組織は多くの場合、異常な速度で増加する大量のデータを管理する必要があります。同時に、運用コストを最適化して、タイムリーな洞察を得るためにこのデータの価値を引き出し、一貫したパフォーマンスでそれを実現する必要があります。
この大規模なデータの増加に伴い、データ ストア、データ ウェアハウス、データ レイク全体にわたるデータの拡散も同様に困難になる可能性があります。とともに 最新のデータアーキテクチャ AWS では、スケーラブルなデータレイクを迅速に構築できます。目的に合わせて構築されたデータ サービスの幅広く深いコレクションを使用します。統合されたデータアクセス、セキュリティ、ガバナンスを通じてコンプライアンスを確保します。パフォーマンスを損なうことなく、低コストでシステムを拡張します。組織の境界を越えてデータを簡単に共有できるため、大規模なスピードと俊敏性で意思決定を行うことができます。
さまざまなサイロからすべてのデータを取得し、そのデータをデータ レイクに集約し、そのデータに基づいて分析と機械学習 (ML) を直接実行できます。また、他のデータを専用のデータ ストアに保存して、構造化データと非構造化データの両方を分析して迅速に洞察を得ることができます。このデータの移動は、内部から外部、外部から内部、境界の周り、または全体で共有することができます。
たとえば、Web アプリケーションからのアプリケーション ログとトレースをデータレイクに直接収集し、そのデータの一部を Amazon OpenSearch Service などのログ分析ストアに移動して毎日の分析を行うことができます。私たちはこのコンセプトを次のように考えています 裏返し データの移動。 Amazon OpenSearch Service に保存された分析および集約されたデータは、再びデータレイクに移動して、アプリケーションからダウンストリームで使用するための ML アルゴリズムを実行できます。この概念を次のように呼びます。 外で データの移動。
使用例を見てみましょう。 Example Corp. は、ソーシャル コンテンツを専門とするフォーチュン 500 の大手企業です。同社には、500 日あたり約 XNUMX TB のデータとトレースを生成するアプリケーションが数百あり、次の基準があります。
- 2 日間の高速分析に利用できるログを用意する
- 2 日を超えた後は、合理的な SLA で分析に利用できるストレージ層でデータを利用できるようにします。
- 1 週間を超えたデータをコールド ストレージで 30 日間保持します (コンプライアンス、監査などの目的)。
次のセクションでは、同様の使用例に対処するために考えられる 3 つのソリューションについて説明します。
- Amazon OpenSearch Service の階層型ストレージとデータのライフサイクル管理
- を使用したログのオンデマンド取り込み Amazon OpenSearch の取り込み
- Amazon OpenSearch Service による Amazon Simple Storage Service (Amazon S3) の直接クエリ
解決策 1: OpenSearch Service の階層型ストレージとデータ ライフサイクル管理
OpenSearch Service は、ホット ストレージ、UltraWarm ストレージ、コールド ストレージの 3 つの統合ストレージ層をサポートします。データ保持、クエリ レイテンシ、予算要件に基づいて、コストとパフォーマンスのバランスを取る最適な戦略を選択できます。異なるストレージ階層間でデータを移行することもできます。
ホット ストレージはインデックス作成と更新に使用され、データへの最速のアクセスを提供します。ホット ストレージはインスタンス ストアの形式をとるか、 Amazon Elastic Blockストア 各ノードにアタッチされた (Amazon EBS) ボリューム。
UltraWarm は、クエリの頻度が低く、ホット ストレージと同じパフォーマンスを必要としない読み取り専用データの GiB あたりのコストを大幅に削減します。 UltraWarm ノードは、Amazon S3 と関連するキャッシュ ソリューションを使用して、パフォーマンスを向上させます。
コールド ストレージは、アクセス頻度の低いデータや履歴データを保存するために最適化されています。コールド ストレージを使用すると、インデックスが UltraWarm 層から切り離され、インデックスにアクセスできなくなります。データをクエリする必要がある場合は、これらのインデックスを数秒で再接続できます。
OpenSearch サービス内のデータ層の詳細については、以下を参照してください。 Amazon OpenSearch Service でニーズに適したストレージ階層を選択してください.
