集できる関連フィードバックを記録することが重要です。 さらに、埋め込みやトピック モデリングなどを使用したセマンティック クラスタリング アルゴリズムを適用して、ユーザー行動の根本的な長期的な変化を検出し、これらを微調整データセットを完成させるための追加の情報源として使用できます。
まとめ
この記事の重要なポイントを要約しましょう。
- Text2SQL を使用すると、ビジネスに直感的で民主的なデータ アクセスを実装できるため、利用可能なデータの価値を最大化できます。
- Text2SQL データは、入力の質問と出力の SQL クエリで構成されます。 質問と SQL クエリ間のマッピングは多対多です。
- プロンプトの一部としてデータベースに関する情報を提供することが重要です。 さらに、データベース構造を最適化して、アルゴリズムが学習して理解しやすくすることができます。
- 入力面での主な課題は、自然言語の質問の言語的多様性です。これには、さまざまなテキスト スタイルで事前トレーニングされた LLM を使用してアプローチできます。
- Text2SQL の出力は有効な SQL クエリである必要があります。 この制約は、SQL の知識をアルゴリズムに「注入」することで組み込むことができます。 あるいは、反復アプローチを使用して、クエリを複数のステップでチェックして改善することもできます。
- 意思決定のために間違ったデータを返す「サイレント障害」は潜在的に大きな影響を与えるため、ユーザー インターフェイスでは障害管理が最大の関心事です。
- 「拡張」形式で、ユーザーは SQL クエリの反復的な検証と改善に積極的に参加できます。 これにより、アプリケーションの流動性が低下しますが、障害率も低下し、ユーザーがより柔軟な方法でデータを探索できるようになり、さらなる学習のための貴重な信号が生成されます。
- 考慮すべき主な非機能要件は、精度、拡張性、速度、説明可能性、プライバシー、長期にわたる適応性です。 主なトレードオフは、一方では精度、もう一方ではスケーラビリティ、速度、プライバシーとの間で構成されます。
参考文献
[1] ケン・ヴァン・ハーレン。 2023年。 SQL アナリストを 26 個の再帰 GPT プロンプトに置き換える
[2] Nitarshan Rajkumar ら。 2022年。 大規模言語モデルの Text-to-SQL 機能の評価
[3] Naihao Deng et al. 2023年。 Text-to-SQL の最近の進歩: 私たちが持っているものと私たちが期待しているものに関する調査
[4] Mohammadreza Pourreza et al. 2023年。 DIN-SQL: 自己修正機能を備えた Text-to-SQL の分解されたインコンテキスト学習
[5] Victor Zhong 他。 2021年。 ゼロショット実行可能セマンティック解析のためのグラウンデッド適応
[6] Xi Victoria Lin 他。 2020年。 クロスドメインのテキストから SQL へのセマンティック解析のためのテキスト データと表形式データのブリッジング
[7] Tong Guo ら。 2019年。 コンテンツ拡張された BERT ベースの Text-to-SQL 生成
[8] Torsten Scholak ら。 2021年。 PICARD: 言語モデルからの制約付き自己回帰デコードのための増分解析
[9] Jinyang Li et al. 2023年。 Graphix-T5: Text-to-SQL 解析用の事前トレーニング済みトランスフォーマーとグラフ対応レイヤーの混合
[10] ラングチェーン。 2023年。 LLM と SQL
[11] タオ・ユウら。 2018年。 Spider: 複雑なクロスドメインのセマンティック解析および Text-to-SQL タスク用の大規模な人間によるラベル付きデータセット
[12] Ruiqi Zhong ら。 2020年。 抽出されたテスト スイートによる Text-to-SQL のセマンティック評価
[13] キャサリン・ティアンら。 2023年。 調整を依頼するだけ: 人間のフィードバックで微調整された言語モデルから調整された信頼スコアを導き出すための戦略
[14] ブレーデン・ハンコックら。 2019年。 導入後の対話から学ぶ: チャットボット、自分自身に餌を与えましょう!
[15] アーメド・エルゴハリーら。 2020年。 パーサーに話しかける: 自然言語フィードバックによるインタラクティブな Text-to-SQL
[16] ジャンナ・リペンコワ。 2022年。 話して! Text2SQL と会社のデータの会話、ニューヨークの自然言語処理ミートアップで講演します。
すべての画像は作者によるものです。
この記事は、最初に公開された データサイエンスに向けて 著者の許可を得てTOPBOTSに再公開しました。
この記事をお楽しみください? AIリサーチの最新情報にサインアップしてください。
このような要約記事がさらにリリースされたらお知らせします。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://www.topbots.com/conversational-ai-for-data-analysis/

