Introduction
LlamaIndex is a popular framework for building LLM applications. To build a robust application, we need to know how to count the embedding tokens before making them, ensure there are no duplicates in the vector store, get source data for the generated response, and many other things. This article will review the steps to build a resilient application using LlamaIndex.
Learning Objectives
- Understand the essential components and functions of the LlamaIndex framework for building robust LLM applications.
- Learn how to create and run an efficient ingestion pipeline to transform, parse, and store documents.
- Gain knowledge on initializing, saving, and loading documents and vector stores to manage persistent data storage effectively.
- Master building indices and using custom prompts to facilitate efficient querying and continuous interactions with chat engines.

Table of contents
Prerequisites
Here are a few prerequisites to build an application using LlamaIndex.
Use the .env file to store the OpenAI Key and load it from the file
import os
from dotenv import load_dotenv
load_dotenv('/.env') # provide path of the .env file
OPENAI_API_KEY = os.environ['OPENAI_API_KEY']We will use Paul Graham’s essay as an example document. It can be downloaded from here https://github.com/run-llama/llama_index/blob/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt
How to Build an Application Using LlamaIndex
Load the Data
The first step in building an application using LlamaIndex is to load the data.
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader(input_files=["./data/paul_graham_essay.txt"],
filename_as_id=True).load_data(show_progress=True)
# 'documents' is a list, which contains the files we have loadedLet us look at the keys of the document object
documents[0].to_dict().keys()
# output
"""
dict_keys(['id_', 'embedding', 'metadata', 'excluded_embed_metadata_keys',
'excluded_llm_metadata_keys', 'relationships', 'text', 'start_char_idx',
'end_char_idx', 'text_template', 'metadata_template', 'metadata_seperator',
'class_name'])
"""We can modify the values of those keys as we do for a dictionary. Let us look at an example with metadata.
If we want to add more information about the document, we can add it to the document metadata as follows. These metadata tags can be used to filter the documents.
documents[0].metadata.update({'author': 'paul_graham'})
documents[0].metadata
# output
"""
{'file_path': 'data/paul_graham_essay.txt',
'file_name': 'paul_graham_essay.txt',
'file_type': 'text/plain',
'file_size': 75042,
'creation_date': '2024-04-16',
'last_modified_date': '2024-04-15',
'author': 'paul_graham'}
"""Ingestion Pipeline
With the ingestion pipeline, we can perform all the data transformations, such as parsing the document into nodes, extracting metadata for the nodes, creating embeddings, storing the data in the doc store, and storing the embeddings and text of the nodes in the vector store. This allows us to keep everything needed to make the data available for indexing in one place.
More importantly, using the doc store and vector store will ensure that duplicate embeddings are not created if we save and load the doc store and vector stores and run the ingestion pipeline on the same documents.
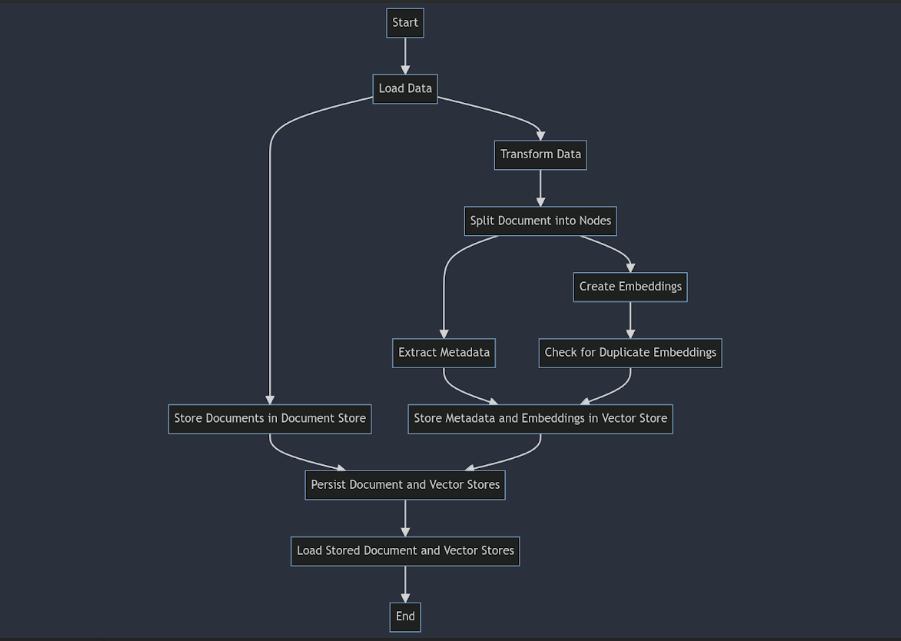
Token Counting
The next step in building an application using LlamaIndex is token counting.