ソリューションの概要
このソリューションのワークフローは次の手順で構成されます。
- アプリケーションによって生成された受信データは、S3 データレイクにストリーミングされます。
- データは次を使用して Amazon OpenSearch に取り込まれます。 S3-SQS のほぼリアルタイムの取り込み S3 バケットに設定された通知を通じて。
- 2 日後、ホット データは読み取りクエリをサポートするために UltraWarm ストレージに移行されます。
- UltraWarm で 5 日間経過した後、データは 21 日間コールド ストレージに移行され、すべてのコンピューティングから切り離されます。必要に応じて、データを UltraWarm に再接続できます。データは 21 日後にコールド ストレージから削除されます。
- 簡単にロールオーバーできるように、毎日のインデックスが維持されます。インデックス状態管理 (ISM) ポリシーは、2 日より古いインデックスのロールオーバーまたは削除を自動化します。
以下は、2 日後にデータを UltraWarm 層にロールオーバーし、5 日後にコールド ストレージに移動し、21 日後にコールド ストレージから削除するサンプル ISM ポリシーです。
考慮事項
UltraWarm は、高度なキャッシュ技術を使用して、アクセス頻度の低いデータのクエリを可能にします。データ アクセスは頻繁ではありませんが、このアクセスを可能にするために UltraWarm ノードのコンピューティングが常に実行されている必要があります。
PB 規模で運用する場合、エラーの影響範囲を減らすために、階層型ストレージを使用する場合は、実装を複数の OpenSearch Service ドメインに分解することをお勧めします。
次の 2 つのパターンでは、長時間実行するコンピューティングの必要性がなくなり、データが必要なときに取得されるか、データが存在する場所で直接クエリされるオンデマンド手法が説明されます。
解決策 2: OpenSearch Ingestion によるログ データのオンデマンド取り込み
OpenSearch Ingestion は、リアルタイムのログおよびトレース データを OpenSearch Service ドメインに配信するフルマネージド データ コレクターです。 OpenSearch インジェストはオープンソース データ コレクターを利用しています データプリッパー。 Data Prepper は、 オープンソース OpenSearch プロジェクト.
OpenSearch Ingestion を使用すると、データをフィルタリング、強化、変換し、下流の分析と視覚化のために配信できます。 OpenSearch Ingestion にデータを送信するようにデータ プロデューサーを構成します。指定したドメインまたはコレクションにデータが自動的に配信されます。データを配信する前に変換するように OpenSearch Ingestion を構成することもできます。 OpenSearch インジェストはサーバーレスであるため、インフラストラクチャの拡張、インジェスト フリートの運用、ソフトウェアのパッチ適用や更新について心配する必要はありません。
Amazon S3 をソースとして使用して、OpenSearch Ingestion でデータを処理するには 3 つの方法があります。最初のオプションは S3-SQS 処理です。 S3 に書き込まれたファイルをほぼリアルタイムでスキャンする必要がある場合は、SXNUMX-SQS 処理を使用できます。それには、 Amazon シンプル キュー サービス (Amazon S3) を受信するキュー S3 イベント通知。処理対象のバケット内でオブジェクトが保存または変更されるたびにイベントを発生させるように S3 バケットを設定できます。
あるいは、3 回限りまたは定期的なスケジュールされたスキャンを使用して、S3 バケット内のデータをバッチ処理することもできます。スケジュールされたスキャンを設定するには、すべての SXNUMX バケットに適用されるスキャン レベル、またはバケット レベルでスケジュールを使用してパイプラインを構成します。スケジュールされたスキャンは、XNUMX 回限りのスキャンまたはバッチ処理用の定期的なスキャンで構成できます。
OpenSearch インジェストの包括的な概要については、次を参照してください。 Amazon OpenSearch の取り込み。 Data Prepper オープンソース プロジェクトの詳細については、次のサイトを参照してください。 データプリッパー.
ソリューションの概要
次の主要コンポーネントを含むアーキテクチャ パターンを示します。
- アプリケーション ログはデータ レイクにストリーミングされ、OpenSearch Ingestion を使用してホット データをほぼリアルタイムで OpenSearch サービスにフィードするのに役立ちます。 S3-SQS処理.
