At AWS re:Invent 2023 年に、一般提供開始を発表しました。 Amazon Bedrock のナレッジベース。 Amazon Bedrock のナレッジベースを使用すると、基盤モデル (FM) を安全に接続できます。 アマゾンの岩盤 フルマネージドの取得拡張生成 (RAG) モデルを使用して、企業データにデータを追加します。
RAG ベースのアプリケーションの場合、FM から生成される応答の精度は、モデルに提供されるコンテキストによって異なります。コンテキストは、ユーザーのクエリに基づいてベクター ストアから取得されます。最近リリースされた Amazon Bedrock のナレッジベースの機能では、 ハイブリッド検索では、セマンティック検索とキーワード検索を組み合わせることができます。ただし、多くの状況では、定義された期間に作成されたドキュメント、または特定のカテゴリでタグ付けされたドキュメントを取得する必要がある場合があります。検索結果を絞り込むには、ドキュメントのメタデータに基づいてフィルタリングして検索精度を向上させることができます。これにより、関心に合わせた、より関連性の高い FM 世代が得られます。
この投稿では、Amazon Bedrock のナレッジベースの新しいカスタム メタデータ フィルタリング機能について説明します。この機能を使用すると、ベクター ストアからの取得を事前にフィルタリングすることで検索結果を改善できます。
メタデータフィルタリングの概要
メタデータ フィルタリングのリリース前は、事前に設定された最大値までの意味的に関連するすべてのチャンクが、応答の生成に使用する FM のコンテキストとして返されていました。メタデータ フィルターを使用すると、意味的に関連するチャンクだけでなく、適用されたメタデータ フィルターと関連する値に基づいて、それらの関連するチャックの明確に定義されたサブセットを取得できるようになります。
この機能を使用すると、ナレッジ ベース内のドキュメントごとにカスタム メタデータ ファイル (それぞれ最大 10 KB) を提供できるようになります。検索にフィルターを適用して、ベクター ストアにドキュメントのメタデータに基づいて事前にフィルターをかけ、関連するドキュメントを検索するように指示できます。こうすることで、特にクエリがあいまいな場合に、取得したドキュメントを制御できます。たとえば、異なるコンテキストで同様の用語が含まれる法律文書を使用したり、異なる年に公開された同様のプロットを含む映画を使用したりできます。さらに、検索されるチャンクの数を減らすことで、精度の向上に加えて、CPU サイクルやベクター ストアのクエリのコストの削減などのパフォーマンス上の利点も得られます。

メタデータ フィルタリング機能を使用するには、ソース データ ファイルと同じ名前のメタデータ ファイルをソース データ ファイルと一緒に提供する必要があります。 .metadata.json サフィックス。メタデータには文字列、数値、またはブール値を指定できます。以下はメタデータ ファイルの内容の例です。
Amazon Bedrock のナレッジベースのメタデータフィルタリング機能は、米国東部 (バージニア北部) と米国西部 (オレゴン) の AWS リージョンで利用できます。
メタデータ フィルタリングの一般的な使用例は次のとおりです。
- ソフトウェア会社向けのドキュメントチャットボット – これにより、ユーザーは製品情報やトラブルシューティング ガイドを見つけることができます。たとえば、オペレーティング システムやアプリケーションのバージョンに基づくフィルターは、古いドキュメントや無関係なドキュメントの取得を回避するのに役立ちます。
- 組織のアプリケーションの会話型検索 – これにより、ユーザーは文書、カンバン、会議記録記録、およびその他の資産を検索できます。作業グループ、事業単位、またはプロジェクト ID に対してメタデータ フィルターを使用すると、チャット エクスペリエンスをパーソナライズし、コラボレーションを向上させることができます。例としては、「プロジェクト Sphinx のステータスと発生するリスクは何ですか」が挙げられ、ユーザーは特定のプロジェクトまたはソース タイプ (電子メールや会議資料など) のドキュメントをフィルターできます。
- ソフトウェア開発者向けのインテリジェントな検索 – これにより、開発者は特定のリリースの情報を探すことができます。リリース バージョン、ドキュメント タイプ (コード、API リファレンス、問題など) によるフィルターは、関連するドキュメントを正確に特定するのに役立ちます。
ソリューションの概要
次のセクションでは、ナレッジ ベースとして使用するデータセットを準備し、メタデータ フィルタリングを使用してクエリを実行する方法を示します。次のいずれかを使用してクエリを実行できます。 AWSマネジメントコンソール またはSDK。
Amazon Bedrock のナレッジベース用のデータセットを準備する
この投稿では、 サンプルデータセット 架空のビデオゲームについて説明し、Amazon Bedrock のナレッジベースを使用してメタデータを取り込み、取得する方法を説明します。自分の AWS アカウントで作業を進めたい場合は、ファイルをダウンロードしてください。
既存のナレッジ ベース内のドキュメントにメタデータを追加する場合は、必要なファイル名とスキーマを使用してメタデータ ファイルを作成し、データをナレッジ ベースと同期する手順に進んで増分取り込みを開始します。
サンプル データセットでは、各ゲームのドキュメントは個別の CSV ファイルです (たとえば、 s3://$bucket_name/video_game/$game_id.csv) 次の列があります。
title, description, genres, year, publisher, score
各ゲームのメタデータには接尾辞が付いています。 .metadata.json (例えば、 s3://$bucket_name/video_game/$game_id.csv.metadata.json) 次のスキーマを使用します。
Amazon Bedrock のナレッジベースを作成する
新しいナレッジ ベースを作成する手順については、次を参照してください。 知識ベースを作成する。この例では、次の設定を使用します。
- ソフトウェア設定ページで、下図のように データソースのセットアップ ページ、下 チャンク戦略選択 チャンキングなし, 前のステップですでにドキュメントを前処理しているためです。
- 埋め込みモデル セクションでは、選択 Titan G1 埋め込み - テキスト.