import the dependencies
import nest_asyncio
nest_asyncio.apply()
import tiktoken
from llama_index.core.callbacks import CallbackManager, TokenCountingHandler
from llama_index.core import MockEmbedding
from llama_index.core.llms import MockLLM
from llama_index.core.node_parser import SentenceSplitter,HierarchicalNodeParser
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.extractors import TitleExtractor, SummaryExtractorInitialize the token counter
token_counter = TokenCountingHandler(
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode,
verbose=True
)Now, we can move on to build an ingestion pipeline using MockEmbedding and MockLLM.
mock_pipeline = IngestionPipeline(
transformations = [SentenceSplitter(chunk_size=512, chunk_overlap=64),
TitleExtractor(llm=MockLLM(callback_manager=CallbackManager([token_counter]))),
MockEmbedding(embed_dim=1536, callback_manager=CallbackManager([token_counter]))])
nodes = mock_pipeline.run(documents=documents, show_progress=True, num_workers=-1)The above code applies a sentence splitter to the documents to create nodes, then uses mock embedding and llm models for metadata extraction and embedding creation.
Then, we can check the token counts
# this returns the count of embedding tokens
token_counter.total_embedding_token_count
# this returns the count of llm tokens
token_counter.total_llm_token_count
# token counter is cumulative. When we want to set the token counts to zero, we can use this
token_counter.reset_counts()We can try different node parsers and metadata extractors to determine how many tokens it will take.
Create Doc and Vector Stores
The next step in building an application using LlamaIndex is to create doc and vector stores.
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.storage.docstore import SimpleDocumentStore
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadbNow we can initialize the doc and vector stores
doc_store = SimpleDocumentStore()
# mention the path, where vector store is saved
chroma_client = chromadb.PersistentClient(path="./chroma_db")
# we will create a collection if doesn't already exists
chroma_collection = chroma_client.get_or_create_collection("paul_essay")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)pipeline = IngestionPipeline(
transformations = [SentenceSplitter(chunk_size=512, chunk_overlap=128),
OpenAIEmbedding(model_name='text-embedding-3-small',
callback_manager=CallbackManager([token_counter]))],
docstore=doc_store,
vector_store=vector_store
)
nodes = pipeline.run(documents=documents, show_progress=True, num_workers=-1)Once we run the pipeline, embeddings are stored in the vector store for the nodes. We also need to save the doc store.
doc_store.persist('./document storage/doc_store.json')
# we can also check the embedding token count
token_counter.total_embedding_token_countNow, we can restart the kernel to load the saved stores.
Load the Doc and Vector Stores
Now, let us import the necessary methods, as mentioned above.
# load the document store
doc_store = SimpleDocumentStore.from_persist_path('./document storage/doc_store.json')
# load the vector store
chroma_client = chromadb.PersistentClient(path="./chroma_db")
chroma_collection = chroma_client.get_or_create_collection("paul_essay")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
Now, you initialize the above pipeline again and run it. However, it doesn’t create embeddings because the system has already processed and stored the document. So, we add any new document to a folder, load all the documents, and run the pipeline, creating embeddings only for the new document.