- OpenSearch Service 内の ISM ポリシーは、インデックスのロールオーバーまたは削除を処理します。 ISM ポリシーを使用すると、インデックスの経過時間、インデックス サイズ、ドキュメント数の変化に基づいてこれらの定期的な管理操作をトリガーすることで、これらの定期的な管理操作を自動化できます。たとえば、2 日後にインデックスを読み取り専用状態に移行し、3 日の設定期間後にインデックスを削除するポリシーを定義できます。
- コールド データは S3 データ レイクで利用でき、OpenSearch インジェストを使用して OpenSearch サービスでオンデマンドで消費されます。 スケジュールされたスキャン。
次の図は、ソリューションのアーキテクチャを示しています。
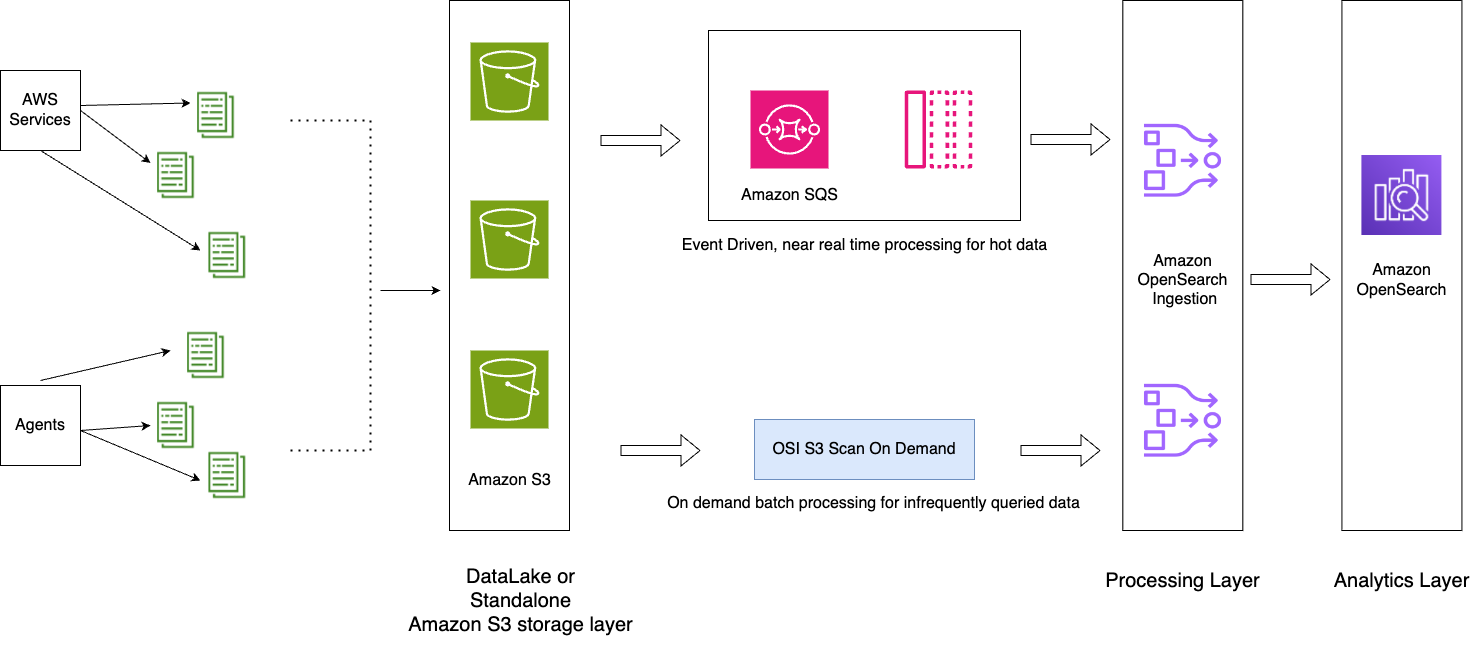
ワークフローには次の手順が含まれます。
- アプリケーションによって生成された受信データは、S3 データレイクにストリーミングされます。
- 当日のデータは、S3 バケットに設定された通知を通じて、S3-SQS のほぼリアルタイムの取り込みを使用して OpenSearch サービスに取り込まれます。
- 簡単にロールオーバーできるように、毎日のインデックスが維持されます。 ISM ポリシーは、2 日より古いインデックスのロールオーバーまたは削除を自動化します。
- 2 日を超えてデータ分析のリクエストが行われ、データが UltraWarm 層にない場合、データは特定の時間枠の間に Amazon S3 のワンタイム スキャン機能を使用して取り込まれます。
たとえば、現在が 10 年 2024 月 6 日で、分析のために特定の間隔で 2024 年 3 月 XNUMX 日のデータが必要な場合、YAML 設定で Amazon SXNUMX スキャンを使用する OpenSearch インジェスト パイプラインを作成できます。 start_time & end_time バケット内のオブジェクトをいつスキャンするかを指定するには、次のようにします。
考慮事項
圧縮を活用する
Amazon S3 内のデータは圧縮できるため、全体的なデータ フットプリントが削減され、大幅なコスト削減につながります。たとえば、毎月 15 PB の生の JSON アプリケーション ログを生成している場合、GZIP などの圧縮メカニズムを使用すると、サイズを約 1 PB 以下に削減でき、大幅なコスト削減につながります。
可能な場合はパイプラインを停止します
OpenSearch Ingestion は、パイプラインに設定された最小 OCU と最大 OCU の間で自動的にスケーリングします。パイプラインがパイプライン設定に記載されている指定期間の Amazon S3 スキャンを完了した後、パイプラインは継続して実行され、最小 OCU での継続的なモニタリングが行われます。
新しいオブジェクトが作成されることが予想されない過去の期間のオンデマンド取り込みの場合は、次のようなサポートされているパイプライン メトリクスの使用を検討してください。 recordsOut.count 作成する アマゾンクラウドウォッチ パイプラインを停止する可能性のあるアラーム。サポートされているメトリクスのリストについては、を参照してください。 パイプラインメトリクスのモニタリング.