- ベクトルデータベース セクションでは、選択 新しいベクター ストアを簡単に作成する。メタデータ フィルタリング機能は、サポートされているすべてのベクター ストアで利用できます。
データセットをナレッジベースと同期する
ナレッジ ベースを作成し、データ ファイルとメタデータ ファイルを Amazon シンプル ストレージ サービス (Amazon S3) バケットを使用すると、増分取り込みを開始できます。手順については、を参照してください。 同期してデータ ソースをナレッジ ベースに取り込む.
Amazon Bedrock コンソールでのメタデータ フィルタリングを使用したクエリ
Amazon Bedrock コンソールでメタデータフィルタリングオプションを使用するには、次の手順を実行します。
- Amazon Bedrock コンソールで、 ナレッジベース ナビゲーションペインに表示されます。
- 作成したナレッジ ベースを選択します。
- 選択する テストの知識ベース.
- 選択する 構成 アイコンをクリックして展開します フィルタ.
- キー = 値 (例: ジャンル = 戦略) の形式で条件を入力し、 を押します。 入力します.
- キー、値、または演算子を変更するには、条件を選択します。
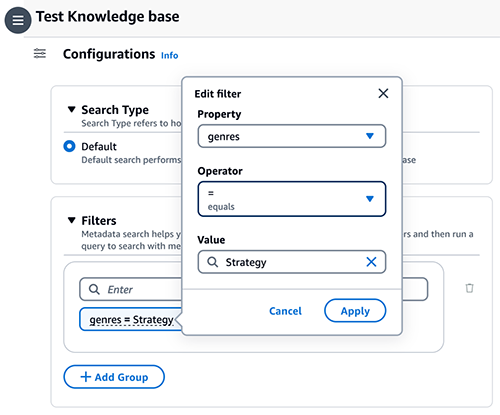
- 残りの条件を続けます (例: (ジャンル = 戦略 AND 年 >= 2023) OR (評価 >= 9))

- 完了したら、メッセージ ボックスにクエリを入力し、[ ラン.