We can check it with the following
# hash of the document
documents[0].hash
# you can get the doc name from the doc_store
for i in doc_store.docs.keys():
print(i)
# hash of the doc in the doc store
doc_store.docs['data/paul_graham_essay.txt'].hash
# When both of those hashes match, duplicate embeddings are not created. Look into the Vector Store
Let’s see what is stored in the vector store.
chroma_collection.get().keys()
# output
# dict_keys(['ids', 'embeddings', 'metadatas', 'documents', 'uris', 'data'])
chroma_collection.get()['metadatas'][0].keys()
# output
# dict_keys(['_node_content', '_node_type', 'creation_date', 'doc_id',
'document_id', 'file_name', 'file_path', 'file_size',
'file_type', 'last_modified_date', 'ref_doc_id'])
# this will return ids, metadatas, and documents of the nodes in the collection
chroma_collection.get() How do we know which node corresponds to which document? We can look into the metadata node_content
ids = chroma_collection.get()['ids']
# this will print doc name for each node
for i in ids:
data = json.loads(chroma_collection.get(i)['metadatas'][0]['_node_content'])
print(data['relationships']['1']['node_id'])# this will include the embeddings of the node along with metadata and text
chroma_collection.get(ids=ids[0],include=['embeddings', 'metadatas', 'documents'])
# we can also filter the collection
chroma_collection.get(ids=ids, where={'file_size': {'$gt': 75040}},
where_document={'$contains': 'paul'}, include=['metadatas', 'documents'])Querying
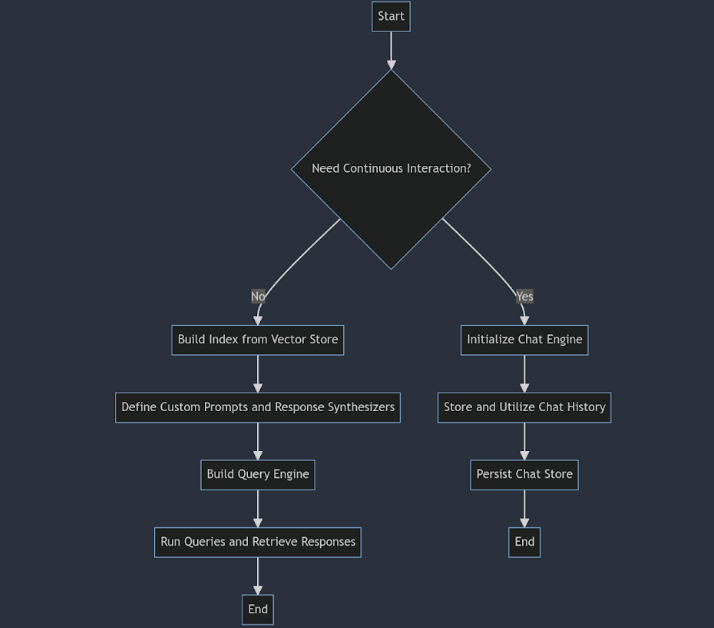
from llama_index.llms.openai import OpenAI
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core import get_response_synthesizer
from llama_index.core.response_synthesizers.type import ResponseMode
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import (ContextChatEngine,
CondenseQuestionChatEngine, CondensePlusContextChatEngine)
from llama_index.core.storage.chat_store import SimpleChatStore
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core import PromptTemplate
from llama_index.core.chat_engine.types import ChatMode
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core import ChatPromptTemplateNow, we can build an index from the vector store. An index is a data structure that facilitates the quick retrieval of relevant context for a user query.
# define the index
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
# define a retriever
retriever = VectorIndexRetriever(index=index, similarity_top_k=3)In the above code, the retriever retrieves the top 3 similar nodes to the query we give.