CloudWatch アラームは、CloudWatch メトリクスが一定期間指定された値を超えたときにアクションを実行します。たとえば、次のように監視するとよいでしょう。 recordsOut.count へのリクエストを開始するには、0 分を超えて 5 になる必要があります。 パイプラインを停止する スルー AWSコマンドラインインターフェイス (AWS CLI) または API。
解決策 3: Amazon S3 を使用した OpenSearch Service の直接クエリ
Amazon S3 を使用した OpenSearch Service の直接クエリ (プレビュー) は、サービス間を切り替えることなく、Amazon S3 および S3 データレイクの操作ログをクエリする新しい方法です。クラウド オブジェクト ストアで頻繁にクエリされないデータを分析し、同時に OpenSearch Service の運用分析および視覚化機能を使用できるようになりました。
Amazon S3 を使用した OpenSearch Service の直接クエリが提供するもの ゼロETL統合 運用データを直接クエリできるようにすることで、データの複製や複数の分析ツールの管理に伴う運用の複雑さを軽減し、コストとアクションまでの時間を削減します。このゼロ ETL 統合は OpenSearch Service 内で構成可能であり、事前定義されたダッシュボードを含むさまざまなログ タイプ テンプレートを利用し、そのログ タイプに合わせたデータ アクセラレーションを構成できます。テンプレートには以下が含まれます VPC フローログ, 弾性負荷分散 ログ、NGINX ログ、およびアクセラレーションには、インデックスのスキップ、マテリアライズド ビュー、およびカバーされたインデックスが含まれます。
Amazon S3 を使用した OpenSearch Service の直接クエリを使用すると、セキュリティフォレンジックや脅威分析に重要な複雑なクエリを実行し、複数のデータソース間でデータを関連付けることができるため、チームがサービスのダウンタイムやセキュリティイベントを調査するのに役立ちます。統合を作成した後、OpenSearch ダッシュボードまたは OpenSearch API から直接データのクエリを開始できます。接続を監査して、接続がスケーラブルでコスト効率が高く、安全な方法で設定されていることを確認できます。