この投稿では、「2023 年以降にリリースされるクールなグラフィックのストラテジー ゲーム」というクエリを入力します。
SDKを使用したメタデータフィルタリングによるクエリ
SDK を使用するには、まず SDK のクライアントを作成します。 Amazon Bedrock のエージェント ランタイム:
次に、フィルターを構築します (以下はいくつかの例です)。
フィルターを渡す retrievalConfiguration 検索API or 取得して生成する API:
次の表に、さまざまなメタデータ フィルタリング条件を持ついくつかの応答を示します。
| クエリー | メタデータのフィルタリング | 取得した文書 | 観測 |
| 「2023年以降にリリースされるクールなグラフィックのストラテジーゲーム」 | オフ |
* ヴァイキング サーガ: シー レイダー、年: 2023、ジャンル: ストラテジー * 中世の城: 包囲と征服、年:2022、ジャンル: ストラテジー * サイバネティック革命: マシンの台頭、年:2022、ジャンル: ストラテジー |
2/5 のゲームが条件を満たしています (ジャンル = ストラテジー、年 >= 2023) |
| On | * ヴァイキング サーガ: シー レイダー、年: 2023、ジャンル: ストラテジー * Fantasy Kingdoms: Chronicles of Eldria、年:2023、ジャンル: ストラテジー |
2/2 のゲームが条件を満たしています (ジャンル = ストラテジー、年 >= 2023) |
カスタム メタデータに加えて、S3 プレフィックスを使用してフィルタリングすることもできます (これは組み込みのメタデータであるため、メタデータ ファイルを提供する必要はありません)。たとえば、ゲーム ドキュメントを発行者ごとにプレフィックスに編成すると (たとえば、 s3://$bucket_name/video_game/$publisher/$game_id.csv)、特定の発行者でフィルタリングできます(たとえば、 neo_tokyo_games) 次の構文を使用します。
クリーンアップ
リソースをクリーンアップするには、次の手順を実行します。
- ナレッジ ベースを削除します。
- Amazon Bedrock コンソールで、 ナレッジベース 下 編成 ナビゲーションペインに表示されます。
- 作成したナレッジ ベースを選択します。
- に注意してください AWS IDおよびアクセス管理 (IAM) サービス ロール名 ナレッジベースの概要 のセクションから無料でダウンロードできます。
- ベクトルデータベース セクションで、コレクション ARN に注目してください。
- 選択する 削除、次に「削除」と入力して確認します。
- ベクター データベースを削除します。
- ソフトウェア設定ページで、下図のように AmazonOpenSearchサービス コンソール、選択 コレクション 下 サーバレス ナビゲーションペインに表示されます。
- 検索バーに保存したコレクション ARN を入力します。
- コレクションを選択して選択しました 削除.
- 確認プロンプトに「confirm」と入力し、選択します 削除.
- IAM サービス ロールを削除します。
- IAMコンソールで、 役割 ナビゲーションペインに表示されます。
- 前にメモしたロール名を検索します。
- 役割を選択して選択します 削除.
- 確認プロンプトにロール名を入力し、ロールを削除します。
- サンプル データセットを削除します。
- Amazon S3 コンソールで、使用した S3 バケットに移動します。
- プレフィックスとファイルを選択し、 削除.
- 削除する場合は、確認プロンプトに「完全に削除」と入力します。
まとめ
この投稿では、Amazon Bedrock のナレッジベースのメタデータ フィルタリング機能について説明しました。 Amazon Bedrock コンソールと SDK を使用してドキュメントを取得およびクエリする際に、カスタムメタデータをドキュメントに追加し、フィルタとして使用する方法を学習しました。これにより、コンテキストの精度が向上し、ベクトル データベースへのクエリのコストの削減を達成しながら、クエリ応答の関連性がさらに高まります。
追加のリソースについては、以下を参照してください。
著者について
 コーバス・リー ロンドンを拠点とする GenAI Labs のシニア ソリューション アーキテクトです。彼は、生成 AI を使用して顧客の問題を解決するプロトタイプの設計と開発に情熱を注いでいます。また、生成 AI と検索技術を現実世界のシナリオに適用することで、最新の開発状況を常に把握しています。
コーバス・リー ロンドンを拠点とする GenAI Labs のシニア ソリューション アーキテクトです。彼は、生成 AI を使用して顧客の問題を解決するプロトタイプの設計と開発に情熱を注いでいます。また、生成 AI と検索技術を現実世界のシナリオに適用することで、最新の開発状況を常に把握しています。
 アーメド・イーウィス は、AWS GenAI Labs のシニア ソリューション アーキテクトであり、お客様がビジネス上の問題を解決するための生成 AI プロトタイプを構築するのを支援しています。顧客と協力していないときは、子供たちと遊んだり、料理をしたりすることを楽しんでいます。
アーメド・イーウィス は、AWS GenAI Labs のシニア ソリューション アーキテクトであり、お客様がビジネス上の問題を解決するための生成 AI プロトタイプを構築するのを支援しています。顧客と協力していないときは、子供たちと遊んだり、料理をしたりすることを楽しんでいます。
 クリス・ペコラ アマゾン ウェブ サービスのジェネレーティブ AI データ サイエンティストです。彼は革新的な製品とソリューションの構築に情熱を注ぐと同時に、顧客重視の科学にも注力しています。実験を行っていないときや、GenAI の最新の開発状況を把握しているときは、子供たちと時間を過ごすのが大好きです。
クリス・ペコラ アマゾン ウェブ サービスのジェネレーティブ AI データ サイエンティストです。彼は革新的な製品とソリューションの構築に情熱を注ぐと同時に、顧客重視の科学にも注力しています。実験を行っていないときや、GenAI の最新の開発状況を把握しているときは、子供たちと時間を過ごすのが大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-metadata-filtering-to-improve-retrieval-accuracy/