If we want the LLM to answer the query based on only the context provided and not anything else, we can use the custom prompts accordingly.
qa_prompt_str = (
"Context information is below.n"
"---------------------n"
"{context_str}n"
"---------------------n"
"Given the context information and not prior knowledge, "
"answer the question: {query_str}n"
)
chat_text_qa_msgs = [
ChatMessage(role=MessageRole.SYSTEM,
content=("Only answer the question, if the question is answerable with the given context.
Otherwise say that question can't be answered using the context"),
),
ChatMessage(role=MessageRole.USER, content=qa_prompt_str)]
text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)Now, we can define the response synthesizer, which passes the context and queries to the LLM to get the response. We can also add a token counter as a callback manager to keep track of the tokens used.
gpt_3_5 = OpenAI(model = 'gpt-3.5-turbo')
response_synthesizer = get_response_synthesizer(llm = gpt_3_5, response_mode=ResponseMode.COMPACT,
text_qa_template=text_qa_template,
callback_manager=CallbackManager([token_counter]))Now, we can combine the retriever and response_synthesizer as a query engine that takes the query.
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer)
# ask a query
Response = query_engine.query("who is paul graham?")
# response text
Response.responseTo know which text is used to generate this response, we can use the following code
for i, node in enumerate(Response.source_nodes):
print(f"text of the node {i}")
print(node.text)
print("------------------------------------n")Similarly, we can try different query engines.
Chatting
If we want to converse with our data, we need to store the previous queries and the responses rather than asking isolated queries.
chat_store = SimpleChatStore()
chat_memory = ChatMemoryBuffer.from_defaults(token_limit=5000, chat_store=chat_store, llm=gpt_3_5)
system_prompt = "Answer the question only based on the context provided"
chat_engine = CondensePlusContextChatEngine(retriever=retriever,
llm=gpt_3_5, system_prompt=system_prompt, memory=chat_memory)In the above code, we have initialized chat_store and created the chat_memory object with a token limit of 5000. We can also provide a system_prompt and other prompts.
Then, we can create a chat engine by also including retriever and chat_memory
We can get the response as follows
streaming_response = chat_engine.stream_chat("Who is Paul Graham?")
for token in streaming_response.response_gen:
print(token, end="")We can read the chat history with given code
for i in chat_memory.chat_store.store['chat_history']:
print(i.role.name)
print(i.content)Now we can save and restore the chat_store as needed
chat_store.persist(persist_path="chat_store.json")
chat_store = SimpleChatStore.from_persist_path(
persist_path="chat_store.json"
)This way, we can build robust RAG applications using the LlamaIndex framework and try various advanced retrievers and re-rankers.
Also Read: Build a RAG Pipeline With the LLama Index
Conclusion
The LlamaIndex framework offers a comprehensive solution for building resilient LLM applications, ensuring efficient data handling, persistent storage, and enhanced querying capabilities. It is a valuable tool for developers working with large language models. The key takeaways from this guide on LlamaIndex are:
- The LlamaIndex framework enables robust data ingestion pipelines, ensuring organized document parsing, metadata extraction, and embedding creation while preventing duplicates.
- By effectively managing document and vector stores, LlamaIndex ensures data consistency and facilitates easy retrieval and storage of document embeddings and metadata.
- The framework supports building indices and custom query engines, enabling quick context retrieval for user queries and continuous interactions through chat engines.
Frequently Asked Questions
A. The LlamaIndex framework is designed to build robust LLM applications. It provides tools for efficient data ingestion, storage, and retrieval, ensuring the organized and resilient handling of large language models.
A. LlamaIndex prevents duplicate embeddings by using document and vector stores to check existing embeddings before creating new ones, ensuring each document is processed only once.
A. LlamaIndex can handle various document types by parsing them into nodes, extracting metadata, and creating embeddings, making it versatile for different data sources.
A. LlamaIndex supports continuous interaction through chat engines, which store and utilize chat history, allowing for ongoing, context-aware conversations with the data.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.analyticsvidhya.com/blog/2024/06/how-to-build-a-resilient-application-using-llamaindex/