OpenSearch Service から Amazon S3 への直接クエリでは、 AWSグルー データカタログ。テーブルが AWS Glue メタデータ カタログにカタログ化されると、OpenSearch ダッシュボードを通じて S3 データレイク内のデータに対して直接クエリを実行できます。
ソリューションの概要
次の図は、ソリューションのアーキテクチャを示しています。
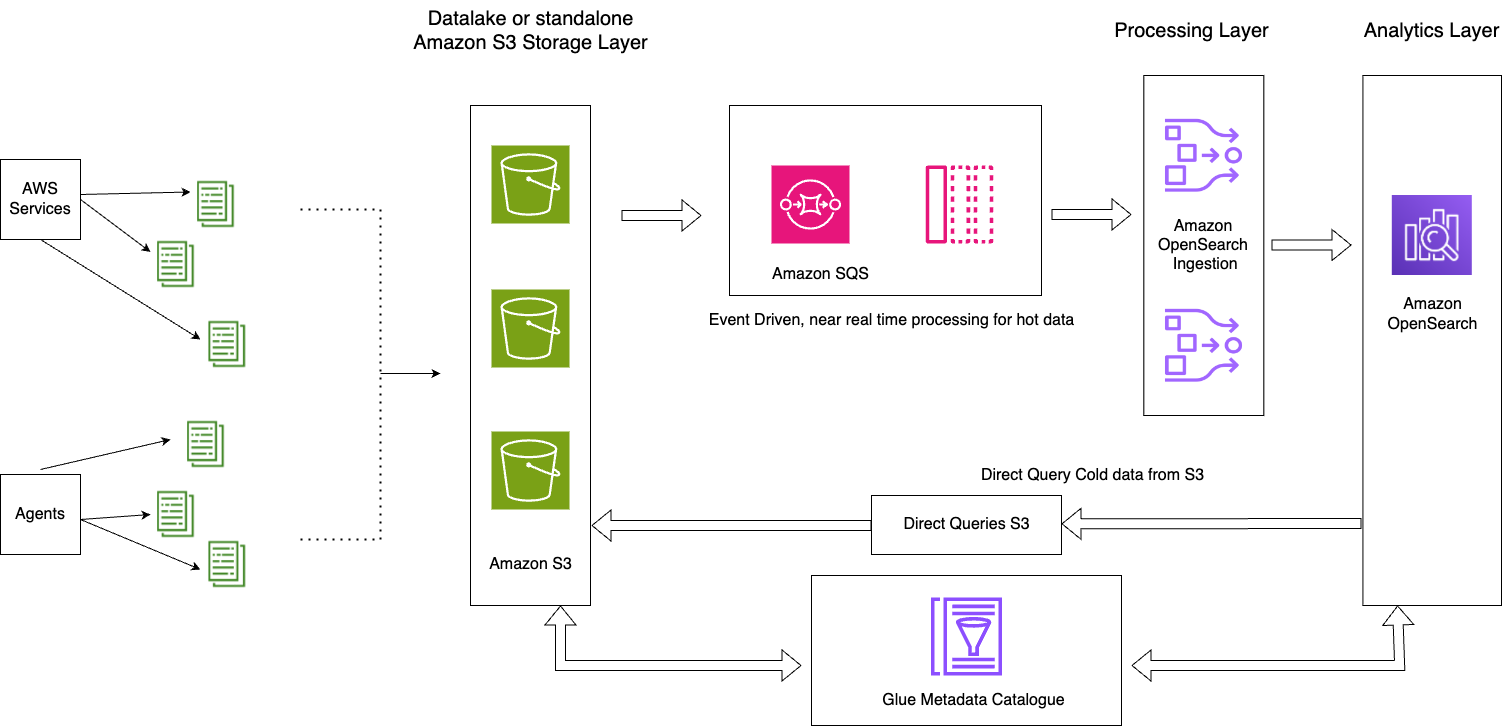
このソリューションは、次の主要コンポーネントで構成されています。
- その日のホット データは、OpenSearch Ingestion S3-SQS 処理機能を使用したイベント駆動型アーキテクチャ パターンを通じて OpenSearch Service ドメインにストリーム処理されます。
- ホット データのライフサイクルは、毎日のインデックスに添付された ISM ポリシーを通じて管理されます。
- コールド データは Amazon S3 バケット内に存在し、パーティション化されカタログ化されます。
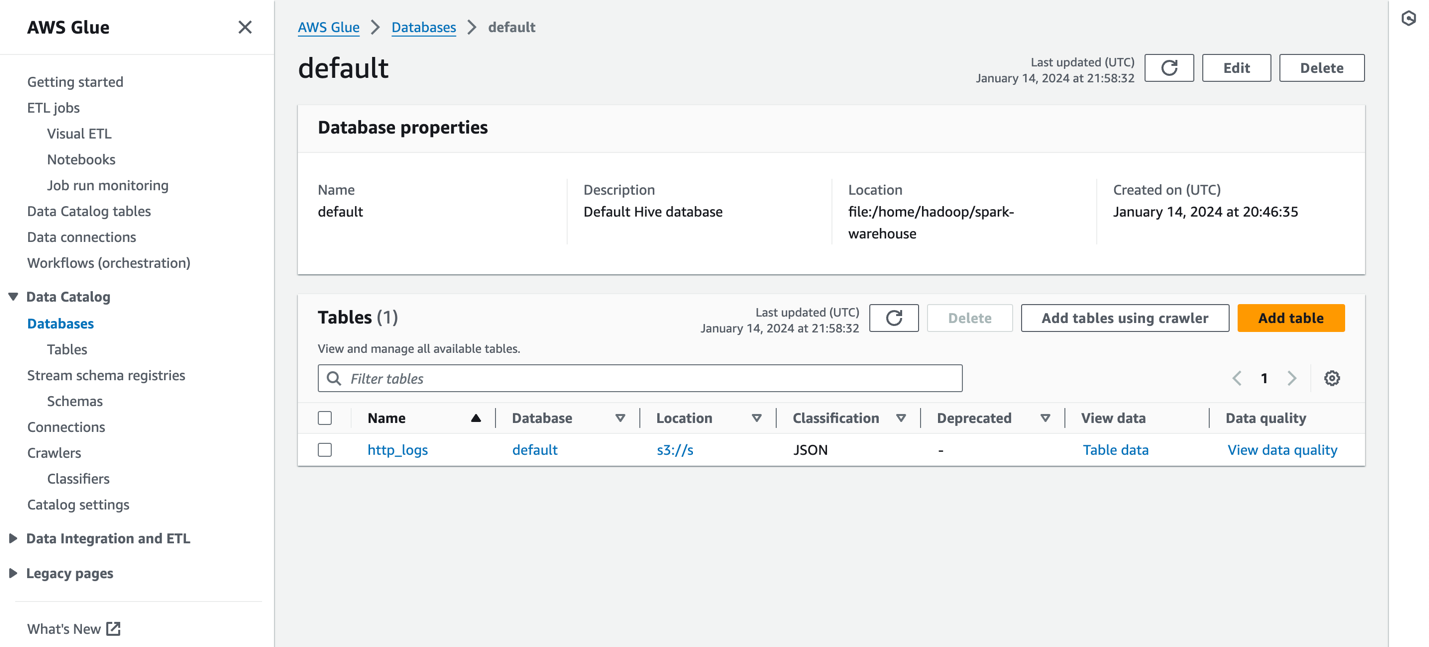
次のスクリーンショットはサンプルを示しています http_logs AWS Glue メタデータ カタログにカタログされているテーブル。詳細な手順については、を参照してください。 AWS Glue のデータカタログとクローラー.
データソースを作成する前に、バージョン 2.11 以降の OpenSearch Service ドメインと、適切なデータ カタログを持つ AWS Glue データ カタログ内のターゲット S3 テーブルが必要です。 AWS IDおよびアクセス管理 (IAM) 権限。 IAM には、目的の S3 バケットへのアクセスと、AWS Glue データ カタログへの読み取りおよび書き込みアクセスが必要です。以下は、OpenSearch サービスを通じて AWS Glue データ カタログにアクセスするための適切なアクセス許可を持つロールと信頼ポリシーの例です。
以下は、Amazon S3 および AWS Glue にアクセスするカスタム ポリシーのサンプルです。
OpenSearch Service コンソールで新しいデータ ソースを作成するには、新しいデータ ソースの名前を指定し、データ ソース タイプを次のように指定します。 Amazon S3 と AWS Glue データカタログをクリックし、データ ソースの IAM ロールを選択します。
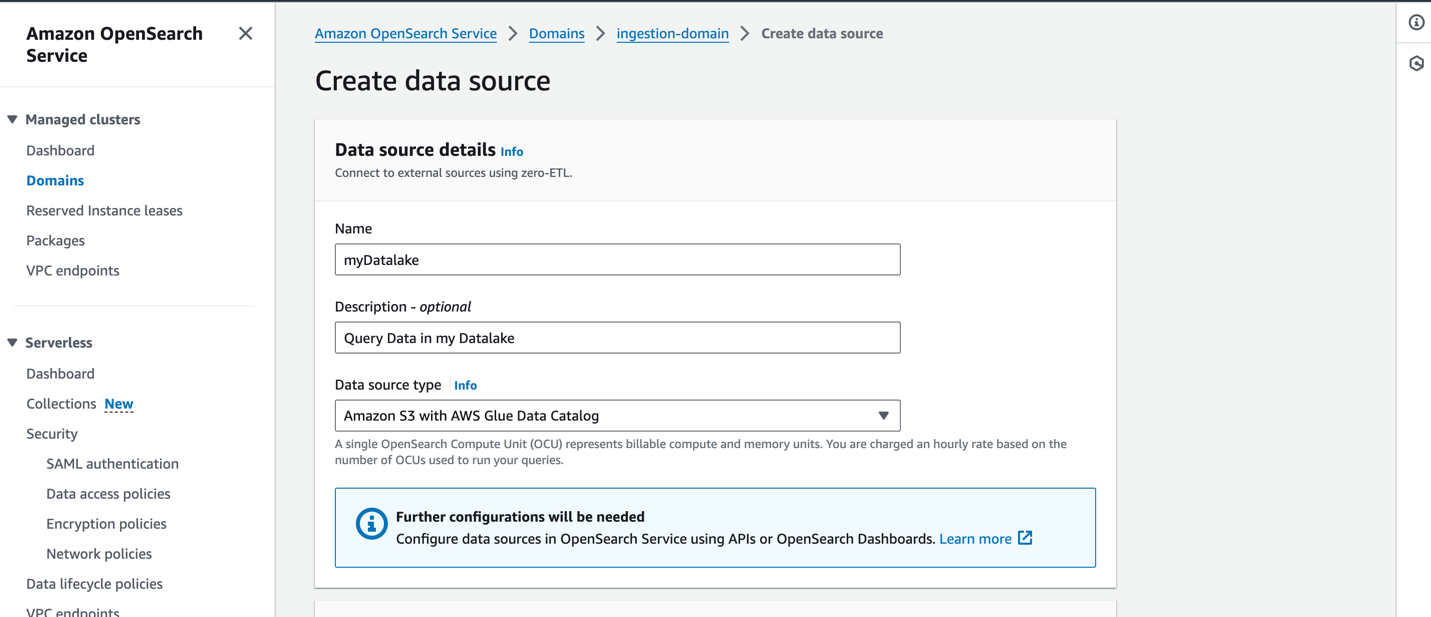
データ ソースを作成した後、ドメインの OpenSearch ダッシュボードに移動して、アクセス制御の構成、テーブルの定義、一般的なログ タイプのログ タイプ ベースのダッシュボードの設定、およびデータのクエリに使用できます。

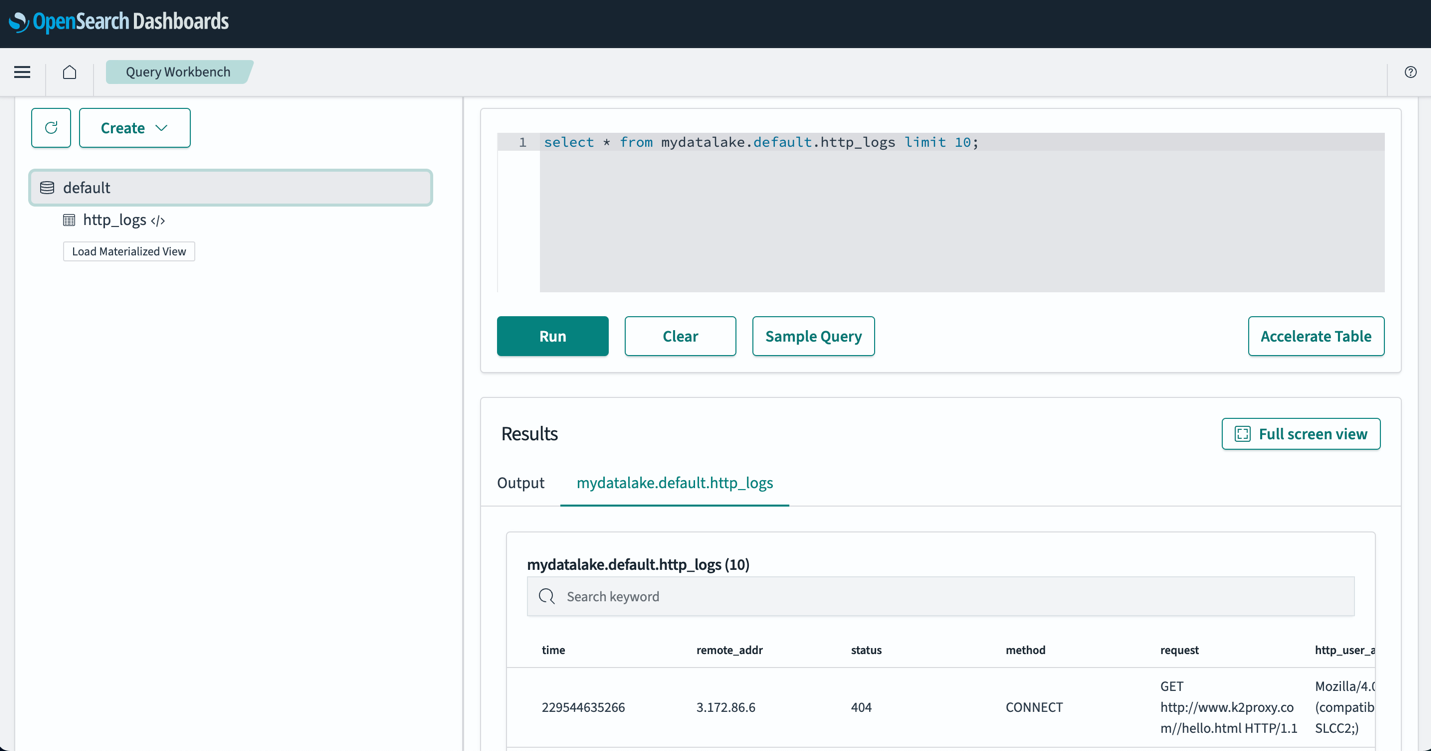
テーブルを設定したら、OpenSearch ダッシュボードを通じて S3 データ レイク内のデータをクエリできます。サンプル SQL クエリを実行できます。 http_logs 次のスクリーンショットに示すように、AWS Glue データカタログテーブルに作成したテーブル。
ベストプラクティス
必要なデータのみを取り込む
ビジネス ニーズから逆算して、必要な適切なデータセットを確立します。ノイズの多いデータの取り込みを回避し、厳選、サンプリング、または集約されたデータのみを取り込めるかどうかを評価します。これらのクリーンで厳選されたデータセットを使用すると、このデータの取り込みに必要なコンピューティング リソースとストレージ リソースを最適化するのに役立ちます。
取り込む前にデータのサイズを削減する
データ取り込みパイプラインを設計するときは、圧縮、フィルタリング、集計などの戦略を使用して、取り込まれたデータのサイズを削減します。これにより、より小さいデータ サイズをネットワーク経由で転送し、データ層に保存できるようになります。
まとめ
この投稿では、最新のデータ アーキテクチャで OpenSearch Service を使用してペタバイト規模のログ分析を可能にするソリューションについて説明しました。サーバーレス インジェスト パイプラインを作成して OpenSearch Service ドメインにログを配信し、ISM ポリシーを通じてインデックスを管理し、OpenSearch インジェストの使用を開始するための IAM 権限を構成し、データ レイク内のデータのパイプライン構成を作成する方法を学習しました。また、Amazon S3 機能 (プレビュー) を使用して OpenSearch サービスの直接クエリを設定して使用し、データレイクからデータをクエリする方法についても学習しました。
OpenSearch サービスを大規模に使用する場合にワークロードに適切なアーキテクチャ パターンを選択するには、パフォーマンス、レイテンシ、コスト、時間の経過に伴うデータ ボリュームの増加を考慮して、正しい決定を下してください。
- ホット データへの高速アクセスが必要で、読み取り専用データ用の UltraWarm ノードを使用してコストとパフォーマンスのバランスをとりたい場合は、インデックス状態管理ポリシーを備えた階層型ストレージ アーキテクチャを使用します。
- ホット ノードに保持されていないデータをクエリするための取り込み遅延を許容できる場合は、OpenSearch Service へのデータのオンデマンド取り込みを使用します。 Amazon S3 で圧縮データを使用し、オンデマンドでデータを OpenSearch Service に取り込むと、大幅なコスト削減を実現できます。
- OpenSearch Service の豊富な分析機能と視覚化機能を使用して、Amazon S3 の操作ログを直接分析する場合は、S3 機能による直接クエリを使用します。
次のステップとして、を参照してください。 Amazon OpenSearch 開発者ガイド エンタープライズ アプリケーション用のスケーラブルなオブザーバビリティ ソリューションを構築するために使用できるログとメトリック パイプラインを調べます。
著者について
 ジャガディッシュ・クマール (ジャグ) AWS のシニアスペシャリストソリューションアーキテクトであり、Amazon OpenSearch Service に重点を置いています。彼はデータ アーキテクチャに深い情熱を持っており、顧客が AWS 上で大規模な分析ソリューションを構築できるよう支援しています。
ジャガディッシュ・クマール (ジャグ) AWS のシニアスペシャリストソリューションアーキテクトであり、Amazon OpenSearch Service に重点を置いています。彼はデータ アーキテクチャに深い情熱を持っており、顧客が AWS 上で大規模な分析ソリューションを構築できるよう支援しています。
 ムトゥ・ピッチャイマニ Amazon OpenSearch Service のシニア スペシャリスト ソリューション アーキテクトです。彼は大規模な検索アプリケーションとソリューションを構築しています。 Muthu はネットワーキングとセキュリティのトピックに興味があり、テキサス州オースティンに拠点を置いています。
ムトゥ・ピッチャイマニ Amazon OpenSearch Service のシニア スペシャリスト ソリューション アーキテクトです。彼は大規模な検索アプリケーションとソリューションを構築しています。 Muthu はネットワーキングとセキュリティのトピックに興味があり、テキサス州オースティンに拠点を置いています。
 サム・セルバン Amazon OpenSearch Service のプリンシパル スペシャリスト ソリューション アーキテクトです。
サム・セルバン Amazon OpenSearch Service のプリンシパル スペシャリスト ソリューション アーキテクトです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/petabyte-scale-log-analytics-with-amazon-s3-amazon-opensearch-service-and-amazon-opensearch-ingestion/

